|
Kernel����
Kernel�����ڳ�������е�һ�������������������OpenCL�豸��ִ�С�һ��Kernel�������kernel�����Լ�����ص����������
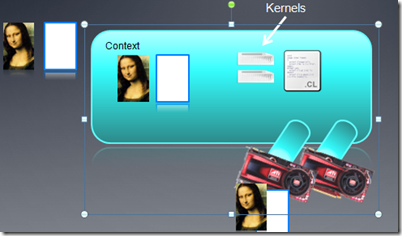
Kernel����ͨ����������Լ�ָ���ĺ������ִ�����ע�⣺���������dz���Դ�����д��ڵĺ�����

����ʱ���룺
������ʱ���������ʹ���kernel��������ʱ�俪���ģ��������Ƚ����ܹ���Ӧ��ͬ��OpenCLӲ��ƽ̨������̬����һ��ֻ��һ�Σ���Kernel�����ڴ������Է������á�
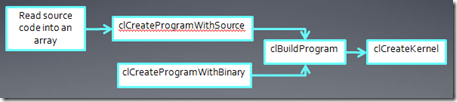
����Kernel������Kernel֮ǰ�����ǻ�ҪΪKernel�������ò��������ǿ�����Kernel���к��������ò����ٴ����С�

arg_indexָ���ò���ΪKernel�����еĵڼ�������(�����һ������Ϊ0���ڶ���Ϊ1,��)���ڴ����͵�����ֵ��������ΪKernel������������2������Kernel���������ӣ�
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&d_iImage);
clSetKernelArg(kernel, 1, sizeof(int), (void*)&a); |
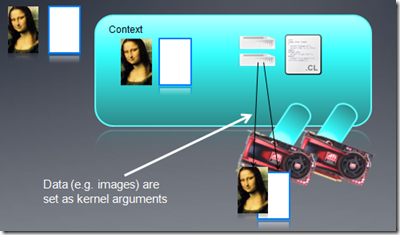
��Kernel����֮ǰ�������ȿ���OpenCL�е��߳̽ṹ��
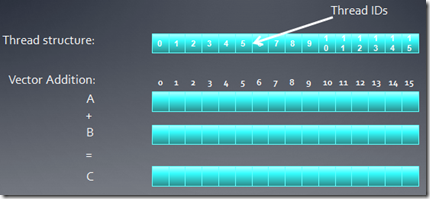
���ģ���г����У�ͨ��ÿ���̴߳���һ�������һ���֣����������ӷ������ǻ�����������ж�Ӧ��Ԫ�ؼ�������������ÿ���߳̿��Դ���һ���ӷ���
�����ҿ�һ��16��Ԫ�ص������ӷ����������뻺��A��B��һ���������C
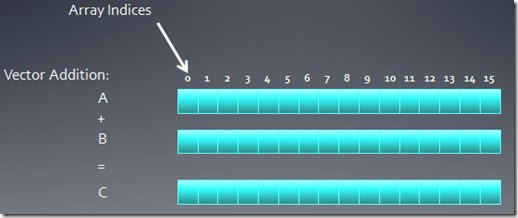
����������£����ǿ��Դ���һά���߳̽ṹȥƥ��������⡣
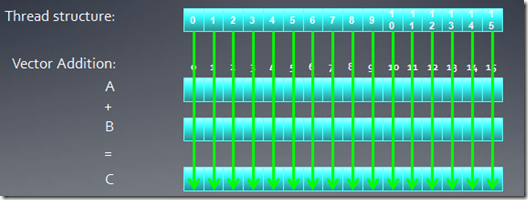
ÿ���̰߳��Լ����߳�id��Ϊ����������ӦԪ�ؼ�������
OpenCL�е��߳̽ṹ�ǿ����ŵģ�Kernel��ÿ������ʵ������WorkItem(Ҳ�����̣߳���WorkItem��֯��һ�����WorkGroup��OpenCL�У�ÿ��Workgroup֮�䶼��������ġ�
ͨ��һ��global id(�������ռ䣬����Ψһ�ģ�����һ��workgroup id��һ��work group�ڵ�local
id���Ҿ��ܱ궨һ��workitem��
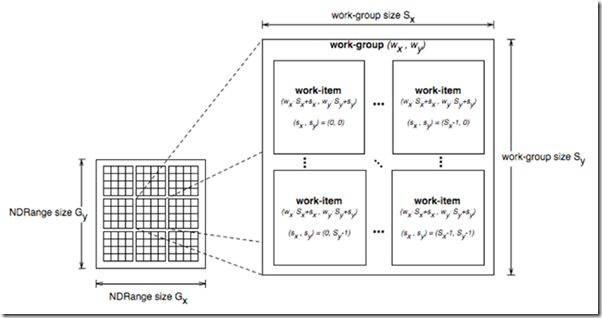
��kernel�����У������ܹ�ͨ��API���õõ�global id�Լ�������Ϣ��
get_global_id(dim)
get_global_size(dim) |
�����������ܵõ�ÿ��ά���ϵ�global id��
get_group_id(dim)
get_num_groups(dim)
get_local_id(dim)
get_local_size(dim��
|
�⼸��������������group id�Լ���group�ڵ�local id��
get_global_id(0) = column, get_global_id(1) = row
get_num_groups(0) * get_local_size(0) == get_global_size(0) |
AMD OpenCL��ѧ�γ�(5)
OpenCL�ڴ�ģ��
OpenCL���ڴ�ģ�Ͷ����˸��ָ����ڴ����ͣ������ڴ�ģ��֮���в㼶��ϵ�������ڴ�֮������ݴ����������ʽ���еģ������host
memory��device memory����global memory��local memory�ȵȡ�
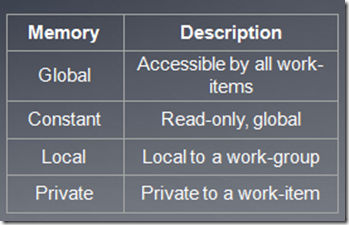
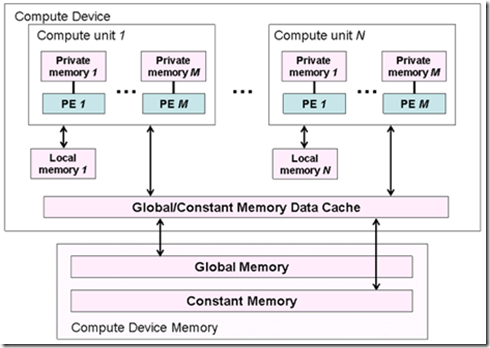
WorkGroup��ӳ�䵽Ӳ����CU��ִ�У���AMD 5xxxϵ���Կ��ϣ�CU����simd��һ��simd����16��pe������˵��stream
