| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФВЩгУСЫИпПЩгУЕФздЖЏЛЏдЫЮЌВПЪ№ЮЂЗўЮёМмЙЙЃЌЯЃЭћЖдФњЕФбЇЯАгаАяжњЁЃ
|
|
ЮЂЗўЮёЬхЯЕЕФЗЂеЙВЂВЛЪЧвЛѕэЖјОЭЕФЃЌОЙ§СЫ2014ФъЧАКѓЕФЕЭГБЦкЃЌЮЂЗўЮёИХФюЖЅВуЕФХнФж№НЅЭЪШЅЃЌФЧаЉеце§ФмЙЛдкЦѓвЕТфЕиЕФЪЕМљдквЛТжгжвЛТжЕФДѓРЫЬдЩГКѓБЛечБ№ЁЂГСЕэЁЃетЦЊЮФеТЯЃЭћЬжТлвЛаЉдкЭХЖгжаЪЕааЮЂЗўЮёМмЙЙЪБжЕЕУПМТЧЕФЁКдіжЕЯюФПЁЛЃЌЫќУЧжаЕФвЛаЉПДЦ№РДвбОЪЧРэЫљгІЕБЕФЃЌЖјСэвЛаЉЫЦКѕКЭЮЂЗўЮёВЂУЛгаБиШЛЕФЙиСЊЃЌЕЋаэЖрОбщФмЙЛжЄУїетаЉЯюФПЖМЪЧБЃеЯЮЂЗўЮёЯЕЭГГЄЦкдЫзїВЂзюДѓЛЏЗЂЛгЦфScale
OutФмСІжЕЕУЭЖШыЕФИпИНМгжЕЪЕМљЁЃ
ГжајНЛИЖ
ЖдгкЮЂЗўЮёЕФГЩЙІЪЕЪЉЃЌЭХЖгГжајНЛИЖФмСІЪЧжСЙиживЊЕФКтСПжИБъЁЃдкгЩЩЯАйИіЗўЮёзщГЩЕФИДдгЯЕЭГжаЃЌШчЙћЫљгаЗўЮёЖМАДееШЫЮЊжИЖЈЗЂВМжмЦкНјааећЬхНЛИЖЃЌКмШнвзГіЯжгЩгкЯИаЁЕФЪЇЮѓЕМжТДѓУцЛ§ЯпЩЯЙЪеЯЁЃ
ГжајНЛИЖЪЕМљвЊЧѓУПИіЖРСЂЗўЮёЖМОпгаЭъБИЕФНЛИЖСїЫЎЯпЃЌдкСїЫЎЯпЕФФЉЖЫЫцЪБФмЬсЙЉЕБЪБзюаТЕФПЩЙЄзїЁЂПЩНЛИЖЕФВњЦЗЁЃГжајНЛИЖЭЈГЃЛсХфКЯздЖЏЛЏЕФВтЪдКЭВПЪ№ЪжЖЮЃЌДгЖјМѕЩйЙІФмДњТыЬсНЛЕНЩЯЯпЕФЖЫЕНЖЫЪБМфЁЃетОЭЪЙЕУУПИіЖРСЂЗўЮёФмАДееИїздВЛЭЌЕФНкзрНјааЗЂВМЃЌВЂЧвНЋздМКЕФЗЂВМзДЬЌПЩЪгЛЏГіРДЁЃ
ВЩгУОЁПЩФмОЋМђЧвЮШЖЈЕФЗжжЇВпТдвВЪЧЪЙЕУГжајНЛИЖСїГЬФмЙЛЫГРћЪЕЪЉЕФЙиМќЃЌЮвУЧЬсГЋЪЙгУЕЅжїИЩЕФЗжжЇВпТдЃЈTrunk
Based DevelopmentЃЉЁЃдкЕЅжїИЩЕФПЊЗЂЗНЪНжаЃЌГ§СЫвЛИігУгкГжајПЊЗЂКЭМЏГЩЕФЁКжїИЩЗжжЇЁЛЃЈЭЈГЃМДMasterЗжжЇЃЉКЭвЛЯЕСавРОнЗЂВМжмЦкДДНЈЕФЗЂВМЗжжЇвдЭтЃЌгІИУБмУтДДНЈЦфЫћЕФLong-livedЗжжЇЁЃШчЙћгаЖрИіЙІФмашвЊПЊЗЂЃЌдђЭЦМіВЩгУЬиадПЊЙиЃЈFeature
ToggleЃЉЕФЗНЗЈРДПижЦЫќУЧЕФЗЂВМЪБЛњЁЃЕБШЛЃЌЕЅжїИЩВпТдЪЧдЪаэДцдкЖЬЩњУќжмЦкЬиадЗжжЇЕФЃЈЖЬгквЛжмЃЉЃЌгаЪБетаЉаЁЗжжЇЩѕжСЮоашЬсНЛЕНдЖГЬВжПтжаЁЃЯТУцетЪЧвЛЗљОЕфЕФЕЅжїИЩЗжжЇВпТдЪОвтЭМЁЃ
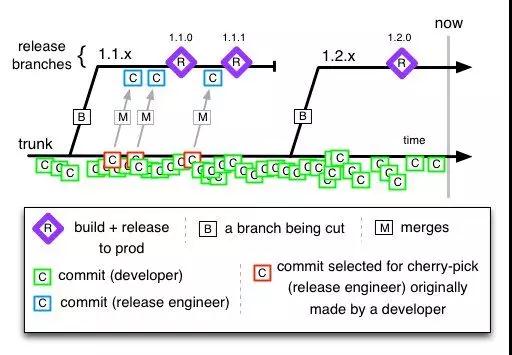
ЕЅжїИЩЗжжЇВпТд
жЕЕУжИГіЕФЪЧЃЌдкЛЎЗжЕУЕБЕФЮЂЗўЮёЯЕЭГжаЃЌЭЌвЛИіЗўЮёашвЊЭЌЪБНјааПЊЗЂЕФЬиадЭЈГЃВЛЛсЖргкСНЕНШ§ИіЃЈЗёдђгІИУПМТЧетИіЗўЮёЪЧЗёГаЕЃСЫЙ§ЖрЕФжАд№ЃЉЁЃвђДЫМДЪЙдкВЛашвЊЬиадПЊЙиКЭЦфЫћЖюЭтПЊЗЂЙЄзїСПЕФЧщПіЯТЃЌвбОПЩвдБШНЯКУЕФЪЕЯжУПИіЙІФмЕуЕФЖРСЂЗЂВМКЭВтЪдЃЌетЗДЯђЫЕУїСЫЮЂЗўЮёМмЙЙЖдгкГжајНЛИЖЕФЪЕЪЉвВЪЧЪЎЗжгбКУЕФЁЃ
