| БрМЭЦМі: |
| БОЮФРДздгкМђЪщЃЌЮФеТЪзЯШНщЩмСЫIstioЪЧЪВУДЃЌдйНщЩмЮЊЪВУДвЊЪЙгУIstioЃЌвдМАIstioФмзіЪВУД?ећЬхМмЙЙгжЪЧЪВУДбљЕФЃЌЮДРДЕФвЛаЉеЙЭћЁЃ |
|
service MeshаТауЃЌГѕГіУЉТЎБуЩљЪЦКЦЕДЃЌЧАгаGoogleЃЌIBMКЭLyftЧуЧщЗюЯзЃЌКѓгавЕНчДѓРаИЉЪзФЄАнЃЌетОЭЪЧНёЬьНЋвЊНщЩмЕФжїНЧЃЌПИЦ№Service
MeshДѓЦьЃЌЯЦЦ№аТвЛТжЮЂЗўЮёПЊЗЂРЫГБЕФIstioЃЁ
НёЬьЕФжїНЧУћНа IstioЃЌЙРМЦКмЖрЭЌбЇдкДЫжЎЧАПЩФмЭъШЋУЛгаЬ§Й§етИіУћзжЁЃЧыВЛБиНщвтЃЌУЛЬ§Й§Кме§ГЃЃЌвђЮЊIstioЕФШЗЪЧвЛИіЗЧГЃаТЕФЖЋЮїЃЌГіЪРвВВХЫФИідТЖјвбЁЃ
НёЬьЕФФкШнНЋЛсЗжГЩШ§ИіВПЗж:
НщЩмЃК ШУДѓМвСЫНтIstioЪЧЪВУДЃЌвдМАгаЪВУДКУДІЃЌвдМАIstioБГКѓЕФПЊЗЂЭХЖг
МмЙЙЃК НщЩмIstioЕФећЬхМмЙЙКЭЫФИіжївЊЙІФмФЃПщЕФОпЬхЙІФмЃЌетПщФкШнЛсБШНЯЦЋММЪѕ
еЙЭћЃК НщЩмIstioЕФКѓајПЊЗЂМЦЛЎЃЌЬНЬжЮДРДЕФЗЂеЙдЄЦк
вЛЁЂНщЩм
IstioЪЧЪВУДЃКIstioЪЧGoogle/IBM/LyftСЊКЯПЊЗЂЕФПЊдДЯюФПЃЌ2017Фъ5дТЗЂВМЕквЛИіrelease
0.1.0ЃЌ ЙйЗНЖЈвхЮЊ:
IstioЃКвЛИіСЌНгЃЌЙмРэКЭБЃЛЄЮЂЗўЮёЕФПЊЗХЦНЬЈЁЃ
АДееisitoЮФЕЕжаИјГіЕФЖЈвх:
IstioЬсЙЉвЛжжМђЕЅЕФЗНЪНРДНЈСЂвбВПЪ№ЕФЗўЮёЕФЭјТчЃЌОпБИИКдиОљКтЃЌЗўЮёЕНЗўЮёШЯжЄЃЌМрПиЕШЕШЙІФмЃЌЖјВЛашвЊИФЖЏШЮКЮЗўЮёДњТыЁЃ
МђЕЅЕФЫЕЃЌгаСЫIstioЃЌФуЕФЗўЮёОЭВЛдйашвЊШЮКЮЮЂЗўЮёПЊЗЂПђМмЃЈЕфаЭШчSpring CloudЃЌDubboЃЉЃЌвВВЛдйашвЊздМКЖЏЪжЪЕЯжИїжжИДдгЕФЗўЮёжЮРэЕФЙІФмЃЈКмЖрЪЧSpring
CloudКЭDubboвВВЛФмЬсЙЉЕФЃЌашвЊздМКЖЏЪжЃЉЁЃжЛвЊЗўЮёЕФПЭЛЇЖЫКЭЗўЮёЦїПЩвдНјааМђЕЅЕФжБНгЭјТчЗУЮЪЃЌОЭПЩвдЭЈЙ§НЋЭјТчВуЮЏЭаИјIstioЃЌДгЖјЛёЕУвЛЯЕСаЕФЭъБИЙІФмЁЃ
ПЩвдНќЫЦЕФРэНтЮЊЃКIstio = ЮЂЗўЮёПђМм + ЗўЮёжЮРэ
УћзжКЭЭМБъЃК
IstioРДздЯЃРАгяЃЌгЂЮФвтЫМЪЧЁБSailЁБЃЌ ЗвыЮЊжаЮФЪЧЁАЦєКНЁБЁЃЫќЕФЭМБъШчЯТ:

ПЩвдРрБШGoogleЕФСэЭтвЛИіЯрЙиВњЦЗЃКKubernetesЃЌУћзжвВЪЧЭЌбљЦ№дДгкЙХЯЃРАЃЌЪЧДЌГЄЛђепМнЪЛдБЕФвтЫМЁЃЯТЭМЪЧKubernetesЕФЭМБъЃК

КѓУцЛсПДЕНЃЌIstioКЭKubernetesЕФЙиЯЕЃЌОЭЯёЫќУЧЕФУћзжКЭЭМБъвЛбљЃЌ ПЩЮНЁБвЛТіЯрДЋЁБЁЃ
жївЊЬиадЃК
IstioЕФЙиМќЙІФм:
HTTP/1.1ЃЌHTTP/2ЃЌgRPCКЭTCPСїСПЕФздЖЏЧјгђИажЊИКдиЦНКтКЭЙЪеЯЧаЛЛЁЃ
ЭЈЙ§ЗсИЛЕФТЗгЩЙцдђЃЌШнДэКЭЙЪеЯзЂШыЃЌЖдСїааЮЊЕФЯИСЃЖШПижЦЁЃ
жЇГжЗУЮЪПижЦЃЌЫйТЪЯожЦКЭХфЖюЕФПЩВхАЮВпТдВуКЭХфжУAPIЁЃ
МЏШКФкЫљгаСїСПЕФздЖЏСПЖШЃЌШежОКЭИњзйЃЌАќРЈМЏШКШыПкКЭГіПкЁЃ
АВШЋЕФЗўЮёЕНЗўЮёЩэЗнбщжЄЃЌдкМЏШКжаЕФЗўЮёжЎМфОпгаЧПДѓЕФЩэЗнБъЪЖЁЃ
етаЉЬиаддкЩдКѓЕФМмЙЙеТНкЪБЛсгаНщЩмЁЃ
ЮЊЪВУДвЊЪЙгУIstio
дкЩюШыIstioЯИНкжЎЧАЃЌЯШРДПДПДЃЌЮЊЪВУДвЊЪЙгУIstioЃПЫќПЩвдАяЮвУЧНтОіЪВУДЮЪЬт?
ЮЂЗўЮёЕФСНУцад
зюНќСНШ§ФъРДЮЂЗўЮёЗНаЫЮДАЌЃЌ ПЩвдПДЕНдНРДдНЖрЕФЙЋЫОКЭПЊЗЂШЫдБТНТНајајЭЖЩэЕНЮЂЗўЮёМмЙЙЃЌ ШУвЛИівЛИіЕФЮЂЗўЮёЯюФПТфЕиЁЃ
ЕЋЪЧЃЌдкетвЛЦЌНаКУЕФањФжжаЃЌ ЮвУЧЛЙЪЧЗЂОѕвЛаЉЦеБщДцдкЕФЮЪЬтЃКЫфШЛЮЂЗўЮёЖдПЊЗЂНјааСЫМђЛЏЃЌЭЈЙ§НЋИДдгЯЕЭГЧаЗжЮЊШєИЩИіЮЂЗўЮёРДЗжНтКЭНЕЕЭИДдгЖШЃЌЪЙЕУетаЉЮЂЗўЮёвзгкБЛаЁаЭЕФПЊЗЂЭХЖгЫљРэНтКЭЮЌЛЄЁЃЕЋЪЧЃЌИДдгЖШВЂЗЧДгДЫЯћЪЇЁЃЮЂЗўЮёВ№ЗжжЎКѓЃЌЕЅИіЮЂЗўЮёЕФИДдгЖШДѓЗљНЕЕЭЃЌЕЋЪЧгЩгкЯЕЭГБЛДгвЛИіЕЅЬхВ№ЗжЮЊМИЪЎЩѕжСИќЖрЕФЮЂЗўЮёЃЌ
ОЭДјРДСЫСэЭтвЛИіИДдгЖШЃКЮЂЗўЮёЕФСЌНгЁЂЙмРэКЭМрПиЁЃ

ЪдЯыЃЌ ЖдгквЛИіДѓаЭЯЕЭГЃЌ ашвЊЖдЖрДяЩЯАйИіЩѕжСЩЯЧЇИіЮЂЗўЮёЕФЙмРэЁЂВПЪ№ЁЂАцБОПижЦЁЂАВШЋЁЂЙЪеЯзЊвЦЁЂВпТджДааЁЂвЃВтКЭМрПиЕШЃЌЬИКЮШнвзЁЃИќВЛвЊЫЕИќИДдгЕФдЫЮЌашЧѓЃЌР§ШчA/BВтЪдЃЌН№ЫПШИЗЂВМЃЌЯоСїЃЌЗУЮЪПижЦКЭЖЫЕНЖЫШЯжЄЁЃ
ПЊЗЂШЫдБКЭдЫЮЌШЫдБдкЕЅЬхгІгУГЬађЯђЗжВМЪНЮЂЗўЮёМмЙЙЕФзЊаЭжаЃЌ ВЛЕУВЛУцСйЩЯЪіЬєеНЁЃ
ЗўЮёЭјИё
Service MeshЃЌЗўЮёЭјИёЃЌвВгаШЫЗвыЮЊЁБЗўЮёФіКЯВуЁБЁЃетУВЫЦЪЧНёФъВХГіРДЕФаТУћДЪЃПдк2017ФъжЎЧАУЛгаЬ§Й§ЃЌЫфШЛРрЫЦЕФВњЦЗвбОДцдкЭІГЄЪБМфЁЃ
ЪВУДЪЧService MeshЃЈЗўЮёЭјИёЃЉЃП
Service MeshЪЧзЈгУЕФЛљДЁЩшЪЉВуЃЌЧсСПМЖИпадФмЭјТчДњРэЁЃЬсЙЉАВШЋЕФЁЂПьЫйЕФЁЂПЩППЕиЗўЮёМфЭЈбЖЃЌгыЪЕМЪгІгУВПЪ№вЛЦ№ЃЌЕЋЖдгІгУЭИУїЁЃ
ЮЊСЫАяжњРэНтЃЌ ЯТЭМеЙЪОСЫЗўЮёЭјИёЕФЕфаЭБпГЕВПЪ№ЗНЪНЃК
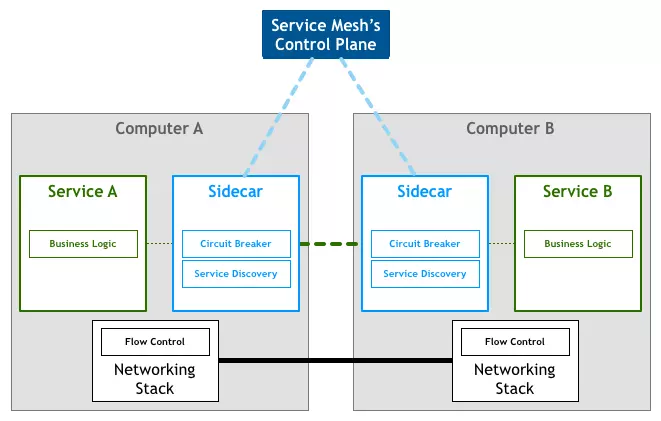
ЭМжагІгУзїЮЊЗўЮёЕФЗЂЦ№ЗНЃЌжЛашвЊгУзюМђЕЅЕФЗНЪННЋЧыЧѓЗЂЫЭИјБОЕиЕФЗўЮёЭјИёДњРэЃЌШЛКѓЭјИёДњРэЛсНјааКѓајЕФВйзїЃЌШчЗўЮёЗЂЯжЃЌИКдиОљКтЃЌзюКѓНЋЧыЧѓзЊЗЂИјФПБъЗўЮёЁЃЕБгаДѓСПЗўЮёЯрЛЅЕїгУЪБЃЌЫќУЧжЎМфЕФЗўЮёЕїгУЙиЯЕОЭЛсаЮГЩЭјИёЃЌШчЯТЭМЫљЪОЃК
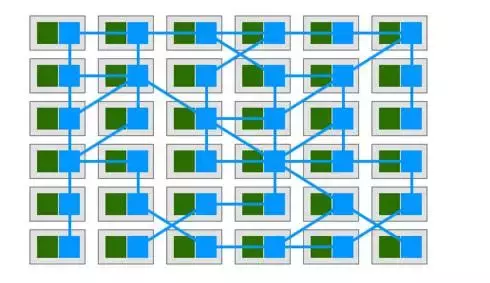
дкЩЯЭМжаТЬЩЋЗНПщЮЊЗўЮёЃЌРЖЩЋЗНПщЮЊБпГЕВПЪ№ЕФЗўЮёЭјИёЃЌРЖЩЋЯпЬѕЮЊЗўЮёМфЭЈбЖЁЃПЩвдПДЕНРЖЩЋЕФЗНПщКЭЯпЬѕзщГЩСЫећИіЭјИёЃЌЮвУЧНЋетИіЭМЦЌа§зЊ90ЁуЃЌОЭИќМгУїЯдСЫЃКЗўЮёЭјИёГЪЯжГівЛИіЭъећЕФжЇГХЬЌЪЦЃЌНЋЫљгаЕФЗўЮёЁБМмЁБдкЭјИёжЎЩЯЃК
ЗўЮёЭјИёЕФЯИНкЮвУЧНёЬьВЛЯъЯИеЙПЊЃЌ ЯъЯИФкШнДѓМвПЩвдВЮПМЭјЩЯзЪСЯЁЃЛђепЩдКѓЮвНЋЛсЭЦГівЛИіЗўЮёЭјИёЕФзЈЬтЃЌЕЅЖРЩюШыНщЩмЗўЮёЭјИёЁЃ
IstioвВПЩвдЪгЮЊЪЧвЛжжЗўЮёЭјИёЃЌ дкIstioЭјеОЩЯЯъЯИНтЪЭСЫетвЛИХФюЃК
ШчЙћЮвУЧПЩвддкМмЙЙжаЕФЗўЮёКЭЭјТчМфЭИУїЕизЂШывЛВуЃЌФЧУДИУВуНЋИГгшдЫЮЌШЫдБЖдЫљашЙІФмЕФПижЦЃЌЭЌЪБНЋПЊЗЂШЫдБДгБрТыЪЕЯжЗжВМЪНЯЕЭГЮЪЬтжаНтЗХГіРДЁЃЭЈГЃНЋетИіЭГвЛЕФМмЙЙВугыЗўЮёВПЪ№дквЛЦ№ЃЌЭГГЦЮЊЁАЗўЮёФіКЯВуЁБЁЃгЩгкЮЂЗўЮёгажњгкЗжРыИїИіЙІФмЭХЖгЃЌвђДЫЗўЮёФіКЯВугажњгкНЋдЫЮЌШЫдБДггІгУЬиадПЊЗЂКЭЗЂВМЙ§ГЬжаЗжРыГіРДЁЃЭЈЙ§ЯЕЭГЕизЂШыДњРэЕНЮЂЗўЮёМфЕФЭјТчТЗОЖжаЃЌIstioНЋхФвьЕФЮЂЗўЮёзЊБфГЩвЛИіМЏГЩЕФЗўЮёФіКЯВуЁЃ
IstioФмзіЪВУД?