core����OpenCL�����ṩ����workgroup֮���һ���ԣ����������Ҫ�ڸ���workgroup֮�乲�����ݻ���ͨ��֮��ģ�Ҫ�Լ�ͨ������ʵ�֡�
Kernel�������
ÿ���̣߳�workitem������һ��kenerl������ʵ�����������ǿ���kernel��д����
__kernel void vecadd(__global const float* A, __global const float* B, __global float* C)
2: {
3: int id = get_global_id(0);
4: C[id] = A[id] + B[id];
5: }
|
ÿ��Kernel������������__kernel��ʼ�����ұ��뷵��void��ÿ�������������������ʹ�õ��ڴ����͡�ͨ��һЩAPI������get_global_id֮��ĵõ��߳�id��
�ڴ�����ַ�ռ��ʶ�������¼��֣�
__global �C memory allocated from global address space
__constant �C a special type of read-only memory
__local �C memory shared by a work-group
__private �C private per work-item memory
__read_only/__write_only �C used for images
|
Kernel��������������ڴ������ôһ����__global,__local����constant��
����Kernel
����Ҫ�����߳������ռ��ά���Լ�workgroup��С�ȡ�
����ͨ������clEnqueueNDRangeKerne��Kernel����һ�������������֤������ִ�У�OpenCL
driver��������У�����Kernel��ִ�С�ע�⣺ÿ���߳�ִ�еĴ��붼����ͬ�ģ���������ִ������ȴ�Dz�ͬ�ġ�
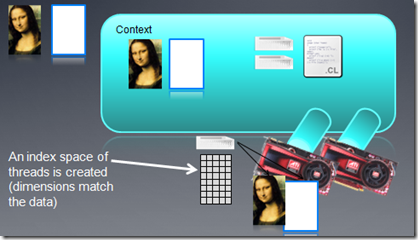
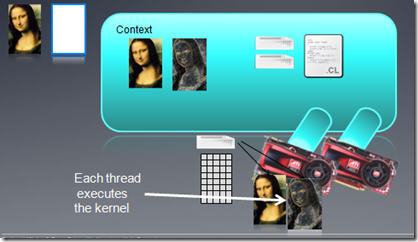

�ú�����Ҫִ�е�Kernel��������ָ������������У�globald��С���߳������ռ䣩����ָ����local��С��work
group������ָ����Ҳ����Ϊ�ա����Ϊ�գ���ϵͳ���Զ�����Ӳ��ѡ����ʵĴ�С��event_wait_list����ѡ��һЩevents��ֻ����Щeventsִ�����kernel�ſ��ܱ�ִ�У�Ҳ����ͨ���¼�������ʵ�ֲ�ͬkernel����֮���ͬ����
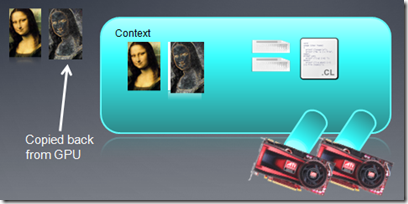
��Kernel����ִ����Ϻ�����Ҫ�����ݴ�device memory�п�����host memory��ȥ��

�ͷ���Դ��
�������OpenCL��Դ����ָ�룬��ʹ�õ�ʱ����Ҫ�ͷŵ�����Ȼ������رյ�ʱ����Щ����Ҳ�ᱻ�Զ��ͷŵ���
�ͷ���Դ�ĺ����ǣ�clRelase{Resource} ������: clReleaseProgram(),
clReleaseMemObject()�ȡ�
������
���OpenCL����ִ��ʧ�ܣ��᷵��һ�������룬һ���Ǹ���ֵ������0���ʾִ�гɹ������ǿ��Ը��ݸô�����֪��ʲô�ط������ˣ���Ҫ�ġ���������cl.h�ж��壬�����Ǽ��������������.
CL_DEVICE_NOT_FOUND -1
CL_DEVICE_NOT_AVAILABLE -2
CL_COMPILER_NOT_AVAILABLE -3
CL_MEM_OBJECT_ALLOCATION_FAILURE -4
�� |
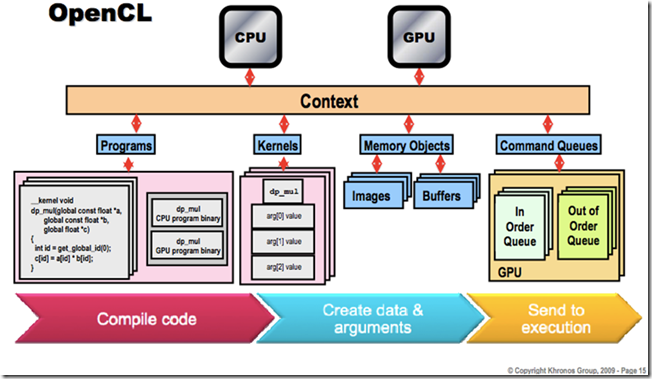
������һ��OpenCL���Ƶ�ʾ��ͼ
����ģ��
���ݲ��У�work item���ڴ����Ԫ��֮����һһӳ���ϵ��workgroup������ʾָ����Ҳ������ʽָ����
�����У�kernel��ִ�ж������߳������ռ䣻������������ʾ���У�����Ѳ�ͬ�����������У����豸ָ����������������͵ȵȡ�
ͬ����workgroup��work item֮���ͬ������������в�ͬ����֮���ͬ����
�����������£�
#include "stdafx.h"
2: #include
3: #include
4: #include
5: #include
