|
本节主要讲述GPU的memory架构。优化基于GPU device的kernel程序时,我们需要了解很多GPU的memory知识,比如内存合并,bank
conflit(冲突)等等,这样才能针对具体算法做一些优化工作。
1、GPU总线寻址介绍
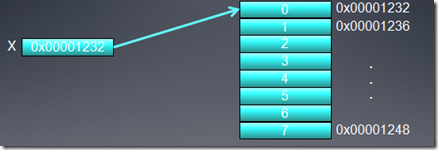
假定X是一个指向整数(32位整数)数组的指针,数组的首地址为0x00001232。一个线程要访问元素X[0],int
tmp = X[0];
假定memory总线宽度为256位(HD5870就是如此,即为32字节),因为基于字节地址的总线要访问memeory,必须和总线宽度对齐,也就是说按必须32字节对齐来访问memory,比如访问0x00000000,0x00000020,0x00000040,…等,所以我们要得到地址0x00001232中的数据,比如访问地址0x00001220,这时,它会同时得到0x00001220到
0x0000123F 的所有数据。因为我们只是取的一个32位整数,所以有用的数据是4个字节,其它28的字节的数据都被浪费了,白白消耗了带宽。
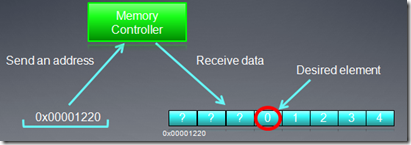
2、合并内存访问
为了利用总线带宽,GPU通常把多个线程的内存访问尽量合并到较少的内存请求命令中去。
假定下面的OpenCL kernel代码:int tmp = X[get_global_id(0)];
数组X的首地址和前面例子一样,也是0x00001232,则前16个线程将访问地址:0x00001232
到 0x00001272。假设每个memory访问请求都单独发送的话,则有16个request,有用的数据只有64字节,浪费掉了448字节(16*28)。
假定多个线程访问32个字节以内的地址,它们的访问可以通过一个memory request完成,这样可以大大提高带宽利用率,在专业术语描述中这样的合并访问称作coalescing。
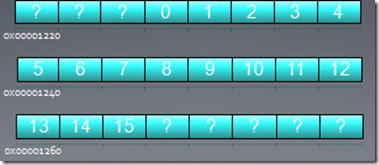
例如上面16个线程访问地址0x00001232 到 0x00001272,我们只需要3次memory
requst。
在HD5870显卡中,一个wave中16个连续线程的内存访问会被合并,称作quarter-wavefront,是重要的硬件调度单位。
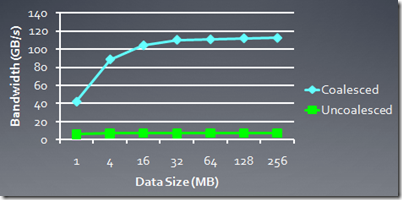
下面的图是HD5870中,使用memory访问合并以及没有使用合并的bandwidth比较:
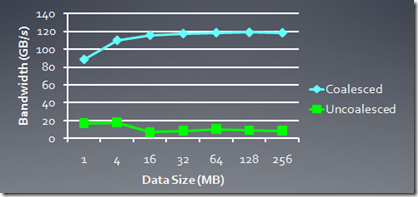
下图是GTX285中的比较:
3、Global memory的bank以及channel访问冲突
我们知道内存由bank,channel组成,bank是实际存储数据的单元,一个mc可以连接多个channel,形成单mc,多channel的连接方式。在物理上,不同bank的数据可以同时访问,相同的bank的数据则必须串行访问,channel也是同样的道理。但由于合并访问的缘故,对于global
memory来说,bank conflit影响要小很多,除非是非合并问,不同线程访问同一个bank。理想情况下,我们应该做到不同的workgroup访问的不同的bank,同一个group内,最好用合并操作。
下面我简单的画一个图,不知道是否准确,仅供参考:
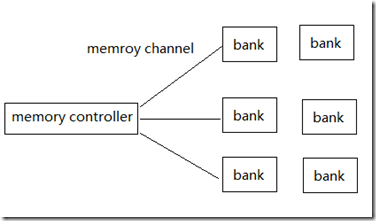

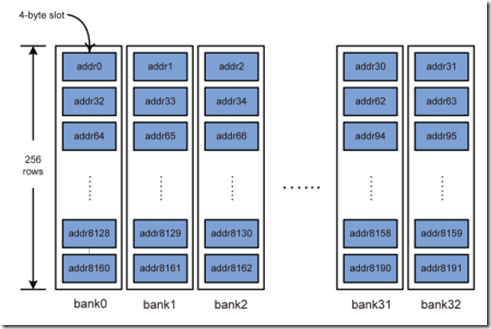
在HD5870中,memory地址的低8位表示一个bank中的数据,接下来的3位表示channel(共8个channel),bank位的多少依赖于显存中bank的多少。
4、local memory的bank conflit
bank访问冲突对local memory操作有更大的影响(相比于global memory),连续的local