IstioСІЭМНтОіЧАУцСаГіЕФЮЂЗўЮёЪЕЪЉКѓашвЊУцЖдЕФЮЪЬтЁЃIstio ЪзЯШЪЧвЛИіЗўЮёЭјТчЃЌЕЋЪЧIstioгжВЛНіНіЪЧЗўЮёЭјИё:
дк LinkerdЃЌ Envoy етбљЕФЕфаЭЗўЮёЭјИёжЎЩЯЃЌIstioЬсЙЉСЫвЛИіЭъећЕФНтОіЗНАИЃЌЮЊећИіЗўЮёЭјИёЬсЙЉааЮЊЖДВьКЭВйзїПижЦЃЌвдТњзуЮЂЗўЮёгІгУГЬађЕФЖрбљЛЏашЧѓЁЃ
IstioдкЗўЮёЭјТчжаЭГвЛЬсЙЉСЫаэЖрЙиМќЙІФм(вдЯТФкШнРДздЙйЗНЮФЕЕ)ЃК
СїСПЙмРэЃКПижЦЗўЮёжЎМфЕФСїСПКЭAPIЕїгУЕФСїЯђЃЌЪЙЕУЕїгУИќПЩППЃЌВЂЪЙЭјТчдкЖёСгЧщПіЯТИќМгНЁзГЁЃ
ПЩЙлВьадЃКСЫНтЗўЮёжЎМфЕФвРРЕЙиЯЕЃЌвдМАЫќУЧжЎМфСїСПЕФБОжЪКЭСїЯђЃЌДгЖјЬсЙЉПьЫйЪЖБ№ЮЪЬтЕФФмСІЁЃ
ВпТджДааЃКНЋзщжЏВпТдгІгУгкЗўЮёжЎМфЕФЛЅЖЏЃЌШЗБЃЗУЮЪВпТдЕУвджДааЃЌзЪдДдкЯћЗбепжЎМфСМКУЗжХфЁЃВпТдЕФИќИФЪЧЭЈЙ§ХфжУЭјИёЖјВЛЪЧаоИФгІгУГЬађДњТыЁЃ
ЗўЮёЩэЗнКЭАВШЋЃКЮЊЭјИёжаЕФЗўЮёЬсЙЉПЩбщжЄЩэЗнЃЌВЂЬсЙЉБЃЛЄЗўЮёСїСПЕФФмСІЃЌЪЙЦфПЩвддкВЛЭЌПЩаХЖШЕФЭјТчЩЯСїзЊЁЃ
Г§ДЫжЎЭтЃЌIstioеыЖдПЩРЉеЙадНјааСЫЩшМЦЃЌвдТњзуВЛЭЌЕФВПЪ№ашвЊЃК
ЦНЬЈжЇГжЃКIstioжМдкдкИїжжЛЗОГжадЫааЃЌАќРЈПчдЦЃЌ дЄжУЃЌKubernetesЃЌMesosЕШЁЃзюГѕзЈзЂгкKubernetesЃЌЕЋКмПьНЋжЇГжЦфЫћЛЗОГЁЃ
МЏГЩКЭЖЈжЦЃКВпТджДаазщМўПЩвдРЉеЙКЭЖЈжЦЃЌвдБугыЯжгаЕФACLЃЌШежОЃЌМрПиЃЌХфЖюЃЌЩѓКЫЕШНтОіЗНАИМЏГЩЁЃ
етаЉЙІФмМЋДѓЕФМѕЩйСЫгІгУГЬађДњТыЃЌЕзВуЦНЬЈКЭВпТджЎМфЕФёюКЯЃЌЪЙЮЂЗўЮёИќШнвзЪЕЯжЁЃ
IstioЕФеце§МлжЕ
ЩЯУцеЊГСЫIstioЙйЗНЕФДѓЖЮЮФЕЕЫЕУїЃЌбѓбѓШїШїЕФСаГіСЫIstioЕФДѓАбДѓАбИпДѓЩЯЕФЙІФмЁЃЕЋЪЧетаЉЖМВЛЪЧжиЕуЃЁРэТлЩЯЫЕЃЌШЮКЮЮЂЗўЮёПђМмЃЌжЛвЊдИвтЭљЩЯУцЖбЙІФмЃЌдчЭэЖМПЩвдЪЕЯжетаЉЁЃФЧЃЌЙиМќдкФФРяЃП
ВЛЗСЩшЯывЛЯТЃЌдкЦНЪБРэНтЕФЮЂЗўЮёПЊЗЂЙ§ГЬжаЃЌдкУЛгаIstioетбљЕФЗўЮёЭјИёЕФЧщПіЯТЃЌвЊШчКЮПЊЗЂЮвУЧЕФгІгУГЬађЃЌВХПЩвдзіЕНЧАУцСаГіЕФетаЉЗсИЛЖрВЪЕФЙІФм?
етЪ§вдМИЪЎМЧЕФИїжжЬиадЃЌШчКЮВХПЩвдМгШыЕНгІгУГЬађ?
ЮоЭтКѕЃЌевИіSpring CloudЛђепDubboЕФГЩЪьПђМмЃЌжБНгИуЖЈЗўЮёзЂВсЃЌЗўЮёЗЂЯжЃЌИКдиОљКтЃЌШлЖЯЕШЛљДЁЙІФмЁЃШЛКѓздМКПЊЗЂЗўЮёТЗгЩЕШИпМЖЙІФмЃЌ
НгШыZipkinЕШApmзіШЋСДТЗМрПиЃЌздМКзіМгУмЁЂШЯжЄЁЂЪкШЈЁЃ ЯыАьЗЈИуЖЈЛвЖШЗНАИЃЌгУRedisЕШЪЕЯжЯоЫйЁЂХфЖюЁЃ
жюШчДЫРрЃЌвЛДѓЖбЕФЪТЧщЃЌ ЖМашвЊздМКзіЃЌЮоТлЪЧевПЊдДЯюФПЛЙЪЧздМКВйЕЖЃЌзюКѓећГівЛИіДјгавЛДѓЖбЙІФмЕФгІгУГЬађЃЌЩЯЯпВПЪ№ЁЃШЛКѓИјИіХфжУЫЕУїЕНдЫЮЌЃЌИцЫпЫћЫЕШчКЮашвЊЛвЖШЃЌвЊШчКЮШчКЮЃЌ
ШчЙћвЊЯоЫйЃЌХфжУФФРяФФРяЁЃ
етаЉЙЄзїЃЌЯраХзіЮЂЗўЮёТфЕиЕФЙЋЫОЃЌЛљБОЖМХмВЛЕєЃЌашЧѓЪЧЯжЪЕДцдкЕФЃЌЮоЗЧФмЗёЪЕЯжЃЌвдМАЪЕЯжЖрЩйЕФЮЪЬтЃЌЕЋЪЧКСЮовЩЮЪЕФЪЧЃЌвЊзіЕНетаЉЃЌОјЖдВЛЪЧвЛМўШнвзЕФЪТЧщЁЃ
ЮЪЬтЪЧЃЌМДЪЙЗбСІзіЕНетаЉЪТЧщЕНетРяЛЙУЛгаЭъЃКдЫЮЌХмРДЬсСЫЕувЊЧѓЃЌдкЫћПДРДКмКЯРэЕФвЊЧѓЃЌБШШчЫЕЃКМђЕЅЕуЕФМгИіКкУћЕЅЃЌ
ИДдгЕуЕФвЊзіИіЬиЪтЕФЛвЖШЃКНЋРДздiPhoneЕФгУЛЇСїСПЕМ1%ЕНStaggingЛЗОГЕФ2.0аТАцБОЁЁ
етРяОЭгавЛИіКмбЯЫрЕФЮЪЬтЃЌ ИјУПИівЕЮёГЬађЕФПЊЗЂШЫдБ: ФуЕНЕзЯыЭљФуЕФвЕЮёГЬађРяУцШћЖрЩйЙмРэКЭдЫЮЌЕФЙІФм?
