|
从今天开始学习OpenCL……
安装AMD OpenCL APP 的过程我这里就不仔细说明了。
一个简单的OpenCL的程序
现在,我们开始写一个简单的OpenCL程序,计算两个数组相加的和,放到另一个数组中去。程序用cpu和gpu分别计算,最后验证它们是否相等。OpenCL程序的流程大致如下:

下面是source code中的主要代码:
int main(int argc, char* argv[])
{
//在host内存中创建三个缓冲区
float *buf1 = 0;
float *buf2 = 0;
float *buf = 0;
buf1 =(float *)malloc(BUFSIZE * sizeof(float));
buf2 =(float *)malloc(BUFSIZE * sizeof(float));
buf =(float *)malloc(BUFSIZE * sizeof(float));
//用一些随机值初始化buf1和buf2的内容
int i;
srand( (unsigned)time( NULL ) );
for(i = 0; i < BUFSIZE; i++)
buf1[i] = rand()%65535;
srand( (unsigned)time( NULL ) +1000);
for(i = 0; i < BUFSIZE; i++)
buf2[i] = rand()%65535;
//cpu计算buf1,buf2的和
for(i = 0; i < BUFSIZE; i++)
buf[i] = buf1[i] + buf2[i];
cl_uint status;
cl_platform_id platform;
//创建平台对象
status = clGetPlatformIDs( 1, &platform, NULL );
|
注意:如果我们系统中安装不止一个opencl平台,比如我的os中,有intel和amd两家opencl平台,用上面这行代码,有可能会出错,因为它得到了intel的opencl平台,而intel的平台只支持cpu,而我们后面的操作都是基于gpu,这时我们可以用下面的代码,得到AMD的opencl平台
cl_uint numPlatforms;
std::string platformVendor;
status = clGetPlatformIDs(0, NULL, &numPlatforms);
if(status != CL_SUCCESS)
{
return 0;
}
if (0 < numPlatforms)
{
cl_platform_id* platforms = new cl_platform_id[numPlatforms];
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
char platformName[100];
for (unsigned i = 0; i < numPlatforms; ++i)
{
status = clGetPlatformInfo(platforms[i],
CL_PLATFORM_VENDOR,
sizeof(platformName),
platformName,
NULL);
platform = platforms[i];
platformVendor.assign(platformName);
if (!strcmp(platformName, "Advanced Micro Devices, Inc."))
{
break;
}
}
std::cout << "Platform found : " << platformName << "\n";
delete[] platforms;
}
|
cl_device_id device;
//创建GPU设备
clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU,
1,
&device,
NULL);
//创建context
cl_context context = clCreateContext( NULL,
1,
&device,
NULL, NULL, NULL);
//创建命令队列
cl_command_queue queue = clCreateCommandQueue( context,
device,
CL_QUEUE_PROFILING_ENABLE, NULL );
//创建三个OpenCL内存对象,并把buf1的内容通过隐式拷贝的方式
//buf1内容拷贝到clbuf1,buf2的内容通过显示拷贝的方式拷贝到clbuf2
cl_mem clbuf1 = clCreateBuffer(context,
CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
BUFSIZE*sizeof(cl_float),buf1,
NULL );
cl_mem clbuf2 = clCreateBuffer(context,
CL_MEM_READ_ONLY ,
BUFSIZE*sizeof(cl_float),NULL,
NULL );
cl_event writeEvt;
status = clEnqueueWriteBuffer(queue, clbuf2, 1,
0, BUFSIZE*sizeof(cl_float), buf2, 0, 0, 0);
|
上面这行代码把buf2中的内容拷贝到clbuf2,因为buf2位于host端,clbuf2位于device端,所以这个函数会执行一次host到device的传输操作,或者说一次system
memory到video memory的拷贝操作,所以我在该函数的后面放置了clFush函数,表示把command
queue中的所有命令提交到device(注意:该命令并不保证命令执行完成),所以我们调用函数waitForEventAndRelease来等待write缓冲的完成,waitForEventAndReleae
是一个用户定义的函数,它的内容如下,主要代码就是通过event来查询我们的操作是否完成,没完成的话,程序就一直block在这行代码处,另外我们也可以用opencl中内置的函数clWaitForEvents来代替clFlush和waitForEventAndReleae。
//等待事件完成
