|
1��Web Server �� DB Server ����
С����վ�� B/S ��Ŀ����ͬʱ�����������࣬�п���ͬһ̨�������������� Web Server������ DB Server�����˶��߽Ի�ռ�ô����� CPU���ڴ桢���� I/O������ö��߷ֱ��ò�ͬ�ķ������������ṩ�����Է�ɢѹ������߸��س������������⣬��������ͬһ���Σ�Ӧ���������� Private IP ���з��ʣ�����Ҫ�� Public IP ���������ơ�
�������� Web �ϵ�Ӧ�ó�������ʲô����Ӳ����ͬʱ��������û��� request��ͨ�����Ƚ����� CPU���������ݿ���ԣ�CPU �Ͳ����û�������ģ������ڴ�ʹ��� I/O �õñ� Web Server �ࡣ���һ�㽨�� Web Server ����ͨ�� PC ���ɣ���Ҫ�ú�һ��� CPU���� DB Server �Ͳ��ܲ��ʣ�Ӧ��������ķ���������Ҫ�� RAID 5 �� 6 �Ĵ������� (Ӳ���� RAID������Զ�Ȳ���ϵͳ���������� RAID Ҫ��)������ 4 GB ���ϵ��ڴ档��Ȼ�������ϵͳ�����ݿⶼ�� 64 λ�汾����ã����������� 64 λ�� SQL Server �� 64 λ�� Windows Server�������ڴ涼�����õ� 64 GB������Ҫ�ǵã�̫�ɵ� PC��һЩ�ܱ�Ӳ���� driver ���ܲ�֧�� 64 λ�IJ���ϵͳ��������
������������������ӣ�������Ӷ�̨ Web Server �� DB Server���á���������Ⱥ (cluster)���������ؾ��� (Load balancing) ��Ⱥ�������߿����Լ�Ⱥ High-availability (HA)�������ݿ⼯Ⱥ����ʵ�ָ����ģ�ķֲ�ʽ����
Deployment Plan������滮����
http://msdn.microsoft.com/zh-cn/library/ms978676.aspx
Three-Tiered Distribution�������ֲ���(Ӳ������ͬ�������������ֲ�)��
http://msdn.microsoft.com/zh-cn/library/ms978694.aspx
Three-Layered Services Application���������Ӧ�ó���(�����������ϵķֲ�)��
http://msdn.microsoft.com/zh-cn/library/ms978689.aspx
Tiered Distribution���ּ��ֲ�����
http://msdn.microsoft.com/en-gb/library/ms978701(zh-cn).aspx
Deployment Patterns��
http://msdn.microsoft.com/zh-cn/library/ms998478.aspx
http://msdn.microsoft.com/en-us/library/ms998478.aspx
2�����ؾ��� (Load Balance)
���ؾ��⼼����չ�˶��꣬�кܶ�רҵ�ķ����ṩ�̺Ͳ�Ʒ��ѡ�������ֿɷ�Ϊ���������͡�Ӳ�����Ľ��������
(1) Ӳ����
Ӳ���Ľ���������� Layer 4 Switch (�� 4 �㽻��)���ɽ�ҵ�������䵽���ʵ� AP Server ���д�����֪����Ʒ�� Alteon��F5 �ȡ���ЩӲ����Ʒ��������Ľ������Ҫ��ö࣬����������ֵ��ͨ�����ṩԶ��������������ܣ��ͷ��㡢���ڹ����� UI ���棬��������Ա�������á���˵ Yahoo �й������ӽ� 2000 ̨������ʱ��ֻ����̨ Alteon �㶨�� [1]��
