| БрМЭЦМі: |
| БОЮФРДздгкЫбКќЃЌНщЩмSpring
CloudжаБШНЯгаДњБэадЕФЫФИізщМўЃЌДгЙІФмЁЂгІгУЕШВЛЭЌЗНУцНјааШЋУцЯИжТЕФНщЩмЁЃ |
|
ЫцзХЮЂЗўЮёММЪѕШеЧїГЩЪьЃЌдНРДдНЖрЕФЦѓвЕЪЙгУSpring CloudЙЙНЈЮЂЗўЮёМмЙЙЁЃEurekaзїЮЊSpring
CloudЮЂЗўЮёМмЙЙжаЕФзЂВсжааФЃЌАчбнзХживЊЕФНЧЩЋЁЃБОЮФНЋДгSpring CloudдДТыНЧЖШГіЗЂЃЌШУДѓМвФмЙЛСЫНтЕНЯрЙизщМўФкВПЕФдЫааЛњжЦЃЌДгЖјИќКУЕФЛиРЁПЊЗЂЕФСїГЬКЭХфжУЩЯЃЌЮЊгУЛЇЬсЙЉИќКУЕФЗНАИЁЃ
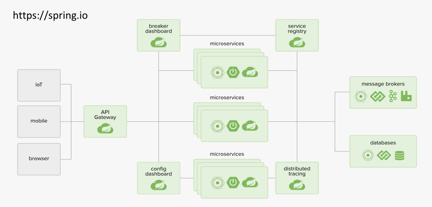
Spring CloudЬсЙЉСЫЮЂЗўЮёМмЙЙжаЕФжкЖрзщМўЃЌР§ШчAPIЭјЙиЁЂзЂВсжааФЁЂИКдиОљКтЁЂШлЖЯЯоСїЁЂЗўЮёзЗзйЁЃЯТЭМЪЧSpringЙйЗНИјГіЕФвЛИіРрЫЦгкSpring
CloudЮЂЗўЮёПђМмЕФНтОіЗНАИМмЙЙЭМЁЃ
Spring Cloud Netflix Eureka
Spring CloudРяУцАќКЌжкЖрзщМўЃЌЕквЛИіашвЊНщЩмЕФзщМўОЭЪЧEurekaЁЃEurekaзїЮЊвЛИізЂВсжааФЃЌЦфКЫаФЙІФмЪЧБЃДцзЂВсаХЯЂЃЌОЭЯёЪжЛњЕФЕчЛАВОвЛбљЃЌдкЕчЛАВОжаЛсБЃДцзХУПвЛИіШЫЕФСЊЯЕЗНЪНЁЃЭЌЪБЃЌEurekaЛсАбБЃДцЕФетаЉаХЯЂЗжЯэИјУПвЛИіПЭЛЇЖЫЃЌвдБугкПЭЛЇЖЫЯђЗўЮёЦїЗЂЦ№ЕїгУЁЃЫљвдЛсгавЛИізЂВсЁЂајдМЁЂШЁЯћКЭФкВПЕФЬоГ§ЛњжЦЁЃ
ЯТЭМЪЧNetflix Eureka GithubЙйЗНИјГіЕФМмЙЙЭМЃЌБШНЯживЊЕФВПЗжЪЧМ§ЭЗЕФзпЯђЁЃДгзѓЯђгвПДЃЌзюзѓБпЪЧEureka
ClientЃЌПЩвдПДЕНEureka ClientИњEureka ServerжЎМфЭЈаХАќРЈСЫзЂВсЪТМўЁЂајдМЪТМўЁЂШЁЯћЪТМўЃЌЭЌЪБEureka
ClientвВЛсДгEureka ServerЕБжаЛёШЁЕНЯрЙиЕФзЂВсаХЯЂЃЌСэЭтServerгыServerжЎМфДцдкИДжЦЕФЛњжЦЁЃ
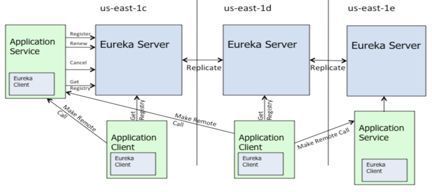
ЯТЭМжаНщЩмЕФЪЧзЂВсЪТМўШчКЮЗЂЩњЕФЁЃРЖЩЋЕФаЁаІСГДњБэЕФЪЧаТClientЦєЖЏжЎКѓЃЌаХЯЂЪЧШчКЮБЃДцЕНEureka
ServerжаЕФЁЃЭЌЪБЃЌEureka ServerгжзіСЫФФаЉЪТЧщЁЃПЩвдПДЕНЃЌEureka ServerИјЧАЖЫЬсЙЉСЫвЛИіAPIЃЌетИіAPIЪЧЭъГЩзЂВсЧыЧѓЁЃЪзЯШЃЌEureka
ServerжаБЃДцаХЯЂЕФЪ§ОнНсЙЙЪЧЫЋВуMAPЁЃЕБClientЗЂЦ№зЂВсЧыЧѓЪБЃЌетИіЪЕР§ЪзЯШвЊзіЕФЪТЧщЪЧБЃДцЕНФкВПEurekaжаЕФЪ§ОнНсЙЙЁЃЭЌЪБЃЌEureka
ServerЕБжаЛсЮЌЛЄвЛИізюНќИФБфЕФЖгСаЃЌЮЊЪВУДЛсДцдкетбљЕФЖгСаЃПвђЮЊEureka ClientЯђEureka
ServerЗЂЦ№ЭЌВНЪБЃЌЭЈГЃгаСНжжЗНЪНЁЃвЛжжЗНЪНЪЧРШЁШЋСПЕФаХЯЂЃЌУПвЛИіClientЖМЯыДгServerжаЛёШЁШЋСПЕФаХЯЂЃЌЕЋВЂВЛЪЧвЛДЮадЛёШЁЭъШЋСПаХЯЂжЎКѓЃЌаХЯЂДЋЪфЕФЙ§ГЬећИіНсЪјСЫЁЃEureka
