| 编辑推荐: |
本文主要介绍了通过套接字(socket)建立连接、长连接和短连接的区别、长连接和短连接的选择等内容
。
本文来自于csdn,由火龙果软件Anna编辑推荐。 |
|
一个完整的软件系统大多数情况下是由多个进程共同协作进行的,哪怕它们在同一台服务器上。所以,进程之间如何进行高效的通信至关重要。
单个应用程序+单个数据库这套基础开发套餐我相信每个人都经历过,甚至在初期它们还有可能部署在同一台服务器上。既然应用程序和数据库分属于两个不同的进程,所以这个问题本质上还是两个进程之间的通信问题。
两个进程之间如果要通信,很显然必须要建立一个连接,通过它来相互传输数据。原则上,如果两个进程在同一台服务器上,有很多种方式可以进行相互通信。不过在分布式系统中,不同的进程很多时候被部署在不同的服务器上。所以我们这次只聊基于TCP/IP的通信方式,因为对大家来说这是最普遍会用到的方式,不管是应用程序间的远程调用(RPC)还是应用程序与数据库间的调用(DAL),皆是如此。
通过套接字(socket)建立连接
socket与TCP/IP之间是唇齿相依般的关系,联系紧密,先来看下维基百科对socket的定义。
socket是计算机网络中用于在节点内发送或接收数据的内部端点。具体来说,它是网络软件(协议栈)中这个端点的一种表示,包含通信协议、目标地址、状态等,是系统资源的一种形式。
它在网络中所处的位置大致就是下面的黑色部分,应用层与传输层之间。
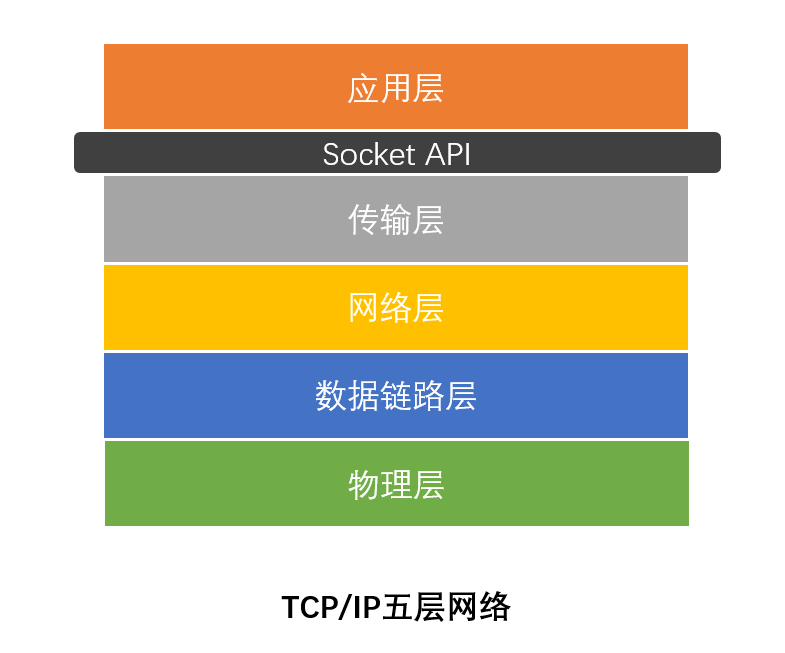
其中的传输层就是TCP/IP所在的地方,而你平时通过代码编写的应用程序大多属于应用层范畴,socket在这里起到就是连接应用层与传输层的作用。
socket的诞生是为了应用程序能够更方便的将数据经由传输层来传输,所以它本质上就是对TCP/IP的运用进行了一层封装,然后应用程序直接调用socket
API即可进行通信。那么它是如何工作的呢?它分为2个部分,服务端需要建立socket来监听指定的地址,然后等待客户端来连接。而客户端则需要建立socket并与服务端的socket地址进行连接。
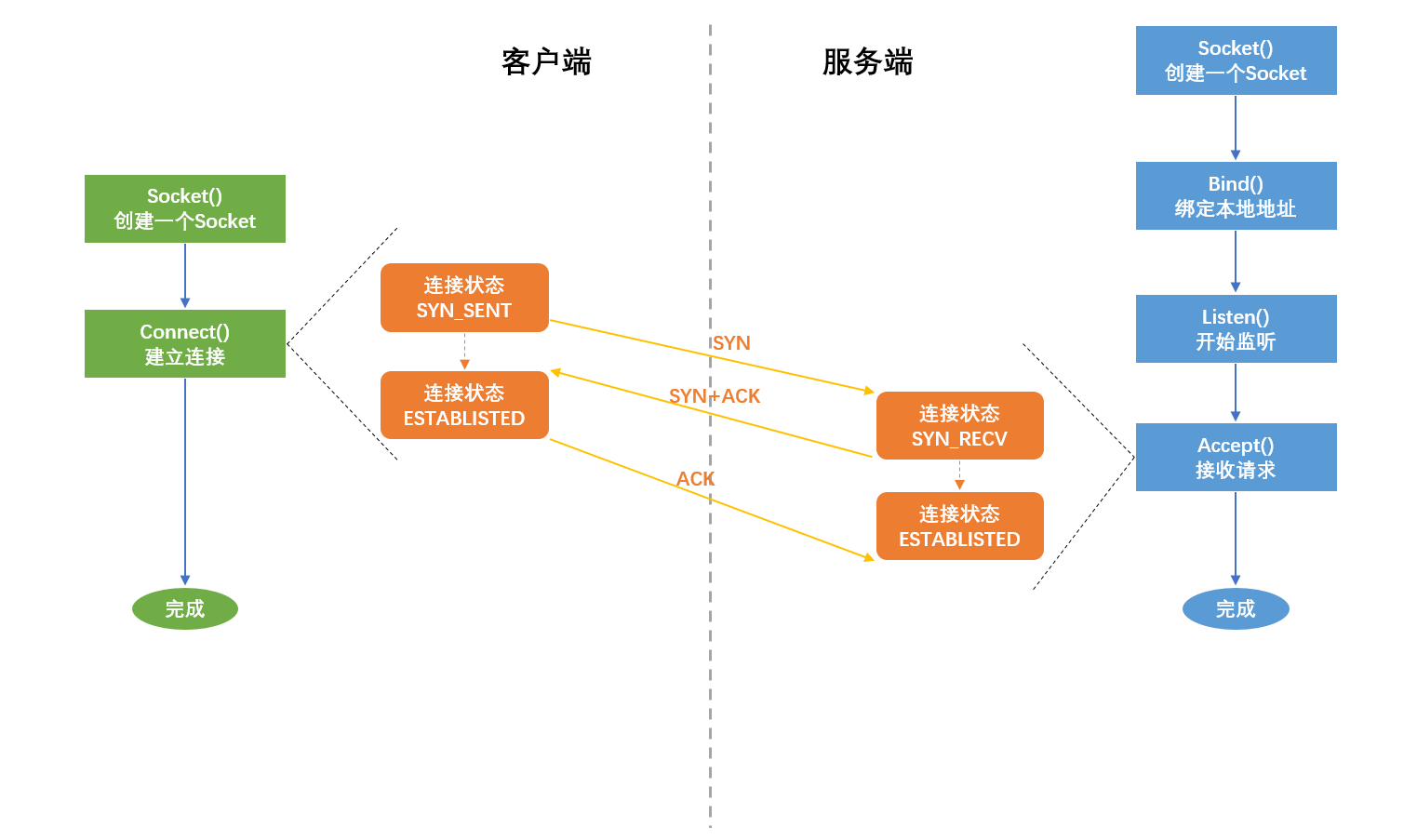
这图展示的就是建立TCP/IP连接的过程,经典的叫法为“三次握手”的过程。顾名思义,这个过程中来回产生了三次网络通信。
接下来的数据传输过程就简单很多,发送数据就是客户端往服务端通信,服务端处理完之后的数据返回则相反。
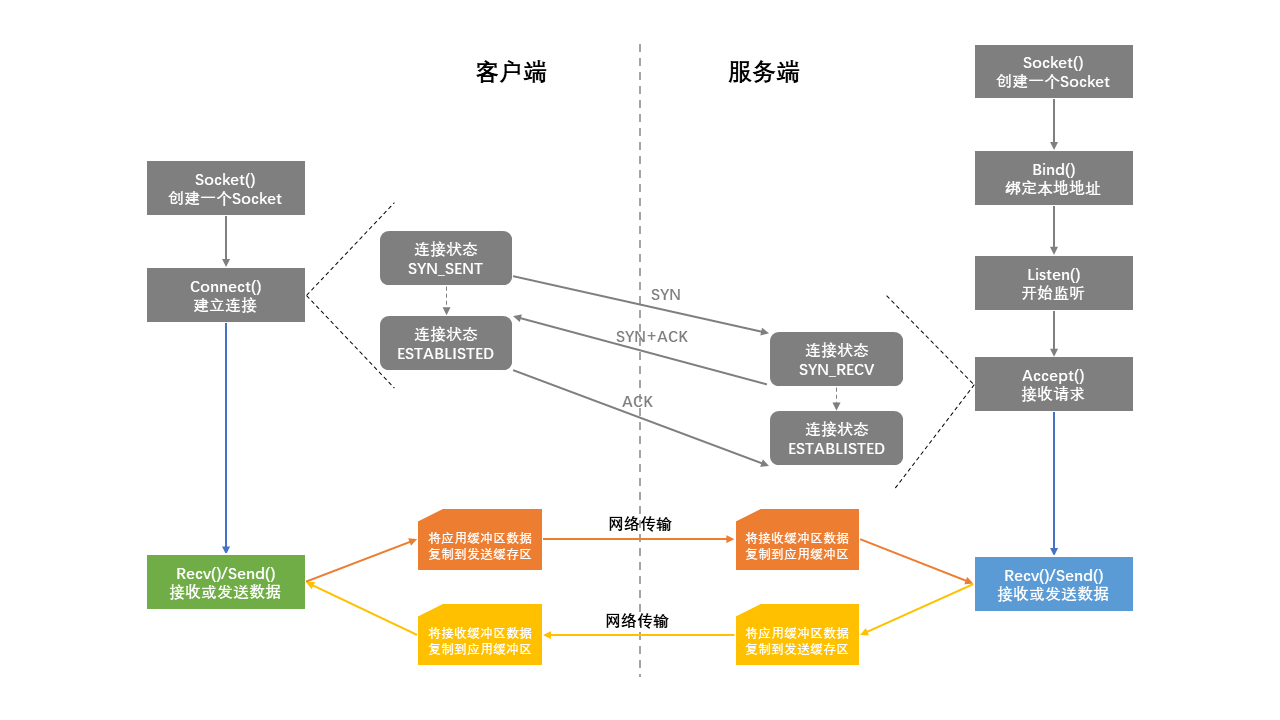