Г§СЫбЯИёЕФЕЅжїИЩЃЌвЛжжГЃМћЕФБфЪНЪЧЖржїИЩВпТдЃЌЕфаЭЕФЪЧвЛИіПЊЗЂЗжжЇМгМИИіЙЬЖЈЕФЗЂВМЗжжЇЃЌЭЈГЃгУгкЮоашЮЌЛЄЖрИіЗЂВМАцБОЕФSaaSЗўЮёНЛИЖЁЃетжжФЃЪНЕФгХЕуЪЧФмЙЛНЋЗЂВМСїЫЎЯпФПБъЛЗОГКЭЗжжЇЯдЪОЕФЙиСЊЦ№РДЃЌР§ШчЁКDevelopЗжжЇЁЛЖдгІМЏГЩЛЗОГЃЌЁКReleaseЗжжЇЁЛЖдгІбщЪеЛЗОГКЭе§ЪНЛЗОГЁЃЯТЭМеЙЪОСЫвЛзщгыДЫФЃЪНЯТЕФГжајНЛИЖСїЫЎЯпЁЃ
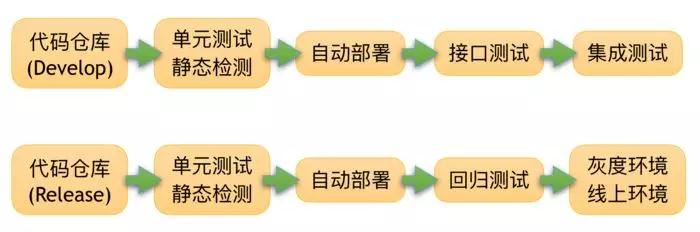
ЖржїИЩЕФСїЫЎЯп
БЃГжУПИіЗўЮёИпЦЕТЪЕФМЏГЩКЭНЛИЖЃЌЛсЪЙЕУгаЙЪеЯЕФЙІФмдкКмЖЬЕФЗДРЁжмЦкФкБЛЗЂЯжЃЌдкПьЫйЕќДњЗЂВМЕФЧАЬсЯТзіЕНећИіЯЕЭГЗЂВМОЎШЛгаађЁЃетбљЕФЗеЮЇВЛНігаРћгкИФЩЦДњТыЕФжЪСПЃЌЖјЧвФмЙЛЬсИпПЊЗЂЪПЦјЃЌЦЕЗБЕФЗЂВМЩЯЯпвВгаРћгкдіЧПЭХЖгЖдВњЦЗЕФШйгўИаКЭздаХаФЁЃ
ШЋЙІФмЭХЖг
ШЋЙІФмЭХЖгЪЧDevOpsдЫЖЏЫљГЋЕМЕФвЛжжВњЦЗЭХЖгзщжЏНсЙЙЃЌЭЈЙ§НЋВЛЭЌНЧЩЋЕФвЕЮёКЭММЪѕГЩдБФЩШыЕНЭХЖгЃЌзщГЩОпБИЖЫЕНЖЫНЛИЖКЭдЫгЊФмСІЕФЭъећЕЅдЊЁЃ
ПЕЭўЖЈТЩВћЪіСЫПЊЗЂЭХЖгЕФзщжЏНсЙЙКЭЦфЩшМЦЕФВњЦЗНсЙЙжЎМфОпгаЕФЯрЫЦЙиЯЕЁЃаэЖрЕФЪЕМљНсЙћвВБэУїЃЌНЋШЋЙІФмЭХЖгЪЕМљгІгУдкЮЂЗўЮёВњЦЗжаДјРДЕФЪевцЃЌвЊдЖдЖГЌЙ§ЫќдкДЋЭГФЃПщЛЏПЊЗЂЕФВњЦЗжаЫљДјРДЕФЪевцЁЃетЪЧвђЮЊЮЂЗўЮёЕФМмЙЙжаЕФЫљгаЗўЮёеце§ОпБИЖРСЂдЫааКЭЖРСЂдЫгЊЕФФмСІЃЌДгБОжЪЩЯРДЫЕОЭЪЧвЛИіЖЫЕНЖЫЕФзгвЕЮёВњЦЗЁЃ
етжжМмЙЙКЭЭХЖгЕФгАЯьЪЧЫЋЯђЕФЁЃвЛЗНУцЃЌЮЂЗўЮёЕФдЫгЊНсЙЙвЊЧѓЭХЖгОпгаИпФкОлЕФзджїЙмРэФмСІЁЃСэвЛЗНУцЃЌШЋЙІФмЭХЖгвВЮЊЬиЖЈЗўЮёНјааЖРСЂММЪѕбЁаЭЬсЙЉСЫИќСщЛюЕФЗЂЛгПеМфЁЃЗўЮёгыЭХЖгЭЈГЃЪЧЖрЖдвЛЕФЙиЯЕЃЌУПИіЭХЖгЙмРэЕФЪЧвЛзщЯрЛЅЙиСЊНєУмЕФЗўЮёШКЃЌВЂЧвПЩвддкБивЊЕФЧщПіЯТЖдЗўЮёНјааНјвЛВНВ№ЗжЁЃдкЪЕМЪЕФЪЕМљжаЭЦМіВЩгУР§ШчНгПкЭјЙиЃЈAPI
GatewayЃЉЕШЗНЪНЖдвЛзщОпгавЕЮёвтвхЕФЗўЮёНгПкНјааОлКЯЃЌДгЖјБЃжЄОжВПЗўЮёНсЙЙБфЛЏВЛЛсжБНггАЯьЗўЮёЕФЯћЗбЗНЕФЕїгУЁЃ
жЕЕУвЛЫЕЕФЪЧЃЌдквЛаЉДЋЭГЦѓвЕФкЕФITВПУХЛЎЗжЃЌЭљЭљвбОАДеежАФмЗжЮЊПЊЗЂЭХЖгЁЂдЫЮЌЭХЖгЁЂдЫгЊЭХЖгЃЌЩѕжСЕЅЖРЕФВтЪдЭХЖгЁЃдкетбљЕФЦѓвЕжаКмФбПьЫйЭъГЩШЋЙІФмЭХЖгЕФзЊБфЃЌвђДЫдкЪЕЪЉЮЂЗўЮёМмЙЙЙ§ГЬжаБШНЯШнвззпЦЋЁЃЖдгкетжжЧщПіПЩвдВЩгУж№ВНбнНјЕФзЊЛЛЗНЪНЃЌОпЬхЭООЖжївЊгаСНжжЁЃ
