| БрМЭЦМі: |
БОЮФЯъЯИНщЩмСЫTCPавщЃЌАќРЈЗжЮіУПВПЗжЕФКЌвхКЭзїгУЃЌВЂЬжТлСЫ
tcpОЙ§ЕФШ§ДЮЮеЪжНЈСЂСЌНг, ЫФДЮЛгЪжЖЯПЊСЌНгЁЃ
БОЮФРДздгкCSDNЃЌгЩЛ№СњЙћШэМўAliceБрМЭЦМіЁЃ |
|
TCPавщ
TCPавщШЋГЦ: ДЋЪфПижЦавщ, ЙЫУћЫМвх, ОЭЪЧвЊЖдЪ§ОнЕФДЋЪфНјаавЛЖЈЕФПижЦ.
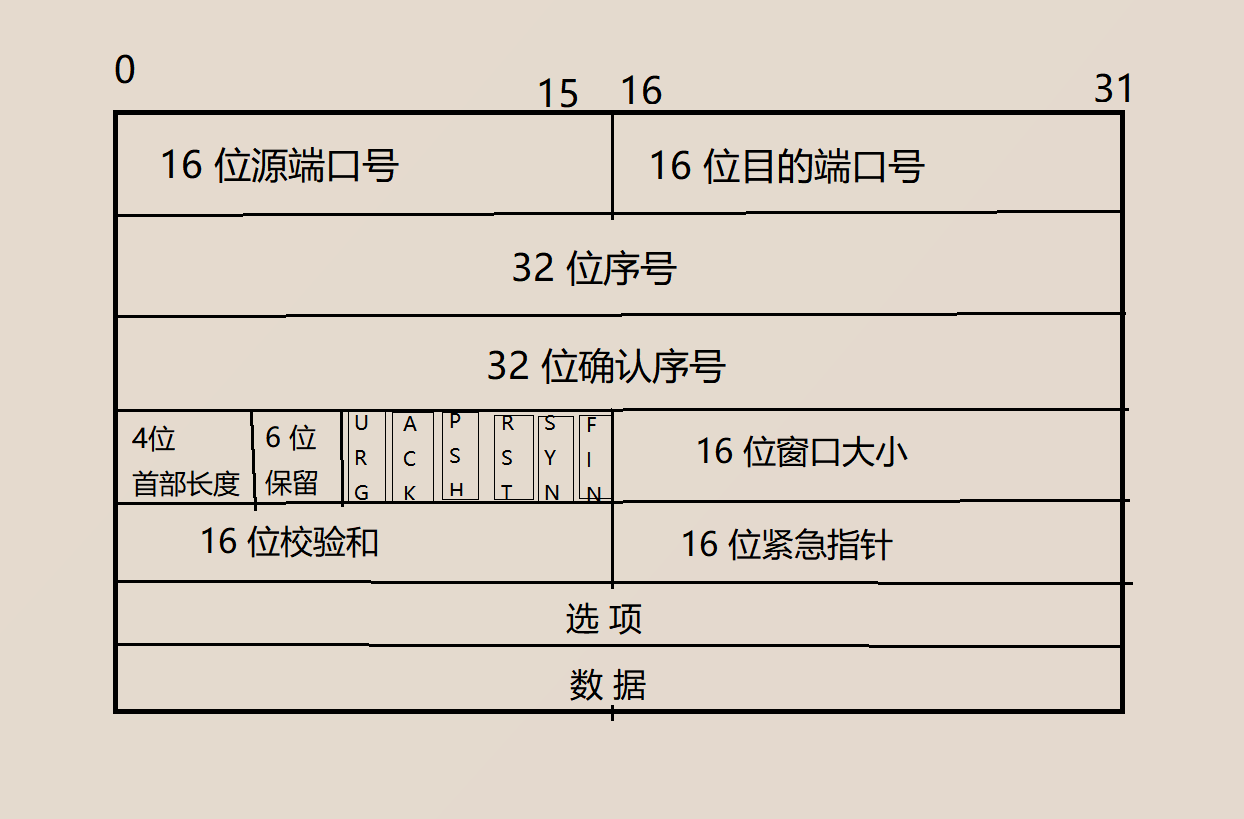
ЯШРДПДПДЫќЕФБЈЭЗ ЮвУЧРДЗжЮіЗжЮіУПВПЗжЕФКЌвхКЭзїгУ
дДЖЫПкКХ/ФПЕФЖЫПкКХ: БэЪОЪ§ОнДгФФИіНјГЬРД, ЕНФФИіНјГЬШЅ.
32ЮЛађКХ:
4ЮЛЪзВПГЄЖШ: БэЪОИУtcpБЈЭЗгаЖрЩйИі4зжНк(32Иіbit)
6ЮЛБЃСє: ЙЫУћЫМвх, ЯШБЃСєзХ, вдЗРЭђвЛ
6ЮЛБъжОЮЛ
URG: БъЪЖНєМБжИеыЪЧЗёгааЇ
ACK: БъЪЖШЗШЯађКХЪЧЗёгааЇ
PSH: гУРДЬсЪОНгЪеЖЫгІгУГЬађСЂПЬНЋЪ§ОнДгtcpЛКГхЧјЖСзп
RST: вЊЧѓжиаТНЈСЂСЌНг. ЮвУЧАбКЌгаRSTБъЪЖЕФБЈЮФГЦЮЊИДЮЛБЈЮФЖЮ
SYN: ЧыЧѓНЈСЂСЌНг. ЮвУЧАбКЌгаSYNБъЪЖЕФБЈЮФГЦЮЊЭЌВНБЈЮФЖЮ
FIN: ЭЈжЊЖдЖЫ, БОЖЫМДНЋЙиБе. ЮвУЧАбКЌгаFINБъЪЖЕФБЈЮФГЦЮЊНсЪјБЈЮФЖЮ
16ЮЛДАПкДѓаЁ:
16ЮЛМьбщКЭ: гЩЗЂЫЭЖЫЬюГф, МьбщаЮЪНгаCRCаЃбщЕШ. ШчЙћНгЪеЖЫаЃбщВЛЭЈЙ§, дђШЯЮЊЪ§ОнгаЮЪЬт.
ДЫДІЕФаЃбщКЭВЛЙтАќКЌTCPЪзВП, вВАќКЌTCPЪ§ОнВПЗж.
16ЮЛНєМБжИеы: гУРДБъЪЖФФВПЗжЪ§ОнЪЧНєМБЪ§Он.
бЁЯюКЭЪ§ОнднЪБКіТд
СЌНгЙмРэЛњжЦ
е§ГЃЧщПіЯТ, tcpашвЊОЙ§Ш§ДЮЮеЪжНЈСЂСЌНг, ЫФДЮЛгЪжЖЯПЊСЌНг.
ФЧУДЪВУДЪЧШ§ДЮЮеЪж? ЪВУДЪЧЫФДЮЛгЪжФи?
Ш§ДЮЮеЪж
ЕквЛДЮ:
ПЭЛЇЖЫ - - > ЗўЮёЦї ДЫЪБЗўЮёЦїжЊЕРСЫПЭЛЇЖЫвЊНЈСЂСЌНгСЫ
ЕкЖўДЮ:
ПЭЛЇЖЫ < - - ЗўЮёЦї ДЫЪБПЭЛЇЖЫжЊЕРЗўЮёЦїЪеЕНСЌНгЧыЧѓСЫ
ЕкШ§ДЮ:
ПЭЛЇЖЫ - - > ЗўЮёЦї ДЫЪБЗўЮёЦїжЊЕРПЭЛЇЖЫЪеЕНСЫздМКЕФЛигІ
ЕНетРя, ОЭПЩвдШЯЮЊПЭЛЇЖЫгыЗўЮёЦївбОНЈСЂСЫСЌНг.
дйРДПДИіЭМ.

ИеПЊЪМ, ПЭЛЇЖЫКЭЗўЮёЦїЖМДІгк CLOSE зДЬЌ.
ДЫЪБ, ПЭЛЇЖЫЯђЗўЮёЦїжїЖЏЗЂГіСЌНгЧыЧѓ, ЗўЮёЦїБЛЖЏНгЪмСЌНгЧыЧѓ.
1, TCPЗўЮёЦїНјГЬЯШДДНЈДЋЪфПижЦПщTCB, ЪБПЬзМБИНгЪмПЭЛЇЖЫНјГЬЕФСЌНгЧыЧѓ, ДЫЪБЗўЮёЦїОЭНјШыСЫ
LISTENЃЈМрЬ§ЃЉзДЬЌ
2, TCPПЭЛЇЖЫНјГЬвВЪЧЯШДДНЈДЋЪфПижЦПщTCB, ШЛКѓЯђЗўЮёЦїЗЂГіСЌНгЧыЧѓБЈЮФЃЌДЫЪББЈЮФЪзВПжаЕФЭЌВНБъжОЮЛSYN=1,
ЭЌЪБбЁдёвЛИіГѕЪМађСаКХ seq = x, ДЫЪБЃЌTCPПЭЛЇЖЫНјГЬНјШыСЫ SYN-SENTЃЈЭЌВНвбЗЂЫЭзДЬЌЃЉзДЬЌЁЃTCPЙцЖЈ,
SYNБЈЮФЖЮЃЈSYN=1ЕФБЈЮФЖЮЃЉВЛФмаЏДјЪ§ОнЃЌЕЋашвЊЯћКФЕєвЛИіађКХЁЃ
3, TCPЗўЮёЦїЪеЕНЧыЧѓБЈЮФКѓ, ШчЙћЭЌвтСЌНг, дђЗЂГіШЗШЯБЈЮФЁЃШЗШЯБЈЮФжаЕФ ACK=1, SYN=1,
ШЗШЯађКХЪЧ x+1, ЭЌЪБвВвЊЮЊздМКГѕЪМЛЏвЛИіађСаКХ seq = y, ДЫЪБ, TCPЗўЮёЦїНјГЬНјШыСЫSYN-RCVDЃЈЭЌВНЪеЕНЃЉзДЬЌЁЃетИіБЈЮФвВВЛФмаЏДјЪ§Он,
ЕЋЪЧЭЌбљвЊЯћКФвЛИіађКХЁЃ
4, TCPПЭЛЇЖЫНјГЬЪеЕНШЗШЯКѓЛЙ, вЊЯђЗўЮёЦїИјГіШЗШЯЁЃШЗШЯБЈЮФЕФACK=1ЃЌШЗШЯађКХЪЧ y+1ЃЌздМКЕФађСаКХЪЧ
x+1.
