| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌжївЊНщЩмСЫЭјТчащФтЛЏЃЌДЋЭГЭјТчМмЙЙЃЌащФтЛЏЭјТчМмЙЙЃЌLinux
ЯТЭјТчЩшБИащФтЛЏЃЌШнЦїащФтЛЏЃЌdockerЭјТчФЃаЭЕШЖрИіЗНУцНщЩмЁЃ |
|
ЭјТчащФтЛЏ
ЧАбд
ЭјТчащФтЛЏЯрЖдМЦЫуЁЂДцДЂащФтЛЏРДЫЕЪЧБШНЯГщЯѓЕФЃЌвдЮвУЧдкбЇаЃЪщБОЩЯбЇЕФФЧЕуЭјТчжЊЪЖРДРэНтЭјТчащФтЛЏПЩФмЪЧВЛЙЛЕФЁЃ
дкЮвУЧЕФгЁЯѓжаЃЌЭјТчОЭЪЧгЩИїжжЭјТчЩшБИЃЈШчНЛЛЛЛњЁЂТЗгЩЦїЃЉЯрСЌзщГЩЕФвЛИіЭјзДНсЙЙЃЌЪРНчЩЯЕФШЮКЮСНИіШЫЖМПЩвдЭЈЙ§ЭјТчНЈСЂЦ№СЌНгЁЃ
ДјзХетбљвЛжжЫМТЗШЅРэНтЭјТчащФтЛЏПЩФмЛсИаОѕдЦРяЮэРяЁЊЁЊетбљвЛИіХгДѓЕФЭјТчШчКЮЪЕЯжащФтЛЏЃП
ЦфЪЕЃЌЭјТчащФтЛЏИќЖрЙизЂЕФЪЧЪ§ОнжааФЭјТчЁЂжїЛњЭјТчетбљБШНЯЁИЯИСЃЖШЁЙЕФЭјТчЃЌЫљЮНЯИСЃЖШЃЌЪЧЯрЖдРДЫЕЕФЃЌЪЧЩюШыЕНФГвЛЬЈЮяРэжїЛњжЎЩЯЕФЭјТчНсЙЙРДЬИЕФЁЃ
ШчЙћАбДЋЭГЕФЭјТчПДзїЁИКъЙлЭјТчЁЙЕФЛАЃЌФЧЭјТчащФтЛЏЙизЂЕФОЭЪЧЁИЮЂЙлЭјТчЁЙЁЃЭјТчащФтЛЏЕФФПЕФЃЌЪЧвЊНкЪЁЮяРэжїЛњЕФЭјПЈЩшБИзЪдДЁЃДгзЪдДетИіНЧЖШШЅРэНтЃЌПЩФмЛсБШНЯКУРэНтвЛЕуЁЃ
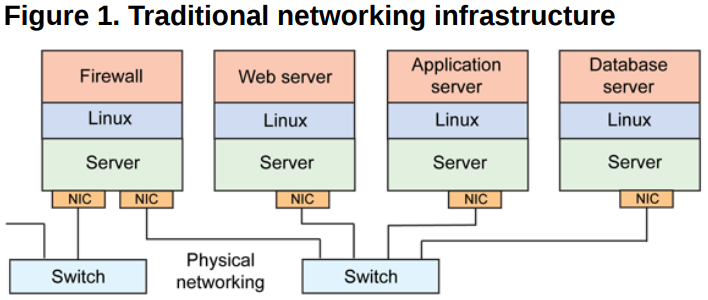
ДЋЭГЭјТчМмЙЙ
дкДЋЭГЭјТчЛЗОГжаЃЌвЛЬЈЮяРэжїЛњАќКЌвЛИіЛђЖрИіЭјПЈЃЈNICЃЉЃЌвЊЪЕЯжгыЦфЫћЮяРэжїЛњжЎМфЕФЭЈаХЃЌашвЊЭЈЙ§здЩэЕФ
NIC СЌНгЕНЭтВПЕФЭјТчЩшЪЉЃЌШчНЛЛЛЛњЩЯЃЌШчЯТЭМЫљЪОЁЃ
етжжМмЙЙЯТЃЌЮЊСЫЖдгІгУНјааИєРыЃЌЭљЭљЪЧНЋвЛИігІгУВПЪ№дквЛЬЈЮяРэЩшБИЩЯЃЌетбљЛсДцдкСНИіЮЪЬт
1ЃЉЪЧФГаЉгІгУДѓВПЗжЧщПіПЩФмДІгкПеЯазДЬЌ
2ЃЉЪЧЕБгІгУдіЖрЕФЪБКђЃЌжЛФмЭЈЙ§діМгЮяРэЩшБИРДНтОіРЉеЙадЮЪЬтЁЃВЛЙмдѕУДбљЃЌетжжМмЙЙЖМЛсЖдЮяРэзЪдДдьГЩМЋДѓЕФРЫЗбЁЃ
ащФтЛЏЭјТчМмЙЙ
ЮЊСЫНтОіетИіЮЪЬтЃЌПЩвдНшжњащФтЛЏММЪѕЖдвЛЬЈЮяРэзЪдДНјааГщЯѓЃЌНЋвЛеХЮяРэЭјПЈащФтГЩЖреХащФтЭјПЈЃЈvNICЃЉЃЌЭЈЙ§ащФтЛњРДИєРыВЛЭЌЕФгІгУЁЃ
етбљЖдгкЩЯУцЕФЮЪЬт
еыЖдЮЪЬт 1ЃЉЃЌПЩвдРћгУащФтЛЏВу Hypervisor (ЯЕЭГЙмРэГЬађ)ЕФЕїЖШММЪѕЃЌНЋзЪдДДгПеЯаЕФгІгУЩЯЕїЖШЕНЗБУІЕФгІгУЩЯЃЌДяЕНзЪдДЕФКЯРэРћгУЃЛ
еыЖдЮЪЬт 2ЃЉЃЌПЩвдИљОнЮяРэЩшБИЕФзЪдДЪЙгУЧщПіНјааКсЯђРЉШнЃЌГ§ЗЧЩшБИзЪдДвбОгУОЁЃЌЗёдђУЛгаБивЊаТдіЩшБИЁЃетжжМмЙЙШчЯТЫљЪОЁЃ
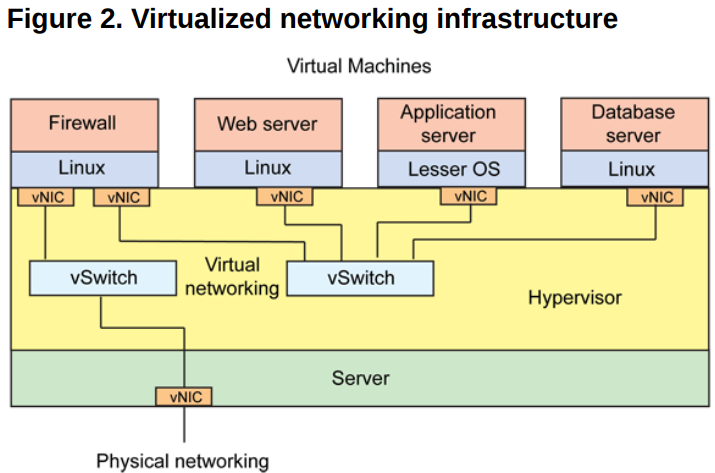
ЦфжаащФтЛњгыащФтЛњжЎМфЕФЭЈаХЃЌгЩащФтНЛЛЛЛњЭъГЩЃЌащФтЭјПЈКЭащФтНЛЛЛЛњжЎМфЕФСДТЗвВЪЧащФтЕФСДТЗЃЌећИіжїЛњФкВПЙЙГЩСЫвЛИіащФтЕФЭјТчЃЌШчЙћащФтЛњжЎМфЩцМАЕНШ§ВуЕФЭјТчАќзЊЗЂЃЌдђгжгЩСэЭтвЛИіНЧЩЋЁЊЁЊащФтТЗгЩЦїРДЭъГЩЁЃ
