| 编辑推荐: |
本文主要介绍Raft算法的原理、工程化时遇到的问题与解决方案、以及改进性能的措施,,希望对您的学习有所帮助。
本文来自于云社区,由火龙果软件Alice编辑推荐。 |
|
导语
Raft算法是一种分布式一致性算法。与paxos相比,它更易理解和工程化。我们完整实现了该算法并将其应用在自研的高可靠消息中间件CMQ中,同时沉淀出对外通用的Raft算法库。本文主要介绍Raft算法的原理、工程化时遇到的问题与解决方案、以及改进性能的措施。
一、背景介绍
分布式系统是指一组独立的计算机,通过网络协同工作的系统,客户看来就如同单台机器在工作。随着互联网时代数据规模的爆发式增长,传统的单机系统在性能和可用性上已经无法胜任,分布式系统具有扩展性强,可用性高,廉价高效等优点,得以广泛应用。
但与单机系统相比,分布式系统在实现上要复杂很多。CAP理论是分布式系统的理论基石,它提出在以下3个要素中:
Consistency(强一致性):任何客户端都可以读取到其他客户端最近的更新。
Availability(可用性): 系统一直处于可服务状态。
Partition-tolenrance(分区可容忍性):单机故障或网络分区,系统仍然可以保证强一致性和可用性。
一个分布式系统最多只能满足其中2个要素。对于分布式系统而言,P显然是必不可少的,那么只能在AP和CP之间权衡。AP系统牺牲强一致性,这在某些业务场景下(如金融类)是不可接受的,CP系统可以满足这类需求,问题的关键在于会牺牲多少可用性。传统的主备强同步模式虽然可以保证一致性,但一旦机器故障或网络分区系统将变得不可用。paxos和raft等一致性算法的提出,弥补了这一缺陷。它们在保证CP的前提下,只要求大多数节点可以正常互联,系统便可以一直处于可用状态,可用性上显著提高。paxos的理论性偏强,开发者需要自己处理很多细节,这也是它有很多变种的原因,相对而言raft更易理解和工程化,一经提出便广受欢迎。
在我们关注的消息中间件领域,金融支付类业务往往对数据的强一致性和高可靠性有严格要求。强一致性:A给B转账100元,系统返回A转账成功。此后B查询余额时应该能显示收到100元,如果发现并未收到或隔一段时间后才收到,那这样的系统非强一致性;高可靠性:一个请求如果返回客户成功,那么需要保证请求结果不丢失。
在对主流的消息中间件进行调研后,发现它们在应对这种场景时都存在一定的不足:
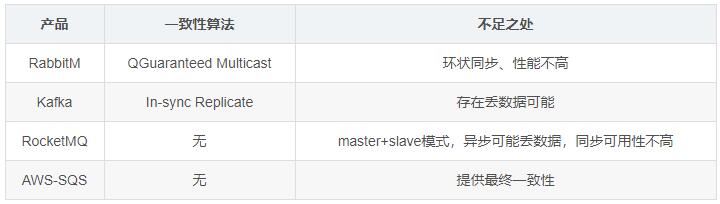
RabbitMQ:一个请求需要在所有节点上处理2次才能保证一致性,性能不高。
Kafka: kafka主要应用在日志、大数据等方向,少量丢失数据业务可以忍受,但不适合要求数据高可靠性的系统。
RocketMQ:未采用一致性算法,如果配置成异步模式可能丢失数据,同步模式下节点故障或网络分区都会影响可用性。
SQS:只提供最终一致性,不保证强一致性。