ОЭЫуФуholdЕФзЁММЪѕКЭЪБМфЃЌФугаФмСІвЛИівЛИіЕФТњзуИїжждЫЮЌКЭЙмРэЕФашЧѓТ№ЃП ЕБФуЗЂЯжФуПЊЪМЦЃгкЯьгІИїжжЗЧЙІФмадЕФашЧѓЪБЃЌОЭИУПЊЪМЗДЪЁСЫ:
ЮвУЧПЊЗЂЕФЪЧвЕЮёГЬађЃЌЫќЕФКЫаФМлжЕдквЕЮёТпМЕФДІРэКЭЪЕЯжЃЌНЋШчДЫжЎЖрЕФЪБМфОЋСІЛЈЗбдкетаЉЗЧвЕЮёЙІФмЩЯЃЌ
етецЕФКЯРэТ№? ЖјЧвМДЪЙЪЧдкЪЕЯжВуУцЃЌЮЂЗўЮёЪЕЪЉЪБЃЌзюживЊЕФЪЧШчКЮЛЎЗжЮЂЗўЮёЃЌШчКЮжЦЖЈНгПкавщЃЌФуИУШчКЮЗжХфФугаЯоЕФЪБМфКЭзЪдДЃП
Istio ГЌдН spring cloudКЭdubbo ЕШДЋЭГПЊЗЂПђМмжЎДІЃЌ ОЭдкгкВЛНіНіДјРДСЫдЖГЌетаЉПђМмЫљФмЬсЙЉЕФЙІФмЃЌ
ЖјЧввВВЛашвЊгІгУГЬађЮЊДЫзіДѓСПЕФИФЖЏЃЌ ПЊЗЂШЫдБвВВЛБиЮЊЩЯУцЕФЙІФмЪЕЯжНјааДѓСПЕФжЊЪЖДЂБИЁЃ
змНс:
Istio ДѓЗљНЕЕЭЮЂЗўЮёМмЙЙЯТгІгУГЬађЕФПЊЗЂФбЖШЃЌЪЦБиМЋДѓЕФЭЦЖЏЮЂЗўЮёЕФЦеМАЁЃИіШЫРжЙлЙРМЦЃЌЫцзХisitoЕФГЩЪьЃЌЮЂЗўЮёПЊЗЂСьгђНЋгРДвЛДЮЕпИВадЕФБфИяЁЃКѓУцЮвУЧдкНщЩмIstioЕФМмЙЙКЭЙІФмФЃПщЪБ,
ДѓМвПЩвдСЫНтЕНIstioЪЧШчКЮзіЕНетаЉЕФЁЃ
ПЊЗЂЭХЖг
дкПЊЪМНщЩмIstioЕФМмЙЙжЎЧА, ЮвУЧдйЯъЯИНщЩмвЛЯТIstioЕФПЊЗЂЭХЖг, ПДПДБГКѓЕФДѓРаЁЃЪзЯШЃЌIstioЕФПЊЗЂЭХЖгжївЊРДзд
GoogleЃЌ IBMКЭLyftЃЌеЊГвЛЖЮЙйЗНАЫЙЩЃК
ЛљгкЮвУЧЮЊФкВПКЭЦѓвЕПЭЛЇЙЙНЈКЭдЫгЊДѓЙцФЃЮЂЗўЮёЕФГЃМћОбщЃЌGoogleЃЌIBMКЭLyftСЊЪжДДНЈIstioЃЌЯЃЭћЮЊЮЂЗўЮёПЊЗЂКЭЮЌЛЄЬсЙЉПЩППЕФЛљДЁЁЃGoogleКЭIBMЯраХВЛашвЊНщЩмСЫ,
дкIstioЯюФПжаетСНИіЙЋЫОЪЧОјЖджїСІЃЌОйИіР§зг,ЯТЭМЪЧ Istio Working GroupЕФГЩдБСаБэЃК
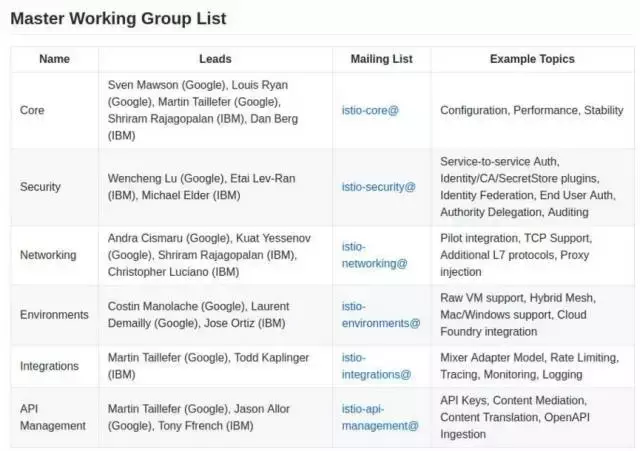
Ъ§вЛЯТ, змЙВ18ШЫЃЌ10ИіgoogleЃЌ8ИіIBMЁЃзЂвтетРяУЛгаLyftГіЯжЃЌвђЮЊLyftЕФЙБЯзжївЊМЏжадкEnvoyЁЃ
Google
IstioРДздЖІЖІДѓУћЕФGCP/Google Cloud Platform, етРяЕЎЩњСЫЭЌбљДѓУћЖІЖІЕФ
App Engine, Cloud EngineЕШжиСПМЖВњЦЗЁЃ
GoogleЮЊIstioДјРДСЫKubernetesКЭgRPC, ЛЙгаКЭEnvoyЯрЙиЕФЬиадШчАВШЋЃЌадФмКЭРЉеЙадЁЃ
АЫид: ИКд№IstioЕФGCPВњЦЗОРэVarun TalwarЃЌ ЭЌЪБвВИКд№gRPCЯюФП, ЫљвдЙизЂgRPCЕФЭЌбЇЃЈБШШчЮвздМКЃЉПЩвдВЛгУЕЃаФЃКIstioЖдgRPCЕФжЇГжБиШЛЪЧУЛгаЮЪЬтЕФЁЃ
IBM
IBMЕФЭХЖгЭЌРДРДздIBMдЦЦНЬЈ, IBMЕФЙБЯзЪЧ:
Г§СЫПЊЗЂIstioПижЦУцАхжЎЭт, ЛЙгаКЭEnvoyЯрЙиЕФЦфЫћЬиадШчПчЗўЮёАцБОЕФСїСПЧаЗж, ЗжВМЪНЧыЧѓзЗзй(Zipkin)КЭЪЇАмзЂШыЁЃ
Lyft
LyftЕФЙБЯзжївЊМЏжадкEnvoyДњРэЃЌетЪЧLyftПЊдДЕФЗўЮёЭјИёЃЌЛљгкC++ЁЃОнЫЕEnvoyдкLyftПЩвдЙмРэГЌЙ§100ИіЗўЮёЃЌПчдН10000ИіащФтЛњЃЌУПУыДІРэ2АйЭђЧыЧѓЁЃБОжмзюаТЯћЯЂЃЌEnvoyИеИеМгШыCNCFЃЌГЩЮЊИУЛљН№ЛсЕФЕкЪЎвЛИіЯюФПЁЃ
зюКѓЃЌ дкIsitoЕФНщЩмЭъГЩжЎКѓ, ЮвУЧПЊЪМЯТвЛНкФкШнЃЌIstioЕФМмЙЙЁЃ
ЖўЁЂМмЙЙ
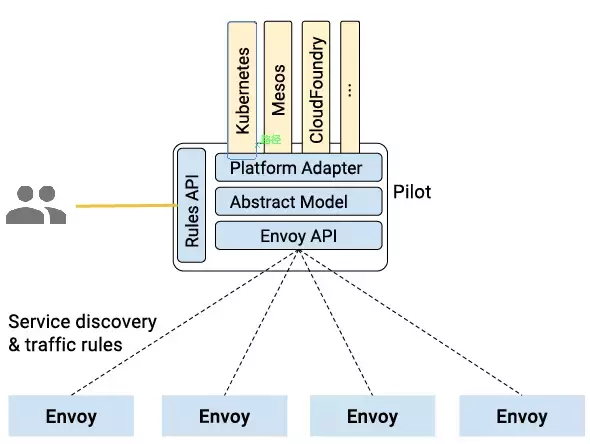
ећЬхМмЙЙ
IstioЗўЮёЭјИёТпМЩЯЗжЮЊЪ§ОнУцАхКЭПижЦУцАхЁЃ
Ъ§ОнУцАхгЩвЛзщжЧФмДњРэЃЈEnvoyЃЉзщГЩЃЌДњРэВПЪ№ЮЊБпГЕЃЌЕїНтКЭПижЦЮЂЗўЮёжЎМфЫљгаЕФЭјТчЭЈаХЁЃ
ПижЦУцАхИКд№ЙмРэКЭХфжУДњРэРДТЗгЩСїСПЃЌвдМАдкдЫааЪБжДааВпТдЁЃ
ЯТЭМЮЊIstioЕФМмЙЙЯъЯИЗжНтЭМЃК
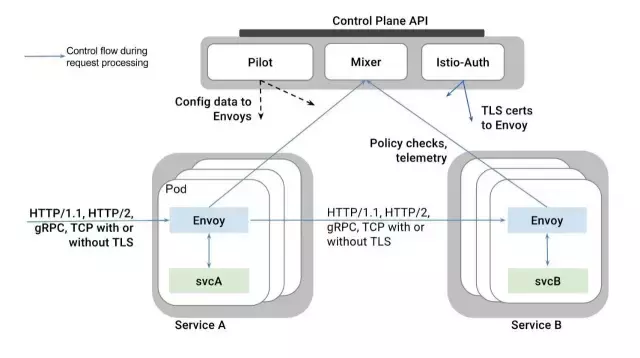
етЪЧКъЙлЪгЭМЃЌПЩвдИќаЮЯѓЕФеЙЪОIstioСНИіУцАхЕФЙІФмКЭКЯзїЃК
вдЯТЗжБ№НщЩм Istio жаЕФжївЊФЃПщ Envoy/Mixer/Pilot/AuthЁЃ
Envory
вдЯТНщЩмФкШнРДздIstioЙйЗНЮФЕЕЃК
Istio ЪЙгУEnvoyДњРэЕФРЉеЙАцБОЃЌEnvoyЪЧвдC++ПЊЗЂЕФИпадФмДњРэЃЌгУгкЕїНтЗўЮёЭјИёжаЫљгаЗўЮёЕФЫљгаШыеОКЭГіеОСїСПЁЃ
IstioРћгУСЫEnvoyЕФаэЖрФкжУЙІФмЃЌР§ШчЖЏЬЌЗўЮёЗЂЯжЃЌИКдиОљКтЃЌTLS terminationЃЌHTTP/2&gRPCДњРэЃЌШлЖЯЦїЃЌНЁПЕМьВщЃЌЛљгкАйЗжБШСїСПВ№ЗжЕФЗжЖЮЭЦГіЃЌЙЪеЯзЂШыКЭЗсИЛЕФmetricsЁЃ
EnvoyЪЕЯжСЫЙ§ТЫКЭТЗгЩЁЂЗўЮёЗЂЯжЁЂНЁПЕМьВщЃЌЬсЙЉСЫОпгаЕЏадЕФИКдиОљКтЁЃЫќдкАВШЋЩЯжЇГжTLSЃЌдкЭЈаХЗНУцжЇГжgRPCЁЃ
ИХРЈЫЕЃЌEnvoyЬсЙЉЕФЪЧЗўЮёМфЭјТчЭЈбЖЕФФмСІЃЌАќРЈ(вдЯТОљПЩжЇГжTLS)ЃК
HTTPЃЏ1.1
HTTP/2
gRPC
TCP
вдМАЭјТчЭЈбЖжБНгЯрЙиЕФЙІФмЃК
ЗўЮёЗЂЯжЃКДгPilotЕУЕНЗўЮёЗЂЯжаХЯЂ
Й§ТЫ
ИКдиОљКт
НЁПЕМьВщ
жДааТЗгЩЙцдђ(Rule): ЙцдђРДздPolit,АќРЈТЗгЩКЭФПЕФЕиВпТд
МгУмКЭШЯжЄ: TLS certsРДзд Istio-Auth
ДЫЭт, Envoy вВЭТГіИїжжЪ§ОнИјMixer:
Metrics
Logging
Distribution Trace: ФПЧАжЇГж Zipkin
змНс: EnvoyЪЧIstioжаИКд№ЁБИЩЛюЁБЕФФЃПщ,ШчЙћНЋећИіIstioЬхЯЕБШгїЮЊвЛИіЪЉЙЄЖг,ФЧУД
Envoy ОЭЪЧзюЕзВуИКд№АсзЉЕФУёЙЄЃЌЫљгаЬхСІЛюЖМгЩEnvoyЭъГЩЁЃЫљгаашвЊПижЦЃЌОіВпЃЌЙмРэЕФЙІФмЖМЪЧЦфЫћФЃПщРДИКд№ЃЌШЛКѓХфжУИјEnvoyЁЃ
IstioМмЙЙЛиЙЫ
дкМЬајНщЩмIstioЦфЫћЕФФЃПщжЎЧАЃЌЮвУЧРДЛиЙЫвЛЯТIstioЕФМмЙЙЃЌЧАУцЮвУЧЬсЕН, IstioЗўЮёЭјИёЗжЮЊСНДѓПщЃКЪ§ОнУцАхКЭПижЦУцАхЁЃ
ИеИеНщЩмЕФEnvoyЃЌдкIstioжаАчбнЕФОЭЪЧЪ§ОнУцАхЃЌЖјЦфЫћЮвУЧЯТУцНЋвЊТНајНщЩмЕФMixerЁЂPilotКЭAuthЪєгкПижЦУцАхЁЃЩЯУцЮвИјГіСЫвЛИіРрБШЃКIstioжаEnvoy
(ЛђепЫЕЪ§ОнУцАх)АчбнЕФНЧЩЋЪЧЕзВуИЩЛюЕФУёЙЄЃЌЖјИУШУетаЉУёЙЄШчКЮЙЄзїЃЌгЩАќЙЄЭЗПижЦУцАхРДИКд№ЭъГЩЁЃ
дкIstioЕФМмЙЙжаЃЌетСНИіФЃПщЕФЗжЙЄЗЧГЃЕФЧхЮњЃЌЬхЯждкМмЙЙЩЯвВЪЧОЮГЗжУїЃК MixerЃЌPilotКЭAuthетШ§ИіФЃПщЖМЪЧGoгябдПЊЗЂЃЌДњТыЭаЙмдкGithubЩЯЃЌШ§ИіВжПтЗжБ№ЪЧ
Istio/mixer, Istio/pilot/authЁЃЖјEnvoyРДздLyftЃЌБрГЬгябдЪЧc++
11ЃЌДњТыЭаЙмдкGithubЕЋВЛЪЧIstioЯТЁЃДгЭХЖгЗжЙЄПДЃЌGoogleКЭIBMЙизЂгкПижЦУцАхжаЕФMixerЃЌPilotКЭAuthЃЌЖјLyftМЬајзЈзЂгкEnvoyЁЃ
IstioЕФетИіМмЙЙЩшМЦЃЌНЋЕзВуService MeshЕФОпЬхЪЕЯжЃЌКЭIstioКЫаФЕФПижЦУцАхВ№ЗжПЊЁЃДгЖјЪЙЕУIstioПЩвдНшжњГЩЪьЕФEnvoyПьЫйЭЦГіВњЦЗЃЌЮДРДШчЙћгаИќКУЕФService
MeshЗНАИвВЗНБуМЏГЩЁЃ
EnvoyЕФОКељеп
ЬИЕНетРяЃЌСФвЛЯТФПЧАЪаУцЩЯEnvoyжЎЭтЕФСэЭтвЛИіService MeshГЩЪьВњЦЗЃКЛљгкScalaЕФLinkerdЁЃ
LinkerdЕФЙІФмКЭЖЈЮЛКЭEnvoyЗЧГЃЯрЫЦЃЌЖјЧвОЭдкНёФъЩЯАыФъГЩЙІНјШыCNCFЁЃЖјдк Istio
ЭЦГіжЎКѓЃЌLinkerdзіСЫвЛИіКмгавтЫМЕФЖЏзїЃКLinkerdЭЦГіСЫКЭIstioЕФМЏГЩЃЌЪЕМЪЮЊЬцЛЛEnvoyзїЮЊIstioЕФЪ§ОнУцАхЃЌКЭIstioЕФПижЦУцАхЖдНгЁЃ
ЛиЕНIstioЕФМмЙЙЭМЃЌНЋетЗљЭМжаЕФEnvoyзжбљЬцЛЛЮЊLinkerdМДПЩЁЃСэЭтЛЙгаВЛдкЭМжаБэЪОЕФLinkerd
Ingress / Linkerd EgressгУгкЬцДњEnvoyЪЕЯж k8sЕФIngress/EgressЁЃ
БОжмзюаТЯћЯЂЃК NginxЭЦГіСЫздМКЕФЗўЮёЭјИёВњЦЗNginmeshЃЌЙІФмРрЫЦЃЌБШНЯгавтЫМЕФЕиЗНЪЧNgxinmeshвЛГіРДОЭжБНгаћВМвЊКЭIstioМЏГЩЃЌЬцЛЛEnvoyЁЃ
ЯТУцПЊЪМНщЩм Istio жазюКЫаФЕФПижЦУцАхЁЃ
Pilot
СїСПЙмРэ
IstioзюКЫаФЕФЙІФмЪЧСїСПЙмРэЃЌЧАУцЮвУЧПДЕНЕФЪ§ОнУцАхЃЌгЩEnvoyзщГЩЕФЗўЮёЭјИёЃЌНЋећИіЗўЮёМфЭЈбЖКЭШыПк/ГіПкЧыЧѓЖМГадигкЦфЩЯЁЃ
ЪЙгУIstioЕФСїСПЙмРэФЃаЭЃЌБОжЪЩЯНЋСїСПКЭЛљДЁЩшЪЉРЉеЙНтёюЃЌШУдЫЮЌШЫдБЭЈЙ§PilotжИЖЈЫќУЧЯЃЭћСїСПзёбЪВУДЙцдђЃЌЖјВЛЪЧФФаЉЬиЖЈЕФpod/VMгІИУНгЪеСїСПЁЃ
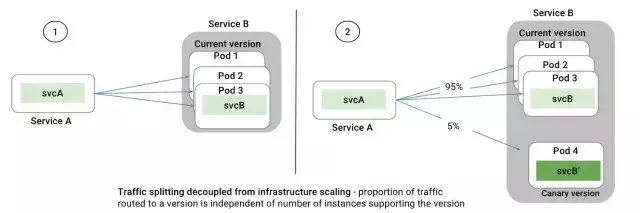
ЖдетЖЮЛАЕФРэНт, ПЩвдПДЯТЭМЃКМйЖЈЮвУЧдгаЗўЮёBЃЌВПЪ№дкPod1/2/3ЩЯЃЌЯждкЮвУЧВПЪ№вЛИіаТАцБОдкPod4дкЃЌЯЃЭћЪЕЯжЧа5%ЕФСїСПЕНаТАцБОЁЃ
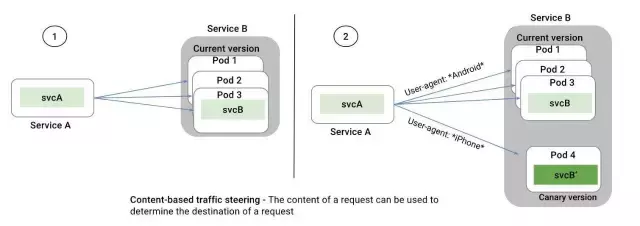
ШчЙћвдЛљДЁЩшЪЉЮЊЛљДЁЪЕЯжЩЯЪі5%ЕФСїСПЧаЗжЃЌдђашвЊЭЈЙ§ФГаЉЪжЖЮНЋСїСПЧа5%ЕНPod4етИіЬиЖЈЕФВПЪ№ЕЅЮЛЃЌЪЕЪЉЪБОЭБиаыКЭServiceBЕФОпЬхВПЪ№ЛЙгаServiceAЗУЮЪServiceBЕФЬиЖЈЗНЪННєУмСЊЯЕдквЛЦ№.