вЛАуЃЌетвЛећЬзащФтЭјТчЕФФЃПщЖМПЩвдЖРСЂГіШЅЃЌгЩЕкШ§ЗНРДЭъГЩЃЌШчЦфжаБШНЯГіУћЕФвЛИіНтОіЗНАИОЭЪЧ Open
vSwitchЃЈOVSЃЉЁЃ
OVS ЕФгХЪЦдкгкЫќЛљгк SDN ЕФЩшМЦддђЃЌЗНБуащФтЛњМЏШКЕФПижЦгыЙмРэЃЌСэЭтОЭЪЧЫќЗжВМЪНЕФЬиадЃЌПЩвдЁИЭИУїЁЙЕиЪЕЯжПчжїЛњжЎМфЕФащФтЛњЭЈаХЃЌШчЯТЪЧПчжїЛњЦєгУ
OVS ЭЈаХЕФЭМЪОЁЃ
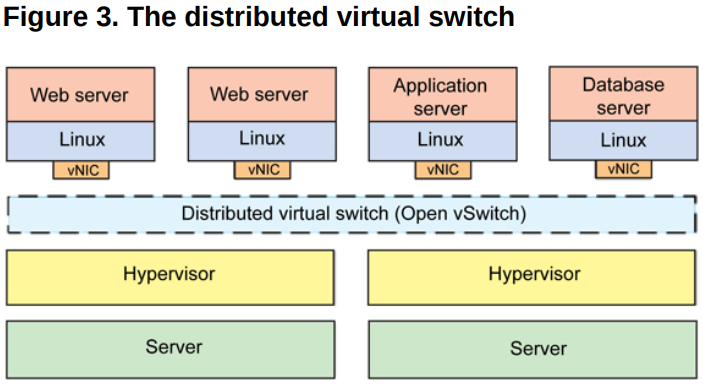
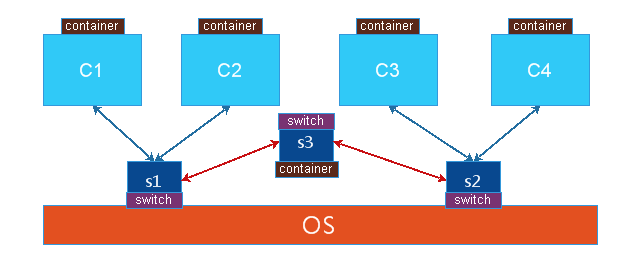
змНсЯТРДЃЌЭјТчащФтЛЏжївЊНтОіЕФЪЧащФтЛњЙЙГЩЕФЭјТчЭЈаХЮЪЬтЃЌЭъГЩЕФЪЧИїжжЭјТчЩшБИЕФащФтЛЏЃЌШчЭјПЈЁЂНЛЛЛЩшБИЁЂТЗгЩЩшБИЕШЁЃ
Linux ЯТЭјТчЩшБИащФтЛЏЕФМИжжаЮЪН
ЮЊСЫЭъГЩащФтЛњдкЭЌжїЛњКЭПчжїЛњжЎМфЕФЭЈаХЃЌашвЊНшжњФГжжЁАЧХСКЁБРДЭъГЩгУЛЇЬЌЕНФкКЫЬЌЃЈGuest ЕН
HostЃЉЕФЪ§ОнДЋЪфЃЌетжжЧХСКЕФНЧЩЋОЭЪЧгЩащФтЕФЭјТчЩшБИРДЭъГЩЃЌЩЯУцНщЩмСЫвЛИіЕкШ§ЗНЕФПЊдДЗНАИЁЊЁЊOVSЃЌЫќЦфЪЕЪЧвЛИіШкКЯСЫИїжжащФтЭјТчЩшБИЕФМЏДѓГЩепЃЌЪЧвЛИіВњЦЗМЖЕФНтОіЗНАИЁЃ
ЕЋ Linux БОЩэгЩгкащФтЛЏММЪѕЕФбнНјЃЌвВМЏГЩСЫвЛаЉащФтЭјТчЩшБИЕФНтОіЗНАИЃЌжївЊгавдЯТМИжжЃК
ЃЈ1ЃЉTAP/TUN/VETH
TAP/TUN ЪЧ Linux ФкКЫЪЕЯжЕФвЛЖдащФтЭјТчЩшБИЃЌTAP ЙЄзїдкЖўВуЃЌTUN ЙЄзїдкШ§ВуЁЃLinux
ФкКЫЭЈЙ§ TAP/TUN ЩшБИЯђАѓЖЈИУЩшБИЕФгУЛЇПеМфГЬађЗЂЫЭЪ§ОнЃЌЗДжЎЃЌгУЛЇПеМфГЬађвВПЩвдЯёВйзїЮяРэЭјТчЩшБИФЧбљЃЌЯђ
TAP/TUN ЩшБИЗЂЫЭЪ§ОнЁЃ
Лљгк TAP Ч§ЖЏЃЌМДПЩЪЕЯжащФтЛњ vNIC ЕФЙІФмЃЌащФтЛњЕФУПИі vNIC ЖМгывЛИі TAP ЩшБИЯрСЌЃЌvNIC
жЎгк TAP ОЭШчЭЌ NIC жЎгк ethЁЃ
ЕБвЛИі TAP ЩшБИБЛДДНЈЪБЃЌдк Linux ЩшБИЮФМўФПТМЯТЛсЩњГЩвЛИіЖдгІЕФзжЗћЩшБИЮФМўЃЌгУЛЇГЬађПЩвдЯёДђПЊвЛИіЦеЭЈЮФМўвЛбљЖдетИіЮФМўНјааЖСаДЁЃ
БШШчЃЌЕБЖдетИі TAP ЮФМўжДаа write ВйзїЪБЃЌЯрЕБгк TAP ЩшБИЪеЕНСЫЪ§ОнЃЌВЂЧыЧѓФкКЫНгЪмЫќЃЌФкКЫЪеЕНЪ§ОнКѓНЋИљОнЭјТчХфжУНјааКѓајДІРэЃЌДІРэЙ§ГЬРрЫЦгкЦеЭЈЮяРэЭјПЈДгЭтНчЪеЕНЪ§ОнЁЃЕБгУЛЇГЬађжДаа
read ЧыЧѓЪБЃЌЯрЕБгкЯђФкКЫВщбЏ TAP ЩшБИЪЧЗёгаЪ§ОнвЊЗЂЫЭЃЌгаЕФЛАдђЗЂЫЭЃЌДгЖјЭъГЩ TAP ЩшБИЕФЪ§ОнЗЂЫЭЁЃ
TUN дђЪєгкЭјТчжаШ§ВуЕФИХФюЃЌЪ§ОнЪеЗЂЙ§ГЬКЭ TAP ЪЧРрЫЦЕФЃЌжЛВЛЙ§ЫќвЊжИЖЈвЛЖЮ IPv4 ЕижЗЛђ
IPv6 ЕижЗЃЌВЂУшЪіЦфЯрЙиЕФХфжУаХЯЂЃЌЦфЪ§ОнДІРэЙ§ГЬвВЪЧРрЫЦгкЦеЭЈЮяРэЭјПЈЪеЕНШ§Ву IP БЈЮФЪ§ОнЁЃ
VETH ЩшБИзмЪЧГЩЖдГіЯжЃЌвЛЖЫСЌзХФкКЫавщеЛЃЌСэвЛЖЫСЌзХСэвЛИіЩшБИЃЌвЛИіЩшБИЪеЕНФкКЫЗЂЫЭЕФЪ§ОнКѓЃЌЛсЗЂЫЭЕНСэвЛИіЩшБИЩЯШЅЃЌетжжЩшБИЭЈГЃгУгкШнЦїжаСНИі
namespace жЎМфЕФЭЈаХЁЃ
ЃЈ2ЃЉBridge