ClientЛЙЛсЖЈЦкЭЈЙ§КѓЬЈЕФЖЈЪБШЮЮёЃЌЯђEureka ServerЛёШЁдіСПЕФаХЯЂЃЌЖјетаЉдіСПаХЯЂЪ§ОнашвЊДгEureka
ServerЕБжаЮЌЛЄЕФЁЂзюНќИФБфЕФЖгСажаЛёШЁЁЃ
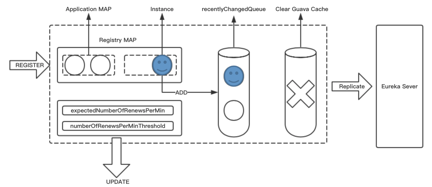
вђДЫЃЌЕБвЛИізЂВсЪТМўЕНРДжЎКѓЃЌГ§СЫЛсАбаХЯЂБЃДцЕНздЩэЕФЪ§ОнНсЙЙжаЃЌЭЌЪБЛЙЛсАбетаЉаХЯЂЗХжУЕНзюНќИФБфЕФЖгСаЕБжаЁЃ
ExpectedNumberOfRenewsPerMinКЭNumberOfRenewsPerMinThresholdетСНИіЪєадЪЧEureka
ServerжаЪЎЗжживЊЕФЪєадЁЃвђЮЊEureka ServerжаДцдквЛИіздЮвБЃЛЄЛњжЦЃЌдк15ЗжжгжЎФкФЌШЯЧщПіЯТЃЌуажЕЕЭгк85%НЋПЊЦєздЮвБЃЛЄЁЃЕБуажЕИпгк85%ЪБЃЌЯЕЭГЛсНјаавЛЯЕСаЕФЬоГ§ВйзїЃЌетИіЬоГ§жИЕФЪЧвЛИіClientЯђServerЗЂЩњзЂВсжЎКѓЃЌВЂУЛгаАДЪБЭъГЩајдМЙІФмЁЃServerЛсШЯЮЊетИідЖГЬЕФClientЛЕЫРЃЌашвЊАбЫќвЦГ§ЁЃИљОнЪВУДРДХаЖЯФиЃПОЭЪЧИљОнЩЯЪіСНИіЪєадРДзіуажЕЕФВЮПМЁЃ
ЭЌЪБЃЌвђЮЊEureka ServerжаЮЌЛЄзХвЛИіCacheЃЌЫљвдЕБвЛИіаХЯЂРДСйЪБЃЌдкБЃДцзХзюНќЖгСаЕФЭЌЪБЃЌЯЕЭГЛсЧхПеетИіGuava
CacheЃЌвВЛсАбетИіЪТМўИДжЦИјдЖЖЫЦфЫћЯрСкЕФEureka ServerЁЃ
ЩЯЪізЂВсЙ§ГЬжЛЪЧвЛИіЕЅвЛЕФВНжшЃЌВЂВЛЪЧЭъГЩвЛДЮзЂВсКѓОЭФмвЛДЮадНтОіЫљгаЮЪЬтЁЃетИіClientЛсЖЈЦкЕФЯђServerЗЂЦ№ЭЌВНЃЌФПЕФЪЧЮЊСЫЯђServerЖЈЦкЗЂГіЁАЮвЛЙЛюзХЃЌВЛвЊАбЮвЬоГ§ЁБЕФаХЯЂЁЃЭЈГЃФЌШЯЗЂЫЭЕФЦЕТЪЪЧ30УывЛДЮЃЌEureka
ClientЛсГжајЯђEureka ServerЗЂЦ№ЭЌВНЁЃЙигкЭЌВНЕФСїГЬЃЌДѓжТЩЯЪЧИљОнгУЛЇЕФЧыЧѓаХЯЂЃЌдкEureka
ServerЕФЪ§ОнНсЙЙжаевЕНИУДЮајдМЖдгІЕФEureka ClientЃЌЭЌЪБАбEureka ClientЖдгІЕФЪБМфНјааИќаТЁЃДгЯТЭМгвВрЕФдДДњТыПЩвдПДГіЃЌетжжИќаТжЛЪЧАбЖдгІЕФНкЕуШЁГіРДЃЌИќаТЕНЖдгІЕФЪБМфДСЁЃЭЌЪБЃЌдйАбетИіаХЯЂИДжЦИјЯрСкЕФEureka
ServerНкЕуЁЃ
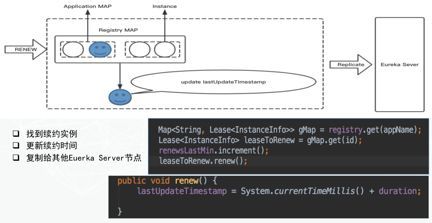
ЕБдЖГЬЕФЗўЮёШЗШЯЭЃжЙЃЌашвЊЖдЦфЗЂЫЭвЛДЮЪТМўЭЈжЊEureka ServerЃЌАбИУClientДгEureka
ServerжаЬоГ§ЃЌЖдгІЕФСїГЬЪЧдѕбљЕФФиЃПЦфЪЕИњзЂВсЕФТпМДѓЬхЯрЫЦЃЌвВЪЧДгЫЋВуЕФMAPЕБжаевЕНЖдгІЕФClientаХЯЂЃЌЭЌЪБАбClientаХЯЂЮЌЛЄЕНзюНќИФБфЕФЖгСаРяУцШЅЁЃетИізюНќИФБфЕФЖгСажаВЂВЛвтЮЖзХжЛДцдкаТдіЕФЃЌЭЌЪБвВДцдкЩОГ§ЕФЁЃвђЮЊЩОГ§КЭаТдіетСНИіЙ§ГЬДгEureka