(2) ������
Apache ��һ��������֪�� HTTP Server����˫�� Proxy / Reverse Proxy ���ܣ���ɴ�� HTTP ���ؾ���ܣ�����Ч���㲻���ر�á�����һ�� HAProxy ���Ǵ��������������ؾ���ģ��Ҿ��мĻ��湦�ܡ�
�Բ���ϵͳ���õĸ��ؾ����������Unix �� Sun �� Solaris ��֧�֣�Linux �����г��õ� LVS (Linux Virtual Server)�������� Windows Server 2003 / 2008 ���� NLB (Network LoadBalance)��
LVS ������ ipvsadm ��һ���� IP Ϊ���ĸ��ؾ���������ﵽ������ TCP/IP ��ͨѶЭ�鶼���Խ��и��ؾ��⡣�������� Linux Kernel ��֧�֣����Ч���൱�ã�ռ�õ� CPU ��Դ�൱�ͣ���ȱ���� ipvsadm ����� Layer 4 ���ϵ����� packet ���ݽ��з�����
���� Windows Server �� NLB����ԭ���Dz����ж���̨����������ȫ������һ������Ⱥ�� IP��������ͼ 1 �� Active Load balancer������ͼ 2 �� Virtual Server 1 (Web Server)���Լ� Virtual DB Server�����ո��ؾ���������������� (Active/Active��Active/Standby��...)�����û�������ֻ�ῴ����һ�� IP�����ڱ����ж���̨���������û�������Ҫ֪�� (��ͬ Cluster ��Ⱥ���Ƽ���ĸ���)��
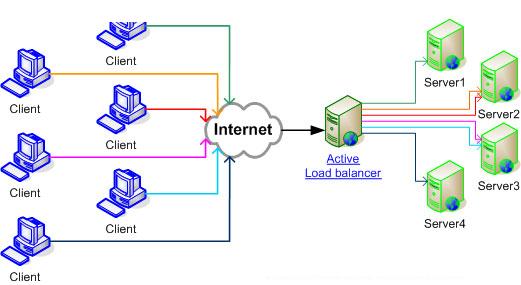
ͼ 1���ֲ�ʽ�û� vs ������ũ�� (Web Server farm)
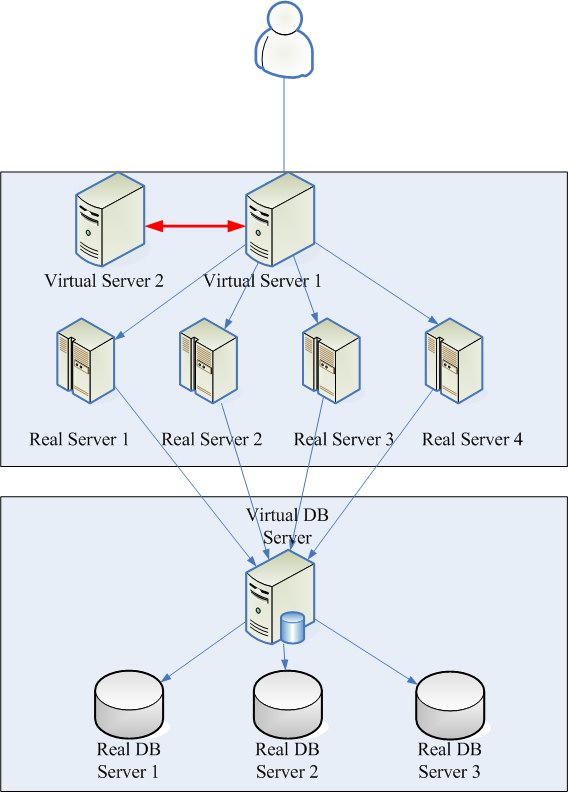
ͼ 2����ɫ��ͷΪ Failover �ܹ� (HA)���书���� Load Balance ��ͬ
��ͼ 2 �У�����̨ Real Server (Web Server)���Լ���̨ Real DB Server���γ� Web �� DB �ķ�������Ⱥ (Cluster)�����ǿ������Ϸ��� Virtual Server 1 �������߱��κε����ݷ��� (�磺.NET ���롢ͼƬ...��)��ֻ��һ�����ܣ����ǽ��û������� request �������µ����·�����̨ Real Server�������������µ��� (director) �ķ�ʽ���������طֲ��� Real Server �ķ�ʽ���ͳ��� Load Balance��
�����ƺ���û��һ�����������Զ����������ġ����ء����Σ�������� CPU ��ʹ�ö��ٰٷֱȣ��Ծ���Ҫ�� request ������һ̨ Real Server������һ�㶼���ǰ������� (Round-robin) �ķ�ʽ�������һЩȨ�ص����ö��ѡ�
�������� Server ������ Load Balance����Ҫִ�� ASP.NET ����Ҫע��һ�����⣬���� Session �Ĵ洢λ��������һ̨ Web Server ���ڴ��ϣ��Ա��ⷢ�����û�������д�ñȽϾã��ȵ����ύʱ���Ѿ��� Windows Server �� NLB ���������л�����һ̨ Web Server �������ˡ���ʱ�Ϳɿ��ǽ� Session State���Ĵ洢�� SQL Server �
�������������� Load Balance ����������أ����������������ģ�����һ�������� 1 + 1 = 2����ͨ������� Availability���༴�������� HA (�߿����Լ�Ⱥ High-availability)���� Failover ��ʽ������ͼ 2 �����Ϸ�����ɫ��ͷ���� Virtual Server 2�����ܹ���� Virtual Server 1 崻������ṩ����ʱ���Զ����Լ��� IP address ȡ�� Virtual Server1����� HA ��ָ�ṩ�������жϵķ������������۵� Load Balance ��ָ�ṩ���ܳ��ܸ߶ȸ��صķ�������ָ�IJ���ͬһ���¡�MIS ��ԱӦ�ӹ�˾��Ӳ����Դ���ɱ���Ԥ�㣬�����Ƿ����߶�Ҫ����
Load-Balanced Cluster������ƽ��Ⱥ������
http://msdn.microsoft.com/zh-cn/library/ms978730.aspx
http://msdn.microsoft.com/en-us/library/ms978730.aspx
Server Clustering��������Ⱥ������
http://msdn.microsoft.com/en-gb/library/ms998414(zh-cn).aspx
Installing Network Load Balancing (NLB) on Windows Server 2008��
http://blogs.msdn.com/clustering/archive/2008/01/08/7024154.aspx
Linux load balancing support & consulting��
http://www.netdigix.com/linux-loadbalancing.php
Load Balancing (WCF, �뱾����ֱ�ӹ�ϵ)��
http://msdn.microsoft.com/zh-cn/library/ms730128.aspx
http://msdn.microsoft.com/en-us/library/ms730128.aspx
3��չʾ���ܵķֲ�
������վ�У�����Ϊ�˽����Ŀ���չ�ԡ�Դ����ά�����㣬����ǰ̨��չʾ (HTML��Script)���ͺ�̨����ҵ�������ݿ���� (.NET/C#��SQL)���гɶ�㡣
���� Martin Fowler �� P of EAA ����f����Layer ��ָ�������ϵķֲ� (logical separation)��Tier ��ָ���������ϵķֲ� (physical separation)�������ǵ� ASP.NET վ̨�����á����⡹�ķֲ� (N-Layer)�����п� UI - BLL - DAL��ͨ�������������ϵ����⣻�������á��������ķֲ� (N-Tier)���༴����ͼ 2 ����ͼ 3������ÿһ̨ AP Server ������ͬ����ҵ�� (���ۡ���桢���������졢��ơ�...)�����Ե�Դ���붼����ڲ�ͬ�����������ϣ��ҿɸ��Զ�����������ʱ��Ҫ���ǵ�ÿһ̨ AP Server �ڱ˴�Э���������Լ����� Web Service (XML �����ܲ���)��ִ�зֲ�ʽ�����ϵ��������⡣
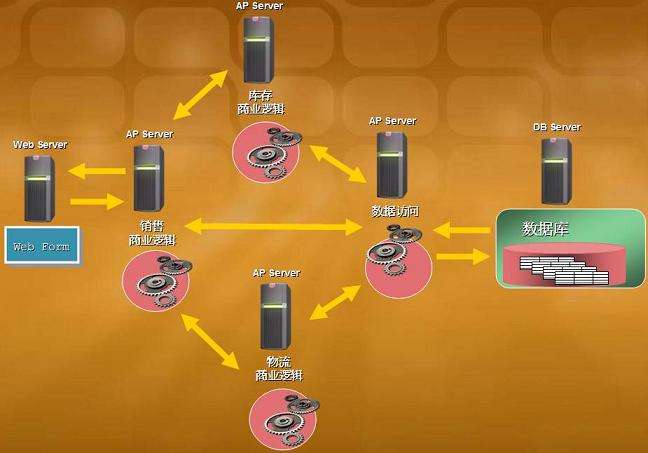
ͼ 3�����������ϵķֲ㣬������ҵ�����ܴ��ڶ�̨����������
̸�����������ֲ��ϵķֲ�ʽ���� (Distributed Transaction)������ Enterprise Services��COM+��WCF��WF �õ�����ϵͳ�ϵ� MS DTC ��Э���������� MS DTC ����ЩӦ�ó�����Դ��ڲ�ͬ�� Process���ڹ�ͨ�ϻ��������л��������л��Ķ�������Ҫ�������������е� AppDomain �Ͳ�ͬ�����ϵ���Դ���ɱ����һ�����������ܡ�
Web Applications: N-Tier vs. N-Layer ��
http://codebetter.com/blogs/david.hayden/archive/2005/07/23/129745.aspx
4�����ݴ�����
�ԱȽϴ�����ݱ�������ʷ���ݱȽ϶�����ݱ����ɸ���һ���������в�֡���ÿ����������dz�����ɲ��ð��մ�ţ�����һ�������ܱ�������¼�����һ������ֵ��Ҳ���Ƚ��Ƚϴ�ı���ֳɶ��������ͨ���������������й����������Ա����ѯ�����ɵ��������� [1]��
��Ҳ���á����������ķ�ʽ�������ݴ洢�ڲ�ͬ���ļ��ϣ�Ȼ���ٲ������������������������� I/O ���£����ƶ�д�����ܡ�
���⣬�ڱ��ĵ�ϵ������30 ���ӿ������ѧ SQL Performance Tuning�����������һ�����ݱ����ֶι��� (��ղ���ļ�¼�����ͬ)��Ӧ��ֱ�и���������ϵ����ݱ���������ͬ���� Primary Key һ�Զ������������磺Northwind �� Orders��Order Details ���ݱ����Ա����ڷ�������ʱ���ԡ������� (clustered index)��ɨ��ʱ����ع�������ݣ���������ʱ��ɻ����������������á�
5��ͼƬ����������
���� Web Server ��˵���û���ͼƬ��������������ϵͳ��Դ�ģ���˿�����վ�Ĺ�ģ����Ŀ�����ԣ����������ͼƬ��������������̨ͼƬ��������
6�������
ͬʱ�����ݿ���С������͡�д���IJ������Ƿdz�ûЧ�ʵ�һ�ַ��ʷ�ʽ���ȽϺõ��������Ǹ��ݶ���д��ѹ�������ֱ�����̨�ṹ��ȫ��ͬ�����ݿ��������������д������̨�����������ݣ���ʱ���Ƹ����𡸶����ķ�������
7��������Ӧ��ͻ������
������վ����Ƽܹ���ʱ���뿼�ǵ��Ժ���������� [1]�����ڻ�����վ��˵������ʱ��ͻ�������Ǿ�ġ�����վ���洢�������ϣ����������ļ���ʽ��ָ��ÿһ���洢�̹��ϴ洢�������ļ��� ID ��Χ����ǰ̨��������Ҫ��ȡһ�����ݵ�ʱ������ͨ��ѯ�����洢�������ϵĽӿڣ���ø��������ڵ��̹�Ŀ¼��ַ��Ȼ����ȥ���̹��ȡʵ�ʵ������ļ��������Ҫ�����̹���ֻҪ�������ļ����ɣ�ǰ̨������ȫ����Ӱ�졣
8������
���� (Cache) �����ݿ��������ڴ��е���ʱ������ʹ�û���ɴ���������ݿ�Ķ�ȡ�������ڴ����ṩ���ݡ��������ǿ����� Web Server��DB Server ֮������һ�㡸���ݻ���㡹�����ڴ��н�����Ƶ���������ĸ��������һ�������������ݿ�Ҳ�ɹ������ݡ����磬�� 100 ���û�����ͬһ�����ϣ���ǰ��Ҫ��ѯ���ݿ� 100 �Σ�������ֻ��Ҫ 1 �Σ�����ɴӻ��������л�ã����Ҷ�ȡ�ٶȡ���ҳ��Ӧ�ٶȻ���������
�ṩ����IJ�Ʒ�кܶ��֣����ɷ�Ϊ��Ӳ�������������Ļ��棬�磺ASP.NET ���õĻ��湦�ܡ����������̵Ļ�������Hibernate �� NHibernate ��Ҳ�� Session �� SessionFactory �Ļ�����ơ�Oracle �� cache group ��������������ǰ�ڡ��� IIS 7��ARR �c Velocity ��������ܵĴ�����վ����ƪ���½��ܵģ����ٷ���һ���ķֲ�ʽ���漼�� Velocity�������� Proxy Server (����������) Ҳ������Ϊ��ҳ�Ļ��棺
