��飺
��־������������ҵ���ܵĻ�������������������־��Ϣ��Ŀʹ�ô��ģ���ݴ���ƽ̨�ij��ֳ�Ϊ��Ȼ��MapReduce
�������ݵ���Ч��Ϊ��־�����ṩ�˿ɿ��ĺ�ܡ����Ľ��ԶԷ�����ҳ�û�����־���з����������ھ���û���Ȥ����һ��������Ϊ�����꾡����
MapReduce ģ�͵Ķ�Ӧʵ�֣����� MapReduce ����ж�����������Ĵ������ɣ��������ѧϰ�㷨�������㷨���������ơ����ӻ��Ƶȡ�
���Ľ��ԶԷ�����ҳ�û�����־���з����������ھ���û���Ȥ����һ��������Ϊ������ϸ����
MapReduce ģ�͵Ķ�Ӧʵ�֣������� MapReduce ����ж�����������Ĵ������ɣ��������ѧϰ�㷨�������㷨���������ơ����ӻ��Ƶȡ����·�������չ�������Ƚ���
MapReduce ���ģ�ͣ�����ԭ�����������������Լ�����������н��ܣ���������������־����������
- �û���Ȥ���ھ�Ĵ������̣����Դ������̵ļ���ģ��ֱ������ MapReduce ��ʵ�֡����ĵ�Ŀ������ͨ��
MapReduce ����־��������ľ���ʵ�֣�ʹ���߶� MapReduce ��ʵ������Ĵ����н�Ϊ�������ʶ��
MapReduce ���ģ�ͼ��
������Ϣ���Ľ�һ������ڸ�����������š���ͨ�����ڡ����ۡ����졢ҽҩ�ȣ��������������ֿ����������ơ���θ�Ч��������ش洢�������������Լ�������Щ���ģ���ݣ���Ϊһ���ؼ������⡣
Ϊ��Ӧ�Դ��ģ���ݴ��������⣬MapReduce ���ģ��Ӧ�˶�����Google
�������һģ�ͣ��������õ������ԺͿ���չ�ԣ��õ��˹�ҵ���ѧ����Ĺ㷺֧�֡�Hadoop��MapReduce
�Ŀ�Դʵ�֣��Ѿ��� Yahoo!, Facebook, IBM, �ٶ� , �й��ƶ��ȶ�ҵ�λ��ʹ�á�
MapReduce ���ģ��
MapReduce �Ժ�����ʽ�ṩ�� Map �� Reduce �����зֲ�ʽ���㡣Map
��Զ����Ҳ������У��Դ洢ϵͳ�е��ļ����д�������������ֵ��key/value���ԡ�Reduce �� Map
�������Ϊ���룬��ͬ key �ļ�¼��۵�ͬһ reduce��reduce �������¼���в������������µ����ݼ�������
Reduce ��������������ս������ʽ���������£�
Map�� (k1,v1) -> list(k2,v2)
Reduce��(k2,list(v2)) ->list(v3)
MapReduce ������Ĵ���������ͼ 1 ��ʾ����Ҫ��Ϊ������
- �û��ύ MapReduce ���������ؽڵ㣬���ؽڵ㽫�����ļ����ֳ����ɷ�Ƭ��split�������ؽڵ�
Master �����ڵ� worker ������Ӧ���̣�
- ���ؽڵ���ݹ����ڵ�ʵ����������� map ����ķ��䣻
- �����䵽 map ����Ľڵ��ȡ�ļ���һ����Ƭ�����н��� map ��������������ڱ��ء�����ֳ�
R ����Ƭ���д洢��R ��Ӧ���� Reduce ��Ŀ��
- Map �ڵ㽫�洢�ļ�����Ϣ���ݸ� Master ���ؽڵ㣬Master ָ�� Reduce �������нڵ㣬����֪���ݻ�ȡ�ڵ���Ϣ��
- Reduce �ڵ���� Master ���ݵ���Ϣȥ map �ڵ�Զ�̶�ȡ���ݡ���Ϊ reduce
������������д�����key ��ͬ�ļ�¼��һͬ��������
- reduce �ڵ���ʽ����ǰ�������еļ�¼���� key ����
- Reduce ���������д�뵽�ֲ�ʽ�ļ�ϵͳ�С�
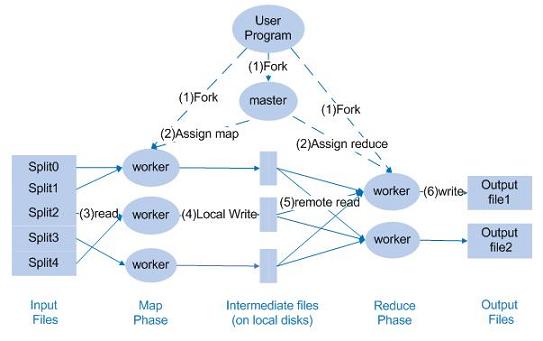
ͼ 1 �� MapReduce ��������ͼ
MapReduce �������
���� MapReduce ���ģ���Ƕ����밴��˳�δ��������������ڶ��������ݽ��д������������õĿ���չ�ԣ�MapReduce
���������ڶԴ��ģ���ݵĴ�����
���ǣ���������ֻ����Ҫ�Ӵ���������ѡȡij�����ر�IJ�����MapReduce
����ھ�������������ϵͳ���ԣ����پ������ơ���Ϊ����Ҫ��ÿ�����ݽ���ƥ�䣬��������������ƥ���������ȡ�������������������ϵͳ��������Ҫ�������е����ݡ�
���⣬����ÿ�β�����Ҫ�����������ݣ�MapReduce ������������Ҫʵʱ��Ӧ��ϵͳ���෴�أ��������������Ԥ��������������ҳ���桢������ϴ���Լ���־������ʵʱ��Ҫ�ߵĺ�̨����������MapReduce
���ģ��������ʤ�εġ�
��־����Ӧ��
���������ߴ���Ӧ��ϵͳ�У���־�IJ����ͼ�¼�Ƿdz���Ҫ�����顣��־�������ǽ��������ھ�����ƽ���һ�������Ļ��������磬�ڹ�����վ������û�������ҳ����Ϣ�������ھ���û�����Ȥ�㣬����������Ʒ�Ƽ����ֱ��磬��Ӧ��ϵͳ�У�ͨ�������û���ϵͳ������ʹ������������ھ����ϵͳ�е��ȵ㲿����������ȡ��Ӧ�Ĵ�ʩ��ǿ���������͵أ�����һ��ҽ������ϵͳ������ҽ���Բ�ͬ���鿪��������־��¼�������ھ��ij�ֲ����ҩƷ�Ķ�Ӧ��ϵ����������һ��ר���Ƽ�ϵͳ�ȡ�
���Ż�������ҵ��׳���Ӧ��ϵͳ��ģ�����䣬��¼��Ӧ��Ϣ����־������Ҳ�ڼ������䡣��ͳ�ĵ�������������Ѿ�����������־����������Ϊ�ˣ����ģ���ݴ���ƽ̨��Ϊ��־����������ƽ̨����һ���棬��־������û�кܸߵ�ʵʱ��Ҫ��MapReduce
