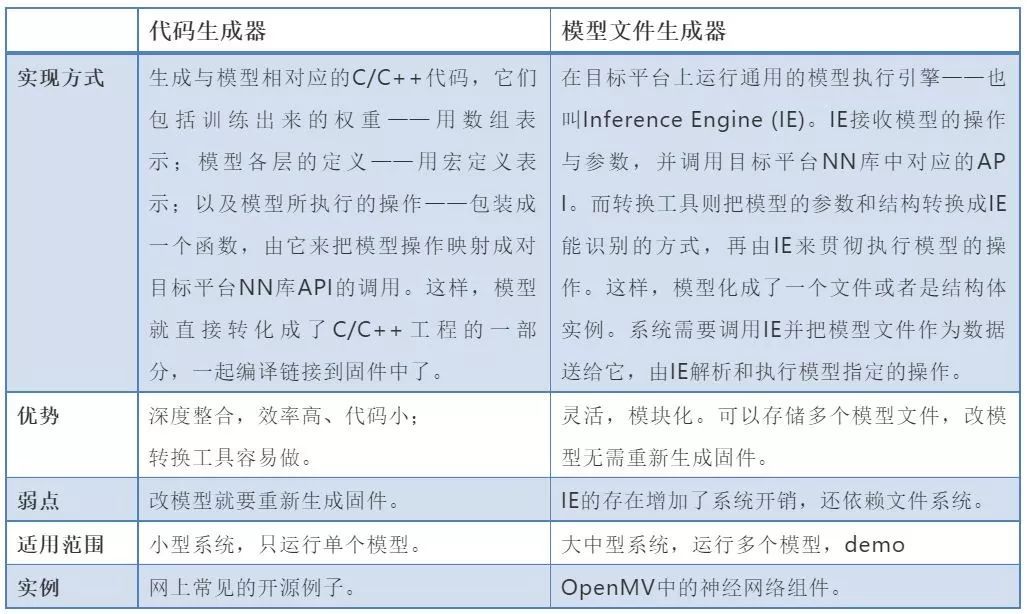
| БрМЭЦМі: |
ЮФеТИјДѓМвНщЩмЪВУДЪЧЛњЦїбЇЯАЃЌМЏГЩAI ФЃПщЕНгВМўжаЃЌAIФЃаЭЕФВПЪ№ЃЌгявєЪЖБ№ЗНАИЃЌШЫСГЪЖБ№ЗНАИЃЌЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздгкЬкбЖдЦЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
зд2017ФъПЊЪМЃЌЁАAIoTЁБвЛДЪБуПЊЪМЦЕЦЕЫЂЦСЃЌГЩЮЊЮяСЊЭјЕФаавЕШШДЪЁЃЁАAIoTЁБМДЁАAI+IoTЁБЃЌжИЕФЪЧШЫЙЄжЧФмММЪѕгыЮяСЊЭјдкЪЕМЪгІгУжаЕФТфЕиШкКЯЁЃЕБЧАЃЌвбОгадНРДдНЖрЕФШЫНЋAIгыIoTНсКЯЕНвЛЦ№РДПДЃЌAIoTзїЮЊИїДѓДЋЭГаавЕжЧФмЛЏЩ§МЖЕФзюМбЭЈЕРЃЌвбОГЩЮЊЮяСЊЭјЗЂеЙЕФБиШЛЧїЪЦЁЃБОГЁchatЮвУЧвЛЦ№бЇЯАЪВУДЪЧAIoTЃЌШчКЮШыУХAIoTПЊЗЂЃЌдкШЫЙЄжЧФмЮяСЊЭјЪБДњРДСйжЎЧАзіКУжЊЪЖДЂБИЁЃ
AIoTВЂВЛЪЧаТММЪѕЕФИяаТЃЌЫќжЎЫљвдФбвдРэНтЪЧвђЮЊИєааШчИєЩНЃЌзіШЫЙЄжЧФмЫуЗЈЕФВЛЖЎгВМўЃЌЖЎЧЖШыЪНЕФгжВЛЖЎШЫЙЄжЧФмЫуЗЈЃЌВЛвЊХТЃЌДЫПЮГЬЛсТ§Т§НвПЊAIoTЕФЩёУиУцЩДЃЌШУФуЭъУРЕиПчНчгНгаТЕФММЪѕГБСїЁЃ
ЪВУДЪЧЛњЦїбЇЯА
зїЮЊШЫЙЄжЧФмЕФзгМЏЃЌЛњЦїбЇЯАЪЙгУЭГМЦбЇММЪѕИГгшМЦЫуЛњбЇЯАЕФФмСІЃЌЖјЮоашУїШЗБрГЬЁЃдкЦфзюдЪМЕФЗНЗЈжаЃЌЛњЦїбЇЯАЪЙгУЫуЗЈРДЗжЮіЪ§ОнЃЌШЛКѓИљОнЦфНтЖСНјаадЄВтЁЃ
ЙиМќвђЫидкгкЃЌЛњЦїОЙ§бЕСЗЃЌПЩДгЪ§ОнжабЇЯАЃЌвђДЫЫќФмЙЛжДааИјЖЈЙЄзїЁЃЮЊДЫЃЌЛњЦїбЇЯАгІгУФЃЪНЪЖБ№КЭМЦЫубЇЯАРэТлЃЌАќРЈИХТЪММЪѕЁЂКЫЗНЗЈКЭБДвЖЫЙИХТЪЃЌетаЉзЈвЕСьгђММЪѕвбГЩЮЊФПЧАЛњЦїбЇЯАЗНЗЈжаЕФжїСїЁЃ
ЛњЦїбЇЯАЫуЗЈВЂВЛзёбОВЬЌГЬађжИСюЃЌЖјЪЧРћгУЪфШыЪОР§бЕСЗМЏРДЙЙНЈФЃаЭНјаадЫЫуЃЌвдБузіГіЪ§ОнЧ§ЖЏаЭдЄВтВЂЪфГіБэЪОГіРДЁЃ
ЮЊСЫЪЙЖСепИќШнвзРэНтЪВУДЪЧЛњЦїбЇЯАЃЌетРяВЛНВПндяЕФЫуЗЈЃЌЮвУЧвдЩњЛюжаЕФГЁОАЮЊР§ПДЯТЕБЧАЕФЛњЦїбЇЯАММФмЃК
дЄВтЪ§жЕЃЌбЇУћЛиЙщЁЃБШШчЃЌИјФуФГШЫЕФбЬСфКЭНЁПЕзДЬЌЃЌдЄВтЫћНЋЛМЗЮАЉЕФИХТЪЁЃетОЭЯёЬюПеЬтЁЃ

ЗжБцжжРрЃЌбЇУћЗжРрЁЃДггаЯоЕФРрБ№жабЁГівЛИіЁЃетЪЧзюГЃМћЕФЃЌЯёЮяЬхЪЖБ№ЃЌШЫСГЪЖБ№ЃЌЖМЪєгкетжжЁЃетОЭЯёбЁдёЬтЃЌВЂЧвЁБЖМВЛЪЧЁБВЂВЛЪЧвЛИіжжРрЃЌЖјЪЧЗжРрЪЇАмЕФЧщПіЁЃ

МрПизДЬЌЃЌбЇУћвьГЃМьВтЁЃетвВПЩПДГЩЪЧЕЅЗжРрЕФЧщПіЁЃЕБЪфШыВЛФмЙщЮЊЮЈвЛЕФРрБ№ЪБОЭШЯЮЊЪЧвьГЃЁЃетОЭЯёХаЖЯЬт