鉴于以上分析,我们设计开发了基于Raft的强一致高可靠消息中间件CMQ。接下来会详细介绍raft算法原理细节、如何应用在CMQ中在保证消息可靠不丢失以及实现过程中我们在性能方面所作的优化。
二、Raft算法核心原理
2.1 概述
raft算法是Diego Ongaro博士在论文《In Search of an Understandable
Consensus Algorithm》,2014 USENIX中首次提出,算法主要包括选举和日志同步两部分:
第一阶段 选举:
从集群中选出一个合适的节点作为Leader。
第二阶段 日志同步:
选举出的Leader接收客户端请求,将其转为raft日志。
Leader将日志同步到其他节点,当大多数节点写入成功后,日志变为Committed,一经Committed日志便不会再被篡改。
Leader故障时,切换到第一阶段,重新选举。
以下是贯穿raft算法的重要术语:
Term: 节点当前所处的周期,可以看作一个文明所处的时代。
votedFor: 当前Term的投票信息,每个节点在给定的Term上只能投票一次。
**Entry: **raft日志中的基本单元,包含index、term和user_data。其中index在日志文件中顺序分配,term为创建该entry的leader
term,user_data 业务数据。
State : 节点角色(Leader、Candidate、Follower之一)。
CommitIndex:已提交到的日志Index。
State Machine:状态机。业务模块,与Raft交互。
ApplyIndex:已应用到的日志Index。
ElectionTime:选举超时时间。
节点之间通过RPC通信来完成选举和日志同步,发送方在发送RPC时会携带自身的Term,接收方在处理RPC时有以下两条通用规则:
RPC中的RTerm大于自身当前Term,更新自身Term = RTerm、votedFor = null,转为Follower。
RPC中的RTerm小于自身当前Term,拒绝请求,响应包中携带自身的Term。
2.2 选举
Raft算法属于强Leader模式,只有Leader可以处理客户端的请求,Leader通过心跳维持自身地位,除非Leader故障或网络异常,否则Leader保持不变。选举阶段的目的就是为了从集群中选出合适的Leader节点。
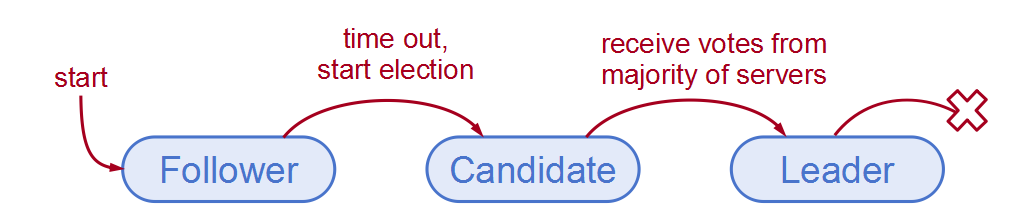
选举流程:
1.节点初始状态均为Follower,Follower只被动接收请求,如果ElectionTime到期时仍未收到Leader的AppendEntry
RPC,Follower认为当前没有Leader,转为Candidate。
2.Candidate在集群中广播RequestVote RPC,尝试竞选Leader,其他节点收到后首先判断是否同意本次选举,并将结果返回给Candidate。如果Candidate收到大多数节点的同意响应,转为Leader。
3.Leader接收客户端请求,将其转为Entry追加到日志文件,同时通过AppendEntry RPC同步日志Entry给其他节点。
下面通过一个案例详细说明选举流程。
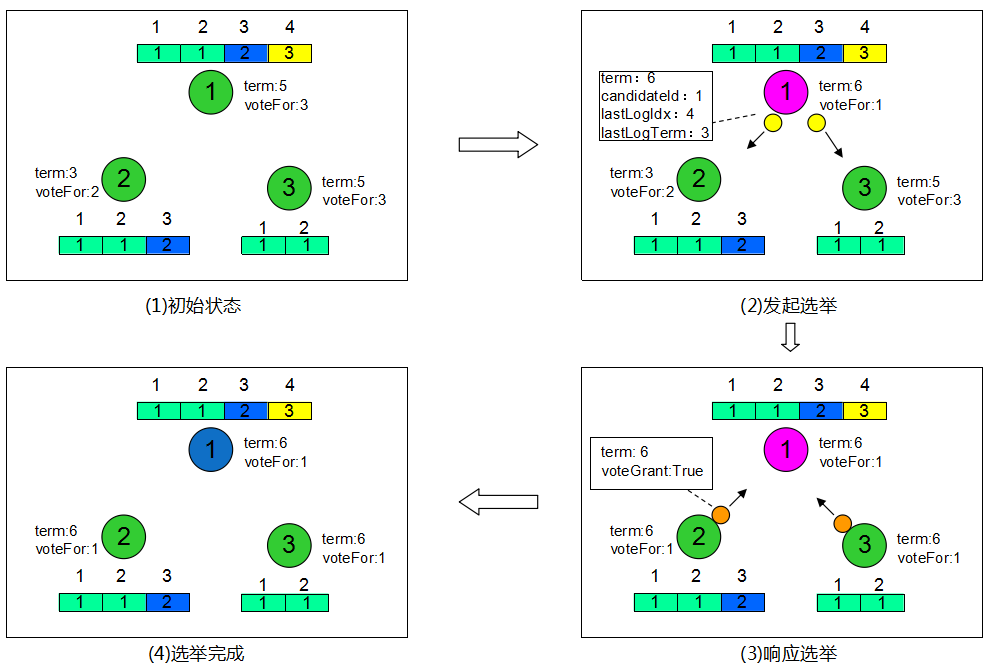
1)初始状态:3个节点组成的集群,初始均为Follower状态,图中方格部分代表节点的raft日志。
2)发起选举:节点1选举定时器先到期,转为Candidate,Term自增,更新voteFor=1(投票给自己),接着广播RequestVote
RPC给集群中其他节点,RequestVote RPC会携带节点的日志信息。
3)响应选举:节点2和3收到RequestVote RPC后,根据RPC规则,更新term和voteFor(term:6
, voteFor:null );然后判断是否同意本次选举,如果已投票给别人,则拒绝本次选举(这里voteFor:null
未投票),如果RequestVote RPC中的日志没有自身全,也拒绝,否则同意(这里节点1的日志比2、3都更全);最后通过voteReply
RPC响应投票结果。
4)选举完成:由于节点2和3都同意本次选举,所以节点1在收到任何一个的voteReply
RPC便转为Leader(大多数同意即可)。
选举超时值:
在选举时可能会出现两个节点的选举定时器同时到期并发起选举,各自得到一半选票导致选举失败,选举失败意味着系统没有Leader,不可服务。如果选举定时器是定值,很可能两者再次同时到期。为了降低冲突的概率,选举超时值采用随机值的方式。此外,选举超时值如果过大会导致Leader故障会很久才会再次选举。选举超时值通常取300ms~600ms之间的随机值。
2.3日志同步
选举阶段完成后,Leader节点开始接收客户端请求,将请求封装成Entry追加到raft日志文件末尾,之后同步Entry到其他Follower节点。当大多数节点写入成功后,该Entry被标记为committed,raft算法保证了committed的Entry一定不会再被修改。
日志同步具体流程:
1)Leader上为每个节点维护NextIndex、MatchIndex,NextIndex表示待发往该节点的Entry
index,MatchIndex表示该节点已匹配的Entry index,同时每个节点维护CommitIndex表示当前已提交的Entry
index。转为Leader后会将所有节点的NextIndex置为自己最后一条日志index+1,MatchIndex全置0,同时将自身CommitIndex置0。