���ģ������������ǿ���������ݹ�ģ��Ϊ��־������������
�������沿�ֻ����û�������ҳ��־Ϊ��������������� MapReduce
��������־�������ھ����Ӧ��Ϣ��
�û�������ҳ��Ϊ��ģ
һ����� , �û�ÿ������ҳʱ , ϵͳ��־�л�洢һ����¼ : �û�
+ url + ����ʱ�䡣�û����ʵ�һϵ����ҳ��¼�����ƶ��û���Ȥ��Ļ����������û� + urlSet��
��θ����û����ʵ�ϵ�� URL ��Ϣ���Ʋ��û���Ȥ�㣿һ����ԣ������¼������蹹�ɣ�
��һ��ҳ��Ϣ�ھ��� URL �õ���ҳ������Ϣ��������ҳ���ݽ��д������õ���������ҳ�ļ����ؼ��ʣ�һ��Ҫ��������ѧϰ�㷨����ר�Ҿ�������ȡ���м�ֵ�Ĵʡ�
�û����ʹؼ�����Ϣ���ܡ������û����ʵĸ��� URL �е����йؼ�����Ϣ�������õ��û���ע�Ĺؼ����б���ÿ���ؼ��ʾ��в�ͬȨ�أ��Ӹô���
URL �г��ֵĴ���������
�ؼ�����չ����Լ�����û���ע�ؼ����б�����һ������չ���Լ�������õ����Ӿ����ձ�����Ĵ���Ϣ���Ը��õر����û�����Ȥ�㡣

ͼ 2 ���û���Ȥ�ھ�����ͼ
��һ��ҳ��Ϣ�ھ�
�� URL �õ�����ҳ���м�ֵ�Ĵ���Ϣ������Ҫ�� URL ����������ȡ���Եõ����Ӧ����ҳ���ݡ�����ҳ����ȡ�ؼ��ʣ�����Ҫһ�����㷨֧�֡���һƪ��ҳ�У���ͬ����Ϊ�ڲ�ͬλ�û����Բ�ͬ�ĸ�ʽ���֣���ӦӰ��̶�Ҳ��ͬ�����磬����ҳ�ı��������ҳ����ÿһ��Ȼ�ζ����߶�β�Ĵʿ��ܸ�Ϊ��Ҫ������ҳ�����ض���ʽ������Ӵֻ�������ϴ���߱����ɫ�Ĵʿ��ܸ�Ϊ��Ҫ��
������һ���ʣ���α������Ҫ�Ի��߶���ҳ�ļ�ֵ�����Խ�ÿ��������������ʽ������������������ÿһά��
d ��ʾ��ͬ�ĺ����������� TF���ڸ���ҳ�г��ֵĴ�������DF����������ҳ�г��ֵĴ��������Ƿ��ڱ����г��֡��Ƿ��ڶ���
/ ��β���֡��Ƿ��ھ��� / ��β���֡���ɫ�������������ʡ��ʵĴ��������� / ���� / ���ݴ� / ���ʣ��ȵȡ�����
w = (v1, v2, v3, v4, �� )��ÿ��ά�� v �Դ�����ҳ�ؼ��ʵľ����̶Ȳ�ͬ�����Ӱ�����ӿ���ͨ������ѧϰ�㷨ѵ�����á�����������ָ���ؼ��ʵ���ҳ������ѵ�����õ�����Ȩ�ء�
�õ�����Ȩ�غ�����ҳ�е�ÿ���ʣ�����ͨ�� w = sum(vi*fi)
�ķ�ʽ���õ�����Ϊ�ؼ��ʵı���������ҳ��ѡȡ�ܴ��������ݵļ����ʣ�Ӧ�����м����Ȩ�صĴʰ�Ȩ�شӴ�С��������ѡȡǰ�������ߴ���ij����ֵ�Ĵʼ��ɡ�
���˼·��ͼ 3 ��ʾ��
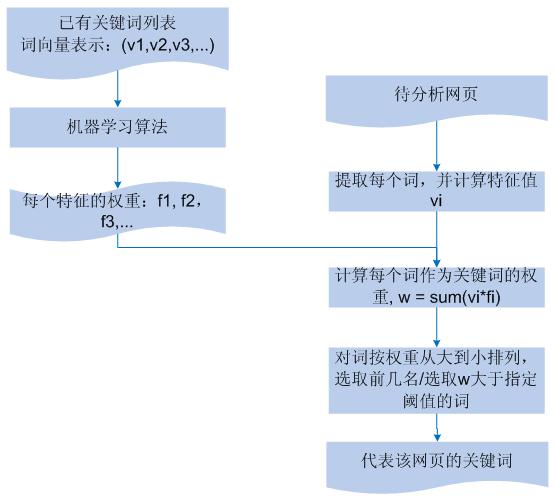
ͼ 3 ����ҳ�ؼ����ھ�����ͼ
�û����ʹؼ��ʻ���
�õ�ÿ����ҳ�Ĵ����ؼ��ʺ����û����ʵĹؼ��ʣ�����ͨ�������û����ʵ�������ҳ�Ĺؼ��ʵõ������ԣ��û�����ÿ���ʵĴ���������Ϊ�ô�Ϊ�û���ע�ʵ�Ȩ�ء���Ϊ���滹Ҫ���н�һ���Ĺؼ�����չ
/ ��Լ��Ϊ��ֹ��ֵ�������������Զ�Ȩ�ؽ��й�һ������Ȼ��Ҳ�����ټ����������ԣ��Դʵ�Ȩ�ؽ��н�һ������������ͨ�����������ߴʵĹ���Ƶ�ʵȷ�ʽ�������ʣ��������û���Ȥ�������õĴʣ����硰���ס������Ա����ȣ�λ�ú�����˴��������չ����
�ؼ�����չ����Լ
�ؼ�����չ
��һ���õ��Ľ�����û�����־����¼��ʱ���ڷ��ʵĹؼ��ʻ��ܣ��������֮��������������ġ����磬�û������ˡ���������ʣ���ʵ���ϸ��û�Ҳ���п��ܶԡ����ǡ�����ʸ���Ȥ����Ϊ�����͡����ǡ����ʴ���һ������������ͨ���ؼ�����չ���ƶϳ��û��ԡ����ǡ�һ��Ҳ����Ȥ��
��εõ�������֮�����ضȣ�һ����ԣ�ͬʱ��һ����ҳԪ��Ϣ��meta����
keyword ����Ĵʺܴ�̶�����صġ���ˣ�ͳ�� meta �дʣ��Ϳ���ͳ�Ƴ�������ʵ���ض���Ϣ����Ϊ�û����ʵĴ����֮�䲢���ǹ�����ȫ�صģ�������һ�������ġ���
meta �д���ʵ��������Ϣ���뵽�û��Ը����ʵĹ�ע���У����Ը��õ������û��Ĺ�ע���档���� meta
��ش���Ϣ��õ��˸��Ӿ�ȷ���û��ԴʵĹ�ע���б���
��ҳ meta �� keyword ������õ������Ǹ���ҳ�ķ�����Ϣ (
��������ҳ )�������Ǹ���ҳ�Ĺؼ��ʣ���������ҳ���������ǰ�ߣ�meta �еĴ�������ضȽϴ���ͬ��վ��
meta ������ʲô��������վ�ı༭�����ġ����Ѳ�ͬ��վ�� meta ���湲�ֵĴ���ȡ���������ܵ�һ����ʵ�ǻ���˸�����վ�༭�ǵļ����ǻۡ���Щ�ʵĹ�����ϢӦ���ܹ��ܺõر��ֳ������֮�������ԡ��������������һ����֣����Ǽ��п�������صġ�
��������Ϊ�����ȣ�ͳ�� meta �й�ͬ���ֵĴʶ��Լ����ǹ�ͬ���ֵĴ�����Ȼ��ͳ����Щ���ֵĴʶ��еĴ�ÿ���ʳ��ֵĴ��������Ӧ�ù�ʽ���й���Ƶ�ʵļ��㣬�õ��ľ��Ǵ����֮�����ضȡ����㹫ʽ
���У�pij��ʾ�� i �ʹ� j ����ضȣ�mi��mj��mij�ֱ��ʾ��
i���� j �Լ��� i �� j ��ͬ����ҳԪ��Ϣ��meta���� keyword �г��ֵĴ�����
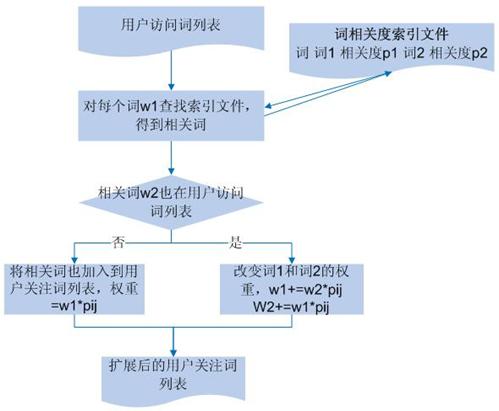
ͼ 4 ���û����ʹؼ�����չ����ͼ
ͼ 4 �����˽���֮�����ضȼ����û����ʹؼ����б��е����̣����ȵõ����дʶ�֮�����ض���Ϣ������������ʽ�洢��Ȼ��֮ǰ�õ����û����ʹؼ����б��е�ÿ���ʣ����������õ���صĴʣ�����ô�δ���û����ʹ���ֱ�ӽ�����뵽�û������б��У����������ʵ�Ȩ�ض�����е���
�ؼ��ʹ�Լ
��ؼ�����չ���Ӧ���ǹؼ��ʹ�Լ���û����ʵ���ҳ���ھ���Ĺؼ��������Ǿ���ģ������û���ע����ҳ����ȡ���Ĵ��ǡ���������������Щ���ڻ��ֵ�ʱ�����������࣬ͨ���ؼ��ʹ�Լ�������Ʋ�����û��ԡ��������Ƚϸ���Ȥ��
�������Ӧ����λ���أ��ڸ����Ż���վ�����ˡ�������ҳ�������������������š����������µȸ����࣬��ÿһ���������и�С�ࣻ���Ա�����Ȥ�����Ͻ���ƽ̨�������ж���Ʒ�Ķ༶��ϸ���ࡣ�ؼ��ʹ�Լ�����Ǹ����û����ʵĹؼ����ݵ��û�����Щ�������ݸ���Ȥ��
�����ǹؼ�����չ���ǹ�Լ������õ����Ӿ�ȷ���û����ʹؼ����б��������дʰ�Ȩ���ɴ�С�������У������ļ����û�����Ȥ�㡣
MapReduce ���û���Ȥ�ھ��ʵ��
��һ���ֽ������û���Ȥ���ھ�����̣������ֽ���Ը���ģ����� MapReduce
��ʵ�֡�����Ӧ�õ��������û�������ҳ��¼��ɵ��ļ����ļ�ÿ�б�ʾ�û�������ҳ��һ����¼����Ϊ��
���û� URL�����������Ϊ�û�����Ȥ���ļ����ļ�ÿ�д洢ÿ���û�����Ȥ�㣬��Ϊ��
���û� �� 1 Ȩ�� 1 �� 2 Ȩ�� 2 �� 3 Ȩ�� 3 ����
��������������ֱ� MapReduce ʵ�֡�
��һ��ҳ��Ϣ�ھ�
��һ��ҳ��Ϣ�ھ��Ŀ����ѡȡ����ҳ�������Ҫ�Ĺؼ��ʡ�����Ϊÿ���ʸ���Ȩ�أ���ѡȡȨ�ؽϴ�Ĵʡ��ʵ�Ȩ�ػ�ȡ��ʽ
v = sum(vi*fi) �������־������ô���ÿ�������ϵ�ȡֵ��������Ȩ�ء�
ÿ��������Ȩ�أ�����ѵ���õ�������Ϊ�����ؼ��ʵ�ϵ����ҳ������Ȩ��ѵ��ͨ�����ض����㷨������
SCGIS �㷨����Ϊѵ�����������������뼯��С�����㷨ͨ��Ҳ�ϸ��ӣ������ʺϲ��л������� MapReduce
����ʼ֮ǰ��������Ȩ��ѵ����
������ÿ������ά���϶�Ӧ��ȡֵ���������IJ�ͬ�����׳̶�Ҳ��ͬ������ʵij���λ�á���Сд�����Եȣ��ڶ���ҳ����ɨ��ʱ������������á���
TF( ������ҳ�г��ֵĴ��� )��DF������������ҳ�г��ֵĴ�������������������ʳ���ʱ������ȡ��������ÿ���ʴ����ij�����ͬ�����Կ���ʹ��
MapReduce ���ģ�Ͳ��л���������о��彲����
��һ��ҳ��Ϣ�ھֵ� MapReduce ������ͼ 5 ��ʾ��

ͼ 5.MapReduce ʵ�ֵ�һ��ҳ��Ϣ�ھ�
TF ������ҳ�г��ִ�����Ϣͳ��
Map������Ϊ�û� +url �б������ڵ�����¼������ url ����ͷִʣ��õ��û����ʵĸ���ҳ�а������дʵ���Ϣ��ÿ����һ���ʣ�Map
����һ�������key Ϊ�û� + ��ҳ + �ʣ�value Ϊ 1����Ȼ����ʱ Map ������ͳ��������Ϣ��������ԣ�����
/ ���ʣ��ȣ�Ϊ���������˴��������չ����
Reduce��Map �������� key ��ͬ�Ļ�۵�һ��Reduce
��ÿ��ͳ���������¼���������û� + ��ҳ + ����Ȼ��Ϊ key �����������ÿ���м�¼������Ϊ value
���������
������Reduce ���������ļ�ÿ�ж�Ӧ��¼Ϊ�� �û� + ��ҳ +
�� �ʵ� TF����
�嵥 1. MapReduce ͳ�� TF
public class TFCal extends Configured implements Tool,
Mapper<Text, Text, Text, IntWritable>,Reducer<Text, IntWritable, Text, IntWritable>{
public void map(Text usr, Text url, OutputCollector<Text, IntWritable> output,
Reporter reporter)throws IOException {
Text[] words = callCrawl(url); // �����������
for(Text word: words) // ÿ���ʽ������
output.collect(usr + url + word, new IntWritable(1));
}
public void reduce(Text key, Iterator<IntWritable>
iter,OutputCollector<Text,
IntWritable> output, Reporter reporter) throws
IOException {
tf = iter �а���Ԫ�ص���Ŀ ;
output.collect(key, tf);
}
public void runCal(Path input, Path output)
throws IOException {
JobConf job = new JobConf(getConf(), TFCal.class);
job.setInputPath(input);
job.setOutputPath(output);
job.setMapperClass(TFCal.class);
job.setMapperClass(TFCal.class);
job.setInputFormat(SequenceFileInputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