5, ДЫЪБЃЌTCPСЌНгНЈСЂЃЌПЭЛЇЖЫНјШыESTABLISHEDЃЈвбНЈСЂСЌНгЃЉзДЬЌЁЃЕБЗўЮёЦїЪеЕНПЭЛЇЖЫЕФШЗШЯКѓвВНјШыESTABLISHEDзДЬЌЃЌДЫКѓЫЋЗНОЭПЩвдПЊЪМЭЈаХСЫЁЃ
ЮЊЪВУДВЛгУСНДЮ?
жївЊЪЧЮЊСЫЗРжЙвбОЪЇаЇЕФСЌНгЧыЧѓБЈЮФЭЛШЛгжДЋЫЭЕНСЫЗўЮёЦїЃЌДгЖјВњЩњДэЮѓЁЃШчЙћЪЙгУЕФЪЧСНДЮЮеЪжНЈСЂСЌНгЃЌМйЩшгаетбљвЛжжГЁОАЃЌПЭЛЇЖЫЗЂЫЭЕФЕквЛИіЧыЧѓСЌНгВЂЧвУЛгаЖЊЪЇЃЌжЛЪЧвђЮЊдкЭјТчжажЭСєЕФЪБМфЬЋГЄСЫЃЌгЩгкTCPЕФПЭЛЇЖЫГйГйУЛгаЪеЕНШЗШЯБЈЮФЃЌвдЮЊЗўЮёЦїУЛгаЪеЕНЃЌДЫЪБжиаТЯђЗўЮёЦїЗЂЫЭетЬѕБЈЮФЃЌДЫКѓПЭЛЇЖЫКЭЗўЮёЦїОЙ§СНДЮЮеЪжЭъГЩСЌНгЃЌДЋЪфЪ§ОнЃЌШЛКѓЙиБеСЌНгЁЃДЫЪБжЎЧАжЭСєЕФФЧвЛДЮЧыЧѓСЌНгЃЌвђЮЊЭјТчЭЈГЉСЫ,
ЕНДяСЫЗўЮёЦїЃЌетИіБЈЮФБОИУЪЧЪЇаЇЕФЃЌЕЋЪЧЃЌСНДЮЮеЪжЕФЛњжЦНЋЛсШУПЭЛЇЖЫКЭЗўЮёЦїдйДЮНЈСЂСЌНгЃЌетНЋЕМжТВЛБивЊЕФДэЮѓКЭзЪдДЕФЗбЁЃ
ШчЙћВЩгУЕФЪЧШ§ДЮЮеЪжЃЌОЭЫуЪЧФЧвЛДЮЪЇаЇЕФБЈЮФДЋЫЭЙ§РДСЫЃЌЗўЮёЖЫНгЪмЕНСЫФЧЬѕЪЇаЇБЈЮФВЂЧвЛиИДСЫШЗШЯБЈЮФЃЌЕЋЪЧПЭЛЇЖЫВЛЛсдйДЮЗЂГіШЗШЯЁЃгЩгкЗўЮёЦїЪеВЛЕНШЗШЯЃЌОЭжЊЕРПЭЛЇЖЫВЂУЛгаЧыЧѓСЌНгЁЃ
ЮЊЪВУДВЛгУЫФДЮ?
вђЮЊШ§ДЮвбОПЩвдТњзуашвЊСЫ, ЫФДЮОЭЖргрСЫ.
дйРДПДПДКЮЮЊЫФДЮЛгЪж.
Ъ§ОнДЋЪфЭъБЯКѓЃЌЫЋЗНЖМПЩвдЪЭЗХСЌНг.
ДЫЪБПЭЛЇЖЫКЭЗўЮёЦїЖМЪЧДІгкESTABLISHEDзДЬЌЃЌШЛКѓПЭЛЇЖЫжїЖЏЖЯПЊСЌНгЃЌЗўЮёЦїБЛЖЏЖЯПЊСЌНг.
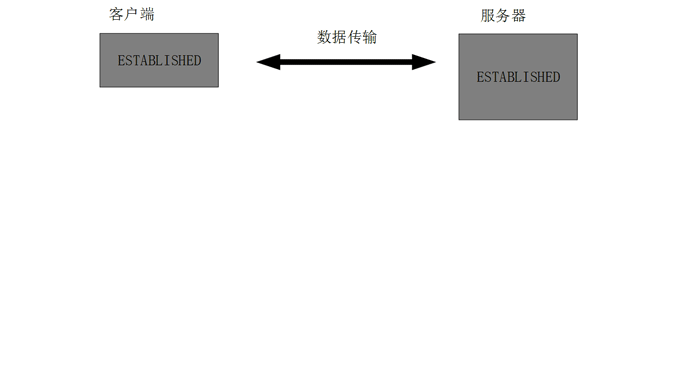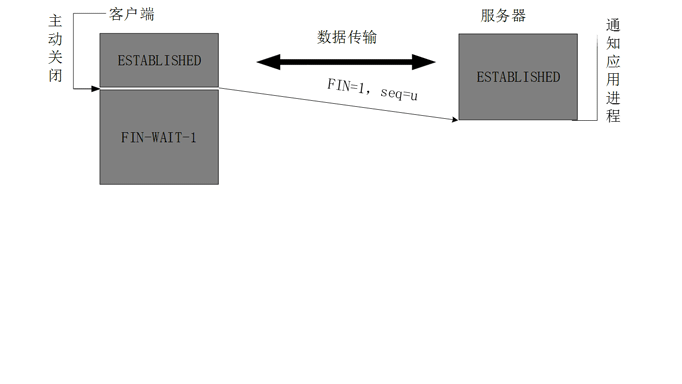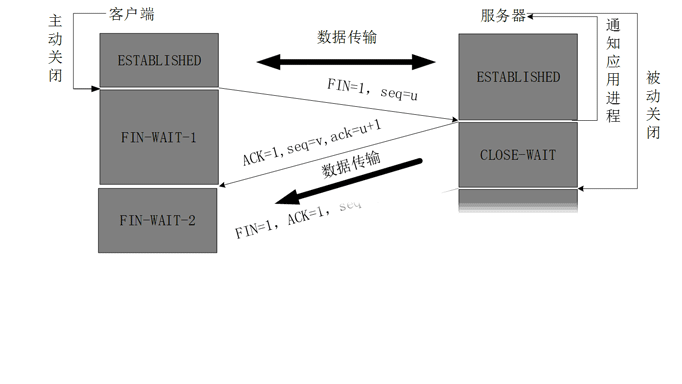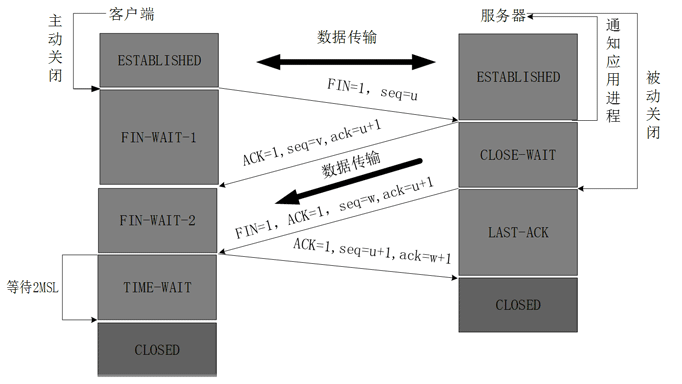
1, ПЭЛЇЖЫНјГЬЗЂГіСЌНгЪЭЗХБЈЮФЃЌВЂЧвЭЃжЙЗЂЫЭЪ§ОнЁЃ
ЪЭЗХЪ§ОнБЈЮФЪзВПЃЌFIN=1ЃЌЦфађСаКХЮЊseq=uЃЈЕШгкЧАУцвбОДЋЫЭЙ§РДЕФЪ§ОнЕФзюКѓвЛИізжНкЕФађКХМг1ЃЉЃЌДЫЪБПЭЛЇЖЫНјШыFIN-WAIT-1ЃЈжежЙЕШД§1ЃЉзДЬЌЁЃ
TCPЙцЖЈЃЌFINБЈЮФЖЮМДЪЙВЛаЏДјЪ§ОнЃЌвВвЊЯћКФвЛИіађКХЁЃ
2, ЗўЮёЦїЪеЕНСЌНгЪЭЗХБЈЮФЃЌЗЂГіШЗШЯБЈЮФЃЌACK=1ЃЌШЗШЯађКХЮЊ u+1ЃЌВЂЧвДјЩЯздМКЕФађСаКХseq=vЃЌДЫЪБЗўЮёЖЫОЭНјШыСЫCLOSE-WAITЃЈЙиБеЕШД§ЃЉзДЬЌЁЃ
TCPЗўЮёЦїЭЈжЊИпВуЕФгІгУНјГЬЃЌПЭЛЇЖЫЯђЗўЮёЦїЕФЗНЯђОЭЪЭЗХСЫЃЌетЪБКђДІгкАыЙиБезДЬЌЃЌМДПЭЛЇЖЫвбОУЛгаЪ§ОнвЊЗЂЫЭСЫЃЌЕЋЪЧЗўЮёЦїШєЗЂЫЭЪ§ОнЃЌПЭЛЇЖЫвРШЛвЊНгЪмЁЃетИізДЬЌЛЙвЊГжајвЛЖЮЪБМфЃЌвВОЭЪЧећИіCLOSE-WAITзДЬЌГжајЕФЪБМфЁЃ
3, ПЭЛЇЖЫЪеЕНЗўЮёЦїЕФШЗШЯЧыЧѓКѓЃЌДЫЪБПЭЛЇЖЫОЭНјШыFIN-WAIT-2ЃЈжежЙЕШД§2ЃЉзДЬЌЃЌЕШД§ЗўЮёЦїЗЂЫЭСЌНгЪЭЗХБЈЮФЃЈдкетжЎЧАЛЙашвЊНгЪмЗўЮёЦїЗЂЫЭЕФзюжеЪ§ОнЃЉ
4, ЗўЮёЦїНЋзюКѓЕФЪ§ОнЗЂЫЭЭъБЯКѓЃЌОЭЯђПЭЛЇЖЫЗЂЫЭСЌНгЪЭЗХБЈЮФЃЌFIN=1ЃЌШЗШЯађКХЮЊv+1ЃЌгЩгкдкАыЙиБезДЬЌЃЌЗўЮёЦїКмПЩФмгжЗЂЫЭСЫвЛаЉЪ§ОнЃЌМйЖЈДЫЪБЕФађСаКХЮЊseq=wЃЌДЫЪБЃЌЗўЮёЦїОЭНјШыСЫLAST-ACKЃЈзюКѓШЗШЯЃЉзДЬЌЃЌЕШД§ПЭЛЇЖЫЕФШЗШЯЁЃ
5, ПЭЛЇЖЫЪеЕНЗўЮёЦїЕФСЌНгЪЭЗХБЈЮФКѓЃЌБиаыЗЂГіШЗШЯЃЌACK=1ЃЌШЗШЯађКХЮЊw+1ЃЌЖјздМКЕФађСаКХЪЧu+1ЃЌДЫЪБЃЌПЭЛЇЖЫОЭНјШыСЫTIME-WAITЃЈЪБМфЕШД§ЃЉзДЬЌЁЃзЂвтДЫЪБTCPСЌНгЛЙУЛгаЪЭЗХЃЌБиаыОЙ§2?MSLЃЈзюГЄБЈЮФЖЮЪйУќЃЉЕФЪБМфКѓЃЌЕБПЭЛЇЖЫГЗЯњЯргІЕФTCBКѓЃЌВХНјШыCLOSEDзДЬЌЁЃ
6, ЗўЮёЦїжЛвЊЪеЕНСЫПЭЛЇЖЫЗЂГіЕФШЗШЯЃЌСЂМДНјШыCLOSEDзДЬЌЁЃЭЌбљЃЌГЗЯњTCBКѓЃЌОЭНсЪјСЫетДЮЕФTCPСЌНгЁЃПЩвдПДЕНЃЌЗўЮёЦїНсЪјTCPСЌНгЕФЪБМфвЊБШПЭЛЇЖЫдчвЛаЉЁЃ
дйРДПДвЛеХЭМ.
