| 我无可救药地成为了Scala的超级粉丝。在我使用Scala开发项目以及编写框架后,它就仿佛凝聚成为一个巨大的黑洞,吸引力使我不得不飞向它,以至于开始背离Java。固然Java
8为Java阵营增添了一丝亮色,却是望眼欲穿,千呼万唤始出来。而Scala程序员,却早就在享受lambda、高阶函数、trait、隐式转换等带来的福利了。
Java像是一头史前巨兽,它在OO的方向上几乎走到了极致,硬将它拉入FP阵营,确乎有些强人所难了。而Scala则不,因为它的诞生就是OO与FP的混血儿――完美的基因融合。
“Object-Oriented Meets Functional”,这是Scala语言官方网站上飘扬的旗帜。这也是Scala的野心,当然,也是Martin
Odersky的雄心。
Scala社区的发展
然而,一门语言并不能孤立地存在,必须提供依附的平台,以及围绕它建立的生态圈。不如此,语言则不足以壮大。Ruby很优秀,但如果没有Ruby
On Rails的推动,也很难发展到今天这个地步。Scala同样如此。反过来,当我们在使用一门语言时,也要选择符合这门语言的技术栈,在整个生态圈中找到适合具体场景的框架或工具。
当然,我们在使用Scala进行软件开发时,亦可以寻求庞大的Java社区支持;可是,如果选择调用Java开发的库,就会牺牲掉Scala给我们带来的福利。幸运的是,在如今,多数情况你已不必如此。伴随着Scala语言逐渐形成的Scala社区,已经开始慢慢形成相对完整的Scala技术栈。无论是企业开发、自动化测试或者大数据领域,这些框架或工具已经非常完整地呈现了Scala开发的生态系统。
快速了解Scala技术栈
若要了解Scala技术栈,并快速学习这些框架,一个好的方法是下载typesafe推出的Activator。它提供了相对富足的基于Scala以及Scala主流框架的开发模板,这其中实则还隐含了typesafe为Scala开发提供的最佳实践与指导。下图是Activator模板的截图:

那么,是否有渠道可以整体地获知Scala技术栈到底包括哪些框架或工具,以及它们的特性与使用场景呢?感谢Lauris
Dzilums以及其他在Github的Contributors。在Lauris Dzilums的Github上,他建立了名为awesome-scala的Repository,搜罗了当下主要的基于Scala开发的框架与工具,涉及到的领域包括:

是否有“乱花渐欲迷人眼”的感觉?不是太少,而是太多!那就让我删繁就简,就我的经验介绍一些框架或工具,从持久化、分布式系统、HTTP、Web框架、大数据、测试这六方面入手,作一次蜻蜓点水般的俯瞰。
持久化
归根结底,对数据的持久化主要还是通过JDBC访问数据库。但是,我们需要更好的API接口,能更好地与Scala契合,又或者更自然的ORM。如果希望执行SQL语句来操作数据库,那么运用相对广泛的是框架ScalikeJDBC,它提供了非常简单的API接口,甚至提供了SQL的DSL语法。例如:
val alice: Option[Member] = withSQL {
select.from(Member as m).where.eq(m.name, name)
}.map(rs => Member(rs)).single.apply() |
如果希望使用ORM框架,Squeryl应该是很好的选择。我的同事杨云在项目中使用过该框架,体验不错。该框架目前的版本为0.9.5,已经比较成熟了。Squeryl支持按惯例映射对象与关系表,相当于定义一个POSO(Plain
Old Scala Object),从而减少框架的侵入。若映射违背了惯例,则可以利用框架定义的annotation如@Column定义映射。框架提供了org.squeryl.Table[T]来完成这种映射关系。
因为可以运用Scala的高阶函数、偏函数等特性,使得Squeryl的语法非常自然,例如根据条件对表进行更新:
update(songs)(s =>
where(s.title === "Watermelon Man")
set(s.title := "The Watermelon Man",
s.year := s.year.~ + 1)
) |
分布式系统
我放弃介绍诸如模块化管理以及依赖注入,是因为它们在Scala社区的价值不如Java社区大。例如,我们可以灵活地运用trait结合cake
pattern就可以实现依赖注入的特性。因此,我直接跳过这些内容,来介绍影响更大的支持分布式系统的框架。
Finagle的血统高贵,来自过去的寒门,现在的高门大族Twitter。Twitter是较早使用Scala作为服务端开发的互联网公司,因而积累了非常多的Scala经验,并基于这些经验推出了一些颇有影响力的框架。由于Twitter对可伸缩性、性能、并发的高要求,这些框架也极为关注这些质量属性。Finagle就是其中之一。它是一个扩展的RPC系统,以支持高并发服务器的搭建。我并没有真正在项目中使用过Finagle,大家可以到它的官方网站获得更多消息。
