| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌЮФеТжївЊНщЩмСЫSpring
Cloud SleuthЃЌZipkinКЭАИР§ЪЕеНЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
ЮЂЗўЮёМмЙЙЪЧвЛИіЗжВМЪНМмЙЙЃЌЮЂЗўЮёЯЕЭГАДвЕЮёЛЎЗжЗўЮёЕЅдЊЃЌвЛИіЮЂЗўЮёЯЕЭГЭљЭљгаКмЖрИіЗўЮёЕЅдЊЁЃгЩгкЗўЮёЕЅдЊЪ§СПжкЖрЃЌвЕЮёЕФИДдгадНЯИпЃЌ
ШчЙћГіЯжСЫДэЮѓКЭвьГЃЃЌКмФбШЅЖЈЮЛЁЃжївЊЬхЯждквЛИіЧыЧѓПЩФмашвЊЕїгУКмЖрИіЗўЮёЃЌЖјФкВПЗўЮёЕФЕїгУИДдгадОіЖЈСЫЮЪЬтФбвдЖЈЮЛЁЃЫљвддкЮЂЗўЮёМмЙЙжаЃЌБиаыЪЕЯжЗжВМЪНСДТЗзЗзйЃЌШЅИњНјвЛИіЧыЧѓЕНЕзгаФФаЉЗўЮёВЮгыЃЌ
ВЮгыЕФЫГађгжЪЧдѕбљЕФЃЌДгЖјДяЕНУПИіЧыЧѓЕФВНжшЧхЮњПЩМћЃЌГіСЫЮЪЬтФмЙЛПьЫйЖЈЮЛЕФФПЕФЁЃ
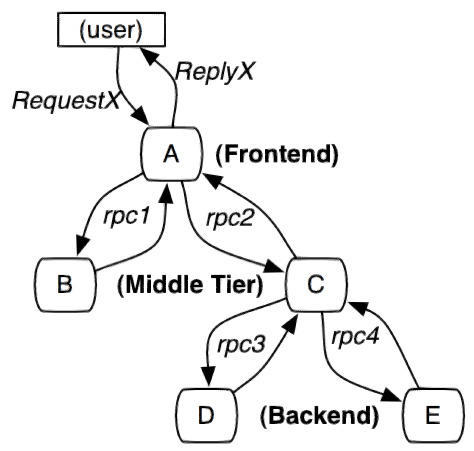
дкЮЂЗўЮёЯЕЭГжаЃЌвЛИіРДздгУЛЇЕФЧыЧѓЯШЕНДяЧАЖЫAЃЈШчЧАЖЫНчУцЃЉЃЌШЛКѓЭЈЙ§дЖГЬЕїгУЃЌЕНДяЯЕЭГЕФжаМфМўBЁЂCЃЈШчИКдиОљКтЁЂЭјЙиЕШЃЉЃЌ
зюКѓЕНДяКѓЖЫЗўЮёDЁЂEЃЌКѓЖЫОЙ§вЛЯЕСаЕФвЕЮёТпММЦЫуЃЌзюКѓНЋЪ§ОнЗЕЛиИјгУЛЇЁЃЖдгкетбљвЛИіЧыЧѓЃЌОРњСЫетУДЖрИіЗўЮёЃЌдѕУДбљНЋЫќЕФЧыЧѓЙ§ГЬгУЪ§ОнМЧТМЯТРДФиЃПетОЭашвЊгУЕНЗўЮёСДТЗзЗзйЁЃ
Spring Cloud Sleuth
Spring Cloud Sleuth ЮЊЗўЮёжЎМфЕїгУЬсЙЉСДТЗзЗзйЁЃЭЈЙ§ Sleuth ПЩвдКмЧхГўЕФСЫНтЕНвЛИіЗўЮёЧыЧѓОЙ§СЫФФаЉЗўЮёЃЌ
УПИіЗўЮёДІРэЛЈЗбСЫЖрГЄЁЃДгЖјШУЮвУЧПЩвдКмЗНБуЕФРэЧхИїЮЂЗўЮёМфЕФЕїгУЙиЯЕЁЃДЫЭт Sleuth ПЩвдАяжњЮвУЧЃК
КФЪБЗжЮі: ЭЈЙ§ Sleuth ПЩвдКмЗНБуЕФСЫНтЕНУПИіВЩбљЧыЧѓЕФКФЪБЃЌДгЖјЗжЮіГіФФаЉЗўЮёЕїгУБШНЯКФЪБ;
ПЩЪгЛЏДэЮѓ: ЖдгкГЬађЮДВЖзНЕФвьГЃЃЌПЩвдЭЈЙ§МЏГЩ Zipkin ЗўЮёНчУцЩЯПДЕН;
СДТЗгХЛЏ: ЖдгкЕїгУБШНЯЦЕЗБЕФЗўЮёЃЌПЩвдеыЖдетаЉЗўЮёЪЕЪЉвЛаЉгХЛЏДыЪЉЁЃ
GoogleПЊдДСЫDapperСДТЗзЗзйзщМўЃЌВЂдк2010ФъЗЂБэСЫТлЮФЁЖDapper, a Large-Scale Distributed
Systems Tracing InfrastructureЁЗЃЌ етЦЊТлЮФЪЧвЕФкЪЕЯжСДТЗзЗзйЕФБъИЫКЭРэТлЛљДЁЃЌОпгаКмИпЕФВЮПММлжЕЁЃ
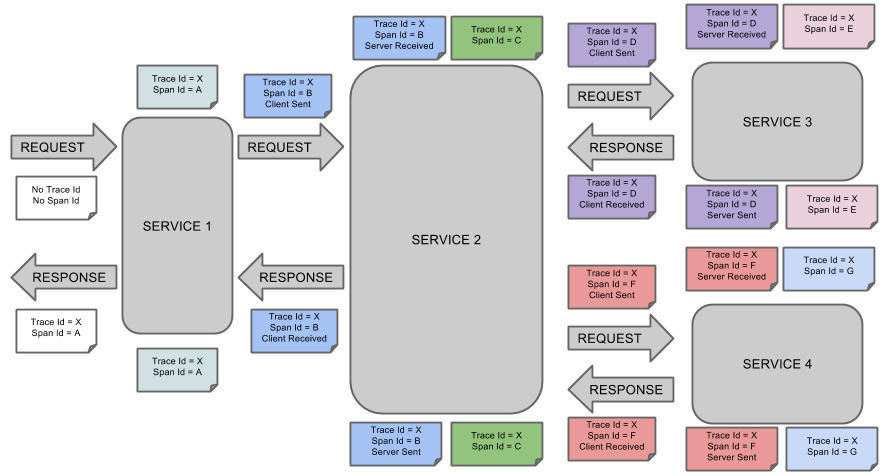
Spring Cloud SleuthВЩгУСЫGoogleЕФПЊдДЯюФПDapperЕФзЈвЕЪѕгяЁЃ
SpanЃКЛљБОЙЄзїЕЅдЊЃЌЗЂЫЭвЛИідЖГЬЕїЖШШЮЮёОЭЛсВњЩњвЛИіSpanЃЌSpanЪЧгУвЛИі64ЮЛIDЮЈвЛБъЪЖЕФЃЌTraceЪЧгУСэвЛИі64ЮЛIDЮЈвЛБъЪЖЕФЁЃ