JobClient.runJob(job);
} } |
�����ҳ�������������ڴ��д�����Ҳ����ֻ�� Map ����ɶ�ÿ���� TF
��ͳ�ƣ���������ʡȥ Map �� Reduce ֮��������ݴ����ʱ�����ġ����崦��˼·Ϊ������һ�����ݽṹ
hashMap<String, value>��Map ��ÿ��������Ϊ�û� +url ��Ϣ����
url ��ҳ����Ľ����ÿ����һ���ʣ�������Ϣ���뵽 hashMap �У�key Ϊ�ʣ�value Ϊԭ��
value+1�����ͬʱ��������ͳ�Ƹôʵ���������ֵ��������Եȡ���Ϊ Map �μ������ TF ͳ�ƣ����Խ�
Reduce ��Ŀ��Ϊ 0��
�嵥 2. Map ͳ�� TF
public class TFCal2 extends Configured implements Tool, Mapper<Text, Text, Text,
IntWritable>{
public void map(Text usr, Text url, OutputCollector<Text, IntWritable> output,
Reporter reporter)throws IOException {
HashMap<Text, int> wordCount = new HashMap<Text, int>(); //HashMap ͳ�� TF
Text[] words = callCrawl(url); // �����������
for(Text word: words){ // ͳ�ƴʴ�����Ϣ
int cnt = wordCount.get(word);
wordCount.put(word,(cnt>0)?(cnt+1):1);
}
Iterator<Text,int> iter = wordCount.entrySet().iterator();
while(iter.hasNext()){
Map.Entry<Text, int> entry = iter.next();
// Map �����key Ϊ�û� +url+ �ʣ�value Ϊ TF
output.collect(usr + url + entry.getKey(), entry.getValue());
}
}
public void runCal(Path input, Path output)
throws IOException {
JobConf job = new JobConf(getConf(), TFCal2.class);
���� InputPath, outPath, MapperClass, InputFormat,
OutputFormat, ��
job.setReduceNum(0); //Reduce ��Ŀ��Ϊ 0�������� Reduce
������
JobClient.runJob(job);
}
}
|
DF ����������ҳ�г��ִ�����Ϣͳ��
Map ����Ϊ TF ����������key Ϊ�û� + ��ҳ + �ʣ�value
Ϊ�ʵ� TF��Map �δ���������ҳ��Ϣȥ������� key Ϊ�û� + �ʣ���� value Ϊ 1��
Reduce �� Map ���Ϊ���룬�û����ʴ���ͬ�Ļᱻͬһ�� reduce
������reduce ��ͳ�Ƹ��������¼����Ŀ�����Ǵʵ� DF�������ڼ���ÿ����Ȩ��ʱ����Ҫ�õ�����������ֵ�����ڼ���
TF ��ʱ����Եõ��ôʳ� DF ��������������Ϣ��������Ҫ����ػ�ȡ DF ��Ϣ��Ϊ�����ѯ DF ����Ϣ��Ӧ��
Reduce �ε�����������ļ�����ʽ���������Lucene �ǿ��� MapReduce ��Դ��� Hadoop
�ϲ�����������ƣ����� Reduce ���ʱ���ã�key Ϊ�û� + �ʣ�value Ϊ DF��
�嵥 3. MapRedcue ͳ�� DF
public class DFCal extends Configured implements Tool, Mapper<Text, IntWritable, Text,
IntWritable>,Reducer<Text, IntWritable, Text, LuceneDocumentWrapper>{
public void map(Text key, IntWritable url, OutputCollector<Text, IntWritable> output,
Reporter reporter)throws IOException {
�� key ��ֳ� user��url��word ������
output.collect(user+word, new IntWritable(1);
}
public void reduce(Text key, Iterator<IntWritable>
iter, OutputCollector<Text,
LuceneDocumentWrapper> output, Reporter reporter)throws
IOException {
int df = iter �а���Ԫ����Ŀ ;
// ���� Lucene �������� user+word Ϊ key��DF ��Ϊ value�����д洢
Document doc = new Document();
doc.add(new Field("word", key.toString(),
Field.Store.NO,
Field.Index.UN_TOKENIZED));
doc.add(new Field("DF", df, Field.Store.YES,Field.Index.NO));
output.collect(new Text(), new LuceneDocumentWrapper(doc));
}
public void runDFCal(Path input, Path output)
throws IOException {
JobConf job = new JobConf(getConf(), DFCal.class);
���� InputPath, outPath, MapperClass, InputFormat,
��
job.setOutputFormat(LuceneOutputFormat); // ���������ʽΪ
LuceneOutputFormat
JobClient.runJob(job);
�ϲ����� reduce ���ɵ������ļ�Ϊһ�����������ļ���Lucene �� IndexWriter
���ṩ����Ӧ�ӿڣ�
}
�� .