ServerЕФНЧЖШРДПДЃЌЖМЪЧзюНќИФБфСЫЕФЪ§ОнНсЙЙФкВПЕФвЛаЉаХЯЂЁЃЭЌЪБЃЌвђЮЊдРДServerЕФНкЕуШчЙћЩйСЫвЛИіЃЌБиЖЈЛсЕМжТСНИіуажЕЕФЪєадЗЂЩњБфЛЏЃЌЫљвдвВЛсШЅИќаТетСНИіуажЕЕФЪєадЃЌзюКѓАбаХЯЂИДжЦИјЯрСкЕФEureka
ServerНкЕуЁЃ
Eureka ServerФкВПздЩэЬоГ§ЕФЛњжЦЪЧЪВУДЃПЪзЯШЃЌЩЯЮФжаЬсЕНдкEureka ServerжаДцдквЛИіздЮвБЃЛЄЕФИХФюЃЌздЮвБЃЛЄЕФИХФюПЩвдРэНтГЩЪВУДФиЃПМйЩшПЊЦєСЫздЮвБЃЛЄЃЌШчЙћEureka
ServerУЛгаЪеЕНEureka ClientЃЌФЧВЂВЛвтЮЖзХEureka ClientБОЩэвбОЛЕЫРСЫЁЃПЩФмЪЧгЩгкЭјТчдьГЩЕФЮЪЬтЃЌЖјУЛгаЪеЕНВПЗжИќаТЧыЧѓЁЃдЖЖЫЕФEureka
ClientЛЙдкСМКУЕФдЫаажаЁЃЫљвдЕБвдздЮвБЃЛЄПЊЦєЃЌЭЌЪБЛсгавЛИіуажЕЕФХаЖЯЃЌетИіуажЕЕФХаЖЯОЭЯрЕБгкЧАУцНщЩмЕФзЂВсЛђCancelЛњжЦЃЌEureka
ServerЛсШЅЖЈЪБИќаТетСНИіуажЕХаЖЯЁЃ
ОЙ§аЃбщжЎКѓЃЌЛсдкећИіФкВПЪ§ОнНсЙЙЃЌМДБЃДцЕФЫљгазЂВсаХЯЂЕФДІАбЪЕР§ЖМЛсШЅбЛЗвЛБщЃЌХаЖЯЪЧЗёЙ§ЦкЃЌУПвЛИіаЁдВШІДњБэЕФОЭЪЧвЛИіЙ§ЦкЕФЪЕР§ЃЌЭЌЪБФУЕНетаЉЪЕР§жЎКѓЃЌEureka
ServerЛсдйДЮМЦЫуетДЮгІИУЬоГ§ЖрЩйИіЗўЮёЁЃ
етРяУцгавЛИіЮЪЬтЃЌEureka ServerдйМЦЫуГіЪЎИіЪЕР§жЎКѓЃЌЪЧвЛДЮадЬоЕєЃЌЛЙЪЧАДееЫГађвЛИівЛИіЬоЕєЃПШчКЮБЃжЄУПвЛДЮЬоЕєЕФЪЕР§ЪЧЙЋЦНЕФФиЃПEureka
ServerЭЈЙ§ЯДХЦЫуЗЈЃЌРДБЃжЄУПвЛДЮЫцЛњФУЕНЕФИХТЪЪЧЯрЕШЕФЁЃДгЖјАбЪЕР§ДгЪ§ОнНсЙЙЕБжаЬоГ§ЕєЃЌЭЌЪБЗХЕНзюНќЕФБфИќЕФЖгСаЃЌШЛКѓНјааБЃДцЁЃетИіTaskЪЧЖЈЪБдкEureka
ServerКѓЬЈдЫааЕФЁЃ
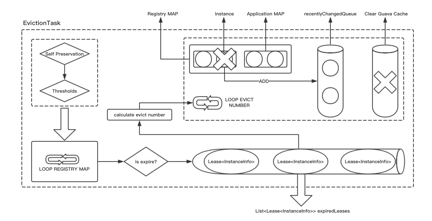
ЬоГ§ТпМЭМ
дкЩЯЮФЕФзЂВсКЭШЁЯћРяЖМЬсЕНСЫCacheЃЌвЊАбетИіCacheЧхПеЁЃФЧУДдкEureka ServerжаЃЌCacheЕФЪЕЯжЛњжЦЪЧЪВУДЃПEureka
ServerБОжЪЩЯЪЧгаСНВуЛКДцЛњжЦЕФЃЌетИіЩшЖЈвВБШНЯСщЛюЃЌгУЛЇПЩвдЭЈЙ§вЛИіВЮЪ§ШУЪЙгУепОіЖЈЪЧЗёПЊЦєЖўМЖЛКДцЁЃОЭЪЧЫЕЮвУЧПЩвдПЊЦєЖўМЖЛКДцЃЌвВПЩвдВЛПЊЦєЖўМЖЛКДцЁЃ
ЕквЛВуОЭЪЧЕквЛМЖЕФЛКДцЃЌБОжЪЩЯЪЧвЛИіGuava CacheЃЌЪЧДцдкЙ§ЦкЪБМфЕФЃЌетИіЙ§ЦкЪБМфЕФВЮЪ§ЪЧПЩвдЩшжУЕФЁЃЖўМЖЛКДцЪЧвЛИіHashmapЃЌБОжЪЩЯЪЧУЛгаЙ§ЦкЪЕР§ЪБМфЕФЁЃЦфЛњжЦЪЧЃКШчЙћЦєгУСЫЖўМЖЛКДцЃЌЫљгаЕФаХЯЂЛсЯШДгЖўМЖЛКДцЛёШЁЃЌШчЙћДгЖўМЖЛКДцЛёШЁВЛЕНЃЌдђЛсДгвЛМЖЛКДцЛёШЁЁЃШчЙћвЛМЖЛКДцЭЌбљЛёШЁВЛЕНЃЌгЩгкCacheДцдквЛИіloadЛњжЦЃЌЪЕЯжетИіздЖЈвхЕФloadжЎКѓЃЌЛсГіЯжCacheжаЛёШЁВЛЕНЪ§ОнМАгУЛЇЕФздЖЈвхааЮЊЃЌвђДЫдкдДТыжаЕФЪЕЯжЪЧЃЌЕБвЛМЖЛКДцвВЛёШЁВЛЕНаХЯЂЪБЃЌЛсдкБЃДцаХЯЂзюЭъећЕФЪ§ОнНсЙЙжаЕїШЁЁЃ