SpanЛЙАќКЌСЫЦфЫћЕФаХЯЂЃЌР§ШчеЊвЊЁЂЪБМфДСЪТМўЁЂSpanЕФIDвдМАНјГЬIDЁЃ
TraceЃКгЩвЛЯЕСаSpanзщГЩЕФЃЌГЪЪїзДНсЙЙЁЃЧыЧѓвЛИіЮЂЗўЮёЯЕЭГЕФAPIНгПкЃЌетИіAPIНгПкашвЊЕїгУЖрИіЮЂЗўЮёЕЅдЊЃЌ
ЕїгУУПИіЮЂЗўЮёЕЅдЊЖМЛсВњЩњвЛИіаТЕФSpanЃЌЫљгагЩетИіЧыЧѓВњЩњЕФSpanзщГЩСЫетИіTraceЁЃ
AnnotationЃКгУгкМЧТМвЛИіЪТМўЃЌвЛаЉКЫаФзЂНтгУгкЖЈвхвЛИіЧыЧѓЕФПЊЪМКЭНсЪјЃЌетаЉзЂНтШчЯТЁЃ
cs-Client SentЃКПЭЛЇЖЫЗЂЫЭвЛИіЧыЧѓЃЌетИізЂНтУшЪіСЫSpanЕФПЊЪМЁЃ
sr-Server ReceivedЃКЗўЮёЖЫЛёЕУЧыЧѓВЂзМБИПЊЪМДІРэЫќЃЌШчЙћНЋЦфsrМѕШЅcsЪБМфДСЃЌБуПЩЕУЕНЭјТчДЋЪфЕФЪБМфЁЃ
ss-Server SentЃКЗўЮёЖЫЗЂЫЭЯьгІЃЌИУзЂНтБэУїЧыЧѓДІРэЕФЭъГЩЃЈЕБЧыЧѓЗЕЛиПЭЛЇЖЫЃЉЃЌгУssЕФЪБМфДСМѕШЅsrЪБМфДСЃЌ
БуПЩвдЕУЕНЗўЮёЦїЧыЧѓЕФЪБМфЁЃ
cr-Client ReceivedЃКПЭЛЇЖЫНгЪеЯьгІЃЌДЫЪБSpanНсЪјЃЌШчЙћcrЕФЪБМфДСМѕШЅcsЪБМфДСЃЌБуПЩвдЕУЕНећИіЧыЧѓЫљЯћКФЕФЪБМфЁЃ
Spring Cloud Sleuth вВЮЊЮвУЧЬсЙЉСЫвЛЬзЭъећЕФСДТЗНтОіЗНАИ,Spring Cloud Sleuth ПЩвдНсКЯ
ZipkinЃЌНЋаХЯЂЗЂЫЭЕН ZipkinЃЌ РћгУ Zipkin ЕФДцДЂРДДцДЂСДТЗаХЯЂЃЌРћгУ Zipkin
UI РДеЙЪОЪ§ОнЁЃ
Zipkin
ZipkinЪЧвЛжжЗжВМЪНСДТЗзЗзйЯЕЭГЁЃ ЫќгажњгкЪеМЏНтОіЮЂЗўЮёМмЙЙжаЕФбгГйЮЪЬтЫљашЕФЪБађЪ§ОнЁЃ ЫќЙмРэетаЉЪ§ОнЕФЪеМЏКЭВщевЁЃ
ZipkinЕФЩшМЦЛљгкGoogle DapperТлЮФЁЃ
ИњзйЦїДцдкгкгІгУГЬађжаЃЌМЧТМЧыЧѓЕїгУЕФЪБМфКЭдЊЪ§ОнЁЃИњзйЦїЪЙгУПтЃЌЫќУЧЕФЪЙгУЖдгУЛЇЪЧЮоИажЊЕФЁЃР§ШчЃЌ WebЗўЮёЦїЛсдкЪеЕНЧыЧѓЪБКЭЗЂЫЭЯьгІЪБЛсМЧТМЯргІЕФЪБМфКЭвЛаЉдЊЪ§ОнЁЃвЛДЮЭъећСДТЗЧыЧѓЫљЪеМЏЕФЪ§ОнБЛГЦЮЊSpanЁЃ
ЮвУЧПЩвдЪЙгУЫќРДЪеМЏИїИіЗўЮёЦїЩЯЧыЧѓСДТЗЕФИњзйЪ§ОнЃЌВЂЭЈЙ§ЫќЬсЙЉЕФ
REST API НгПкРДИЈжњЮвУЧВщбЏИњзйЪ§ОнвдЪЕЯжЖдЗжВМЪНЯЕЭГЕФМрПиГЬађЃЌ ДгЖјМАЪБЕиЗЂЯжЯЕЭГжаГіЯжЕФбгГйЩ§ИпЮЪЬтВЂевГіЯЕЭГадФмЦПОБЕФИљдДЁЃГ§СЫУцЯђПЊЗЂЕФ
API НгПкжЎЭтЃЌЫќвВЬсЙЉСЫЗНБуЕФ UI зщМўРДАяжњЮвУЧжБЙлЕФЫбЫїИњзйаХЯЂКЭЗжЮіЧыЧѓСДТЗУїЯИЃЌ БШШчЃКПЩвдВщбЏФГЖЮЪБМфФкИїгУЛЇЧыЧѓЕФДІРэЪБМфЕШЁЃ
Zipkin ЬсЙЉСЫПЩВхАЮЪ§ОнДцДЂЗНЪНЃКIn-MemoryЁЂMySqlЁЂCassandra вдМА ElasticsearchЁЃНгЯТРДЕФВтЪдЮЊЗНБужБНгВЩгУ
In-Memory ЗНЪННјааДцДЂЃЌЩњВњЭЦМі Elasticsearch.