}
|
���嵥 3 �г��ֵ� LuceneDocumentWrapper �� LuceneOutputFormat
����Ϊ�� MapReduce ��ʹ�� Lucene �����ļ���Ϊ Map/Reduce ������ӵ��࣬���߷ֱ�̳���
WritableComparable �� FileOutputFormat���嵥 4 �ṩ�����ߵĶ��塣
�嵥 4. Lucene �� MapReduce �ϵ�ʹ��
public class LuceneDocumentWrapper implements Writable {
private Document doc;
public LuceneDocumentWrapper(Document doc) {
this.doc = doc;
}
public void set(Document doc_) {
doc = doc_;
}
public Document get() {
return doc;
}
public void readFields(DataInput in) throws IOException {
// intentionally left blank
}
public void write(DataOutput out) throws IOException {
// intentionally left blank
}
}
public class OutputFormat extends
org.apache.hadoop.mapred.FileOutputFormat<WritableComparable,
LuceneDocumentWrapper> {
public RecordWriter<WritableComparable, LuceneDocumentWrapper>
getRecordWriter(final
FileSystem fs,JobConf job, String name, final
Progressable progress)
throws IOException {
final Path perm = new Path(FileOutputFormat.getOutputPath(job),
name);
final Path temp = job.getLocalPath("index/_"
+ Integer.toString(
new Random().nextInt())); // ������ʱ���·��Ϊ Reduce
�ڵ㱾�ؾֲ�·��
final IndexWriter writer = new IndexWriter(fs.startLocalOutput(perm,
temp).toString(), new StandardAnalyzer(), true);
// ��ʼ�� IndexWriter
return new RecordWriter<WritableComparable,
LuceneDocumentWrapper>() {
public void write(WritableComparable key, LuceneDocumentWrapper
value)
throws IOException { // �� document ���뵽����֮��
Document doc = value.get();
writer.addDocument(doc);
progress.progress();
}
public void close(final Reporter reporter) throws
IOException {
boolean closed = false; // ��ʶ�����Ƿ��Ѿ�������
Thread prog = new Thread() {
public void run() {
�������δ������ closed != true�����ֵȴ��������� reporter ״̬Ϊ
closing
}
};
try {
prog.start();
writer.optimize(); // ���������Ż����ر�
writer.close();
�������������ȫ���ļ�ϵͳ HDFS ��
}finally{
closed = true;
}
}
};
}
}
|
��ҳ�ؼ��ʼ���
��� DF ��Ϣ������һ���µ� Map �����ж���ҳ��ÿ���ʼ�����Ȩ�أ�����Ϊ��ҳ�ؼ��ʵĸ��ʣ��˴�����ָ��һ����ֵ�������ʴ��ڸ���ֵ����Ϊ�ôʿ��Դ�����ҳ�����������������ԡ�
�嵥 5. Map ������ҳ�ؼ���
public class KeyWordCal extends Configured implements Tool, Mapper<Text, Text, Text,
IntWritable>{
String fWeights[]; // ��¼����Ȩ��
IndexSearcher searcher = null; // ���ڲ�ѯ Lucene �����ļ�
public void map(Text key, Text wordInfo, OutputCollector<Text, IntWritable> output,
Reporter reporter)throws IOException {
���� key�����еõ� word ��Ϣ
// ���������ļ����õ� DF
Term t = new Term("word", word);
Query query = new TermQuery(t);
Hits hits = searcher.search(query);
if (hits.length() == 1) {
Document doc = hits.doc(0);
String df = doc.get(��DF��);
�� wordInfo ����ȡ����ÿ��������Ӧȡֵ , �洢������ val ��
weight = sum��val[i] �� fWeights[i]��; // ����ô���Ϊ�ؼ���Ȩ��
if(weight >= threshold) // Ȩ�ش�����ֵ����Ϊ��ҳ�ؼ���
output.collect(key, new Writable(1)); // �ؼ��������key �����û� + �ؼ��ʣ�value Ϊ 1
}
}
// configure ��������ÿ�� Map �ڵ����� Map �������ļ����д���֮ǰ���ã�ͨ��������ȫ�ֲ���
public void configure(JobConf job) {
String fWeightPath = job.getStrings(��fWeight.path��)[0];
/// �ڲ��������Ȩ��·��
��ȡ����Ȩ���ļ����õ�����Ȩ���б������� fWeights;
String dfPath = job.getStrings(��DF.path��)[0];
FsDirectory fsDirectory = new FsDirectory(FileSystem.get(getConf()),dfpath,
false, getConf());
searcher = new IndexSearcher(fsDirectory);
}
public void runkeyWordCal(String input, String
output, String DFPath){
String featureWeightFile��
SCGIS(featureWeightFile); // ���û���ѧϰ�㷨����������Ȩ�أ�����Ȩ�ش洢��ָ���ļ���
JobConf job = new JobConf(getConf(),KeyWordCal.class);
���� InputPath, outPath, MapperClass, InputFormat,
OutputFormat, ��
job.setStrings(��fWeight.path��, featureWeightFile);//
���ò������Դ��� Map �� configure
job.setStrings(��DF.path��, DFPath); // ���� DF �����ļ�λ��
JobClient.run(job);
}
�� .
} |
�û����ʹؼ��ʻ���
���û��ؼ��ʻ���ģ�飬һ����Ҫ���������� Reduce������ͼ��ͼ 6
��ʾ��
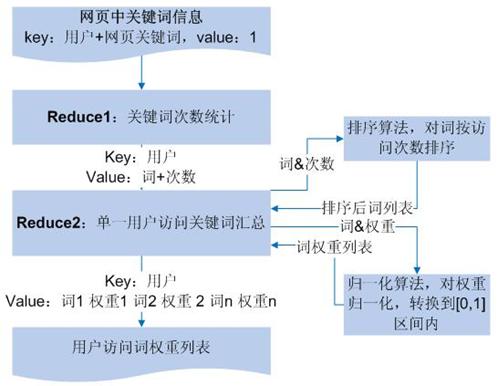
ͼ 6.MapReduce ʵ���û��ؼ��ʻ���
�û����ʴʴ�������
������һ��ҳ��Ϣ�ھ�ģ��Ĵ�������ÿ����ҳ������ϣ�����ļ�¼��Ϊ���û�
+ ��ҳ�ؼ��ʡ�������ֻ�辭��һ�� Reduce ����ͳ�Ƴ��û�����ÿ���ʵĴ�����Ϊ���������ÿ���û��Ĺ�ע�ʽ��л��ܴ�������
Reduce ����� key Ϊ�û���value Ϊ�� + �û����ʸôʵĴ���
�û����ʴʰ���������
�ڶ��� Reduce ������Ϊ��һ�� Reduce ��������ڱ� Reduce
�У�ͬһ�û����ʵĴʻᱻ��۵�һ��Ϊ�˸��õ������û�����Ȥ�㣬Ӧ�����дʰ����ʴ������дӴ�С����������ͨ��
Reduce �ڲ��Գ��������㷨�������������ĵ�����ʵ�֡�
��Ȩ�ع�һ��
��Ϊ��ͬ�ʵķ��ʴ������ܲ��ϴ�������ʷ��� 20 �Σ����γ����ʿ��ܷ���
10 �Σ���˴�IJ�ಢ�����ڶԴ�Ȩ�صĽ�һ�����������Բ��������ھ������Ĺ�һ���������Դ�Ȩ�ؽ��е��������������
[0��1] �����ڡ���IJ����ǽ�����ʵķ��ʴ���ȥ������ÿ���ʵĴ�����Weight��w��=Times��w��/Times��MAX�������Ȩ�ع�һ���Ĺ���ͬ�������ڵڶ���
Reduce ��������ɡ�
�嵥 6. ���� Reduce �����û����ʹؼ���
public class UserWordCal1 extends Configured implements Tool, Reducer<Text, IntWritable,
Text,Text>{
public void reduce(Text key, Iterator<IntWritable> iter, OutputCollector<Text, Text>
output, Reporter reporter)throws IOException {
���� key���ֱ�õ� user ��Ϣ�� word ��Ϣ
output.collect(user, new Text(word + iter �а���Ԫ�صĸ��� )); //value Ϊ�û����ʸôʴ���
}
�� .
}
public class UserWordCal2 extends Configured
implements Tool, Reducer<Text, Text, Text,
Text>{
public void reduce(Text key, Iterator<Text>
iter, OutputCollector<Text, Text>
output, Reporter reporter)throws IOException {
Struct<Text, int> Word; // ����һ�����ݽṹ����������ֱ�洢
word �ʹ�����Ϣ
ArrayList<Word> wList;
���� iter�������ʴʵ���Ϣ���� wList;
QuickSort(wList); // �� wList ����������
Normalize(wList); // �� wList ����Ȩ�ع�һ��
String wordInfo = ����;
for(Word word: wList) // ���ʺͶ�Ӧ��Ȩ����Ϣƴ��
wordInfo = wordInfo + word + word.getWeight();
output.collect(user, new Text(wordInfo));
}
�� .