值得注意的是,传输的过程涉及到数据Copy,不过这些Copy是必不可少的。其中的发送缓冲区和接收缓冲区就是套接字缓存(socket
buffer)。
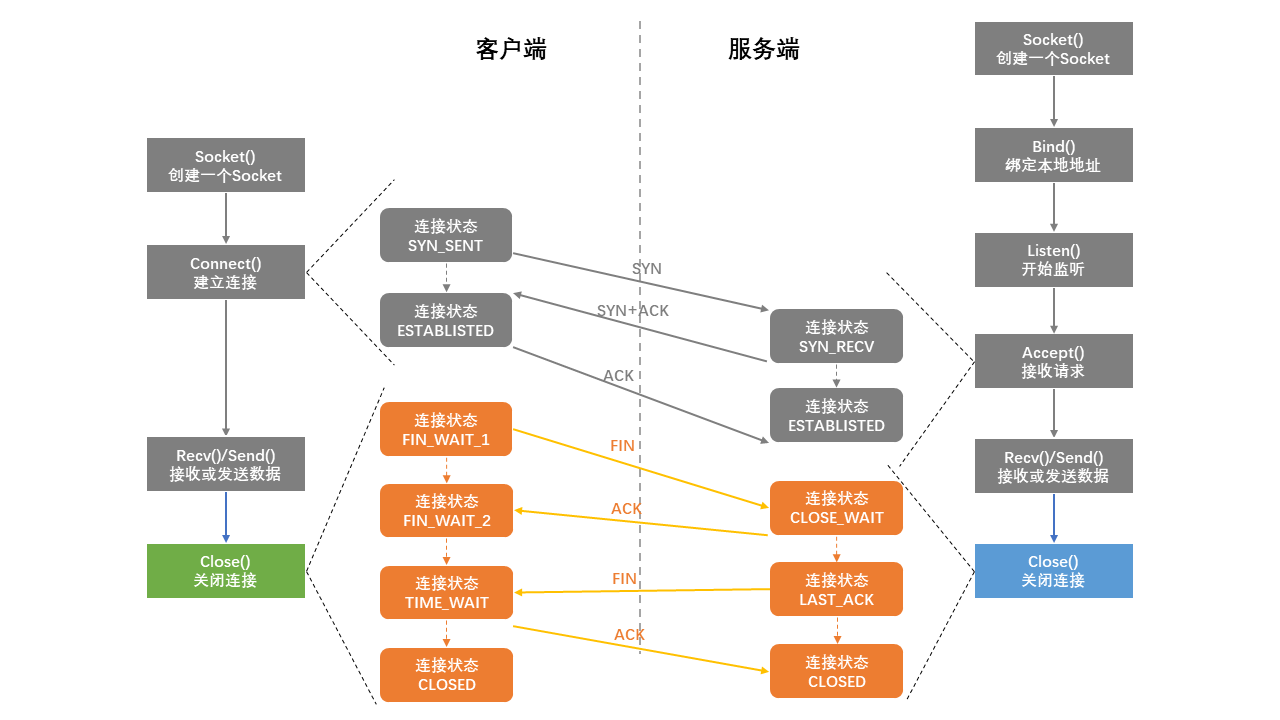
连接使用完之后需要关闭,不过TCP/IP连接关闭过程比创建更复杂一些,次数多了一次,这就是经典的“四次握手”过程。
简单总结一下socket。socket是进程间数据传输的媒介,为了保证连接的可靠,你需要特别注意建立连接和关闭连接的过程。为了确保准确、完整的数据传输,客户端和服务端来回进行了多次网络通信才得以完成连接的创建和关闭,这同时也是你在运用一个连接时所花费的额外成本。
基于socket我们可以选择建立长连接或者短连接,在实际运用中两者都有可能被用到。
长连接和短连接的区别
先带你来认识一下它俩的区别。
长连接意味着进行一次数据传输后,不关闭连接,长期保持连通状态。如果两个应用程序之间有新的数据需要传输,则直接复用这个连接,无需再建立一个新的连接。就像下图这样。
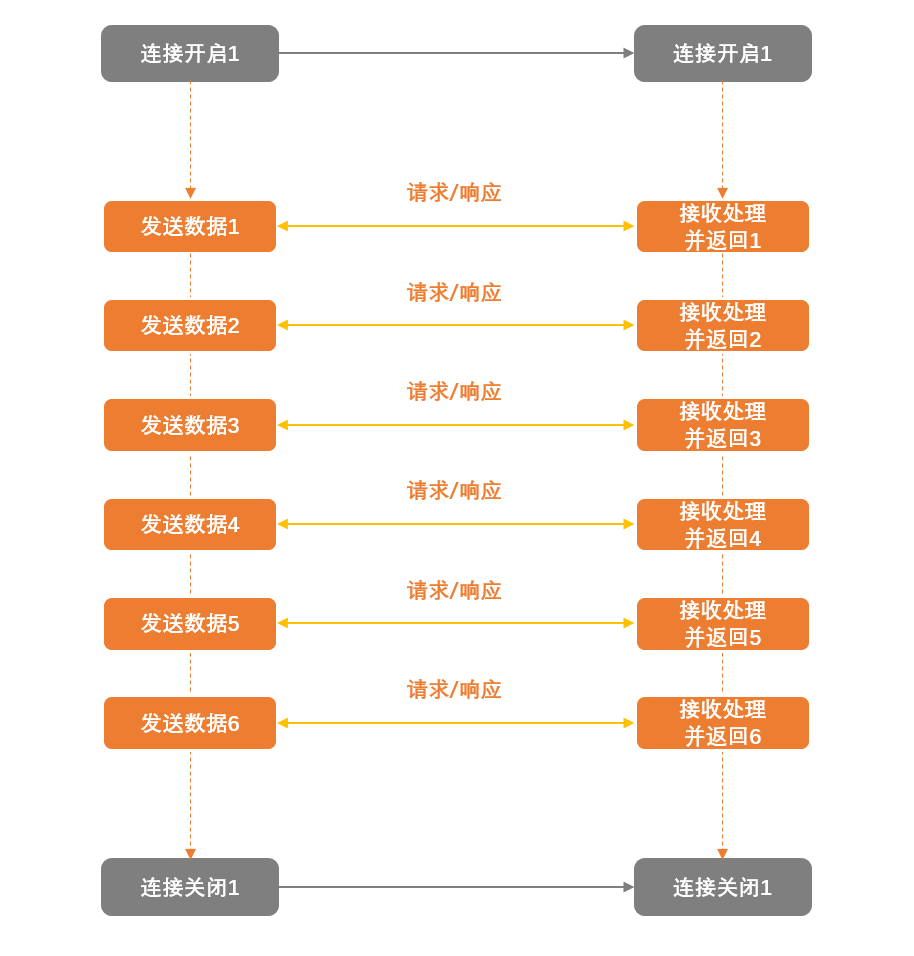