ЩЯЭМеЙЪОСЫ Zipkin ЕФЛљДЁМмЙЙЃЌЫќжївЊгЩ 4 ИіКЫаФзщМўЙЙГЩЃК
CollectorЃКЪеМЏЦїзщМўЃЌЫќжївЊгУгкДІРэДгЭтВПЯЕЭГЗЂЫЭЙ§РДЕФИњзйаХЯЂЃЌ НЋетаЉаХЯЂзЊЛЛЮЊ Zipkin ФкВПДІРэЕФ
Span ИёЪНЃЌвджЇГжКѓајЕФДцДЂЁЂЗжЮіЁЂеЙЪОЕШЙІФмЁЃ
StorageЃКДцДЂзщМўЃЌЫќжївЊЖдДІРэЪеМЏЦїНгЪеЕНЕФИњзйаХЯЂЃЌФЌШЯЛсНЋетаЉаХЯЂДцДЂдкФкДцжаЃЌ ЮвУЧвВПЩвдаоИФДЫДцДЂВпТдЃЌЭЈЙ§ЪЙгУЦфЫћДцДЂзщМўНЋИњзйаХЯЂДцДЂЕНЪ§ОнПтжаЁЃ
RESTful APIЃКAPI зщМўЃЌЫќжївЊгУРДЬсЙЉЭтВПЗУЮЪНгПкЁЃБШШчИјПЭЛЇЖЫеЙЪОИњзйаХЯЂЃЌ ЛђЪЧЭтНгЯЕЭГЗУЮЪвдЪЕЯжМрПиЕШЁЃ
Web UIЃКUI зщМўЃЌЛљгк API зщМўЪЕЯжЕФЩЯВугІгУЁЃЭЈЙ§ UI зщМўгУЛЇПЩвдЗНБуЖјгажБЙлЕиВщбЏКЭЗжЮіИњзйаХЯЂЁЃ
АИР§ЪЕеН
дкБОАИР§вЛЙВгаШ§ИігІгУЃЌЗжБ№ЮЊзЂВсжааФЃЌeureka-serverЁЂeureka-clientЁЂeureka-client-feignЃЌ Ш§ИігІгУЕФЛљБОаХЯЂШчЯТЃК
| гІгУУћ |
ЖЫПк |
зїгУ |
|
eureka-server |
8761 |
зЂВсжааФ |
|
eureka-client |
8763 |
ЗўЮёЬсЙЉеп |
|
eureka-client-feign |
8765 |
ЗўЮёЯћЗбеп |
Цфжаeureka-server гІгУЮЊзЂВсжааФЃЌЦфЫћСНИігІгУЯђЫќзЂВсЁЃeureka-clientЮЊЗўЮёЬсЙЉепЃЌЬсЙЉСЫвЛИіRESTAPI,eureka-client-feignЮЊЗўЮёЯћЗбепЃЌ
ЭЈЙ§Feign ClientЯђЗўЮёЬсЙЉепЯћЗбЗўЮёЁЃ дкжЎЧАЕФЮФеТвбОНВЪіСЫШчКЮШчКЮДюНЈЗўЮёзЂВсжааФЃЌдкетРяОЭЪЁТдетвЛВПЗжФкШнЁЃЗўЮёЬсЙЉепЬсЙЉвЛИіRESTНгПкЃЌЗўЮёЯћЗбепЭЈЙ§FeignClientЯћЗбЗўЮёЁЃ
ЗўЮёЬсЙЉеп eureka-clientЗўЮёЬсЙЉепЃЌЖдЭтЬсЙЉвЛИіRESTAPIЃЌВЂЯђЗўЮёзЂВсжааФзЂВсЃЌетВПЗжФкШнЃЌВЛдйНВЪіЃЌМћдДТыЁЃашвЊдкЙЄГЬЕФpomЮФМўМгЩЯsleuthЕФЦ№ВНвРРЕКЭzipkinЕФЦ№ВНвРРЕЃЌДњТыШчЯТЃК
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency> |
дкЙЄГЬЕФХфжУЮФМўapplication.ymlашвЊзівдЯТЕФХфжУЃК
spring:
sleuth:
web:
client:
enabled: true
sampler:
probability: 1.0 # НЋВЩбљБШР§ЩшжУЮЊ 1.0ЃЌвВОЭЪЧШЋВПЖМашвЊЁЃФЌШЯЪЧ 0.1
zipkin:
base-url: http://localhost:9411/ # жИЖЈСЫ Zipkin
ЗўЮёЦїЕФЕижЗ |
Цфжаspring.sleuth.web.client.enableЮЊtrueЩшжУЕФЪЧwebПЊЦєsleuthЙІФм;spring.sleuth.sampler.probabilityПЩвдЩшжУЮЊаЁЪ§ЃЌ