2)Leader节点不断将user_data转为Entry追加到日志文件末尾,Entry包含index、term和user_data,其中index在日志文件中从1开始顺序分配,term为Leader当前的term。
3)Leader通过AppendEntry RPC将Entry同步到Followers,Follower收到后校验该Entry之前的日志是否已匹配。如匹配则直接写入Entry,返回成功;否则删除不匹配的日志,返回失败。校验是通过在AppendEntry
RPC中携带待写入Entry的前一条entry信息完成。
4)当Follower返回成功时,更新对应节点的NextIndex和MatchIndex,继续发送后续的Entry。如果MatchIndex更新后,大多数节点的MatchIndex已大于CommitIndex,则更新CommitIndex。Follower返回失败时回退NextIndex继续发送,直到Follower返回成功。
5)Leader每次AppendEntry RPC中会携带当前最新的LeaderCommitIndex,Follower写入成功时会将自身CommitIndex更新为Min(LastLogIndex,LeaderCommitIndex)。
同步过程中每次日志的写入均需刷盘以保证宕机时数据不丢失。
下面通过一个例子介绍日志同步基本流程:
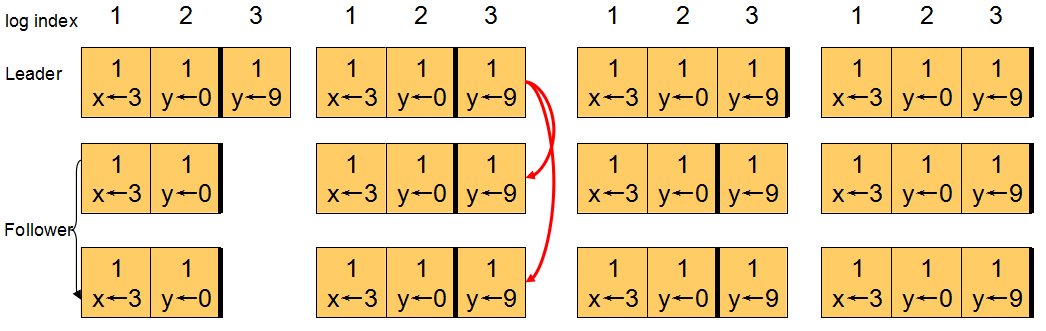
1)初始状态所有节点的Term=2,CommitIndex=2,接着Leader收到一条y←9的请求,转为Entry写入日志的末尾,Entry的index
=3 term =1。
2)Leader通过AppendEntry RPC同步该Entry给2个Follower,RPC中包含前一条Entry信息(index=2
term =1),Follower收到后首先校验前一条Entry是否与自身匹配(这里匹配成功),之后写入该Entry,返回Leader成功。
3)Leader在收到Follower的回包后,更新相应节点的NextIndex和MatchIndex,这时大多数节点MatchIndex已经大于CommitIndex,所以Leader更新CommitIndex=3。
4)Leader继续发送AppendEntry到Follower,此时由于没有新Entry,所以RPC中entry信息为空,LeaderCommitIndex为3。Follower收到后更新CommitIndex=3
(Min(3,3))。
日志冲突:
在日志同步的过程中,可能会出现节点之间日志不一致的问题。例如Follower写日志过慢、Leader切换导致旧Leader上未提交的脏数据等场景下都会发生。在Raft算法中,日志冲突时以Leader的日志为准,Follower删除不匹配部分。
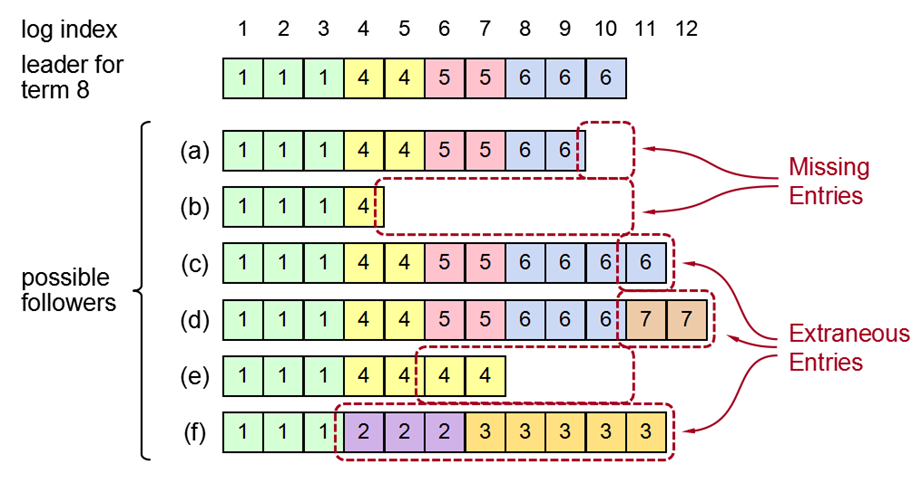