ЗЂЯжНсЙЙЃЌбЇУћОлРрЁЃгУгкЗЂЯжДѓСПИіЬхЕФЗжВМФЃЪНВЂвЛвЛСаГіЃЌетОЭЯёМђД№ЬтЁЃетКЭЗжРрЕФвЛИіживЊЧјБ№ЪЧУПЁАДиЁБВЂУЛгаЖдгІЕФРрБ№УћГЦЃЌвВУЛгаЪТЯШЖЈКУЕФРрБ№Ъ§СПЁЃ

бЇЯАВпТдЃЌбЇУћЧПЛЏбЇЯАЁЃБШШчШУЛњЦїЙЗбЇЛсзпТЗЃЌШУЕчФдбЇЛсЯТЮЇЦхЃЌетОЭЯёЪЕбщЬтЁЃетвВЪЧзюГЃДјИјШЫРрЖдПЙКЭПжОхЕФвЛРргІгУЁЃ

гааФЕФЖСепвбОЗЂЯжШЫЙЄжЧФмОЭЪЧДѓСПЪ§ОнЭГМЦКѓЕФЙцТЩФтКЯЃЌЮвУЧвдвЛеХЭМОйР§ПДЯТЁАДгЙХжСНёЁБШЫЙЄжЧФмЗЂЩњСЫФФаЉБфЛЏЃК
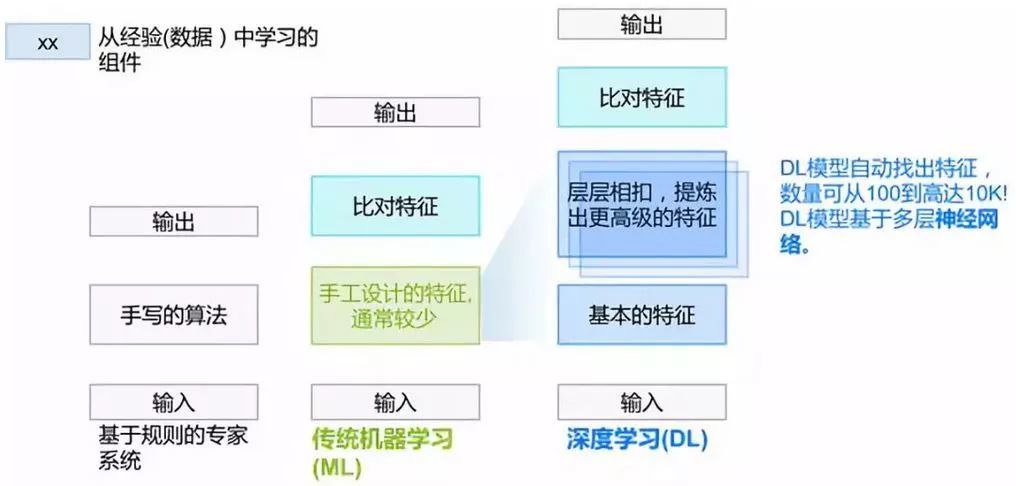
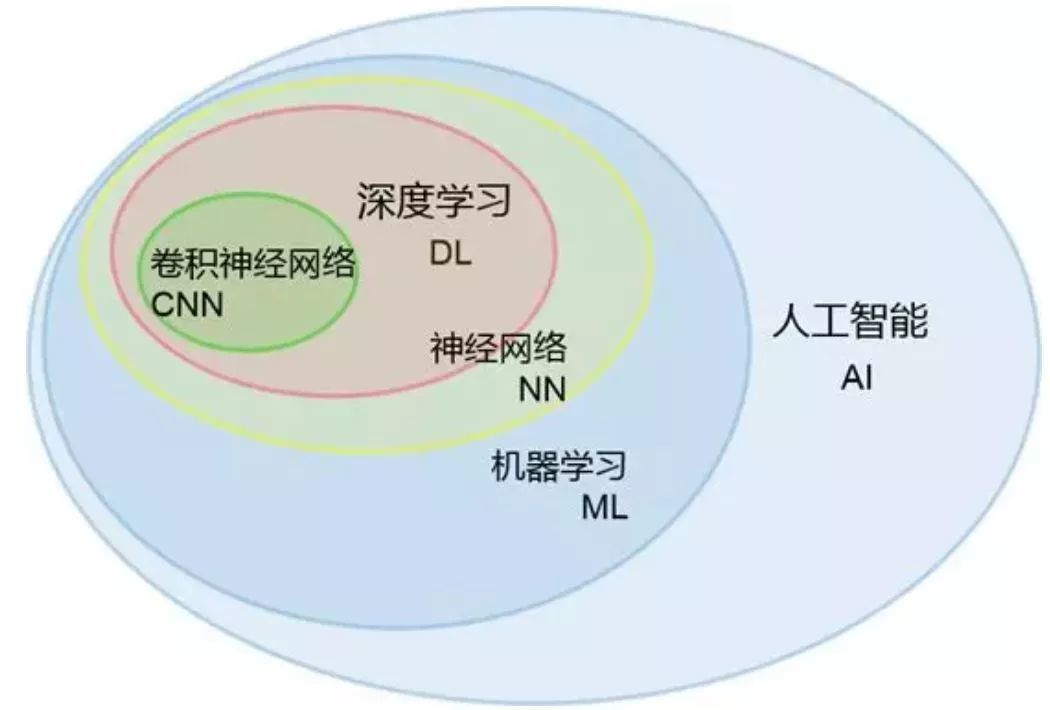
зюдчЕФAIЯЕЭГЪЧЛљгкЙцдђЕФзЈМвЯЕЭГЁЃЫљЮНЙцдђЃЌПЩвдМђЕЅЕиРэНтЮЊвЛДѓЖбif ЈC then -elseЁЃетаЉЙцдђЪЧЬ§ДгзЈМвЕФвтМћЪжаДЕФДњТыЁЃДгетИіНЧЖШЩЯЃЌЮвУЧвЛжБдкзіAIЁЊЁЊжЛвЊгУЛЇШЯПЩЮвУЧзіЕФЖЋЮїОЭЪЧгажЧФмЕФЁЃзЈМвЯЕЭГЕФадФмШнвзГіЯжЬьЛЈАхЃЌвЛИіживЊдвђЪЧКмЖрОбщжЛПЩвтЛсФбвдбдДЋЁЃ КѓРДЃЌЛњЦїбЇЯА(ML)ЕФГіЯжЃЌЪЙЮвУЧВЛБидйжБНгаДЙцдђЃЌЖјЪЧДгЪ§ОнжаЬсШЁГівЛаЉжИБъЛђепЫЕЪЧЬиеїЃЌНсКЯИїЬиеїЕФЧПЖШгыживЊадЃЌОЭПЩзіГідЄВтЛђХаЖЯЁЃВЛЙ§ЃЌбЁЖЈВЂЬсШЁЬиеїЪЧИіашвЊЗДИДЭЦЧУЕФММЪѕЛю+ЬхСІЛюЁЃ дйКѓРДЃЌЩюЖШбЇЯА(DL)АбЬсШЁЬиеїЕФЙЄзївВНгЙмСЫЃЌЭЈЙ§ЖрИіЩёОЭјТчВуЃЌвЛЕуЕуЬсСЖГіИпМЖЕФЬиеїЁЃДђИіаЮЯѓЕФБШЗНЃЌдкзіШЫСГЪЖБ№ЪБЃЌДгЯёЫи>ЯпЬѕ>ТжРЊ>ЮхЙйЁЃвђДЫЃЌЩюЖШбЇЯАНјвЛВННтЗХСЫШЫРрЕФЫЋЪжЁЃ
МЏГЩ AI ФЃПщЕНгВМўжа
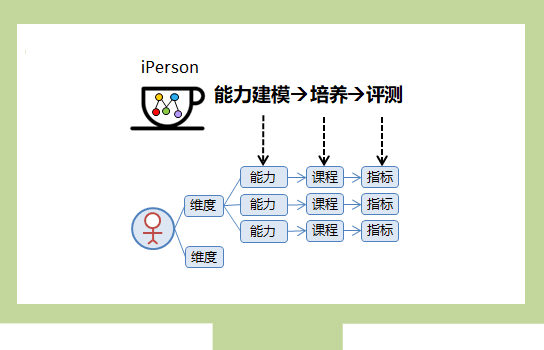
ЮвУЧжЊЕРШЫЙЄжЧФмЖдгкгВМўОЭЪЧФЃаЭЕФВПЪ№ЃЌЮвУЧЯШАб AI ФЃаЭПДГЩКкЯЛзгЃЌбЇЯАЯТШчКЮАбетИіКкЯЛзгМЏГЩЕНгВМўЩЯЃК 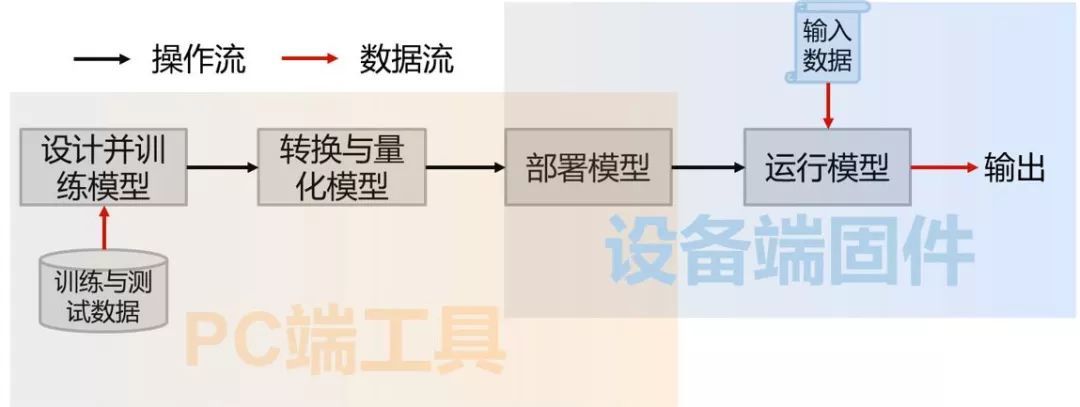
зЈжАзіЫуЗЈЕФЖд AIoT гаИіЮѓНтЃЌЛсОѕЕУгВМўадФметУДЕЭбЕСЗ AI ФЃаЭвЊЕНКяФъТэдТЁЃзЂвтетРяЕФ AI ФЃаЭВЂВЛдкЧЖШыЪНгВМўЩЯбЕСЗЃЌетРяжЛЪЧАбдкЗўЮёЦїЩЯбЕСЗКУЕФФЃаЭВПЪ№ЕНЧЖШыЪНгВМўЩЯЁЃетвЛЕуДгЩЯЭМПЩвдПДГіЃЌФЃаЭбЕСЗдкPCЖЫЃЌАббЕСЗКУЕФФЃаЭВПЪ№дкЩшБИЖЫЃЌБОЮФжЛНВЪіШчКЮМЏГЩ AI ФЃаЭЕНгВМўЩЯЃЌвдМАШчКЮМгЫй AI ЕФМЦЫуЃЌШУШЫЙЄжЧФмеце§ЕФТфЕиЁЃ ФЃаЭдкбЕСЗЪБашвЊМгШыИЈжњбЕСЗЕФНсЙЙЃЌВЂЧвбЕСЗЙ§ГЬжаЮЊСЫЬсИпОЋЖШЃЌвЛАуЪЙгУжСЩйЕЅОЋЖШИЁЕуЪ§ЁЃЭЈГЃВЛЭЌЕФбЕСЗЙЄОп(вВНаПђМм)ЃЌЛсЪЙгУВЛЭЌЕФИёЪНРДБэДябЕСЗГіРДЕФФЃаЭЃЌетбљЕФФЃаЭЛЙашвЊНјвЛВНМгЙЄВХФмгІгУЁЃ ЪзЯШЃЌвЊШЅЕєИЈжњбЕСЗЕФНсЙЙЃЌгаЕФПЩвджБНгФУШЅЃЌгаЕФЬхЯжГЩСЫЖдФЃаЭВЮЪ§ЕФБфЛЛЁЃШЛКѓЃЌ АбИЁЕуЪ§БэДяЕФВЮЪ§КЭИїИіжаМфВуЕФЪфГіЃЌзЊЛЛГЩГЃгУЕФ8ЮЛЛђ16ЮЛећЪ§ЁЃвЛЗНУцЪЧвђЮЊКУЕФФЃаЭЖдОЋЖШЕФвЊЧѓЦфЪЕВЛИпЃЌСэвЛЗНУцвВЪЧећЪ§дЫЫуЕФДњМлдЖаЁгкИЁЕуЪ§дЫЫуЁЃетаЉНазіЖдФЃаЭЕФСПЬхВУвТЃЌвВНазіФЃаЭЕФзЊЛЏгыСПЛЏЁЃ ФЃаЭгХЛЏКѓОЭПЩвдВПЪ№ЕНгВМўЩЯЃЌзЊЛЛФЃаЭЕФИёЪНЛђепГЪЯжЗНЪНЃЌЪЙЫќФмЖдНгЕНФПБъгІгУЯЕЭГЕФШэгВМўНгПкЩЯЃЌВЂВПЪ№ЕНФПБъЩшБИжаЁЃФПЧАГЃгУЕФВПЪ№ЗНЗЈгаСНжжЃК
зюКѓЮвУЧгУЙ§вЛеХЭМРДЫЕУїФУЕНбЕСЗКУЕФФЃаЭКѓашвЊОЋМђСПЛЏКЭВПЪ№жДааЕФЙ§ГЬЃК
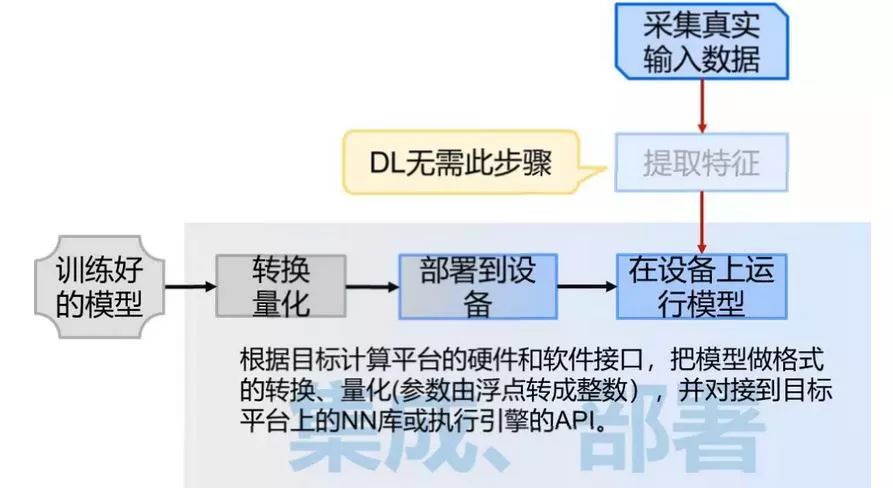
AI ФЃаЭЕФВПЪ№
ЩЯУцНВСЫФЃаЭЕФОЋМђКЭВПЪ№ЃЌЦфжаЗЧГЃЙиМќЕФОЭЪЧAIФЃаЭЕФзЊЛЛгыВПЪ№ЃЌЫќЙсЭЈСЫбЕСЗФЃаЭгыЪЙгУФЃаЭЕФСНИіЪРНчЃЛВЂЧвгажївЊЕФ2жжЗНЪНЃЌЗжБ№ЪЧАбФЃаЭзЊЛЛГЩЖдНгЦНЬЈЕзВуПтЕФДњТыЃЌЛђепЪЧдкЙЬМўРяАВВхвЛИіжДаав§ЧцВЂАбФЃаЭзЊЛЛГЩЖдгІЕФжИСюЁЃ
ШчЭМЪзЯШдкPCЩЯгУ TensorFlow ЕШПђМмШЅаэЗћКЯвЊЧѓЕФФЃаЭЃЌШЛКѓАбФЃаЭзЊЮЊДњТыЃЌгыCMSIS-NNНсКЯЃЈCMSIS-NNЪЧarmЕФвЛИіПЊдДsdkЃЉЁЃСэЭтвЛжжОЭЪЧРћгУФЃаЭзЊЛЛЦїзЊЛЛЮЊЧЖШыЪНЩшБИФЃаЭЃЌШЛКѓЭЈЙ§ЯргІв§ЧцШЅВПЪ№ЕНЧЖШыЪНЩшБИЩЯЁЃЯТУцЮвУЧЯъЯИНВЯТетСНжжЗНЗЈЁЃ
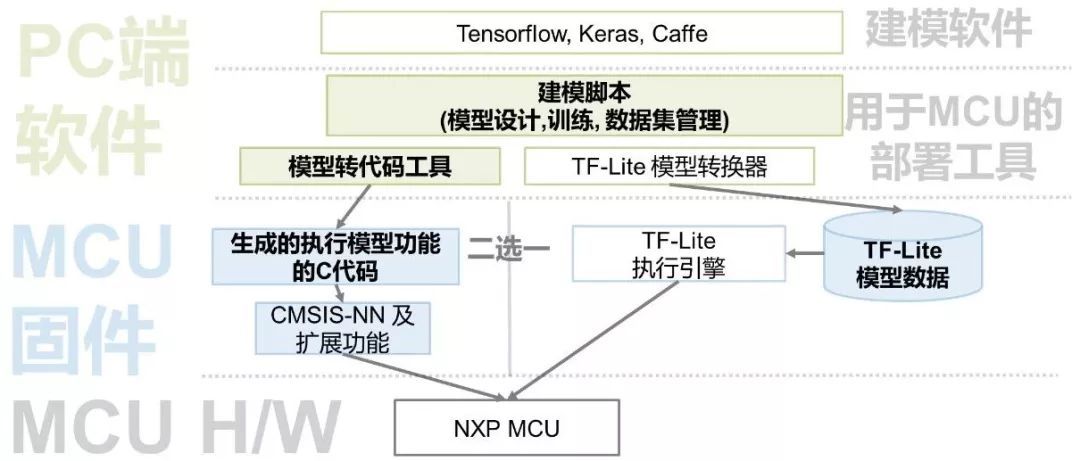
ФЃаЭзЊДњТы дкCortex-MЦНЬЈЩЯЃЌArmЬсЙЉСЫзЈгУгкжДааЩёОЭјТчВйзїЕФЕзВуПтЃЌУћЮЊCMSIS-NNЃЌЫќЯђЩЯЬсЙЉСЫCгябдЕФAPIНгПкЃЌжЇГжГЃМћЕФЦеЭЈОэЛ§ЁЂПеМфгыЭЈЕРЗжРыЕФОэЛ§ЃЌвдМАШЋСЌНгаЭдЫЫуЃЌЛЙжЇГжгыжїдЫЫуХфЬзЪЙгУЕФМЄЛюЁЂЯђЯТВЩбљЕШИЈжњВйзїЁЃет5жжЁАЛ§ФОЁБПщЕФгаЛњзщКЯЃЌзувдЙЙНЈОјДѓЖрЪ§ЩюЖШЩёОЭјТчФЃаЭЁЃ ЮвУЧПЩвдаЮЯѓЕиАбCMSIS-NNПДГЩЪЧвЛИіЬиЪтЕФCPUЃЌЫќЬсЙЉСЫЩЯУц5ЬѕжИСюЃЌЖјФЃаЭдђЪЧдДДњТыЃЌФЃаЭзЊДњТыОЭЪЧАбФЃаЭЁАБрвыЁБГЩCMSIS-NNЕФЁАЛњЦїгябдЁБЁЃетРяВЛЯъЯИНВНтCMSIS-NNЃЌД§ЛсЛсгУзЈУХвЛНкНщЩмЁЃ