Bridge вВЪЧ Linux ФкКЫЪЕЯжЕФвЛИіЙЄзїдкЖўВуЕФащФтЭјТчЩшБИЃЌЕЋВЛЭЌгк TAP/TUN етжжЕЅЖЫПкЕФЩшБИЃЌBridge
ЪЕЯжЮЊЖрЖЫПкЃЌБОжЪЩЯЪЧвЛИіащФтНЛЛЛЛњЃЌОпБИКЭЮяРэНЛЛЛЛњРрЫЦЕФЙІФмЁЃ
Bridge ПЩвдАѓЖЈЦфЫћ Linux ЭјТчЩшБИзїЮЊДгЩшБИЃЌВЂНЋетаЉДгЩшБИащФтЛЏЮЊЖЫПкЃЌЕБвЛИіДгЩшБИБЛАѓЖЈЕН
Bridge ЩЯЪБЃЌОЭЯрЕБгкецЪЕЭјТчжаЕФНЛЛЛЛњЖЫПкЩЯВхШыСЫвЛИљСЌгажеЖЫЕФЭјЯпЁЃ
ШчЯТЭМЫљЪОЃЌBridge ЩшБИ br0 АѓЖЈСЫЪЕМЪЩшБИ eth0
КЭ ащФтЩшБИ?tap0/tap1ЃЌЕБетаЉДгЩшБИНгЪеЕНЪ§ОнЪБЃЌЛсЗЂЫЭИј br0 ЃЌbr0 ЛсИљОн MAC
ЕижЗгыЖЫПкЕФгГЩфЙиЯЕНјаазЊЗЂЁЃ
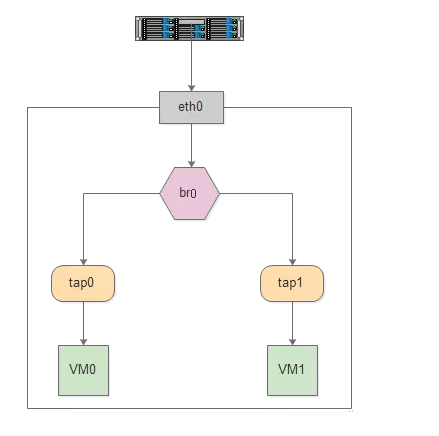
вђЮЊ Bridge ЙЄзїдкЖўВуЃЌЫљвдАѓЖЈЕНЫќЩЯУцЕФДгЩшБИ eth0ЁЂtap0ЁЂtap1 ОљВЛашвЊЩш
IPЃЌЕЋЪЧашвЊЮЊ br0 ЩшжУ IPЃЌвђЮЊЖдгкЩЯВуТЗгЩЦїРДЫЕЃЌетаЉЩшБИЮЛгкЭЌвЛИізгЭјЃЌашвЊвЛИіЭГвЛЕФ
IP НЋЦфМгШыТЗгЩБэжаЁЃ
етРягаШЫПЩФмЛсгавЩЮЪЃЌBridge ВЛЪЧЙЄзїдкЖўВуТ№ЃЌЮЊЪВУДЛсга IP ЕФЫЕЗЈЃПЦфЪЕ Bridge
ЫфШЛЙЄзїдкЖўВуЃЌЕЋЫќжЛЪЧ Linux ЭјТчЩшБИГщЯѓЕФвЛжжЃЌФмЩш IP вВВЛзуЮЊЦцЁЃ
ЖдгкЪЕМЪЩшБИ eth0 РДЫЕЃЌБОРДЫќЪЧгаздМКЕФ IP ЕФЃЌЕЋЪЧАѓЖЈЕН br0 жЎКѓЃЌЦф IP ОЭЩњаЇСЫЃЌОЭКЭ
br0 ЙВЯэвЛИі IP ЭјЖЮСЫЃЌдкЩшТЗгЩБэЕФЪБКђЃЌОЭашвЊНЋ br0 ЩшЮЊФПБъЭјЖЮЕФЕижЗЁЃ
змНс
ДЋЭГЭјТчМмЙЙЕНащФтЛЏЕФЭјТчМмЙЙЃЌПЩвдПДзїЪЧКъЙлЭјТчЕНЮЂЙлЭјТчЕФЙ§ЖЩ
TAP/TUN/VETHЁЂBridge етаЉащФтЕФЭјТчЩшБИЪЧ Linux ЮЊСЫЪЕЯжЭјТчащФтЛЏЖјЪЕЯжЕФЭјТчЩшБИФЃПщЃЌКмЖрЕФдЦПЊдДЯюФПЕФЭјТчЙІФмЖМЪЧЛљгкетаЉММЪѕзіЕФЃЌБШШч
NeutronЁЂDocker network ЕШЁЃ
OVS ЪЧвЛИіПЊдДЕФГЩЪьЕФВњЦЗМЖЗжВМЪНащФтНЛЛЛЛњЃЌЛљгк SDN ЕФЫМЯыЃЌБЛДѓСПгІгУдкЩњВњЛЗОГжаЁЃ
ШнЦїащФтЛЏ
УћГЦПеМфЃКUTSЁЂUserЁЂMountЁЂIPCЁЂPIDЁЂNET
NETЃКЭјТчУћГЦПеМф
УшЪіЃКжївЊЪЧЭјТчЩшБИЁЂавщеЛЕШЪЕЯжЃЌМйЩшЮяРэЛњЩЯгаЫФПщЭјПЈЃЌашвЊДДНЈСНИіУћГЦПеМфЃЌетаЉЩшБИПЩвдЕЅЖРЙиСЊИјФГИіПеМфЫљЪЙгУЕФЃЌШчЕквЛИіЭјПЈЗжХфИјЕквЛИіУћГЦПеМфЪЙгУЃЌЦфЫћОЭПДВЛМћетИіЩшБИСЫЃЌвЛИіЩшБИвЛАужЛФмЪкгшвЛИіПеМфЃЌЭЌбљгаЫФИіЭјПЈОЭПЩвдЪЙгУЫФИіУћГЦПеМфЃЌЪЙЕУУПИіУћГЦПеМфЖМПЩвдХфжУIPЕижЗгыЭтНчНјааЭЈаХЁЃ