对于分布式的支持,绝对绕不开的框架还是AKKA。它产生的影响力如此之大,甚至使得Scala语言从2.10开始,就放弃了自己的Actor模型,转而将AKKA
Actor收编为2.10版本的语言特性。许多框架在分布式处理方面也选择了使用AKKA,例如Spark、Spray。AKKA的Actor模型参考了Erlang语言,为每个Actor提供了一个专有的Mailbox,并将消息处理的实现细节做了良好的封装,使得并发编程变得更加容易。AKKA很好地统一了本地Actor与远程Actor,提供了几乎一致的API接口。AKKA也能够很好地支持消息的容错,除了提供一套完整的Monitoring机制外,还提供了对Dead
Letter的处理。
AKKA天生支持EDA(Event-Driven Architecture)。当我们针对领域建模时,可以考虑针对事件进行建模。在AKKA中,这些事件模型可以被定义为Scala的case
class,并作为消息传递给Actor。借用Vaughn Vernon在《实现领域驱动设计》中的例子,针对如下的事件流:

我们可以利用Akka简单地实现:
case class AllPhoneNumberListed(phoneNumbers: List[Int])
case class PhoneNumberMatched(phoneNumbers: List[Int])
case class AllPhoneNumberRead(fileName: String)
class PhoneNumbersPublisher(actor: ActorRef)
extends ActorRef {
def receive = {
case ReadPhoneNumbers =>
//list phone numbers
actor ! AllPhoneNumberListed(List(1110, ))
}
}
class PhoneNumberFinder(actor: ActorRef) extends
ActorRef {
def receive = {
case AllPhoneNumberListed(numbers) =>
//match
actor ! PhoneNumberMatched()
}
}
val finder = system.actorOf(Prop(new PhoneNumberFinder(...)))
val publisher = system.actorOf(Prop(new PhoneNumbersPublisher(finder)))
publisher ! ReadPhoneNumbers("callinfo.txt") |
若需要处理的电话号码数据量大,我们可以很容易地将诸如PhoneNumbersPublisher、PhoneNumberFinder等Actors部署为Remote
Actor。此时,仅仅需要更改客户端获得Actor的方式即可。
Twitter实现的Finagle是针对RPC通信,Akka则提供了内部的消息队列(MailBox),而由LinkedIn主持开发的Kafka则提供了支持高吞吐量的分布式消息队列中间件。这个顶着文学家帽子的消息队列,能够支持高效的Publisher-Subscriber模式进行消息处理,并以快速、稳定、可伸缩的特性很快引起了开发者的关注,并在一些框架中被列入候选的消息队列而提供支持,例如,Spark
Streaming就支持Kafka作为流数据的Input Source。
HTTP
严格意义上讲,Spray并非单纯的HTTP框架,它还支持REST、JSON、Caching、Routing、IO等功能。Spray的模块及其之间的关系如下图所示:
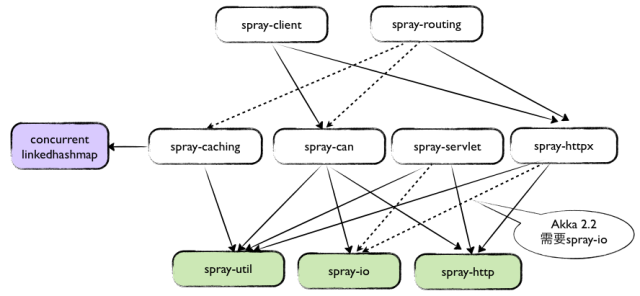
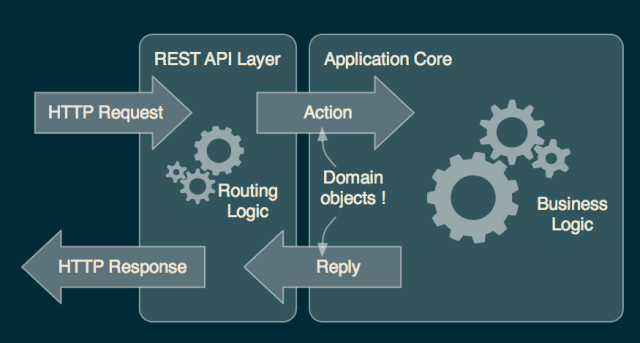
我在项目中主要将Spray作为REST框架来使用,并结合AKKA来处理领域逻辑。Spray处理HTTP请求的架构如下图所示:
Spray提供了一套DSL风格的path语法,能够非常容易地编写支持各种HTTP动词的请求,例如:
trait HttpServiceBase extends Directives with Json4sSupport {
implicit val system: ActorSystem
implicit def json4sFormats: Formats = DefaultFormats
def route: Route
}
trait CustomerService extends HttpServiceBase
{
val route =