ФЃаЭзЊжаМфБэДя ШчЙћЫЕЩЯУцФЃаЭзЊДњТыЗТЗ№ЪЧБрвыЕФЗНЪНЃЌФЧУДАбФЃаЭзЊЛЛГЩФГИіжДаав§ЧцЕФжаМфБэДяЃЌОЭЯёЪЧЁАНтЪЭЁБЕФЗНЪНЃЌЖјетИіжДаав§ЧцОЭЪЧНтЪЭЦїЁЃ НтЪЭЦїМШПЩвдЕїгУCMSIS-NNРДдкCortex-MЦНЬЈЩЯЬсИпаЇТЪЃЌвВПЩвдФкжУЕзВуNNдЫЫуПтРДЬсИпЭЈгУадЁЃвђЮЊдкMCUЦНЬЈЩЯдЫааDLФЃаЭЛЙЛљБОЪЧПщаТДѓТНЃЌЯжгаЕФжДаав§ЧцЛЙУЛгаеыЖдCMSIS-NNгХЛЏЃЌжЛФмЪЙгУФкжУЕФЭЈгУNNПтЁЃ жДаав§ЧцЕФвЛИіДњБэЃЌОЭЪЧGoogleЕФTensorflow-LiteЃЈМђГЦTF-LiteЃЉЁЃTFЕФДѓУћЯыБидчвбШчРзЙсЖњЃЌЕЋетИіTF-LiteШДВЛЪЧвЛИіМђЛЏАцЕФTFЃЌЖјжЛЪЧвЛИіжДаав§ЧцЃЌзюжївЊЕФОЭЪЧЫќВЛДјгабЕСЗФЃаЭЕФЙІФмЁЃ GoogleЬсЙЉСЫУћЮЊЁАtocoЁБЕФЙЄОпЃЌгУгкАбTFФЃаЭЃЈpbИёЪНЕФЮФМўЃЉзЊЛЛГЩTF-LiteФмНтЪЭЕФжаМфБэДяЁЃдкМЏГЩЕНMCUЪБЃЌАбзЊЛЛКѓЕФЮФМўеЙГЩCЪ§зщЖЈвхЛђепЗХдкSDПЈжаЃЌВЂЧвАбTF-LiteБрвыСДНгНјMCUЖЫЕФЙЬМўЃЌОЭПЩвдЪЙгУЫќСЫЁЃ
CMSIS-NNНщЩм
ArmЭЦГіСЫЛљгкCortex-MКЫЕФгХЛЏЗНАИЃЌУћЮЊCMSIS-NNЁЃCMSISЕФШЋГЦЪЧCortex Microcontroller Software Interface Standard ( CortexЮЂДІРэЦїШэМўНгПкБъзМ)ЃЌФПЕФОЭЪЧЮЊСЫНтОіЮЂДІРэЦїЩњЬЌжаШэМўЮоЗЈМцШнЕФЮЪЬтЁЃ ФПЧАЮЂПижЦЦїЩЯЕФШэМўВйзїЯЕЭГЗЧГЃЗжЩЂЃЌЯргІЕФШэМўЮоЗЈКмКУЕФИДгУЃЌДцдкДѓСПЕФжиИДдьТжзгЕФЯжЯѓЁЃЖјArmЫљв§ШыЕФCMSISПђМмЃЌзіЕНСЫвЛжжвЛЭГНКўЕФИаОѕЃЌЭЈЙ§в§ШывЛЯЕСаМЋМђЕФГщЯѓВуAPIЃЌНЋгІгУГЬађЁЂжаМфМўЭЌOSНјааИєРыЖјВЛЛсгАЯьЯЕЭГЕФадФмЃЌЭЌЪБгжКмгбКУЕиЬсЙЉСЫЖдгкжїСїЕїЪдЦїDS-5/KEIL/IARЕШЕФжЇГжЁЃ ЯТУцЪЧCMSISЕФШэМўПђМмЭМЃК
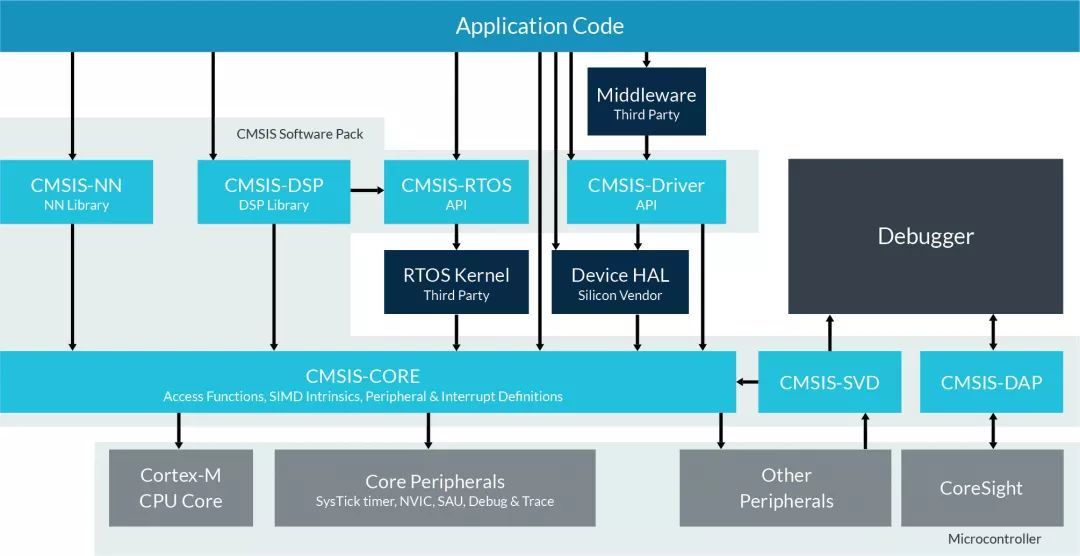
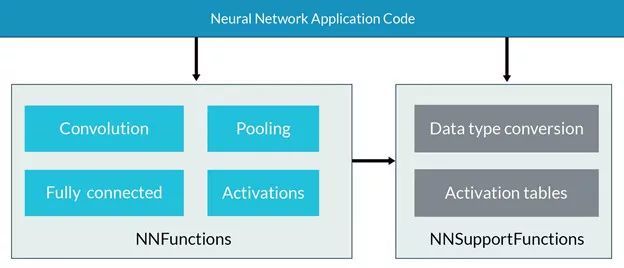
CMSIS-NNЪЧзюНќМгШыCMSISМвзхЕФаТГЩдБЃЌЫ§ЕФМгШыДѓДѓЛКНтСЫЛљгкMCUЕФЩёОЭјТчЯрЙиШэМўЕФгХЛЏбЙСІЁЃ CMSIS-NNЭЈЙ§ЖдЩёОЭјТчжаЫљашвЊЕФЙиМќКЏЪ§НјаагХЛЏЃЌвдДяЕНЧПЛЏадФмЕФФПЕФЁЃБШШчЃЌЭЈЙ§ВщБэБмУтМЄЛюКЏЪ§МЦЫуЕШЃЌЭЌЪБВЩгУЖЈЕудЫЫу(8/16bits)ЬцДњИЁЕудЫЫувВФмЙЛЯджјМѕЩйФкДцЯћКФЁЃИќМгжЕЕУЭЦМіЕФЪЧЃЌдкГЬађжаЪЙгУCMSIS-NNЬэМгЩёОЭјТчвВЗЧГЃЗНБуЃЌжЛашвЊЕїгУЯргІЕФAPIМДПЩЭъГЩЁЃ вђДЫЃЌеыЖдгкArm Cortex-MЯЕСаДІРэЦїФкКЫЃЌШчЙћФњЯывЊЧПЛЏадФмВЂЧвМѕЩйФкДцЯћКФЃЌCMSIS-NNЛсЪЧФњзюКУЕФХѓгбЁЃЛљгкCMSIS-NNКЏЪ§ПтЕФЩёОЭјТчЭЦРэдЫЫуЃЌЖдгкдЫааЪБМф/ЭЬЭТСПЃЌЯрБШЮДгУCMSIS-NNКЏЪ§ПтЃЌНЋЛсга4.6XЕФЬсЩ§ЃЌЖјЖдгкФмаЇНЋга4.9XЕФЬсЩ§ЁЃ CMSIS-NNКЏЪ§ПтАќКЌгаСНВПЗжЃКNNFunctionsКЭNNSupportFunctionsЁЃЦфжаЃЌNNFunctionsАќКЌСЫЪЕЯжЩёОЭјТчГЃгУВйзїЕФAPIЃЌБШШчОэЛ§(convolution)ЃЌЩюЖШПЩЗжРыОэЛ§(depthwise separable convolution)ЃЌШЋСЌНг(МДФкЛ§inner-product)ЃЌГиЛЏ(polling)КЭМЄЛю(activation)ЁЃетаЉКЏЪ§ЕФгаађзщКЯОЭвЁЩэвЛБфГЩЮЊСЫЩёОЭјТчЕФжаЪрЯЕЭГЃЌШэМўВугІгУГЬађЭЈЙ§ЕїгУетаЉКЏЪ§ЃЌЪЕЯжЩёОЭјТчЕФЭЦРэгІгУЁЃ NNSupportFunctionsКЏЪ§МЏАќРЈВЛЭЌЕФЪЕгУКЏЪ§ЃЌШчNNFunctionsжаЪЙгУЕФЪ§ОнзЊЛЛКЭМЄЛюЙІФмБэЁЃе§ШчЦфУћЃЌетзщКЏЪ§ЮЊNNЫуЗЈЬсЙЉИќЛљБОЕФВйзїЁЃДЫЭтЃЌШчЙћCMSIS-NNЕФЙІФмРЉеЙЃЌвВПЩвдгУЫќУЧЙЙдьИќИДдгЕФNNФЃПщЃЌР§ШчЃЌГЄЦкЖЬЪБМЧвф(LSTM)ЛђУХПибЛЗЕЅдЊ(GRU)ЁЃ CMSIS-NNЕФAPIЪЧжБНгЖдНгЕНCPUЕФЕзВуПтЃЌAPIвЊЧѓЕФВЮЪ§ЭљЭљЖрДяЪЎгрИіЃЌЬиБ№ЪЧЛЙвЊЧѓЬсЙЉШЈжиБэЁЃЪжЖЏЕїгУетаЉAPIЪЕЯжЖЏщќЪЎгрВуЕФЩёОЭјТчПндяЁЂКФЪБВЂЧввзДэЃЌЫљвдвЛАугУЩЯвЛЦкЬсЕНЕФВПЪ№ЙЄОпЪЕЯжФЃаЭзЊДњТыЛђепЭЈЙ§жДаав§ЧцРДЕїгУCMSIS-NNЁЃ ЯТЭМЪЧCMSIS-NNЕФПђМмЭМЃК
гявєЪЖБ№ЗНАИ
етРяНЬДѓМвДггявєЧАЖЫДІРэЁЂЛљгкЭГМЦбЇгявєЪЖБ№КЭЛљгкЩюЖШбЇЯАгявєЪЖБ№ЕШЗНУцВћЪігявєЪЖБ№ЕФдРэЁЃ гявєЪЖБ№ЕФБОжЪОЭЪЧНЋгявєађСазЊЛЛЮЊЮФБОађСаЃЌЦфГЃгУЕФЯЕЭГПђМмШчЯТЃК
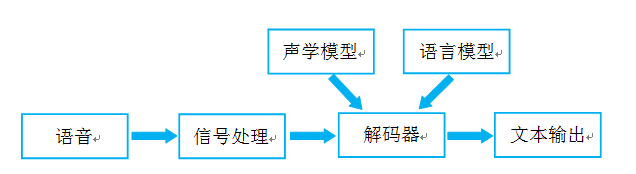
НгЯТРДЖдгявєЪЖБ№ЯрЙиММЪѕНјааНщЩмЃЌЮЊСЫБугкећЬхРэНтЃЌЪзЯШЃЌНщЩмгявєЧАЖЫаХКХДІРэЕФЯрЙиММЪѕЃЌШЛКѓЃЌНтЪЭгявєЪЖБ№ЛљБОдРэЃЌВЂеЙПЊЕНЩљбЇФЃаЭКЭгябдФЃаЭЕФа№ЪіЁЃ
1. ЧАЖЫаХКХДІРэ ЧАЖЫЕФаХКХДІРэЪЧЖддЪМгявєаХКХНјааЕФЯрЙиДІРэЃЌЪЙЕУДІРэКѓЕФаХКХИќФмДњБэгявєЕФБОжЪЬиеїЃЌЯрЙиММЪѕЕуШчЯТБэЫљЪіЃК a.гявєЛюЖЏМьВт: гявєЛюЖЏМьВтЃЈVoice Activity Detection, VADЃЉгУгкМьВтГігявєаХКХЕФЦ№ЪМЮЛжУЃЌЗжРыГігявєЖЮКЭЗЧгявєЃЈОВвєЛђдыЩљЃЉЖЮЁЃVADЫуЗЈДѓжТЗжЮЊШ§РрЃКЛљгкуажЕЕФVADЁЂЛљгкЗжРрЦїЕФVADКЭЛљгкФЃаЭЕФVADЁЃ b.НЕды: дкЩњЛюЛЗОГжаЭЈГЃЛсДцдкР§ШчПеЕїЁЂЗчЩШЕШИїжждыЩљЃЌНЕдыЫуЗЈФПЕФдкгкНЕЕЭЛЗОГжаДцдкЕФдыЩљЃЌЬсИпаХдыБШЃЌНјвЛВНЬсЩ§ЪЖБ№аЇЙћЁЃГЃгУНЕдыЫуЗЈАќРЈздЪЪгІLMSКЭЮЌФЩТЫВЈЕШЁЃ c.