зюДѓжЕЮЊ1.0ЃЌЕБЩшжУЮЊ1.0ЪБОЭЪЧСДТЗЪ§Он100%ЪеМЏЕНzipkin-serverЃЌЕБЩшжУЮЊ0.1ЪБЃЌМД10%ИХТЪЪеМЏСДТЗЪ§Он;spring.zipkin.base-urlЩшжУzipkin-serverЕФЕижЗЁЃ
ЖдЭтЬсЙЉвЛИіApiЃЌДњТыШчЯТЃК
@RestController
public class HiController {
@Value("${server.port}")
String port;
@GetMapping("/hi")
public String home(@RequestParam String name)
{
return "hi "+name+",i am from
port:" +port;
}
} |
ЗўЮёЯћЗбеп
ЗўЮёЯћЗбепЭЈЙ§FeignClientЯћЗбЗўЮёЬсЙЉепЬсЙЉЕФЗўЮёЁЃЭЌЗўЮёЬсЙЉепвЛбљЃЌашвЊдкЙЄГЬЕФpomЮФМўМгЩЯsleuthЕФЦ№ВНвРРЕКЭzipkinЕФЦ№ВНвРРЕЃЌ
СэЭтвВашвЊдкХфжУЮФМўapplication.ymlзіЯрЙиЕФХфжУЃЌОпЬхЭЌЗўЮёЬсЙЉепЁЃ
ЗўЮёЯћЗбепЭЈЙ§feignClientНјааЗўЮёЯћЗбЃЌfeignclientДњТыШчЯТЃК
@FeignClient(value
= "eureka-client",configuration = FeignConfig.class)
public interface EurekaClientFeign {
@GetMapping(value = "/hi")
String sayHiFromClientEureka(@RequestParam(value
= "name") String name);
}
|
servcieВуДњТыШчЯТЃК
@Service
public class HiService {
@Autowired
EurekaClientFeign eurekaClientFeign;
public String sayHi(String name){
return eurekaClientFeign.sayHiFromClientEureka(name);
}
} |
controllerДњТыШчЯТЃК
@RestController
public class HiController {
@Autowired
HiService hiService;
@GetMapping("/hi")
public String sayHi(@RequestParam( defaultValue
= "forezp",required = false)String
name){
return hiService.sayHi(name);
} |
ЩЯУцЕФДњТыЖдЭтБЉТЖвЛИіAPIЃЌЭЈЙ§FeignClientЕФЗНЪНЕїгУeureka-clientЕФЗўЮёЁЃ
zipkin-server
дкSpring Cloud DАцБОЃЌzipkin-serverЭЈЙ§в§ШывРРЕЕФЗНЪНЙЙНЈЙЄГЬЃЌздДгEАцБОжЎКѓЃЌетвЛЗНЪНИФБфСЫЃЌВЩгУЙйЗНЕФjarаЮЪНЦєЖЏЃЌ
ЫљвдашвЊЭЈЙ§ЯТдиЙйЗНЕФjarРДЦєЖЏЃЌвВЭЈЙ§вдЯТУќСювЛМќЦєЖЏЃК
curl -sSL https://zipkin.io/quickstart.sh
| bash -s
java -jar zipkin.jar |
ЩЯУцЕФЕквЛааУќСюЛсДгzipkinЙйЭјЯТдиЙйЗНЕФjarАќЁЃ ШчЙћЪЧwindowЯЕЭГЃЌНЈвщЪЙгУgitbashжДааЩЯУцЕФУќСюЁЃ ШчЙћгУ Docker ЕФЛАЃЌЪЙгУвдЯТУќСюЃК
| docker run -d
-p 9411:9411 openzipkin/zipkin |
ЭЈЙ§java -jar zipkin.jarЕФЗНЪНЦєЖЏжЎКѓЃЌдкфЏРРЦїЩЯЗУЮЪlcoalhost:9411ЃЌЯдЪОЕФНчУцШчЯТЃК