它的优势是在多次通信中可以省去连接建立和关闭连接的开销,并且从总体上来看,进行多次数据传输的总耗时更少。缺点是需要花费额外的精力来保持这个连接一直是可用的,因为网络抖动、服务器故障等都会导致这个连接不可用,甚至是由于防火墙的原因。所以,一般我们会通过下面这几种方式来做“保活”工作,确保连接在被使用的时候是可用状态:
利用TCP自身的保活(Keepalive)机制来实现,保活机制会定时发送探测报文来识别对方是否可达。一般的默认定时间隔是2小时,你可以根据自己的需要在操作系统层面去调整这个间隔,不管是Linux还是Windows系统。
上层应用主动的定时发送一个小数据包作为“心跳”,探测是否能成功送达到另外一端。 保活功能大多数情况下用于服务端探测客户端的场景,一旦识别客户端不可达,则断开连接,缓解服务端压力。
提前多说一句,如果在做了高可用的分布式系统场景中运用长连接会更麻烦一些。因为高可用必然包含自动故障转移、故障隔离等机制。这恰恰导致了一旦发生故障,客户端需要及时发现哪些连接已处于不可用状态,并进行相应的重连,包括重新做负载均衡等工作。
了解完了长连接,那么短连接就很容易理解了。短连接意味着每一次的数据传输都需要建立一个新的连接,用完再马上关闭它。下次再用的时候重新建立一个新的连接,如此反复。
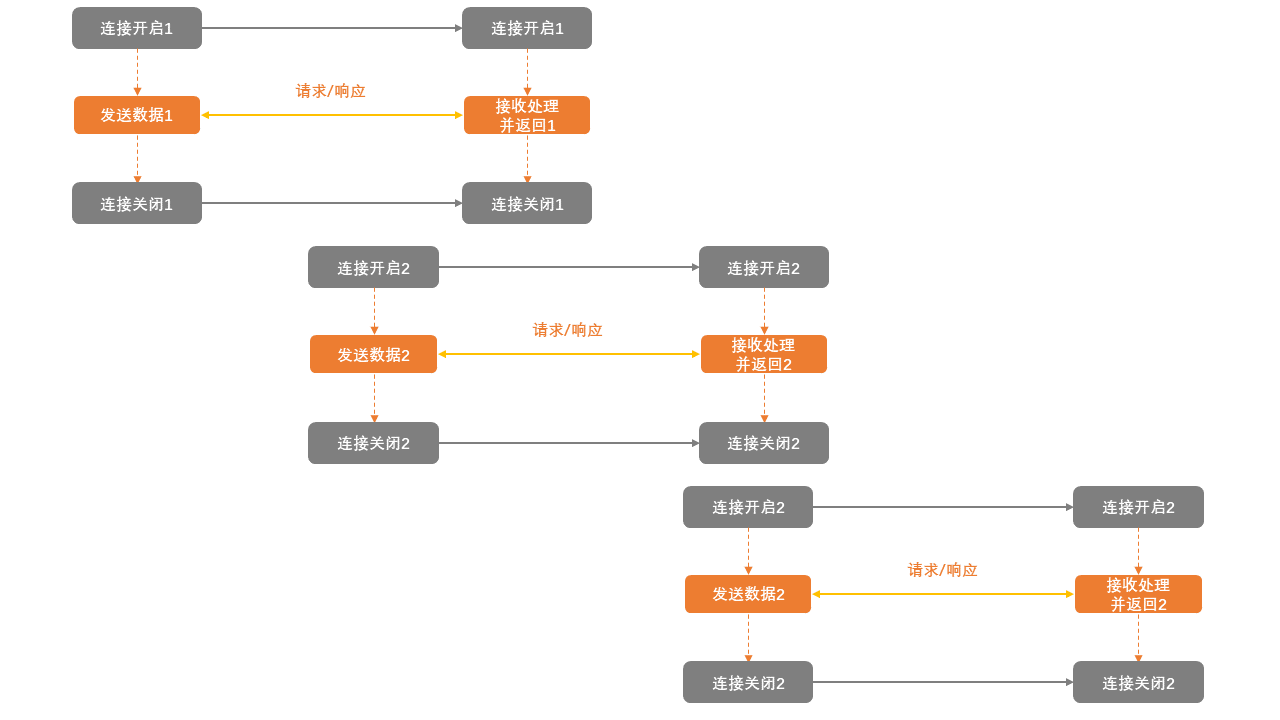