ЮЊЪВУДзюКѓПЭЛЇЖЫЛЙвЊЕШД§ 2*MSLЕФЪБМфФи?
MSLЃЈMaximum Segment LifetimeЃЉЃЌTCPдЪаэВЛЭЌЕФЪЕЯжПЩвдЩшжУВЛЭЌЕФMSLжЕЁЃ
ЕквЛЃЌБЃжЄПЭЛЇЖЫЗЂЫЭЕФзюКѓвЛИіACKБЈЮФФмЙЛЕНДяЗўЮёЦїЃЌвђЮЊетИіACKБЈЮФПЩФмЖЊЪЇЃЌеОдкЗўЮёЦїЕФНЧЖШПДРДЃЌЮввбОЗЂЫЭСЫFIN+ACKБЈЮФЧыЧѓЖЯПЊСЫЃЌПЭЛЇЖЫЛЙУЛгаИјЮвЛигІЃЌгІИУЪЧЮвЗЂЫЭЕФЧыЧѓЖЯПЊБЈЮФЫќУЛгаЪеЕНЃЌгкЪЧЗўЮёЦїгжЛсжиаТЗЂЫЭвЛДЮЃЌЖјПЭЛЇЖЫОЭФмдкетИі2MSLЪБМфЖЮФкЪеЕНетИіжиДЋЕФБЈЮФЃЌНгзХИјГіЛигІБЈЮФЃЌВЂЧвЛсжиЦє2MSLМЦЪБЦїЁЃ
ЕкЖўЃЌЗРжЙРрЫЦгыЁАШ§ДЮЮеЪжЁБжаЬсЕНСЫЕФЁАвбОЪЇаЇЕФСЌНгЧыЧѓБЈЮФЖЮЁБГіЯждкБОСЌНгжаЁЃПЭЛЇЖЫЗЂЫЭЭъзюКѓвЛИіШЗШЯБЈЮФКѓЃЌдкетИі2MSLЪБМфжаЃЌОЭПЩвдЪЙБОСЌНгГжајЕФЪБМфФкЫљВњЩњЕФЫљгаБЈЮФЖЮЖМДгЭјТчжаЯћЪЇЁЃетбљаТЕФСЌНгжаВЛЛсГіЯжОЩСЌНгЕФЧыЧѓБЈЮФЁЃ
ЮЊЪВУДНЈСЂСЌНгЪЧШ§ДЮЮеЪжЃЌЙиБеСЌНгШЗЪЧЫФДЮЛгЪжФиЃП
НЈСЂСЌНгЕФЪБКђЃЌ ЗўЮёЦїдкLISTENзДЬЌЯТЃЌЪеЕННЈСЂСЌНгЧыЧѓЕФSYNБЈЮФКѓЃЌАбACKКЭSYNЗХдквЛИіБЈЮФРяЗЂЫЭИјПЭЛЇЖЫЁЃ
ЖјЙиБеСЌНгЪБЃЌЗўЮёЦїЪеЕНЖдЗНЕФFINБЈЮФЪБЃЌНіНіБэЪОЖдЗНВЛдйЗЂЫЭЪ§ОнСЫЕЋЪЧЛЙФмНгЪеЪ§ОнЃЌЖјздМКвВЮДБиШЋВПЪ§ОнЖМЗЂЫЭИјЖдЗНСЫЃЌЫљвдМКЗНПЩвдСЂМДЙиБеЃЌвВПЩвдЗЂЫЭвЛаЉЪ§ОнИјЖдЗНКѓЃЌдйЗЂЫЭFINБЈЮФИјЖдЗНРДБэЪОЭЌвтЯждкЙиБеСЌНгЃЌвђДЫЃЌМКЗНACKКЭFINвЛАуЖМЛсЗжПЊЗЂЫЭЃЌДгЖјЕМжТЖрСЫвЛДЮЁЃ
ШчЙћвбОНЈСЂСЫСЌНг, ЕЋЪЧПЭЛЇЖЫЭЛЗЂЙЪеЯСЫдѕУДАь?
TCPЩшгавЛИіБЃЛюМЦЪБЦїЃЌЯдШЛЃЌПЭЛЇЖЫШчЙћГіЯжЙЪеЯЃЌЗўЮёЦїВЛФмвЛжБЕШЯТШЅЃЌАзАзРЫЗбзЪдДЁЃЗўЮёЦїУПЪеЕНвЛДЮПЭЛЇЖЫЕФЧыЧѓКѓЖМЛсжиаТИДЮЛетИіМЦЪБЦїЃЌЪБМфЭЈГЃЪЧЩшжУЮЊ2аЁЪБЃЌШєСНаЁЪБЛЙУЛгаЪеЕНПЭЛЇЖЫЕФШЮКЮЪ§ОнЃЌЗўЮёЦїОЭЛсЗЂЫЭвЛИіЬНВтБЈЮФЖЮЃЌвдКѓУПИє75ЗжжгЗЂЫЭвЛДЮЁЃШєвЛСЌЗЂЫЭ10ИіЬНВтБЈЮФШдШЛУЛЗДгІЃЌЗўЮёЦїОЭШЯЮЊПЭЛЇЖЫГіСЫЙЪеЯЃЌНгзХОЭЙиБеСЌНгЁЃ
РэНтTIME_WAITзДЬЌ
ПЩвдзівЛИіЪЕбщ, ЯШдЫааserver, дйдЫааclientСЌНгserver, ШЛКѓЖЯПЊserver,
дйСЂТэдЫааserver.
ЮвУЧЛсЗЂЯж:
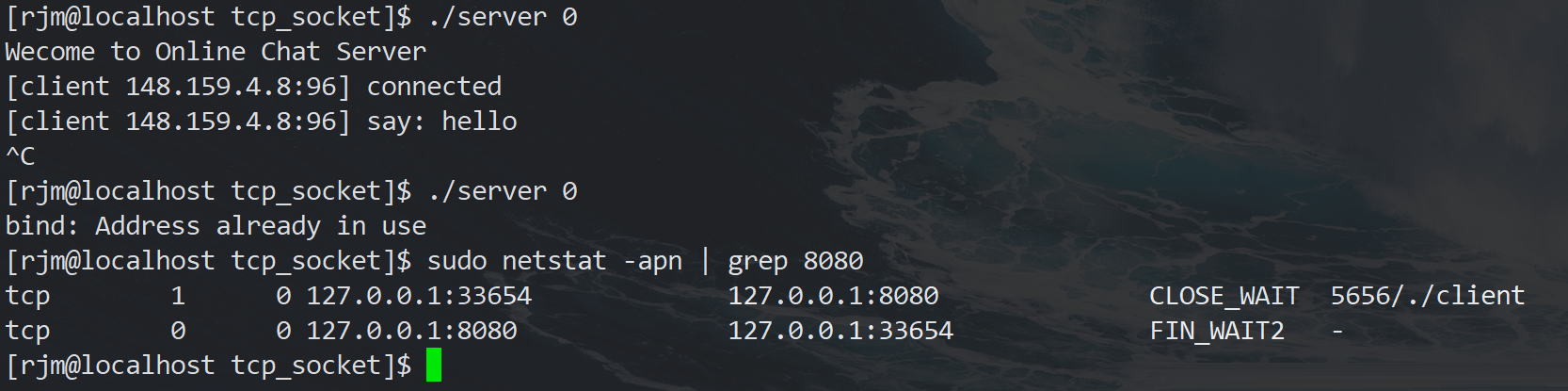
АѓЖЈЕФЪБКђГіСЫЮЪЬт.