如下图所示,Follower节点与Leader节点的日志都存在不一致问题,其中(a)、(b)节点日志不全,(c)、(d)、(e)、(f)有冲突日志。Leader首先从index=11(最后一条Entry
index +1)开始发送AppendEntry RPC,Follower均返回不匹配,Leader收到后不断回退。(a)、(b)在找到第一条匹配的日志后正常同步,(c)、(d)、(e)、(f)在这个过程中会逐步删除不一致的日志,最终所有节点的日志都与Leader一致。成为Leader节点后不会修改和删除已存在的日志,只会追加新的日志。
2.4 算法证明
Raft算法的2个核心属性:
1)已提交的日志不会再修改;(可靠性)
2)所有节点上的数据一致。(一致性)
具体证明如下:
1)Leader Completeness:给定Term上提交的日志一定存在于后续更高Term的 Leader上。(日志不丢失)
选举出的Leader一定包含当前已提交所有日志:已提交的日志存在于大多数节点上,而同意选举的前提是候选者的日志必须够全或更新。一个不包含已提交日志的节点必然不会得到大多数节点的选票(这些节点上都有已提交的日志,不满足日志足够全的前提),也就无法成为Leader。
Leader节点不修改和删除已存在日志(算法的约束)。
综上所述,选举和日志同步时都不会破坏已提交的日志,得证。
2)State Machine Safety:所有节点的数据最终一致。
根据Leader Completeness可知已提交的日志不会再修改,业务的状态机依次取出Entry中的user_data应用,最终所有节点的数据一致。
2.5集群管理
Raft算法中充分考虑了工程化中集群管理问题,支持动态的添加节点到集群,剔除故障节点等。下面详细描述添加和删除节点流程。
添加节点
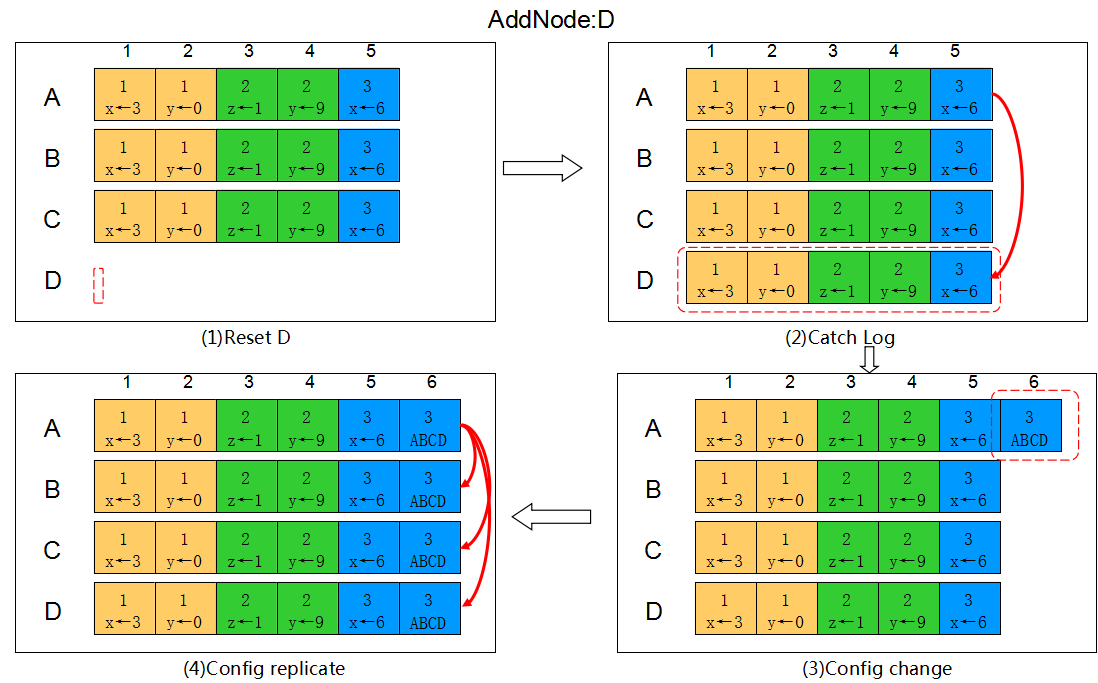
如下图所示,集群中包含A B C,A为Leader,现在添加节点D。
1)清空D节点上的所有数据,避免有脏数据。
2)Leader将存量的日志通过AppendEntry RPC同步到D,使D的数据跟上其他节点。
3)待D的日志追上后,Leader A创建一条Config Entry,其中集群信息包含ABCD。
4)Leader A将Config Entry同步给B C D,Follower收到后应用,之后所有节点的集群信息都变为ABCD,添加完成。
注:在步骤2过程中,Leader仍在不断接收客户请求生成Entry,所以只要D与A日志相差不大即认为D已追上。
删除节点
如下图所示,集群中原来包含A B C D,A为Leader,现在剔除节点D。
1) Leader A创建一条Config Entry,其中集群信息为ABC。
2) A将日志通过AppendEntry RPC同步给节点B C。
