1ЁЂHamaИХТл
НЈСЂдкHadoopЩЯЕФЗжВМЪНВЂааМЦЫуФЃаЭЁЃ
Лљгк Map/Reduce КЭ Bulk Synchronous ЕФЪЕЯжПђМмЁЃ
дЫааЛЗОГашвЊЙиСЊ ZookeeperЁЂHBaseЁЂHDFS зщМўЁЃ
МЏШКЛЗОГжаЕФЯЕЭГМмЙЙгЩ BSPMaster/GroomServer(Computation
Engine)ЁЂZookeeper(Distributed Locking)ЁЂHDFS/HBase(Storage
Systems) ет3ДѓПщзщГЩЁЃ
Hamaжага2ИіжївЊЕФФЃаЭ:
ЈC ОиеѓМЦЫу(Matrix package)
ЈC УцЯђЭММЦЫу(Graph package)
HamaЯюФПЦ№дДгкдк2008Фъ5дТ19Ше
HamaжївЊГЩдБ Edward J. Yoon (ИпРіАєзг)
HamaЯюФПЕФзюДѓжЇГжеп КЋЙњNHNЛЅСЊЭјЫбЫїв§ЧцвдМАЭјТчгЮЯЗЙЋЫОЃЌУВЫЦжаЙњЕФАйЖШЃЌЯъМћетРяЁЃ
2ЁЂHamaНщЩм
2008Фъ5дТHamaБЛЪгЮЊApacheжкЖрЯюФПжавЛИіБЛЗѕЛЏЕФЯюФПЃЌФПЧА(2010Фъ12дТ)дкHamaЕФЯюФПЭјеОЩЯЛЙУЛгае§ЪНЕФreleaseАцБОЃЌзїЮЊHadoopЯюФПжаЕФвЛИізгЯюФПЃЌBSPФЃаЭЪЧHamaМЦЫуЕФКЫаФЃЌВЂЧвЪЕЯжСЫЗжВМЪНЕФМЦЫуПђМмЃЌВЩгУетИіПђМмПЩвдгУгкОиеѓМЦЫу(matrix)КЭУцЯђЭММЦЫу(grah)ЁЂЭјТчМЦЫу(network)ЁЃ
ЮвЕФЗЯЛА:
- ШчЙћвЊЩюШыСЫНтЕН HamaжаВЩгУЕНЕФММЪѕЬхЯЕЃЌашвЊШЅдФЖСвЛаЉBSPЁЂMPIЁЂPregelЕШЯрЙизЪСЯЃЌПЩвдгажњгкЖдHamaЯюФПЕФСЫНтЁЃ
- ПДРДApacheЛљН№ЛсЖдGoogleЮДПЊдДЕФКЫаФММЪѕГЙЕзЕФзіСЫвЛИіЩНеЏАцБОЃЌБШШчЮвжЎЧАЬсЕНЙ§ЙигкYahooЩНеЏСЫGoogleЕФФЧаЉММЪѕЁЃ
- HamaжавРШЛДцдкSPFOЕФЕЅЕуЮЪЬтЃЌШчЙћжїНкЕуBSPMasterЙвСЫЃЌвРШЛШЋЙвЃЌЕБШЛгаЦфЫћЕФНтОіАьЗЈЃЌВЛЙ§етРяжївЊЯыжИГіЕФЪЧHamaднЪБЛЙУЛгаЩшМЦЕНетЕуЁЃ
- HamaдкMapReduceЕФЛљДЁЩЯЪЕЯжСЫ2жжЫуЗЈЃЌIterative КЭ Block ЃЌЦфжаIterativeБШНЯМђЕЅЃЌЖјBlockЯрЖдИДдгаЉЁЃ
3ЁЂЙигкBSPФЃаЭ
