|
性能优化
1、线程映射
所谓线程映射是指某个线程访问哪一部分数据,其实就是线程id和访问数据之间的对应关系。
合适的线程映射可以充分利用硬件特性,从而提高程序的性能,反之,则会降低performance。
请参考Static Memory Access Pattern Analysis on a Massively
Parallel GPU这篇paper,文中讲述线程如何在算法中充分利用线程映射。这是我在google中搜索到的下载地址:http://www.ece.neu.edu/~bjang/patternAnalysis.pdf
使用不同的线程映射,同一个线程可能访问不同位置的数据。下面是几个线程映射的例子:
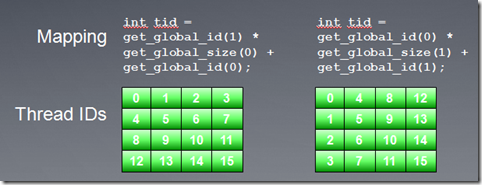
我们考虑一个简单的串行矩阵乘法:这个算法比较适合输出数据降维操作,通过创建N*M个线程,我们移去两层外循环,这样每个线程执行P个加法乘法操作。现在需要我们考虑的问题是,线程索引空间究竟应该是M*N还是N*M?

当我们使用M*N线程索引空间时候,Kernel如下图所示:

而使用N*M线程索引空间时候,Kernel如下图所示:

使用两种映射关系,程序执行结果是一样的。下面是在nv的卡GeForce 285 and 8800 GPUs上的执行结果。可以看到映射2(及N*M线程索引空间),程序的performance更高。

performance差异主要是因为在两种映射方式下,对global memory访问的方式有所不同。在行主序的buffer中,数据都是按行逐个存储,为了保证合并访问,我们应该把一个wave中连续的线程映射到矩阵的列(第二维),这样在A*B=C的情况下,会把矩阵B和C的内存读写实现合并访问,而两种映射方式对A没有影响(A又i3决定顺序)。
完整的源代码请从:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amduniCourseCode4.zip&can=2&q=#makechanges下载,程序中我实现了两种方式的比较。结果确实第二种方式要快一些。
下面我们再看一个矩阵转置的例子,在例子中,通过改变映射方式,提高了global memory访问的效率。
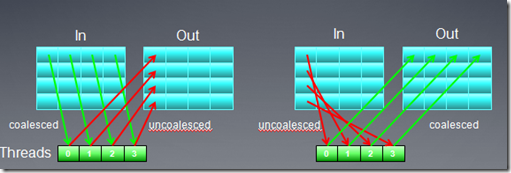
矩阵转置的公式是:Out(x,y) = In(y,x)
从上图可以看出,无论才去那种映射方式,总有一个buffer是非合并访问方式(注:在矩阵转置时,必须要把输入矩阵的某个元素拷贝到临时位置,比如寄存器,然后才能拷贝到输出矩阵)。我们可以改变线程映射方式,用local
memory作为中间元素,从而实现输入,输出矩阵都是global memory合并访问。

下面是AMD 5870显卡上,两种线程映射方式实现的矩阵转置性能比较:

完整代码:http://code.google.com/p/imagefilter-opencl/downloads/detail?name=amduniCourseCode5.zip&can=2&q=#makechanges
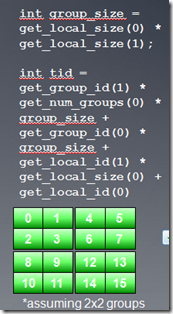
2、Occupancy
前面的教程中,我们提到过Occupancy的概念,它主要用来描述CU中资源的利用率。
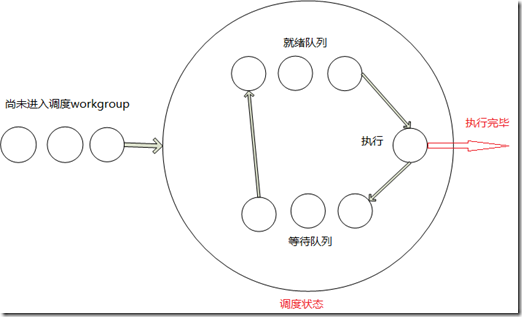
OpenCL中workgroup被映射到硬件的CU中执行,在一个workgroup中的所有线程执行完之后,这个workgroup才算执行结束。对一个特定的cu来说,它的资源(比如寄存器数量,local
memory大小,最大线程数量等)是固定的,这些资源都会限制cu中同时处于调度状态的workgroup数量。如果cu中的资源数量足够的的话,映射到同一个cu的多个workgroup能同时处于调度状态,其中一个workgroup的wave处于执行状态,当处于执行状态的workgroup所有wave因为等待资源而切换到等待状态的话,不同workgroup能够从就绪状态切换到ALU执行,这样隐藏memory访问时延。这有点类似操作系统中进程之间的调度状态。我简单画个图,以供参考:
1.对于一个比较长的kernel,寄存器是主要的资源瓶颈。假设kernel需要的最大寄存器数目为35,则workgroup中的所有线程都会使用35个寄存器,而一个CU(假设为5870)的最大寄存器数目为16384,则cu中最多可有16384/35=468线程,此时,一个workgroup中的线程数目(workitem)不可能超过468,
2.考虑另一个问题,一个cu共16384个寄存器,而workgroup固定为256个线程,则使用的寄存器数量可达到64个。
每个CU的local memory也是有限的,对于AMD HD 5XXX显卡,local memory是32K,NV的显卡local
memory是32-48K(具体看型号)。和使用寄存器的情况相似,如果kernel使用过多的local
memory,则workgroup中的线程数目也会有限制。
GPU硬件还有一个CU内的最大线程数目限制:AMD显卡256,nv显卡512。
NV的显卡对于每个CU内的激活线程有数量限制,每个cu 8个或16个warp,768或者1024个线程。
AMD显卡对每个CU内的wave数量有限制,对于5870,最多496个wave。
这些限制都是因为有限的资源竞争引起的,在nv cuda中,可以通过可视化的方式查看资源的限制情况。
3、向量化
向量化允许一个线程同时执行多个操作。我们可以在kernel代码中,使用向量数据类型,比如float4来获得加速。向量化在AMD的GPU上效果更为明显,这是因为AMD的显卡的stream
core是(x,y,z,w)这样的向量运算单元。
下图是在简单的向量赋值运算中,使用float和float4的性能比较。
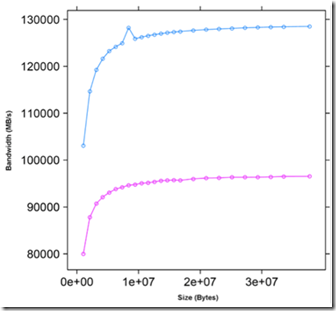
kernel代码为:

本节主要介绍NBody算法的OpenCL性能优化。
1、NBody
NBody系统主要用来通过粒子之间的物理作用力来模拟星系系统。每个粒子表示一个星星,多个粒子之间的相互作用,就呈现出星系的效果。

上图为一个粒子模拟星系的图片:Source: THE GALAXY-CLUSTER-SUPERCLUSTER
CONNECTION,http://www.casca.ca/ecass/issues/1997-DS/West/west-bil.html
由于每个粒子之间都有相互作用的引力,所以这个算法的复杂度是N2的。下面我们主要探讨如何优化算法以及在OpenCL基础上优化算法。
2、NBody算法
假设两个粒子之间通过万有引力相互作用,则任意两个粒子之间的相互作用力F公式如下:

最笨的方法就是计算每个粒子和其它粒子的作用力之和,这个方法通常称作N-Pair的NBody模拟。
粒子之间的万有引力和它们之间的距离成反比,对于一个粒子而言(假设粒子质量都一样),远距离粒子的作用力有时候很小,甚至可以忽略。Barnes
Hut 把3D空间按八叉树进行分割,只有在相邻cell的粒子才直接计算它们之间的引力,远距离cell中的粒子当作一个整体来计算引力。
3、OpenCL优化Nbody
在本节中,我们不考虑算法本身的优化,只是通过OpenCL机制来优化N-Pair的NBody模拟。
最简单的实施方法就是每个例子的作用力相加,代码如下:
for(i=0; i<n; i++)
{
ax = ay = az = 0;
// Loop over all particles "j”
for (j=0; j<n; j++) {
//Calculate Displacement
dx=x[j]-x[i];
dy=y[j]-y[i];
dz=z[j]-z[i];
// small eps is delta added for dx,dy,dz = 0
invr= 1.0/sqrt(dx*dx+dy*dy+dz*dz +eps); |
我们对每个粒子计算作用在它上面的合力,然后求在合力作用下,delta时间内粒子的新位置,并把这个新位置当作下次计算的输入参数。
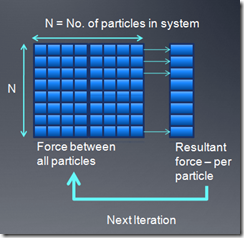
没有优化的OpenCL kernel代码如下:
__global float4* pos ,
__global float4* vel,
int numBodies,
float deltaTime,
float epsSqr,
__local float4* localPos,
__global float4* newPosition,
__global float4* newVelocity)
{
unsigned int tid = get_local_id(0);
unsigned int gid = get_global_id(0);
unsigned int localSize = get_local_size(0);
|
在这种实现中,每次都要从global memory中读取其它粒子的位置,速度,内存访问= N reads*N
threads= N2
我们可以通过local memory进行优化,一个粒子数据读进来以后,可以被p*p个线程共用,p*p即为workgroup的大小,对于每个粒子,我们通过迭代p*p的tile,累积得到最终结果。
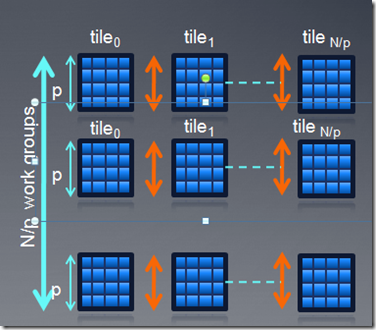
优化后的kernel代码如下:
int numBodies,
float deltaTime,
float epsSqr,
__local float4* localPos,
__global float4* newPosition,
__global float4* newVelocity)
{
unsigned int tid = get_local_id(0);
|
下面是在AMD, NV两个平台上性能测试结果:
AMD GPU = 5870 Stream SDK 2.2
Nvidia GPU = GTX 480 with CUDA 3.1
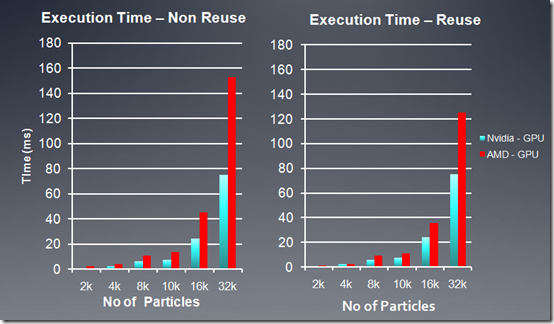
另外,在程序中,也尝试了循环展开,通过展开内循环,从而减少GPU执行分支指令,我的测试中,使用展开四次,得到的FPS比没展开前快了30%。(AMD
5670显卡)。具体实现可以看kernel代码中的__kernel void nbody_sim_unroll函数。在AMD平台上,使用向量化也可以提高10%左右的性能。
1、OpenCL扩展
OpenCL扩展是指device支持某种特性,但这中特性并不是OpenCL标准的一部分。通过扩展,厂商可以给device增加一些新的功能,而不用考虑兼容性问题。现在各个厂商在OpenCL的实现中或多或少的使用了自己的扩展。
扩展的类型分为三种:
1.Khronos OpenCL工作组批准的扩展,这种要经过一致性测试,可能会被增加到新版本的OpenCL规范中。这种扩展都以cl_khr作为扩展名。
2.外部扩展, 以cl_ext为扩展名。这种扩展是由2个或2个以上的厂商发起,并不需要进行一致性测试。比如cl_ext_device_fission扩展。
3.某个厂商自己的扩展,比如AMD的扩展printf
2、使用扩展
OpenCL中,要使用扩展,我们必须打开扩展,在默认状态下,所有的扩展都是禁止的。
#pragma OPENCL EXTENSION extension_name : enable
对于OpenCL,一个函数只有在运行时,才知道其是否可用,所以要确定某个扩展是否可用,是程序员的责任,我们必须在使用前查询它的状态。下面是查询扩展是否可用的代码:
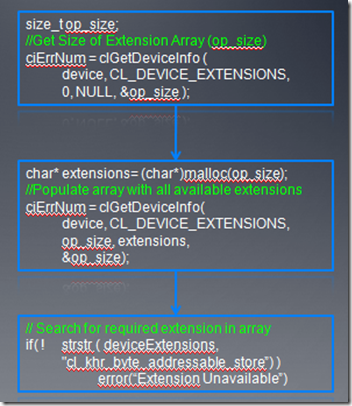
3、一些Khronos批准的扩展
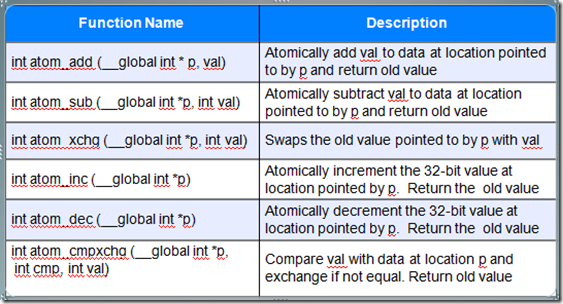
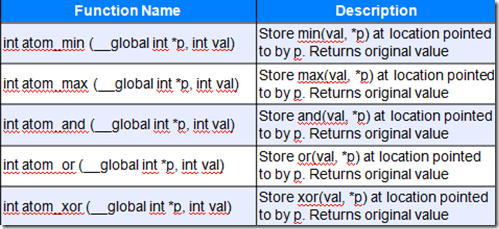
原子操作,它可以保证函数只在一个device上实施原子操作,比如:
―cl_khr_{global | local}_int32_base_atomics
―cl_khr_{global | local}_int32_extended_atomics
―cl_khr_int64_base_atomics
―cl_khr_int64_extended_atomics
注意:原子操作能够保证操作结果正确,但不保证操作的顺序。
双精度和half精度扩展cl_khr_fp64,在一些物理模拟或者科学计算中,需要双精度支持。AMD的64位扩展用cl_amd_fp64,对于cl_khr_fp64是部分支持,NV支持cl_khr_fp64扩展。但half精度扩展cl_khr_fp16,这两家厂商现在都还不支持。
在OpenCL中,Byte addressable store 也是一个扩展,对于sub 32的写,比如char,需要该扩展的支持。例如AMD
直方图的例子中,每个bin用一个byte来存储。
3D Image Write Extensions,在OpenCL标准中,支持2D图像的读写,3D图形的写就需要通过扩展来操作。
The extension cl_KHR_gl_sharing 允许应用程序使用OpenGL buffer,纹理等。
4、AMD扩展
cl_ext_device_fission扩展,通过该扩展把一个设备分成多个子设备,每一个设备都有自己的队列,主要是多核cpu以及Cell
Broadband Engine使用,该扩展由AMD,Apple,Intel以及IBM四家联合提出。
fission设备可能的用途包括:
1.保留一部分设备处理高优先级、低时延的任务。
2.Control for the assignment of work to individual
compute units
3.Subdivide compute devices along some shared hardware
feature like a cache
对于每个子设备,都有自己的queue,比如下面的图中,我们把不同任务发送到两个子设备。值得注意的是:要把设备拆分为子设备,首先我们要了解该设备的架构,然后根据任务及device架构进行拆分。
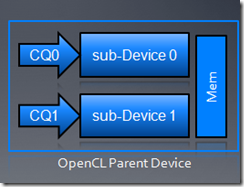
GPU printf 扩展,主要用来debug kernel代码。cl_amd_media_ops扩展,主要用于一些多媒体操作。The
AMD device query extension 主要用于查询和事件处理。
5、NV扩展
1.Compiler Options
2.Interoperability Extensions
3.Device Query Extension
6、Cell Broadband Engine Extensions
cell处理器用的不多,就不详细说了,使用的人可以查询其相关手册。
|