етЪЧвђЮЊ,ЫфШЛserverгІгУГЬађжежЙСЫ,ЕЋTCPавщВуЕФСЌНгВЂУЛгаЭъШЋЖЯПЊ,вђДЫВЛФмдйДЮМрЬ§АѓЖЈЭЌбљЕФserverЖЫПк.
TCPавщЙцЖЈ,жїЖЏЙиБеСЌНгЕФвЛЗНвЊДІгкTIME_ WAITзДЬЌ,ЕШД§2*MSL(maximum segment
lifetime)ЕФЪБМфКѓВХФмЛиЕНCLOSEDзДЬЌ.
ЮвУЧЪЙгУCtrl-CжежЙСЫserver, ЫљвдserverЪЧжїЖЏЙиБеСЌНгЕФвЛЗН, дкTIME_WAITЦкМфШдШЛВЛФмдйДЮМрЬ§ЭЌбљЕФserverЖЫПк
MSLдкRFC1122жаЙцЖЈЮЊСНЗжжг,ЕЋЪЧИїВйзїЯЕЭГЕФЪЕЯжВЛЭЌ, дкCentos7ЩЯФЌШЯХфжУЕФжЕЪЧ60s;
ПЩвдЭЈЙ§ cat /proc/sys/net/ipv4/tcp_fin_timeout
ВщПДMSLЕФжЕ

НтОіTIME_WAITв§Ц№ЕФbindЪЇАмЮЪЬт
дкserverЕФTCPСЌНгУЛгаЭъШЋЖЯПЊжЎЧАВЛдЪаэжиаТМрЬ§, ФГаЉЧщПіЯТПЩФмЪЧВЛКЯРэЕФ.
БШШч:
ЗўЮёЦїашвЊДІРэЗЧГЃДѓСПЕФПЭЛЇЖЫЕФСЌНг(УПИіСЌНгЕФЩњДцЪБМфПЩФмКмЖЬ, ЕЋЪЧУПУыЖМгаДѓСПЕФПЭЛЇЖЫРДЧыЧѓ).
етИіЪБКђШчЙћгЩЗўЮёЦїЖЫжїЖЏЙиБеСЌНг(БШШчФГаЉПЭЛЇЖЫВЛЛюдО, ОЭашвЊБЛЗўЮёЦїЖЫжїЖЏЧхРэЕє), ОЭЛсВњЩњДѓСПTIME_WAITСЌНг.
гЩгкЮвУЧЕФЧыЧѓСПКмДѓ, ОЭПЩФмЕМжТTIME_WAITЕФСЌНгЪ§КмЖр, ЕМжТЗўЮёЦїЕФЖЫПкВЛЙЛгУ, ЮоЗЈДІРэаТЕФСЌНг.
НтОіЗНЗЈ:
- ЪЙгУsetsockopt()ЩшжУsocketУшЪіЗћЕФбЁЯюSO_REUSEADDRЮЊ1, БэЪОдЪаэДДНЈЖЫПкКХЯрЭЌЕЋIPЕижЗВЛЭЌЕФЖрИіsocketУшЪіЗћ.
гУЗЈ:
дкserverДњТыЕФsocket()КЭbind()ЕїгУжЎМфВхШыШчЯТДњТы
int opt = 1;
setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &opt,
sizeof(opt));
ШЗШЯгІД№ЛњжЦ(ACKЛњжЦ)
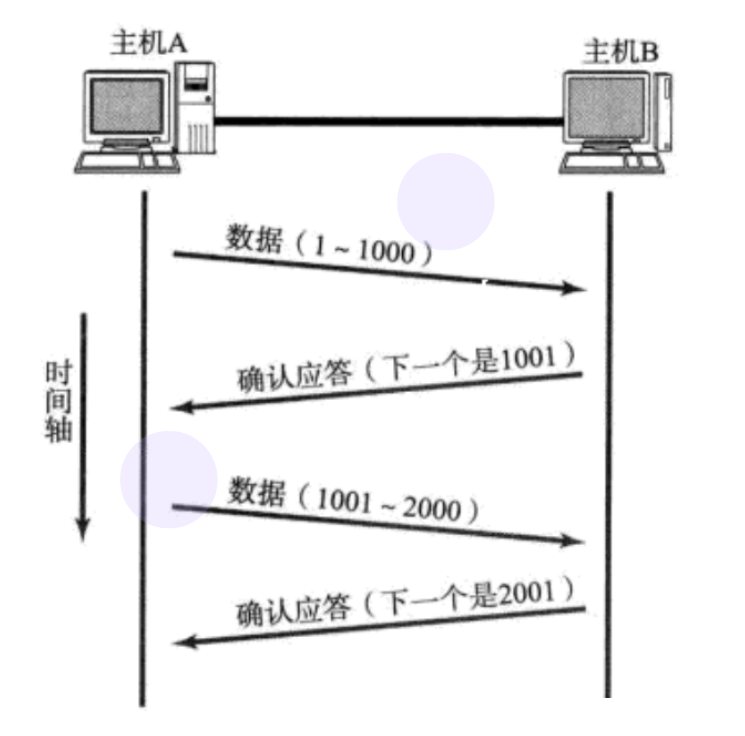
TCPНЋУПИізжНкЕФЪ§ОнЖМНјааСЫБрКХ, МДЮЊађСаКХ.
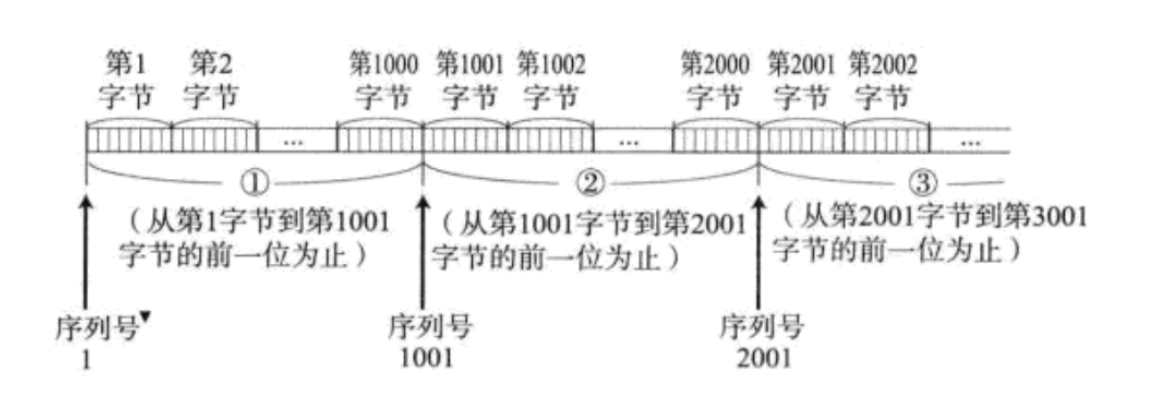
УПвЛИіACKЖМДјгаЖдгІЕФШЗШЯађСаКХ, втЫМЪЧИцЫпЗЂЫЭеп, ЮввбОЪеЕНСЫФФаЉЪ§Он;
ЯТвЛДЮФувЊДгФФРяПЊЪМЗЂ.
БШШч, ПЭЛЇЖЫЯђЗўЮёЦїЗЂЫЭСЫ1005зжНкЕФЪ§Он, ЗўЮёЦїЗЕЛиИјПЭЛЇЖЫЕФШЗШЯађКХЪЧ1003, ФЧУДЫЕУїЗўЮёЦїжЛЪеЕНСЫ1-1002ЕФЪ§Он.
1003, 1004, 1005ЖМУЛЪеЕН.
ДЫЪБПЭЛЇЖЫОЭЛсДг1003ПЊЪМжиЗЂ.
ГЌЪБжиДЋЛњжЦ
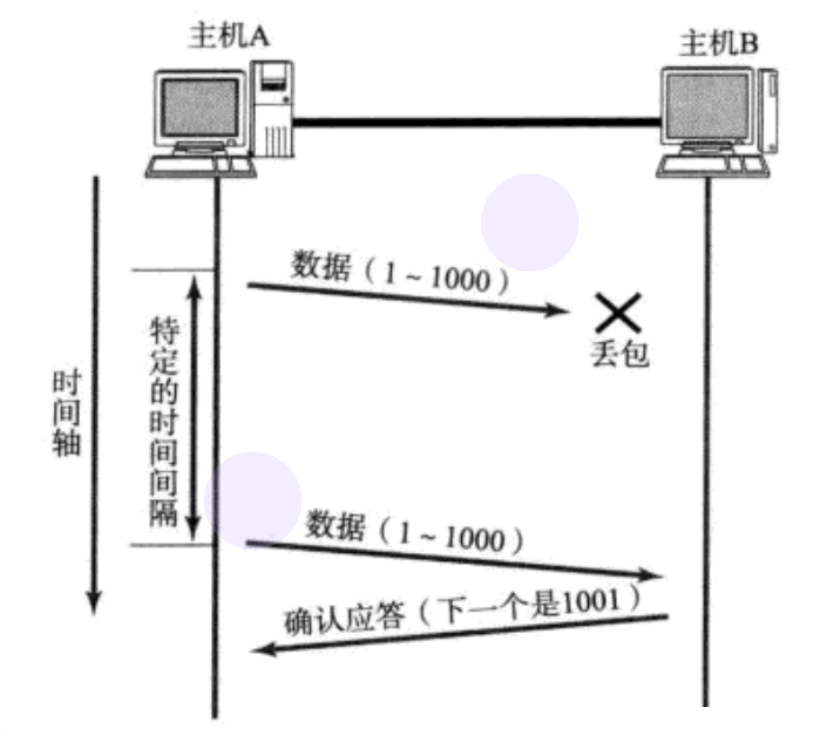
жїЛњAЗЂЫЭЪ§ОнИјBжЎКѓ, ПЩФмвђЮЊЭјТчгЕЖТЕШдвђ, Ъ§ОнЮоЗЈЕНДяжїЛњB
ШчЙћжїЛњAдквЛИіЬиЖЈЪБМфМфИєФкУЛгаЪеЕНBЗЂРДЕФШЗШЯгІД№, ОЭЛсНјаажиЗЂ
ЕЋЪЧжїЛњAУЛЪеЕНШЗШЯгІД№вВПЩФмЪЧACKЖЊЪЇСЫ.