СДТЗЪ§ОнбщжЄ
вРДЮЦєЖЏeureka-serverЃЌeureka-client,eureka-client-feignЕФШ§ИігІгУЃЌЕШЫљгагІгУЦєЖЏЭъГЩКѓЃЌдкфЏРРЦїЩЯЗУЮЪhttp://localhost:8765/hi
ЃЈШчЙћБЈДэЃЌЪЧЗўЮёгыЗЂЯжашвЊвЛЖЈЕФЪБМфЃЌФЭаФЕШД§МИЪЎУыЃЉЃЌЗУЮЪГЩЙІКѓЃЌдйДЮдкфЏРРЦїЩЯЗУЮЪzipkin-serverЕФвГУцЃЌЯдЪОШчЯТЃК
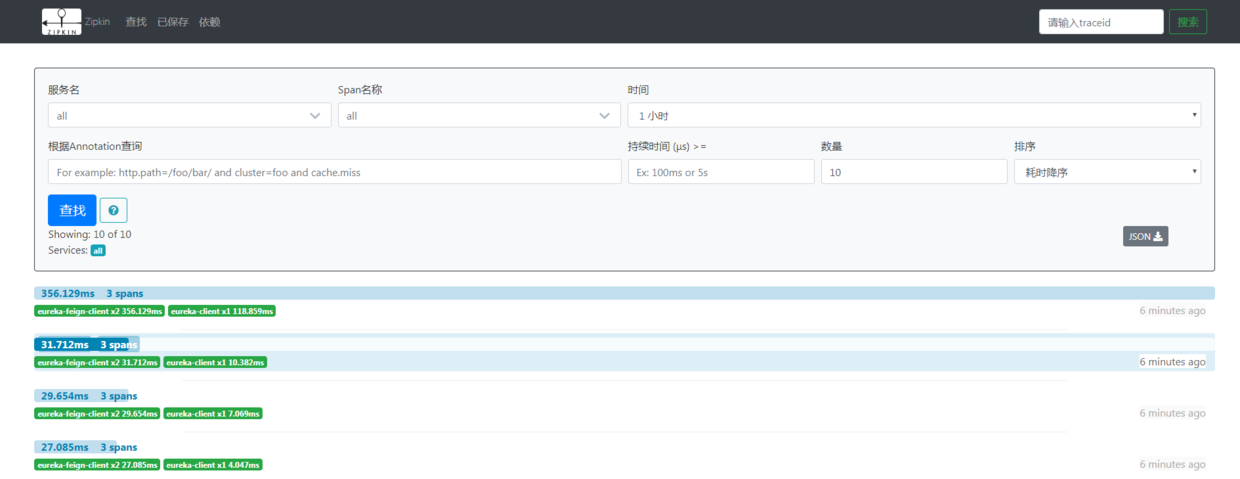
ДгЩЯЭМПЩвдПДГіУПДЮЧыЧѓЫљЯћКФЕФЪБМфЃЌвдМАвЛаЉspanЕФаХЯЂЁЃ

ДгЩЯЭМПЩвдПДГіОпЬхЕФЗўЮёвРРЕЙиЯЕЃЌeureka-feign-clientвРРЕСЫeureka-clientЁЃ
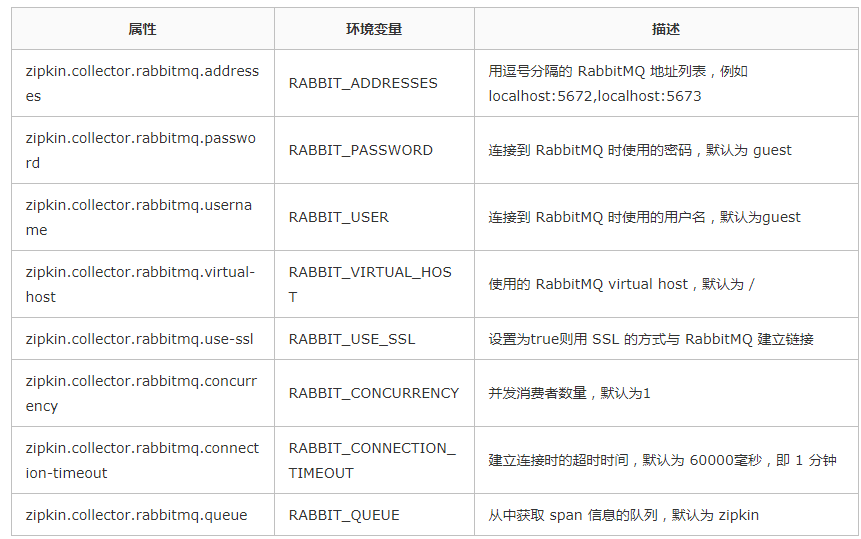
ЪЙгУrabbitmqНјааСДТЗЪ§ОнЪеМЏ
дкЩЯУцЕФАИР§жаЪЙгУЕФhttpЧыЧѓЕФЗНЪННЋСДТЗЪ§ОнЗЂЫЭИјzipkin-serverЃЌЦфЪЕЛЙПЩвдЪЙгУrabbitmqЕФЗНЪННјааЗўЮёЕФЯћЗбЁЃ
ЪЙгУrabbitmqашвЊАВзАrabbitmqГЬађЃЌЯТдиЕижЗhttp://www.rabbitmq.com/ЁЃ
ЯТдиЭъГЩКѓЃЌашвЊeureka-clientКЭeureka-client-feignЕФЦ№ВНвРРЕМгЩЯrabbitmqЕФвРРЕЃЌвРРЕШчЯТЃК
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency> |
дкХфжУЮФМўЩЯашвЊХфжУrabbitmqЕФХфжУЃЌХфжУаХЯЂШчЯТЃК
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672 |
СэЭташвЊАбspring.zipkin.base-urlШЅЕєЁЃ
дкЩЯУц2ИіЙЄГЬжаЃЌrabbitmqЭЈЙ§ЗЂЫЭСДТЗЪ§ОнЃЌФЧУДzipkin-serverЪЧдѕУДбљжЊЕРrabbitmqЕФЕижЗФиЃЌдѕУДМрЬ§ЪеЕНЕФСДТЗЪ§ОнФиЃП
еташвЊдкГЬађЦєЖЏЕФЪБКђЃЌЭЈЙ§ЛЗОГБфСПЕФаЮЪНЕНЛЗОГжаЃЌШЛКѓzikin-serverДгЛЗОГБфСПжаЖСШЁЁЃ
ПЩХфжУЕФЪєадШчЯТЃК
БШШчЃЌЭЈЙ§вдЯТУќСюЦєЖЏЃК
| RABBIT_ADDRESSES=localhost
java -jar zipkin.jar |
ЩЯУцЕФУќСюЕШЭЌгквЛЯТЕФУќСюЃК
| java -jar zipkin.jar
--zipkin.collector.rabbitmq.addressed=localhost |
гУЩЯУцЕФ2ЬѕУќСюжаЕФШЮКЮвЛжжЗНЪНжиаТЦєЖЏzipkin-serverГЬађЃЌВЂжиаТЦєЖЏeureka-clientЁЂeureka-serverЁЂeureka-client-feignЃЌ
ЖЏЭъГЩКѓдкфЏРРЦїЩЯЗУЮЪhttp://localhost:8765/hiЃЌдйЗУЮЪhttp://localhost:9411/zipkin/ЃЌОЭПЩвдПДЕНЭЈЙ§HttpЗНЪНЗЂЫЭСДТЗЪ§ОнвЛбљЕФНгПкЁЃ
здЖЈвхTag
дквГУцЩЯПЩвдВщПДУПИіЧыЧѓЕФtraceIdЃЌУПИіtraceгжАќКЌШєИЩЕФspanЃЌУПИіspanгжАќКЌСЫКмЖрЕФtagЃЌздЖЈвхtagПЩвдЭЈЙ§TracerетИіРрРДздЖЈвхЁЃ
@Autowired
Tracer tracer;