ЛиЩљЯћГ§: ЛиЩљДцдкгкЫЋЙЄФЃЪНЪБЃЌТѓПЫЗчЪеМЏЕНбяЩљЦїЕФаХКХЃЌБШШчдкЩшБИВЅЗХвєРжЪБЃЌашвЊгУгявєПижЦИУЩшБИЕФГЁОАЁЃЛиЩљЯћГ§ЭЈГЃЪЙгУздЪЪгІТЫВЈЦїЪЕЯжЕФЃЌМДЩшМЦвЛИіВЮЪ§ПЩЕїЕФТЫВЈЦїЃЌЭЈЙ§здЪЪгІЫуЗЈЃЈLMSЁЂNLMSЕШЃЉЕїећТЫВЈЦїВЮЪ§ЃЌФЃФтЛиЩљВњЩњЕФаХЕРЛЗОГЃЌНјЖјЙРМЦЛиЩљаХКХНјааЯћГ§ЁЃ d.ЛьЯьЯћГ§: гявєаХКХдкЪвФкОЙ§ЖрДЮЗДЩфжЎКѓЃЌБЛТѓПЫЗчВЩМЏЃЌЕУЕНЕФЛьЯьаХКХШнвзВњЩњбкБЮаЇгІЃЌЛсЕМжТЪЖБ№ТЪМБОчЖёЛЏЃЌашвЊдкЧАЖЫДІРэЁЃЛьЯьЯћГ§ЗНЗЈжївЊАќРЈЃКЛљгкФцТЫВЈЗНЗЈЁЂЛљгкВЈЪјаЮГЩЗНЗЈКЭЛљгкЩюЖШбЇЯАЗНЗЈЕШЁЃ e.ЩљдДЖЈЮЛ: ТѓПЫЗчеѓСавбОЙуЗКгІгУгкгявєЪЖБ№СьгђЃЌЩљдДЖЈЮЛЪЧеѓСааХКХДІРэЕФжївЊШЮЮёжЎвЛЃЌЪЙгУТѓПЫЗчеѓСаШЗЖЈЫЕЛАШЫЮЛжУЃЌЮЊЪЖБ№НзЖЮЕФВЈЪјаЮГЩДІРэзізМБИЁЃЩљдДЖЈЮЛГЃгУЫуЗЈАќРЈЃКЛљгкИпЗжБцТЪЦзЙРМЦЫуЗЈЃЈШчMUSICЫуЗЈЃЉЃЌЛљгкЩљДяЪБМфВюЃЈTDOAЃЉЫуЗЈЃЌЛљгкВЈЪјаЮГЩЕФзюаЁЗНВюЮоЪЇецЯьгІЃЈMVDRЃЉЫуЗЈЕШЁЃ f.ВЈЪјаЮГЩЃК ВЈЪјаЮГЩЪЧжИНЋвЛЖЈМИКЮНсЙЙХХСаЕФТѓПЫЗчеѓСаЕФИїИіТѓПЫЗчЪфГіаХКХЃЌОЙ§ДІРэЃЈШчМгШЈЁЂЪБбгЁЂЧѓКЭЕШЃЉаЮГЩПеМфжИЯђадЕФЗНЗЈЃЌПЩгУгкЩљдДЖЈЮЛКЭЛьЯьЯћГ§ЕШЁЃВЈЪјаЮГЩжївЊЗжЮЊЃКЙЬЖЈВЈЪјаЮГЩЁЂздЪЪгІВЈЪјаЮГЩКЭКѓжУТЫВЈВЈЪјаЮГЩЕШЁЃ
2. гявєЪЖБ№ЕФЛљБОдРэ вбжЊвЛЖЮгявєаХКХЃЌДІРэГЩЩљбЇЬиеїЯђСПжЎКѓБэЪОЮЊЃЌЦфжаБэЪОвЛжЁЪ§ОнЕФЬиеїЯђСПЃЌНЋПЩФмЕФЮФБОађСаБэЪОЮЊЃЌЦфжаБэЪОвЛИіДЪЁЃгявєЪЖБ№ЕФЛљБОГіЗЂЕуОЭЪЧЧѓЃЌМДЧѓГіЪЙзюДѓЛЏЕФЮФБОађСаЁЃНЋЭЈЙ§БДвЖЫЙЙЋЪНБэЪОЮЊ?
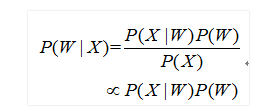
ЦфжаЃЌГЦжЎЮЊЩљбЇФЃаЭЃЌГЦжЎЮЊгябдФЃаЭЁЃДѓЖрЪ§ЕФбаОПНЋЩљбЇФЃаЭКЭгябдФЃаЭЗжПЊДІРэЃЌВЂЧвЃЌВЛЭЌГЇМвЕФгявєЪЖБ№ЯЕЭГжївЊЬхЯждкЩљбЇФЃаЭЕФВювьадЩЯУцЁЃДЫЭтЃЌЛљгкДѓЪ§ОнКЭЩюЖШбЇЯАЕФЖЫЕНЖЫЃЈEnd-to-EndЃЉЗНЗЈвВдкВЛЖЯЗЂеЙЃЌЫќжБНгМЦЫу ЃЌМДНЋЩљбЇФЃаЭКЭгябдФЃаЭзїЮЊећЬхДІРэЁЃБОЮФжївЊЖдЧАепНјааНщЩмЁЃ
3. ЩљбЇФЃаЭ ЩљбЇФЃаЭЪЧНЋгявєаХКХЕФЙлВтЬиеїгыОфзгЕФгявєНЈФЃЕЅдЊСЊЯЕЦ№РДЃЌМДМЦЫуЁЃЮвУЧЭЈГЃЪЙгУвўТэЖћПЦЗђФЃаЭЃЈHidden Markov ModelЃЌHMMЃЉНтОігявєгыЮФБОЕФВЛЖЈГЄЙиЯЕЃЌБШШчЯТЭМЕФвўТэЖћПЦЗђФЃаЭжаЁЃ
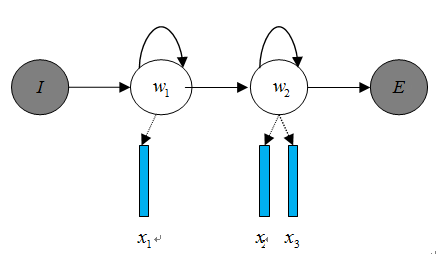