БШШчШчЙћСНИіЗўЮёжЎМфЪЧгУNginxзіЗДЯђДњРэЃЌдђашвЊдіМгPod4ЕФIPзїЮЊUpstreamЃЌВЂЕїећPod1/2/3/4ЕФШЈживдЪЕЯжСїСПЧаЗжЁЃ
ШчЙћЪЙгУIstioЕФСїСПЙмРэЙІФм, гЩгкEnvoyзщГЩЕФЗўЮёЭјТчЭъШЋдкIstioЕФПижЦжЎЯТ,вђДЫвЊЪЕЯжЩЯЪіЕФСїСПВ№ЗжЗЧГЃМђЕЅ.
МйЖЈдАцБОЮЊ1.0ЃЌаТАцБОЮЊ2.0ЃЌжЛвЊЭЈЙ§Polit ИјEnvoyЗЂЫЭвЛИіЙцдђЃК2.0АцБО5%СїСПЃЌЪЃЯТЕФИј1.0ЁЃ
етжжЧщПіЯТЃЌЮвУЧЮоашЙизЂ2.0АцБОЕФВПЪ№ЃЌвВЮоашИФЖЏШЮКЮММЪѕЩшжУ, ИќВЛашвЊдквЕЮёДњТыжаЮЊДЫЬсЙЉШЮКЮХфжУжЇГжКЭДњТыаоИФЁЃвЛЧагЩ
Pilot КЭжЧФмEnvoyДњРэИуЖЈЁЃ
ЮвУЧЛЙПЩвдЭцЕФИќьХвЛЕу, БШШчИљОнЧыЧѓЕФФкШнРДдДНЋСїСПЗЂЫЭЕНЬиЖЈАцБОЃК
КѓУцЮвУЧЛсНщЩмШчКЮДгЧыЧѓжаЬсШЁГіUser-AgentетбљЕФЪєадРДХфКЯЙцдђНјааСїСППижЦЁЃ
PilotЕФЙІФмИХЪі
ЮвУЧдкЧАУцгаЧПЕїЫЕЃЌEnvoyдкЦфжаАчбнЕФИКд№АсзЉЕФУёЙЄНЧЩЋЃЌЖјжИЛгEnvoyЙЄзїЕФУёЙЄЭЗОЭЪЧPilotФЃПщЁЃ
ЙйЗНЮФЕЕжаЖдPilotЕФЙІФмУшЪіЃК
PilotИКд№ЪеМЏКЭбщжЄХфжУВЂНЋЦфДЋВЅЕНИїжжIstioзщМўЁЃЫќДгMixerКЭEnvoyжаГщШЁЛЗОГЬиЖЈЕФЪЕЯжЯИНкЃЌЮЊЫћУЧЬсЙЉЖРСЂгкЕзВуЦНЬЈЕФгУЛЇЗўЮёЕФГщЯѓБэЪОЁЃДЫЭтЃЌСїСПЙмРэЙцдђЃЈМДЭЈгУ4ВуЙцдђКЭ7ВуHTTP/gRPCТЗгЩЙцдђЃЉПЩвддкдЫааЪБЭЈЙ§PilotНјааБрГЬЁЃ
УПИіEnvoyЪЕР§ИљОнЦфДгPilotЛёЕУЕФаХЯЂвдМАЦфИКдиОљКтГижаЕФЦфЫћЪЕР§ЕФЖЈЦкНЁПЕМьВщРДЮЌЛЄ ИКдиОљКтаХЯЂЃЌДгЖјдЪаэЦфдкФПБъЪЕР§жЎМфжЧФмЗжХфСїСПЃЌЭЌЪБзёбЦфжИЖЈЕФТЗгЩЙцдђЁЃ
PilotИКд№дкIstioЗўЮёЭјИёжаВПЪ№ЕФEnvoyЪЕР§ЕФЩњУќжмЦкЁЃ
PilotЕФМмЙЙ
ЯТЭМЪЧPilotЕФМмЙЙЭМЃК
Envoy APIИКд№КЭEnvoyЕФЭЈбЖ, жївЊЪЧЗЂЫЭЗўЮёЗЂЯжаХЯЂКЭСїСППижЦЙцдђИјEnvoy
EnvoyЬсЙЉЗўЮёЗЂЯжЃЌИКдиОљКтГиКЭТЗгЩБэЕФЖЏЬЌИќаТЕФAPIЁЃетаЉAPIНЋIstioКЭEnvoyЕФЪЕЯжНтёюЁЃ(СэЭтЃЌвВЪЙЕУLinkerdжЎРрЕФЦфЫћЗўЮёЭјТчЪЕЯжЕУвдЦНЛЌНгЙмEnvoy)
PolitЖЈСЫвЛИіГщЯѓФЃаЭЃЌвдДгЬиЖЈЦНЬЈЯИНкжаНтёюЃЌЮЊПчЦНЬЈЬсЙЉЛљДЁ
Platform AdapterдђЪЧетИіГщЯѓФЃаЭЕФЯжЪЕЪЕЯжАцБО, гУгкЖдНгЭтВПЕФВЛЭЌЦНЬЈ
зюКѓЪЧ Rules APIЃЌЬсЙЉНгПкИјЭтВПЕїгУвдЙмРэPilotЃЌАќРЈУќСюааЙЄОпIstioctlвдМАЮДРДПЩФмГіЯжЕФЕкШ§ЗНЙмРэНчУц
ЗўЮёЙцЗЖКЭЪЕЯж
PilotМмЙЙжа, зюживЊЕФЪЧAbstract ModelКЭPlatform AdapterЃЌЮвУЧЯъЯИНщЩмЁЃ
Abstract ModelЃКЪЧЖдЗўЮёЭјИёжаЁБЗўЮёЁБЕФЙцЗЖБэЪО, МДЖЈвхдкistioжаЪВУДЪЧЗўЮёЃЌетИіЙцЗЖЖРСЂгкЕзВуЦНЬЈЁЃ
Platform AdapterЃКетРягаИїжжЦНЬЈЕФЪЕЯжЃЌФПЧАжївЊЪЧKubernetesЃЌСэЭтзюаТЕФ0.2АцБОЕФДњТыжаГіЯжСЫConsulКЭEurekaЁЃ
РДПДвЛЯТPilot 0.2ЕФДњТыЃЌpilot/platform ФПТМЯТ: 
УщвЛблplatform.goЃК

ЗўЮёЙцЗЖЕФЖЈвхдкmodle/service.goжа:

гЩгкЦЊЗљгаЯоЃЌДњТыВПЗжетРяВЛЩюШы, жЛЪЧЭЈЙ§ЩЯУцЕФСНЖЮДњТыРДеЙЪОPilotжаЖдЗўЮёЕФЙцЗЖЖЈвхКЭФПЧАЕФМИИіЪЕЯжЁЃ
днЪБЖјбд(ЕБЧААцБОЪЧ0.1.6, 0.2АцБОЩаЮДе§ЪНЗЂВМ)ЃЌФПЧА Istio жЛжЇГжK8sвЛжжЗўЮёЗЂЯжЛњжЦЁЃ
БИзЂ: ConsulЕФЪЕЯжОнЫЕжївЊЪЧЮЊСЫжЇГжКѓУцНЋвЊжЇГжЕФCloud FoundryЃЌEurekaУЛгаевЕНзЪСЯЁЃEtcd3
ЕФжЇГжЛЙдкIssueСаБэжаЃЌПДIssueМЧТМељжДжаЁЃ
PilotЙІФм
ЛљгкЩЯЪіЕФМмЙЙЩшМЦЃЌPilotЬсЙЉвдЯТживЊЙІФмЃК
ЧыЧѓТЗгЩ
ЗўЮёЗЂЯжКЭИКдиОљКт
ЙЪеЯДІРэ
ЙЪеЯзЂШы
ЙцдђХфжУ
гЩгкЦЊЗљЯожЦЃЌНёЬьВЛж№ИіеЙПЊЯъЯИНщЩмУПИіЙІФмЕФЯъЧщЁЃДѓМвЭЈЙ§УћзжОЭДѓИХПЩвджЊЕРЪЧЪВУДЃЌШчЙћЯЃЭћСЫНтЯъЧщПЩвдЙизЂжЎКѓЕФЗжЯэЁЃЛђепВщдФЙйЗНЮФЕЕЕФНщЩмЁЃ
Mixer
MixerЗвыГЩжаЮФЪЧЛьвєЦї, ЯТУцЪЧЫќЕФЭМБъЃК
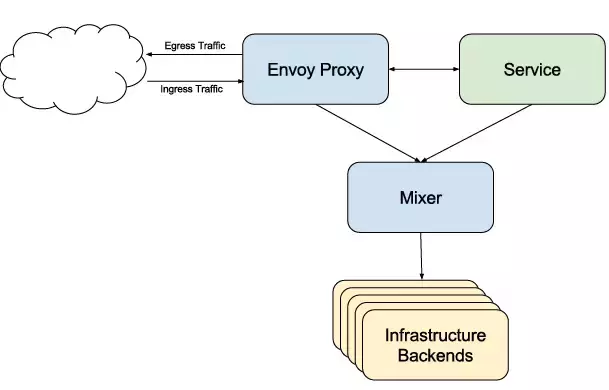
ЙІФмИХРЈЃКMixerИКд№дкЗўЮёЭјИёЩЯжДааЗУЮЪПижЦКЭЪЙгУВпТдЃЌВЂЪеМЏEnvoyДњРэКЭЦфЫћЗўЮёЕФвЃВтЪ§ОнЁЃ
MixerЕФЩшМЦБГОА
ЮвУЧЕФЯЕЭГЭЈГЃЛсЛљгкДѓСПЕФЛљДЁЩшЪЉЖјЙЙНЈЃЌетаЉЛљДЁЩшЪЉЕФКѓЖЫЗўЮёЮЊвЕЮёЗўЮёЬсЙЉИїжжжЇГжЙІФмЁЃАќРЈЗУЮЪПижЦЯЕЭГЃЌвЃВтВЖЛёЯЕЭГЃЌХфЖюжДааЯЕЭГЃЌМЦЗбЯЕЭГЕШЁЃдкДЋЭГЩшМЦжа,
ЗўЮёжБНггыетаЉКѓЖЫЯЕЭГМЏГЩЃЌШнвзВњЩњгВёюКЯЁЃ
дкIstioжаЃЌЮЊСЫБмУтгІгУГЬађЕФЮЂЗўЮёКЭЛљДЁЩшЪЉЕФКѓЖЫЗўЮёжЎМфЕФёюКЯЃЌЬсЙЉСЫ Mixer зїЮЊСНепЕФЭЈгУжаНщВуЃК
Mixer ЩшМЦНЋВпТдОіВпДггІгУВувЦГіВЂгУХфжУЬцДњЃЌВЂдкдЫЮЌШЫдБПижЦЯТЁЃгІгУГЬађДњТыВЛдйНЋгІгУГЬађДњТыгыЬиЖЈКѓЖЫМЏГЩдквЛЦ№ЃЌЖјЪЧгыMixerНјааЯрЕБМђЕЅЕФМЏГЩЃЌШЛКѓ
Mixer ИКд№гыКѓЖЫЯЕЭГСЌНгЁЃ
ЬиБ№Ьсаб: MixerВЛЪЧЮЊСЫдкЛљДЁЩшЪЉКѓЖЫжЎЩЯДДНЈвЛИіГщЯѓВуЛђепПЩвЦжВадВуЁЃвВВЛЪЧЪдЭМЖЈвхвЛИіЭЈгУЕФLogging
APIЃЌЭЈгУЕФMetric APIЃЌЭЈгУЕФМЦЗбAPIЕШЕШЁЃ
MixerЕФЩшМЦФПБъЪЧМѕЩйвЕЮёЯЕЭГЕФИДдгадЃЌНЋВпТдТпМДгвЕЮёЕФЮЂЗўЮёЕФДњТызЊвЦЕНMixerжа, ВЂЧвИФЮЊШУдЫЮЌШЫдБПижЦЁЃ
MixerЕФЙІФм
Mixer ЬсЙЉШ§ИіКЫаФЙІФмЃК
ЧАЬсЬѕМўМьВщЁЃдЪаэЗўЮёдкЯьгІРДздЗўЮёЯћЗбепЕФДЋШыЧыЧѓжЎЧАбщжЄвЛаЉЧАЬсЬѕМўЁЃЧАЬсЬѕМўАќРЈШЯжЄЃЌКкАзУћЕЅЃЌACLМьВщЕШЕШЁЃ
ХфЖюЙмРэЁЃЪЙЗўЮёФмЙЛдкЖрИіЮЌЖШЩЯЗжХфКЭЪЭЗХХфЖюЁЃЕфаЭР§згШчЯоЫйЁЃ