СэЭтКѓЬЈЛсЦєЖЏСэвЛЯюШЮЮёЃЌМДДгвЛМЖЛКДцЯђЖўМЖЛКДцЭЌВНЪ§ОнЁЃЮЊЪВУДЪЧДгвЛМЖЛКДцЯђЖўМЖЛКДцЭЌВНЃЌЖјВЛЪЧЖўМЖЛКДцЯђвЛМЖЛКДцЭЌВНФиЃПЪЧвђЮЊЖўМЖЛКДцЕФЪ§ОнгаПЩФмЛсБШвЛМЖЛКДцЕФЪ§ОнвЊЖрЁЃ
ЯТЭМЪЧДгClientЯђEureka ServerЛёШЁЪ§ОнЕФећЬхТпМЁЃЕБEureka ClientЦєЖЏЪБЃЌашвЊДгEureka
ServerЛёШЁШЋСПЕФаХЯЂЃЌЗХжУЕНEureka ClientБОЕиЁЃдкаХЯЂЭЌВНЕФЙ§ГЬжаБиШЛЛсУцСйСНИіЮЪЬтЃЌЕквЛИіЮЪЬтЪЧдіСПЭЌВНЛЙЪЧШЋСПЭЌВНЃПетШЁОігкЕБЪБЕФЪЕМЪЧщПіЃЌеыЖдВЛЭЌЕФЯжГЁзДПіЫљВЩШЁЕФЭЌВНЗНЪНЪЧВЛвЛбљЕФЁЃЕБEureka
ClientдкЭъГЩЦєЖЏЪБЃЌЕквЛДЮЭЈГЃЧщПіЯТНјааЕФЪЧШЋСПЕФЭЌВНЁЃШчЙћдіСПЭЌВНЪЇАмЃЌФЧУДЛсШЅРШЁНјааШЋСПЕФЭЌВНЁЃдкEureka
ServerжаЛсОпгавЛИіВЮЪ§ЃЌБэЪОЪЧЗёдкКѓЬЈЕФlogЕБжаЛсПДЕНдіСПгыШЋСПЕФЧјБ№ЁЃШчЙћетИіВЮЪ§ПЊЦєЃЌФЧвВЛсШЅРШЁШЋСПЕФЪ§ОнЁЃ
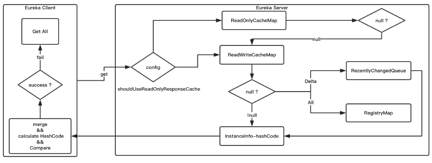
діСПаХЯЂЛёШЁЕФСїГЬЦфЪЕКмМђЕЅЃЌКѓЬЈЛсгавЛИіTaskЙІФмЖЈЦкЗЂЫЭвЛДЮЧыЧѓЃЌДгEureka ServerЕБжаЛёШЁЕНдіСПЕФаХЯЂЁЃетРяашвЊзЂвтЕФЪЧЃЌдкЩЯЮФжавВЬсЕНЙ§ЃЌдіСПЭЌВНЪЇАмЃЌРДЛёШЁШЋСПЁЃетИіЛЗНкЛсГіЯжвЛИіЮЪЬтЃЌЪВУДЧщПіЯТШЯЮЊдіСПЭЌВНЪЇАмФиЃПЛЙвдЩЯЭМЮЊР§ЃЌЭМжаеЙЪОСЫEureka
ClientКЭEureka ServerЕФвЛжТадhashаЃбщЁЃБШШчЃЌгУЛЇЕБЧАЕФEureka ServerжазЂВсаХЯЂЪЕР§гаЪЎИіЃЌЪЎИіEureka
ClientЖМЛсдкЕБЧАЕФEureka ServerаХЯЂЕБжаЁЃЖјетЪЎИіEureka ClientжаПЩФмЛсгаЦпИіЪЧЛЙдкЬсЙЉЗўЮёЕФЃЌдкУЛгаЬоГ§жЎЧАЃЌСэЭтШ§ИіЪЕР§вбОЛЕЫРСЫЃЌФЧУДЕБЧАЯдЪОЕФзДЬЌЪЧdownЁЃДЫЪБЃЌEureka
ServerЛсБЃГжвЛИіHashCodeЃЌетИіHashCodeЕФжЕОЭЪЧЦДНгзДЬЌЪЧupЕФИіЪ§вдМАзДЬЌЪЧdownЕФИіЪ§ЕФSpringBuilderЁЃ
ОпЬхЕФСїГЬЙ§ГЬЪЧЃЌЕБвЛИіEureka ClientдкЦєЖЏЪБЃЌЪзДЮЛёШЁШЋСПЃЌжБНгФУШЁШЋСПаХЯЂБЃДцЕНБОЕиЁЃЕБЛёШЁдіСПаХЯЂЪБЃЌдкEureka
ServerжаЛсГіЯжвЛИіВЮЪ§ЃЌетИіВЮЪ§ДњБэзХЪЧЗёПЊЦєЖўМЖЛКДцЁЃШчЙћEureka ServerетИіВЮЪ§ДњБэПЊЦєСЫЖўМЖЛКДцЃЌЛсДгHashMapЕБжаЛёШЁЪ§ОнЁЃШчЙћЛёШЁВЛЕНЪ§ОнЛсДгвЛМЖЛКДцНјааЛёШЁЭЌЪБАбетИіЪ§ОнЭЌВНЕНЖўМЖЛКДцВЂАбНсЙћЗЕЛиЕНEureka