ЕквЛжжЗНЪНЪЧНјааЯюФПЪдЕуЁЃЖдгкЯАЙпСЫАДЙІФмЗжВуЁЂЗжПщЕФЁКЪЕЯжНгПкПЊЗЂЁЛЪНЕФзщжЏЃЌМДЪЙУуЧПДеЦыУПИіНЧЩЋЕФШЫзщдквЛЦ№вВФбвдГЩЮЊеце§ОпБИЖЫЕНЖЫНЛИЖФмСІЕФЭХЖгЁЃвђДЫгыЦфзіЕУЭНгаЦфБэЃЌВЛШчевГіЯюФПжавЛаЉШЋОжвтЪЖБШНЯЕНЮЛЕФГЩдБЃЌЖдЬиЖЈЕФЯюФПНјааЪдЕуЃЌШЛКѓж№ВНРЉДѓЃЌНЋетжжЖЫЕНЖЫЕФд№ШЮКЭвтЪЖДјШыЕНИќЖрЕФЯюФПжаШЅЁЃЪдЕуЕФЯюФПгІИУЪЧвдЪЕЪЉЯжгаЯЕЭГЕФвЛИіЖРСЂвЕЮёЙІФмЕуЮЊФПБъЃЌЖјВЛЪЧПЊЗЂгыЦѓвЕжїЯпЯЕЭГЮоЙиЕФЖЬЦкВњЦЗЃЌЗёдђШнвзГіЯжЪдЕуЯюФПКмГЩЙІЃЌЕЋЯюФПНсЪјБуВЛСЫСЫжЎЕФНсЙћЁЃ
ЕкЖўжжЗНЪНЪЧЯШДгЗжПЊЗЂЭХЖгШыЪжЃЌзнЯђЛЎЗжЯюФПЁЃетЪЧЖдШЋЙІФмЭХЖгЕФвЛжжЭзаЪНЕФв§ШыЗНЪНЃЌМДдкПЊЗЂЭХЖгжаЪзЯШИФБфЯЕЭГМмЙЙКсЯђЗжВуЁЂОжВПЗжПщЕФПЊЗЂФЃЪНЃЌвРОнвЕЮёЙІФмНјааЩЯжСЭтВПНгПкЁЂЯТжСвЕЮёЪ§ОнЕФЖРСЂЗўЮёВ№ЗжЃЌЕЋВЂВЛМБгкдкПЊЗЂЭХЖгжав§ШыжюШчВтЪдЁЂдЫЮЌЁЂвЕЮёЕШНЧЩЋЕФГЩдБЁЃетжжЯюФПЛЎЗжЫфШЛдквЛЖЈГЬЖШЩЯЮЊЮЂЗўЮёМмЙЙжДаажЦдьСЫЬѕМўЃЌЕЋДгГЄдЖРДПДЃЌВЂВЛФмЮЊЭХЖгНјаазджїЕФММЪѕеЛКЭЛљДЁЩшЪЉбЁаЭЁЂвдМАвЕЮёЪ§ОнЕФРћгУЬсЙЉзуЙЛЕФПеМфЁЃ
здЖЏЛЏдЫЮЌ
здЖЏЛЏдЫЮЌЪЧЪЕЪЉГжајНЛИЖЕФБивЊЧАЬсЃЌвђДЫвВПЩвдЫЕЪЧВЩгУЮЂЗўЮёМмЙЙЕФБивЊЧАЬсЁЃЕЋетРяЫљЫЕЕФздЖЏЛЏдЫЮЌЃЌВЛНіНіАќКЌГжајНЛИЖЫљашЕФЗўЮёВПЪ№ЪБЁКвЛМќВйзїЁЛФмСІЃЌИќживЊЕФЪЧдЫЮЌЛљДЁЩшЪЉЙЙНЈЕФздЖЏЛЏЁЂвдМАЗўЮёджБИЁЂЛжИДЕФздЖЏЛЏЁЃЮЂЗўЮёМмЙЙзюГѕЪмЕНзЗХѕЕФвЛИідвђЪЧЫќСщЛюЕФЁКОжВПScale
OutЁЛФмСІЃЌвдЙІФмЕуЮЊЕЅдЊЕФРЉеЙЁЂЪеЫѕЃЌетЖдгкОпгавЕЮёжмЦкадЕФЗўЮёЖјбдИќМгживЊЁЃЕЋвЛаЉЦѓвЕдкздЩэЛљДЁЩшЪЉздЖЏЛЏВЛЕНЮЛЕФЧщПіЯТУЄФПЪЕЪЉЮЂЗўЮёЃЌЦкЭћЭЈЙ§ЦфЪЕЯжИДдгМмЙЙЕФНтЙЙЃЌНсЙћдкУцЖдЭЛЗЂЯпЩЯЪТЙЪЪБГіЯжбЉБРЪНЕФСЌЫјЗДгІЃЌЧщМБжЎЯТвВжЛФмЪжЙЄЛжИДжиНЈЃЌЕЂЮѓДѓСПЪБМфЁЃ
ЪЕЪЉздЖЏЛЏдЫЮЌЩцМАЕФЙЄОпгаКмЖрЃЌР§ШчAnsibleЁЂSaltStackЁЂTerraformЃЌЩѕжСDockerЖМПЩвдПДзіЪЧздЖЏЛЏдЫЮЌЕФвЛВПЗжЁЃетЕБжаДѓЖрЪ§ЙЄОпЖМЬсЙЉгаЖЈвхВйзїааЮЊЕФСьгђDSLЃЌЫќУЧЭЈГЃЪЧвЛаЉХфжУЪНгябдЛђНХБОгябдЃЌвђДЫздЖЏЛЏдЫЮЌвВЩцМАЕНДњТыЕФБраДЁЃгыПЊЗЂЯюФПДњТыВЛЭЌЕФЕиЗНдкгкЃЌздЖЏЛЏдЫЮЌЕФДњТыДѓЖрВЛЪЧГЄЦкдЫааЕФЃЌКмЖрДњТывВаэжЛдкЬиЖЈГЁОАЪЙгУвЛДЮЃЌШЛКѓОЭЛсЗЧГЃГЄЪБМфЮоШЫЮЪНђЃЌжБЕНФГаЉНєМБЧщПіВХЛсдйДЮашвЊгУЕНЁЃДЫЭтЃЌдЫЮЌЕФДњТыБОЩэВЂВЛжБНгОпгавЕЮёМлжЕЃЌетаЉвђЫиЕМжТЫќУЧЭљЭљУЛгаБЛКмКУЕФЙмРэЦ№РДЁЃ
