| БрМЭЦМі: |
| БОЮФРДздгкcnblogs
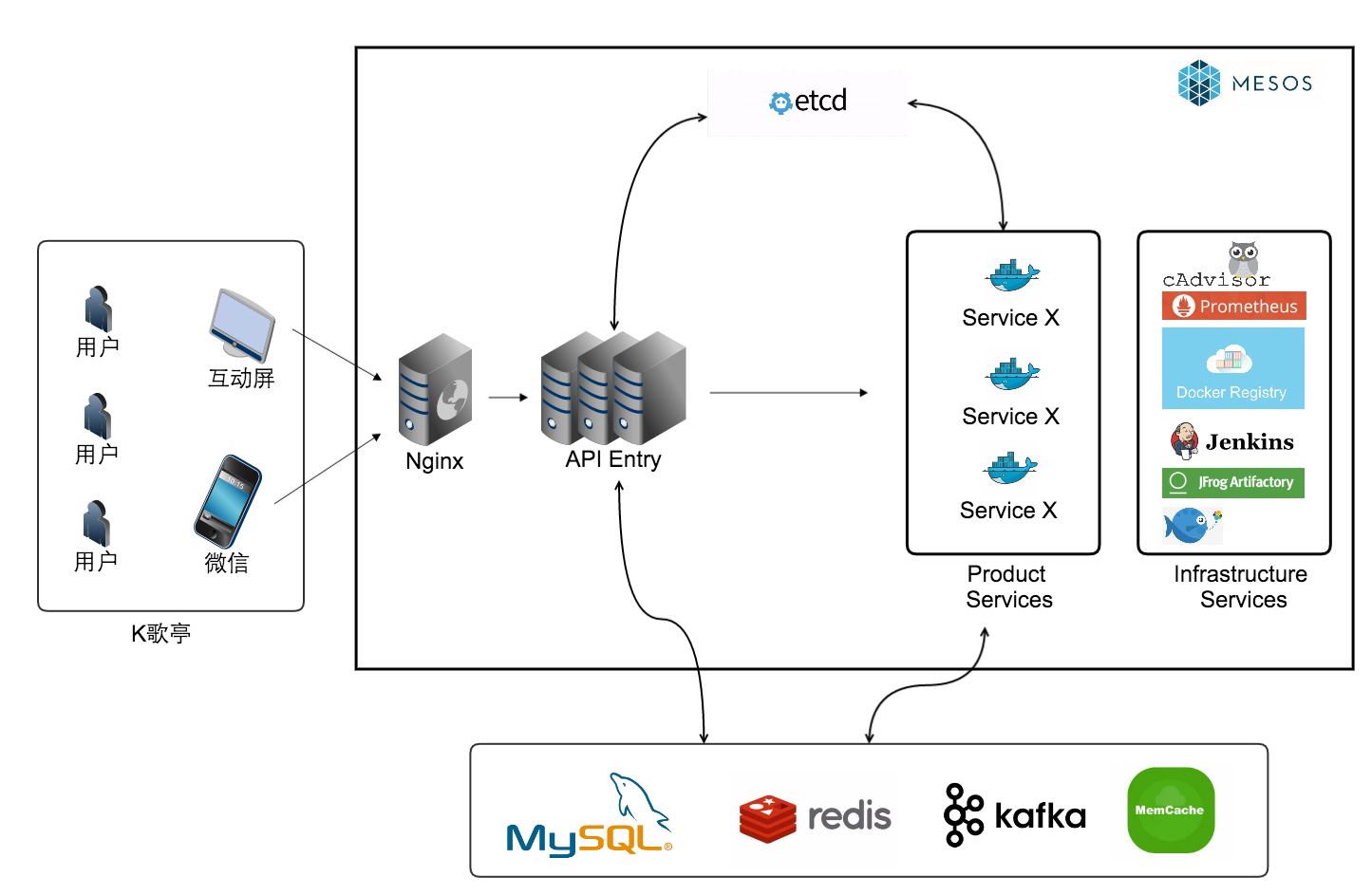
ЃЌНщЩмСЫвЕЮёМмЙЙЃКДгЕЅЬхЪНЕНЮЂЗўЮёЃЌЯЕЭГМмЙЙЕФЙЙЫМгыНтЖСЛљгкMesos+MarathonЕФCI/CDЕШЁЃ |
|
1ЁЂвЕЮёМмЙЙЃКДгЕЅЬхЪНЕНЮЂЗўЮё
KИшЭЄЪЧГЊАЩЕФвЛЬѕаТвЕЮёЯпЃЌжМдкЬсЙЉЯпЯТБуНнЕФПьВЭЪНKИшЗНЪНЃЌгУЛЇПЩвддквЛИіЕчЛАЭЄДѓаЁЕФПеМфРяЭъГЩKИшЬхбщЁЃKИшЭЄдкПЭЛЇЖЫгаVODЁЂЮЂаХКЭWebЙВШ§ИіНЛЛЅШыПкЃЌвЕЮёИДдгЖШНЯИпЃЌШчГЄСЌНгГиЗўЮёЁЂгУЛЇЯЕЭГЗўЮёЁЂЩЬЛЇЯЕЭГЁЂдіСПИќаТЗўЮёЁЂERPЕШЁЃЖдгкЗўЮёЖЫЕФЮШЖЈадвЊЧѓвВКмИпЃЌвђЮЊKИшЭЄАкЗХЕиЕуВЛЙЬЖЈЃЌКмЖрГЁЫљЕФдЫгЊЛюЖЏЛсдьГЩЭЛЗЂСїСПЁЃ
ЮЊСЫПьЫйПЊЗЂЩЯЯпЃЌKИшЭЄЯюФПзюГѕВЩгУЕФЪЧДЋЭГЕФЕЅЬхЪНМмЙЙЃЌЕЋЪЧЫцзХЪБМфЕФЭЦвЦЃЌашЧѓЕФЕќДњЫйЖШБфЕУКмПьЃЌДњТыШпгрБфЖрЃЌОГЃЛсГіЯжЧЃвЛЗЂЖЏШЋЩэЕФИФЖЏЁЃжиЙЙВЛЕЋЛсЛЈЗбДѓСПЕФЪБМфЃЌЖјЧвЖддЫЮЌКЭЮШЖЈадвВЛсдьГЩКмДѓЕФбЙСІЃЛДЫЭтЃЌДњТыЕФёюКЯЖШИпЃЌаТШЫЩЯЪжНЯРЇФбЃЌЭљЭљашвЊЭЈЖСДѓСПДњТыВХВЛЛсВШНјПгРяЁЃ
МјгкЩЯЪіБзЖЫЃЌЮвУЧОіЖЈНгЯТРДЕФАцБОРяВЩгУЮЂЗўЮёЕФМмЙЙФЃаЭЁЃДгЕЅЬхЪННсЙЙзЊЯђЮЂЗўЮёМмЙЙжаЛсГжајХіЕНЗўЮёБпНчЛЎЗжЕФЮЪЬтЃКБШШчЃЌЮвУЧгаuserЗўЮёРДЬсЙЉгУЛЇЕФЛљДЁаХЯЂЃЌФЧУДгУЛЇЕФЭЗЯёКЭЭМЦЌЕШЪЧгІИУЕЅЖРЛЎЗжЮЊвЛИіаТЕФserviceИќКУЛЙЪЧгІИУКЯВЂЕНuserЗўЮёРяФиЃПШчЙћЗўЮёЕФСЃЖШЛЎЗжЕФЙ§ДжЃЌФЧОЭЛиЕНСЫЕЅЬхЪНЕФРЯТЗЃЛШчЙћЙ§ЯИЃЌФЧЗўЮёМфЕїгУЕФПЊЯњОЭБфЕУВЛПЩКіЪгСЫЃЌЙмРэФбЖШвВЛсжИЪ§МЖдіМгЁЃФПЧАЮЊжЙЛЙУЛгавЛИіПЩвдГЦжЎЮЊЗўЮёБпНчЛЎЗжЕФБъзМЃЌжЛФмИљОнВЛЭЌЕФвЕЮёЯЕЭГМгвдЕїНкЃЌФПЧАKИшЭЄВ№ЗжЕФДѓддђЪЧЕБвЛПщвЕЮёВЛвРРЕЛђМЋЩйвРРЕЦфЫќЗўЮёЃЌгаЖРСЂЕФвЕЮёгявхЃЌЮЊГЌЙ§2ИіЕФЦфЫћЗўЮёЛђПЭЛЇЖЫЬсЙЉЪ§ОнЃЌФЧУДЫќОЭгІИУБЛВ№ЗжГЩвЛИіЖРСЂЕФЗўЮёФЃПщЁЃ
дкВЩгУСЫЮЂЗўЮёМмЙЙжЎКѓЃЌЮвУЧОЭПЩвдЖЏЬЌЕїНкЗўЮёЕФзЪдДЗжХфДгЖјгІЖдбЙСІЁЂЗўЮёзджЮЁЂПЩЖРСЂВПЪ№ЁЂЗўЮёМфНтёюЁЃПЊЗЂШЫдБПЩвдздгЩбЁдёздМКПЊЗЂЗўЮёЕФгябдКЭДцДЂНсЙЙЕШЃЌФПЧАећЬхЩЯЪЙгУPHPзіЛљДЁЕФWebЗўЮёКЭНгПкВуЃЌЪЙгУGoгябдРДзіГЄСЌНгГиЕШЦфЫћКЫаФЗўЮёЃЌЗўЮёМфВЩгУthriftРДзіRPCНЛЛЅЁЃ
2ЁЂЯЕЭГМмЙЙЕФЙЙЫМгыНтЖС
2.1 ШнЦїБрХХ
ГЊАЩKИшЭЄЕФЮЂЗўЮёМмЙЙВЩгУСЫMesosКЭMarathonзїЮЊШнЦїБрХХЕФЙЄОпЁЃдкЮвУЧбЁаЭГѕЦкЕФЪБКђЛЙгаШ§ИіЦфЫћбЁдёЃЌKubernetesЁЂ
SwarmЁЂ DC/OSЃК