ЁЁЁЁШчЙћУћГЦПеМфЕФЪ§СПГЌЙ§ЮяРэЭјПЈЪ§СПЃЌУПИіУћГЦПеМфФкВПЕФНјГЬвВЪЧашвЊЭЈЙ§ЭјТчНјааЭЈаХЃЌгІИУШчКЮЩЯБЈЃЌПЩвдЪЙгУФЃФтММЪѕЃЌlinuxЩшБИжЇГжСНжжФкКЫМЖЕФФЃФтЃЌЪЧЖўВуЩшБИКЭШ§ВуЩшБИЃЌЭјПЈОЭЪЧвЛИіЖўВуЩшБИЃЌЙЄзїдкСДТЗВуЃЌФмЙЛЗтзАБЈЮФЪЕЯжИїЩшБИжЎМфБЈЮФзЊЗЂЕФЪЕЯжЃЌетЙІФмЪЧЭъШЋПЩвддкLinuxжЎЩЯРћгУФкКЫжаЖдЖўВуащФтЩшБИЕФжЇГжЃЌДДНЈащФтЭјПЈНгПкЃЌЖјЧветжжащФтЭјПЈНгПкКмЖРЬиЃЌУПИіЭјТчНгПкЩшБИЪЧГЩЖдГіЯжЕФЃЌПЩвдФЃФтЮЊвЛИљЭјЯпЕФСНЭЗЃЌЦфжавЛЭЗПЩвдВхдкжїЛњжЎЩЯЃЌСэвЛЭЗВхдкНЛЛЛЛњжЎЩЯНјааФЃФтЃЌЯрЕБгквЛИіжїЛњСЌНгЕННЛЛЛЛњЩЯШЅСЫЃЌЖјlinuxФкКЫдДЩњОЭжЇГжФЃФтЖўВуЭјТчЩшБИЃЌЪЙгУШэМўРДЙЙНЈвЛИіНЛЛЛЛњЁЃ
ЁЁЁЁШчЙћгаСНИіУћГЦПеМфЃЌФЧУДСНЬЈжїЛњОЭЯёСЌНгЕНЭЌвЛИіНЛЛЛЛњЩЯНјааЭЈаХЃЌШчЙћХфжУЕФЭјТчЕижЗдкЭЌвЛИіЭјЖЮОЭПЩвджБНгНјааЭЈбЖСЫЁЃетОЭЪЧащФтЛЏЕФЭјТчЁЃ
OVS: OpenVSwitch ПЩвдФЃФтИпМЖЕФЭјТчММЪѕЃЌЖўВуНЛЛЛЃЌЩѕжСШ§ВуЭјТчЩшБИЃЌvlanЃЌЃЌВЛЪєгкLinuxФкКЫзщМўЃЌвЊЖюЭтАВзАЃЌгЩciscoжкЖрЙЋЫОЫљЙЙНЈЕФЃЌгадЦМЦЫуЕФРЫГБЯТЃЌЙЙНЈЭјТчЪЧБШНЯИДдгЕФЃЌШЛКѓВХЪЧЭјТчжЎЩЯЫљГадиЕФжїЛњЃЌВХФмЭЈбЖЃЌетИіЭјТчащФтЛЏЫљЪЕЯжЕФЙІФмЃЌашвЊШэМўгВМўНсКЯЦ№РДЪЕЯжЃЌЖјЧвАбДЋЭГвтвхЩЯЕФЭјТчЦНУцЃЌПижЦЦНУцЃЌДЋЪфЦНУцЕШЃЌИєРыПЊРДЃЌМЏжаЕНвЛИіЩшБИжЎЩЯЪЕЯжШЋОжЕФЕїЖШЃЌЪЕЯжSDN,ШэМўЖЈвхЭјТч
ЕЅНкЕуЩЯШнЦїЭЈбЖЃКЭЌвЛИіЮяРэЛњЩЯЕФСНИіШнЦїЃЌЛђепСНИіУћГЦПеМфвЊЭЈбЖЃЌОЭЪЧдкжїЛњЩЯНЈСЂвЛИіащФтЕФНЛЛЛЛњЃЌШУСНИіШнЦїИїздЪЙгУДПШэМўЕФЗНЪНЃЌНЈвЛЖдащФтЭјПЈЃЌвЛАыдкНЛЛЛЛњЩЯЃЌвЛАыдкШнЦїЩЯЃЌДгЖјЪЕЯжЕЅНкЕуЩЯШнЦїНјааЭЈбЖЃЌЕЋЪЧвВгаБШНЯИДдгЕФЧщПіЃЌгаПЩФмЛсГіЯжгаСНИіШэНЛЛЛЛњЕФЧщПіЃЌСЌНгВЛЭЌЕФШнЦїЃЌетЪБСНИіШэНЛЛЛЛњвЊСЌНгЃЌашвЊдйзівЛПщЭјПЈЃЌвЛЭЗдкНЛЛЛЛњ1ЩЯЃЌСэвЛЭЗдкНЛЛЛЛњ2жЎЩЯЃЌШчЙћВЛЭЌНЛЛЛЛњжЎМфвЊЪЕЯжТЗгЩзЊЗЂЃЌОЭашвЊдкСНФмНЛЛЛЛњЩЯМгвЛЬЈТЗгЩЦїЃЌlinuxФкКЫздЩэПЩвдЕБзїТЗгЩЦїРДЪЙгУЃЌДђПЊзЊЗЂЛђепЪЙгУiptablesЙцдђЃЌЕЋЪЧТЗгЩЦїЪЧвЛИіШ§ВуЕФЩшБИЃЌдкlinuxФкКЫжБНгЪЙгУвЛИіЕЅЖРЕФУћГЦПеМфОЭПЩвдЪЕЯжЃЌОЭЪЧдйзівЛИіШнЦїЕБзїТЗгЩЦїРДЪЙгУЃЌЕБЪЧвЊФЃФтГіЭјПЈРДШУЫќУЧНЈСЂЙиСЊЙиЯЕ
ЖрНкЕуЃКСэвЛЬЈжїЛњЩЯЕФвЛИіШнЦїЃЌгы1КХжїЛњЩЯЕФШнЦїНјааЭЈаХЃЌvmwareЪЕЯжВЛЭЌжїЛњЩЯЕФащФтЛњжЎМфЕФЭЈбЖПЩвдЪЙгУЧХНгЕФЗНЪНЃЌОЭЪЧАбЮяРэЭјПЈЕБзїНЛЛЛЛњРДЪЙгУЃЌЫљгавЛЬЈжїЛњЩЯЕФШнЦїЖМЕНвЛИіЮяРэЭјПЈРДЃЌЭЈЙ§MACЕижЗРДШЗЖЈНЛИјФЧИіШнЦїЃЌШчЙћЪЧЕНЮяРэЛњЕФЃЌОЭИјЮяРэЛњЃЌвВОЭЪЧащФтЛњРявВгаздЩэЕФЖРЬиЕФMACЕижЗЃЌЫљвдЪ§ОнАќРДЪБПЩвдЧјБ№ИїИіЩшБИЃЌАбЮяРэЭјПЈЕБзїНЛЛЛЛњРДЪЙгУЃЌАбБЈЮФзЊЗЂИјИїШнЦїЃЌШчЙћБЈЮФФПБъЪЧЮяРэЭјПЈЪБЃЌашвЊащФтГівЛИіШэЭјПЈзїЮЊЮяРэЭјПЈЕФЪЙгУЃЌетбљОЭУЛгаащФтНЛЛЛЛњИХФюЃЌЫљвдСНЬЈжїЛњЩЯЕФащФтЛњвЊЪЙгУЧХНгЭЈбЖЪБЃЌЖМЪЧСЌНгЕНИїзджїЛњЩЯЕФЮяРэЭјПЈЕФЕФЃЌЕЋЪЧетжжЭЈбЖЗНЪНвЊЪЕЯжгаКмДѓЕФДњМлЃЌвђЮЊЫљгаШнЦїЕФЧХНгЖМдкЭЌвЛИіЦНУцжаЃЌКмШнвзВњЩњЗчБЉЃЌЫљвддкДѓЙцФЃЕФащФтЛњЛђШнЦїЕФЪЙгУГЁОАжаЪЙгУЧХНгВЛЬЋКУЃЌГ§ЗЧФмИєРыЕУКмКУ(ЧХНг)