ЯТУцвдВЩгУAnsibleЛђSaltStackетРрЭЈгУздЖЏЛЏЙЄОпЮЊР§ЃЌНщЩмвЛаЉдкЪЕМљжаашвЊзЂвтЕФЕиЗНЁЃ
ЪзЯШЪЧдЫЮЌНХБОгІИУЭЈЙ§GitЛђSVNетбљЕФАцБОЙмРэЙЄОпНјааЙщРрКЭЙмРэЁЃЭЈГЃРДЫЕЃЌЭЦМіНЋЬиЖЈЗўЮёВПЪ№ЕФAnsibleЛђSaltStack
YAMLНХБОЮФМўгыЗўЮёБОЩэЕФДњТыЗХдкЭЌвЛИіДњТыВжПтжаЃЌЗНБуПЊЗЂШЫдБдкБивЊЪБКђПьЫйЕФаоИФЫќЁЃШЛКѓНЋЛљДЁЩшЪЉЙмРэЕФYAMLНХБОЮФМўЗХдкЕЅЖРЕФДњТыВжПтЃЌЗНБуИДгУКЭВщевЁЃЕЋетбљПЩФмДјРДЕФЮЪЬтЪЧЃЌдкЪЕМЪЪЙгУЪБПЩФмЛсашвЊЭЌЪБЛёШЁСНИіДњТыВжПтЕФНХБОвдЛёЕУЭъећЕФВПЪ№ЙІФмЃЌвђДЫШчЙћЪЙгУЕФЦфЫћХфЬзЙЄОпЖдЖрВжПтжЇГжВЛМбЃЌвВПЩвдНЋЫљгадЫЮЌНХБОдкЭЌвЛИіВжПтЙмРэЁЃ
ЦфДЮЃЌгІИУдкГжајНЛИЖСїЫЎЯпЩЯЪЙгУЗўЮёВПЪ№ЕФздЖЏЛЏЙЄОпЃЌДгЖјЪЕЯжПьЫйЕФНЛИЖЩЯЯпЁЃдкЬѕМўдЪаэЕФЧщПіЯТЃЌЛЙгІИУдкСїЫЎЯпЩЯжБНгХфБИздЖЏЛЏЕФджБИЛжИДШЮЮёШыПкЃЌвдМАЖЈЦкЕФЖдетаЉЛжИДНХБОНјааВтЪдКЭбнСЗЁЃ
зюКѓЃЌЫфШЛЮвУЧЙФРјУПИіЭХЖгЪЙгУЪЪКЯздЩэвЕЮёЕФММЪѕеЛНјааПЊЗЂЃЌЕЋЖдгкдЫЮЌЙЄОпЕФбЁдёЭЈГЃШУЭЌвЛИіВњЦЗЕФИїЗўЮёВЩгУЭГвЛММЪѕеЛБШНЯКЯЪЪЃЈР§ШчВЛвЊЛьгУAnsibleКЭSaltStackЕФНХБОЃЉЁЃетИіНЈвщжївЊПМТЧЕНдЫЮЌЙЄзїПЩФмЛсгаНЯЖрПчЭХЖгазїЃЌвдМАЙЪеЯЛжИДГЁОАЯТЕФПьЫйОШджВйзїЃЌЭГвЛЕФММЪѕеЛФмЮЊдЫЮЌШЫдБНкдМЕєЙЄОпЧаЛЛЕФЪБМфЁЃ
ЗўЮёИпПЩгУ
гЩгкЮЂЗўЮёЯЕЭГжаДцдкзХжкЖрПчЗўЮёЕїгУЃЌШЮКЮвЛИіЗўЮёЖМВЛФмМйЩшздМКПЩвдЫцвтЕФЭЃЛњвЛЖЮЪБМфЖјВЛЖдЯЕЭГЕФећЬхЙІФмдьГЩгАЯьЁЃЕЋдкЯжЪЕЧщПіжаЃЌе§ГЃЕФЗўЮёЩ§МЖЛђвтЭтЕФЙЪеЯЖМгаПЩФмдьГЩЗўЮёЖЬднЛђГЄЪБМфЕФжаЖЯЃЌетжжжаЖЯЧсдђв§Ц№ОжВПЙІФмВЛПЩгУЃЌжидђЕМжТСЌЫјЗДгІдьГЩжиДѓЪТЙЪЁЃетаЉЖМЪЧдкМмЙЙЩшМЦЪБКђОЭгІИУгшвдПМТЧЕФЮЪЬтЁЃгІЖдетСНРрЧщПіЕФЗНЗЈЗжБ№ЪЧЖдЗўЮёВЩгУИпПЩгУЕФВПЪ№ЗНЪНЃЌКЭНјааВЛРыЯпЕФВПЪ№ЁЃЪЕЯжЗўЮёИпПЩгУЕФЗНЗЈгаКмЖрЃЌГЃМћЕФгаЃКL7ИКдиОљКтЁЂDNSИКдиОљКтЁЂЗўЮёЗЂЯжЁЂЭЌВН/вьВНЯћЯЂЖгСаЕШЁЃ
L7ИКдиОљКтМДдкOSIЭјТчФЃаЭгІгУВуНјааЕФШэМўИКдиОљКтЃЌР§ШчNginxКЭHAProxyЖМЪєгкетРрЁЃетаЉL7ИКдиОљКтЭЈГЃДјгаКѓЖЫЗўЮёМьВщЕФФмСІЃЌЛсздЖЏЦСБЮЕєВЛПЩгУЕФКѓЖЫЗўЮёЃЌДгЖјдквЛВПЗжЗўЮёГіЯжЙЪеЯЪБКђЃЌЧыЧѓШдШЛФмБЛе§ГЃдЫааЕФКѓЖЫЗўЮёНгЪеЁЃ