@GetMapping("/hi")
public String home(@RequestParam String name)
{
tracer.currentSpan().tag("name","forezp");
return "hi "+name+",i am from
port:" +port;
} |
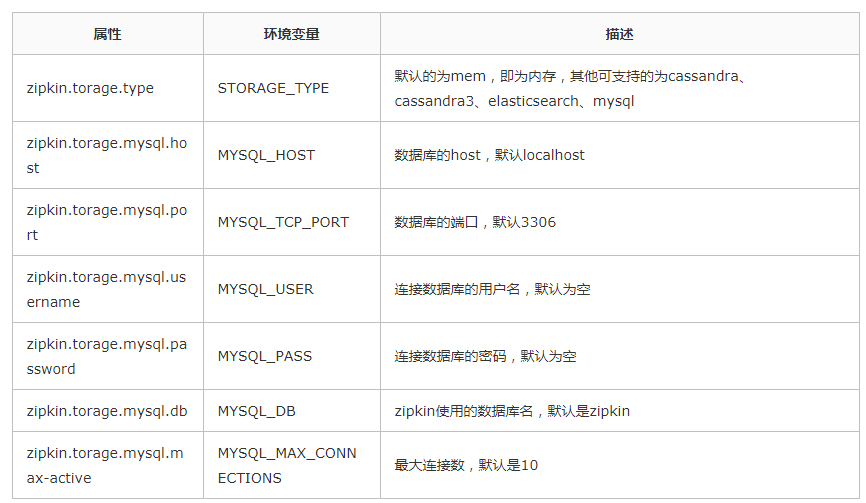
НЋСДТЗЪ§ОнДцДЂдкMysqlЪ§ОнПтжа
ЩЯУцЕФР§згЪЧНЋСДТЗЪ§ОнДцдкФкДцжаЃЌжЛвЊzipkin-serverжиЦєжЎКѓЃЌжЎЧАЕФСДТЗЪ§ОнШЋВПВщевВЛЕНСЫЃЌzipkinЪЧжЇГжНЋСДТЗЪ§ОнДцДЂдкmysqlЁЂcassandraЁЂelasticsearchжаЕФЁЃ
ЯждкНВНтШчКЮНЋСДТЗЪ§ОнДцДЂдкMysqlЪ§ОнПтжаЁЃ
ЪзЯШашвЊГѕЪМЛЏzikinДцДЂдкMysqlЕФЪ§ОнЕФschemeЃЌПЩвддкетРяВщПД https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sqlЃЌОпЬхШчЯТЃК
CREATE TABLE
IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT
'If non zero, this means the trace uses 128 bit
traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch
micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros
used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER
SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`,
`trace_id`, `id`) COMMENT 'ignore insert on
duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`,
`trace_id`, `id`) COMMENT 'for joining with
zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`,
`trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT
'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`)
COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations
(
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT
'If non zero, this means the trace uses 128
bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides
with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides
with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key
or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(),
which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type()
or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement
TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint
is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when
Binary/Annotation.endpoint is null, or no IPv6
address',
`endpoint_port` SMALLINT COMMENT 'Null when
Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT
'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER
SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`,
`trace_id`, `span_id`, `a_key`, `a_timestamp`)
COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`,
`trace_id`, `span_id`) COMMENT 'for joining
with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`,
`trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`)
COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`)
COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`)
COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`,
`span_id`, `a_key`) COMMENT 'for dependencies
job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies
(
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER
SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE
KEY(`day`, `parent`, `child`); |
дкЪ§ОнПтжаГѕЪМЛЏЩЯУцЕФНХБОжЎКѓЃЌашвЊзіЕФОЭЪЧzipkin-serverШчКЮСЌНгЪ§ОнПтЁЃzipkinШчКЮСЌЪ§ОнПтЭЌСЌНгrabbitmqвЛбљЁЃ
zipkinСЌНгЪ§ОнПтЕФЪєадЫљЖдгІЕФЛЗОГБфСПШчЯТЃК
-
| STORAGE_TYPE=mysql
MYSQL_HOST=localhost MYSQL_TCP_PORT=3306 MYSQL_USER=root
MYSQL_PASS=123456 MYSQL_DB=zipkin java -jar zipkin.jar |
ЕШЭЌгквдЯТЕФУќСю
| java -jar zipkin.jar
--zipkin.torage.type=mysql --zipkin.torage.mysql.
host=localhost --zipkin.torage.mysql.port=3306
--zipkin.torage.mysql.username=root --zipkin.torage.mysql.password=123456 |
ЪЙгУЩЯУцЕФУќСюЦєЖЏzipkin.jarЙЄГЬЃЌШЛКѓдйфЏРРЪ§ЩЯЗУЮЪhttp://localhost:8765/hiЃЌдйЗУЮЪhttp://localhost:9411/zipkin/ЃЌПЩвдПДЕНСДТЗЪ§ОнЁЃетЪБШЅЪ§ОнПтВщПДЪ§ОнЃЌвВЪЧПЩвдПДЕНДцДЂдкЪ§ОнПтЕФСДТЗЪ§ОнЃЌШчЯТЃК
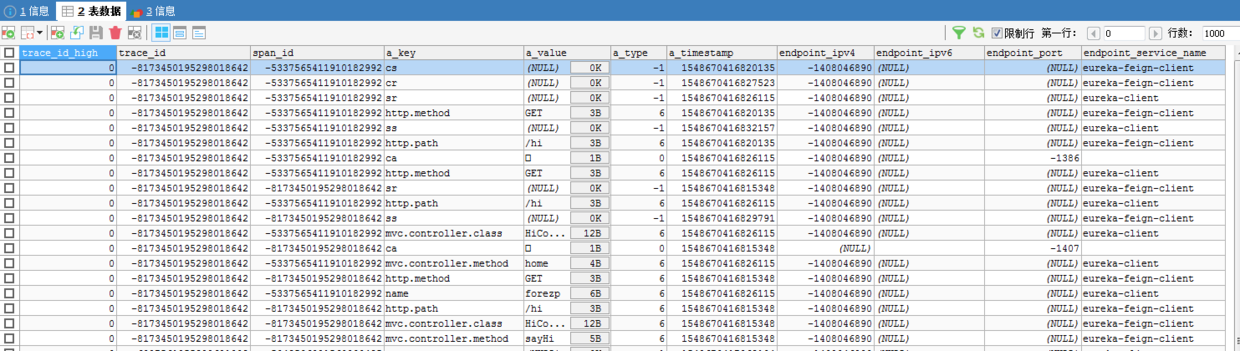