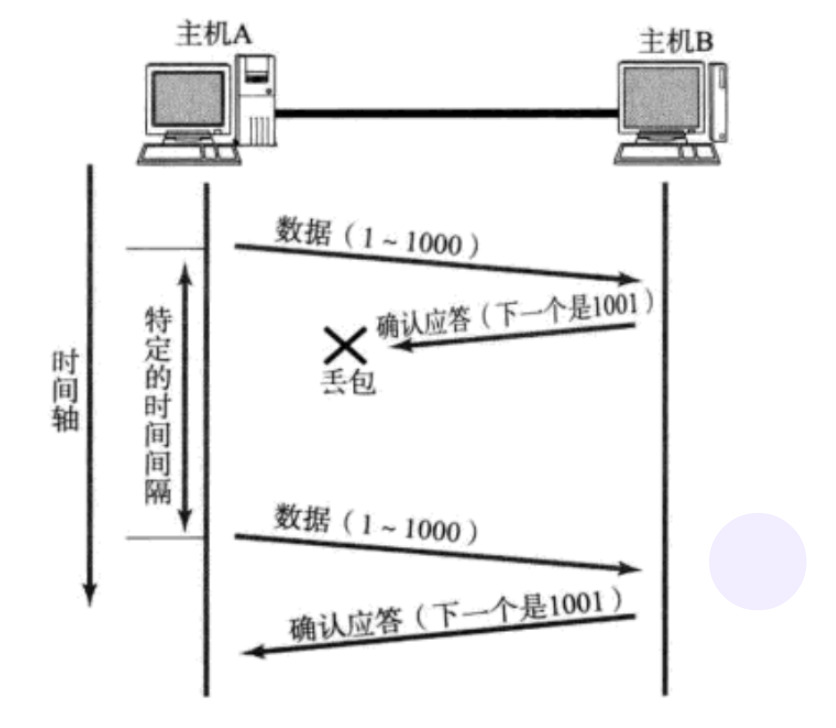
етжжЧщПіЯТ, жїЛњBЛсЪеЕНКмЖржиИДЪ§Он.
ФЧУДTCPавщашвЊЪЖБ№ГіФФаЉАќЪЧжиИДЕФ, ВЂЧвАбжиИДЕФЖЊЦњ.
етЪБКђРћгУЧАУцЬсЕНЕФађСаКХ, ОЭПЩвдКмШнвззіЕНШЅжи.
ГЌЪБЪБМфШчКЮШЗЖЈ?
зюРэЯыЕФЧщПіЯТ, евЕНвЛИізюаЁЕФЪБМф, БЃжЄ ЁАШЗШЯгІД№вЛЖЈФмдкетИіЪБМфФкЗЕЛиЁБ.
ЕЋЪЧетИіЪБМфЕФГЄЖЬ, ЫцзХЭјТчЛЗОГЕФВЛЭЌ, ЪЧгаВювьЕФ.
ШчЙћГЌЪБЪБМфЩшЕФЬЋГЄ, ЛсгАЯьећЬхЕФжиДЋаЇТЪ; ШчЙћГЌЪБЪБМфЩшЕФЬЋЖЬ, гаПЩФмЛсЦЕЗБЗЂЫЭжиИДЕФАќ.
TCPЮЊСЫБЃжЄШЮКЮЛЗОГЯТЖМФмБЃГжНЯИпадФмЕФЭЈаХ, вђДЫЛсЖЏЬЌМЦЫуетИізюДѓГЌЪБЪБМф.
Linuxжа(BSD UnixКЭWindowsвВЪЧШчДЫ), ГЌЪБвд500msЮЊвЛИіЕЅЮЛНјааПижЦ, УПДЮХаЖЈГЌЪБжиЗЂЕФГЌЪБЪБМфЖМЪЧ500msЕФећЪ§БЖ.
ШчЙћжиЗЂвЛДЮжЎКѓ, ШдШЛЕУВЛЕНгІД№, ЕШД§ 2*500ms КѓдйНјаажиДЋ. ШчЙћШдШЛЕУВЛЕНгІД№, ЕШД§
4*500ms НјаажиДЋ.
вРДЮРрЭЦ, вджИЪ§аЮЪНЕнді. РлМЦЕНвЛЖЈЕФжиДЋДЮЪ§, TCPШЯЮЊЭјТчвьГЃЛђепЖдЖЫжїЛњГіЯжвьГЃ, ЧПжЦЙиБеСЌНг.
ЛЌЖЏДАПк
ИеВХЮвУЧЬжТлСЫШЗШЯгІД№ЛњжЦ, ЖдУПвЛИіЗЂЫЭЕФЪ§ОнЖЮ, ЖМвЊИјвЛИіACKШЗШЯгІД№. ЪеЕНACKКѓдйЗЂЫЭЯТвЛИіЪ§ОнЖЮ.
етбљзігавЛИіБШНЯДѓЕФШБЕу, ОЭЪЧадФмНЯВю. гШЦфЪЧЪ§ОнЭљЗЕЪБМфНЯГЄЕФЪБКђ.
ФЧУДЮвУЧПЩВЛПЩвдвЛДЮЗЂЫЭЖрИіЪ§ОнЖЮФи?
Р§Шчетбљ:
вЛИіИХФю: ДАПк
ДАПкДѓаЁжИЕФЪЧЮоашЕШД§ШЗШЯгІД№ОЭПЩвдМЬајЗЂЫЭЪ§ОнЕФзюДѓжЕ.
ЩЯЭМЕФДАПкДѓаЁОЭЪЧ4000ИізжНк (ЫФИіЖЮ).
ЗЂЫЭЧАЫФИіЖЮЕФЪБКђ, ВЛашвЊЕШД§ШЮКЮACK, жБНгЗЂЫЭ
ЪеЕНЕквЛИіACKШЗШЯгІД№Кѓ, ДАПкЯђКѓвЦЖЏ, МЬајЗЂЫЭЕкЮхСљЦпАЫЖЮЕФЪ§ОнЁ
вђЮЊетИіДАПкВЛЖЯЯђКѓЛЌЖЏ, ЫљвдНазіЛЌЖЏДАПк.
ВйзїЯЕЭГФкКЫЮЊСЫЮЌЛЄетИіЛЌЖЏДАПк, ашвЊПЊБйЗЂЫЭЛКГхЧјРДМЧТМЕБЧАЛЙгаФФаЉЪ§ОнУЛгагІД№
жЛгаACKШЗШЯгІД№Й§ЕФЪ§Он, ВХФмДгЛКГхЧјЩОЕє.
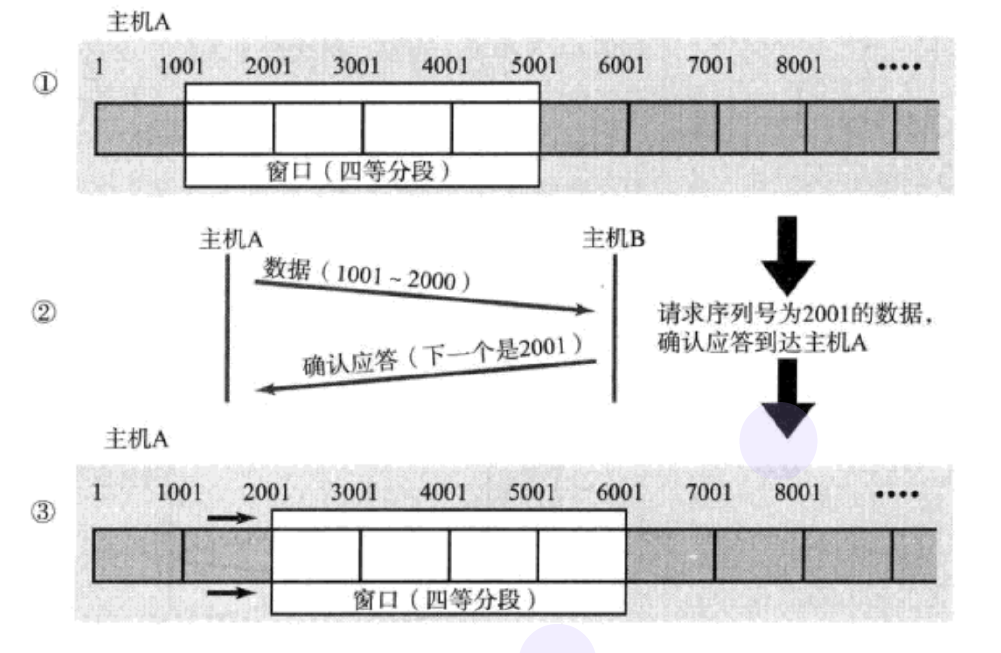
ШчЙћГіЯжСЫЖЊАќ, ФЧУДИУШчКЮНјаажиДЋФи?
ДЫЪБЗжСНжжЧщПіЬжТл:
1, Ъ§ОнАќвбОЪеЕН, ЕЋШЗШЯгІД№ACKЖЊСЫ.