DNSИКдиОљКтЪЧРћгУСЫDNSЗўЮёПЩвдЮЊЭЌвЛИігђУћХфжУЖрИіНтЮіЕижЗЃЌЧвХфжУЖрИіЕижЗКѓЃЌУПДЮНтЮігђУћЪБТжбЏзХНЋХфжУЕФЕижЗЗЕЛиИјЧыЧѓЗНЃЌетИіЬиадГЦЮЊDNSТжбЏЁЃЪЕМЪЩЯDNSТжбЏНіНіЪЧвЛжжЬиЪтЕФИКдиОљКтММЪѕЃЌБОЩэВЂВЛОпгаМьВтЗўЮёзДЬЌЁЂЬсЙЉКѓЖЫЗўЮёИпПЩгУЕФЙІФмЁЃЕЋвЛаЉаТГіЯжЕФПЊдДDNSВњЦЗЃЌР§ШчSkyDNSКЭConsulНЋDNSЗўЮёгыЗўЮёЗЂЯжММЪѕНјааСЫНсКЯЃЌОпгаздЖЏвЦГ§ВЛПЩЗУЮЪЕФНтЮіЕижЗЕФЙІФмЃЌетЪЙЕУDNSИКдиОљКтвВПЩвдБЛгУгкЪЕЯжЗўЮёЕФИпПЩгУСЫЁЃ
ЗўЮёЗЂЯжЪЧвЛжжЛљгкзЂВсКЭВщбЏЗўЮёаХЯЂЕФМќжЕЪ§ОнПтЗўЮёЁЃЬсЙЉЗўЮёЕФвЛЗННЋздМКЕФУћГЦКЭIPЕижЗзЂВсЕНЗўЮёЗЂЯжЕФЗўЮёЖЫЃЌЪЙгУЗўЮёЕФвЛЗНдђЭЈЙ§ЗўЮёЗЂЯжЕФЗўЮёЖЫНјааВщбЏЃЌШЛКѓНЋЪЕМЪЧыЧѓЗЂЫЭИјВщбЏЕНЕФФПБъIPЕижЗЁЃЗўЮёЗЂЯжЕФЗўЮёЖЫЛсИКд№МьВтУПИізЂВсЗўЮёЕФдЫаазДЬЌЃЌМАЪБвЦçóЯжЙЪеЯЕФЗўЮёЃЌВЂдкУПДЮЪеЕНВщбЏЪБДгЗћКЯУћГЦЕФЗўЮёжаШЮвтЗЕЛивЛИізїЮЊНсЙћЁЃ
ЯћЯЂЖгСадђЪЧвЛжжВЩгУжаМфУННщНтёюЗўЮёЬсЙЉепКЭЯћЗбепЕФЗНЗЈЁЃЗўЮёжЎМфЭЈЙ§ЗЂВМКЭЖЉдФЯћЯЂНјааНЛЛЅЃЌЫљгаЕФЯћЯЂЭЈЙ§ЖгСаНјааЗжЗЂКЭжазЊЁЃетжжНсЙЙЪЙЕУЯћЯЂЖгСаБОЩэГЩЮЊЫљгаЪ§ОнЭЈаХЕФЦПОБЃЌгыЮЂЗўЮёЕФШЅжааФЛЏЫМЯыЯруЃЃЌвђДЫВЂВЛЭЦМідкДѓаЭЮЂЗўЮёЯЕЭГжаВЩгУЁЃ
ВЛРыЯпВПЪ№
ВЛРыЯпВПЪ№ЪЧШЗБЃЗўЮёЫцЪБФмЗЂВМЕФБивЊДыЪЉЃЌвВЪЧЮЂЗўЮёМмЙЙЭХЖгашвЊЙизЂЕФвЛжжФмСІЁЃдкЪЕМЪгІгУжаЃЌГ§СЫвЛаЉЬьЩњжЇГжВЛРыЯпВПЪ№ЕФММЪѕеЛЃЌШчErlangЃЌЖрЪ§ЕФЗўЮёЪЧдЩњВЛжЇГжШШЩ§МЖЕФЁЃЖдгкетаЉЗўЮёЃЌЭЈГЃРДЫЕПЩИљОнЗўЮёЁКЪЧЗёФмЕнНјЪНЩ§МЖЁЛКЭЁКЪЧЗёОпгаГЄШЮЮёЁЛЕФЬиадЃЌЗжГЩШ§жжРраЭЃКЁКВЛФмЕнНјЩ§МЖЕФЗўЮёЁЛЃЌЁКФмЕнНјЩ§МЖЁЂЮоГЄШЮЮёЕФЗўЮёЁЛЃЌвдМАЁКФмЕнНјЩ§МЖЁЂгаГЄШЮЮёЕФЗўЮёЁЛЃЌЗжБ№ВЩгУВЛЭЌВпТдНјааЁЃетРяЯШНщЩмвЛЯТЗўЮёЕФЁКЕнНјЪНЩ§МЖЁЛКЭЁКОпгаГЄШЮЮёЁЛЁЃ
ЕнНјЪНЩ§МЖЃЈRolling UpdateЃЉЪЧжИНЋМЏШКжаЕФЗўЮёЛЎГЩЖрИіЗжзщЃЌУПДЮжЛЩ§МЖЦфжаЕФвЛИіЗжзщЃЌШЛКѓвРДЮНјааЃЌжБЕНЫљгаЗўЮёЖМЩ§МЖЭъГЩЕФЙ§ГЬЁЃВЩгУЕнНјЪНЩ§МЖЛсЪЙЕУМЏШКжаЕФЗўЮёгавЛЖЮЪБМфЭЌЪБДцдкаТОЩСНИіАцБОЁЃ
ГЄШЮЮёжИЪЧНгЪеЕНЧыЧѓКѓашвЊЛЈЗбМИУыЁЂЩѕжСМИаЁЪБВХФмжДааЭъЕФШЮЮёЃЌР§ШчвЛаЉЩцМАДѓСПМЦЫуЛђашвЊдЖГЬЭЌВНЕїгУЕФЪТЮёЁЃОпгаГЄШЮЮёЕФЗўЮёЖМгаЁКдЫаажаЁЛКЭЁКПеЯаЁЛетбљЕФдЫаазДЬЌЁЃЕБЗўЮёДІгкЁКдЫаажаЁЛЕФЪБКђЃЌжаЖЯЫќПЩФмЕМжТвтЭтЕФНсЙћЁЃвЛАуРДЫЕдкLinuxжаЭЃжЙЗўЮёЕФСїГЬЪЧЯШЯђЗўЮёЗЂЫЭвЛИіTERMаХКХЃЌЪЙЦфе§ГЃНсЪјЃЌШєЪЧаХКХЗЂЫЭМИУыКѓЃЌЗўЮёШдШЛдкдЫааЃЌВХЛсЗЂЫЭKILLаХКХНЋЫќЧПаажежЙЁЃДІРэЖЬШЮЮёЕФЗўЮёЭЈГЃПЩвддкНгЪеЕНTERMаХКХКѓМАЪБЭЃжЙЃЌвђДЫВЛДцдкетжжЗчЯеЁЃетРягІИУНЋЁКЮоГЄШЮЮёЕФЗўЮёЁЛгыЁКЮозДЬЌЕФЗўЮёЁЛМгвдЧјЗжЃЌКѓепжИЕФЪЧЗўЮёЖдУПДЮЧыЧѓЕФДІРэЃЌВЛвРРЕгкЦфЫћЧыЧѓЁЃМДЗўЮёДІРэвЛДЮЧыЧѓЫљашЕФШЋВПаХЯЂЃЌвЊУДЖМАќКЌдкетИіЧыЧѓРяЃЌвЊУДПЩвдДгЭтВПЛёШЁЕНЃЈБШШчЫЕЪ§ОнПтЃЉЃЌЗўЮёЦїБОЩэВЛДцДЂШЮКЮаХЯЂЁЃЭЈГЃРДЫЕЃЌЮЂЗўЮёМмЙЙжаЕФЗўЮёвЛЖЈЪЧЮозДЬЌЕФЃЌЕЋВЛвЛЖЈЪЧЮоГЄШЮЮёЕФЁЃ
ШчЙћЗўЮёВЛФмВЩгУЕнНјЪНЕФЩ§МЖЃЌВЛТлЦфЪЧЗёОпгаГЄШЮЮёЃЌРЖТЬВПЪ№ЖМЪЧвЛжжЪЎЗжЭЦМіЕФВПЪ№ЗНЪНЁЃРЖТЬВПЪ№ЕФзіЗЈЪЧЭЌЪБзМБИвЛзщЯпЩЯдЫааЕФЗўЮёЦїЃЌвдМАвЛзщгУгкЯТДЮВПЪ№ЕФЗўЮёЦїЃЌСНзщЗўЮёЦїОпгаЯрЭЌЕФЪ§СПКЭХфжУЁЃжДааВПЪ№ЪБЃЌЯШНЋаТЕФЗўЮёВПЪ№ЕНУЛгаЗХЕНЯпЩЯдЫааЕФФЧзщЗўЮёЦїЩЯЃЌЕШЕНВПЪ№ШЋВПЭъГЩЃЌжБНгНЋИКдиОљКтЕФСїСПЕМЯђЕНИеИеетзщЗўЮёЦїЩЯЃЌДгЖјЪЙЕУСНзщЗўЮёЦїЕФНЧЩЋЛЅЛЛЁЃЯТвЛДЮНјааВПЪ№ЕФЪБКђЃЌдђЛЛгУСэЭтвЛзщЗўЮёЦїжДааВПЪ№ЃЌШЛКѓНЋИКдиОљКтЧаЛЛЛиРДЁЃетИіЙ§ГЬШчЯТЭМЫљЪОЃК
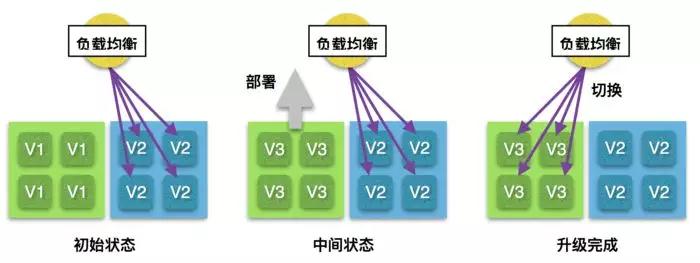
РЖТЬВПЪ№ЕФЙ§ГЬ
РЖТЬВПЪ№ЕФгХЕудкгкаТОЩЗўЮёЕФЧаЛЛЪЧЫВМфЭъГЩЕФЃЌВЂЧвЕБСїСПЧаЛЛЕНСэвЛзщЗўЮёЦїЩЯжЎКѓЃЌдЯШЕФФЧзщЗўЮёЦїПЩвдМЬајдЫааЃЌетбљМДЪЙЩЯУцгаЮДЭъГЩЕФШЮЮёвВВЛЛсБЛЧПаажаЖЯЃЌШчЙћЩ§МЖКѓЕФАцБОЗЂЯжСЫБШНЯбЯжиЕФЮЪЬтЃЌвВПЩвдПьЫйЕФЧаЛЛЛидЯШЕФАцБОЁЃЖјЫќЕФШБЕувВЪЎЗжУїЯдЃЌФЧОЭЪЧЛсеМгУБШЪЕМЪашвЊЖрвЛБЖЕФЗўЮёЦїзїЮЊЯТДЮВПЪ№ЕФБИгУЛњЦїЁЃ
вЛаЉЧАЖЫЗўЮёПЩФмЛсЪєгкетРрЧщПіЃЌЮвУЧвВаэВЛЯЃЭћдкЩ§МЖЕФЙ§ГЬжаЃЌвЛВПЗжгУЛЇПДЕНЪЧаТЕФвГУцЃЌСэвЛВПЗжПДЕНЛЙЪЧОЩЕФвГУцЁЃСэЭтЖдгкNginxетРрИКдиОљКтЙЄОпЃЌКѓЖЫЗўЮёЕФНЁПЕМьВщВЂЗЧЪЧЪЕЪБЩњаЇЕФЃЌгаПЩФмГіЯжЗўЮёвбОРыЯпЃЌЕЋЧыЧѓШдШЛБЛЗжЗЂЕНетИіжїЛњЕФЧщПіЃЌвђДЫВЩгУИКдиОљКтзїЮЊИпПЩгУЗНАИЕФЗўЮёЃЌРЖТЬВПЪ№вВЪЧБШНЯПЩШЁЕФЗНЪНЁЃ
ШчЙћЗўЮёЕФЪ§СПБШНЯЖрЃЌВЂЧвдЪаэЭЌЪБДцдкСНИідЫааЕФАцБОЃЌФЧУДВЩгУЕнНјЪНЩ§МЖЗНЪНдђЛсИќМгНкЪЁзЪдДЁЃвдУПДЮЩ§МЖвЛИіНкЕуЕФЕнНјЗНЪНЮЊР§ЃЌЕБЩ§МЖПЊЪМКѓЃЌЮвУЧЪзЯШЭЃжЙЫљгаЗўЮёНкЕужаЕФШЮвтвЛИіЃЌНЋЫќНјааЩ§МЖЃЌШЛКѓШУЫќжиаТМгШыМЏШКЃЌНгзХДгЪЃЯТЕФЗўЮёНкЕуДгдйШЮвтбЁдёвЛИіЃЌжБЕНзюКѓвЛИіЗўЮёвВБЛЩ§МЖЭъГЩЁЃетИіЙ§ГЬВЛашвЊдіМгЖюЭтЕФЗўЮёЦїзЪдДЃЌжЛвЊД§Щ§МЖЕФЗўЮёОпгаСНИівдЩЯЕФНкЕуЃЌОЭВЛЛсЖдЗўЮёЕФећЬхЙІФмдьГЩжаЖЯЁЃЕнНјЪНЩ§МЖЕФЙ§ГЬШчЯТЭМЫљЪОЃК