6: #include
7: #include
8:
9: using namespace std;
10: #define NWITEMS 262144
11:
12: #pragma comment (lib,"OpenCL.lib")
13:
14: //���ı��ļ�����һ��string��
15: int convertToString(const char *filename, std::string& s)
16: {
17: size_t size;
18: char* str;
19:
20: std::fstream f(filename, (std::fstream::in | std::fstream::binary));
21:
22: if(f.is_open())
23: {
24: size_t fileSize;
25: f.seekg(0, std::fstream::end);
26: size = fileSize = (size_t)f.tellg();
27: f.seekg(0, std::fstream::beg);
28:
29: str = new char[size+1];
30: if(!str)
31: {
32: f.close();
33: return NULL;
34: }
35:
36: f.read(str, fileSize);
37: f.close();
38: str[size] = '\0';
39:
40: s = str;
41: delete[] str;
42: return 0;
43: }
44: printf("Error: Failed to open file %s\n", filename);
45: return 1;
46: }
47:
48: int main(int argc, char* argv[])
49: {
50: //��host�ڴ��д�������������
51: float *buf1 = 0;
52: float *buf2 = 0;
53: float *buf = 0;
54:
55: buf1 =(float *)malloc(NWITEMS * sizeof(float));
56: buf2 =(float *)malloc(NWITEMS * sizeof(float));
57: buf =(float *)malloc(NWITEMS * sizeof(float));
58:
59: //��ʼ��buf1��buf2������
60: int i;
61: srand( (unsigned)time( NULL ) );
62: for(i = 0; i < NWITEMS; i++)
63: buf1[i] = rand()%65535;
64:
65: srand( (unsigned)time( NULL ) +1000);
66: for(i = 0; i < NWITEMS; i++)
67: buf2[i] = rand()%65535;
68:
69: for(i = 0; i < NWITEMS; i++)
70: buf[i] = buf1[i] + buf2[i];
71:
72: cl_uint status;
73: cl_platform_id platform;
74:
75: //����ƽ̨����
76: status = clGetPlatformIDs( 1, &platform, NULL );
77:
78: cl_device_id device;
79:
80: //����GPU�豸
81: clGetDeviceIDs( platform, CL_DEVICE_TYPE_GPU,
82: 1,
83: &device,
84: NULL);
85: //����context
86: cl_context context = clCreateContext( NULL,
87: 1,
88: &device,
89: NULL, NULL, NULL);
90: //�����������
91: cl_command_queue queue = clCreateCommandQueue( context,
92: device,
93: CL_QUEUE_PROFILING_ENABLE, NULL );
94: //��������OpenCL�ڴ������buf1������ͨ����ʽ�����ķ�ʽ
95: //������clbuf1,buf2������ͨ����ʾ�����ķ�ʽ������clbuf2
96: cl_mem clbuf1 = clCreateBuffer(context,
97: CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
98: NWITEMS*sizeof(cl_float),buf1,
99: NULL );
100:
101: cl_mem clbuf2 = clCreateBuffer(context,
102: CL_MEM_READ_ONLY ,