�ͻ���<---->����������<---->Ŀ�ķ�����
�� .NET ������У����ṩ CacheDependency �� AggregateCacheDependency �������࣬�������� ASP.NET �л���Ķ��� (�磺DataSet)����һ���������ļ� (�磺XML �ļ�) �����ݿ��еı���ȥ����һ�ֹ�������������һ�� XML �ļ����Ļ��Ƴ�ʱ����������� DataSet Ҳ��һ�����ڴ����Ƴ�����Ȼ��Ҳ�������������趨��ʱ���Զ��Ƴ���
ASP.NET 2.0 �Ժ�Ļ��棬���ĸı����� CacheDependency ���Ѿ��������¸�д��������Ҳ�����Զ�����ȥ�̳������ٸ�д���Դ�����¹��ܣ�
- �� Active Directory �е������û���ʧЧ (���汻�Զ��Ƴ�)
- �� MSMQ �� MQSeries �е������û���ʧЧ
- �� Web Service �е������û���ʧЧ
- �������� Oracle �� CacheDependency
- ����
���⣬SQL Server �л���һ�� SqlCacheDependency (����������)���ɼ������ݱ��е������Ƿ������ı䣬�༴�����û��ڻ����ڼ�鵽�������Ǿɵģ��ﵽ������ݲ��仯���û���һֱ�ӻ�����ȡ�����ݣ�һ�������б仯�����Զ����»����е����ݡ����� SqlCacheDependency �ķ�ʽ��ֻҪ�� aspnet_regsql.exe ������ߣ����������������ͻ��� SQL Server �в���һ���µ� AspNet_SqlCacheTablesForChangeNotification ��������ͼ 4 ��ʾ�����ű��ĵ�ÿһ����¼����������Ҫ����������һ���������Ҳ�� changeId �ֶΣ���ֵΪ��ϵͳ�жϣ��û��� ASP.NET �е�����Ӧ���ڴ��еĻ������ṩ���ֻ�Ҫ�����ݿ���������ѯ��
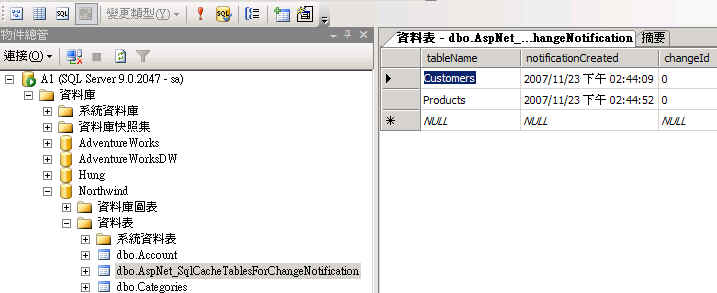
ͼ 4������ SqlCacheDependency ���Զ��������������ı�
������̸�������ڡ���վ����Խ��Խ����ô�죿����ƪ���£�Ҳ�������������ݣ�
(4) �������������
�ó��������棬�� ASP.NET �� 1.x ʱ���������ڽ��� Cache (����) ���ƣ�����һЩ�������ĸ���������Framework��
(5) ��Ӳ������ȡ�塢��Ǯ��װ AP Server
������ԭ������ҳ�������������ݿ�������ļܹ��У�����һ��Ӧ�ó������������Ϊ��ҳ������ cache ���ݵ���Դ��
�İ�֮�������վ����Ѱ�ٶ��������࣬��ǰÿ�յ�ͳ�������У������ٶȳ��� 3 ������ݳ��� 50 ��ʣ����İ��ÿ���ڳ��� 3 ��IJ�ѯ���� 10 �ʡ�
(6) ��Ӳ�������� (cache)
ȫʢʱ�ڣ��������� blog ������ÿ��� 80 ��Ρ����������ʵ���ߣ��Գ��������˵��С��һ�����������ǰ���ӹ���ʦ��֪ʶ����Ҳ��˿��ܳ���д�ò��ã�ƵƵ�����������̷��ž��棬Ҫ�������վϵͳ���ܡ�����Ҿ������� cache system��cache system ����ϵͳ���ߺ����ݿ��д����ÿ�� 80 ��ν��͵�ÿ�� 16 ��Ρ�
�ظ���
Peter.z.lu
�м�������кܶ�ѡ��
Ncache, Coherence, Velocity, MemCache...