HamaжазюЙиМќЕФОЭЪЧBSP(Bulk Synchronous Parallel-ЁАДѓаЭЁБЭЌВНФЃаЭ)ФЃаЭ,
BSPЕФИХФюгЩValiant(1990)ЬсГіЕФЃЌЁАПщЁБЭЌВНФЃаЭЃЌЪЧвЛжжвьВНMIMD-DMФЃаЭЃЌжЇГжЯћЯЂДЋЕнЯЕЭГЃЌПщФквьВНВЂааЃЌПщМфЯдЪНЭЌВНЃЌИУФЃаЭЛљгквЛИіmasterаЕїЃЌЫљгаЕФworkerЭЌВН(lock-step)жДаа,
Ъ§ОнДгЪфШыЕФЖгСажаЖСШЁЃЌ ИУФЃаЭЕФМмЙЙШчЭМЫљЪОЃК
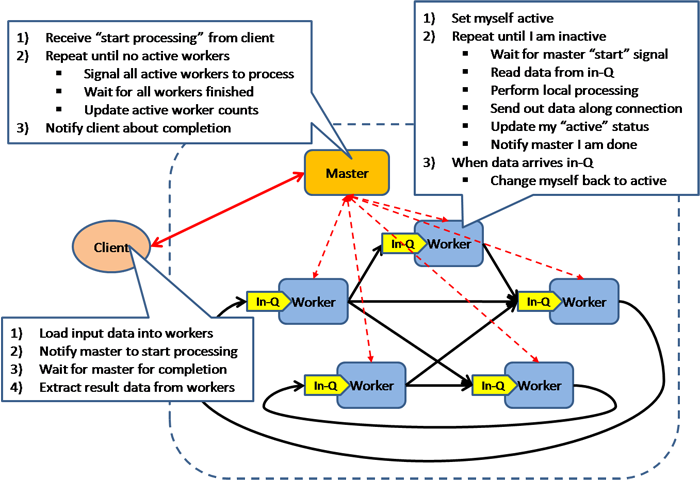
СэЭтЃЌBSPВЂааМЦЫуФЃаЭПЩвдгУ p/s/g/i 4ИіВЮЪ§НјааУшЪіЃК
- PЮЊДІРэЦїЕФЪ§ФП(ДјгаДцДЂЦї)
- sЮЊДІРэЦїЕФМЦЫуЫйЖШ
- gЮЊУПУыБОЕиМЦЫуВйзїЕФЪ§ФП/ЭЈаХЭјТчУПУыДЋЫЭЕФзжНкЪ§ЃЌГЦжЎЮЊбЁТЗЦїЭЬЭТТЪЃЌЪгЮЊДјПэвђзг (time
steps/packet)=1/bandwidth
- iЮЊШЋОжЕФЭЌВНЪБМфПЊЯњ,ГЦжЎЮЊШЋОжЭЌВНжЎМфЕФЪБМфМфИє (Barrier synchronization
time)
ФЧУДМйЩшгаpЬЈДІРэЦїЭЌЪБДЋЫЭhИізжНкаХЯЂЃЌдђg?hОЭЪЧЭЈаХЕФПЊЯњЁЃЭЌВНКЭЭЈаХЕФПЊЯњЖМЙцИёЛЏЮЊДІРэЦїЕФжИЖЈЬѕЪ§ЁЃ
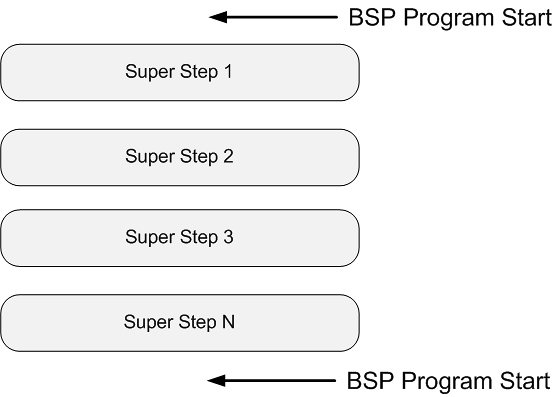
BSPМЦЫуФЃаЭВЛНіЪЧвЛжжЬхЯЕНсЙЙФЃаЭЃЌвВЪЧЩшМЦВЂааГЬађЕФвЛжжЗНЗЈЁЃBSPГЬађЩшМЦзМдђЪЧ
bulkЭЌВН (bulk synchrony)ЃЌЦфЖРЬижЎДІдкгкГЌВН(superstep)ИХФюЕФв§ШыЁЃвЛ
ИіBSPГЬађЭЌЪБОпгаЫЎЦНКЭДЙжБСНИіЗНУцЕФНсЙЙЁЃДгДЙжБЩЯПД,вЛИіBSPГЬађгЩвЛЯЕСаДЎааЕФГЌВН(superstep)зщГЩ,ШчЭМЫљЪО:
етжжНсЙЙРрЫЦгквЛИіДЎааГЬађНсЙЙЁЃДгЫЎЦНЩЯПДЃЌ дквЛИіГЌВНжаЃЌ ЫљгаЕФНјГЬВЂаажДааОжВПМЦЫуЁЃвЛИіГЌВНПЩЗжЮЊШ§ИіНзЖЮ
,ШчЭМЫљЪО:
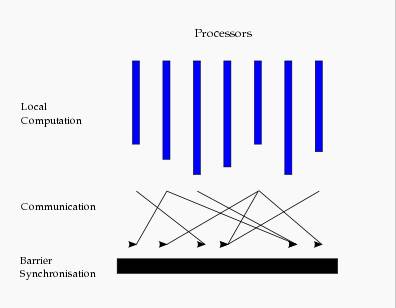
1 )БОЕиМЦЫуНзЖЮЃЌ УПИіДІРэЦїжЛЖдДцДЂБОЕиФкДцжаЕФЪ§ОнНјааБОЕиМЦЫуЁЃ