НЋЩљбЇФЃаЭБэЪОЮЊЃК
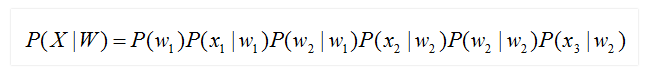
ЦфжаЃЌГѕЪМзДЬЌИХТЪКЭзДЬЌзЊвЦИХТЪПЩгУЭЈЙ§ГЃЙцЭГМЦЕФЗНЗЈМЦЫуЕУГіЃЌЗЂЩфИХТЪ )ПЩвдЭЈЙ§ЛьКЯИпЫЙФЃаЭGMMЛђЩюЖШЩёОЭјТчDNNЧѓНтЁЃ ДЋЭГЕФгявєЪЖБ№ЯЕЭГЦеБщВЩгУЛљгкGMM-HMMЕФЩљбЇФЃаЭЃЌЪОвтЭМШчЯТЃК
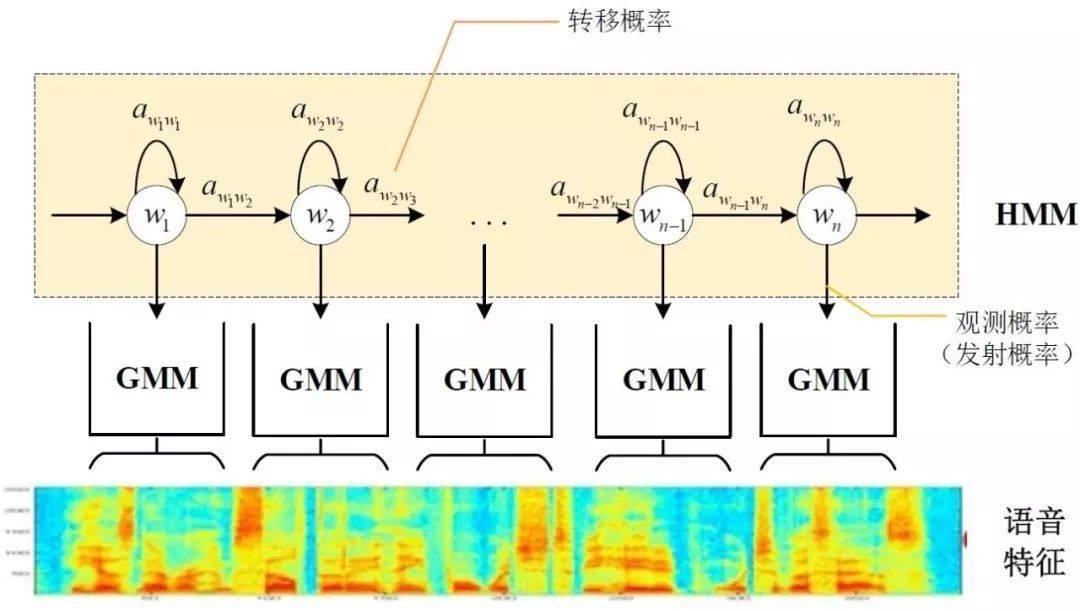
ЦфжаЃЌБэЪОзДЬЌзЊвЦИХТЪЃЌгявєЬиеїБэЪОЃЌЭЈЙ§ЛьКЯИпЫЙФЃаЭGMMНЈСЂЬиеїгызДЬЌжЎМфЕФСЊЯЕЃЌДгЖјЕУЕНЗЂЩфИХТЪЃЌВЂЧвЃЌВЛЭЌЕФзДЬЌЖдгІЕФЛьКЯИпЫЙФЃаЭВЮЪ§ВЛЭЌЁЃЛљгкGMM-HMMЕФгявєЪЖБ№жЛФмбЇЯАЕНгявєЕФЧГВуЬиеїЃЌВЛФмЛёШЁЕНЪ§ОнЬиеїМфЕФИпНзЯрЙиадЃЌDNN-HMMРћгУDNNНЯЧПЕФбЇЯАФмСІЃЌФмЙЛЬсЩ§ЪЖБ№адФмЃЌЦфЩљбЇФЃаЭЪОвтЭМШчЯТЃК
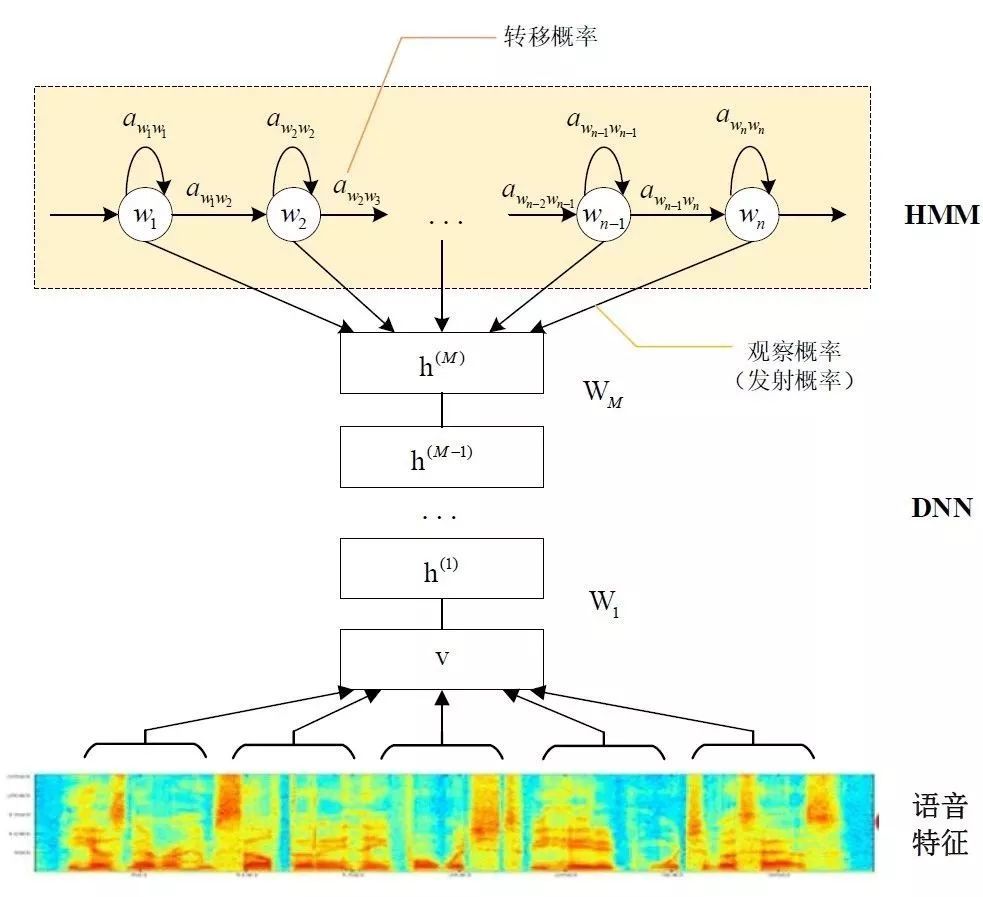
GMM-HMMКЭDNN-HMMЕФЧјБ№дкгкгУDNNЬцЛЛGMMРДЧѓНтЗЂЩфИХТЪЃЌGMM-HMMФЃаЭгХЪЦдкгкМЦЫуСПНЯаЁЧваЇЙћВЛЫзЁЃDNN-HMMФЃаЭЬсЩ§СЫЪЖБ№ТЪЃЌЕЋЖдгкгВМўЕФМЦЫуФмСІвЊЧѓНЯИпЁЃвђДЫЃЌФЃаЭЕФбЁдёПЩвдНсКЯЪЕМЪЕФгІгУЕїећЁЃ
4. гябдФЃаЭ гявєЪЖБ№жаЕФгябдФЃаЭвВгУгкДІРэЮФзжађСаЃЌЫќЪЧНсКЯЩљбЇФЃаЭЕФЪфГіЃЌИјГіИХТЪзюДѓЕФЮФзжађСазїЮЊгявєЪЖБ№НсЙћЁЃгЩгкгябдФЃаЭЪЧБэЪОФГвЛЮФзжађСаЗЂЩњЕФИХТЪЃЌвЛАуВЩгУСДЪНЗЈдђБэЪОЃЌШчЪЧгЩзщГЩЃЌдђПЩгЩЬѕМўИХТЪЯрЙиЙЋЪНБэЪОЮЊЃК
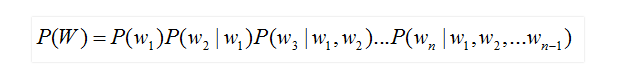
гЩгкЬѕМўЬЋГЄЃЌЪЙЕУИХТЪЕФЙРМЦБфЕУРЇФбЃЌГЃМћЕФзіЗЈЪЧШЯЮЊУПИіДЪЕФИХТЪЗжВМжЛвРРЕгкЧАМИИіГіЯжЕФДЪгяЃЌетбљЕФгябдФЃаЭГЩЮЊn-gramФЃаЭЁЃдкn-gramФЃаЭжаЃЌУПИіДЪЕФИХТЪЗжВМжЛвРРЕгкЧАУцn-1ИіДЪЁЃР§ШчдкtrigramЃЈnШЁжЕЮЊ3ЃЉФЃаЭЃЌПЩНЋЩЯЪНЛЏМђЃК
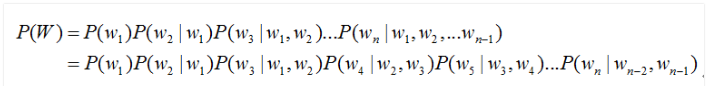
ИљОнЩЯУцЕФЫуЗЈдРэАббЕСЗЕФФЃаЭвЦжВЕНcortex-m7жаЃЌdemoШчЯТЃК гявєЪЖБ№бнЪОdemo
ШЫСГЪЖБ№ЗНАИ
ЮвУЧЯШРДПДвЛеХЭМЃК
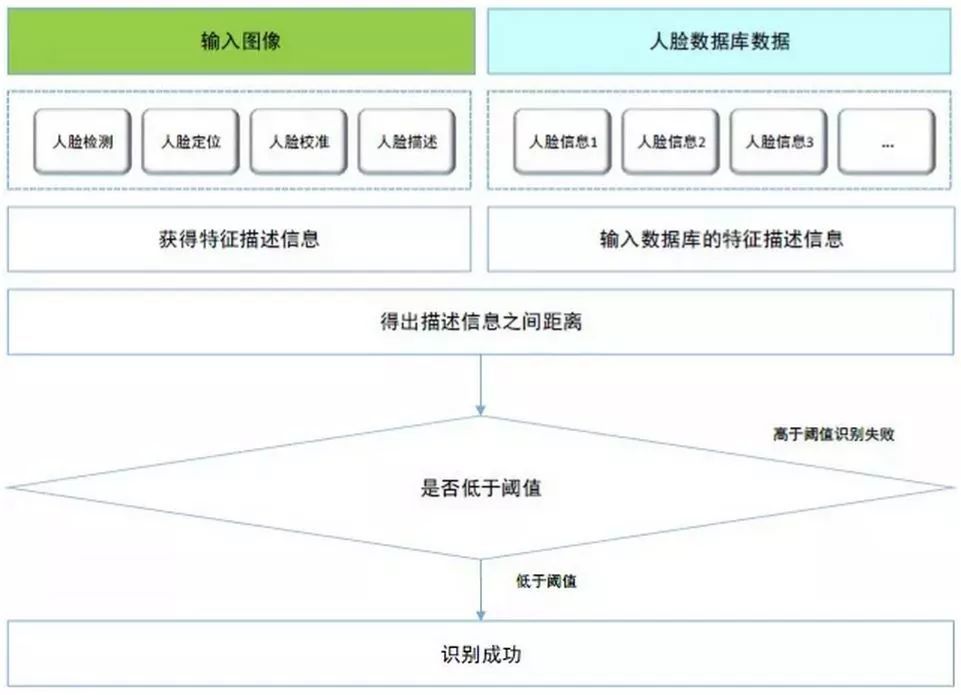
ПЩвдПДГіШЫСГЪЖБ№ЫуЗЈАќРЈШЫСГМьВтЁЂШЫСГЖЈЮЛЁЂШЫСГаЃзМЁЂШЫСГБШЖдЕШЁЃЗЯЛАЩйЫЕЮвУЧжБНгНјШыжїЬтЁЃ