int waitForEventAndRelease(cl_event *event)
{
cl_int status = CL_SUCCESS;
cl_int eventStatus = CL_QUEUED;
while(eventStatus != CL_COMPLETE)
{
status = clGetEventInfo(
*event,
CL_EVENT_COMMAND_EXECUTION_STATUS,
sizeof(cl_int),
&eventStatus,
NULL);
}
status = clReleaseEvent(*event);
return 0;
}
|
status = clFlush(queue);
//等待数据传输完成再继续往下执行
waitForEventAndRelease(&writeEvt);
cl_mem buffer = clCreateBuffer( context,
CL_MEM_WRITE_ONLY,
BUFSIZE * sizeof(cl_float),
NULL, NULL );
|
kernel文件中放的是gpu中执行的代码,它被放在一个单独的文件add.cl中,本程序中kernel代码非常简单,只是执行两个数组相加。kernel的代码为:
__kernel void vecadd(__global const float* A, __global const float* B, __global float* C)
{
int id = get_global_id(0);
C[id] = A[id] + B[id];
} |
//kernel文件为add.cl
const char * filename = "add.cl";
std::string sourceStr;
status = convertToString(filename, sourceStr);
|
convertToString也是用户定义的函数,该函数把kernel源文件读入到一个string中,它的代码如下:
/ f.read(str, fileSize);
f.close();
str[size] = '\0';
s = str;
delete[] str;
return 0;
}
printf("Error: Failed to open file %s\n", filename);
return 1;
} |
const char * source = sourceStr.c_str();
size_t sourceSize[] = { strlen(source) };
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
//编译程序对象
status = clBuildProgram( program, 1, &device, NULL, NULL, NULL );
if(status != 0)
{
printf("clBuild failed:%d\n", status);
char tbuf[0x10000];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf, NULL);
printf("\n%s\n", tbuf);
return -1;
}
//创建Kernel对象
cl_kernel kernel = clCreateKernel( program, "vecadd", NULL );
//设置Kernel参数
cl_int clnum = BUFSIZE;
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &clbuf1);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &clbuf2);
clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &buffer);
|
注意:在执行kernel时候,我们只设置了global work items数量,没有设置group
size,这时候,系统会使用默认的work group size,通常可能是256之类的。
//执行kernel,Range用1维,work itmes size为BUFSIZE
cl_event ev;
size_t global_work_size = BUFSIZE;
clEnqueueNDRangeKernel( queue,
kernel,
1,
NULL,
&global_work_size,
NULL, 0, NULL, &ev);
status = clFlush( queue );
waitForEventAndRelease(&ev);
//数据拷回host内存
cl_float *ptr;
cl_event mapevt;
ptr = (cl_float *) clEnqueueMapBuffer( queue,
buffer,
CL_TRUE,
CL_MAP_READ,
0,
BUFSIZE * sizeof(cl_float),
0, NULL, NULL, NULL );
status = clFlush( queue );
waitForEventAndRelease(&mapevt);
//结果验证,和cpu计算的结果比较
if(!memcmp(buf, ptr, BUFSIZE))
printf("Verify passed\n");
else printf("verify failed");
if(buf)
free(buf);
if(buf1)
free(buf1);
if(buf2)
free(buf2);
|
程序结束后,这些opencl对象一般会自动释放,但是为了程序完整,养成一个好习惯,这儿我加上了手动释放opencl对象的代码。
//删除OpenCL资源对象
clReleaseMemObject(clbuf1);
clReleaseMemObject(clbuf2);
clReleaseMemObject(buffer);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
return 0;
} |
程序执行后的界面如下:
存储kernel文件为二进制