它的优势是由于每次使用的连接都是新建的,所以基本上只要能够建立连接,数据就大概率能送达到对方。并且哪怕这次传输出现异常也不用担心影响后续新的数据传输,因为届时又是一个新的连接。缺点是每个连接都需要经过三次握手和四次握手的过程,耗时大大增加。
另外,短连接还有一个致命的缺点。我们回到前面提到的维基百科对socket的定义,其中说到socket包含通信协议、目标地址、状态等。实际当你在基于socket进行开发的时候,这些包含的具体资源主要就是这5个:源IP、源端口、目的IP、目的端口、协议,有个专业的叫法称之为“五元组”。在一台计算机上只要这五元组的值不重复,那么连接就可以被建立。然而一台计算机最多只能开启65535个端口,如果现在两个进程之间需要通信,作为服务端的IP和端口必然是固定的,因此单个客户端理论上最多只能与服务端同时建立65535个socket连接。如果除去操作系统和其它进程所占用的端口,实际还会更少。所以,一旦使用不当,在很短的时间内建立了大量连接,端口很容易被占用完。这不但会导致自身无法正常工作,还会影响到同一台计算机上的其它进程。
我猜你在项目中大多数情况使用的是短连接的方式,因为这对我们编程来说可以少考虑很多问题,潜在的这些缺点可能是你没有遇到或者意识到而已。存在必有其价值,接下去我们根据实际的案例让你清楚知道如何来选择它们。
