�ӽ���ʼ����ʼ���רһ����ѧ���������ڵġ��Ƽ��㡷�Ȿ�飬����дЩ�Լ��ıʼǵģ����Ѿ�������Ӧ����PPT������Ѿ��������ˣ����ԣ�����ıʼǣ���ʵֻ���൱���Լ��ıʼDZ��������Լ��Ժ�����̶��ط����Ұɡ�
Ϊ�˼�ࣨ����˵����ֱ�Ӱ�PPT��������ɣ���
1��ʲô���Ƽ���
�Ƽ�����һ����ҵģʽ�������ڸ߿ɿ��ԡ����Զ��������Զ�������ô������˴��ģ�Ļ�����˵��������Ǿ������˲��������������߿����Եļ�����Դ���豸(��רҵһ��ģ��м�������)��֧���£�����ֻҪ���뻥���������ܷdz�����ط��ʸ��ֻ����Ƶ�Ӧ�ú���Ϣ������ȥ�˰�װ��ά���ȷ�������(�������������Զ����Լ�ϲ����ģʽ����ɫ��
�Ƽ�����һ����ҵ����ģ�͡�������������ֲ��ڴ�����������ɵ���Դ���ϣ�ʹ����Ӧ��ϵͳ�ܹ�������Ҫ��ȡ���������洢�ռ����Ϣ����
�Ƽ����ص㣺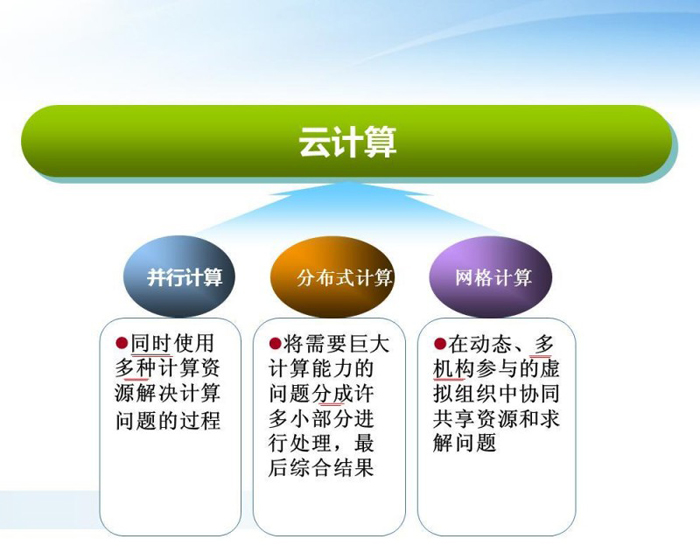
- �����ģ
- ���⻯
- �߿ɿ���
- ͨ����
- �߿�������
- �������
- ��������
2���Ƽ���ķ�չ��״���ԣ�
3���Ƽ������ϵ�ṹ���ԣ�
4���Ƽ������������
������㡪���ڶ�̬������������������֯��Эͬ������Դ���������

����������Ƽ���Ĺ�ϵ��������OSI��TCP/IP֮��Ĺ�ϵ�����������Ӧ����ȽϾ�ȷ
�Ƽ�������������һ�ּ���̬������Ҫ�����칹��Դ����Ҫ�������Ǽ�����Э�����⣬Ҳ�����Ƽ����гɹ�����ҵģʽ�ƶ�������ʵ������Ҫ���Ƽ����Ѷȴ�ܶࡣ����������߶˿�ѧ�����Ӧ�ö��ԣ��Ƽ���������������ģ��������������������
���õĽ������������Ƽ���֮�ϵġ���ҵ2.0���뽨�����������֮�ϵġ���ѧ2.0������ȡ�óɹ���
����Gloud���Ƹ�=Grid+Cloud1,��Ҳ�������ķ�չ����
��������Ҫ����ֲ��ڲ�ͬ�����ĸ�����Ϣ��Դ�Ĺ������⣬���Ƽ�����Ҫ����������ʹ洢�ռ�ļ��й���ʹ�����⡣
5���Ƽ���ķ�չ����
3G���Ƽ����ǻ������桢����ٽ��Ĺ�ϵ
J3G��Ϊ�Ƽ�����������ڼƵĿ����ƶ��û����û����ն˼��������ʹ洢�ռ����ޣ�ȴ�к�ǿ���������������Ƽ���������Ȼ������
J�Ƽ����ܹ���3G�û��ṩ���õ��û����顣�Ƽ�����ǿ��ļ����������ӽ����Ĵ洢�ռ䣬��֧�Ÿ��ָ�������������Ϣ�����ܹ�Ϊ3G�û��ṩǰ��δ�еķ�������
�ƶ����������Ƽ������ศ��ɵ�
ͨ���Ƽ��㼼������Ӳ����ÿ�ǰ�ļ�Լ��Ӧ��
�ƶ�������ʱ�����٣����û���������õ������ǵ������ߺ����ߵĸ���Ƽ�������ͻ�Ƹ����նˣ���ʾ�����ݡ�Ӧ�ö��ܱ���һ���Ժ�ͬ����
�Ƽ�������ƺͶ�������д�ͳģʽ���ɱ��������
�����ں�Ϊ�Ƽ����ṩ��ʵ��Ӧ�û���
a�Ƽ��㼼��ʹ��һЩ���´�ͳ��ҵ����ҵҲ�ܴ��������ںϺ���һ��������Ŀ쳵
a�Ƽ����������ںϼ���һ��������е�Ӧ�ã��漰���ݴ洢�����ݼ��㡢�����ٴ������������������ݴ��䡢����Эͬ�ȶ������
Google���Ƽ���ԭ����Ӧ�ã�GFS��MapReduce��
Googleҵ��
ȫ������������桢Google Maps��Google Earth��Gmail��YouTube�ȡ����ص㣺�������Ӵ�����ȫ���û��ṩʵʱ����
Google�Ƽ���ƽ̨�����ܹ�
���ļ��洢��Google Distributed File System��GFS
�鲢�����ݴ���MapReduce
��ֲ�ʽ��Chubby
��ֲ�ʽ�ṹ�����ݱ�BigTable
��ֲ�ʽ�洢ϵͳMegastore
��ֲ�ʽ���ϵͳDapper
һ��Google�ļ�ϵͳGFS
������������ģ�ϵͳ�ܹ����ݴ����ơ�ϵͳ��������
1��ϵͳ�ܹ�
Client���ͻ��ˣ���Ӧ�ó���ķ��ʽӿ�
Master�������������������ڵ㣬������ֻ��һ��������ϵͳ��Ԫ���ݣ����������ļ�ϵͳ�Ĺ���
ChunkServer�����ݿ�����������������Ĵ洢�������������ļ�����ʽ�洢��ChunkServer��
��������ļܹ�ͼ֮ǰ������һƪ���ͣ����������ܸ�֪(Rack Awareness)������һ���ı�ʾ���ܿ�ϧ���;�δ�ҵ��������ǣ�
����Rack Awareness����Rack1:Chunk1 ��Chunk4��Chunk7����Rack
n:Chunk2��Chunk 5��Chunk6����
������ns:file����Chunk1��Chunk2����
����������һ��ϣ������ļ��顢��������ԵIJ��ҵ��Ż��ȱȽϷ���
GFS�ص㣺
�������ķ�����ģʽ