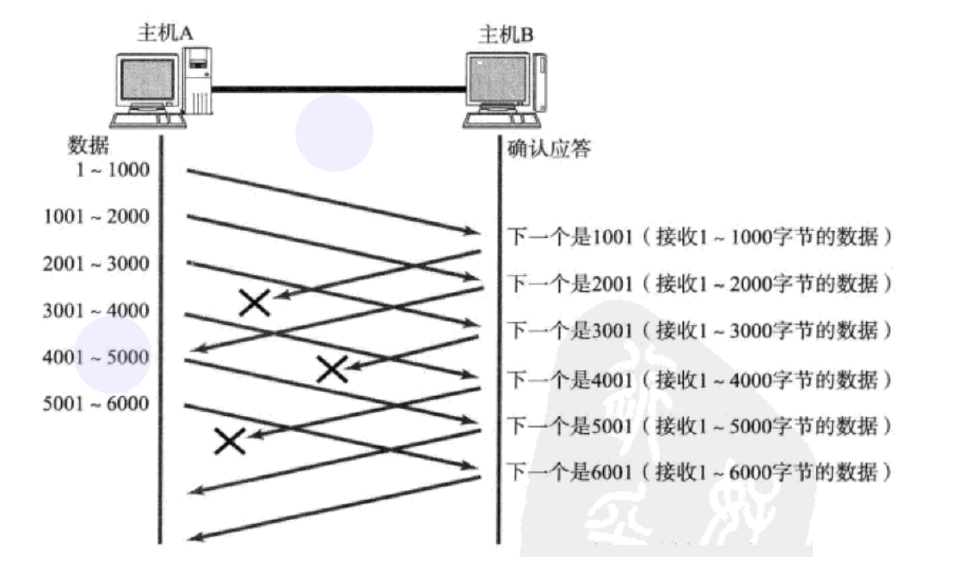
етжжЧщПіЯТ, ВПЗжACKЖЊЪЇВЂЮоДѓА, вђЮЊЛЙПЩвдЭЈЙ§КѓајЕФACKРДШЗШЯЖдЗНвбОЪеЕНСЫФФаЉЪ§ОнАќ.
2, Ъ§ОнАќЖЊЪЇ
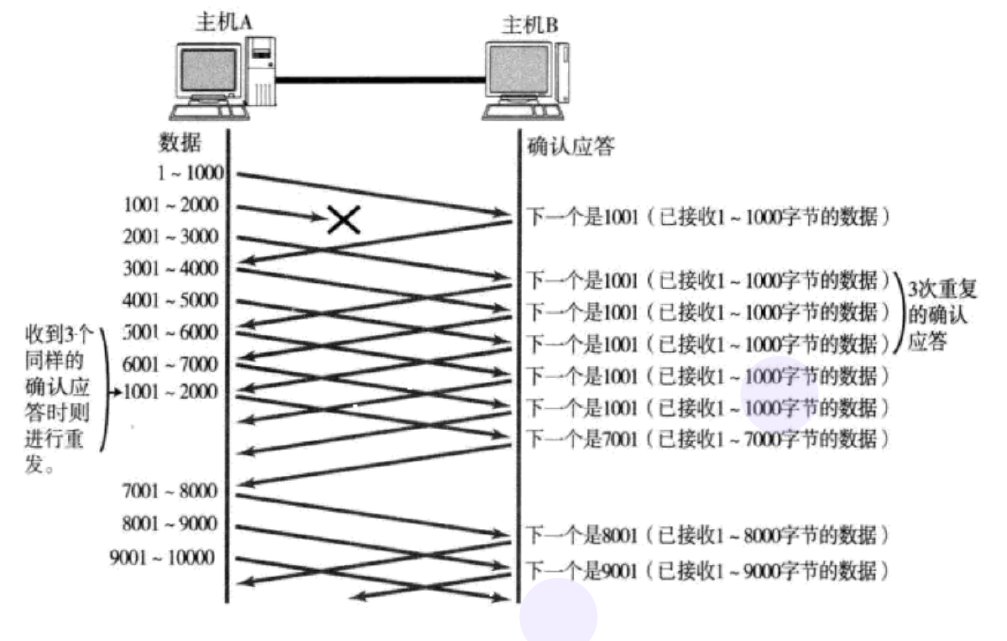
ЕБФГвЛЖЮБЈЮФЖЊЪЇжЎКѓ, ЗЂЫЭЖЫЛсвЛжБЪеЕН 1001 етбљЕФACK,
ОЭЯёЪЧдкЬсабЗЂЫЭЖЫ ЁАЮвЯывЊЕФЪЧ 1001ЁБ
ШчЙћЗЂЫЭЖЫжїЛњСЌајШ§ДЮЪеЕНСЫЭЌбљвЛИі ЁА1001ЁБ етбљЕФгІД№, ОЭЛсНЋЖдгІЕФЪ§Он 1001 - 2000
жиаТЗЂЫЭ
етИіЪБКђНгЪеЖЫЪеЕНСЫ 1001 жЎКѓ, дйДЮЗЕЛиЕФACKОЭЪЧ7001СЫ
вђЮЊ2001 - 7000НгЪеЖЫЦфЪЕжЎЧАОЭвбОЪеЕНСЫ, БЛЗХЕНСЫНгЪеЖЫВйзїЯЕЭГФкКЫЕФНгЪеЛКГхЧјжа.
етжжЛњжЦБЛГЦЮЊ ЁАИпЫйжиЗЂПижЦЁБ ( вВНа ЁАПьжиДЋЁБ )
СїСППижЦ
НгЪеЖЫДІРэЪ§ОнЕФЫйЖШЪЧгаЯоЕФ. ШчЙћЗЂЫЭЖЫЗЂЕФЬЋПь, ЕМжТНгЪеЖЫЕФЛКГхЧјБЛЬюТњ, етИіЪБКђШчЙћЗЂЫЭЖЫМЬајЗЂЫЭ,
ОЭЛсдьГЩЖЊАќ, НјЖјв§Ц№ЖЊАќжиДЋЕШвЛЯЕСаСЌЫјЗДгІ.
вђДЫTCPжЇГжИљОнНгЪеЖЫЕФДІРэФмСІ, РДОіЖЈЗЂЫЭЖЫЕФЗЂЫЭЫйЖШ.
етИіЛњжЦОЭНазі СїСППижЦ(Flow Control)
НгЪеЖЫНЋздМКПЩвдНгЪеЕФЛКГхЧјДѓаЁЗХШы TCP ЪзВПжаЕФ ЁАДАПкДѓаЁЁБ зжЖЮ,
ЭЈЙ§ACKЭЈжЊЗЂЫЭЖЫ;
ДАПкДѓаЁдНДѓ, ЫЕУїЭјТчЕФЭЬЭТСПдНИп;
НгЪеЖЫвЛЕЉЗЂЯжздМКЕФЛКГхЧјПьТњСЫ, ОЭЛсНЋДАПкДѓаЁЩшжУГЩвЛИіИќаЁЕФжЕЭЈжЊИјЗЂЫЭЖЫ;
ЗЂЫЭЖЫНгЪмЕНетИіДАПкДѓаЁЕФЭЈжЊжЎКѓ, ОЭЛсМѕТ§здМКЕФЗЂЫЭЫйЖШ;
ШчЙћНгЪеЖЫЛКГхЧјТњСЫ, ОЭЛсНЋДАПкжУЮЊ0;
етЪБЗЂЫЭЗНВЛдйЗЂЫЭЪ§Он, ЕЋЪЧашвЊЖЈЦкЗЂЫЭвЛИіДАПкЬНВтЪ§ОнЖЮ, ШУНгЪеЖЫАбДАПкДѓаЁдйИцЫпЗЂЫЭЖЫ.
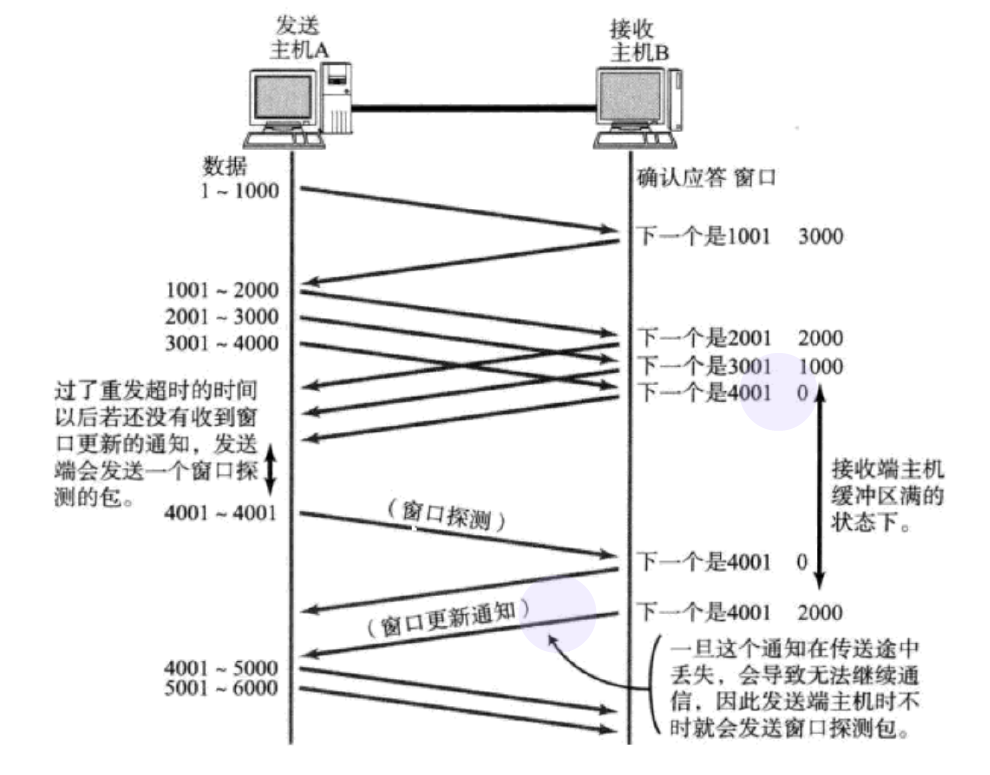
ФЧУДНгЪеЖЫШчКЮАбДАПкДѓаЁИцЫпЗЂЫЭЖЫФи?
ЮвУЧЕФTCPЪзВПжа, гавЛИі16ЮЛДАПкДѓаЁзжЖЮ, ОЭДцЗХСЫДАПкДѓаЁЕФаХЯЂ;
16ЮЛЪ§зжзюДѓБэЪО65536, ФЧУДTCPДАПкзюДѓОЭЪЧ65536зжНкУД?