вЃВтБЈИцЁЃЪЙЗўЮёФмЙЛЩЯБЈШежОКЭМрПиЁЃ
дкIstioФкЃЌEnvoyжиЖШвРРЕMixerЁЃ
MixerЕФЪЪХфЦї
MixerЪЧИпЖШФЃПщЛЏКЭПЩРЉеЙЕФзщМўЁЃЦфжавЛИіЙиМќЙІФмЪЧГщЯѓГіВЛЭЌВпТдКЭвЃВтКѓЖЫЯЕЭГЕФЯИНкЃЌдЪаэEnvoyКЭЛљгкIstioЕФЗўЮёгыетаЉКѓЖЫЮоЙиЃЌДгЖјБЃГжЫћУЧЕФПЩвЦжВЁЃ
MixerдкДІРэВЛЭЌЛљДЁЩшЪЉКѓЖЫЕФСщЛюадЪЧЭЈЙ§ЪЙгУЭЈгУВхМўФЃаЭЪЕЯжЕФЁЃЕЅИіЕФВхМўБЛГЦЮЊЪЪХфЦїЃЌЫќУЧдЪаэMixerгыВЛЭЌЕФЛљДЁЩшЪЉКѓЖЫСЌНгЃЌетаЉКѓЬЈПЩЬсЙЉКЫаФЙІФмЃЌР§ШчШежОЃЌМрПиЃЌХфЖюЃЌACLМьВщЕШЁЃЪЪХфЦїЪЙMixerФмЙЛБЉТЖвЛжТЕФAPIЃЌгыЪЙгУЕФКѓЖЫЮоЙиЁЃдкдЫааЪБЭЈЙ§ХфжУШЗЖЈШЗЧаЕФЪЪХфЦїЬзМўЃЌВЂЧвПЩвдЧсЫЩжИЯђаТЕФЛђЖЈжЦЕФЛљДЁЩшЪЉКѓЖЫЁЃ
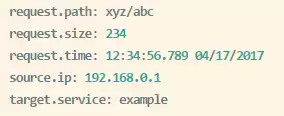
етИіЭМЪЧЙйЭјИјЕФЃЌСаГіЕФЙІФмВЛЖрЃЌЮвДгGithubЕФДњТыжазЅИіЭМИјДѓМвеЙЪОвЛЯТФПЧАвбгаЕФMixer
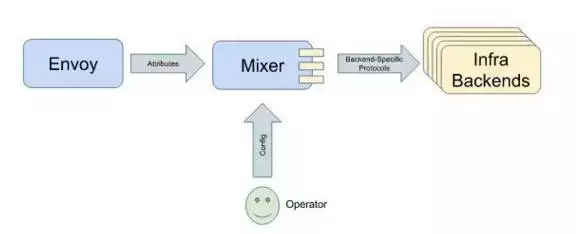
AdapterЃК
MixerЕФЙЄзїЗНЪН
IstioЪЙгУЪєадРДПижЦдкЗўЮёЭјИёжадЫааЕФЗўЮёЕФдЫааЪБааЮЊЁЃЪєадЪЧУшЪіШыПкКЭГіПкСїСПЕФгаУћГЦКЭРраЭЕФдЊЪ§ОнЦЌЖЮЃЌвдМАДЫСїСПЗЂЩњЕФЛЗОГЁЃIstioЪєадаЏДјЬиЖЈаХЯЂЦЌЖЮЃЌР§ШчЃК
ЧыЧѓДІРэЙ§ГЬжаЃЌЪєадгЩEnvoyЪеМЏВЂЗЂЫЭИјMixerЃЌMixerжаИљОндЫЮЌШЫдБЩшжУЕФХфжУРДДІРэЪєадЁЃЛљгкетаЉЪєадЃЌMixerЛсВњЩњЖдИїжжЛљДЁЩшЪЉКѓЖЫЕФЕїгУЁЃ
MixerЩшМЦгавЛЬзЧПДѓ(вВКмИДдг, ПАГЦIstioжазюИДдгЕФвЛИіВПЗж)ЕФХфжУФЃаЭРДХфжУЪЪХфЦїЕФЙЄзїЗНЪНЃЌЩшМЦгаЪЪХфЦїЁЂЧаУцЁЂЪєадБэДяЪНЃЌбЁдёЦїЁЂУшЪіЗћЃЌmanifests
ЕШвЛЖбИХФю.
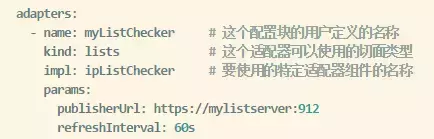
гЩгкЦЊЗљЫљЯоЃЌНёЬьВЛеЙПЊетПщФкШнЃЌетРяИјГіСНИіМђЕЅЕФР§згШУДѓМвЖдMixerЕФХфжУгаИіИаадЕФШЯЪЖ:
1ЁЂетЪЧвЛИіIPЕижЗМьВщЕФAdapterЃЌЪЕЯжРрЫЦКкУћЕЅЛђепАзУћЕЅЕФЙІФмЃК
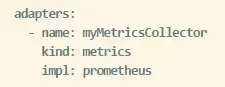
2ЁЂmetricsЕФЪЪХфЦї,НЋЪ§ОнБЈИцИјPrometheusЯЕЭГ

3ЁЂЖЈвхЧаУц, ЪЙгУЧАУцЖЈвхЕФ myListChecker етИіadapter ЖдЪєад source.ip
НјааКкУћЕЅМьВщЁЃ
Istio-Auth
Istio-AuthЬсЙЉЧПДѓЕФЗўЮёЕНЗўЮёКЭжеЖЫгУЛЇШЯжЄЃЌЪЙгУНЛЛЅTLSЃЌФкжУЩэЗнКЭЦООнЙмРэЁЃЫќПЩгУгкЩ§МЖЗўЮёЭјИёжаЕФЮДМгУмСїСПЃЌВЂЮЊдЫЮЌШЫдБЬсЙЉЛљгкЗўЮёЩэЗнЖјВЛЪЧЭјТчПижЦЪЕЪЉВпТдЕФФмСІЁЃ
IstioЕФЮДРДАцБОНЋдіМгЯИСЃЖШЕФЗУЮЪПижЦКЭЩѓМЦЃЌвдЪЙгУИїжжЗУЮЪПижЦЛњжЦЃЈАќРЈЛљгкЪєадКЭНЧЩЋЕФЗУЮЪПижЦвдМАЪкШЈЙГзгЃЉРДПижЦКЭМрЪгЗУЮЪФњЕФЗўЮёЃЌAPIЛђзЪдДЕФШЫдБЁЃ
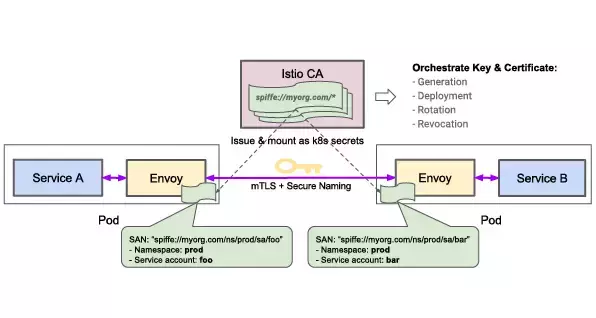
AuthЕФМмЙЙ
ЯТЭМеЙЪОIstio AuthМмЙЙЃЌЦфжаАќРЈШ§ИізщМўЃКЩэЗнЃЌУмдПЙмРэКЭЭЈаХАВШЋЁЃ
дкетИіР§згжа, ЗўЮёAвдЗўЮёеЪЛЇЁАfooЁБдЫаа, ЗўЮёBвдЗўЮёеЪЛЇЁАbarЁБдЫаа, ЫћУЧжЎМфЕФЭЈбЖдРДЪЧУЛгаМгУмЕФ.
ЕЋЪЧIstioдкВЛаоИФДњТыЕФЧщПі, вРЭаEnvoyаЮГЩЕФЗўЮёЭјИё, жБНгдкПЭЛЇЖЫEnvoyКЭЗўЮёЦїЖЫEnvoyжЎМфНјааЭЈбЖМгУмЁЃ
ФПЧАдкKubernetesЩЯдЫааЕФ IstioЃЌЪЙгУKubernetes service account/ЗўЮёеЪЛЇРДЪЖБ№дЫааИУЗўЮёЕФШЫдБЁЃ
ЮДРДНЋЭЦГіЕФЙІФм
AuthдкФПЧАЕФIstioАцБО(0.1.6КЭМДНЋЗЂВМЕФ0.2)жаЃЌЙІФмЛЙВЛЪЧКмШЋЃЌЮДРДдђЙцЛЎгаЗЧГЃЖрЕФЬиадЃК
ЯИСЃЖШЪкШЈКЭЩѓКЫ
АВШЋIstioзщМўЃЈMixer, PilotЕШЃЉ
МЏШКМфЗўЮёЕНЗўЮёШЯжЄ
ЪЙгУJWT/OAuth2/OpenID_ConnectжеЖЫЕНЗўЮёЕФШЯжЄ
жЇГжGCPЗўЮёеЪЛЇКЭAWSЗўЮёеЪЛЇ
ЗЧhttpСїСПЃЈMySqlЃЌRedisЕШЃЉжЇГж
UnixгђЬзНгзжЃЌгУгкЗўЮёКЭEnvoyжЎМфЕФБОЕиЭЈаХ
жаМфДњРэжЇГж
ПЩВхАЮУмдПЙмРэзщМў
ашвЊЬсабЕФЪЧЃКетаЉЙІФмЖМЪЧВЛИФЖЏвЕЮёгІгУДњТыЕФЧАЬсЯТЪЕЯжЕФЁЃ
ЛиЕНЮвУЧЧАУцЕФдјОЬжТлЕФЮЪЬтЃЌШчЙћздМКРДзіЃЌЭъГЩетаЉЙІФмДѓМвОѕЕУашвЊЖрЩйЙЄзїСПЃПвЊАбЫљгаЕФвЕЮёФЃПщЖМЧЈвЦЕНОпБИетаЉЙІФмЕФПђМмКЭЬхЯЕжаЃЌашвЊИФЖЏЖрЩйЃПЖјIstioЃЌЮДРДОЭЛсжБНгНЋетаЉЖЋЮїАкЩЯЮвУЧЕФВЭзРЁЃ
Ш§ЁЂЮДРД
ЧАУцЮвУЧНщЩмСЫIstioЕФЛљБОЧщПіЃЌЛЙгаIstioЕФМмЙЙКЭжївЊзщМўЁЃЯраХДѓМвЖдIstioгІИУгаСЫвЛИіГѕВНЕФШЯЪЖЁЃашвЊЬсабЕФЪЧЃЌIstioЪЧвЛИіНёФъ5дТВХЗЂВМ
0.1.0 АцБОЕФаТЯЪГіТЏЕФПЊдДЯюФПЃЌФПЧАИУЯюФПвВВХЗЂВМЕН0.1.6е§ЪНАцБОКЭ 0.2.2 pre
releaseАцБО. КмЖрЕиЗНЛЙВЛЭъЩЦЃЌЯЃЭћДѓМвПЩвдРэНтЃЌгаЕуРрЫЦгкзюдчЦкНзЖЮЕФKubernetesЁЃдкНгЯТРДЕФЪБМфЃЌЮвУЧНЋМђЕЅНщЩмвЛЯТIstioКѓУцЕФвЛаЉПЊЗЂМЦЛЎКЭЗЂеЙдЄЦкЁЃ
дЫааЛЗОГжЇГж
IstioФПЧАжЛжЇГжKubernetes, етЪЧСюШЫБШНЯвХКЖЕФвЛЕу. ВЛЙ§ istio ИјГіЕФНтЪЭЪЧistioЮДРДЛсжЇГждкИїжжЛЗОГжадЫааЃЌжЛЪЧФПЧАдк
0.1/0.2 етбљЕФГѕЪМНзЖЮднЪБзЈзЂгкKubernetesЃЌЕЋКмПьЛсжЇГжЦфЫћЛЗОГЁЃ
зЂвт: KubernetesЦНЬЈЃЌГ§СЫдЩњKubernetes, ЛЙгажюШч IBM Bluemix
Container ServiceКЭRedHat OpenShiftетбљЕФЩЬвЕЦНЬЈЁЃ вдМАgoogleздМвЕФ
Google Container EngineЁЃетЪЧздМвЕФЖЋЮї, ЖјЧвЯждкk8s/istio/gRPCЖМвбОБЛЛЎЙщЕН
Google cloud platformВПУХ, здШЛЛсгХЯШжЇГж.