u���Է��������Chunk Server
u Master����ϵͳ������Chunk Server�������������и��ؾ���
u������Ԫ���ݵ�һ��������
����������
�ļ�����������ʽ��д�������ڴ����ظ���д��ʹ��Cache��������߲���
Chunk Server�����ݴ�ȡʹ�ñ����ļ�ϵͳ������ȡƵ����ϵͳ����Cache
�ӿ����Կ���Cache��ʵ�����ݵ�һ����ά��Ҳ���临��
���û�̬��ʵ��
������POSIX��̽ӿڴ�ȡ���ݽ�����ʵ���Ѷȣ����ͨ����
��POSIX�ӿ��ṩ���ܸ��ḻ
���û�̬���ж��ֵ��Թ���
��Master��Chunk Server���Խ��̷�ʽ���У��������̲�Ӱ����������ϵͳ
��GFS�Ͳ���ϵͳ�����ڲ�ͬ�Ŀռ䣬��������Խ���
ֻ�ṩר�ýӿ�
�齵��ʵ�ֵ��Ѷ�
���Ӧ���ṩһЩ����֧��
�齵���Ӷ�
2���ݴ�����
Master�ݴ�
Name Space���ļ�ϵͳĿ¼�ṹ
Chunk���ļ�����ӳ��
Chunk������λ����Ϣ(Ĭ������������)
����Master������ǰ����Ԫ���ݣ�GFSͨ��������־���ṩ�ݴ�����
������Ԫ������Ϣ�����ڸ���ChunkServer�ϣ�Master����ʱ�����ָ̻�
GFS���ṩ��MasterԶ�̵�ʵʱ����,��ֹMaster�������������
Chunk Server�ݴ�
u���ø�����ʽʵ��Chunk Server�ݴ�
��ÿһ��Chunk�ж���洢������Ĭ��Ϊ���������ֲ��洢�ڲ�ͬ��Chunk
Server���û�̬��GFS����Ӱ��Chunk Server���ȶ���
�������ķֲ�������Ҫ���Ƕ������أ�����������ˡ����ܵķֲ������̵������ʵ�
������ÿһ��Chunk�����뽫���еĸ���ȫ��д��ɹ�������Ϊ�ɹ�д��
����һ��������Ҫ�洢���ݣ�������̿ռ�������ʲ��ߣ����ۺϱȽ϶������أ���֮���̵ijɱ������½������ø���
�����������ɿ�������Ч������ʵ�ֵ��Ѷ�Ҳ��С��һ�ַ�����
�� GFS�е�ÿһ���ļ������ֳɶ��Chunk��Chunk��Ĭ�ϴ�С��64MB
��Chunk Server�洢����Chunk�ĸ������������ļ�����ʽ���д洢
�� ÿ��Chunk�ֻ���Ϊ����Block��64KB����ÿ��Block��Ӧһ��32bit��У���룬��֤������ȷ����ij��Block����
��ת��������Chunk������
ϵͳ��������
�����ֲ�ʽ���ݴ���MapReduce
1����������
MapReduce
- һ�ִ����������ݵIJ��б��ģʽ�����ڴ��ģ���ݼ���ͨ������1TB���IJ������㡣
- ��Map��ӳ�䣩������Reduce�������ĸ������Ҫ˼�룬���ǴӺ���ʽ�������( �ʺ��ڽṹ���ͷǽṹ���ĺ������ݵ��������ھ������������ѧϰ��)��ʸ��������Խ��
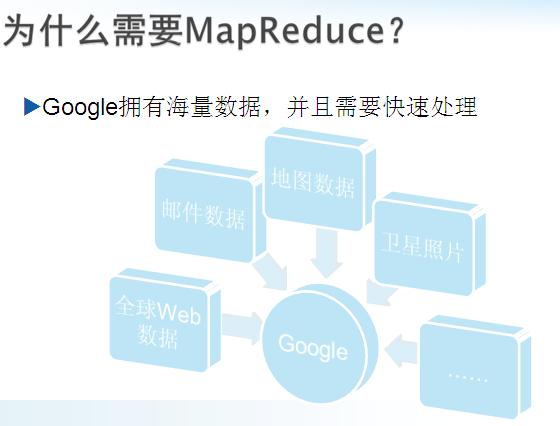
u������������������
�C��������������PB������ֻ�зֲ��ڳɰ���ǧ���ڵ��ϲ��м�������ڿɽ��ܵ�ʱ�������
�C��ν��в��зֲ�ʽ���㣿
�C��ηַ����������ݣ�
�C��δ����ֲ�ʽ�����еĴ���
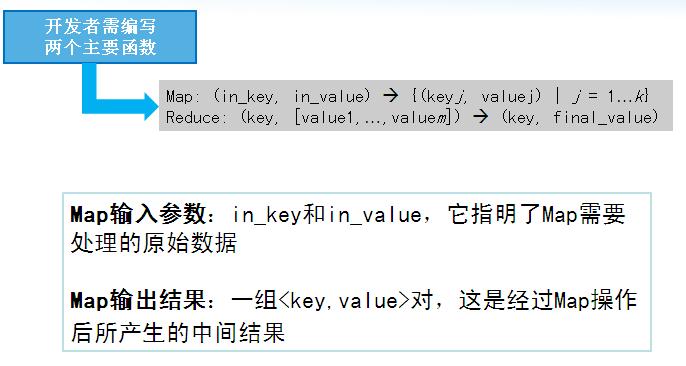
JefferyDean���һ���µij���ģ�ͣ���װ���д������ݴ����������ػ����㡢���ؾ����ϸ�ڣ����ṩ��һ����ǿ��Ľӿ������MapReduce
2�����ģ��
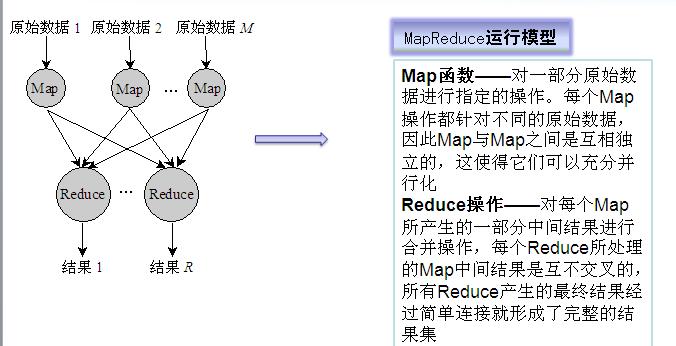
��ô��MapReduce����һ�������ı��ļ��и����ʳ��ִ�����Map���������ָ������Ҫ�����IJ������ݣ��ԡ�<���ı��е���ʼλ�ã���Ҫ���������ݳ���>����ʾ������Map�������γ�һ���м�����<���ʣ����ִ���>������Reduce���������м���������ͬ���ʳ��ֵĴ��������ۼӣ��õ�ÿ�������ܵij��ִ���3��ʵ�ֻ���
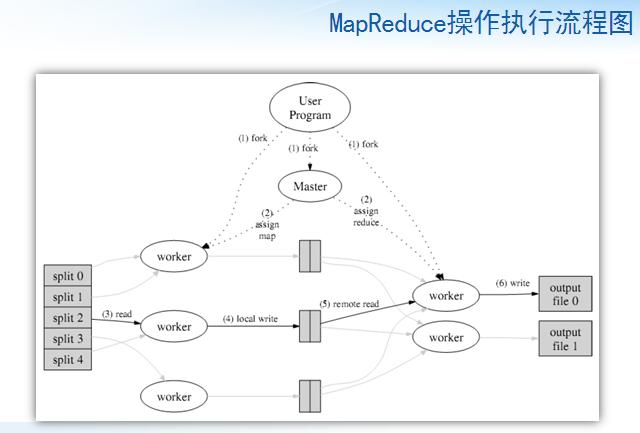
��������
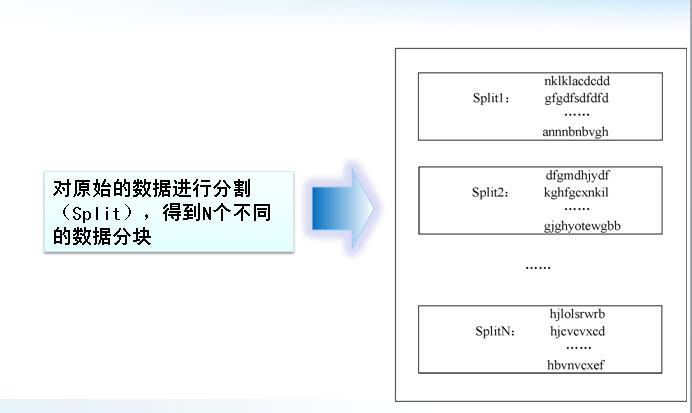
��1�������ļ��ֳ�M�飬ÿ����16M��64MB������ͨ�������������������ڼ�Ⱥ�Ļ�����ִ�з��ɴ�������
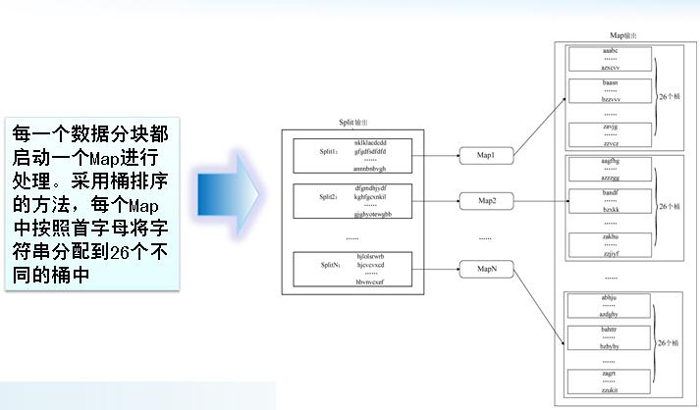
��2��M��Map�����R��Reduce������Ҫ���ɣ�Masterѡ�����Worker��������ЩMap��Reduce����
��3��Worker��ȡ�������������飬Map�����������м���<key,value>����ʱ���嵽�ڴ�
��4���м�����ʱд������Ӳ�̣�������������ֳ�R�������м����ڱ���Ӳ�̵�λ����Ϣ�������ͻ�Master��Ȼ��Master�������Щλ����Ϣ����ReduceWorker