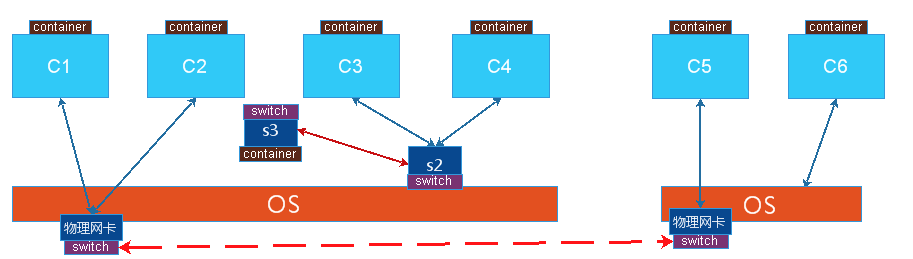
NatММЪѕЃКШчЭМжаC3гыC6ЭЈбЖЃЌC3ЪЧащФтЭјПЈЃЌC3ЭјПЈгыЮяРэЭјПЈЮяРэЕижЗВЛдкЭЌвЛИіЭјЖЮжа,C3АбЭјЙижИЯђS2,АбS3ЕБзїЫожїЛњЕФвЛИіЭјПЈРДЪЙгУЃЌIPЕижЗгыC3дкЭЌвЛИіЭјЖЮЃЌАбC3ЕФЭјЙижИЯђS2,ШЛКѓдкЮяРэЛњЩЯДђПЊКЫаФзЊЗЂЙІФмЃЌЫљвдЕБC3гыC6ЭЈбЖЪБЃЌЯШзЊИјs2,дйЕНДяФкКЫЃЌФкКЫХаЖЈВщТЗгЩСаВЛЪЧздМКвЊЕНСэвЛИіжїЛњЩЯЕФC6ЃЌетЪББЈЮФЛиВЛРДЃЌвђЮЊC3КЭC4ЪЧвЛИіЫНгаЕижЗЃЌШчЙћвЊБЈЮФФмЙЛЛиРДЃЌзюКѓЕНБЈЮФЫЭзпЮяРэЛњжЎЧАЃЌвЊАбдДIPЕижЗаоИФГЩЮяРэЭјПЈЕФIPЕижЗЃЌетбљC5ЛђепC6ЛиИДЮяРэжїЛњЕФIPОЭПЩвдСЫЃЌЭЈЙ§NATБэЕФВщбЏЪЧC3ЕФЗУЮЪЃЌОЭАбБЈЮФЫЭИјC3,етОЭЪЙгУNATЪЕЯжПчжїЛњжЎМфЕФЭЈбЖЃЌЕЋЪЧетРягавЛИіКмДѓЕФЮЪЬтЃЌC6вВПЩФмЪЧNATЕФФЃЪНЯТЙЄзїЃЌвВОЭЪЧЫЕЫќвВЪЧЪЙгУЫНгаЕижЗЕФЃЌШчЙћC6вЊБЛЗУЮЪжЛФмАбЫќБЉТЖГіШЅЃЌдкЮяРэЛњЕФФмЭтЭјПЈЩЯУїШЗЫЕУїФГИіЖЫПкЪЧЬсЙЉЗўЮёЕФЃЌШчЙћвЊC4ФмЙЛЗУЮЪC6ЃЌОЭвЊЯШЗУЮЪC6ЫљдкЕФЫожїЛњЕФЮяРэЕижЗЃЌдйЪЙгУH2зіdnatЗЂИјC6,ЕЋЪЧC4ЗЂЫЭБЈЮФЪБЪЧЭЈЙ§SNATГіРДЕФЃЌC4вВЪЧвўВидкNATБГКѓЕФЃЌЗЂГіШЅЕФБЈЮФвЊЦфЫћЕФжїЛњПЩвдЯьгІОЭгІИУИФаДдДЕижЗЁЃЫљвддкПчЗўЮёжїЛњЪЕЯжСНИіащФтЛњжЎМфЕФЭЈбЖвЊЪЕЯжСНМЖЕФNATВйзїЃЌДгC4ЕНC6ЃЌЪзЯШC4ГіШЅОЭSNAT,ЕНЕНC6вЊЪЙгУЕНDNATЃЌетбљЕФаЇТЪВЛЛсИпЃЌЕЋЪЧЭјТчБШНЯШнвзЙмРэЁЃ
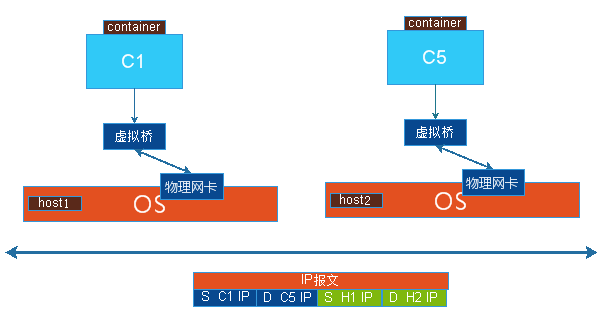
Overlay Network: ЕўМгЭјТчЃЌЪЧNATКЭЧХНгЕФвЛИіНтОіЗНАИЃЌгаЖрИіЮяРэжїЛњЃЌдкащФтЛњЩЯзівЛИіащФтЕФЧХЃЌШУИїащФтЛњСЌНгЕНащФтЧХЩЯЃЌЭЈаХЪБНшгУЮяРэЭјТчРДЭъГЩБЈЮФЕФЫэЕРзЊЗЂЃЌДгЖјЪЕЯжC1ПЩвджБНгПДМћC5ЛђC6,ЮяРэжїЛњБОРДОЭЪЧЪЙгУЮяРэЭјТчСЌНгдквЛЦ№ЕФЃЌC1гыЮяРэЭјТчВЛдкЭЌвЛИіЕижЗЖЮФкЃЌЕЋЪЧC1гыC5ЪЧдкЭЌвЛЕижЗЖЮФкЕФЃЌC1ЗЂЫЭБЈЮФЪБЃЌЯШЗЂЫЭИјащФтЛњЃЌМйЩшЫќЪЧжЊЕРC5ЪЧВЛвЊБОЕиЕФЮяРэжїЛњЩЯЕФЃЌвдЪЧБЈЮФвЊДгЮяРэЭјПЈЗЂЫЭГіШЅЃЌЕЋЪЧвЊзіЫэЕРзЊЗЂЃЌвВОЭЪЧC1ЕФБЈЮФдДIPЕижЗЪЧC1,ФПБъЕижЗЪЧC5ЃЌШЛКѓдйЗтзАвЛИіIPАќЭЗЕФЪзВПдДЕижЗЪЧC1ЫљдкЮяРэжїЛњЕФIPЕижЗЃЌФПБъЕижЗЪЧC5ЫљдкЮяРэжїЛњЕФIPЕижЗЃЌЕББЈЮФЫЭЕНC5ЫљдкЕФЮяРэЛњЃЌАбБЈЮФВ№ЭъЕквЛВуКѓЃЌЕкЖўВуЕФФПБъЕижЗОЭЪЧC5ЕФЃЌОЭжБНгНЛИјБОЕиЕФШэНЛЛЛЛњЃЌдйНЛИјC5ЃЌC1гыC5жЎМфЕФЭЈбЖжБНгдДЕижЗКЭФПБъЕижЗОЭЪЧИїздЫЋЗНЃЌЕЋЪЧЫќМФгкБ№ЕФЭјТчЃЌБОЕиздЩэОЭЪЧвЛИіШ§ВуЕФЭјТчЃЌгІИУЗтзАЖўВуЃЌЕЋЪЧУЛгаЗтзАЃЌгжЗтзАШ§ВуЫФВуБЈЮФЃЌОЭЪЧвЛИіTCPЛђепUDPЕФЪзВПЃЌдйЗтзАвЛИіЪзВПЪЕЯжвЛИіСНМЖЕФШ§ВуЗтзАЃЌДгЖјЭъГЩБЈЮФЕФзЊЗЂ