path("customer" / "groups")
{
get {
parameters('groupids.?) {
(groupids) =>
complete {
groupids match {
case Some(groupIds) =>
ViewUserGroup.queryUserGroup(groupIds.split(",").toList)
case None => ViewUserGroup.queryUserGroup()
}
}
}
}
} ~
path("customers" / "vip" /
"failureinfo") {
post {
entity(as[FailureVipCustomerRequest]) {
request =>
complete {
VipCustomer.failureInfo(request)
}
}
}
}
} |
我个人认为,在进行Web开发时,完全可以放弃Web框架,直接选择AngularJS结合Spray和AKKA,同样能够很好地满足Web开发需要。
Spray支持REST,且Spray自身提供了服务容器spray-can,因而允许Standalone的部署(当然也支持部署到Jetty和tomcat等应用服务器)。Spray对HTTP请求的内部处理机制实则是基于Akka-IO,通过IO这个Actor发出对HTTP的bind消息。例如:
IO(Http) ! Http.Bind(service, interface = "0.0.0.0", port = 8889) |
我们可以编写不同的Boot对象去绑定不同的主机Host以及端口。这些特性都使得Spray能够很好地支持当下较为流行的Micro
Service架构风格。
Web框架
正如前面所说,当我们选择Spray作为REST框架时,完全可以选择诸如AngularJS或者Backbone之类的JavaScript框架开发Web客户端。客户端能够处理自己的逻辑,然后再以JSON格式发送请求给REST服务端。这时,我们将模型视为资源(Resource),视图完全在客户端。JS的控制器负责控制客户端的界面逻辑,服务端的控制器则负责处理业务逻辑,于是传统的MVC就变化为VC+R+C模式。这里的R指的是Resource,而服务端与客户端则通过JSON格式的Resource进行通信。
若硬要使用专有的Web框架,在Scala技术栈下,最为流行的就是Play Framework,这是一个标准的MVC框架。另外一个相对小众的Web框架是Lift。它与大多数Web框架如RoR、Struts、Django以及Spring
MVC、Play不同,采用的并非MVC模式,而是使用了所谓的View First。它驱动开发者对内容生成与内容展现(Markup)形成“关注点分离”。
Lift将关注点重点放在View上,这是因为在一些Web应用中,可能存在多个页面对同一种Model的Action。倘若采用MVC中的Controller,会使得控制变得非常复杂。Lift提出了一种所谓view-snippet-model(简称为VSM)的模式。

View主要为响应页面请求的HTML内容,分为template views和generated views。Snippet的职责则用于生成动态内容,并在模型发生更改时,对Model和View进行协调。
大数据
大数据框架最耀眼的新星非Spark莫属。与许多专有的大数据处理平台不同,Spark建立在统一抽象的RDD之上,使得它可以以基本一致的方式应对不同的大数据处理场景,包括MapReduce,Streaming,SQL,Machine
Learning以及Graph等。这即Matei Zaharia所谓的“设计一个通用的编程抽象(Unified
Programming Abstraction)。
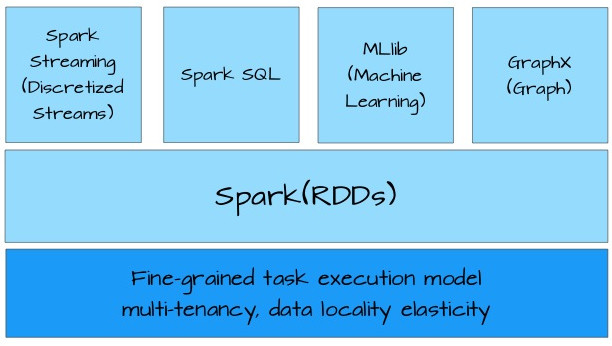
由于Spark具有先进的DAG执行引擎,支持cyclic data flow和内存计算。因此相比较Hadoop而言,性能更优。在内存中它的运行速度是Hadoop
MapReduce的100倍,在磁盘中是10倍。
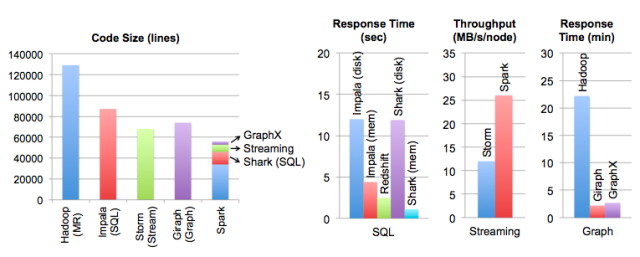
由于使用了Scala语言,通过高效利用Scala的语言特性,使得Spark的总代码量出奇地少,性能却在多数方面都具备一定的优势(只有在Streaming方面,逊色于Storm)。下图是针对Spark
0.9版本的BenchMark:
由于使用了Scala,使得语言的函数式特性得到了最棒的利用。事实上,函数式语言的诸多特性包括不变性、无副作用、组合子等,天生与数据处理匹配。于是,针对WordCount,我们可以如此简易地实现:
file = spark.textFile("hdfs://...")