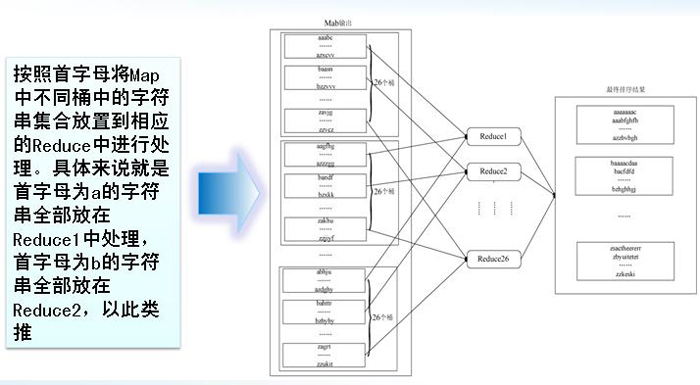
��5����Masterִ֪ͨ��Reduce��Worker�����м�<key,value>�Ե�λ��ʱ��������Զ�̹��̣���MapWorker�ı���Ӳ���϶�ȡ������м����ݡ���Reduce
Worker�������е��м����ݣ�����ʹ���м�key��������������ʹ��ͬkey��ֵ����һ��
��6��Reduce Worker����ÿһ��Ψһ�м�key���������е��������м����ݣ����Ұ�key����ص��м���ֵ���ϴ��ݸ��û������Reduce������Reduce�����Ľ��д��һ�����յ�����ļ�
��7�������е�Map�����Reduce������ɵ�ʱ��Master�����û�����ʱMapReduce�����û�����ĵ��õ��������Ӳ�̵�λ����Ϣ�������ͻ�Master��Ȼ��Master�������Щλ����Ϣ����ReduceWorker
��������������һ�����������ݣ�ÿ�����ݶ�����26����ĸ��ɵ��ַ�����ԭʼ�����ݼ�������ȫ����ģ�����ͨ��MapReduce�����������ʹ�������ֵ����أ�
��������ͨ�����ں����ֲ�ʽ���ݴ�����ܵ����ݴ�������
Google���Ƽ���ԭ����Ӧ��(�ֲ�ʽ������Chubby)
һ���ֲ�ʽ������
���죬Ҫ�Ӵ���Щ�������֪ʶ���ˣ���Ҳ�������漰����ʱ��������ʦǿ�������й�û�������ʸͽ������һ�顪�ֲ�ʽ�㷨��˵ʵ������鿴�������ˣ������ڻ�����˵�Լ��˶���һ�밡����
Chubby
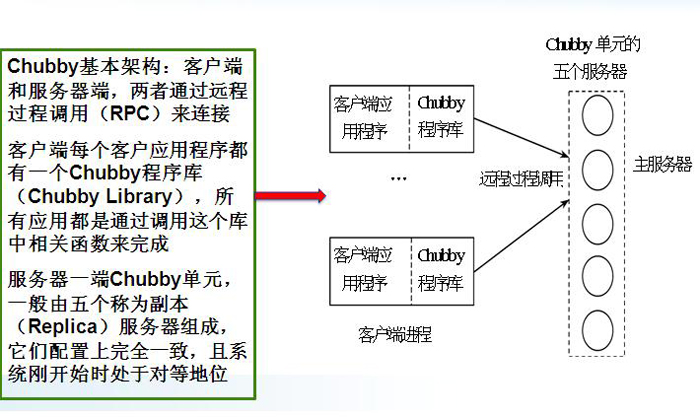
- Google��Ƶ��ṩ������������(???)��һ���ļ�ϵͳ������������Ϸֲ�ʽϵͳ������˷ֲ���һ��������
����һ�ֽ����Ե���(���ſ�����UNIX�����¸���̡����˶Խ����Ե���������ʲ���İ��)��������һ��ǿ���Ե��������и���������
- GFSʹ��Chubbyѡȡһ��GFS��������
- Bigtableʹ��Chubbyָ��һ���������������֡�����������ص��ӱ�������
- Chubby��������Ϊһ���ȶ��Ĵ洢ϵͳ�洢����Ԫ�������ڵ�С����
- Google�ڲ���ʹ��Chubby�������ַ���Name Server��
����һ�£�Ҫ�ڴ��ģ��Ⱥ�������£���֤����ָ������ݵ�һ���ԣ������ڳ�ʼ״̬��ͬ����£�Ҫ��������յ�ͬ����ָͬ�������״̬һ�£�������ʲô�������ѣ�������Ҳ�����Ƿֲ�ʽ�㷨Ҫ�������õľ��أ��ܶ�ʱ����Ƶ��㷨���������ܻ���ʮȫʮ����Chubby�м�Ҫ�õ�Paxos�㷨
1��Paxos�㷨
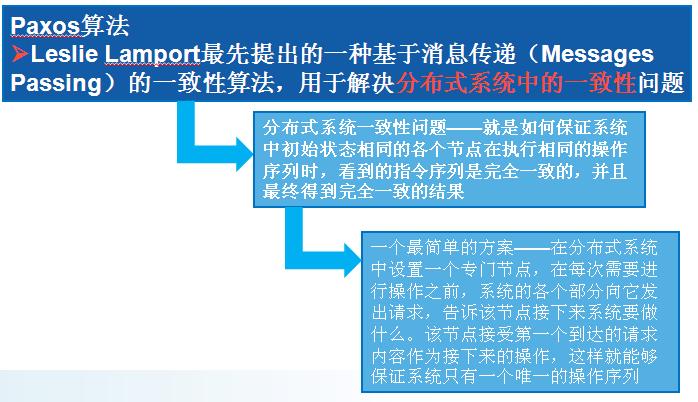
�����룺�÷�������ʲôȱ�ݣ�������
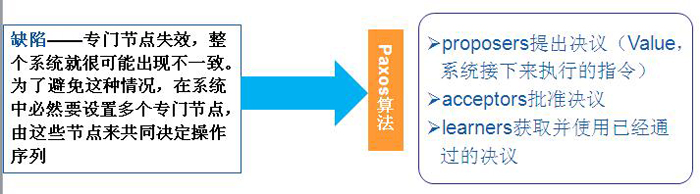
��ͼ��������������֤���ݵ�һ����:
��1������ֻ�б�proposers����������
��2��ÿ��ֻ��һ������
��3��ֻ�о���ȷ��������learners���ܻ�ȡ�������
ϵͳ��Լ��������
p1:ÿ��acceptorֻ�������õ��ĵ�һ������
p1����ÿ�����Խ��յ�������飬Ϊ���֣���ÿ��������б�ţ���õ��ľ�����Ҫ�����ȵ��ı�ţ�p1���Ǻ��걸!!(??һ����������ǣ�����ÿ����㣬���յ�����ν��һ������Ƿ���һ������)
P2��һ��ij������ͨ����֮��ͨ���ľ������þ��鱣��һ��
P1+P2����>P2a:һ��ij������V�õ�ͨ����֮���κ�acceptor�����ľ��������V
P2a��P1����ì�ܵ�!(�ҵ������ǣ��п������V����ij������յ��ĵ�һ������)
P2a������P2b:һ��ij������V�õ�ͨ����֮���κ�proposer������ľ��������V
P1��P2b��֤������2�����˴�֮�䲻����ì�ܡ�����P2b����ͨ��һ�ּ����ֶ���ʵ��������������һ���̺�P2b��Լ��P2c
P2b������P2c:���һ�����Ϊn�������ֵv����ô����һ���������ɡ���Ҫô������û��˭�������С��n���κ����Ҫô���ǽ��е����һ��������ֵv
����ͨ���������Σ�
���Σ�proposersѡ��һ����������ı����Ϊn��Ȼ��������acceptors�е�һ���������ɡ���Acceptors�յ��������ı�Ŵ������Ѿ��ظ���������Ϣ����acceptors���Լ��ϴε����ظ���proposers����������С��n���
����ô���������ʣ����С�����Ѿ��ظ���������Ϣ�أ����˼��֮���㷨�����̾��и�ӡ�����ƺ�����һ�룬���м���ӳٵ����Ǹ����⣬����������㷨����δŪ��������
���Σ���proposers���յ�acceptors �е�����������ɡ��Ļظ�����ظ������acceptors����accept�����ڷ���acceptorsһ����Լ�������£�acceptors�յ�accept��������������
���һ���������㷨��Ϊ�˼��پ��鷢�������е���Ϣ����acceptors�����ͨ���ľ��鷢��learners��һ���Ӽ���Ȼ��������Ӽ��е�learnersȥ֪ͨ����������learners��
����������������proposer����������¶�ת�����һ����Ÿ���������ô�Ϳ��������������ʱ��Ҫѡ�ٳ�һ��president��������
president����
2��Chubby��ϵͳ���

Chubby�л�������һЩ�µĹ������ԣ����������Ҫ�ǿ��ǵ����¼�������:
1�������߳��ں��ٿ���ϵͳ��һ���ԣ������ſ������У��������Խ��Խ���ء���������������Ա�֤ԭ��ϵͳ�ܹ����ᷢ���ı䣬��ʹ�ú�����ܿ�����Ҫ��ϵͳ�ܹ���������ȵĸĶ�
2��ϵͳ�кܶ��¼���������Ҫ��֪�����û��ͷ�������ʹ��һ�������ļ�ϵͳ����������Խ���Щ�䶯д���ļ��С�����Ҫ���û��ͷ�����ֱ�ӷ�����Щ�ļ����ɣ����������ϵͳ���֮���¼�ͨ�Ŵ���ϵͳ�����½�
3���������Ŀ����ӿ����ױ������߽��ܡ���Ȼ�ڷֲ�ʽϵͳ������ʹ�û��кܴ�IJ�ͬ�����Ǻ�һ�����㷨��ȣ�����Ȼ������Ŀ���������֪
Paxos�㷨ʵ�ֹ�������Ҫһ���������ɡ���ij��ֵ���һ�£������Ͼ��Ƿֲ�ʽϵͳ�г�����quorum���ƣ�Ϊ��֤ϵͳ�߿����ԣ���Ҫ����̨��������ʹ�õ���������Ļ�һ̨����Ҳ�ܱ�֤���ָ߿�����
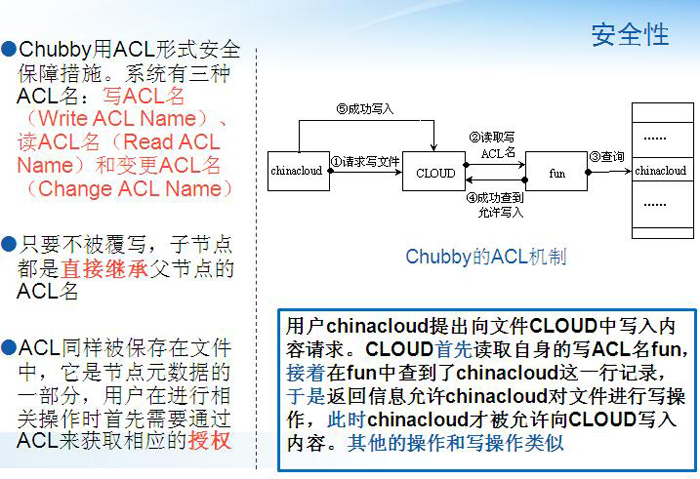
Chubby��ƹ�����һЩϸ������ֵ�ù�ע��
��Chubbyϵͳ�в����˽����Ե�����û�в���ǿ���Ե��������ߵĸ������������û�����ij�����������ļ�ʱ�������Ե���������ֹ���ʣ���ǿ���Ե��������ֹ���ʣ�ʵ��������Ϊ�˷���ϵͳ���֮�����Ϣ����
���⣬Chubby�������˴����ȣ�Coarse-Grained���������û�в���ϸ���ȣ�Fine-Grained�����������ߵIJ������ڳ�������ʱ�䣬ϸ���ȵ�������ʱ��ܶ�
3��Chubby�е�Paxos�㷨
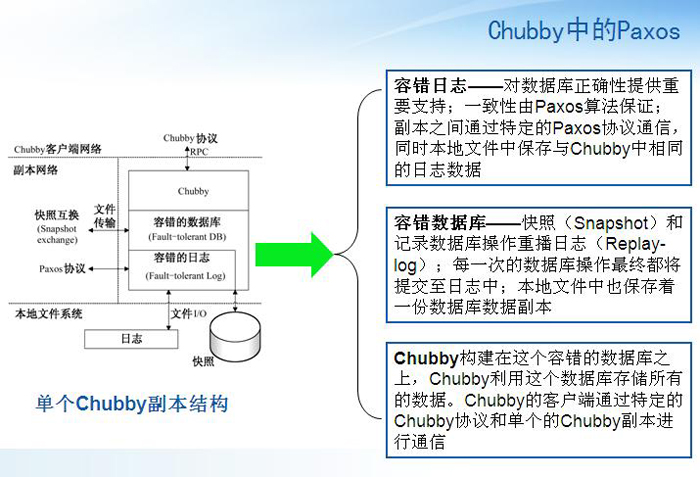
(�������ʣ��������������ƺ���������ǵ������ǡ�����������������ϵͳ��ÿ�����ڱ������ݺ�ָ���һ���ԣ�ֻ���������־��һ�£���ô˵�������һ�£���)
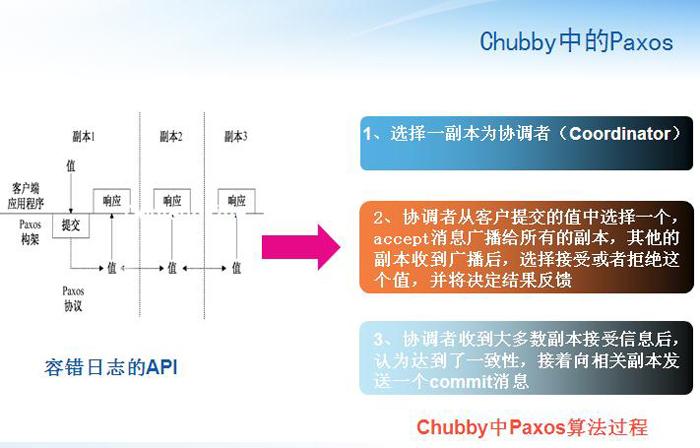
Chubby����߽����Paxos�����ֽ�����ƣ���Э����ָ����Ż�����Э���߿���ѡ���ֵFָ����ŵķ���
�C��1����һ����n������ϵͳ�У�Ϊÿ����������һ��id ������ 0��ir��n-1��������ţ�����k�ij�ʼֵΪ0
("������ţ�����k�ij�ʼֵΪ0 "��仰����д���е����⣬����û����)
�C��2��ij���������ΪЭ����֮�������ݹ�������һ��������ǰ����Ÿ������ţ�ʵ���Ͼ������k��ֵ��������������ͨ��propose��Ϣ�㲥���������еĸ���
�C��3��������ܵ��㲥�ĸ������ָ���ű�����ǰ��������Ŷ��������㲥�ĸ�������һ��promise��Ϣ�����ҳ�ŵ���ٽ��ܾɵ�Э���߷��͵���Ϣ����������������������promise��Ϣ�����µ�Э���߾Ͳ�����F����Э���߿���ѡ���ֵ
�CPaxosǿ���µ�Э���߱���ѡ���ǰ����ͬ��ֵ
Chubby����һ����Ҫ�Ż������ϵͳЧ�ʡ���ѡ��ijһ��������ΪЭ����֮��ͳ��ڲ��䣬��ʱЭ���߾ͱ���Ϊ����������Master��
F�ͻ��˵���������������������ɣ�Chubby��֤��һ��ʱ�������ҽ���һ���������������ʱ��ͳ�Ϊ����������Լ�ڣ�Master
Lease��
F�ͻ�����Ҫȷ������������λ�ã�����DNS����һ������������λ�������������ĸ������Ը�����������Ӧ
Chubby����Paxos������δ�ἰ��һЩ����ϸ�ڽ����˲��䣬����Chubby��ʵ���ǻ���Paxos�����似���ֶθ��ӵķḻ��������ʵ����
4��Chubby�ļ�ϵͳ
Chubbyϵͳ�����Ͼ���һ���ֲ�ʽ�ġ��洢����С�ļ����ļ�ϵͳ�������еIJ����������ļ��Ļ��������
Chubby��õ��������У�ÿһ���ļ��ʹ���һ�������û�ͨ�����رպͶ�ȡ�ļ�����ȡ������Shared�������ռ��Exclusive����
ѡ���������������У����������ķ�������ͬʱ�����ij���ļ���������ס���ļ�
�ɹ�������ķ������Զ���Ϊ���������������ַд������ļ��У��Ա��������������û����Ի�֪���������ĵ�ַ��Ϣ
Chubby���ļ�ϵͳ��UNIX����
F�������ļ�����/ls/foo/wombat/pouch���У�ls����lock
service����������Chubby�ļ�ϵͳ�Ĺ���ǰ��foo��ij����Ԫ�����ƣ�/wombat/pouch����foo�����Ԫ�ϵ��ļ�Ŀ¼�����ļ���
Google��Chubby����һЩ��UNIX��ͬ�ĸı�
F����Chubby��֧���ڲ��ļ����ƶ�������¼�ļ���������ʱ�䣻������Chubby�в�û�з������ӣ�Symbolic
Link���ֽ������ӣ�������Windowsϵͳ�еĿ�ݷ�ʽ����Ӳ���ӣ�HardLink�������ڱ������ĸ���
�ھ���ʵ��ʱ���ļ�ϵͳ������ڵ���ɣ���Ϊ�����ͺ���ʱ�ͣ�ÿ���ڵ����һ���ļ���Ŀ¼���ڵ��б����Ű���ACL��Access
Control List�����ʿ����б������ڵĶ���ϵͳԪ���� o


5��ͨ��Э��
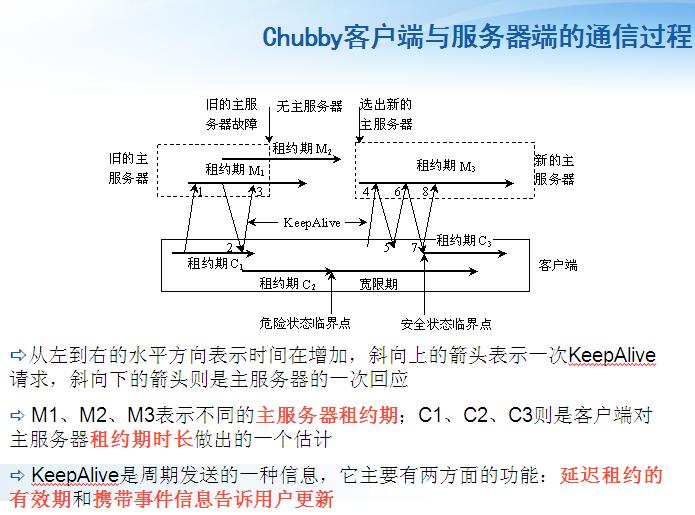
���ϴ���
�ͻ�����Լ����
- �ͻ�����������������һ��KeepAlive������ͼ1��
- �������Ҫ֪ͨ���¼�ʱ����������������������Ӧ������ȵ��ͻ��˵���Լ��C1�������ʱ���������Ӧ��ͼ2��������������������Լ��ΪM2
- �ͻ��˽ӵ���Ӧ����Ϊ�����������Դ��ڻ�Ծ״̬�����ǽ���Լ�ڸ���ΪC2�����̷����µ�KeepAlive����ͼ3��
- �������ڣ��ͻ��˲������̶Ͽ�����������˵���ϵ�����Dz��ϵ���̽ѯ�������ӵ��ͻ��˵ĵ�һ��KeepAlive����ͼ4��ʱ��ܾ���ͼ5��
- �ͻ��������������ܾ���ʹ���¼�Ԫ��������KeepAlive����ͼ6��
- �µ������������������������������Ӧ��ͼ7��
����ͻ��˽��յ������Ӧ��ʱ���Դ��ڿ������ڣ�ϵͳ��ָ�����ȫ״̬����Լ�ڸ���ΪC3������ڿ�����δ�ӵ�������������ػ�Ӧ���ͻ�����ֹ��ǰ�ĻỰ
������������
��������¾ɵ������������ֹ��Ϻ�ϵͳ��ܿ��ѡ�ٳ��µ�������������ѡ����Ҫ�������¾Ÿ����裺
��1������һ���µļ�Ԫ���Ա���ͻ���ͨ��ʱʹ�ã����ܱ�֤��ǰ�������������ش�����Ծɵ���������������
��2��ֻ������������λ����ص���Ϣ���������Ự��ص���Ϣ
��3�����������Ự����������ڲ����ݽṹ
��4�������ͻ��˷���KeepAlive�������������Ự��ص���Ϣ
��5����ÿ���Ự����һ�������¼�����ʹ���еĿͻ�����ջ���
��6���ȴ�ֱ�����еĻỰ���յ������¼���Ự��ֹ
��7����ʼ����ִ�����еIJ���
��8������ͻ���ʹ���˾ɵľ������ҪΪ�����¹����µľ��
��9��һ��ʱ��κ�1���ӣ���ɾ��û�б�������ʱ�ļ���
���������һ�����ڿ�������˳����ɣ����û�����о����κι��ϵķ�����Ҳ����˵�¾������������滻�����û���˵�����ģ��û��о����Ľ�����һ���ӳ�
ϵͳʵ��ʱ��Chubby��ʹ����һ���Կͻ��˻��棨Consistent
Client-Side Caching����������������Ŀ���Ǽ���ͨ��ѹ��������ͨ��Ƶ��
F�ڿͻ��˱���һ���͵�Ԫ������һ�µı��ػ��棬��Ҫʱ�ͻ�����ֱ�Ӵӻ�����ȡ�����ݶ������ٺ���������ͨ��
F��ij���ļ����ݻ���Ԫ������Ҫ��ʱ�������������Ƚ������������Ȼ��ͨ����ѯ������������ά����һ�������������ĵ����ݽ����˻�������пͻ��˷���һ����Ч��־��Invalidation��F�ͻ����յ������Ч��־��᷵��һ��ȷ�ϣ�Acknowledge���������������յ����е�ȷ�Ϻ�Ž����������������
����������̵�ִ��Ч�ʷdz��ߣ�������Ҫ����һ����Ч��־���ɣ���Ϊ����û�з���ȷ�ϵĽڵ㣬��������ֱ����Ϊ����δ����
6����ȷ��������
һ����
ÿ��Chubby��Ԫ�������������ɵģ��������������Ҫѡ�ٲ���һ����������������ѡ�ٱ����Ͼ���һ��һ�������⡣ʵ��ִ�й����У�Chubbyʹ��Paxos�㷨�����
��������������ͻ��˵����ж�д����������������������ɵ�
a�������ܼ��ͻ�ֱ�Ӵ����������϶�ȡ�������ݼ���
aд�����ͻ��漰����һ���Ե����⣻Ϊ�˱�֤�ͻ���д�����ܹ�ͬ�������еķ������ϣ�ϵͳ�ٴ�������Paxos�㷨
�����Ż�
Ϊ����ϵͳ�߿���չ�ԣ�ChubbyĿǰ�Ѿ���ȡ��һЩ��ʩ�����������������Ĭ�ϵ���Լ�ڡ�ʹ��Э��ת������ChubbyЭ��ת���ɽϼ�Э�顢�ͻ���һ���Ի���ȣ�����֮�⣬Google�Ĺ���ʦ�ǻ�����ʹ�ô�����Proxy���ͷ�����Partition������
a�������Լ���������������KeepAlive�Լ�����������ķ��������أ������������ܼ���д����������ͨ����
aʹ�÷��������Ļ����Խ�һ����Ԫ�������ռ䣨NameSpace�����ֳ�N�ݡ����������Ŀ����ͨ���⣬�ֵķ��������Զ��Եش�����������ͨ���������Լ��ٸ��������ϵĶ�дͨ�����������ܼ���KeepAlive�����ͨ����
Google���Ƽ���ԭ����Ӧ��(�ֲ�ʽ�ṹ�����ݱ�BigTable)
1����ƶ�����Ŀ��
(1)��ƶ���
��Ҫ�洢����������ࣺGoogleĿǰ���ڿ��ŵķ���ܶ࣬��Ҫ��������������Ҳ�dz��ࡣ����URL����ҳ���ݡ��û��ĸ��Ի��������ڵ����ݶ���Google��Ҫ����������
�����ķ�������Google������Ŀǰ�������æ��ϵͳ����ÿʱÿ�̴����Ŀͻ�����������������ͨ��ϵͳ���������ܵ�
�������ݿ�������Google������һ���������������ݿ�������۵�����ͨ���ԣ�����������Google�Ŀ��̷���Ҫ����һ������ڵײ�ϵͳ����ȫ�ƿػ�����ڵ�ϵͳά����������������ı���
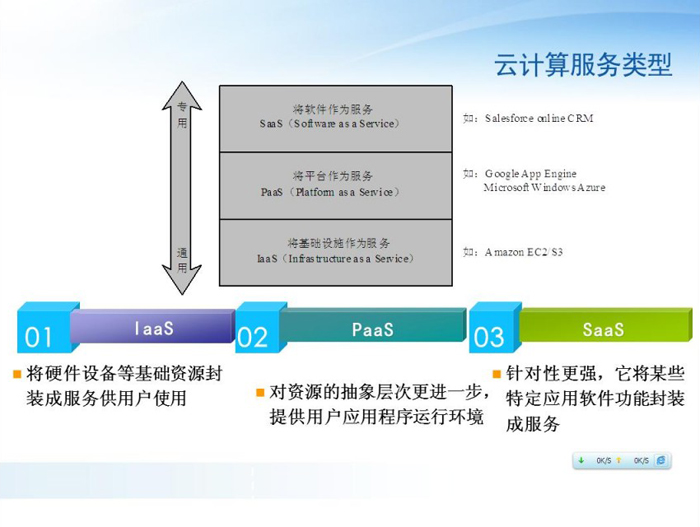
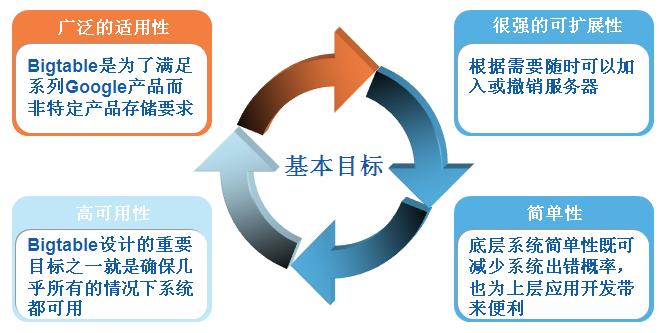
(2)����Ŀ��
2������ģ��
Bigtable��һ���ֲ�ʽ��άӳ��������е�����ͨ��һ���йؼ��֣�Row
Key����һ���йؼ��֣�Column Key���Լ�һ��ʱ�����Time Stamp����������
Bigtable�Դ洢�����е����ݲ����κν�����һ�ɿ����ַ���
Bigtable�Ĵ洢�����Ա�ʾΪ�� (row:string,column:string,
time:int64)��string
��
- Bigtable���йؼ��ֿ�����������ַ��������Ǵ�С���ܳ���64KB��Bigtable�ʹ�ͳ�Ĺ�ϵ�����ݿ��кܴ�ͬ������֧��һ�������ϵ������ܱ�֤�����еĶ�д��������ԭ���ԣ�Atomic��
- �������ݶ��Ǹ����йؼ��ֽ�������ģ�����ʹ�õ��Ǵʵ���
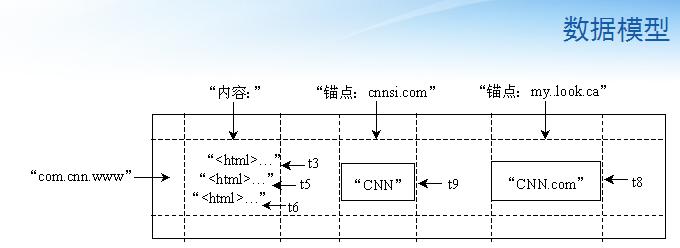
- һ������ʵ��������com.cnn.www����һ���йؼ��֡���ֱ�Ӵ洢��ҳ��ַ�����䵹����Bigtable��һ��������ơ����������ٻ�������������ô�
ͬһ��ַ�����ҳ�ᱻ�洢�ڱ��е�����λ�ã��������û����Һͷ������ű�������ѹ�������Դ�����ѹ����
��
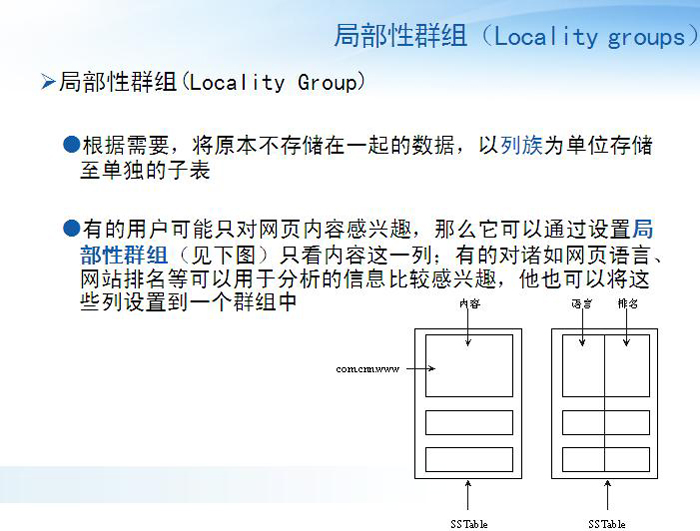
Bigtable�����Ǽش洢���е��йؼ��֣����ǽ�����֯����ν�����壨Column
Family����ÿ�����е����ݶ�����ͬһ�����ͣ�����ͬ������ݻᱻѹ����һ�𱣴档����������ĸ���֮���йؼ��־Ͳ�������������������壺
���������ʣ�family��qualifier��
�������������壬�������������ѡ��
ͼ�У����ݣ�Contents����ê�㣨Anchor�����Dz�ͬ���塣��cnnsi.com��my.look.ca����ê�����в�ͬ������
��ͬʱҲ��Bigtable�з��ʿ��ƣ�Access Control��������Ԫ��Ҳ����˵����Ȩ��������������һ�����Ͻ��е�
ʱ���
Google�ĺܶ���������ҳ�������û��ĸ��Ի����õȶ���Ҫ���治ͬʱ������ݣ���Щ��ͬ�����ݰ汾����ͨ��ʱ��������֡�ͼ2�������е�t3��t5��t6�������б�������t3��t5��t6������ʱ���ȡ����ҳ��Bigtable�е�ʱ�����64λ������������ĸ�ֵ��ʽ���Բ�ȡϵͳĬ�ϵķ�ʽ��Ҳ�����û����ж���Ϊ�˼�ͬ�汾�����ݹ�����BigtableĿǰ�ṩ���������ã�һ���DZ��������N����ͬ�汾��ͼ������ģ�Ͳ�ȡ�ľ������ַ��������������µ������汾���ݡ���һ�־��DZ�����ʱ���ڵ����в�ͬ�汾��������Ա������10������в�ͬ�汾���ݡ�ʧЧ�İ汾������Bigtable���������ջ����Զ�����
3��ϵͳ�ܹ�
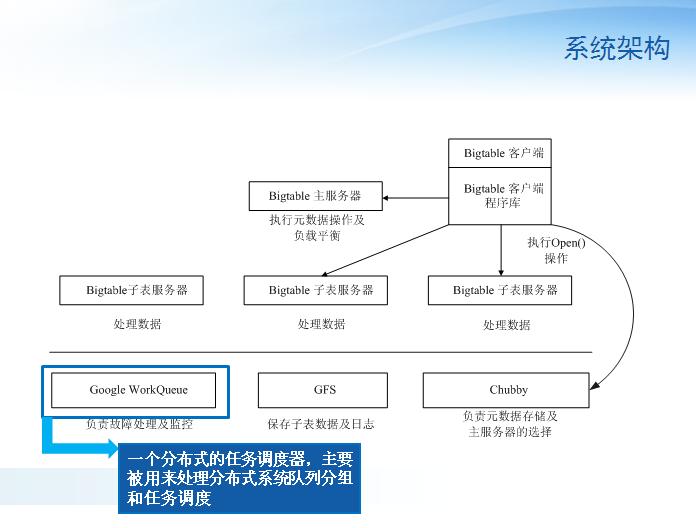
��Bigtable��Chubby��Ҫ�����¼������ã�
��1��ѡȡ����֤ͬһʱ����ֻ��һ������������MasterServer��
��2����ȡ�ӱ���λ����Ϣ
��3������Bigtable��ģʽ��Ϣ�����ʿ����б�
������Bigtable��ʵ��ִ�й����У�Google��MapReduce��SawzallҲ����������������
4����������
��һ�����ӱ�����ʱ����������ͨ��һ���������������һ���ռ��㹻���ӱ��������������±������ϲ��Լ��ϴ��ӱ��ķ��Ѷ������һ���������ӱ�������ǰ�����֣������������Զ��������ϴ��ӱ��ķ��������ӷ�������ɵģ��������������������Զ���������ڷָ����֮���ӷ�������Ҫ��������һ��֪ͨ
����ϵͳ���֮����Ҫ���ܴﵽ���õ���չ��(��ȻҪ������չ�ԣ���ô�������µķ������ӽ���ʱ������ü�ʱ֪��)��������������������ӱ���������״̬���м�أ��Ա㼰ʱ���������ļ������
Bigtable�������������ӱ��������ļ����ͨ��Chubby��ɵġ����ӱ��������ڳ�ʼ��ʱ�����Chubby�еõ�һ����ռ����ͨ�����ַ�ʽ�����ӱ�������������Ϣ��������Chubby��һ����Ϊ������Ŀ¼��ServerDirectory��������Ŀ¼֮��
���������ᶨ������ѯ�ʶ�ռ����״̬������ӱ�������������ʧ��û�л�Ӧ�����ʱ�������������
Ҫô��Chubby���������⣨��Ȼ���ָ��ʺ�С������ȷ���ڣ�Google�Լ�Ҳ������ز��ԣ�
Ҫô���ӱ��������������������⡣�Դ��������������Լ����Ի�ȡ�����ռ�������ʧ��˵��Chubby����������⣬��ȴ��ָ�������ɹ���˵��Chubby�������ö��ӱ���������������������
����״̬���ʱ����ij���ӱ��������ϸ��ع���ʱ�������������Զ�������и��ؾ������
����ϵͳ���ֹ�����һ�ֳ�̬��������ÿ�������������趨��һ���Ựʱ������ơ���ij������������ʱ�˳�����ϵͳ�ͻ�ָ��һ���µ������������������������������Ҫ���������ĸ����裺
��1����Chubby�л�ȡһ����ռ����ȷ��ͬһʱ��ֻ��һ����������
��2��ɨ�������Ŀ¼������Ŀǰ��Ծ���ӱ�������
��3�������еĻ�Ծ�ӱ�������ȡ����ϵ�Ա��˽������ӱ��ķ������
��4��ɨ��Ԫ���ݱ�������δ������ӱ���������䵽�����ӱ�������
���Ԫ���ݱ�δ���䣬��������Ҫ�����ӱ���Root Tablet������δ������ӱ��С����ڸ��ӱ���������������Ԫ�����ӱ�����Ϣ��ȷ����ɨ���ܹ���������δ������ӱ�
5���ӱ�������
����һ��BigTable��Ҫ�洢�������ݣ����������ò����ֳɶ��Tablet����ÿ��Tablet���Ḻ��һ����Χ���С����Ҵ洢�ڶ���������ϡ�
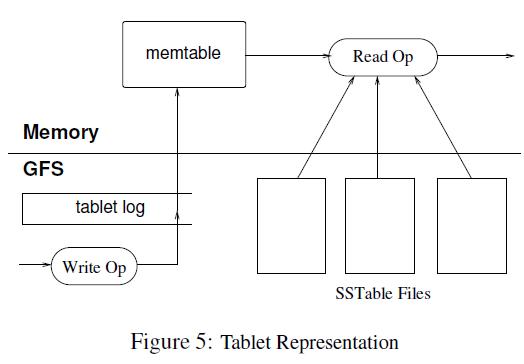
SSTable���ӱ������ṹ
SSTable��Sorted String Table����д�����ռ������洢��/ֵ��(Key����Value)�ַ������������Dz��ɱ䶯�ģ�Ҳ����д��֮��ֻ�ܽ�����¸������������ֱ�Ӷ�������ģ�������Ϊ����ϵͳ��ִ�д������ó���˳����ʣ�������������ʡ�
SSTable���ӱ������ṹ
�ӱ�ʵ�����
Bigtable�е���־�ļ���һ�ֹ�����־��ÿ���ӱ��������Ͻ�����һ����־�ļ���ij���ӱ���־ֻ�����������־��һ��Ƭ�Ρ��������ʡ�����Ŀռ䣬���ڻָ�ʱȴ��һ�����Ѷ�
GoogleΪ�˱�������������֣�����־����һЩ�Ľ���Bigtable�涨����־�����ݰ��ռ�ֵ��������������ͬ���ӱ�������������������ȡ��־�ļ���
һ����˵ÿ���ӱ��Ĵ�С��100MB��200MB֮�䡣ÿ���ӱ��������ϱ�����ӱ��������ԴӼ�ʮ����ǧ���ȣ�ͨ���������100������
���������⣺�ɴˣ�һ���ӱ�����������һ����־�ļ�����ͬʱ��ÿ���ӱ���Ҳ���Լ�����־�����������ڷ���������־�ļ��е�һ��Ƭ�Σ�
SSTable���Ľṹ
SSTable�����ݱ����ֳ�һ�����Ŀ飨Block����ÿ����Ĵ�С�ǿ������õģ�һ��Ϊ64KB
��SSTable�Ľ�β��һ��������Index����������������˿��λ����Ϣ����SSTable��ʱ��������ᱻ���ؽ��ڴ棬�û��ڲ���ij����ʱ�������ڴ��в��ҿ��λ����Ϣ��Ȼ����Ӳ����ֱ���ҵ������
����ÿ��SSTableһ�㶼���Ǻܴ��û�������ѡ����������ؽ��ڴ棬�����������������
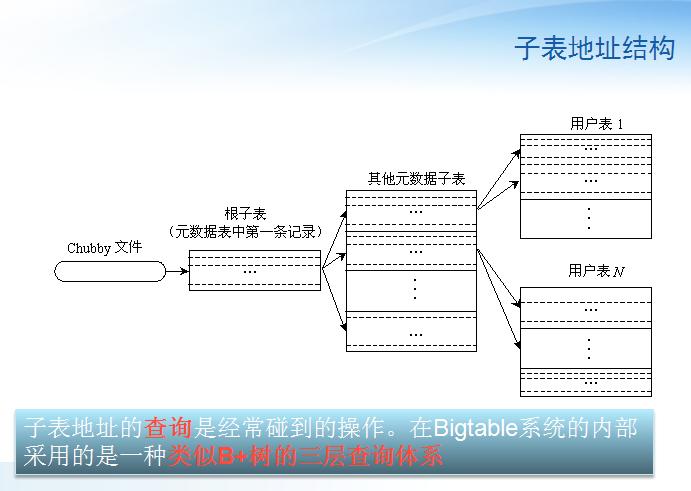