СэЭтisitoЫљЫЕЕФЦфЫћЛЗОГжИЕФЪЧ:
Mesos: етИіЙРМЦЪЧДѓЖрШЫЗЧK8sЕФDockerЪЙгУепзюЙиаФЕФСЫ, днЪБДгGithubЩЯЕФДњТыжаЮДМћЕНгаПЊЙЄМЃЯѓ,
ЕЋЪЧIstioЕФЮФЕЕКЭЙйЗНЩљУїЖМУїЯдЫЕЛсжЇГж, ЙРМЦЛЙЪЧЯЃЭћКмДѓЕФ.
Cloud foundry: етИіЖЋЖЋЮвУЧЙњФкГ§СЫЫНгадЦЭтЭцЕФВЛЖр, IstioЖдЫќЕФжЇГжЫЦКѕвбОЦєЖЏ.
БШШчЮвПДЕНДњТыжавбОгаСЫConsulетИіЗўЮёзЂВсЕФжЇГж, ДгIssueЬжТлЩЯПДЕНЪЧЫЕЮЊЩЯCloud
foundryзізМБИ, вђЮЊCloud foundryУЛгаk8sФЧбљЕФдЩњЗўЮёзЂВсЛњжЦЁЃ
VM: етПщУЛгаПДЕННщЩм, ЕЋЪЧгаПДЕНIstioЕФЬжТлжаЬсЕНЛсжЇГжШнЦїКЭЗЧШнЦїЕФЛьКЯ(Hybrid)жЇГж
жЕЕУЬиБ№жИГіЕФЪЧЃЌФПЧАЮвЛЙУЛгаПДЕНIstioгаЖдDockerМвЕФSwarmгажЇГжЕФМЦЛЎЛђепЬжТл, ФПЧАЮвевЕНЕФШЮКЮIstioЕФзЪСЯжаЖМВЛДцдкSwarmетИіЖЋЖЋЁЃЮвжЛФмВЛИКд№ШЮЕФНтЖСЮЊЃКгаШЫЕФЕиЗНОЭгаНКўЃЌгаНКўОЭздШЛЛсгаНКўЖїдЙЁЃ
ТЗЯпЭМ
АДееIstioЕФЫЕЗЈЃЌЫћУЧМЦЛЎУП3ИідТЗЂВМвЛДЮаТАцБОЃЌЮвУЧПДвЛЯТФПЧАЕУЕНЕФвЛаЉаХЯЂЃК
0.1 АцБО2017Фъ5дТЗЂВМ,жЛжЇГжKubernetes
0.2 МДНЋЗЂВМ,ЕБЧАЪЧ0.2.1 pre-release, вВжЛжЇГжKubernetes
0.3 roadmapЩЯЫЕвЊжЇГжk8sжЎЭтЕФЦНЬЈ, ЁАSupport for Istio meshes
without Kubernetes.ЁБ, ЕЋЪЧОпЬхФФаЉЬиадЛсЗХдк0.3жа,ЛЙдкЬжТлжа
1.0 АцБОдЄМЦНёФъФъЕзЗЂВМ
зЂ: 1.0АцБОЕФЗЂВМЪБМфЙйЗНУЛгаУїШЗИјГіЃЌЮвжЛЪЧПДЕНЙйЭјзЪСЯРяУцгааХЯЂЭИТЖШчЯТ:
ЁАwe invite the community to join us in shaping the
project as we work toward a 1.0 release later this
year.ЁБ
АДееЩЯУцИјЕФаХЯЂЃЌМђЕЅЭЦЫуЃКгІИУЪЧ9дТЗЂ0.2, ШЛКѓ12дТЗЂ0.3, ЕЋЪЧетОЭвбОЪЧФъЕзСЫ, ЫљвдВЛХХГ§1.0ЭЦГйЗЂВМЕФПЩФмЃЌЛђеп0.3жБНгЕБГЩ
1.0 ЗЂВМЁЃ
ЩчЧјжЇГж
ЫфШЛIstioГѕГіНКўЃЌШщГєЮДИЩЃЌЕЋЪЧЦОНшgoogleКЭIBMЕФН№зжеаХЦЃЌЛЙгаIstioЧАЮРЖјЪЕМЪЕФЩшМЦРэФюЃЌФПЧАвбОгаКмЖрЙЋЫОдкПЊЪМЬсЙЉЖдIstioЕФжЇГжЛђепМЏГЩЃЌетЪЧIstioЙйЗНвГУцгаМЧдиЕФЃК
Red HatЃКOpenshift and OpenShift Application Runtimes
PivotalЃКCloud Foundry
WeaveworksЃКWeave Cloud and Weave Net 2.0
TigeraЃКProject Calico Network Policy Engine
DatawireЃКAmbassador project
ШЛКѓвЛаЉЦфЫћЭтЮЇжЇГж, ДгДњТыжаПДЕНЕФ:
eureka
consul
etcd v3: етИіЛЙдкељжДжа,зїЮЊetcdЕФМсЖЈгЕЛЄеп, ЮвЖдДЫБЃГжУмЧаЙизЂ
ДцдкЮЪЬт
IstioБЯОЙФПЧАВХЪЧ0.2.2 pre releaseАцБОЃЌБЯОЙВХГіРДЫФИідТЃЌвђДЫЛЙЪЧДцдкДѓСПЕФЮЪЬтЃЌМЏжаБэЯжЮЊЃК
жЛжЇГжk8sЃЌЖјЧввЊЧѓk8s 1.7.4+ЃЌвђЮЊЪЙгУЕНk8sЕФ CustomResourceDefinitions
адФмНЯЕЭЃЌДгФПЧАЕФВтЪдЧщПіПДЃЌ0.1АцБОКмдуИтЃЌ0.2АцБОгаИФЩЦ
КмЖрЙІФмЩаЮДЭъГЩ
ИјДѓМвЕФНЈвщЃКПЩвдУмЧаЙизЂIstioЕФЖЏЯђЃЌЬсЧАзіКУММЪѕДЂБИЁЃЕЋЪЧЃЌзюЦ№ТыдкФъЕзЕФ1.0АцБОГіРДжЎЧАЃЌБ№МБзХЩЯЩњВњЛЗОГЁЃ
Нсгя
ИааЛДѓМвдкНёЬьВЮгыетДЮЕФIstioЗжЯэЃЌгЩгкЪБМфгаЯоЃЌКмЖрЯИНкЮоЗЈдкНёЬьИјДѓМвОЁЧщеЙПЊЁЃШчЙћДѓМвЖд
Istio ИааЫШЄЃЌПЩвджЎКѓздаафЏРР Istio ЕФЙйЗНЭјеОЃЌЮввВдЄЦкЛсдкжЎКѓТНТНајајЕФИјГіIstioЯрЙиЕФЮФеТКЭЗжЯэЁЃ
ШЋЬьКђОлНЙIaaS/PaaS/SaaSзюаТММЪѕЖЏЬЌЃЌЩюЖШЭкОђММЪѕДѓПЇЕквЛЪжЪЕМљЃЌМАЪБЭЦЫЭдЦаавЕжиДѓаТЮХЃЌвЛМќЙизЂЃЌзмРРЙњФкЭтдЦМЦЫуДѓЪЦЃЁ
ЪВУДЪЧService MeshЃП
Service MeshЪЧзЈгУЕФЛљДЁЩшЪЉВуЁЃ
ЧсСПМЖИпадФмЭјТчДњРэЁЃ
ЬсЙЉАВШЋЕФЁЂПьЫйЕФЁЂПЩППЕиЗўЮёМфЭЈбЖЁЃ
гыЪЕМЪгІгУВПЪ№вЛЦ№ЕЋЖдгІгУЪЧЭИУїЕФЁЃ
Service MeshФмзіЪВУДЃП
ЬсЙЉШлЖЯЛњжЦЃЈcircuit-breakingЃЉЁЃ
ЬсЙЉИажЊбгГйЕФИКдиОљКтЃЈlatency-awareload balancingЃЉЁЃ
зюжевЛжТЕФЗўЮёЗЂЯжЃЈservice discoveryЃЉЁЃ
СЌНгжиЪдЃЈretriesЃЉМАжежЙЃЈdeadlinesЃЉЁЃ
ЙмРэЮЂЗўЮёКЭдЦдЩњгІгУЭЈбЖЕФИДдгадЃЌШЗБЃПЩППЕиНЛИЖгІгУЧыЧѓЁЃ
Service MeshЪЧБивЊЕФТ№ЃПетПЩФмУЛгавЛИіОјЖдЕФД№АИЃЌЕЋЪЧ:
Service MeshПЩЪЙЕУПьЫйзЊЯђЮЂЗўЮёЛђепдЦдЩњгІгУЁЃ
Service MeshвдвЛжжздШЛЕФЛњжЦРЉеЙгІгУИКдиЃЌНтОіЗжВМЪНЯЕЭГВЛПЩБмУтЕФВПЗжЪЇАмЃЌВЖзНИпЖШЖЏЬЌЗжВМЪНЯЕЭГЕФБфЛЏЁЃ
ЭъШЋНтёюгкгІгУЁЃ
вЕНчгаФФаЉService MeshВњЦЗЃП
BuoyantЕФlinkerdЃЌЛљгкTwitterЕФFingleЃЌГЄЦкЕФЪЕМЪВњЯпдЫааОбщМАбщжЄЃЌжЇГжKubernetesЁЂDC/OSШнЦїЙмРэЦНЬЈЃЌвВЪЧCNCFЙйЗНжЇГжЕФЯюФПжЎвЛЁЃ
LyftЕФEnvoyЃЌ7ВуДњРэМАЭЈаХзмЯпЃЌжЇГж7ВуHTTPТЗгЩЁЂTLSЁЂgRPCЁЂЗўЮёЗЂЯжвдМАНЁПЕМрВтЕШЁЃ
IBMЁЂGoogleЁЂLyftжЇГжЕФIstioЃЌвЛИіПЊдДЕФЮЂЗўЮёСЌНгЁЂЙмРэЦНЬЈвдМАИјЮЂЗўЮёЬсЙЉАВШЋЙмРэЃЌжЇГжKubernetesЁЂMesosЕШШнЦїЙмРэЙЄОпЃЌЦфЕзВувРРЕгкEnvoyЁЃ
ЪВУДЪЧlinkerdЃП
ЮЊдЦдЩњгІгУЬсЙЉЕЏадЕФService MeshЁЃ
ЭИУїИпадФмЭјТчДњРэЁЃ
ЬсЙЉЗўЮёЗЂЯжЛњжЦЁЂЖЏЬЌТЗгЩЁЂДэЮѓДІРэЛњжЦМАгІгУдЫааЪБПЩЪгЛЏЁЃ
linkerdЕФЬиадЃК
ПьЫйЁЂЧсСПМЖЁЂИпадФмЁЃ
УПУывдзюаЁЕФЪБбгМАИКдиДІРэЭђМЖЧыЧѓЁЃ
взгкЫЎЦНРЉеЙЁЃ
жЇГжШЮвтПЊЗЂгябдМАШЮвтЛЗОГЁЃ
ЬсЙЉЛљгкИажЊЪБбгЕФИКдиОљКтЁЃ
ЭЈЙ§ЪЕЪБадФмЪ§ОнЗжЗЂЧыЧѓЁЃ
гЩгкlinkerdЙЄзїгкRPCВуЃЌПЩИљОнЪЕЪБЙлВтЕНЕФRPCбгГйЁЂвЊДІРэЧыЧѓЖгСаДѓаЁОіЖЈШчКЮЗжЗЂЧыЧѓЃЌгХгкДЋЭГЦєЗЂЪНИКдиОљКтЫуЗЈШчLRUЁЂTCPЛюЖЏЧщПіЕШЁЃ
ЬсЙЉЖржжИКдиОљКтЫуЗЈШчЃКPower of Two Choices (P2C): Least LoadedЁЂPower
of Two Choices: Peak EWMAЁЂAperture: Least LoadedЁЂHeap:
Least LoadedвдМАRound-RobinЁЃ
дЫааЪБСїСПТЗгЩЁЃ
ЭЈЙ§ЬиЖЈHTTPЭЗНјааPer-RequestМЖБ№ТЗгЩЁЃ
ЖЏЬЌаоИФdtabЙцдђЪЕЯжСїСПЧЈвЦЁЂРЖТЬВПЪ№ЁЂН№ЫПШИВПЪ№ЁЂПчЪ§ОнжааФfailoverЕШЁЃ
ШлЖЯЛњжЦЁЃ
Fail Fast ЁЊ ЛсЛАЧ§ЖЏЕФШлЖЯЦїЁЃ
Failure Accrual ЁЊ ЧыЧѓЧ§ЖЏЕФШлЖЯЦїЁЃ
ВхШыЪНЗўЮёЗЂЯжЁЃ
жЇГжИїжжЗўЮёЗЂЯжЛњжЦШчЃКЛљгкЮФМўЃЈFile-basedЃЉЃЌZookeeperЃЌConsulМАKubernetesЁЃ
жЇГжЖржжавщЃКHTTP/1.1ЁЂHTTP/2ЁЂgRPCЁЂThriftЁЂMuxЁЃ
ОЙ§ВњЯпВтЪдМАбщжЄЁЃ
linkerdЪѕгяЃК
<pre class="prettyprint"
style="box-sizing: border-box; overflow: hidden;
font-family: Menlo, Monaco, Consolas, "Courier
New", monospace; font-size: 14px; display: block;
padding: 16px; margin: 0px 0px 10px; line-height:
20px; color: rgb(51, 51, 51); word-break: break-all;
word-wrap: break-word; background-color: rgb(247,
247, 247); border: none; border-radius: 3px; font-style:
normal; font-variant-ligatures: normal; font-variant-caps:
normal; font-weight: 400; letter-spacing: normal;
orphans: 2; text-align: start; text-indent: 0px; text-transform:
none; widows: 2; word-spacing: 0px; -webkit-text-stroke-width:
0px; text-decoration-style: initial; text-decoration-color:
initial;">
########################
A basic service mesh for internal linkerd config.