ClientЁЃШчЙћвЛМЖЛКДцЛёШЁВЛЕНЃЌдђЛсДгЪ§ОнНсЙЙжаЛёШЁЁЃ
ЭЌЪБКѓЬЈЛсМЦЫуетДЮЛёШЁЭъЪ§ОнЕФHashCodeЃЌвВОЭЪЧЕБЧАEureka ServerЫљгаЪЕР§ЕФHashCodeжЕЃЌШЛКѓзїЮЊвЛИіЗЕЛиНсЙћЃЌЗЕЛиИјEureka
ClientЁЃетИіЪБКђEureka ClientШчЙћЪЧЕквЛДЮЦєЖЏЃЌФЧУДБОЕиЕФЪ§ОнЪЧПеЕФЁЃШчЙћЪЧдіСПЕФЧщПіЯТЃЌЧАЦкEureka
ClientвбОЛсДцдкДцСПЕФаХЯЂСЫЁЃДгEureka ServerЛёШЁЪ§ОнКѓЃЌБОЕиЕФЪ§ОнвЊЭъГЩвЛИіКЯВЂЕФЖЏзїЃЌКЯВЂЭъжЎКѓЃЌФУКЯВЂЕФНсЙћШЅАДееЯрЭЌЕФЗНЗЈЃЌетИіЗНЗЈОЭЪЧEureka
ServerЕФЗНЗЈЃЌШЅМЦЫуДЫЪБдкEureka ClientБОЕиЕФHashCodeЪЧЖрЩйЁЃ
ЕЋЩЯЪіЙ§ГЬДцдквЛИіВЛбЯНїЕФЕиЗНЃЌОЭЪЧгУЛЇЮоЗЈЕЅДПЭЈЙ§ЪЕР§ЕФИіЪ§РДХаЖЯДЫЪБClientБЃДцЕФаХЯЂгыEureka
ServerБЃДцЕФаХЯЂЪЧЗёЭъШЋвЛжТЁЃвђЮЊдкФГаЉМЋЖЫЕФЧщПіЯТЃЌетжжХаЖЯЪЧВЛбЯНїЕФЁЃЕЋДгДѓИХТЪЕФНЧЖШРДНВЃЌетжжЧщПіЪЧУЛгаЮЪЬтЕФЁЃвЛДЮПЩФмЭЌВНВЛе§ШЗЃЌПЩвдЭЈЙ§ЗЂЦ№ЖрДЮРДМьбщзюжеНсЙћЪЧЗёвЛжТЁЃEureka
ServerЕФЩшМЦддђБЃжЄЕФЪЧAPЃЌЖјВЂВЛЪЧCPЃЌвђДЫФмЙЛБЃжЄзюжеЪ§ОнЕФвЛжТадЁЃ
жСДЫЃЌEurekaЕФећИізщМўвбОШЋВПНщЩмЭъБЯЁЃМђЕЅИХРЈвЛЯТЃЌДгServerЕФНЧЖШРДЫЕЃЌАќРЈзЂВсЁЂајдМвдМАШЁЯћЃЌФкВПЛЙгаЬоГ§ЕФЛњжЦЁЃЭЌЪБEureka
ClientвВЛсКЭEureka ServerЭЌВНаХЯЂЃЌЭЌВНаХЯЂЕФЪБКђПЩФмЛсЗжЮЊЪзДЮЕФШЋСПвдМАУПвЛДЮЖЈЪБЕФдіСПаХЯЂЁЃХаЖЯдіСПЪЧЗёГЩЙІгыЪЇАмФиЃЌПЩвдЭЈЙ§вЛИіHashCodeетИіжЕЃЌМДЭЈЙ§ЫљгаЪЕР§ЕФupКЭdownзДЬЌЕФБэЪіРДХаЖЯЪЧЗёЭЌВНГЩЙІЁЃШчЙћЭЌВНГЩЙІЃЌЕШД§ЯТвЛДЮЭЌВНМДПЩЁЃШчЙћЭЌВНВЛГЩЙІЃЌдђвЊНјааШЋСПЕФРШЁЁЃ
Spring Cloud Netflix Ribbon
ЭЈЙ§EurekaзщМўЃЌгУЛЇФмЙЛЛёЕУЕФВЛНіНіЪЧвЛИіМђЕЅЕФЗўЮёЃЌПЩФмЪЧЯрЭЌЗўЮёЕФвЛИіМЏШКЁЃгУЛЇашвЊдкжкЖрЕФЗўЮёжабЁШЁвЛИізюгХЗўЮёРДЗЂЦ№зЪдДЕїгУЃЌЪЕЯжетИіЙІФмЕФзщМўЃЌОЭЪЧSpring
Cloud Netflix RibbonЁЃRibbonетИізщМўЪЧПЭЛЇЖЫЕФИКдиОљКтЃЌДгзжУцЩЯПДЃЌRibbonПЩвдЗжЮЊСНВПЗжЃЌвЛВПЗжЪЧПЭЛЇЖЫЃЌСэвЛВПЗжЪЧИКдиОљКтЁЃ