2�����ӱ���ַ������¼��Ԫ���ݱ��У�Ԫ���ݱ�Ҳ����һ������Ԫ�����ӱ���Metadata
tablet�����
2���ӱ���Ԫ���ݱ���һ���Ƚ�������ӱ���������Ԫ���ݱ��ĵ�һ����¼��Ҳ����������Ԫ�����ӱ��ĵ�ַ��ͬʱChubby�е�һ���ļ�Ҳ�洢��������ӱ�����Ϣ��
2��ѯʱ�����ȴ�Chubby����ȡ������ӱ��ĵ�ַ��������ȡ�����Ԫ�����ӱ���λ�ã����Ϳ��Դ�Ԫ�����ӱ����ҵ�����ѯ���ӱ���������Щ�ӱ���Ԫ����֮�⣬Ԫ���ݱ��л�����������һЩ�����ڵ��Ժͷ�������Ϣ�������¼���־��
Ϊ�˼��ٷ��ʿ�������߿ͻ�����Ч�ʣ�Bigtableʹ���˻��棨Cache����Ԥȡ��Prefetch������
�ӱ��ĵ�ַ��Ϣ�������ڿͻ��ˣ��ͻ���Ѱַʱֱ�Ӹ��ݻ�����Ϣ���в��ҡ�һ�����ֻ���Ϊ�ջ���Ϣ��ʱ��������ͻ��˾���Ҫ����ͼʾ��ʽ�������������ͨ�ţ�Network
Round-trips������Ѱַ���ڻ���Ϊ�յ��������Ҫ������������ͨ�š�����������Ϣ�ǹ�ʱ�ģ�����Ҫ������������ͨ�š�������������ȷ����Ϣ�ǹ�ʱ�ģ�����������ȡ�µĵ�ַ
Ԥȡ������ÿ�η���Ԫ���ݱ�ʱ��������ȡ������ӱ�Ԫ���ݣ����Ƕ�ȡ����ӱ���Ԫ���ݣ������´���Ҫʱ�Ͳ����ٴη���Ԫ���ݱ�
�ӱ����ݴ洢��Ԫ����
Bigtable�����ݴ洢���ֳ����飺���µ����ݴ洢���ڴ���һ����Ϊ�ڴ����Memtable����������������������SSTable��ʽ������GFS��
д������Write Op�������Ȳ�ѯChubby�б���ķ��ʿ����б�ȷ���û�����ӦдȨ�ޣ�ͨ����֤֮��д����������ȱ��������ύ��־��Commit
Log���С��ύ��־����������¼��RedoRecord������ʽ�����������һϵ�����ݸ��ģ���Щ������¼���ӱ����лָ�ʱ������ϵͳ�ṩ����ɵĸ�����Ϣ��
��������Read Op��������ͨ����֤��֮���������Ҫ����ڴ����SSTable�ļ������У���Ϊ�ڴ����SSTable�ж�����������
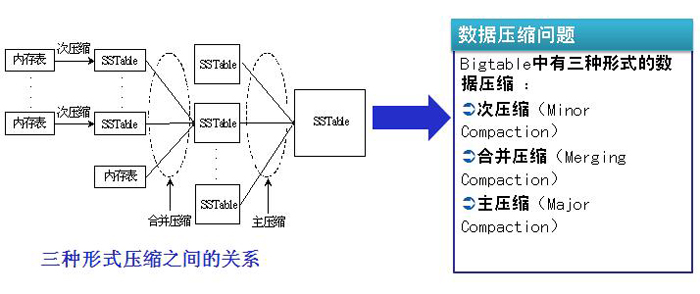
ÿһ�ξɵ��ڴ��ֹͣʹ��ʱ�������һ����ѹ��������������һ��SSTable�������ϵͳ��ֻ������ѹ���Ļ���SSTable�������ͻ������Ƶ�������ȥ
����Bigtable�У�������ʵ���ϱ�д��������Ҫ�����Bigtable�ᶨ�ڵ�ִ��һ�κϲ�ѹ���IJ�������һЩ���е�SSTable�����е��ڴ��һ������һ��ѹ��
��ѹ����ʵ�Ǻϲ�ѹ����һ�֣�ֻ�����������е�SSTableһ����ѹ����һ�����SSTable�ļ�����ѹ��Ҳ�Ƕ���ִ�У�ִ��һ����ѹ��֮����Ա�֤�����еı�ѹ�����ݳ���ɾ��
ѹ��
ѹ��������Ч�ؽ�ʡ�ռ䣬Bigtable�е�ѹ����Ӧ���ںܶೡ��
F����ѹ�����Ա����ڹ��ɾֲ���Ⱥ���SSTable�У�����ѡ���Ƿ�Ը��˵ľֲ���Ⱥ���SSTable����ѹ��������ѹ���Ƕ�ÿ���ֲ���Ⱥ��������У���Ȼ���˷�һЩ�ռ䣬��������Ҫ��ʱ��ѹ�ٶȷdz���
ͨ������£��û����Բ�������ѹ���ķ�ʽ��
F��һ������Bentley & McIlroy��ʽ��BMDiff���ڴ��ɨ�贰�ڽ������ij�������ѹ�����ڶ�����ȡZippy�������п���ѹ��������һ��16KB��С��ɨ�贰����Ѱ���ظ����ݣ�������̷dz���
ѹ����������������ӱ��Ļָ��ٶȣ���ij���ӱ�������ֹͣʹ�ú���Ҫ���������е��ӱ�������һ���ӱ���������ת��ǰ����ѹ������һ��ѹ���������ύ��־��δѹ��״̬���ļ���ʽת��ǰ��Ҫ����һ��ѹ������Ҫ�ǽ���һ��ѹ����������δѹ���ռ����ѹ��
��¡��������Bloom Filter��
�Ͷ١���¡��1970������ģ�ʵ��������һ���ܳ��Ķ�����������һϵ�����ӳ�亯�����ڶ�������ȷ���ӱ���λ��ʱ�dz�����
F���ƣ��ٶȿ죬ʡ�ռ䡣��������һ�����ĺô����������Ὣһ�����ڵ��ӱ��ж�Ϊ������
Fȱ�㣺��ijЩ��������Ὣ�����ڵ��ӱ��ж�Ϊ���ڡ���������������ֵĸ��ʷdz�С�����������ľ�ô�������ȱ���ǿ������ܵ�
Ŀǰ����Google Analytics��Google Earth�����Ի�������Orkut��RRS�Ķ������ڼ�ʮ����Ŀ��ʹ��Bigtable����ЩӦ�ö�Bigtable��Ҫ���Լ�ʹ�õļ�Ⱥ����������������ͬ������ʵ������������Bigtable��ȫ����������Щ��ͬ�����Ӧ�ã�����һ�ж��������������Ĺ����Լ�ǡ���ļ���ѡ�� |