长连接和短连接的选择
我想你肯定见过一些监控或者实时报价类系统,比如股票软件,它需要在几秒之内刷新最新的价格。像这种场景中同时包含了需要运用长连接的三个主要因素:高频、服务端主动推送和有状态。
高频的原因我想你根据前面的内容也明白了,因为频次越高的话,使用短连接带来的建立连接和关闭连接的总开销越大。
而服务端主动推送也需要长连接的原因是,由于服务端往往是“中心化”的,一般都是1个服务端为多个客户端提供服务。所以,如果使用短连接的方式,那么在客户端未主动连接到服务端的情况下,服务端并不知道需要往哪些客户端去推送数据,这是原因之一。所以此时,长连接成为了一个很好的选择。另外一个原因是,哪怕客户端通过定时的短连接轮询方式进行主动连接,除了增加了额外的建立连接和关闭连接的开销外,还可能遇到通信完成后结果数据并未发生变化,做了无用功。
成熟股票软件的服务端,为了支撑更多的用户以及做高可用,必然部署了多台。但是这个业务场景,用户无法容忍由于多个服务端之间数据同步的误差导致他在客户端看到的价格刷新产生“回退”现象。所以,只能尽量保持一直连接在同一台服务器上,才能避免这个情况。这种场景被称之为“有状态”,也可以理解为是“串行”的,因为多次请求的前后需要保持“连续性”。