МйЩшЯТЭМжаЕФРЖЩЋаІСГДњБэRibbonЃЌФЧУДRibbonШчКЮЙЄзїЃПЕБClientЗЂЦ№вЛДЮrequestЕїгУЪБЃЌзїЮЊПЭЛЇЖЫЕФИКдиОљКтЃЌгУЛЇЯывЊЕФЪЧЧыЧѓУЛгаЗЂЫЭЪБОЭвбОФмЙЛжЊЕРФФвЛИіЗўЮёЪЧзюгХЕФЃЌДгЖјдкетИізюгХЕФЛљДЁЩЯзщзАrequestЕїгУЁЃМђЕЅИХРЈвЛЯТЪЕМЪСїГЬЃЌЯрЕБгквЛИіРЙНиЛњжЦЃЌЕБrequestНјШыЕФЪБКђЃЌRibbonЕФЙІФмЪЧРЙЭЌЪБРЙНижкЖрЕФServerЃЌВЂдкЦфжабЁШЁвЛИізюгХЕФЃЌШЛКѓЯђЫќЗЂЦ№вЛДЮЕїгУЁЃ
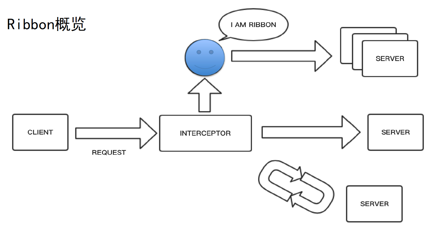
гвЯТЗНЕФбЛЗДњБэЪВУДЃПгаПЩФмЕквЛДЮЕїгУЪЇАмЃЌашвЊжиЪдВйзїЁЃЕБClientЗЂЦ№вЛДЮЕїгУЃЌдкЕїгУжЎЧАЯШНЋЦфРЙНиЃЌДгЖјДгжкЖрЕФServerЕБжабЁШЁвЛИіServerЃЌЗЂЦ№вЛДЮеце§ЕФЕїгУЁЃШчЙћГЩЙІбЁШЁзюгХServerЃЌдђНјШыЯТвЛЛЗНкЁЃШчЙћВЛГЩЙІЃЌПЩФмашвЊОЙ§ЖрДЮжиЪдЃЌДгЖјЪЙЫќДяЕНГЩЙІЕФФПЕФЁЃ
ЕквЛИіЮЪЬтЪЧШчКЮНјааРЙНиЁЃетРяОЭашвЊгУЕНRestTemplateЕФЬиадЁЃЦфЪЕдкЪЙгУRibbonЕФЪБКђЃЌашвЊдкRestTemplateЩЯМгвЛИізЂНтЃЌЕБШнЦїдкЦєЖЏЪБЃЌЛсЯШЫбЫїЫљгадкRestTemplateЩЯДђЙ§зЂНтЕФRestTemplateЃЌетвВвтЮЖзХвЊевЕНЫљгаНЋвЊЪЕЯжRibbonЕФетаЉRestTemplateЃЌвЊАбЫќзЅШЁЕНЁЃ
НгЯТРДНјШыеце§ЕФРЙНиВНжшЃЌДЫЪБRibbonНЋРћгУSpringЕФСэЭтвЛИіНгПкЃЌЕБЪЕЯжетИіНгПкЪБЃЌдкШнЦїжаЭъГЩЕФФГвЛИіНкЕуЃЌSpringЛсздЖЏШЅЛиЕїетИіНгПкЕФЗНЗЈЁЃвђЮЊЪзЯШвбОевЕНСЫЫљгавЊЪЕЯжRestTemplateЃЌАбетИіRestTemplateШЁГіРДЃЌвђЮЊRestTemplateРяУцЛсгавЛИіЬиадЪЧвЛИіintercepterЃЌЫќЛсАбЕБЧАЫљгаЕФintercepterФУЕНЃЌШЛКѓАбетСНИіРЙНиЦїМгШыЕНЯжГЩЕФРЙНиЦїРяУцЁЃ
ЭъГЩРЙНижЎКѓЃЌашвЊДгжкЖрЕФServerЕБжаЛёШЁвЛИіЪ§ОнЃЌетвВЪЧRibbonЕФКЫаФЙІФмЁЃШчЙћНЋRibbonБШзївЛИіШЫЃЌетИіШЫЕФзїгУЪЧвЊДгжкЖрЕФServerЕБжабЁШЁвЛИідкЕБЧАзДПіЯТЫќШЯЮЊзюгХЕФServerЁЃетИіШЫЕФЫФжЋОЭШчЭЌRibbonЕФКЫаФааЮЊЃЌМДIPingЁЂIRuleЁЂServerListUpdaterЁЂServerListFilterЁЃвЊДгжкЖрЕФServerЕБжабЁШЁвЛИіServerЃЌЯШОіЬѕМўЪЧвЊДцдкServerЃЌетаЉServerЭЈГЃРДдДгквдЯТСНжжЁЃ
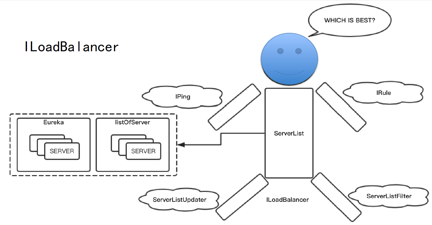
ЕквЛжжЗНЪНЪЧОВЬЌЕФЃЌПЩвдЭЈЙ§гВБрТыНјааХфжУЃЌ RibbonНЋИљОнЪфШыЕФServerЪ§СПДгжабЁШЁвЛИіЗЂЦ№вЛДЮЕїгУЁЃЛЙгавЛжжЗНЪНЪЧНсКЯЩЯЮФжаЕФEurekaЃЌПЩвдЭЈЙ§EurekaЕБжаЛёШЁдЖГЬЕФServerЁЃетЪЧЗНЪНЪЧЖЏЬЌЕФЃЌвђЮЊгавЛИіЗўЮёе§дкБЛЦєгУЁЃЦєгУЕФетИіЗўЮёОЭЛсзЂВсЕНEureka
ServerЕБжаЃЌЭЌЪБEureka ClientЛсЖЈЦкФУЕНетИізюаТЕФЪ§ОнЃЌЖјЭъГЩЖЏЬЌЕФЙІФмЁЃ