2 )ШЋОжЭЈаХНзЖЮЃЌ ЖдШЮКЮЗЧБОЕиЪ§ОнНјааВйзїЁЃ
3 )еЄРИЭЌВННзЖЮЃЌ ЕШД§ЫљгаЭЈаХааЮЊЕФНсЪјЁЃ
BSPФЃаЭЯрЖдгкЦфЫћСНжжФЃаЭЖјбдЃЌ ОпгаШчЯТСНИіЗНУцЕФгХЕуЃК
- MPI КЭ PVMСНжжВЂааМЦЫуФЃаЭЃЌвРРЕгкНгЪеКЭЗЂЫЭ ЕФВйзїЖдЁЃетбљЭЈаХЗНЪНШнвзЕМжТЩЯВугІгУГЬађВњЩњЫРЫјЃЌЖјBSPВЂааМЦЫуПтЪЧвЛИіГЬађЛЎЗжЮЊГЌВН(superstep)ЃЌЪЙЕУЫРЫјВЛдйЗЂЩњЁЃ
- BSPФЃаЭгЩгкЦфБОЩэЕФЬиЕуЃЌ ЪЙЕУЖдгкГЬађЕФе§ШЗадКЭЪБМфЕФИДдгаддЄВтГЩЮЊПЩФмЁЃ
4ЁЂApache HamaгыGoogle Pregel
HamaРрЫЦGoogleЗЂУїЕФPregelЃЌШчЙћФуЬ§Й§Google PregelетИіРћЦїЕФЛАЃЌФЧУДОЭЖдBSPМЦЫуФЃаЭВЛЛсФАЩњЃЌGoogleЕФPregelвВЪЧЛљгкBSPФЃаЭЃЌдкGoogleЕФећИіМЦЫуЬхЯЕжага20%ЕФ
МЦЫуЪЧвРРЕгкPregelЕФМЦЫуФЃаЭЃЌGoogleРћгУPregelЪЕЯжСЫЭМБщРњ(BFS)ЁЂзюЖЬТЗОЖ(SSSP)ЁЂPageRankМЦЫу,ЮвВТЯы
GoogleЕФGoogle Me ВњЦЗКмгаПЩФмЛсДѓСПВЩгУPregelЕФМЦЫуЗНЪНЃЌгУPregelРДЛцжЦGoogle
MeВњЦЗжаSNSЕФЙиЯЕЭМЁЃ
GoogleЕФPregelЪЧВЩгУGFSЛђBigTableНјааГжОУДцДЂЃЌGoogleЕФPregelЪЧвЛИіMaster-slaveжїДгНсЙЙЃЌгавЛИіНкЕуАчбнmasterНЧЩЋЃЌЦфЫќНкЕуЭЈЙ§name
serviceЖЈЮЛИУЖЅЕуВЂдкЕквЛДЮЪБНјаазЂВсЃЌmasterИКд№ЖдМЦЫуШЮЮёНјааЧаЗжЕНИїНкЕу(вВПЩвдздМКжИЖЈЃЌПМТЧload
balanceЕШвђЫи)ЃЌИљОнЖЅIDЙўЯЃЗжХфЖЅЕуЕНЛњЦї(вЛИіЛњЦїПЩвдгаЖрИіНкЕуЃЌЭЈЙ§name serviceНјааТпМЧјЗж)ЃЌУПИіНкЕуМфвьВНДЋЪфЯћЯЂЃЌЭЈЙ§checkpointЛњжЦЪЕааШнДэ(ИќИпМЖЕФШнДэЭЈЙ§confined
recoveryЪЕЯж)ЃЌВЂЧвУПИіНкЕуЯђmasterЛуБЈаФЬј(ping)ЮЌГжзДЬЌЁЃ
HamaЪЧApacheжаHadoopЕФзгЯюЃЌЫљвдHamaПЩвдгыApacheЕФHDSFНјааЭъУРЕФећКЯЃЌРћгУHDFSЖдашвЊдЫааЕФШЮЮёКЭЪ§ОнНјааГжОУЛЏДцДЂЃЌвВПЩвддкШЮКЮЮФМўЯЕЭГКЭЪ§ОнПтжаЁЃЕБШЛЮвУЧПЩвдЯраХBSPФЃаЭЕФДІРэМЦЫуФмСІЪЧЯрЖдУЛгаМЋЯоЕФЬиБ№ЖдгкЭММЦЫуРДЫЕЃЌЛЛОфЛАЫЕBSPФЃаЭОЭЯёMapReduceвЛбљПЩвдЙуЗКЕФЪЙгУдкШЮКЮвЛИіЗжВМЪНЯЕЭГжаЃЌЮвУЧПЩвдГЂЪдЕФЖдЪЕЯжЪЙгУHamaПђМмдкЗжВМЪНМЦЫужаЕУЕНИќЖрЕФЪЕМљЃЌБШШчЃКОиеѓМЦЫуЁЂХХађМЦЫуЁЂpagerankЁЂBFS
ЕШЕШЁЃ
5ЁЂHama Architecture
ApacheЕФHamaжївЊгЩШ§ИіВПЗжзщГЩЃКBSPMasterЃЌGroomServersКЭZookeeperЃЌЯТУцетеХЭМжївЊИХЪіСЫHamaЕФећЬхЯЕЭГМмЙЙ,ВЂЧвУшЪіСЫЯЕЭГФЃПщжЎМфЕФЭЈбЖгыНЛЛЅЁЃHamaЕФМЏШКжаашвЊгаHDFSЕФдЫааЛЗОГИКд№ГжОУЛЏДцДЂЪ§Он(Р§Шч:job.jar),BSPMasterИКд№НјааЖдGroom
Server НјааШЮЮёЕїХфЃЌgroom Server ИКд№НјааЖдBSPPeersНјааЕїгУ ГЬађНјааОпЬхЕФЕїгУЃЌZookeeperИКд№ЖдGroom
Server НјааЪЇаЇзЊЗЂЁЃ
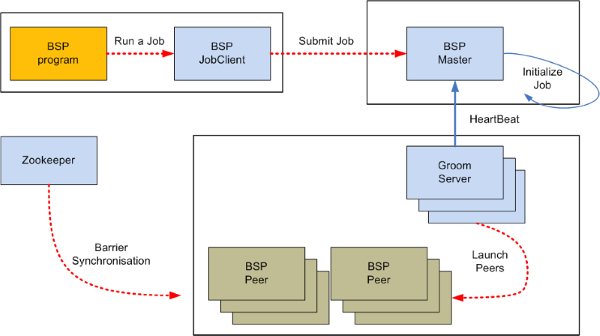
BSPMaster
дкApache HamaжаBSPMasterФЃПщЪЧЯЕЭГжаЕФвЛИіжївЊНЧЩЋЃЌЫћжївЊИКд№ЕФЪЧаЭЌИїИіМЦЫуНкЕужЎМфЕФЙЄзїЃЌУПвЛИіМЦЫуНкЕудкЦфзЂВсЕНmasterЩЯРДЕФЪБКђЛсЗжХфЕНвЛИіЮЈвЛЕФIDЁЃMasterФкВПЮЌЛЄзХвЛИіМЦЫуНкЕуСаБэЃЌБэУїЕБЧАФФаЉМЦЫуНкЕуГігкaliveзДЬЌЃЌИУСаБэжаОЭАќРЈУПИіМЦЫуНкЕуЕФIDКЭЕижЗаХЯЂЃЌвдМАФФаЉМЦЫуНкЕуЩЯБЛЗжХфЕНСЫећИіМЦЫуШЮЮёЕФФФвЛВПЗжЁЃMasterжаетаЉаХЯЂЕФЪ§ОнНсЙЙДѓаЁШЁОігкећИіМЦЫуШЮЮёБЛЗжГЩЖрЩйИіpartitionЁЃвђДЫЃЌвЛЬЈЦеЭЈХфжУЕФBSPMasterзуЙЛгУРДаЕїЖдвЛИіДѓаЭМЦЫуЁЃ
ЯТУцЮвУЧРДПДПДBSPMasterзіСЫФФаЉЙЄзїЃК
- ЮЌЛЄзХGroomЗўЮёЦїЕФзДЬЌЁЃ
- ПижЦдкМЏШКЛЗОГжаЕФsuperstepЁЃ