}
|
MapReduce �����������֧��
ʵ���ϣ�MapReduce �����Ļ���Ҳ����ʵ�������ܡ����ݴ� Map
��������� Reduce ����������Ҫ������������ģ�������Map �˸��� Reduce ��Ŀ�Ա���������з��飻Map
�� Reduce ֮������ݴ��� shuffle��Reduce �˶����Զ�� Map �����ݰ� key
���������飬ÿ�鴫��� Reduce �������д�����
��������̿��Կ�����ͬһ�� Reduce ����������ʵ�����ǰ��� key
����ģ������ Reduce ��Ŀ��Ϊ 1(job.setReduceNum(1))������������ֶ���
Map ��������Ϊ key���Ϳ���ʵ�����ݵ�ȫ������
�ؼ�����չ����Լ
�ؼ�����չ��Լ���û����ʴ��б����е�������ͬ����ĵ�����������ϸ����һ�����Թؼ�����չ����չ����
�������ض���Ϣ��ȡ
�ؼ�����չ�Ĺؼ��ǵõ�����ʵ���ضȣ������ڴ���ضȶ��û����ʴ��б����е����������֮����ضȵļ��㹫ʽ����ǰ��С���г���

ͼ 7 ��MapReduce ʵ�ִ������ضȼ���

ͼ 7 չʾ�� MapReduce ����
pij�����̡�
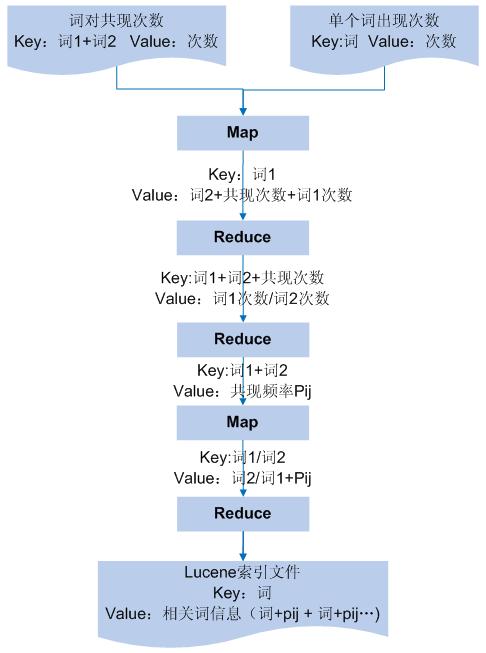
ͳ�ƴʶԹ��ִ���
Map�����û����� url ��ϢΪ���룬�� Map �ڲ�������ҳ���棬��ֻ��ȡ��ҳ��
meta �� keyword ��Ĵ���Ϣ��ÿ����ҳ�ж�Ӧ�Ĵ�������ɴʶԽ���������ʶ��е�һ���ʵ�ƴ����
/ ��ĸ��Ҫ���ڵڶ����ʡ���� key Ϊ�� 1+ �� 2��value Ϊ 1��
Reduce ͳ�ƴ� i �ʹ� j ��ͬ���ֵĴ��� mij���� Reduce
�ڲ�ͳ��ÿ�������¼����Ŀ����Ȼ�Դ� 1+ �� 2 ��Ϊ key�������ִ�����Ϊ value ���������
�嵥 7. �������ضȼ��� -1 ���ʶԹ��ִ���ͳ�ƣ�
public class WordsCorrCal1 extends Configured implements Tool, Mapper<Text,
Text, Text, IntWritable>, Reducer<Text, IntWritable, Text, IntWritable>{
public void map(Text key, Text url, OutputCollector<Text, IntWritable>
output, Reporter reporter)throws IOException {
Text[] words = callCrawlKeyWord(url); // ����ҳ���棬��ȡ meta �� keyword ��Ĵ�
for(int i = 0; i < words.length(); i++)
for(int j = i + 1; j < words.length(); j++)
output.collect((words[i] < words[j])? (
words[i] + words[j]) : (words[j] + words[i]), new IntWriable(1));
}
public void reduce(Text key, Iterator<IntWritable>
iter, OutputCollector<Text,
IntWritable> output, Reporter reporter)throws
IOException {
output.collect(key, iter �а���Ԫ�ص���Ŀ ); //value Ϊ�����ʹ��ִ���
}
�� .
}
|
ͳ�Ƶ����ʳ��ִ���
Ϊ�������ʵ���ضȣ���������ʹ��ִ����⣬��Ӧ���ÿ���ʵij��ִ���������ͨ��һ�������
Map/Reduce ������ͳ�ơ����У�Map �Ե�һ�� Reduce �����Ϊ���룬��ÿ���ʶ� i ��
j�����������¼��key �ֱ�Ϊ�� i �ʹ� j��value ��Ϊ���ʹ��ִ��� ;Reduce ��ɴʴ�����ͳ�ơ�
�嵥 8. �������ضȼ��� -1 �������ʴ���ͳ�ƣ�
public class WordsCorrCal2 extends Configured implements Tool, Mapper<Text,
IntWritable, Text, IntWritable>, Reducer<Text, IntWritable, Text,
LuceneDocumentWrapper >{
public void map(Text wordPair, IntWritable cnt, OutputCollector<Text,
IntWritable> output, Reporter reporter)throws IOException {
�� wordPair �������� word1, word2
output.collect(word1, cnt);
output.collect(word2, cnt);
}
public void reduce(Text key, Iterator<IntWritable>
iter, OutputCollector<Text,
LuceneDocumentWrapper> output, Reporter reporter)throws
IOException {
int wordCnt = 0;
while(iter.hasNext())
wordCnt += iter.next().get();
// ���� Lucene �������� word Ϊ key�����ִ�����Ϊ value�����д洢
Document doc = new Document();
doc.add(new Field("word", key.toString(),
Field.Store.NO,
Field.Index.UN_TOKENIZED));
doc.add(new Field("count", wordCnt,
Field.Store.YES,Field.Index.NO));
output.collect(new Text(), new LuceneDocumentWrapper(doc));
}
�� .
}
|
����ʶ���ض�
�����������ļ���һ���ļ��м�¼���ǵ����ʳ��ֵĴ�������һ�ļ���¼�����ǴʶԳ��ֵĴ�������δ��������ļ��õ�����ʵ���ضȣ���ֱ�۵�˼·�ǽ������ʳ��ִ�����Ϊ�����ļ������key
Ϊ�ʣ�value Ϊ�ʵĴ�������ִ��һ�� Map���ԵڴʶԹ��ִ����ļ�Ϊ���룬�ڴ���ÿ����¼ʱ����ѯ�����ļ����Σ�Ȼ���չ���Ƶ�ʹ�ʽ����õ������
�嵥 9. �������ضȼ��� -1 �����������ļ���
public class WordsCorrCal3 extends Configured implements Tool, Mapper<Text,
IntWritable, Text, FloatWritable >{
public void map(Text wordPair, IntWritable cnt, OutputCollector<Text,
FloatWritable > output, Reporter reporter)throws IOException {
�� wordPair �������� word1, word2
���� Lucene �����ļ� , �õ� word1 ���ִ��� cnt1
���� Lucene �����ļ� , �õ� word2 ���ִ��� cnt2
���� Pij��Pij = cnt/(cnt1 + cnt2 �C cnt);
output.collect(wordPair, new FloatWritable(Pij));
}
�� .