етЪБжиЦєгІгУzipkin.jarЃЌдйДЮдкфЏРРЦїЩЯЗУЮЪhttp://localhost:9411/zipkin/ЃЌШдШЛПЩвдЕУЕНжЎЧАЕФНсЙћЃЌжЄУїСДТЗЪ§ОнДцДЂдкЪ§ОнПтжаЃЌЖјВЛЪЧФкДцжаЁЃ
НЋСДТЗЪ§ОнДцдкдкElasticsearchжа
zipkin-serverжЇГжНЋСДТЗЪ§ОнДцДЂдкElasticSearchжаЁЃЖСепашвЊздааАВзАElasticSearchКЭKibanaЃЌЯТдиЕижЗЮЊ
https://www. elastic.co/products/elasticsearchЁЃАВзАЭъГЩКѓЦєЖЏЃЌЦфжаElasticSearchЕФФЌШЯЖЫПкКХЮЊ9200ЃЌKibanaЕФФЌШЯЖЫПкКХЮЊ5601ЁЃ
ЭЌРэЃЌzipkinСЌНгelasticsearchвВЪЧДгЛЗОГБфСПжаЖСШЁЕФЃЌelasticsearchЯрЙиЕФЛЗОГБфСПКЭЖдгІЕФЪєадШчЯТЃК
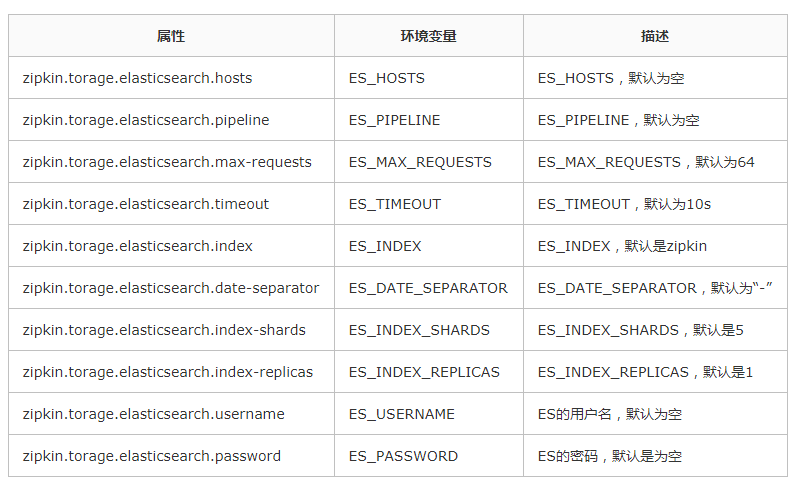
ВЩгУвдЯТУќСюЦєЖЏzipkin-server:
| STORAGE_TYPE=elasticsearch
ES_HOSTS=http://localhost:9200 ES_INDEX=zipkin
java -jar zipkin.jar |
| java -jar zipkin.jar
--STORAGE_TYPE=elasticsearch --ES_HOSTS= http://localhost:9200
--ES_INDEX=zipkin |
| java -jar zipkin.jar
--STORAGE_TYPE=elasticsearch --ES_HOSTS= http://localhost:9200
--ES_INDEX=zipkin |
| java -jar zipkin.jar
--zipkin.torage.type=elasticsearch --zipkin.torage.elasticsearch.hosts=http://localhost:9200
--zipkin.torage.elasticsearch.index=zipkin |
ЦєЖЏЭъГЩКѓЃЌШЛКѓдкфЏРРЪ§ЩЯЗУЮЪhttp://localhost:8765/hiЃЌдйЗУЮЪhttp://localhost:9411/zipkin/ЃЌПЩвдПДЕНСДТЗЪ§ОнЁЃетЪБСДТЗЪ§ОнДцДЂдкElasticSearchЁЃ
дкzipkinЩЯеЙЪОСДТЗЪ§Он
СДТЗЪ§ОнДцДЂдкElasticSearchжаЃЌElasticSearchПЩвдКЭKibanaНсКЯЃЌНЋСДТЗЪ§ОнеЙЪОдкKibanaЩЯЁЃАВзАЭъГЩKibanaКѓЦєЖЏЃЌKibanaФЌШЯЛсЯђБОЕиЖЫПкЮЊ9200ЕФElasticSearchЖСШЁЪ§ОнЁЃKibanaФЌШЯЕФЖЫПкЮЊ5601ЃЌЗУЮЪKibanaЕФжївГhttp://localhost:5601ЃЌЦфНчУцШчЯТЭМЫљЪОЁЃ
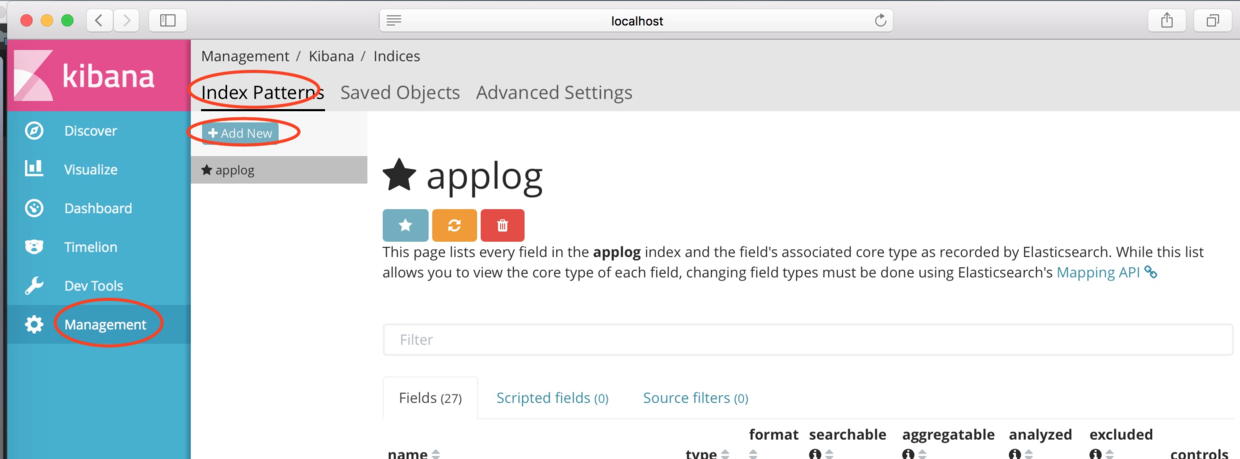
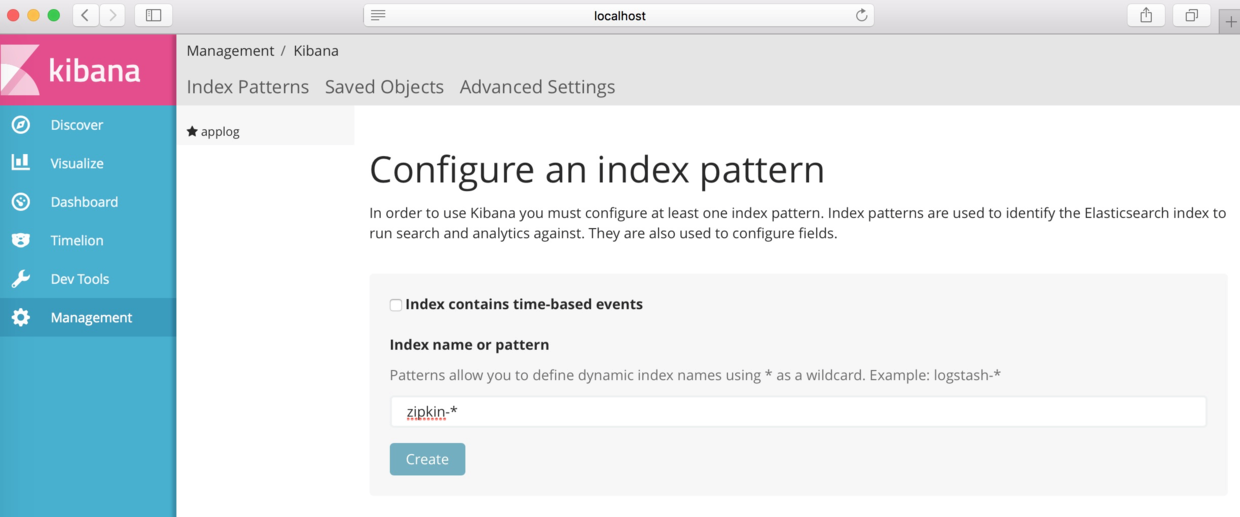
дкЩЯЭМЕФНчУцжаЃЌЕЅЛїЁАManagementЁБАДХЅЃЌШЛКѓЕЅЛїЁАAdd NewЁБЃЌЬэМгвЛИіindexЁЃЮвУЧНЋдкЩЯНкElasticSearchжааДШыСДТЗЪ§ОнЕФindexХфжУЮЊЁАzipkinЁБЃЌФЧУДдкНчУцЬюаДЮЊЁАzipkin-*ЁБЃЌЕЅЛїЁАCreateЁБАДХЅЃЌНчУцШчЯТЭМЫљЪОЃК
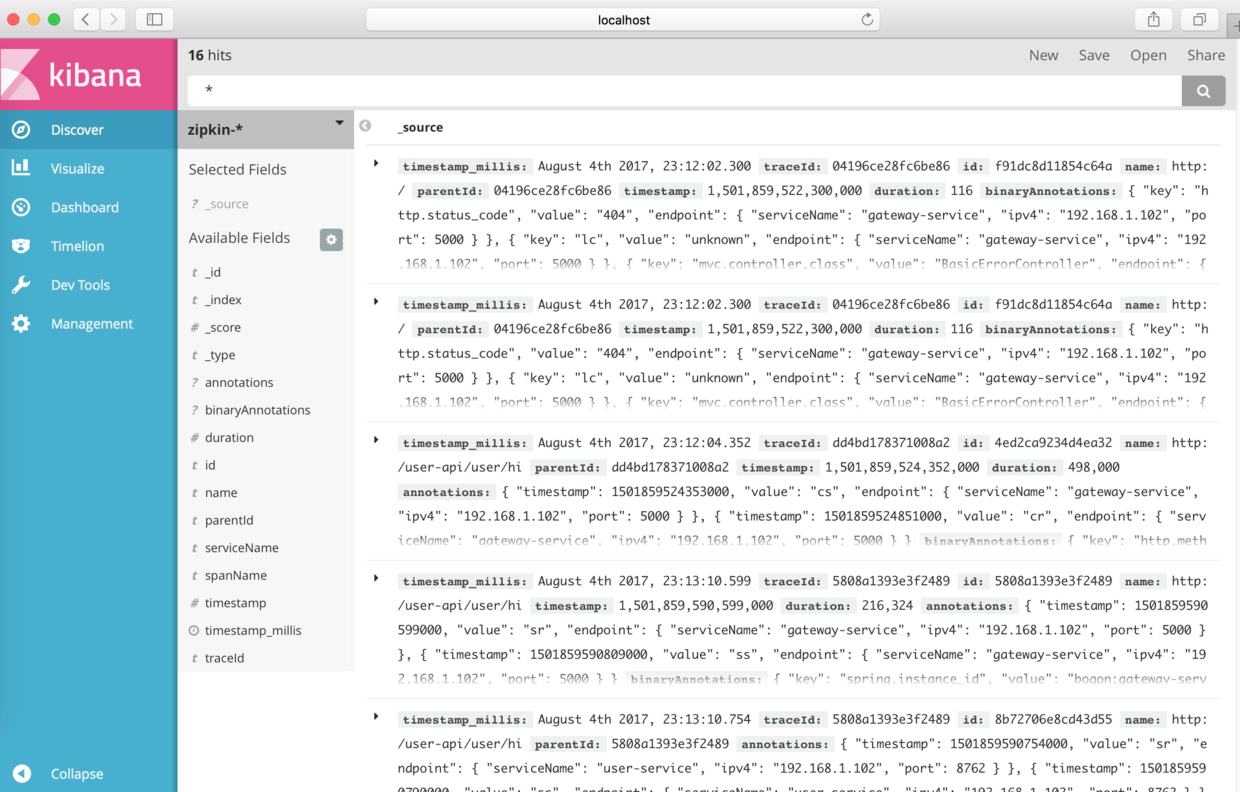
ДДНЈЭъГЩindexКѓЃЌЕЅЛїЁАDiscoverЁБЃЌОЭПЩвддкНчУцЩЯеЙЪОСДТЗЪ§ОнСЫЃЌеЙЪОНчУцШчЯТЭМЫљЪОЁЃ
|