dockerЭјТч:bridgeЁЂhostЁЂnone
bridge:ЧХНгЪБЭјТчЃЌВЂВЛЪЧЮяРэЧХЃЌАбБОЛњЩЯДДНЈвЛИіДПДтЕФШэНЛЛЛЛњdocker0ЃЌвВПЩвдЕБзїЭјПЈРДЪЙгУЃЌУПЦєЖЏвЛИіШнЦїОЭПЩвдИјШнЦїЗжХфвЛЖЮЭјПЈЕФЕижЗЃЌвЛАыдкШнЦїЩЯЃЌвЛАыдкdocker0ЧХЩЯЃЌveth176661bетжждкЛњЦїПЩвдПДЕНЕФЮоТлШнЦїЛЙЪЧKVMЪБЃЌУПДЮДДНЈЭјПЈЪБЃЌЖМЪЧДДНЈвЛЖдЕФЃЌвЛАыЗХдкащФтЛњЩЯЃЌвЛАыЗХдкШэНЛЛЛЛњЩЯЃЌЯрЕБгквЛИљЭјЯпСЌНгзХСНИіЩшБИвЛбљЁЃ

[root@node1 ~]#
ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
?mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast
172.17.255.255
veth56d0ee7: flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
mtu 1500
inet6 fe80::8c58:bff:fed2:1390 prefixlen 64 scopeid
0x20<link>
veth8853ed8: flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
mtu 1500
inet6 fe80::98fd:21ff:fe2e:54ef prefixlen 64 scopeid
0x20<link>
veth93be8d9: flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
mtu 1500
inet6 fe80::2424:7dff:fe25:9886 prefixlen 64 scopeid
0x20<link>
vethf4c3d12: flags=4163<UP,BROADCAST,RUNNING,MULTICAST>
mtu 1500
|
зЂЃКвђЮЊЦєЖЏСЫЫФИіШнЦїЃЌЫљвдЩњГЩСЫЫФИіащФтIPЃЌЭЌЪБетЫФИіащФтIPЖМЪЧВхдкdocker0ЧХЩЯЕФ
[root@node1 ~]#
yum install bridge-utils -y
[root@node1 ~]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.024201e0b27e no &nveth56d0ee7
veth8853ed8
veth93be8d9
|
[root@node1 ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc
noqueue state UNKNOWN mode DEFAULT group default qlen
1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu
1500 qdisc pfifo_fast state UP mode DEFAULT group
default qlen 1000
link/ether 00:0c:29:52:7f:22 brd ff:ff:ff:ff:ff:ff
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu
1500 qdisc pfifo_fast state UP mode DEFAULT group
default qlen 1000
link/ether 00:0c:29:52:7f:2c brd ff:ff:ff:ff:ff:ff
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue state UP mode DEFAULT group
default?