在教程2中,我们通过函数convertToString,把kernel源文件读到一个string串中,然后用函数clCreateProgramWithSource装入程序对象,再调用函数clBuildProgram编译程序对象。其实我们也可以直接调用二进制kernel文件,这样,当不想把kernel文件给别人看的时候,起到一定的保密作用。在本教程中,我们会把读入的源文件存储一个二进制文件中,并且还会建立一个计时器类,用来记录数组加法在cpu和gpu端分别执行的时间。
首先我们建立工程文件gclTutorial2,在其中增加类gclFile,该类主要用来读取文本kernel文件,或者读写二进制kernel文件。
class gclFile
{
public:
gclFile(void);
~gclFile(void);
//打开opencl kernel源文件(文本模式)
bool open(const char* fileName);
//读写二进制kernel文件
bool writeBinaryToFile(const char* fileName, const char* birary, size_t numBytes);
bool readBinaryFromFile(const char* fileName);
…
}
|
gclFile中三个读写kernel文件的函数代码为:
bool gclFile::writeBinaryToFile(const char* fileName, const char* birary, size_t numBytes)
{
FILE *output = NULL;
output = fopen(fileName, "wb");
if(output == NULL)
return false;
fwrite(birary, sizeof(char), numBytes, output);
fclose(output);
return true;
}
|
现在,在main.cpp中,我们就可以用gclFile类的open函数来读入kernel源文件了:
//kernel文件为add.cl
gclFile kernelFile;
if(!kernelFile.open("add.cl"))
{
printf("Failed to load kernel file \n");
exit(0);
}
const char * source = kernelFile.source().c_str();
size_t sourceSize[] = {strlen(source)};
//创建程序对象
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
|
编译好kernel后,我们可以通过下面的代码,把编译好的kernel存储在一个二进制文件addvec.bin中,在教程4种,我们将会直接装入这个二进制的kernel文件。
//存储编译好的kernel文件
char **binaries = (char **)malloc( sizeof(char *) * 1 ); //只有一个设备
size_t *binarySizes = (size_t*)malloc( sizeof(size_t) * 1 );
status = clGetProgramInfo(program,
CL_PROGRAM_BINARY_SIZES,
sizeof(size_t) * 1,
binarySizes, NULL);
binaries[0] = (char *)malloc( sizeof(char) * binarySizes[0]);
status = clGetProgramInfo(program,
CL_PROGRAM_BINARIES,
sizeof(char *) * 1,
binaries,
NULL);
kernelFile.writeBinaryToFile("vecadd.bin", binaries[0],binarySizes[0]);
|
我们还会建立一个计时器类gclTimer,用来统计时间,这个类主要用QueryPerformanceFrequency得到时钟频率,用QueryPerformanceCounter得到流逝的ticks数,最终得到流逝的时间。函数非常简单,
class gclTimer
{
public:
gclTimer(void);
~gclTimer(void);
private:
double _freq;
double _clocks;
double _start;
public:
void Start(void); // 启动计时器
void Stop(void); //停止计时器
void Reset(void); //复位计时器
double GetElapsedTime(void); //计算流逝的时间
};
|
下面我们在cpu端执行数组加法时,增加计时器的代码:
gclTimer clTimer;
clTimer.Reset();
clTimer.Start();
//cpu计算buf1,buf2的和
for(i = 0; i < BUFSIZE; i++)
buf[i] = buf1[i] + buf2[i];
clTimer.Stop();
printf("cpu costs time:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );
|
同理在gpu执行kernel代码,以及copy gpu结果到cpu时候,增加计时器代码:
//执行kernel,Range用1维,work itmes size为BUFSIZE,
cl_event ev;
size_t global_work_size = BUFSIZE;
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
1,
NULL,
&global_work_size,
NULL, 0, NULL, &ev);
status = clFlush( queue );
waitForEventAndRelease(&ev);
//clWaitForEvents(1, &ev);
clTimer.Stop();
printf("kernal total time:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );
//数据拷回host内存