短连接则更适用于诸如阅读类软件的场景中,例如,很多时候用户点开一篇文章后需要花一些时间进行阅读,这个时间有长有短,并且直到用户下一次操作之前都没有数据传输发生。这个场景中包含了运用短连接的两个主要因素:低频、无状态。
因为低频,所以更能容忍建立连接和关闭连接的开销。
用户的下一次点击往往跳转到了其它文章,并且新打开的与当前文章并不需要具有“连续性”,所以这种场景我们称之为“无状态”的。另外,理论上同一时刻打开几篇文章也不会存在什么不妥。
通过这两个案例我们可以总结出一个决定何时运用长连接和短连接的最佳实践。
长连接适用于:两个进程之间需要高频通信并且具备服务端主动推送或者有状态(需串行)两者之一的场景,否则并不是必选项。
短连接适用于:两个进程之间通信频率较低,或者属于无状态(可并行)的场景,否则并不是必选项。
其它情况就根据所需的侧重点来,比如侧重性能就长连接,侧重编码的便捷性就选择短连接。
总结
至此,相信你应该清楚了长连接和短连接在跨进程通信中该如何选择,而且还对通过socket建立TCP连接有了一定的认识。你在实际的工作中可能遇到的场景千奇百怪,只需要保持先识别所处场景的特点,再基于这些特点来作出选择的习惯,必然至少是个不错的决策。