1. ШЫСГЪЖБ№ ШЫСГМьВтЫуЗЈЗБЖрЃЌЮвУЧВЩгУгЩДжЕНОЋЕФИпаЇЗНЪНЃЌМДЯШгУМЦЫуСПаЁЕФЬиеїПьЫйЙ§ТЫДѓСПЗЧШЫСГДАПкЭМЯёЃЌШЛКѓгУИДдгЬиеїЩИбЁШЫСГЁЃетжжЗНЪНФмПьЫйЧвИпОЋЖШЕФМьВтГіе§СГЃЈШЫСГа§зЊВЛГЌЙ§45ЖШЃЉЁЃИУВНжшжМдкбЁШЁзюМбКђбЁПђЃЌМѕаЁЗЧШЫСГЧјгђЕФДІРэЃЌДгЖјМѕаЁКѓајШЫСГаЃзММАБШЖдЕФМЦЫуСПЁЃ
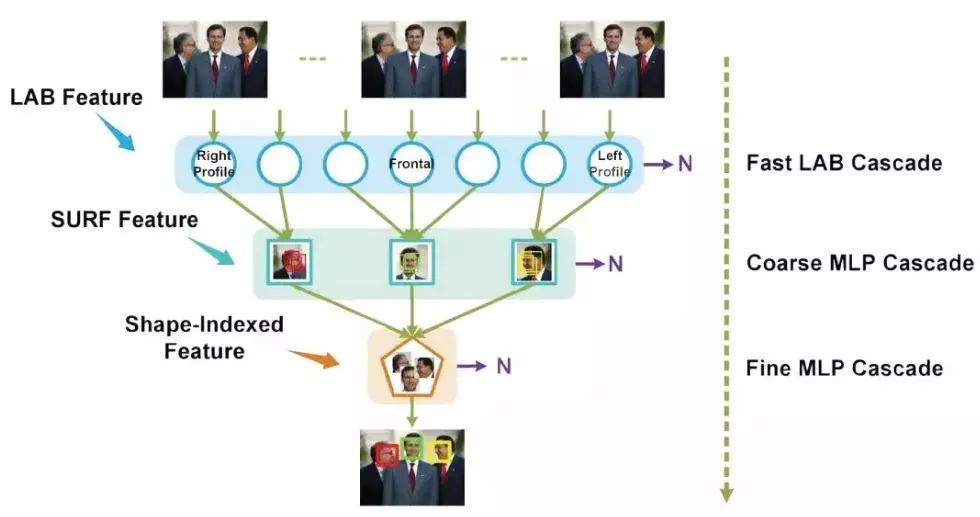
2. ШЫСГЖЈЮЛ УцВПЬиеїЕуЖЈЮЛдкШЫСГЪЖБ№ЁЂБэЧщЪЖБ№ЁЂШЫСГЖЏЛЕШШЫСГЗжЮіШЮЮёжажСЙиживЊЕФвЛЛЗЁЃШЫСГЖЈЮЛЫуЗЈашвЊбЁШЁШєИЩИіУцВПЬиеїЕуЃЌЕудНЖрдНОЋЯИЃЌЕЋЭЌЪБМЦЫуСПвВдНДѓЁЃМцЙЫОЋШЗЖШКЭаЇТЪЃЌвЛАубЁгУЫЋблжааФЕуЁЂБЧМтМАзьНЧЮхИіЬиеїЕуЁЃ
3. ШЫСГаЃзМ БОВНжшФПЕФЪЧАке§ШЫСГЃЌНЋШЫСГжУгкЭМЯёжабыЃЌМѕаЁКѓајБШЖдФЃаЭЕФМЦЫубЙСІЃЌЬсЩ§БШЖдЕФОЋЖШЁЃжївЊРћгУШЫСГЖЈЮЛЛёЕУЕФ5ИіЬиеїЕуЃЈШЫСГЕФЫЋблЁЂБЧМтМАзьНЧЃЉЛёШЁЗТЩфБфЛЛОиеѓЃЌЭЈЙ§ЗТЩфБфЛЛЪЕЯжШЫСГЕФАке§ЁЃ ФПБъЭМаЮвдЃЈx,yЃЉЮЊжсаФЫГЪБеыа§зЊІЈЛЁЖШЃЌБфЛЛОиеѓЮЊЃК
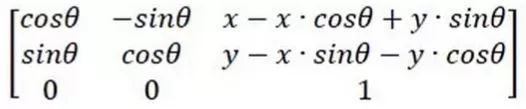
ШЫСГаЃзМЕФаЇЙћШчЭМЫљЪОЃК

4. ШЫСГЖдБШ ШЫСГБШЖдКЭШЫСГЩэЗнШЯжЄЕФЧАЬсЪЧашвЊЬсШЁШЫСГЖРгаЕФЬиеїЕуаХЯЂЁЃдкШЫСГаЃзМжЎКѓПЩвдРћгУЩюЖШЩёОЭјТчЃЌНЋЪфШыЕФШЫСГНјааЬиеїЬсШЁЁЃШчНЋ112ЁС112ЁС3ЕФСГВПЭМЯёЬсШЁ256ИіИЁЕуЪ§ОнЬиеїаХЯЂЃЌВЂНЋЦфзїЮЊШЫСГЕФЮЈвЛБъЪЖЁЃдкзЂВсНзЖЮАб256ИіИЁЕуЪ§ОнЪфШыЯЕЭГЃЌЖјШЯжЄНзЖЮдђЬсШЁЯЕЭГДцДЂЕФЪ§ОнгыЕБЧАЭМЯёаТЩњГЩЕФ256ИіИЁЕуЪ§ОнНјааБШЖдзюжеЕУЕНШЫСГБШЖдНсЙћЁЃ ЭЈЙ§ЩёОЭјТчЫуЗЈЕУЕНЕФЬиеїЕуЪОвтЭМШчЯТЃК

ЖјШЫСГБШЖддђЪЧЖд256ИіИЁЕуЪ§ОнжЎМфНјааОрРыдЫЫуЁЃМЦЫуЗНЪНГЃгУЕФгаСНжжЃЌвЛжжЪЧХЗЪНОрРыЃЌвЛжжЪЧгрЯвОрРыЁЃx,yЯђСПХЗЪНОрРыЖЈвхШчЯТЃК
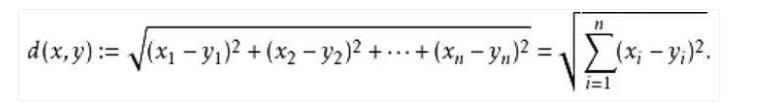
x,yЯђСПжЎМфгрЯвОрРыЖЈвхШчЯТЃК
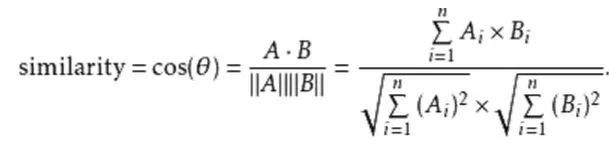
грЯвОрРыЛђХЗЪНОрРыдНДѓЃЌдђСНИіЬиеїжЕЯрЫЦЖШдНЕЭЃЌЪєгкЭЌвЛИіШЫЕФПЩФмаддНаЁЁЃШчЯТЭМЃЌЫћУЧЕФСГВПВювьжЕЮЊ0.4296 ДѓгкЩЯЮФЫљЫЕЕФИУФЃаЭзюМбуажЕ0.36ЃЌДЫЪБХаЖЯСНШЫЮЊВЛЭЌЕФШЫЃЌПЩМћНсЙћЪЧе§ШЗЕФЁЃ

АбЙщвЛЛЏЮЊ-1ЕН1ЕФЭМЯёЪ§ОнЁЂЬиеїЕуЬсШЁФЃаЭЕФВЮЪ§ЛЙгаШЫСГЪ§ОнПтЪфШыЕНШЫСГБШЖдЕФКЏЪ§НгПкface_recgnitionЃЌМДПЩЕУШЫСГШЯжЄНсЙћЁЃ
зюКѓИљОнЩЯУцЕФЫуЗЈдРэАббЕСЗЕФФЃаЭвЦжВЕНcortex-m7жаЃЌdemoШчЯТЃК ШЫСГЪЖБ№бнЪОdemo
|