бЁШЁзюгХServerЕФЙцдђЪЧЪВУДЃПгааЉЧщПіЯТЕБгУЛЇЯђServerЗЂЦ№еце§ЕїгУЪБЃЌЯыжЊЕРетИіServerДЫЪБеце§ЕФзДЬЌЪЧЗёСМКУЁЃЛђепМйЩшШЯЮЊЫљгаЕФServerЪЧКУЕФЃЌвВПЩвдЭЈЙ§Eureka
ServerжаЛёШЁЕФClientаХЯЂЕФзДЬЌЪЧЗёЪЧupРДХаЖЯетИіServerЕФКУЛЕЁЃСэвЛжжЗНЪНЪЧеце§ЕФЯђServerЗЂЦ№PingВйзїЃЌЭЈЙ§PingВйзїРДВщПДServerЪЧЗёДцЛюЁЃ
RibbonЕФДІРэЙ§ГЬЗжЮЊСНРрЃЌвЛРрЪЧЦеЭЈЕФЗЧжиЪдашЧѓЃЌЕкЖўРрЪЧжиЪдЕФашЧѓЁЃЗЧжиЪдЕФЧыЧѓЪЧвбОдкRestTemplateжаМгдиНјааРЙНиЕФЙІФмЃЌЭЌЪБШЅДДдьОпгаСЫбЁШЁзюгХServerЕФааЮЊЕФФмСІЃЌбЁШЁЕНзюгХЕФServerЭъГЩЕїгУЁЃЖјдкжиЪдЕФЧщПіЯТЃЌбЁШЁвЛИіServerЃЌЗЂЦ№вЛДЮдЖГЬЕїгУЃЌШчЙћГЩЙІЛсЛёЕУЗДРЁЃЌШчЙћВЛГЩЙІОЭЛсИљОнздЖЈвхЕФВйзїКЭааЮЊЗЂЦ№ЯТвЛДЮЕїгУЁЃашвЊзЂвтЕФЪЧЃЌSpring
CloudЫфШЛгУСЫдЩњзщМўЃЌЕЋЫљгаЕФжиЪдЛњжЦЖМЪЧЛљгкSpring RetryЪЕЯжЕФЃЌШчЙћЯывЊЭЈЙ§RibbonжиЪдетИіЙІФмЃЌашвЊМгШыSpring
RetryетИіЙЄОпАќРДЭъГЩжиЪдЁЃ
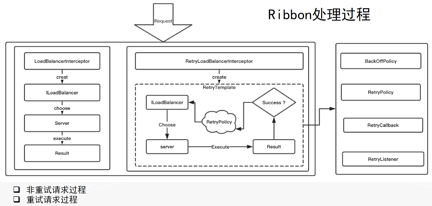
ЕквЛДЮжиЪдКЭЕкЖўДЮжиЪдЕФМфИєашвЊзіЪВУДЃПЪЧЕШД§вЛЖЮЪБМфЃЌЛЙЪЧСЂТэЗЂЦ№ЕїгУЃПетаЉашвЊИљОнОпЬхЧщПіРДНтЮіЃЌВЛЭЌЕФздЖЈвхааЮЊЛсДјРДВЛЭЌЕФВйзїЁЃетОЭЪЧSpring
RetryЯрЙиЕФвЛаЉНгПкЃЌАяжњПЊЗЂепХаЖЯВЂШЗЖЈУПвЛНзЖЮЕФздЖЈвхааЮЊЪЧЪВУДЁЃ
змжЎЃЌЭЈЙ§RibbonетИізщМўРДЭъГЩвЛДЮдЖЖЫзюгХServerЕФбЁдёЙ§ГЬЃЌПЩвдРэНтГЩЪзЯШашвЊдѕУДАбЫќвЦжВЕНПЭЛЇЖЫЃЌдкПЭЛЇЖЫУЛгаЗЂЦ№ЧыЧѓжЎЧАЃЌОЭвЊЪЕЯжРЙНиЁЃРЙНиЕНжЎКѓЃЌбЁШЁжкЖрЕФServerЗЂЦ№ЕїгУЃЌЕїгУШчЙћГЩЙІЃЌДѓЙІИцГЩЁЃШчЙћЪЇАмЃЌвВПЩвдЭЈЙ§жиЪдРДНтОіЁЃ
Spring Cloud Netflix Zuul
Spring Cloud Netflix ZuulПЩвдРэНтЮЊБпдЕЗўЮёЃЌЗўЮёЛЏЕФвЛИіAPIЭјЙиЁЃШчЯТЭМЫљЪОЃЌЕБЧыЧѓНјРДЪБЃЌЛсгаЧАжУЁЂТЗгЩЁЂКѓжУЕФШ§жжFilterРраЭЁЃЭЈЙ§ДЎаЭМмЙЙЃЌзюжеевЕНвЊДњРэЕФФЧИіЗўЮёВЂЗЕЛиЁЃ
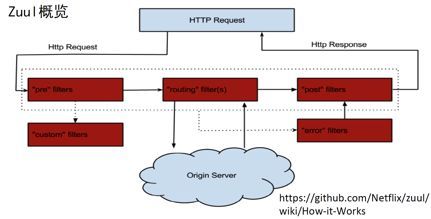
Spring Cloud Netflix ZuulФкжУСЫКмЖрFilterЃЌдкЦєЖЏЪБSpringЛсздЖЏНЋетаЉFilterзЂШыЕНЕБЧАЕФШнЦїЁЃ
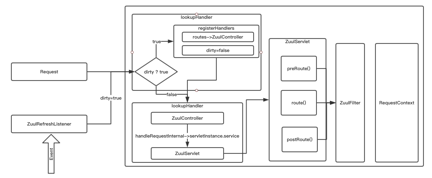
ZuulServletКЭZuulControllerЪЧZuulжаБШНЯживЊЕФСНИіРрЁЃZuulServletБОЩэОЭЪЧвЛИіServletЁЃZuulServletжївЊЙЄзїЪЧжДааЧАжУЁЂТЗгЩЁЂКѓжУFilterЁЃZuulControllerжївЊЙЄзїЪЧРЙНиЧыЧѓЃЌВЂНЋЧыЧѓзЊЗЂИјZuulServletНјааДІРэЁЃ