}
|
MapReduce �е����� -- �ϲ����ݼ��IJ���
������Ϣ�ļ��ϴ�ѯ Lucene �����ļ���Ч��Ҳ�ή�ͣ���Ϊ��ÿ���ʶԣ���Ҫ�������δʵ������ļ������Բ��������ļ��Ĵ���������
O��n2������ѯ����Ҳ����Խϴ���������һ�ֲ�����ɴʶ���ضȵļ��㡣�������ļ�ͬʱ��Ϊ Map �����룬��
Map �ڲ��жϼ�¼�������ĸ��ļ������ж�Ӧ�������� Reduce ��������ݼ��ĺϲ���ͼ 8 չʾ�˶�Ӧ���̡�
ͼ 8��MapReduce ʵ�ִ������ضȼ���
-2
�� 1 �� map-reduce
�ϲ������ʴ����ļ��ʹʶԴ����ļ���
Map ��������������ͬ�ļ��������ʴ����ļ��ʹʶԹ��ִ����ļ���Map
�ڲ������������ļ��ļ�¼���в�ͬ���������ƴ����ͬ��ʽ�������������� key Ϊ�����ʣ�value ����
���ڶ����� + ���ִ��� \t �����ʴ�������û�еIJ��֣��Կ��ַ����롣���������ڵ�һ�������value
���� \t ����ĵ�һ���־��ǿ��ַ��������ڵڶ��������value ���� \t ����ĵڶ�����Ϊ���ַ���
Reduce �����������м�¼���Ե�һ����Ϊ���ַ��ģ��� key �ʶ�Ӧ������ȡ����������¼��Ӧ������ô���ص������ʼ����ִ�����Ϣ������Щ��Ϣ�ŵ�һ�����顣������ϣ���������ÿ��Ԫ�أ�������������
key Ϊ�� 1+ �� 2+ ���ִ��� ( �ֵ�����ǰ�Ĵ���ǰ )��value Ϊ Reduce ����
key �ʣ��� 1 ���ߴ� 2���Ĵ�����Ϣ��
�嵥 10. �������ضȼ��� -2 ��ƴ��ͳһ��ʽ��
public class WordsCorrCal_21 extends Configured implements Tool, Mapper<Text,
IntWritable, Text, Text>, Reducer<Text, Text, Text, IntWritable >{
public void map(Text key, IntWritable cnt, OutputCollector<Text,Text> output,
Reporter reporter)throws IOException {
String[] words = key.toString.split(��[\t]��);
// �����Ӧ���ǴʶԵ������ļ�
if(words.length() == 2){
output.collect(new Text(words[0]), new Text(
words[1] + ��\t�� + cnt + ��\t��));
output.collect(new Text(words[1]), new Text(
words[0] + ��\t�� + cnt + ��\t��)};
) else if(words.length() == 1) { // �����Ӧ���ǵ����ʵ������ļ�
output.collect(key, new Text(��\t�� + cnt);
)
}
public void reduce(Text key, Iterator<Text>
iter, OutputCollector<Text,
IntWritable> output,Reporter reporter)throws
IOException {
ArrayList<String> corrWords = new ArrayList<String>();
int wordCnt;
while(iter.hasNext()){
String val = iter.next().toString();
String[] vals = val.split(��[\t]��);
if(vals.length() == 2) //val �洢���ǵ����ʳ��ִ���
wordCnt = Integer.parse(vals[1]);
else //val �洢���ǴʶԵ���Ϣ��ǰ����ֱ��ǹ��ִʼ����ִ���
corrWords.add(vals[0]+��\t��+vals[1]);
)
for(String corrWord: corrWords){ // ��� key ����
1+ �� 2+ ���ִ�����
//��� value�������ʴ���
String[] cor = corrWords.split(��[\t]��);
output.collect((key < cor[0])?(key + ��\t�� +
corrWord):(
cor[0] + ��\t�� + key + cor[1]),wordCnt);
}
}
�� .
}
|
�� 2 �� map-reduce ���㹲��Ƶ�ʡ�
����һ�� Reduce������Ϊ��һ map-reduce �������key
Ϊ�� 1+ �� 2+ ���ִ�����value Ϊ�����ʵĴ�������������ֱ�õ������ʵĴ�����Ϣ��Ȼ�����ù���Ƶ�ʹ�ʽ���������ʵ���ضȡ�Reduce
����� key Ϊ�� 1+ �� 2��value Ϊ�����ʵĹ���Ƶ�ʡ�
�嵥 11. �������ضȼ��� -2 ��������ضȣ�
public class WordsCorrCal_22 extends Configured implements Tool, Reducer<Text,
IntWritable,Text, FloatWritable >{
public void reduce(Text key, Iterator<IntWritable> iter,
OutputCollector<Text,FloatWritable> output,Reporter reporter)throws IOException {
int word1Cnt = iter.next().get();
int word2Cnt = iter.next().get();
�� key ������ word1��word2�����ִ��� corrCnt��
float pij = corrCnt/(word1Cnt + word2Cnt - corrCnt);
output.collect(new Text(word1 + word2), new FloatWritable(pij));
}
�� .
} |
�� 3 �� map-reduce ��������ض���Ϣ�����ļ���
�� 3 �� map-reduce �õ�ÿ���ʵ���ش���Ϣ�������������ļ���Lucene
�����ļ���������ֱ�Ϊ��word���͡�corrInfo����
Map ������ key Ϊ�� 1+ �� 2��value Ϊ��ضȡ�Map ���� 1 �ʹ� 2 ������������
key Ϊ�� 1��value Ϊ�� 2+ ��ضȣ���� key Ϊ�� 2��value Ϊ�� 1+ ��ضȡ�
Reduce �� key ��ͬ�Ļ�۵�һ�𣬲��ѵ������еĴʼ���ע����Ϣƴ��һ���γ�һ���ַ�������Ϊ
corrInfo ������ݡ�
�嵥 12. �������ضȼ��� -2 ����������ļ���
public class WordsCorrCal_23 extends Configured implements Tool, Mapper<Text,
FloatWritable, Text, Text>, Reducer<Text, Text,Text, LuceneDocumentWrapper>{
public void map(Text wordPair, FloatWritable corr,
OutputCollector<Text,Text> output,Reporter reporter)throws IOException {
�� key ������ word1��word2
output.collect(new Text(word1), new Text(word2 + ��\t�� + corr.get());
output.collect(new Text(word2), new Text(word1 + ��\t�� + corr.get());
}
public void reduce(Text key, Iterator<Text> iter, OutputCollector<Text,
LuceneDocumentWrapper> output,Reporter reporter)throws IOException {
String corrInfo = ����;
while(iter.hasNext())
corrInfo = corrInfo + iter.next() + ��\t��;
// ���� Lucene �������� word Ϊ key�����ִ���Ϣ��Ϊ value�����д洢
Document doc = new Document();
doc.add(new Field("word", key.toString(), Field.Store.NO,
Field.Index.UN_TOKENIZED));
doc.add(new Field("corrInfo", corrInfo, Field.Store.YES,Field.Index.NO));
output.collect(new Text(), new LuceneDocumentWrapper(doc));
}
�� .