3) A B C在应用该日志后集群信息变为ABC,A不再发送AppendEntry给D,D从集群中移除。
4) 此时D的集群信息依旧为ABCD,在选举超时到期后,发起选举,为了防止D的干扰,引入额外机制:所有节点在正常接收Leader的AppendEntry时,拒绝其他节点发来的选举请求。
5) 将D的数据清空并下线。
2.6 Raft应用
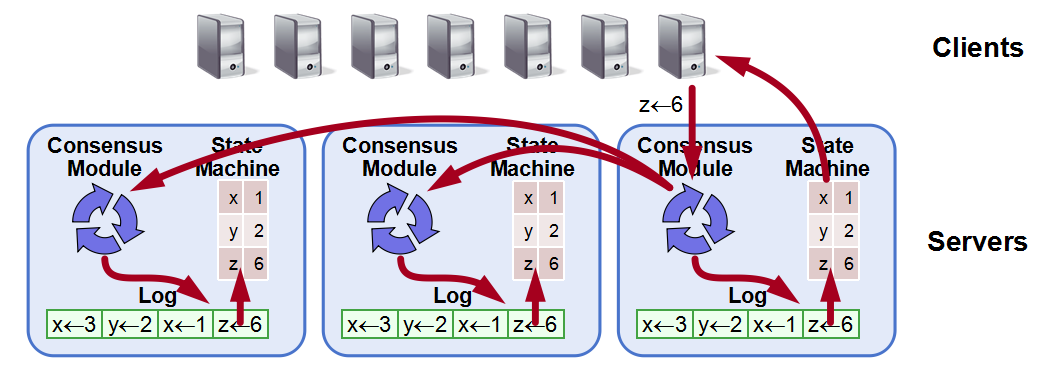
我们用State Matchine统一表示业务模块,其通过ApplyIndex维护已应用到的日志index。以下为Raft与状态机交互的流程:
1)客户端请求发往Leader节点。
2)Leader节点的Raft模块将请求转为Entry并同步到Followers。
3)大多数节点写入成功后Raft模块更新CommitIndex。
4)各节点的State Machine顺序读取ApplyIndex+1到CimmitIndex之间的Entry,取出其中的user_data并应用,完成后更新ApplyIndex。
5)Leader 上的State Machine通知客户端操作成功。
6)如此循环。
2.7 快照管理
在节点重启时,由于无法得知State Matchine当前ApplyIndex(除非每次应用完日志都持久化ApplyIndex,还要保证是原子操作,代价较大),所以必须清空State
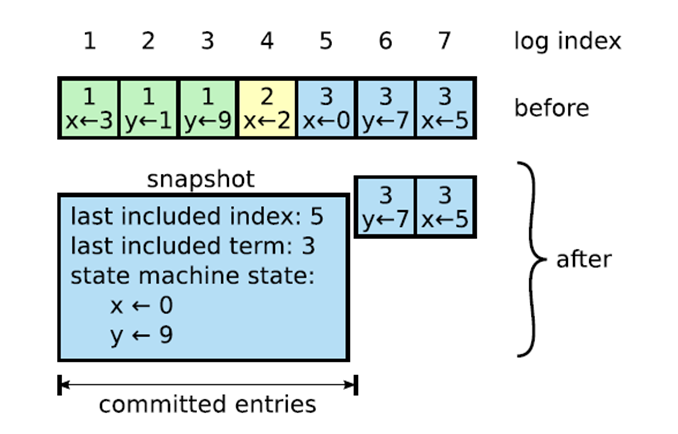
Matchine的数据,将ApplyIndex置为0,,从头开始应用日志,代价太大,可以通过定期创建快照的方式解决该问题。如下图所示:
1) 在应用完Entry 5 后,将当前State Matchine的数据连同Entry信息写入快照文件。
2) 如果节点重启,首先从快照文件中恢复State Matchine,等价于应用了截止到Entry
5为止的所有Entry,但效率明显提高。
3) 将ApplyIndex置为5,之后从Entry 6继续应用日志,数据和重启前一致。
快照的优点:
降低重启耗时:通过snapshot + raft log恢复,无需从第一条Entry开始。
节省空间:快照做完后即可删除快照点之前的Raft日志。
2.8 异常场景及处理
Raft具有很强的容错性,只要大多数节点正常互联,即可保证系统的一致性和可用性,下面是一些常见的异常情况,以及他们的影响及处理:
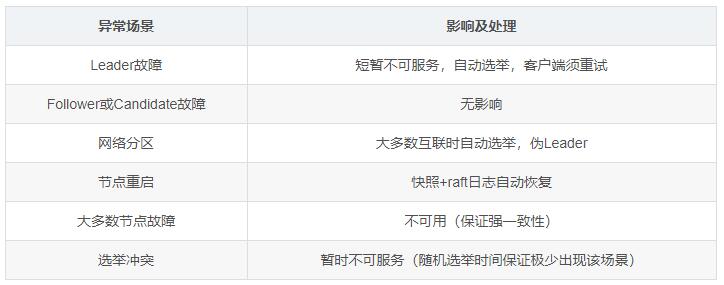
异常场景 影响及处理
Leader故障 短暂不可服务,自动选举,客户端须重试
Follower或Candidate故障 无影响
网络分区 大多数互联时自动选举,伪Leader
节点重启 快照+raft日志自动恢复
大多数节点故障 不可用(保证强一致性)
选举冲突 暂时不可服务(随机选举时间保证极少出现该场景)