不过有时候我们可能需要一个中庸的方案来作为默认选择,因为很多场景中的请求并不是平稳的,甚至波动会较大,而且可能同时存在有状态和无状态的场景,此时如果单方面的选择长连接或者短连接都会产生较多的资源浪费。那么我们可以通过增加一些复杂度来实现一个能够综合长连接和短连接各自优点的方案:建立多个长连接,每次数据传输的时候独占使用,用完之后放回,再给后续使用。这种方案被称之为“连接池”。例如,很多的数据库访问框架都内置了连接池机制,因为作为底层框架的它不知道会被使用到何种场景的系统中,所以提供了这个选项。
连接池的运作流程大致如下图。除了上面所说的,独占使用,用完放回之外,一般都会在应用程序启动时预先建立好指定数据量的连接,以更好应对冷启动后请求数快速上升带来的资源竞争问题,这个数量一般称之为最小连接数。另外,如果新的请求进来时,所有已建立的连接都在使用中,但是连接数的上限未达到指定数量,可以再建立新的长连接来使用,用完依旧放回到空闲池,相当于把连接池扩大了,这个上限数量一般称之为最大连接数。
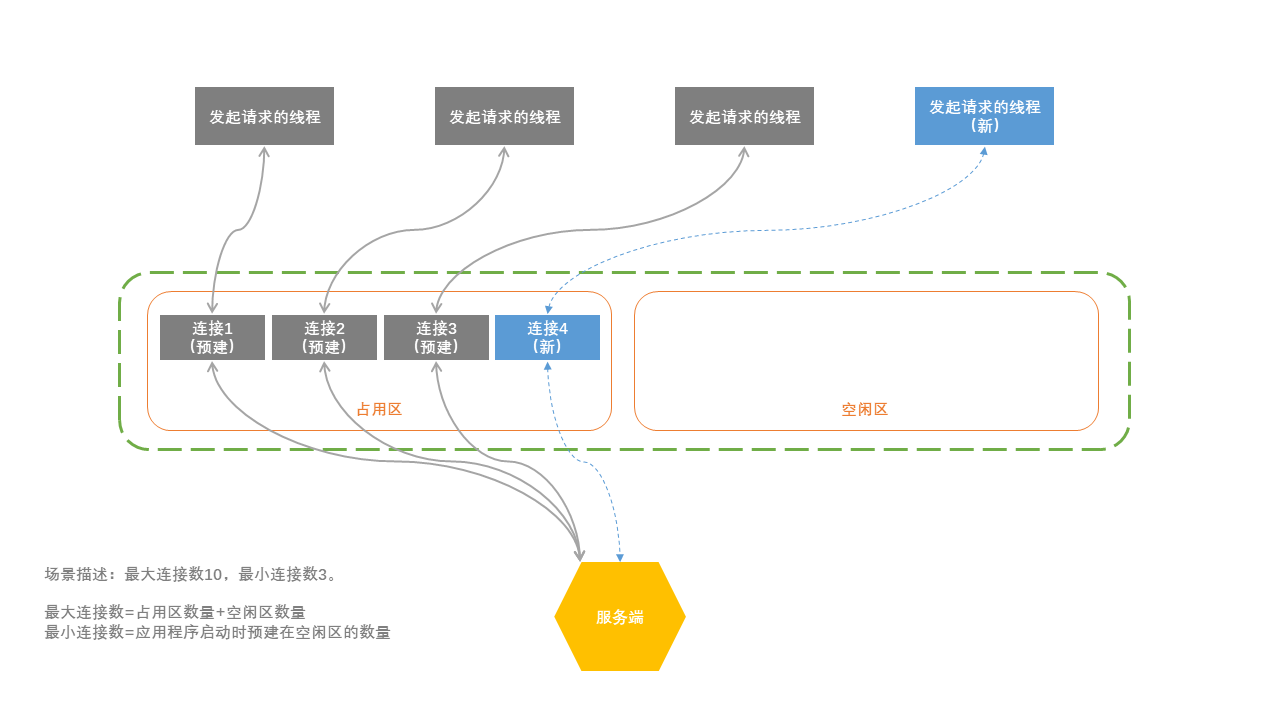
不知道大家对长连接和短连接的运用有什么样的经验和认识呢?欢迎在下方评论区留言,我们一起讨论。 |