103: NWITEMS*sizeof(cl_float),NULL,
104: NULL );
105:
106: status = clEnqueueWriteBuffer(queue, clbuf2, 1,
107: 0, NWITEMS*sizeof(cl_float), buf2, 0, 0, 0);
108:
109: cl_mem buffer = clCreateBuffer( context,
110: CL_MEM_WRITE_ONLY,
111: NWITEMS * sizeof(cl_float),
112: NULL, NULL );
113:
114: const char * filename = "add.cl";
115: std::string sourceStr;
116: status = convertToString(filename, sourceStr);
117: const char * source = sourceStr.c_str();
118: size_t sourceSize[] = { strlen(source) };
119:
120: //�����������
121: cl_program program = clCreateProgramWithSource(
122: context,
123: 1,
124: &source,
125: sourceSize,
126: NULL);
127: //����������
128: status = clBuildProgram( program, 1, &device, NULL, NULL, NULL );
129: if(status != 0)
130: {
131: printf("clBuild failed:%d\n", status);
132: char tbuf[0x10000];
133: clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf, NULL);
134: printf("\n%s\n", tbuf);
135: return -1;
136: }
137:
138: //����Kernel����
139: cl_kernel kernel = clCreateKernel( program, "vecadd", NULL );
140: //����Kernel����
141: cl_int clnum = NWITEMS;
142: clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*) &clbuf1);
143: clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*) &clbuf2);
144: clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*) &buffer);
145:
146: //ִ��kernel
147: cl_event ev;
148: size_t global_work_size = NWITEMS;
149: clEnqueueNDRangeKernel( queue,
150: kernel,
151: 1,
152: NULL,
153: &global_work_size,
154: NULL, 0, NULL, &ev);
155: clFinish( queue );
156:
157: //���ݿ���host�ڴ�
158: cl_float *ptr;
159: ptr = (cl_float *) clEnqueueMapBuffer( queue,
160: buffer,
161: CL_TRUE,
162: CL_MAP_READ,
163: 0,
164: NWITEMS * sizeof(cl_float),
165: 0, NULL, NULL, NULL );
166: //�����֤����cpu����Ľ���Ƚ�
167: if(!memcmp(buf, ptr, NWITEMS))
168: printf("Verify passed\n");
169: else printf("verify failed");
170:
171: if(buf)
172: free(buf);
173: if(buf1)
174: free(buf1);
175: if(buf2)
176: free(buf2);
177:
178: //ɾ��OpenCL��Դ����
179: clReleaseMemObject(clbuf1);
180: clReleaseMemObject(clbuf2);
181: clReleaseMemObject(buffer);
182: clReleaseProgram(program);
183: clReleaseCommandQueue(queue);
184: clReleaseContext(context);
185: return 0;
186: }
187:
|
|