- ЮЌЛЄдкgroomжаjobЕФЙЄзїзДЬЌаХЯЂЁЃ
- ЗжХфШЮЮёЁЂЕїЖШШЮЮёЕНЫљгаЕФgroomЗўЮёЦїНкЕуЁЃ
- ЙуВЅЫљгаЕФgroomЗўЮёЦїжДааЁЃ
- ЙмРэЯЕЭГНкЕужаЕФЪЇаЇзЊЗЂЁЃ
- ЬсЙЉгУЛЇЖдМЏШКЛЗОГЕФЙмРэНчУцЁЃ
вЛИіBSPMasterЛђепЖрИіgroomsЗўЮёЦїЪЧЭЈЙ§НХБОЦєЖЏЕФЃЌдкGroomЗўЮёЦїжаЛЙАќКЌСЫBSPeerЕФЪЕР§ЃЌдкЦєЖЏGroomServerЕФЪБКђОЭЛсЦєЖЏСЫBSPPeerЃЌBSPPeerЪЧећКЯдкGrommServerжаЕФЃЌGrommServerЭЈЙ§PRCДњРэгыBSPmasterСЌНгЁЃЕБBSPmasterЁЂGroomServerЦєЖЏЭъБЯвдКѓЃЌУПИіGroomServerЕФЩњУќжмЦкЭЈЙ§ЗЂЫЭЁАаФЬјЁБаХЯЂИјBSPmasterЗўЮёЦїЃЌдкетИіЁАаФЬјЁБаХЯЂжаАќКЌСЫGrommServerЗўЮёЦїЕФзДЬЌЃЌетаЉзДЬЌАќКЌСЫФмЙЛДІРэШЮЮёЕФзюДѓШнСПЃЌКЭПЩгУЕФЯЕЭГФкДцзДЬЌЃЌЕШЕШЁЃ
BSPMasterЕФОјДѓВПЗжЙЄзїЃЌШчinput ЃЌoutputЃЌcomputationЃЌsavingвдМАresuming
from checkpointЃЌЖМНЋЛсдквЛИіНазіbarrierЕФЕиЗНжежЙЁЃMasterЛсдкУПвЛДЮВйзїЖМЛсЗЂЫЭЯрЭЌЕФжИСюЕНЫљгаЕФМЦЫуНкЕуЃЌШЛКѓЕШД§ДгУПИіМЦЫуНкЕуЕФЛигІ(response)ЁЃУПвЛДЮЕФBSPжїЛњНгЪеаФЬјЯћЯЂвдКѓЃЌетИіаХЯЂЛсДјРДСЫзюаТЕФgroomЗўЮёЦїзДЬЌЃЌBSPMasterЗўЮёЦїЖдИјГівЛИіЛигІЕФаХЯЂЃЌBSPMasterЗўЮёЦїНЋЛсгыgroom
ЗўЮёЦїНјааШЗЖЈЛюЖЏЕФgroom serverПеЯазДЬЌЃЌвВОЭЪЧgroom ЗўЮёЦїПЩзЪдДВЂЧвЖдЦфНјааШЮЮёЕїЖШКЭШЮЮёЗжХфЁЃ
BSPMasterгыGroom ServerСНепжЎМфЭЈбЖЪЙгУЗЧГЃМђЕЅЕФFIFO(ЯШНјЯШГі)ддђЖдМЦЫуЕФШЮЮёНјааЗжХфЁЂЕїЖШЁЃ
GroomServer
вЛИіGroomЗўЮёЦїЖдгІвЛИіДІРэBSPMasterЗжХфЕФШЮЮёЃЌУПИіgroomЖМашвЊгыBSPMasterНјааЭЈбЖЃЌДІРэШЮЮёВЂЧвЯыBSPMasterДІРэБЈИцзДЬЌЃЌМЏШКзДЬЌЯТЕФGroom