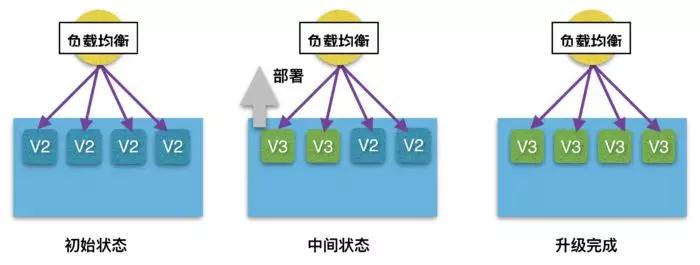
ЕнНјЪНЩ§МЖЕФЙ§ГЬ
ЯдШЛШчЙћЗўЮёБОЩэЪЧВЛФмБЛЫцЪБЭЃжЙЕФЃЌФЧУДетжжМђЕЅЕФЕнНјЩ§МЖОЭВЛФмКмКУЕФТњзуСЫЁЃДЫЪБЮвУЧашвЊЖдЗўЮёЕФЕїЖШНјааИЩЩцЃЌвдВЩгУЗўЮёЗЂЯжЕФИпПЩгУЗНЪНЮЊР§ЃЌЯТЭМеЙЪОСЫвЛжжЁКДјзДЬЌМьВщЕФЕнНјЪНЩ§МЖЁЛВпТдНјааЗўЮёВПЪ№ЁЃ
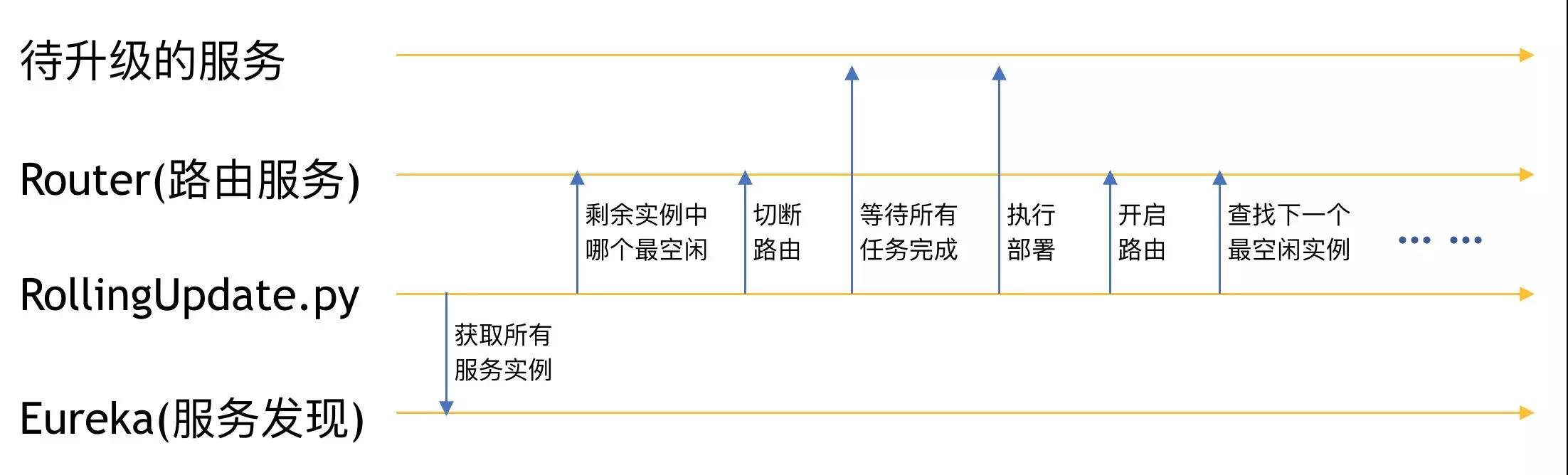
ДјзДЬЌМьВщЕФЕнНјЪНЩ§МЖ
етжжЩ§МЖЗНЗЈОпгаЦеЭЈЕнНјЪНЩ§МЖЕФЯрЫЦгХЪЦЃЌЕЋдкМЏШКжагаИіБ№ЗўЮёжДааШЮЮёЪБМфКмГЄЃЌЪМжеДІгкЁКдЫаажаЁЛзДЬЌЕФЧщПіЯТЃЌНЋЪЙЕУЩ§МЖЙ§ГЬзшШћЃЌДѓДѓЕФбгГЄЗўЮёВПЪ№ЕФЪБМфЁЃЪТЪЕЩЯЃЌГЄШЮЮёЕФЗўЮёЭЈГЃЖМПЩвдБЛИФдьГЩЮЊХњДІРэЪНЕФЗўЮёЃЈBatch-Task
ServiceЃЉЃЌХњДІРэЪНЗўЮёЕФЩ§МЖжЛашвЊжБНгНЋЗўЮёжДааЮФМўЬцЛЛЃЌДгИљБОЩЯМђЛЏСЫЩ§МЖФбЖШЁЃ
МрПиИцОЏ
ФкДцВЛзуЁЂДХХЬКФОЁЁЂЭјТчжаЖЯЁЂЗўЮёЪЇаЇЃЌетаЉЬьджШЫЛіЫцЪБПЩФмбъМАВњЦЗЕФЗўЮёМЏШКЁЃКмФбЯыЯѓЃЌдквЛИіХгДѓЕФЮЂЗўЮёЯЕЭГжаЃЌШчЙћУЛгаКЯЪЪЕФМрПиКЭИцОЏЩшЪЉЃЌЗўЮёЕФдЫгЊЛсБфЕУЖрУДЛьТвВЛПАЁЃ
ЖдЮЂЗўЮёЯЕЭГНјааМрПижївЊашвЊПМТЧСНИіЗНУцЃКЛљДЁЩшЪЉЕФМрПиКЭгІгУЗўЮёЕФМрПиЁЃ
ЛљДЁЩшЪЉЕФМрПиЭЈГЃгЩВПЪ№дкУПИіНкЕуЩЯЕФЪ§ОнВЩМЏЖЫЁЂМЏжаЪНЕФЪ§ОнЛуОлЖЫЁЂвдМАЪ§ОнеЙЪОЁЂЪ§ОнЗжЮіКЭИцОЏЭЈжЊЕШВПЗжзщГЩЁЃЖјМрПиИцОЏЯЕЭГЕФЪЕЪЉжаЃЌЛЙашвЊНсКЯЭХЖгЕФдЫЮЌздЖЏЛЏФмСІЃЌбЁдёКЯЪЪЕФММЪѕеЛНјааЁЃПЊдДЕФPromethusКЭInfluxDBЖМЪЧжЕЕУПМТЧЕФЙЄОпЁЃ
гІгУЗўЮёЕФМрПиЭЈГЃашвЊвРОнОпЬхЕФПЊЗЂММЪѕеЛНјаабЁдёЃЌР§ШчJava Spring BootЕФЗўЮёПЩвдгУSpring
Boot AdminЁЂNodejsЕФЗўЮёдђПЩгУnode-monitorКЭpm2ЕШЃЌДЫЭтвВгавЛаЉЭЈгУЕФПЊдДЙЄОпЃЌР§ШчMonitЁЃгІгУЗўЮёЕФМрПиГ§СЫашвЊФмЙЛБШНЯКУЭъГЩЙЪеЯЕФИцОЏЭтЃЌвЛаЉМрПиЙЄОпЛЙФмГЂЪдздЖЏЛжИДЙЪеЯЗўЮёЕФдЫааЃЌетаЉДыЪЉЖМФмгааЇЕФдіМгЗўЮёЕФПЩППадЁЃ
ШнЦїЛЏ