This config contains an
outgoing router that proxies requests from local applications
to the linkerd
running on the destination host and an incoming router
that reverse-proxies
incoming requests to the application instance running
on the local host.
###########################
admin:
port: 9990
namers:
kind: io.l5d.consul
host: 127.0.0.1
port: 8500
includeTag: false
setHost: false
kind: io.l5d.rewrite
prefix: /srv
pattern: "/{service}"
name: ЁА/srv/{service}"
routers:
protocol: http
identifier:
kind: io.l5d.path
segments: 1
label: routerA_outgoing
dtab: |
/srv => /#/io.l5d.consul/dc;
/svc => /#/srv;
httpAccessLog: /alloc/logs/access_routerA.log
servers:
port: 8080
ip: 0.0.0.0
protocol: http
label: outgoing
dtab: |
/consul => /#/io.l5d.consul/dc;
/svc => /$/io.buoyant.http.subdomainOfPfx/svc.consul/consul;
httpAccessLog: /alloc/logs/access_outgoing.log
servers:
port: 80
ip: 0.0.0.0
interpreter:
kind: default
transformers:
Instead of sending the request directly to the destination,
send it to
the linkerd (listening on port 81) running on the
destination host.
kind: io.l5d.port
port: 81
protocol: http
label: incoming
dtab: |
/consul => /#/io.l5d.consul/dc;
/svc => /$/io.buoyant.http.subdomainOfPfx/svc.consul/consul;
servers:
port: 81
ip: 0.0.0.0
interpreter:
kind: default
transformers:
Instead of sending the request to a random destination
instance, send it
only to instances running on localhost.
telemetry:
kind: io.l5d.recentRequests
sampleRate: 1.0
kind: io.l5d.prometheus
usage:
enabled: false
</pre>
RouterЃКlinkerdХфжУБиаыЖЈвхrouterФЃПщЃЌПЩвдЖЈвхЖрИіrouterЃЌЦфЫќАќРЈЗўЮёЫљЪЙгУавщProtocolЁЂIdentifierЁЂTransformerЁЂServerЁЂDtabЁЂClientЁЂServiceвдМАInterpreterЁЃ
IdentifierЃКгУгкИјЧыЧѓИГжЕТпМУћзжЃЈlogical nameЃЉЛђепГЩТЗОЖЃЈpathЃЉЃЌГЃгУЕФIdentifierШчЃКio.l5d.methodAndHostЃЌio.l5d.pathЃЌio.l5d.headerЃЌio.l5d.header.tokenКЭio.l5d.staticЃЌР§ШчIdentiferЃКio.l5d.header.tokenНЋGET
http://example/helloИГжЕТпМУћзж/svc/exampleЁЃПЩвдПЊЗЂздЖЈжЦЕФIndentifierВхМўЁЃИќЖрВЮПМhttps://linkerd.io/config/1.1.
... iers.
Namer: ЖЈвхШчКЮНЋПЭЛЇЖЫУћзжКЭецЪЕЕижЗНјааАѓЖЈЃЌБОжЪЩЯЪЧШчКЮЭЈЙ§ЗўЮёЗЂЯжЯЕЭГНјааЗўЮёЗЂЯжЃЌГЃгУNamerШчЃКio.l5d.fsЃЌio.l5d.consulЃЌio.l5d.k8sЃЌio.l5d.marathonКЭ
io.l5d.rewriteЃЌИќЖрВЮПМhttps://linkerd.io/config/1.1.
... amersЁЃ
InterpreterЃКОіЖЈШчКЮНтЮіnamer, ГЃгУШчЃКdefault, io.l5d.namerd,
io.l5d.namerd.http, io.l5d.meshКЭio.l5d.fsЃЌИќЖрВЮПМhttps://linkerd.io/config/1.1.
... reterЁЃ
TransformerЃКИљОнInterpreterШчКЮзЊЛЛвбНтЮіЕФЕижЗЃЌTransformerвдГіЯжЕФЫГађЩњаЇЃЌШчЃКio.l5d.localhostЃЌio.l5d.specificHostЃЌio.l5d.portЃЌio.l5d.k8s.daemonsetЃЌio.l5d.k8s.localnodeЃЌio.l5d.replaceКЭio.l5d.constЃЌИќЖрВЮПМhttps://linkerd.io/config/1.1.
... ormerЁЃ
Delegation TableЃЈa.k.a. DtabЃЉЃКЖЈвхШчКЮАбЗўЮёУћзжЃЈservice nameЃЉЃЈТпМУћзжЃЉзЊЛЛЮЊПЭЛЇЖЫУћзжЃЈclient
nameЃЉЃЌ ПЭЛЇЖЫУћзжЖдгІгУгкЗўЮёЗЂЯжЬѕФПЃЌЗўЮёЗЂЯжЙЄОпИљОнетИіЬѕФПШчКЮЗЂЯжЗўЮёЃЌЦфБиаывд/$Лђеп/#ДђЭЗЃЌШч/#/io.l5d.consul/dc/productЁЃ
linkerdШчКЮДІРэгІгУЧыЧѓЃП
дкЯИСФlinkerdШчКЮДІРэгІгУЧыЧѓжЎЧАЃЌЮвУЧРДПДПДlinkerdЙйЗНИјГіЕФЪ§ОнДІРэСїГЬЭМЁЃ
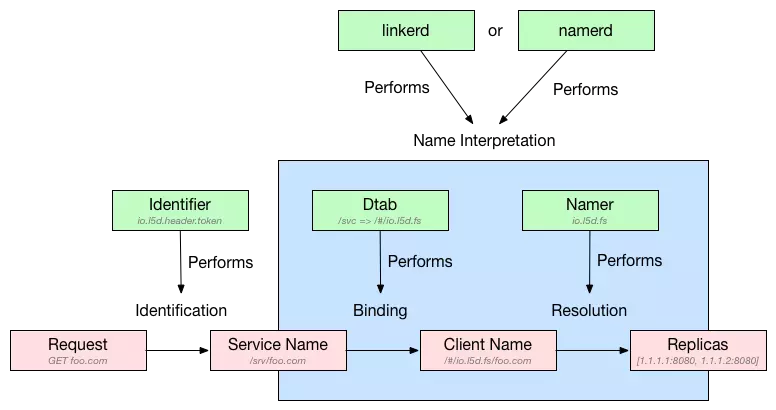
ДгЭМжаЮвУЧПЩвдАбећИіСїГЬЗжНтЮЊ4ИіжївЊВНжш:
Identification: АбЪЕМЪгІгУЧыЧѓШчhttp://foo.comЪЕМЪЮЊGET foo.comзЊЛЛЮЊТпМУћзжЃЈlogical
nameЃЉЛђЗўЮёУћзжЃЈservice nameЃЉЃЌОпЬхзЊЛЛЙцдђгЩIdentifierОіЖЈЃЌlinkerdЬсЙЉЖржжIdentifierВЂИљОнЪЕМЪашЧѓбЁдёЪЙгУЃЌШчЭМжаIdentifierЮЊio.l5d.header.tokenНЋGET
foo.comзЊЛЛЮЊ/svc/foo.comЁЃ
BindingЃКдкIdentificationЭъГЩКѓЃЌDtabПЊЪМЕЧГЁЃЌНЋВњЩњЕФЗўЮёУћзжИњПЭЛЇЖЫУћзжАѓЖЈЦ№РДЃЌШчКЮАѓЖЈШЁОігкDtabЙцдђШчКЮЩшжУЃЌШчЭМжаЫљЪОDtabЃЌдђНЋ/svc/foo.comАѓЖЈЮЊ/#/io.l5d.fs/foo.comЁЃ
ResolutionЃКМДЪЙBindingЭъГЩКѓЃЌДЫЪБlinkerdШдШЛЮДФмНЋЧыЧѓзЊЗЂИјКѓЖЫЗўЮёЃЌЪЕМЪЩЯЛЙВЛжЊЕРПЭЛЇЖЫУћзж/#/io.l5d.fs/foo.comОпЬхДњБэЪВУДЃЌЖјResolutionдђНЋПЭЛЇЖЫУћзжзЊЛЛЮЊецЪЕЗўЮёЕижЗЃЌIPЕижЗвдМАЖЫПкЁЃзЊЛЛТпМгЩжИЖЈЕФNamerРДШЗЖЈЃЌВЛЭЌЕФNamerзЊЛЛТпМВЛвЛбљЃЌШєNamerЮЊio.l5d.consulдђВщевConsul
Catalog APIЛёШЁIPЕижЗКЭЖЫПкаХЯЂЃЌЖјЭМжаNamerЮЊio.l5d.fsЃЌFile-basedЕФNamerЃЌlinkerdНЋЖСШЁУћЮЊfoo.comЕФБОЕиЮФМўЃЌЮФМўОпЬхЮЛжУгЩХфжУЫљОіЖЈЃЌИУЮФМўЛсАќКЌЭМжаЕФ2ЬѕМЧТМ1.1.1.1:8080КЭ1.1.1.2:8080ЃЌШЛКѓЗЕЛиЩЯЪі2ЬѕМЧТМЁЃ