ServerашвЊдЫаадкHDFSЗжВМЪНДцДЂЛЗОГжаЃЌЖјЧвЖдгкGroom ServerРДЫЕ вЛИіgroom ЗўЮёЦїЖдгІвЛИіBSPPeerНкЕуЃЌашвЊдЫаадкЭЌвЛИіЮяРэНкЕуЩЯЁЃ
Zookeeper
ZookeeperетРяОЭВЛЖрЬсСЫЃЌПЩвдВЮПМЮвжЎЧАаДЕФМИЦЊЮФеТЃЌдкApache
HaMaЯюФПжаzookeeperЪЧгУРДгааЇЕФЙмРэBSPPeerНкЕужЎМфЕФЭЌВНМфИє(barrier synchronisation),ЭЌЪБдкЯЕЭГЪЇаЇзЊЗЂЕФЙІФмЩЯЗЂЛгСЫживЊЕФзїгУЁЃ
6ЁЂHamaЖдBSPФЃаЭЕФЪЕЯж
дквЛИіBSPМЦЫуФЃаЭЕФГЬађжаАќКЌСЫвЛИіsuperstepsВНжшЃЌУПвЛИіsuperstepгЩвдЯТ3ИіЬхЯЕЃК
- БОЕиМЦЫу
- НјГЬЭЈаХ
- ЭЌВНМфИє
public class BSPEaxmple {
public static class MyBSP extends BSP {
@Override
public void bsp(BSPPeer bspPeer) throws IOException, KeeperException,
InterruptedException {
// 1. Do something locally
// 2. Sends/receives data to/from neighbor nodes
bspPeer.send(peerName, msg);
while ((message = bspPeer.getCurrentMessage()) != null) {
byte[] data = message.getData();
}
// 3. Barrier synchronization
bspPeer.sync();
}
@Override
public Configuration getConf() {
return conf;
}
@Override
public void setConf(Configuration conf) {
this.conf = conf;
}
}
// BSP job configuration
public void main(String[] args) throws Exception {
BSPJob bsp = new BSPJob(new HamaConfiguration(), BSPEaxmple.class);
// Set the job name
bsp.setJobName("My BSP Job");
bsp.setBspClass(MyBSP.class);
// Submit job
BSPJobClient.runJob(bsp);
}
} |
|