link/ether 02:42:01:e0:b2:7e brd ff:ff:ff:ff:ff:ff
6: vethf4c3d12@if5: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master docker0 state UP mode
DEFAULT group default?
link/ether 62:45:53:e4:fd:29 brd ff:ff:ff:ff:ff:ff
link-netnsid 0
8: veth93be8d9@if7: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master docker0 state UP mode
DEFAULT group default?
link/ether 26:24:7d:25:98:86 brd ff:ff:ff:ff:ff:ff
link-netnsid 1
10: veth56d0ee7@if9: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master docker0 state UP mode
DEFAULT group default?
link/ether 8e:58:0b:d2:13:90 brd ff:ff:ff:ff:ff:ff
link-netnsid 2
12: veth8853ed8@if11: <BROADCAST,MULTICAST,UP,LOWER_UP>
mtu 1500 qdisc noqueue master docker0 state UP mode
DEFAULT group default?
link/ether 9a:fd:21:2e:54:ef brd ff:ff:ff:ff:ff:ff
link-netnsid 3
зЂЃККьЩЋЮЊШнЦїФкВПЭјПЈ
[root@node1 ~]#
docker attach b1 //НјШыШнЦїb1
/ # ls
bin data dev etc home proc root sys
tmp usr var
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 ?Bcast:172.17.255.255
Mask:255.255.0.0
/ # ping 172.17.0.1
PING 172.17.0.1 (172.17.0.1): 56 data bytes
64 bytes from 172.17.0.1: seq=0 ttl=64 time=0.249
ms
|
NatЧХЃКdockerДДНЈЪБФЌШЯОЭЪЧnatЧХЃЌЪЧЪЙгУIptablesРДЪЕЯжЕФ
[root@node1 ~]# iptables -t nat -vnL
Chain PREROUTING (policy ACCEPT 13 packets, 1843 bytes)
pkts bytes target prot opt in out source
destination
5 268 DOCKER all -- * * 0.0.0.0/0
0.0.0.0/0 ADDRTYPE match dst-type
LOCAL
Chain INPUT (policy ACCEPT 13 packets, 1843 bytes)
pkts bytes target prot opt in out source
destination
Chain OUTPUT (policy ACCEPT 69 packets, 5112 bytes)
pkts bytes target prot opt in out source
destination
0 0 DOCKER all -- * * 0.0.0.0/0
!127.0.0.0/8 ADDRTYPE match dst-type
LOCAL
Chain POSTROUTING (policy ACCEPT 69 packets, 5112
bytes)
pkts bytes target prot opt in out source
destination
0 0 MASQUERADE all -- * !docker0 172.17.0.0/16
0.0.0.0/0
in: ДгЪЙгУНгПкНјРДЃЌжЛвЊВЛГіdocker0ГіШЅЃЌдДЕижЗРДздгк172.17.0.0/16ЕФЃЌЮоТлЕНДяШЮКЮжїЛњ0.0.0.0/0ЃЌЖМвЊзіЕижЗЮБзАMASQUERADEЃЌЯрЕБгкSNAT,ЖјЧвЪЧздЖЏЪЕЯжSNATЃЌвВОЭЪЧздЖЏбЁдёвЛИізюКЯЪЪЮяРэЕижЗЕБзїдДЕижЗЃЌЫљвдdocker0ЧХФЌШЯОЭЪЧnatЧХ
Chain DOCKER (2
references)
pkts bytes target prot opt in out
source destination
1 84 RETURN all -- docker0 *
0.0.0.0/0 0.0.0.0/0
|
ШнЦїжаЭјТчЭЈбЖЧщПі
a. ЭЌвЛИіЫожїЛњжаЃЌЪЙгУЭЌвЛИіdocker0жаЕФШэНЛЛЛЛњНјааЭЈбЖ
[root@node1 ~]# docker exec -it web1 /bin/sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:05
inet addr:172.17.0.5 Bcast:172.17.255.255
Mask:255.255.0.0