LoadbalancingЃКвЛЕЉЭъГЩResolutionЃЌевЕНецЪЕЕФЗўЮёЕижЗЃЌШЛКѓlinkerdЛсИљОнЧАУцЫљЪіХфжУЕФИКдиОљКтЫуЗЈбЁШЁвЛЗўЮёЕижЗЬсЙЉЗўЮёЁЃ
жСДЫЃЌlinkerdвбЭъГЩШчКЮДІРэгІгУЧыЧѓЃЌЯТУцЪЧвЛИібнЯАШчКЮДгЗўЮёУћзжЕНецЪЕЕижЗзЊЛЛЕФР§згЁЃ
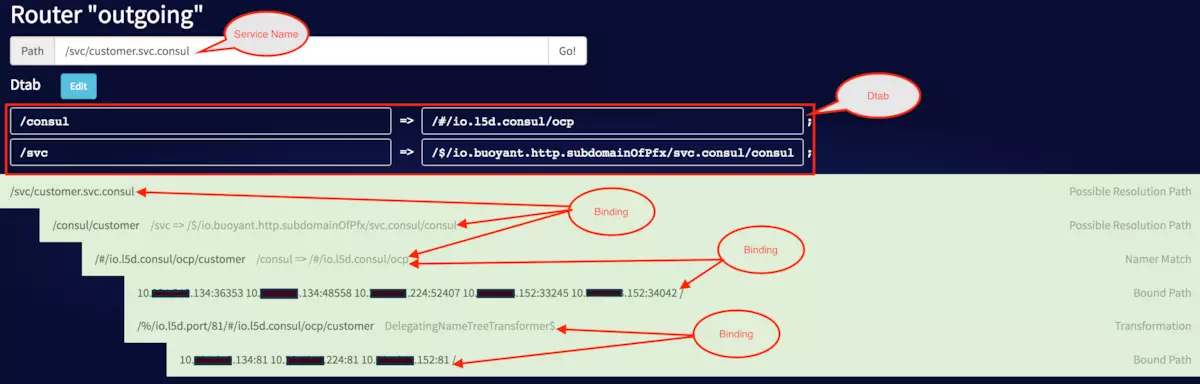
МђЕЅDemo
1.вдhostФЃЪНВПЪ№linkerdЁЃ
2.ДДНЈЗўЮёcustomerКЭproductЃЌcustomerЛсИњproductНјааЭЈбЖВЂЗЕЛивЛаЉаХЯЂЃЌСНепЖМвдШнЦїЕФЗНЪНдЫааЁЃ
3.зЂВсЗўЮёcustomerКЭproductЕНConsulЁЃ
4.ЭЈЙ§linkerdЗУЮЪЗўЮёcustomerЃЌcurl -s -H
ЁАHost: customer.svc.consulЁБ 10.xx.xx.199/productЛсЪфГіШчЯТаХЯЂЃК

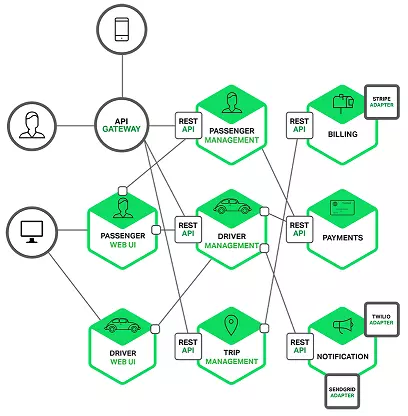
ЗўЮёМмЙЙЪЧЖд Moli
1. НЋвЕЮёВ№ЗжЮЊвЛИіИіЖРСЂЕФЗўЮёЁЃ
2. ЗўЮёМфЭЈЙ§ REST API РДНЋЗўЮёБЉТЖГіШЅЃЌЭЌЪБДг ЯћКФЗўЮёAPI РДЛёШЁЦфЫћФЃПщЕФЗўЮёЁЃ
гЩ ЁЖThe Art of ScalabilityЁЗ жаЕФ Scale Cube 3D ФЃаЭРДеЙЪОЃК
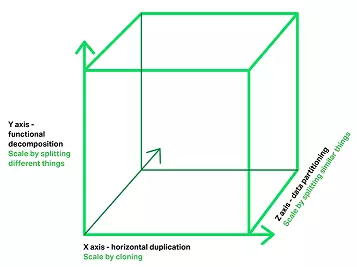
1. ЮЂЗўЮёМмЙЙЗЖЪНЖдгІ Y жсЁЃ
2. XжсгЩИКдиОљКтЦїКѓЖЫдЫааЕФЖрИігІгУИББОзщГЩЁЃ
3. ZжсЃЈЪ§ОнЗжИюЃЉНЋашЧѓТЗгЩЕНЯрЙиЗўЮё
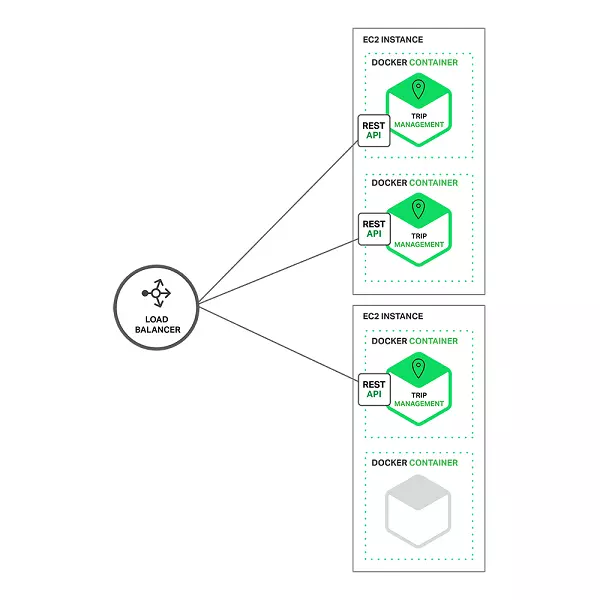
гІгУЭЈГЃЪЙгУетШ§жжВЛЭЌРраЭЕФРЉеЙЃК
Y жсРЉеЙНЋгІгУЗжНтЮЊ ЯТЭМ ЫљЪОЕФЮЂЗўЮёЃК
дЫааЪБЃЌааГЬЙмРэЗўЮёАќРЈЖрИіЗўЮёЪЕР§ЃЌУПИіЗўЮёЪЕР§ЖМЪЧвЛИі Docker ШнЦїЁЃ
ЮЊСЫЪЕЯжИпПЩгУадЃЌетаЉШнЦїдЫаадкЖрИідЦащФтЛњЩЯЁЃ
дкгІгУЪЕР§ЧАУцЪЧ NGINX етбљЕФИКдиОљКтЃЌНЋЧыЧѓЗжЗЂИјШЋВПЪЕР§ЁЃ
ИКдиОљКтвВПЩвдДІРэЛКДцЁЂЗУЮЪПижЦЁЂAPI ВтСПКЭМрПиЕШЁЃ
ЮЂЗўЮёМмЙЙЗЖЪНЖдгІгУКЭЪ§ОнПтЕФЙиЯЕгАЯьОоДѓЁЃ
УПИіЗўЮёЖМгаздЩэЕФЪ§ОнПтМЦЛЎЃЌЖјВЛгыЦфЫћЗўЮёЙВЯэЭЌвЛИіЪ§ОнПтЁЃ
вЛЗНУцЃЌРрЫЦЦѓвЕМЖЪ§ОнФЃаЭЁЃ
ЭЌЪБЃЌвВЕМжТВПЗжЪ§ОнЕФжиИДЁЃ
ЮЊУПИіЗўЮёЬсЙЉЕЅИіЕФЪ§ОнПтМЦЛЎЗЧГЃБивЊЁЃБЃжЄЫЩЩЂёюКЯЁЃ
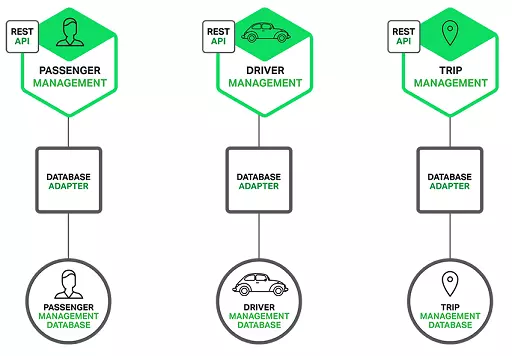
УПИіЗўЮёЖМгаЦфздМКЕФЪ§ОнПтЁЃ
ДЫЭтЃЌЕЅИіЗўЮёПЩвдЪЙгУЗћКЯздМКашвЊЕФЬиЖЈРраЭЕФЪ§ОнПтЃЌМДЖргябдвЛжТадМмЙЙЁЃ
Р§ШчЃЌМнЪЛЙмРэЗўЮёБиаыЪЙгУИпаЇжЇГжЕиРэЮЛжУЧыЧѓЕФЪ§ОнПтЁЃ
ЮЂЗўЮёМмЙЙЕФКУДІЃК
1. ЭЈЙ§ЗжНтОоДѓЕЅЬхгІгУЮЊЖрИіЗўЮёЗНЗЈНтОіСЫИДдгадЮЪЬтЁЃдкЙІФмадВЛБфЕФЧщПіЯТЃЌгІгУБЛЗжНтЮЊЖрИі
ПЩЙмРэЕФЗжжЇЛђЗўЮёЁЃУПИіЗўЮёЖМгавЛИігУ RPC -- ЛђЯћЯЂЧ§ЖЏ API ЖЈвхЧхГўЕФБпНчЁЃ
ЕЅИіЗўЮёКмШнвзПЊЗЂЁЂРэНтКЭЮЌЛЄЁЃ
2. ЮЂЗўЮёМмЙЙЪЙЕУУПИіЗўЮёЖМПЩвдгазЈУХПЊЗЂЭХЖгРДПЊЗЂЁЃПЊЗЂЭХЖгздгЩбЁдёПЊЗЂММЪѕЃЌЬсЙЉ API ЗўЮёЁЃ
етжжздгЩвтЮЖзХПЊЗЂепВЛашвЊБЛЦШЪЙгУФГЯюФППЊЪМЪБВЩгУЕФЙ§ЪБММЪѕЃЌПЩвдбЁдёЯждкЕФММЪѕЁЃЩѕжСгкЃЌвђЮЊЗўЮёЖМЪЧЯрЖдМђЕЅЃЌМДЪЙгУЯждкММЪѕжиаДвдЧАДњТывВВЛЪЧКмРЇФбЕФЪТЧщЁЃ
3. ЮЂЗўЮёМмЙЙФЃЪНЪЙЕУУПИіЮЂЗўЮёЦїЖРСЂВПЪ№ЃЌВЛашвЊаЕїЦфЫћЗўЮёВПЪ№ЁЃПЩМгПьВПЪ№ЫйЖШЃЌ
ЪЧЕФ ГжајЛЏВПЪ№ГЩЮЊПЩФмЁЃ
4. ЮЂЗўЮёМмЙЙФЃЪНЪЙЕУУПИіЗўЮёЖРСЂРЉеЙЁЃ
ЮЂЗўЮёЕФФПЕФЪЧгааЇЕФВ№ЗжгІгУЃЌЪЕЯжУєНнПЊЗЂКЭВПЪ№ЁЃ
ЮЂЗўЮёМмЙЙЕФВЛзу
1. "there are no silver bullets" ЁАЮЂЗўЮёЁБЧПЕїСЫЗўЮёДѓаЁЁЃ
ЮЂЗўЮёЕФФПЕФЪЧгааЇЕФВ№ЗжгІгУЃЌЪЕЯжУєНнПЊЗЂКЭВПЪ№ЁЃ
2. ЮЂЗўЮёгІгУЪЧЗжВМЪНЯЕЭГЃЌЙЬгаЕФИДдгадЃЌашвЊдк RPC Лђеп ЯћЯЂДЋЕнжЎМфбЁдёВЂЭъГЩНјГЬМфЭЈбЖЛњжЦЁЃ
ЕЋЪЧЃЌПЊЗЂепБиаыаДДњТыРДДІРэЯћЯЂДЋЕнжаЫйЖШЙ§Т§ЛђепВЛПЩФмЕШОжВПЪЇаЇЮЪЬтЁЃ
ЕЋВЛЪЧЪВУДФбЪТЃЌЯрЖдгкЕЅЬхЪНгІгУжаЭЈЙ§гябдВуМЖЕФЗНЗЈЛђепНјГЬЕїгУЃЌЮЂЗўЮёЯТетжжММЪѕИќИДдгвЛаЉЁЃ
3. вЛИіЙигкЮЂЗўЮёЕФЬєеНРДздгкЗжЧјЕФЪ§ОнПтМмЙЙЁЃЭЌЪБИќаТЖрИівЕЮёжїЬхЕФЪТЮёКмЦеБщЁЃ
етжжЪТЮёЖдгкЕЅЬхЪНгІгУРДЫЕКмШнвзЃЌвђЮЊжЛгавЛИіЪ§ОнПтЁЃ
дкЮЂЗўЮёМмЙЙгІгУжаЃЌашвЊИќаТВЛЭЌЗўЮёЫљЪЙгУЕФВЛЭЌЕФЪ§ОнПтЁЃ
ВЛНіНіЪЧ CAP РэТлЃЌЕБЧАИпРЉеЙЕФ NoSql Ъ§ОнПтКЭЯћЯЂДЋЕнжаМфМўВЂВЛжЇГжетвЛашЧѓЁЃашвЊвЛИізюжевЛжТадЕФЗНЗЈЁЃ
ВтЪдЛљгкЮЂЗўЮёМмЙЙЕФгІгУвВКмИДдгЁЃ
ЮЂЗўЮёМмЙЙФЃЪНгІгУЕФИФБфЛсВЈМАЖрИіЗўЮёЁЃавдЫЕФЪЧЃЌаэЖрИФБфвЛАужЛгАЯьвЛИіЗўЮёЁЃ
ВПЪ№вЛИіЮЂЗўЮёгІгУвВКмИДдгЃЌвЛИіЕЅЬхгІгУашвЊдкИДдгОљКтЦїКѓУцВПЪ№ИјздЕФЗўЮёЦїОЭКУСЫЁЃ
УПИігІгУЪЕР§ашвЊХфжУжюШчЪ§ОнПтКЭЯћЯЂжаМфМўЕШЛљДЁЗўЮёЁЃ
ЯрБШжЎЯТЃЌвЛИіЮЂЗўЮёгІгУвЛАугЩДѓХњЗўЮёЙЙГЩЁЃУПИігІгУЪЕР§ЪЧашвЊХфжУжюШчЪ§ОнПтКЭЯћЯЂжаМфМўЕШЛљДЁЗўЮёЁЃ
КмЖрЕФЗўЮёЪЕР§ЃЌОЭаЮГЩДѓСПашвЊХфжУЁЂВПЪ№ЁЂРЉеЙКЭМрПиЕФВПЗжЁЃ
Г§ДЫжЎЭтЃЌашвЊЭъГЩвЛИіЗўЮёЗЂЯжЛњжЦЃЌвдгУРДЗЂЯжгыЫќЭЈбЖЗўЮёЕФЕижЗЃЈАќРЈЗўЮёЦїЕижЗКЭЖЫПкЃЉ
вдгУРДЗЂЯжгыЫќЭЈбЖЗўЮёЕФЕижЗЃЈАќРЈЗўЮёЦїЕижЗКЭЖЫПкЃЉЁЃ
ГЩЙІВПЪ№вЛИіЮЂЗўЮёгІгУашвЊПЊЗЂепгазуЙЛЕФПижЦВПЪ№ЗНЗЈЃЌВЂИпЖШздЖЏЛЏЁЃ
здЖЏЛЏЕФЗНЗЈжЎвЛЪЧЪЙгУ ЦЉШч Cloud Foundry етбљЕФ PaaS ЗўЮёЁЃШУПЊЗЂепЧсЫЩВПЪ№КЭЙмРэЮЂЗўЮёЁЃЃЌШУЫћУЧ
ЮоашЮЊЛёШЁВЂХфжУ IT зЪдДЁЃХфжУ PaaS ЕФЯЕЭГКЭЭјТчзЈМвПЩвдВЩгУзюМбЪЕМљКЭВпТдРДМђЛЏетаЉЮЪЬтЁЃ
СэвЛИіздЖЏВПЪ№ЮЂЗўЮёгІгУЕФЗНЗЈЪЧПЊЗЂздМКЕФЛљДЁ PaaS ЯЕЭГЁЃ
ЭЈГЃЕФЦ№ВНЗНЪНЪЧ Mesos Лђ Kubernetes етбљЕФМЏШКЙмРэЗНАИЃЌХфКЯ Docker ЪЙгУЁЃ
зїЮЊвЛжжЛљгкШэМўЕФгІгУНЛИЖЗНЗЈЃЌ NGINX ФмЙЛЗНБуЕидкЮЂЗўЮёВуУцЬсЙЉ
1. ЛКГх
2. ШЈЯоПижЦ
3. APIЭГМЦ
4. МрПи
|