дкЖЈвхZuulЕФFilterЪБЮвУЧВЛНіПЩвддкFilterжаБраДОпЬхЕФвЕЮёТпМЭЌЪБвВПЩвджИЖЈFilterЕФжДааЫГађЃЌСэЭтвВПЩвджИЖЈЪЧЗёжДааИУFilterЁЃ
ZuulЕФЖЏЬЌТЗгЩЗНЪНгаСНжжЃЌЕквЛжжЗНЪНЪЧНЋТЗгЩЙцдђЮЌЛЄдкЭтВПЃЌЮвУЧвЛАуРћгУDB+RedisЁЃ
СэвЛжжЪЧдкEdgwareвдМАКѓајАцБОжаЃЌЕБдЖЖЫЗўЮёЦєЖЏЕФЪБКђ(ZuulБОЩэвВЪЧEureka Client)ЛсЛёШЁЕНзюаТЕФЗўЮёСаБэЃЌВЂРћгУзюаТЗўЮёСаБэИќаТЯжгаЕФТЗгЩЙцдђ(ЭъГЩЖЏЬЌТЗгЩЕФЙІФм)ЁЃ
ИќаТТЗгЩОпЬхТпМВЮМћЯТЭМ
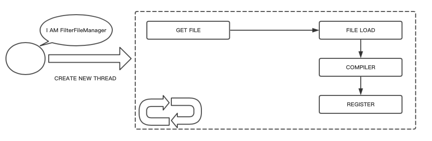
ЮвУЧвВПЩвдЪЙгУGroovyБраДZuulЕФFilterЃЌдкZuulЕФФкВПЮЌЛЄзХвЛИіЖЈЪБШЮЮёЃЌЛсЩЈУшжИЖЈТЗОЖЯТЕФGroovy
FilterЮФМўЃЌВЂНјааМгдиЁЃЭЈЙ§етжжЛњжЦЮвУЧПЩвдзіЕНдкВЛжиЦєZuulЕФЧщПіЯТЖЏЬЌЬэМгFilterЁЃОпЬхЕФТпМШчЯТ
Spring Cloud Openfeign
FeignетИіЕЅДЪгЂЮФЕФКЌвхЪЧЮБзАЃЌЛђепПЩвдРэНтГЩащМйЕФЃЌетИівтЫМЦфЪЕПЩвдЧхЮњЕиЗДгГГіетИізщМўБОжЪЕФКЌвхЁЃдкЗўЮёжЎМфЕїгУЕФЪБКђЃЌПЩФмЭЈЙ§ЪЎааЁЂЖўЪЎааДњТыОЭФмЙЛЭъГЩвЛДЮЕїгУЁЃЖдгкЕїгУЙ§ГЬжаЩцМАЕНЕФЙЋЙВДњТыЃЌгаУЛгавЛжжАьЗЈАбЫќГщРыГіРДЃЌОЙ§ПђМмЩшМЦжЎКѓШУЪЙгУБфЕУИќМгМђЕЅЃПжЛашвЊЖЈвхНгПкЃЌНгПкжаЖЈвхЗНЗЈЃЌШЛКѓЭЈЙ§ФГжжЪжЖЮжБНгЭъГЩвЛДЮЕїгУЁЃЫљвдетвВЪЧFeignЕФвЛИіГѕждЃЌОЭЪЧВЂВЛЙиаФЧыЧѓЪЧдѕбљЕФЃЌжЛЮЊСЫШУгУЛЇЗНБуШЅЪЙгУHTTPЕїгУЕФвЛИіДњРэЁЃ
вЊЪЙгУFeignЃЌЪзЯШвЊзіЕФОЭЪЧЪЙгУEnableFeignClientsзЂНтЃЌВЂдкЖдгІЕФInterfaceЩЯЬэМгЁЃFeignClientЕФзЂНтЁЃдкSpringЦєЖЏЪБЛсНЋДјгаFeignClientзЂНтЕФInterfaceзЂШыЕНSpringШнЦїжаЁЃШчЯТЭМЫљЪО
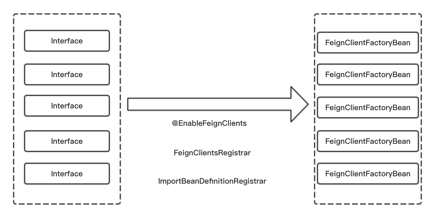
дкзЂШыSpringШнЦїЕФЭЌЪБЛсРћгУJAVAЕФЖЏЬЌДњРэЛњжЦЃЌетжжЛњжЦЛсдкРћгУInterfaceЗЂЦ№еце§ЕїгУЪБЭъГЩРЙНиЃЌдкРЙНиФкВПЭъГЩзщзАHTTPЧыЧѓЕФВйзїЁЃОпЬхЩњГЩДњРэЛњжЦШчЯТЭМЫљЪО
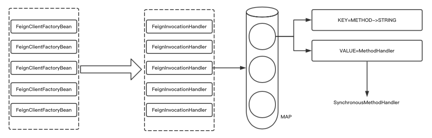
дкЪЙгУFeignЪБЮвУЧПЩвдПЊЦєHystrixЙІФмЃЌЭЈЙ§HystrixПЩвдзіЕНПьЫйШнДэЕФЙІФмЁЃЕБЪЙгУHystrixЪБЮвУЧашвЊжИЖЈfallbackЗНЗЈ(ШнДэЗНЗЈ)ЁЃДЫЪБЕїгУЙ§ГЬБЛЗтзАдквЛИіHystriCommandжаЃЌОпЬхЛњжЦШчЯТЭМЫљЪО
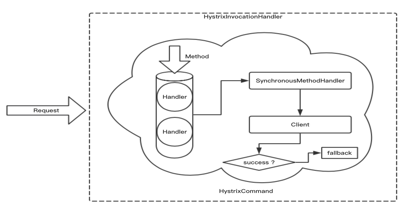
|