ЪЕМЪЩЯ, TCPЪзВП40зжНкбЁЯюжаЛЙАќКЌСЫвЛИіДАПкРЉДѓвђзгM, ЪЕМЪДАПкДѓаЁЪЧДАПкзжЖЮЕФжЕзѓвЦ M
ЮЛ(зѓвЦвЛЮЛЯрЕБгкГЫвд2).
гЕШћПижЦ
ЫфШЛTCPгаСЫЛЌЖЏДАПкетИіДѓЩБЦї, ФмЙЛИпаЇПЩППЕиЗЂЫЭДѓСПЪ§Он.
ЕЋЪЧШчЙћдкИеПЊЪМОЭЗЂЫЭДѓСПЕФЪ§Он, ШдШЛПЩФмв§ЗЂвЛаЉЮЪЬт.
вђЮЊЭјТчЩЯгаКмЖрМЦЫуЛњ, ПЩФмЕБЧАЕФЭјТчзДЬЌвбОБШНЯгЕЖТ.
дкВЛЧхГўЕБЧАЭјТчзДЬЌЕФЧщПіЯТ, УГШЛЗЂЫЭДѓСПЪ§Он, КмгаПЩФмбЉЩЯМгЫЊ.
вђДЫ, TCPв§Шы Т§ЦєЖЏ ЛњжЦ, ЯШЗЂЩйСПЕФЪ§Он, ЬНЬНТЗ, УўЧхЕБЧАЕФЭјТчгЕЖТзДЬЌвдКѓ,
дйОіЖЈАДееЖрДѓЕФЫйЖШДЋЪфЪ§Он.
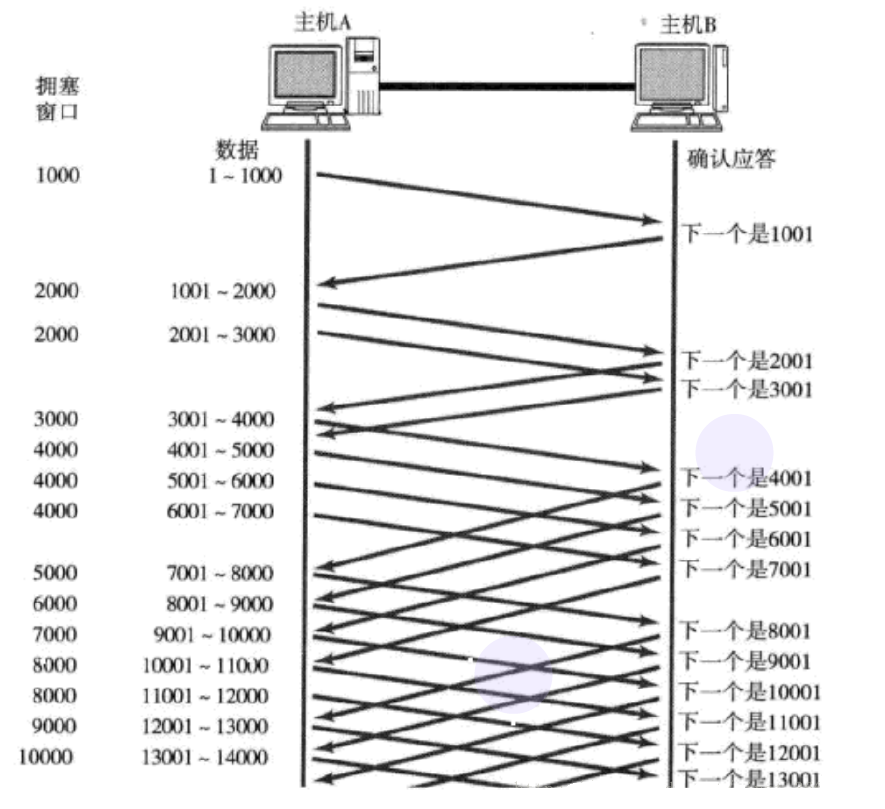
дкДЫв§ШывЛИіИХФю гЕШћДАПк
ЗЂЫЭПЊЪМЕФЪБКђ, ЖЈвхгЕШћДАПкДѓаЁЮЊ1;
УПДЮЪеЕНвЛИіACKгІД№, гЕШћДАПкМг1;
УПДЮЗЂЫЭЪ§ОнАќЕФЪБКђ, НЋгЕШћДАПкКЭНгЪеЖЫжїЛњЗДРЁЕФДАПкДѓаЁзіБШНЯ, ШЁНЯаЁЕФжЕзїЮЊЪЕМЪЗЂЫЭЕФДАПк
ЯёЩЯУцетбљЕФгЕШћДАПкдіГЄЫйЖШ, ЪЧжИЪ§МЖБ№ЕФ.
ЁАТ§ЦєЖЏЁБ жЛЪЧжИГѕЪЙЪБТ§, ЕЋЪЧдіГЄЫйЖШЗЧГЃПь.
ЮЊСЫВЛдіГЄЕУФЧУДПь, ДЫДІв§ШывЛИіУћДЪНазіТ§ЦєЖЏЕФуажЕ, ЕБгЕШћДАПкЕФДѓаЁГЌЙ§етИіуажЕЕФЪБКђ,
ВЛдйАДеежИЪ§ЗНЪНдіГЄ, ЖјЪЧАДееЯпадЗНЪНдіГЄ.
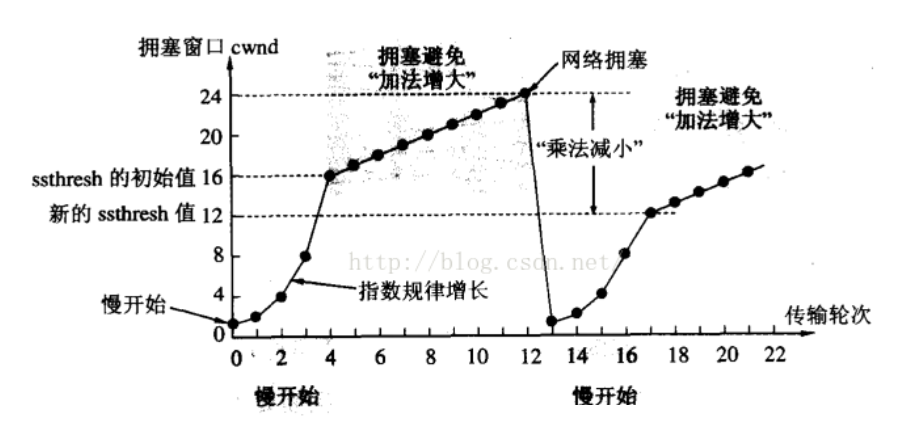
ЕБTCPПЊЪМЦєЖЏЕФЪБКђ, Т§ЦєЖЏуажЕЕШгкДАПкзюДѓжЕ
дкУПДЮГЌЪБжиЗЂЕФЪБКђ, Т§ЦєЖЏуажЕЛсБфГЩдРДЕФвЛАы, ЭЌЪБгЕШћДАПкжУЛи1
ЩйСПЕФЖЊАќ, ЮвУЧНіНіЪЧДЅЗЂГЌЪБжиДЋ;
ДѓСПЕФЖЊАќ, ЮвУЧОЭШЯЮЊЪЧЭјТчгЕШћ;
ЕБTCPЭЈаХПЊЪМКѓ, ЭјТчЭЬЭТСПЛсж№НЅЩЯЩ§;
ЫцзХЭјТчЗЂЩњгЕЖТ, ЭЬЭТСПЛсСЂПЬЯТНЕ.
гЕШћПижЦ, ЙщИљНсЕзЪЧTCPавщЯыОЁПЩФмПьЕФАбЪ§ОнДЋЪфИјЖдЗН, ЕЋЪЧгжвЊБмУтИјЭјТчдьГЩЬЋДѓбЙСІЕФелжаЗНАИ.
бгГйгІД№
ШчЙћНгЪеЪ§ОнЕФжїЛњСЂПЬЗЕЛиACKгІД№, етЪБКђЗЕЛиЕФДАПкПЩФмБШНЯаЁ.
МйЩшНгЪеЖЫЛКГхЧјЮЊ1M. вЛДЮЪеЕНСЫ500KЕФЪ§Он;
ШчЙћСЂПЬгІД№, ЗЕЛиЕФДАПкДѓаЁОЭЪЧ500K;
ЕЋЪЕМЪЩЯПЩФмДІРэЖЫДІРэЕФЫйЖШКмПь, 10msжЎФкОЭАб500KЪ§ОнДгЛКГхЧјЯћЗбЕєСЫ; дкетжжЧщПіЯТ,
НгЪеЖЫДІРэЛЙдЖУЛгаДяЕНздМКЕФМЋЯо, МДЪЙДАПкдйЗХДѓвЛаЉ, вВФмДІРэЙ§РД;
ШчЙћНгЪеЖЫЩдЮЂЕШвЛЛсЖљдйгІД№, БШШчЕШД§200msдйгІД№, ФЧУДетИіЪБКђЗЕЛиЕФДАПкДѓаЁОЭЪЧ1M
ДАПкдНДѓ, ЭјТчЭЬЭТСПОЭдНДѓ, ДЋЪфаЇТЪОЭдНИп.
TCPЕФФПБъЪЧдкБЃжЄЭјТчВЛгЕЖТЕФЧщПіЯТОЁСПЬсИпДЋЪфаЇТЪ;
ФЧУДЫљгаЕФЪ§ОнАќЖМПЩвдбгГйгІД№УД?