可以看到异常情况对系统的影响很小,即使是Leader故障也可以在极短的时间内恢复,任何情况下系统都一直保持强一致性,为此牺牲了部分可用性(大多数节点故障时,概率极低)。不过,Leader故障时新的Leader可能会包含旧Leader未提交或已提交但尚未通知客户端的日志,由于算法规定成为Leader后不允许删除日志,所以这部分日志会被新Leader同步并提交,但由于连接信息丢失,客户端无法得知该情况,当发起重试后会出现重复数据,需要有幂等性保证。此外,raft的核心算法都是围绕Leader展开,网络分区时可能出现伪Leader问题,也需要特殊考虑。
以下是网络分区时产生伪Leader 的过程:
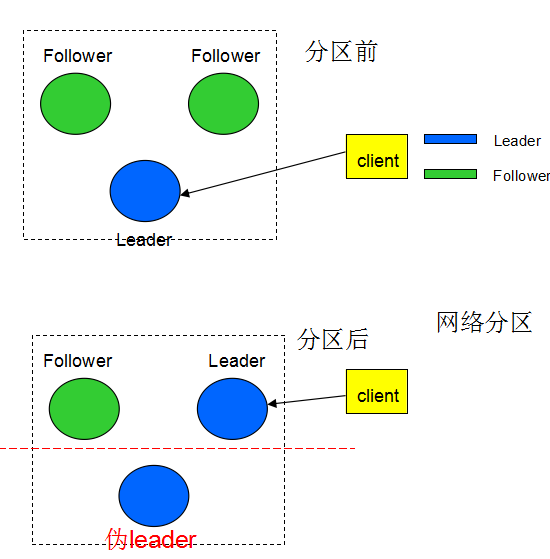
上述情况下,Leader与2个Follower网络异常,而2个Follower之间通信正常,由于收不到Leader的心跳,其中一个Follower发起选举并成为Leader,原Leader成为伪Leader,接下来我们分析该场景下是否会影响系统的一致性:
写一致性:发往新Leader的写请求可以被提交,而发往伪Leader的请求无法得到提交,只有一个Leader在正常处理写请求,所以不影响写一致性。
读一致性:如果读请求不经过Raft同步,那么当客户端的写请求被发往新Leader并执行成功后,读请求发往了伪Leader并得到结果,就会造成数据不一致。有两种方案可以解决该问题:
读请求也经过Raft同步,这样就不会有不一致的问题,但会增加系统负载。
读请求收到后,Leader节点等待大多数节点再次响应心跳RPC,接着返回结果。
因为大多数节点响应心跳,说明当前一定没有另一个Leader存在(大多数节点还与当前Leader维持租约,新Leader需要得到大多数投票)。
2.9 小结
Raft算法具备强一致、高可靠、高可用等优点,具体体现在:
强一致性:虽然所有节点的数据并非实时一致,但Raft算法保证Leader节点的数据最全,同时所有请求都由Leader处理,所以在客户端角度看是强一致性的。
高可靠性:Raft算法保证了Committed的日志不会被修改,State Matchine只应用Committed的日志,所以当客户端收到请求成功即代表数据不再改变。Committed日志在大多数节点上冗余存储,少于一半的磁盘故障数据不会丢失。
高可用性:从Raft算法原理可以看出,选举和日志同步都只需要大多数的节点正常互联即可,所以少量节点故障或网络异常不会影响系统的可用性。即使Leader故障,在选举超时到期后,集群自发选举新Leader,无需人工干预,不可用时间极小。但Leader故障时存在重复数据问题,需要业务去重或幂等性保证。
高性能:与必须将数据写到所有节点才能返回客户端成功的算法相比,Raft算法只需要大多数节点成功即可,少量节点处理缓慢不会延缓整体系统运行。
|