cl_float *ptr;
clTimer.Reset();
clTimer.Start();
cl_event mapevt;
ptr = (cl_float *) clEnqueueMapBuffer( queue,
buffer,
CL_TRUE,
CL_MAP_READ,
0,
BUFSIZE * sizeof(cl_float),
0, NULL, &mapevt, NULL );
status = clFlush( queue );
waitForEventAndRelease(&mapevt);
//clWaitForEvents(1, &mapevt);
clTimer.Stop();
printf("copy from device to host:%.6f ms \n ", clTimer.GetElapsedTime()*1000 );
|
最终程序执行界面如下,在bufsize为262144时,在我的显卡上gpu还有cpu快呢…,在程序目录,我们可以看到也产生了vecadd.bin文件了。
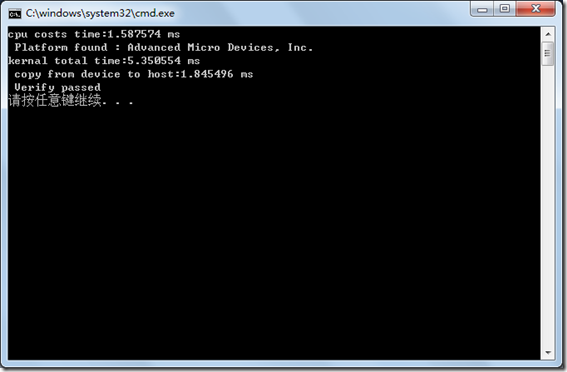
读入二进制kernel文件
本教程中,我们使用上一篇教程中产生的二进制kernel文件vecadd.bin作为输入来创建程序对象,程序代码如下:
//kernel文件为vecadd.bin
gclFile kernelFile;
if(!kernelFile.readBinaryFromFile("vecadd.bin"))
{
printf("Failed to load binary file \n");
exit(0);
}
const char * binary = kernelFile.source().c_str();
size_t binarySize = kernelFile.source().size();
cl_program program = clCreateProgramWithBinary(context,
1,
&device,
(const size_t *)&binarySize,
(const unsigned char**)&binary,
NULL,
NULL);
|
程序执行的界面和教程3中一摸一样…
完整的代码请参考:工程文件gclTutorial3
代码下载:http://files.cnblogs.com/mikewolf2002/gclTutorial.zip
使用二维NDRange workgroup
在本教程中,我们使用二维NDRange来设置workgroup,这样在opencl中,workitme的组织形式是二维的,Kernel中
的代码也要做相应的改变,我们先看一下clEnqueueNDRangeKernel函数的变化。首先我们指定了workgroup
size为localx*localy,通常这个值为64的倍数,但最好不要超过256。
//执行kernel,Range用2维,work itmes size为width*height,
cl_event ev;
size_t globalThreads[] = {width, height};
size_t localx, localy;
if(width/8 > 4)
localx = 16;
else if(width < 8)
localx = width;
else localx = 8;
if(height/8 > 4)
localy = 16;
else if (height < 8)
localy = height;
else localy = 8;
size_t localThreads[] = {localx, localy}; // localx*localy应该是64的倍数
printf("global_work_size =(%d,%d), local_work_size=(%d, %d)\n",width,height,localx,localy);
clTimer.Reset();
clTimer.Start();
clEnqueueNDRangeKernel( queue,
kernel,
2,
NULL,
globalThreads,
localThreads, 0, NULL, &ev);
|
注意:在上面代码中,定义global threads以及local threads数量,都是通过二维数组的方式进行的。
新的Kernel代码如下:
#pragma OPENCL EXTENSION cl_amd_printf : enable
__kernel void vecadd(__global const float* a, __global const float* b, __global float* c)
{
int x = get_global_id(0);
int y = get_global_id(1);
int width = get_global_size(0);
int height = get_global_size(1);
if(x == 1 && y ==1)
printf("%d, %d,%d,%d,%d,%d\n",get_local_size(0),get_local_size(1),get_local_id(0),get_local_id(1),get_group_id(0),get_group_id(1));
c[x + y * width] = a[x + y * width] + b[x + y * width];
}
|
我们在kernel中增加了#pragma OPENCL EXTENSION cl_amd_printf
: enable,以便在kernel中通过printf函数进行debug,这是AMD的一个扩展。printf还可以直接打印出float4这样的向量,比如printf(“%v4f”,
vec)。
另外,在main.cpp中增加一行代码:
//告诉driver dump il和isa文件
_putenv("GPU_DUMP_DEVICE_KERNEL=3"); |
我们可以在程序目录dump出il和isa形式的kernel文件,对于熟悉isa汇编的人,这是一个很好的调试performance的方法。
在最新的app sdk 2.7中,在kernel中使用printf的时候,这个程序会hang在哪儿,以前没这种情况。
程序执行界面。

|