ПЯЖЈвВВЛЪЧ
гаСНИіЯожЦ
Ъ§СПЯожЦ: УПИєNИіАќОЭгІД№вЛДЮ
ЪБМфЯожЦ: ГЌЙ§зюДѓбгГйЪБМфОЭгІД№вЛДЮ
ОпЬхЕФЪ§СПNКЭзюДѓбгГйЪБМф, вРВйзїЯЕЭГВЛЭЌвВгаВювь
вЛАу N ШЁ2, зюДѓбгГйЪБМфШЁ200ms
ЩгДјгІД№
дкбгГйгІД№ЕФЛљДЁЩЯ, ЮвУЧЗЂЯж, КмЖрЧщПіЯТ
ПЭЛЇЖЫКЭЗўЮёЦїдкгІгУВувВЪЧ ЁАвЛЗЂвЛЪеЁБ ЕФ
втЮЖзХПЭЛЇЖЫИјЗўЮёЦїЫЕСЫ ЁАHow are youЁБ
ЗўЮёЦївВЛсИјПЭЛЇЖЫЛивЛИі ЁАFine, thank youЁБ
ФЧУДетИіЪБКђACKОЭПЩвдДюЫГЗчГЕ, КЭЗўЮёЦїЛигІЕФ ЁАFine,
thank youЁБ вЛЦ№ЗЂЫЭИјПЭЛЇЖЫ
УцЯђзжНкСї
ДДНЈвЛИіTCPЕФsocket, ЭЌЪБдкФкКЫжаДДНЈвЛИі ЗЂЫЭЛКГхЧј КЭвЛИі НгЪеЛКГхЧј;
ЕїгУwriteЪБ, Ъ§ОнЛсЯШаДШыЗЂЫЭЛКГхЧјжа;
ШчЙћЗЂЫЭЕФзжНкЪ§ЬЋДѓ, ЛсБЛВ№ЗжГЩЖрИіTCPЕФЪ§ОнАќЗЂГі;
ШчЙћЗЂЫЭЕФзжНкЪ§ЬЋаЁ, ОЭЛсЯШдкЛКГхЧјРяЕШД§, ЕШЕНЛКГхЧјДѓаЁВюВЛЖрСЫ, ЛђепЕНСЫЦфЫћКЯЪЪЕФЪБЛњдйЗЂЫЭГіШЅ;
НгЪеЪ§ОнЕФЪБКђ, Ъ§ОнвВЪЧДгЭјПЈЧ§ЖЏГЬађЕНДяФкКЫЕФНгЪеЛКГхЧј;
ШЛКѓгІгУГЬађПЩвдЕїгУreadДгНгЪеЛКГхЧјФУЪ§Он;
СэвЛЗНУц, TCPЕФвЛИіСЌНг, МШгаЗЂЫЭЛКГхЧј, вВгаНгЪеЛКГхЧј,
ФЧУДЖдгкетвЛИіСЌНг, МШПЩвдЖСЪ§Он, вВПЩвдаДЪ§Он, етИіИХФюНазі ШЋЫЋЙЄ
гЩгкЛКГхЧјЕФДцдк, ЫљвдTCPГЬађЕФЖСКЭаДВЛашвЊвЛвЛЦЅХф
Р§Шч:
аД100ИізжНкЕФЪ§Он, ПЩвдЕїгУвЛДЮwriteаД100ИізжНк, вВПЩвдЕїгУ100ДЮwrite, УПДЮаДвЛИізжНк;
ЖС100ИізжНкЪ§ОнЪБ, вВЭъШЋВЛашвЊПМТЧаДЕФЪБКђЪЧдѕУДаДЕФ, МШПЩвдвЛДЮread 100ИізжНк, вВПЩвдвЛДЮreadвЛИізжНк,
жиИД100ДЮ;
еГАќЮЪЬт
ЪзЯШвЊУїШЗ, еГАќЮЪЬтжаЕФ ЁААќЁБ, ЪЧжИгІгУВуЕФЪ§ОнАќ.
дкTCPЕФавщЭЗжа, УЛгаШчЭЌUDPвЛбљЕФ ЁАБЈЮФГЄЖШЁБ зжЖЮ
ЕЋЪЧгавЛИіађКХзжЖЮ.
еОдкДЋЪфВуЕФНЧЖШ, TCPЪЧвЛИівЛИіБЈЮФДЋЙ§РДЕФ. АДееађКХХХКУађЗХдкЛКГхЧјжа.
еОдкгІгУВуЕФНЧЖШ, ПДЕНЕФжЛЪЧвЛДЎСЌајЕФзжНкЪ§Он.
ФЧУДгІгУГЬађПДЕНСЫетвЛСЌДЎЕФзжНкЪ§Он, ОЭВЛжЊЕРДгФФИіВПЗжПЊЪМЕНФФИіВПЗжЪЧвЛИіЭъећЕФгІгУВуЪ§ОнАќ.
ДЫЪБЪ§ОнжЎМфОЭУЛгаСЫБпНч, ОЭВњЩњСЫеГАќЮЪЬт
ФЧУДШчКЮБмУтеГАќЮЪЬтФи?
ЙщИљНсЕзОЭЪЧвЛОфЛА, УїШЗСНИіАќжЎМфЕФБпНч
ЖдгкЖЈГЄЕФАќ
- БЃжЄУПДЮЖМАДЙЬЖЈДѓаЁЖСШЁМДПЩ
Р§ШчЩЯУцЕФRequestНсЙЙ, ЪЧЙЬЖЈДѓаЁЕФ, ФЧУДОЭДгЛКГхЧјДгЭЗПЊЪМАДsizeof(Request)вРДЮЖСШЁМДПЩ
ЖдгкБфГЄЕФАќ
- ПЩвддкЪ§ОнАќЕФЭЗВП, дМЖЈвЛИіЪ§ОнАќзмГЄЖШЕФзжЖЮ, ДгЖјОЭжЊЕРСЫАќЕФНсЪјЮЛжУ
ЛЙПЩвддкАќКЭАќжЎМфЪЙгУУїШЗЕФЗжИєЗћРДзїЮЊБпНч(гІгУВуавщ, ЪЧГЬађдБздМКРДЖЈЕФ, жЛвЊБЃжЄЗжИєЗћВЛКЭе§ЮФГхЭЛМДПЩ)
ЖдгкUDPавщРДЫЕ, ЪЧЗёвВДцдк ЁАеГАќЮЪЬтЁБ Фи?
ЖдгкUDP, ШчЙћЛЙУЛгаЯђЩЯВуНЛИЖЪ§Он, UDPЕФБЈЮФГЄЖШШдШЛДцдк.
ЭЌЪБ, UDPЪЧвЛИівЛИіАбЪ§ОнНЛИЖИјгІгУВуЕФ, ОЭгаКмУїШЗЕФЪ§ОнБпНч.
еОдкгІгУВуЕФНЧЖШ, ЪЙгУUDPЕФЪБКђ, вЊУДЪеЕНЭъећЕФUDPБЈЮФ, вЊУДВЛЪе.
ВЛЛсГіЯжЪеЕН ЁААыИіЁБ ЕФЧщПі.
TCP вьГЃЧщПі
НјГЬжежЙ: НјГЬжежЙЛсЪЭЗХЮФМўУшЪіЗћ, ШдШЛПЩвдЗЂЫЭFIN. КЭе§ГЃЙиБеУЛгаЪВУДЧјБ№.
ЛњЦїжиЦє: КЭНјГЬжежЙЕФЧщПіЯрЭЌ.
ЛњЦїЕєЕч/ЭјЯпЖЯПЊ: НгЪеЖЫШЯЮЊСЌНгЛЙдк, вЛЕЉНгЪеЖЫгааДШыВйзї, НгЪеЖЫЗЂЯжСЌНгвбОВЛдкСЫ, ОЭЛсНјаа
reset. МДЪЙУЛгааДШыВйзї, TCPздМКвВФкжУСЫвЛИіБЃЛюЖЈЪБЦї, ЛсЖЈЦкбЏЮЪЖдЗНЪЧЗёЛЙдк. ШчЙћЖдЗНВЛдк,
вВЛсАбСЌНгЪЭЗХ.
СэЭт, гІгУВуЕФФГаЉавщ, вВгавЛаЉетбљЕФМьВтЛњжЦ.
Р§ШчHTTPГЄСЌНгжа, вВЛсЖЈЦкМьВтЖдЗНЕФзДЬЌ.
Р§ШчQQ, дкQQЖЯЯпжЎКѓ, вВЛсЖЈЦкГЂЪджиаТСЌНг.
TCP аЁНс
ЮЊЪВУДTCPетУДИДдг?
вђЮЊМШвЊБЃжЄПЩППад, ЭЌЪБгжвЊОЁПЩФмЬсИпадФм.
БЃжЄПЩППадЕФЛњжЦ
аЃбщКЭ
ађСаКХ(АДађЕНДя)
ШЗШЯгІД№
ГЌЪБжиДЋ
СЌНгЙмРэ
СїСППижЦ
гЕШћПижЦ
ЬсИпадФмЕФЛњжЦ
ЛЌЖЏДАПк
ПьЫйжиДЋ
бгГйгІД№
ЩгДјгІД№
ЖЈЪБЦї
ГЌЪБжиДЋЖЈЪБЦї
БЃЛюЖЈЪБЦї
TIME_WAITЖЈЪБЦї
Лљгк TCP ЕФгІгУВуавщ
HTTP
HTTPS
SSH
Telnet
FTP
SMTP
Ё
ЕБШЛ, вВАќРЈЮвУЧздМКаДTCPГЬађЪБздЖЈвхЕФгІгУВуавщ
TCP КЭ UDP ЖдБШ
ЮвУЧЫЕСЫTCPЪЧПЩППСЌНг, ФЧУДЪЧВЛЪЧTCPвЛЖЈОЭгХгкUDPФи?
TCPКЭUDPжЎМфЕФгХЕуКЭШБЕу, ВЛФмМђЕЅОјЖдЕиНјааБШНЯ
TCPгУгкПЩППДЋЪфЕФЧщПі, гІгУгкЮФМўДЋЪф, живЊзДЬЌИќаТЕШГЁОА
UDPгУгкЖдИпЫйДЋЪфКЭЪЕЪБадвЊЧѓНЯИпЕФЭЈаХСьгђ
Р§Шч, дчЦкЕФQQ, ЪгЦЕДЋЪфЕШ. СэЭтUDPПЩвдгУгкЙуВЅ
ЙщИљНсЕз, TCPКЭUDPЖМЪЧвЛжжЙЄОп, ЪВУДЪБЛњгУ, ОпЬхдѕУДгУ, ЛЙЪЧвЊИљОнОпЬхЕФашЧѓГЁОАШЅОіЖЈ.
|