���⣬�������� Memcached��Cacheman ���ֲַ�ʽ�����ϵͳ��ǰ�߿ɻ��� Linux �� Win32 ƽ̨ʹ�ã�ͨ�����ڴ���ά��һ����� hash �����ɴ洢ͼ����Ƶ���ļ������ݿ�����Ľ��������֧�ֶ���������ɽ�� ASP.NET ���õĻ�����ƽ������ڵ����ķ����������߾�˵�������� Popfly ��Ŀ���Ա Sriram Krishnan ����Ʒ������Ҳ�п��ܳ�Ϊ������ʽ��Ʒ��
9���ֲ�ʽϵͳ���ݽṹ - �� MySpace Ϊ��
������������һƪ�ܻ������¡��� MySpace ���ݿ⿴�ֲ�ʽϵͳ���ݽṹ��Ǩ���������ᵽ MySpace ������͵�������վ��ʹ����ƽ̨�� Windows Server��SQL Server��ASP.NET ���������ÿ���µ��û��������ߴ� 500 �ڣ������� 2 �ڸ����ϵ��û�ע�ᡣ���½���¼���ĵ��ص㣺
��һ���ܹ� - ���ø���� Web ������
�� MySpace �� 50 ���ע���û���ʱ����վֻ������̨ Dell ˫ CPU��4 GB �ڴ�� Web Server (��ɢ�û�������)��һ̨ DB Server (�������ݶ��洢����)��
�ڶ����ܹ� - �������ݿ������
��������̨���ݿ�������ϣ�һ̨���ڸ������� (�������Ƶ���������)������̨���ڶ�ȡ���ݣ���Ϊ����ҳ���˶࣬����Ҫд������١��ȵ��û����ͷ����������ˣ����ټ�װӲ�̡�
�������ݿ�������� I/O ����ƿ�����Ͱ��մ�ֱ�ָ�ģʽ��ƣ�����վ��IJ�ͬ���ܣ��磺��¼���û����ϺͲ��ͣ����Ƶ���ͬ�����ݿ�������У��Էֵ�����ѹ������Ҫ�����¹��ܣ�����Ͷ���µ����ݿ��������
��ע���û��ﵽ 200 ����Ӵ洢�豸�����ݿ������ֱ�ӽ����ķ�ʽ���л��� SAN (�洢��������)��һ�ָߴ�����ר����Ƶ�����ϵͳ���ɽ��������̴洢�豸������һ��MySpace �����ݿ����ӵ� SAN�����ǵ��û����ӵ� 300 ���˺�ֱ�ָ����Ҳ�������ά����ȥ�������ܹ�ʦ���������������� 34 �� CPU �İ����������ȴҲ�����ɡ�
�������ܹ� - ת���ֲ�ʽ����ܹ�
�ܹ�ʦ�� MySpace �Ƶ��ֲ�ʽ����ܹ������������Ϸֲ����ڶ������������������ϵ�ͬ�ڵ�̨�����������ݿ���˵���Ͳ��������ȥ������Ӧ�ò�֣����Բ�ͬ���ݿ�ֱ�֧�֣������뽫����վ�㿴��һ��Ӧ�á���Σ����ٰ�վ�㹦�ܺ�Ӧ�÷ָ����ݿ⣬MySpace ��ʼ�������û���ÿ 100 ��һ��ָȻ�����ȫ�����ݷֱ��������� SQL Server ʵ�������� MySpace ��ÿ̨���ݿ������ʵ���������� SQL Server ʵ����Ҳ����˵ÿ̨������������Լ 200 ���û���
���Ĵ��ܹ� - �������ݻ����
���û��ﵽ 900-1000 ��ʱ��MySpace�ٴ������洢ƿ�����⣬�����������µ� SAN ��Ʒ����վ��Ŀǰ��Ҫ���Ѿ���Խ SAN �� I/O ���̴洢ϵͳ�������д���ݵļ����ٶȡ�
���û��ﵽ 1700 ��ʱ��������һ�����ݻ���㣬��λ�� Web �����������ݿ������֮�䣬��Ψһְ�������ڴ��н�����Ƶ���������ݶ���ĸ�������ǰÿһλ�û���ѯһ����Ϣ��������һ�����ݿ⣻���ڵ���һ���û��������ݿ�����ͻᱣ��һ���������������û��ٷ���ʱ�Ͳ���Ҫ���������ݿ��ˣ����һ�������������ݿ�Ҳ���Թ������ݡ�
������ܹ� - ת��֧�� 64 λ�������IJ���ϵͳ�����ݿ�����
���û����ﵽ 2600 ��ʱ��ת���˻����� Beta �桢��֧�� 64 λ�������� SQL Server 2005���������� 64 λ�� SQL Server 2005 �� Windows Server 2003 ��MySpace ÿ̨�������䱸�� 32 GB �ڴ棬�������������� 64 GB��
�� MySpace ���ݿ⿴�ֲ�ʽϵͳ���ݽṹ��Ǩ��
http://www.cnblogs.com/cxccbv/archive/2009/07/15/1524387.html
http://www.javaeye.com/topic/152766
http://smb.pconline.com.cn/database/0808/1403100.html
http://idai.blogbus.com/logs/14736411.html
| 