} |
�û����ʴ��б�����
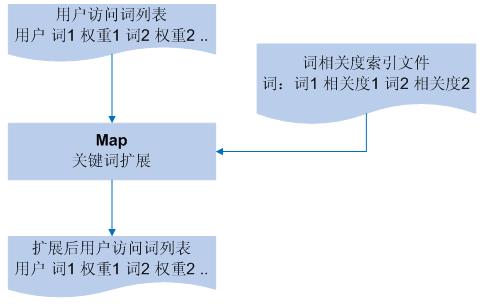
ͼ 9��MapReduce ʵ���û����ʹؼ�����չ
��ôʶ���ضȺ����Զ��û����ʹؼ����б�������չ����ͼ 9 ��ʾ��ֻ��һ��
Map ������ɲ�����Map ���û����ʴ��б�Ϊ���룬key Ϊ�û���value Ϊ�ؼ����б������ڹؼ����б��е�ÿ����
A��������Ҵ���ض������ļ����õ���� A ��صĴ��б� AL������ AL����� AL�еĴ� B Ҳ���û����ʹ�����ôҪ���û����ʴ�
B ��ֵ�� A �� B ����ضȵĽ�����뵽 A �ľ�ֵ�ϣ���� AL�еĴ� C �û�û�з��ʹ�����Ҫ�Ѵ�
C ���뵽�û����ʴ��б��У������� A �ľ�ֵ�� A �� C ����ضȼ��뵽�� C ֵ�ϡ�Map �����
key ��Ϊ�û���value Ϊ�û����ʵĴ��б�����Ӧ���µĹ�ע��ֵ��
public class WordExp extends Configured implements Tool, Mapper<Text, Text,
Text, Text >{
IndexSearcher searcher = null; // ���ڲ�ѯ Lucene �����ļ�
public void map(Text key, Text val, OutputCollector<Text,Text> output,Reporter
reporter)throws IOException {
HashMap<String, float> words; //key Ϊ�ʣ�value Ϊ�û����ʸôʵ�Ȩ��
HashMap<String, float> wordNewInfo; // �洢��������б���Ϣ
�� val �ؼ�����Ϣ���н������������� words;
���� words ����Ϣ�� wordNewInfo �� ;
for(words ��ÿһ���ؼ��� word){
float w1 = words.get(word);
���� Lucene �����ļ����õ��ô���ش��б� corrWords;
for(corrWords ��ÿ���� corrW){
// ��� corrW Ҳ���û����ʣ��������ʵ�Ȩ��
if((float w2 = words.get(corrW)) != null){
wordsNewInfo.put(word, wordsNewInfo.get(word) + w2 * corrW.pij);
wordsNewInfo.put(corrW, wordsNewInfo.get(corrW) + w1 * corrW.pij);
}else{ // ���δ�����ʣ����ʼ��뵽�û������б���
wordsNewInfo.put(corrW, w1 * corrW.pij);
}
}
}
String wordListNew = ����;
for(wordNewInfo ��ÿ��Ԫ�� entry)
wordListNew = wordListNew + entry.getKey() + entry.getVal();
output.collect(key, new Text(wordListNew);
}
// configure ��������ÿ�� Map �ڵ����� Map �������ļ����д���֮ǰ���ã�ͨ��������ȫ�ֲ���
public void configure(JobConf job) {
String corListPath = job.getStrings(��corrList.path��)[0]; /// �ڲ��������Ȩ��·��
FsDirectory fsDirectory = new FsDirectory(FileSystem.get(getConf()),corListPath,
false,getConf());
searcher = new IndexSearcher(fsDirectory);
}
public void runWordExp(String input, String output, String corPath){
JobConf job = new JobConf(getConf(),WordExp.class);
���� InputPath, outPath, MapperClass, InputFormat, OutputFormat, ��
job.setStrings(��corrList.path��, corPath); // ������ش��б�������Ϣ
JobClient.run(job);
}
�� .
}
|
������
MapReduce ���ģ��������ǿ��ļ������������õĿ���չ�Ժ������ԣ��ڹ�ҵ���ѧ����õ��˹㷺ʹ�á��Դ��ģ���������������ص㣬ʹ��
MapReduce ������������־������Ӧ�á�MapReduce ���ģ�͵Ļ����� Map �� Reduce
��������ν�Ӧ��ȫ�����߲���ת�������������ģʽ������Ӧ�ò��л�������һ�����ɵġ����Ķ��û���Ȥ���ھ�Ӧ�ý���
MapReduce ��ʵ�֣����������ھ�����������⣬MapReduce ��ʵ�ַ�ʽҲΪ�û�����Ӧ�ò��л��ṩ�˲ο���
�����
�鿴 MapReduce Wiki���˽���� MapReduce ���ģ�͵�ԭ��
�鿴 Welcome to Apache Hadoop, �˽� MapReduce
��Դ��� hadoop ������
�鿴 Hadoop In China, �˽��й� Hadoop ���������ҹ�˾��
Hadoop ��ʹ�����
���� �� Hadoop ���зֲ�ʽ���б�̣��� 1 ���֣��˽� MapReduce
���ʵ��
�鿴 Welcome to Apache Lucene���鿴���� Lucene
�������Ƶ�����
�鿴 IEEE Xplore A Switch Criterion for
Hybrid Datasets Merging on Top of MapReduce, �˽����߶� MapReduce
�ϲ������ӻ��Ƶ��о�
���� ����ѧϰ�����㷨�������˽�������ѧϰ���㷨
���� Behavior Analysis and Learning���˽��û���Ϊ�������������
��������ʹ�� MapReduce ����ƽ�⡱��developerWorks��2010
�� 8 �£����˽�������ƻ�����ʵ�� Hadoop MapReduce ��ܣ��Լ����ʹ������ĸ���ƽ��Ľ����ڵ�Ͷ�ڵ�ϵͳ�����ܡ�
���� MapReduce ������Ƽ�����ص� Big Data ���⡱��developerWorks��2011
�� 1 �£������ڷdz����ӵļ��㣬��ʱ����Ҫ�ܹ����ʸ���������������Դ���ܵõ��������������֯�ڽ�������ϵͳҪ�����Դ�����ںͼ����ϰ���������һЩ�����ϰ����Ƽ����ܹ����������⡣ͨ���ð�����������ӵ�λ�ñ�����Ͳ���أ��Ƽ��������
MapReduce ���������ؽ���Դ������� Big Data ���㡣���������Ƽ���� MapReduce
Ϊʲô�����ڽ�� Big Data ���⡣
��Java ���� 2.0���� Hadoop MapReduce ���д����ݷ�������developerWorks��2011
�� 4 �£���Apache Hadoop ��Ŀǰ�����ֲ�ʽ���ݵ���ѡ���ߣ��ʹ���� Java 2.0 ����һ�����ǿ���չ�ġ���
Hadoop �� MapReduce ��̽�ģ��ʼ��ѧϰ����������������ݣ�������СС����ҵ��Ϣ����
developerWorks Java ����ר��������������ƪ���� Java
��̸�����������¡�
|