memory访问地址,应该映射到不同的bank上,
在AMD显卡中,一个产生bank访问冲突wave将会等待所有的local memory访问完成,硬件不能通过切换到另一个wave来隐藏local
memory访问时延。所以对local memory访问的优化就很重要。HD5870显卡中,每个cu(simd)有32bank,每个bank
1k,按4字节对齐访问。如果没有bank conflit,每个bank能够没有延时的返回一个数据,下面的图就是这种情况。
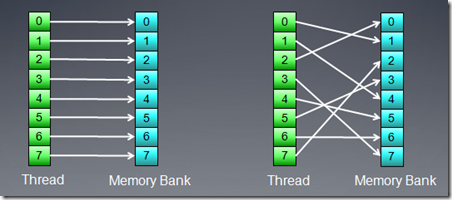
如果多个memory访问对应到一个bank上,则conflits的数量决定时延的大小。下面的访问方式将会有3倍的时延。
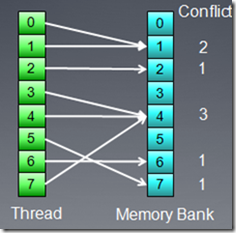
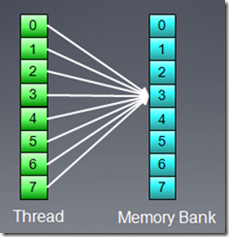
但是,如果所有访问都映射到一个bank上,则系统会广播数据访问,不会产生额外时延。
GPU线程及调度
本节主要讲述OpenCL中的Workgroup如何在硬件设备中被调度执行。同时也会讲一下同一个workgroup中的workitem,如果它们执行的指令发生diverage(就是执行指令不一致)对性能的影响。学习OpenCL并行编程,不仅仅是对OpenCL
Spec本身了解,更重要的是了解OpenCL硬件设备的特性,现阶段来说,主要是了解GPU的的架构特性,这样才能针对硬件特性优化算法。
现在OpenCL的Spec是1.1,随着硬件的发展,相信OpenCL会支持更多的并行计算特性。基于OpenCL的并行计算才刚刚起步,…
1、workgroup到硬件线程
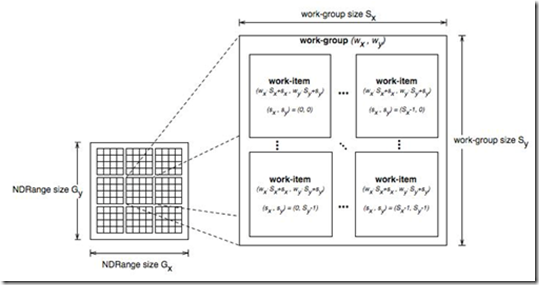
在OpenCL中,Kernel函数被workgroup中的workitem(线程,我可能混用这两个概念)执行。在硬件层次,workgroup被映射到硬件的cu(compute
unit)单元来执行具体计算,而cu一般由更多的SIMT(单指令,线程)pe(processing elements)组成。这些pe执行具体的workitem计算,它们执行同样的指令,但操作的数据不一样,用simd的方式完成最终的计算。
由于硬件的限制,比如cu中pe数量的限制,实际上workgroup中线程并不是同时执行的,而是有一个调度单位,同一个workgroup中的线程,按照调度单位分组,然后一组一组调度硬件上去执行。这个调度单位在nv的硬件上称作warp,在AMD的硬件上称作wavefront,或者简称为wave。

上图显示了workgroup中,线程被划分为不同wave的分组情况。wave中的线程同步执行相同的指令,但每个线程都有自己的register状态,可以执行不同的控制分支。比如一个控制语句
if(A)
{
… //分支A
}
else
{
… //分支B
}
|
假设wave中的64个线程中,奇数线程执行分支A,偶数线程执行分支B,由于wave中的线程必须执行相同的指令,所以这条控制语句被拆分为两次执行[编译阶段进行了分支预测],第一次分支A的奇数线程执行,偶数线程进行空操作,第二次偶数线程执行,奇数线程空操作。硬件系统有一个64位mask寄存器,第一次是它为01…0101,第二次会进行反转操作10…1010,根据mask寄存器的置位情况,来选择执行不同的线程。可见对于分支多的kernel函数,如果不同线程的执行发生diverage的情况太多,会影响程序的性能。
2、AMD wave调度
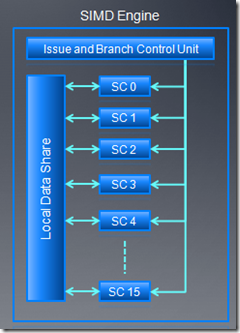
AMD GPU的线程调度单位是wave,每个wave的大小是64。指令发射单元发射5路的VLIW指令,每个stream
core(SC)执行一条VLIW指令,16个stream core在一个时钟周期执行16条VLIW指令。每个时钟周期,1/4wave被完成,整个wave完成需要四个连续的时钟周期。
另外还有以下几点值得我们了解:
?发生RAW hazard情况下,整个wave必须stall 4个时钟周期,这时,如果其它的wave可以利用,ALU会执行其它的wave以便隐藏时延,8个时钟周期后,如果先前等待wave已经准备好了,ALU会继续执行这个wave。
?两个wave能够完全隐藏RAW时延。第一个wave执行时候,第二个wave在调度等待数据,第一个wave执行完时,第二个wave可以立即开始执行。
3、nv warp调度
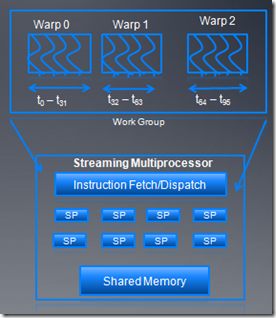
work group以32个线程为单位,分成不同warp,这些warp被SM调度执行。每次warp中一半的线程被发射执行,而且这些线程能够交错执行。可以用的warp数量依赖于每个block的资源情况。除了大小不一样外,wave和warp在硬件特性上很相似。
4、Occupancy开销
在每个cu中,同时激活的wave数量是受限制的,这和每个线程使用register和local memory大小有关,因为对于每个cu,register和local
memory总量是一定的。
我们用术语Occupancy来衡量一个cu中active wave的数量。如果同时激活的wave越多,能更好的隐藏时延,在后面性能优化的章节中,我们还会更具体讨论Occupancy。
5、控制流和分支预测(prediction)
前面我说了if else的分支执行情况,当一个wave中不同线程出现diverage的时候,会通过mask来控制线程的执行路径。这种预测
prediction)的方式基于下面的考虑:
1.分支的代码都比较短
2.这种prediction的方式比条件指令更高效。
3.在编译阶段,编译器能够用predition替换switch或者if
else。
prediction 可以定义为:根据判断条件,条件码被设置为true或者false。
__kernel
void test() {
int tid= get_local_id(0) ;
if( tid %2 == 0)
Do_Some_Work() ;
else
Do_Other_Work() ;
} |
例如上面的代码就是可预测的,
Predicate = True for threads 0,2,4….
Predicate = False for threads 1,3,5….
|
下面在看一个控制流diverage的例子
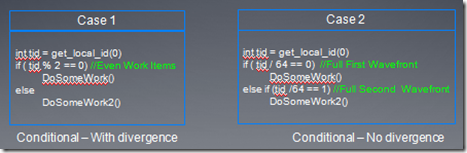
1.在case1中,所有奇数线程执行DoSomeWork2(),所有偶数线程执行DoSomeWorks,但是在每个wave中,if和else代码指令都要被发射。
2.在case2中,第一个wave执行if,其它的wave执行else,这种情况下,每个wave中,if和else代码只被发射一个。
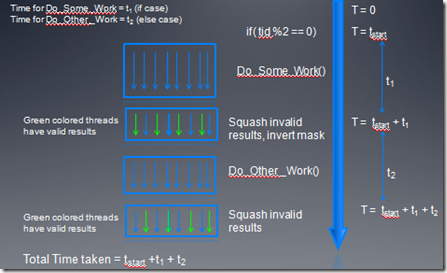
在prediction下,指令执行时间是if,else两个代码快执行时间之和。
6、Warp voting
warp voting是一个warp内的线程之间隐式同步的机制。
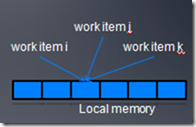
比如一个warp内线程同时写Local meory某个地址,在线程并发执行时候,warp
voting机制可以保证它们的前后顺序正确。更详细的warp voting大家可以参考cuda的资料。
在OpenCL编程中,由于各种硬件设备不同,导致我们必须针对不同的硬件进行优化,这也是OpenCL编程的一个挑战,比如warp和wave数量的不同,使得我们在设计workgroup大小时候,必须针对自己的平台进行优化,如果选择32,对于AMD
GPU,可能一个wave中32线程是空操作,而如果选择64,对nv GPU来说,可能会出现资源竞争的情况加剧,比如register以及local
meomory的分配等等。这儿还不说混合CPU device的情况,OpenCL并行编程的道路还很漫长,期待新的OpenCL架构的出现。
|