file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _) |
要是使用Hadoop,就没有这么方便了。幸运的是,Twitter的一个开源框架scalding提供了对Hadoop
MapReduce的抽象与包装。它使得我们可以按照Scala的方式执行MapReduce的Job:
class WordCountJob(args : Args) extends Job(args) {
TextLine( args("input") )
.flatMap('line -> 'word) { line : String => tokenize(line) }
.groupBy('word) { _.size }
.write( Tsv( args("output") ) )
// Split a piece of text into individual words.
def tokenize(text : String) : Array[String] =
{
// Lowercase each word and remove punctuation.
text.toLowerCase.replaceAll("[^a-zA-Z0-9\\s]",
"").split("\\s+")
}
} |
测试
虽然我们可以使用诸如JUnit、TestNG为Scala项目开发编写单元测试,使用Cocumber之类的BDD框架编写验收测试。但在多数情况下,我们更倾向于选择使用ScalaTest或者Specs2。在一些Java开发项目中,我们也开始尝试使用ScalaTest来编写验收测试,乃至于单元测试。
若要我选择ScalaTest或Specs2,我更倾向于ScalaTest,这是因为ScalaTest支持的风格更具备多样性,可以满足各种不同的需求,例如传统的JUnit风格、函数式风格以及Spec方式。我的一篇博客《ScalaTest的测试风格》详细介绍了各自的语法。
一个被广泛使用的测试工具是Gatling,它是基于Scala、AKKA以及Netty开发的性能测试与压力测试工具。我的同事刘冉在InfoQ发表的文章《新一代服务器性能测试工具Gatling》对Gatling进行了详细深入的介绍。
ScalaMeter也是一款很不错的性能测试工具。我们可以像编写ScalaTest测试那样的风格来编写ScalaMeter性能测试用例,并能够快捷地生成性能测试数据。这些功能都非常有助于我们针对代码或软件产品进行BenchMark测试。我们曾经用ScalaMeter来编写针对Scala集合的性能测试,例如比较Vector、ArrayBuffer、ListBuffer以及List等集合的相关操作,以便于我们更好地使用Scala集合。以下代码展示了如何使用ScalaMeter编写性能测试:
import org.scalameter.api._
object RangeBenchmark
extends PerformanceTest.Microbenchmark {
val ranges = for {
size <- Gen.range("size")(300000,
1500000, 300000)
} yield 0 until size
measure method "map" in {
using(ranges) curve("Range") in {
_.map(_ + 1)
}
}
} |
根据场景选择框架或工具
比起Java庞大的社区,以及它提供的浩如烟海般的技术栈,Scala技术栈差不多可以说是沧海一粟。然而,麻雀虽小却五脏俱全,何况Scala以及Scala技术栈仍然走在迈向成熟的道路上。对于Scala程序员而言,因为项目的不同,未必能涉猎所有技术栈,而且针对不同的方面,也有多个选择。在选择这些框架或工具时,应根据实际的场景做出判断。为稳妥起见,最好能运用技术矩阵地方式对多个方案进行设计权衡与决策。
我们也不能固步自封,视Java社区而不顾。毕竟那些Java框架已经经历了千锤百炼,并有许多成功的案例作为佐证。关注Scala技术栈,却又不局限自己的视野,量力而为,选择合适的技术方案,才是设计与开发的正道。 |