/ # netstat -lnt
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign
Address State
tcp 0 0 0.0.0.0:80 0.0.0.0:*
LISTEN
/ # wget -O - -q http://172.17.0.5
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
[root@node1 ~]# curl http://172.17.0.5
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
b. ПчжїЛњЭЈбЖ
дкЭЌвЛИіЫоЗНЛњжЎМфЕФШнЦїЭЈбЖПЩвдЪЕЯжЃЌЕЋЪЧПчжїЛњОЭЛсВњЩњЮЪЬтЃЌвђЮЊdockerБОЩэОЭЪЧвЛИіnat bridge,ЖдЭтРДЫЕЪЧВЛПЩМћЕФЃЌвЊЪЕЯжВЛЭЌжїЛњжЎМфЕФШнЦїЕФЪЕЯжЭЈбЖЃЌОЭвЊзіdnatЃЌАбНгПкжаЗЂВМГіРДЕФЃЌМйЩшЮяРэжїЛњЩЯгавЛИіЮяРэЭјПЈЃЌПЊЭЈвЛИіЖЫПкШЛКѓЬсЙЉЖдЭтЗўЮёЃЌЭтВПжїЛњЗУЮЪШнЦїжаЕФЗўЮёЪБЃЌЪЙгУdnatЕФЗНЪНзЊЕНШнЦїжаЕФащФтЭјПЈжаЃЌЬсЙЉЗўЮёЁЃ
ЕЋЪЧДцдквЛИіЮЪЃЌШчЙћдкЭЌвЛЬЈЫожїЛњЩЯЃЌЦ№СЫСНИіШнЦїЗжБ№ЪЧСНИіnginxЕФwebЗўЮёЃЌЕЋЪЧЖдЭтЕФIPжЛгавЛИіЃЌжЛФмЪЙгУЖЫПкРДЧјЗжЃЌМйЩшnginx1ЪЙгУ80ЃЌСэвЛИіnginx2ОЭжЛФмЪЙгУЗЧ80ЕФЖЫПкЃЌетЪБclientЗУЮЪЕФГіЯжЮЪЬтЃЌвђЮЊФЌШЯЗУЮЪОЭвЊИј80ЃЌШчЙћЪЧЗЧ80ЖЫПкОЭЧыЧѓВЛЕНЁЃ
ШчВщЪЙгУovetlay networkЕўМгЭјТчЗНЪНОЭПЩвджБНгЪЙгУЫэЕРРДГадиЃЌжБНгЗУЮЪОЭПЩвдСЫЃЌПЩвдВЛгУЖдЕижЗНјаагГЩфЁЃвЛАуЕФПчжїЛњжЎМфЕФащФтЛњЗУЮЪЗНЪНЧХНгЁЂnatЕФЁЃ
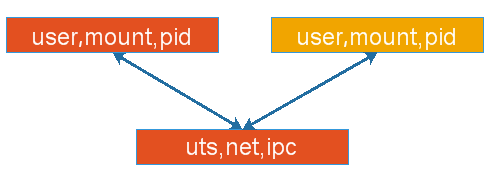
ШнЦїЬиЪтЙІФмЃЌдкШнЦїФкВПга6ИіИєРыЕФУћГЦПеМфЃЌuser,mount,pid,uts,net,ipcЃЌУПИіШнЦїЖМгаздЩэЖРСЂЕФзЪдДЃЌМйЩшШУУПИіШнЦїЖМгаИєРыЖјЖРСЂЕФuser,mount,pid,Жјuts,net,ipcетШ§ИізЪдДЪЧЙВЯэЪЙгУЕФЃЌгЕгаЭЌвЛИіЭјПЈЃЌЭЌвЛзщЭјТчавщеЛЃЌгаЭЌвЛИіжїЛњУћКЭгђУћЃЌЖдЭтЪЙгУЭЌвЛИіIPЕижЗЃЌгХЕуЪЧШчЕквЛИіШнЦїЪЙгУЕФtomcatЗўЮёЃЌЕкЖўИіШнЦїЕФЪЧredisЗўЮёЪБЃЌШчЙћtomcatвЊЗУЮЪredisжаЕФЪ§ОнЪБЃЌЪЧЭЌвЛИіавщеЛЃЌжЎЧАШчЙћЪЧИєРыЕФЃЌЭЈЙ§127РДЗУЮЪЪЧВЛПЩвдЕФЃЌЪЕЯжгаздМКЖРСЂИєРыЕФУћГЦПеМфЃЌШДгжЙВЯэвЛВПЗжУћГЦПеМфdockerжаЕФhostФЃЪН
ЮяРэЛњвВгаУћГЦПеМфЃЌвВШУШнЦїЪЙгУЮяРэЛњЕФУћГЦПеМфЃЌШнЦїКЭШнЦїжЎМфПЩвдЙВЯэУћГЦПеМфЃЌЫљвдвВПЩвдЙВЯэЮяРэЗўЮёЦїЕФУћГЦПеМфРДЪЙгУЃЌШчПЩвдШУЕквЛИіШнЦїжБНгЪЙгУЮяРэЛњЕФУћГЦПеМфЃЌвВОЭЪЧШнЦїжааоИФЭјПЈжаЕФаХЯЂЪЧжБНгИФЮяРэЛњжаЕФЭјПЈЕФаХЯЂЕФЃЌЕкЖўИіШнЦїПЩвдЪЙгУЧХНгЃЌЫљвдЕквЛИіШнЦїОЭгЕгаСЫЙмРэЭјТчЕФЬиШЈhostОЭЪЧШУШнЦїЪЙгУЫожїЛњЕФЭјТчУћГЦПеМф
dockerжаЕФnoneФЃЪН
ЩшЖЈШнЦїЪЙгУnoneЭјТчБэЪОУЛЕФЭјТчЃЌЯрЕБгкУЛгаЭјПЈЃЌжЛгаLoopНгПкЃЌгааЉШнЦїПЩФмжЛашвЊВЛЯђЭтЭЈбЖЕФ
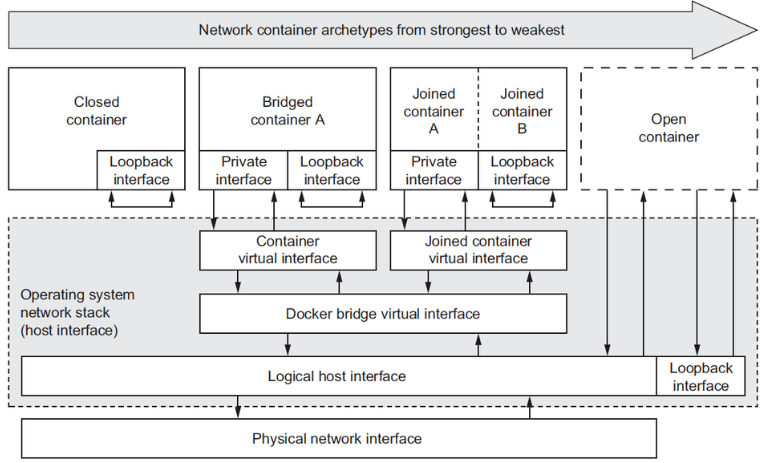
dockerЭјТчФЃаЭ
closed container ЗтБеЪНЭјТчНгПкЃЌжЛгаLoopНгПк
bridged container ЧХНгЃЌЪЙгУШнЦїНгПкСЌНгЕНdocker0ЩЯЃЌФЌШЯЩшжУЕФ
jonied container СЊУЫЪНШнЦїЭјТчЃЌвЛВПЗжУћГЦПеМфЪЧИєРыЕФЃЌЮФМўЯЕЭГЃЌгУЛЇЃЌpidЪЧИїздЕФЃЌЦфЫћШ§ИіЪЧЙВЯэЕФЃЌ
СНИіШнЦїПЩвдЪЙгУloopНгПкРДЭЈбЖ ,ПЊЗХЪНШнЦїЭјТч,жБНгЙВЯэЮяРэЛњЕФЭјТчНгПк
[root@node1 ~]# docker network inspect bridge|grep
bridge.name
"com.docker.network.bridge.name":"docker0",#bridgeЭјТчЫљЙиСЊЕФЪЧdocker0
|