ШнЦїЪЧвЛжжФмЙЛМгЫйДйНјЭХЖгDevOpsЫЎЦНЕФащФтЛЏММЪѕЁЃЫќЭЈЙ§АбЗўЮёКЭЯЕЭГвРРЕШЋСПДђАќЕФОЕЯёИёЪНЃЌНЋдЫааЛЗОГЕФЩшМЦЬсЧАЕНСЫПЊЗЂНзЖЮЃЌВЂЧвЪЕЯжСЫПЊЗЂЁЂВтЪдЁЂЯпЩЯЛЗОГЕФИпЖШвЛжТЁЃгЩгкШнЦїЦСБЮСЫВЛЭЌЗўЮёдЫааЪБЕФВювьадЃЌЪЙЕУЛљгкетжжЗНЪННјааЗўЮёЕФДѓЙцФЃВПЪ№КЭЕїЖШБфЕУМђЕЅЁЃОпЬхРДЫЕЬхЯждквдЯТМИИіЗНУцЃКЪзЯШЪЧдЫааЛЗОГЕФИєРыЁЃдкащФтЛњЪБДњЃЌгЩгкУПИівЕЮёвРРЕЕФЯЕЭГЛЗОГВЛЭЌЃЌЗўЮёЦїжЎМфЮоЗЈЭЈгУЁЃИїИівЕЮёЖМашвЊЖРСЂЙмРэЗўЮёдЫааЛЗОГЃЌЛЙЭљЭљдьГЩЖрИіЗўЮёЭЌЪБдЫааЕФГхЭЛЃЌКЭИїИідЫааЛЗОГВЛвЛжТЕШЮЪЬтЁЃШнЦїЮЊУПИіЗўЮёЬсЙЉИєРыЕФдЫааЛЗОГЃЌМДЪЙдкЭЌвЛИіЗўЮёЦїЩЯдЫааЖржждЫааЪБЯрЛЅгаГхЭЛЕФЗўЮёвВВЛЛсГіЮЪЬтЁЃ
ЦфДЮЪЧОЋЯИЕФзЪдДЗжХфЁЃЭЈЙ§ащФтЛњЗжХфЗўЮёзЪдДЪБЃЌЮЊСЫМђЛЏЙмРэЃЌЭЈГЃВЛТлЗўЮёЪЕМЪЪЙгУЖрЩйCPUКЭФкДцзЪдДЃЌЖМжЛФмДгЙЬЖЈЕФжїЛњРраЭжаЬєбЁвЛжжЃЌАДжїЛњЕФИіЪ§МЦЗбЁЃШнЦїФмЙЛКмКУЕФЪЕЯжУцЯђзЪдДГиЕФЗўЮёЙмРэЃЌИїИіЗўЮёПЩвдИљОнВЂЗЂНјГЬЪ§ЁЂCPUКЭФкДцгУСПЕШзЪдДМЦЗбЃЌЪЕЯжИќМгОЋЯИЕФзЪдДЙмРэЁЃ
ДЫЭтЃЌШнЦїЛЙгаРћгкзЪдДЕФЖЏЬЌЕїећЁЃЙ§ШЅЦѓвЕРяЕФЗўЮёЦїзЪдДвЛАуЪЧАДМЦЛЎЗжХфЕФЃЌгаЕФВПУХЮЊСЫБмПЊЗБЫіЕФзЪдДЩъЧыСїГЬЃЌвЛДЮадЩъЧыДѓСПзЪдДЖкЛ§БИгУЃЌдьГЩРЫЗбЁЃШнЦїЕФУцЯђзЪдДГиЬиадЃЌЪЙЕУЦѓвЕФмЙЛНЋЫљгаМЦЫузЪдДНјаадЫааЪБЖЏЬЌЕїећЃЌЪЕЯжАДМЦЛЎЗжХфЕНАДашЗжХфЕФзЊБфЁЃвЕЮёжЛашЪЪгІСїСПИКдиЕФБфЛЏЁЃдкИКдиИпЗхЦкПьЫйдіМгзЪдДЃЌБЃжЄвЕЮёЗўЮёжЪСПЃЌдкИКдиЕЭЗхЦкЪЭЗХзЪдДИјЦфЫќЗўЮёЃЌЬсИпМЏШКзЪдДРћгУТЪЁЃ
ШнЦїНЋВПЪ№ЁЂдЫааЕФЗНЪНКЭвЕЮёКмКУЕФНјааСЫНтёюЃЌФПЧАвбОгааэЖрГЩЪьЕФЛљгкШнЦїЩшМЦЕФПЊдДЕїЖШПђМмЃЌР§ШчSwarmKitЁЂKubernetesЁЂMesosЁЂRancherЕШЁЃгЩгкЮЂЗўЮёМмЙЙЬьЩњОпгаМЏШКЕФЬиадЃЌВЩгУетаЉПђМмФмЙЛМЋДѓЕФМђЛЏЗўЮёВПЪ№КЭдЫЮЌЕФЙЄзїСПЁЃ
аЁНс
ГЩЙІЕФЪЕЪЉЮЂЗўЮёМмЙЙашвЊЩшМЦЕФВЛНіНіЪЧМмЙЙБОЩэЃЌЛЙгаЮЇШЦећИіЗўЮёМЏШКЕФЫљгаЛљДЁЩшЪЉКЭЭХЖгЕФзджїадЮФЛЏЁЃДгЪЕМљЕФНЧЖШЩЯЫЕЃЌБОЮФЫљЬсЕНЕФетаЉЗНУцвВдЖВЛЪЧЮЂЗўЮёЫљашвЊПМТЧЕФШЋВПЁЃЛЙгаКмЖрУЛгаЬсЕНЕФЪЕМљЃЌЭЌбљЪЧжЕЕУВЩФЩЕФЃЌжЛЪЧЫќУЧЯрЖдЖјбдВЂЗЧФЧУДвЊНєЁЃБШШчЛвЖШЗЂВМЃЌдкЮЂЗўЮёЬхЯЕжавВОпгаКмДѓЕФдЫгУПеМфЁЃ
УПвЛИіОЋаФЩшМЦЕФЦѓвЕМЖМмЙЙБГКѓЃЌЖМдЬКЌСЫЯрЕБЕФИДдгадЃЌЮЂЗўЮёврЪЧШчДЫЁЃгХауЕФМмЙЙВЂВЛФмШУШэМўЕФИДдгЖШЦОПеЯћЪЇЃЌЖјЪЧЭЈЙ§ИќМгКЯРэЕФВ№ЗжКЭдМЪјЃЌЪЙЕУШэМўНсЙЙИќМгШнвзЦЅХфвЕЮёЁЂЪЪгІБфЛЏЃЌДгЖјдкЙцФЃЛЏЕФЭЌЪББЃГжИпЖШЕФЯьгІСІЁЃМмЙЙВЛЪЧвјЕЏЃЌРыПЊСЫБивЊЕФЪЕМљЧАЬсЃЌПеЬИЮЂЗўЮёЃЌгЬШчЖЋЪЉаЇђЃЌЦкЭћВ№СЫЗўЮёОЭФмЮЊЦѓвЕДјРДЪмвцЃЌЮовЩгкПежаТЅИѓЕФаІЛАЖјвбЁЃ
|