DC/OSЃКзїЮЊMesosphereЙЋЫОЕФШЭЗВњЦЗЃЌЛљБОЩЯЪЧЯЃЭћвЛЭГЬьЯТЕФНкзрЁЃЫљвдзщМўКмЖрЃЌЙІФмвВКмШЋУцЁЃЕЋЪЧЖдгкЮвУЧдкНјааЮЂЗўЮёМмЙЙГѕЦкЃЌЙІФмЙ§гкХгДѓЃЌбЇЯАГЩБОБШНЯИпЃЌКѓЦкЕФЩњВњЛЗОГЮЌЛЄбЙСІвВБШНЯДѓЁЃ
SwarmЃКDockerЙЋЫОздМКзіЕФШнЦїБрХХЙЄОпЃЌЕБЪБСЫНтЕН100ИівдЩЯЮяРэНкЕуЛсгаЮоЯьгІЕФЧщПіЃЌЖдгкЮШЖЈадгавЛаЉЕЃгЧЁЃ
KubernetesЃКGoogleПЊдДЕФЕФШнЦїБрХХЙЄОпЃЌдкбЁаЭГѕЦкЛЙУЛгаКмЖрЙЋЫОЪЙгУЕФАИР§ЃЌЭЌЪБвВЬ§ЕНСЫКмЖрЙигкЮШЖЈадЕФЩљвєЃЌЫљвдУЛгаПМТЧЁЃЕЋЪЧдкећИі2016ФъЃЌдНРДдНЖрЕФЙЋЫОПЊЪМдкЯпЩЯЪЙгУKubernetesЃЌЦфЮШЖЈадж№ВНЬсИпЃЌШчЙћдйбЁаЭгІИУвВЪЧИіКУбЁдёЁЃ
MesosЃКвђЮЊСЫНтЕНTwitterвбОАбMesosгУгкЩњВњЛЗОГЃЌВЂЧвИаОѕМмЙЙКЭЙІФмвВЯрЖдМђЕЅЃЌЫљвдзюКѓбЁдёСЫMesos+MarathonзїЮЊШнЦїБрХХЕФЙЄОпЁЃ
2.2 ЗўЮёЗЂЯж
ЮвУЧВЩгУСЫetcdзїЮЊЗўЮёЗЂЯжЕФзщМўЃЌetcdЪЧвЛИіИпПЩгУЕФЗжВМЪНЛЗОГЯТЕФ key/value
ДцДЂЗўЮёЁЃдкetcdжаЃЌДцДЂЪЧвдЪїаЮНсЙЙРДЪЕЯжЕФЃЌЗЧвЖНсЕуЖЈвхЮЊЮФМўМаЃЌвЖНсЕудђЪЧЮФМўЁЃЮвУЧдМЖЈУПИіЗўЮёЕФИљТЗОЖЮЊ/v2/keys/service/$service_name/ЃЌУПИіЗўЮёЪЕР§ЕФЪЕМЪЕижЗдђДцДЂгквдЗўЮёЪЕР§ЕФuuidЮЊЮФМўУћЕФЮФМўжаЃЌБШШчеЫЛЇЗўЮёaccount
serviceЕБЧАЦєЖЏСЫ3ИіПЩвдЪЕР§ЃЌФЧУДЫќдкetcdжаЕФБэЯжаЮЪНдђШчЯТЭМ:
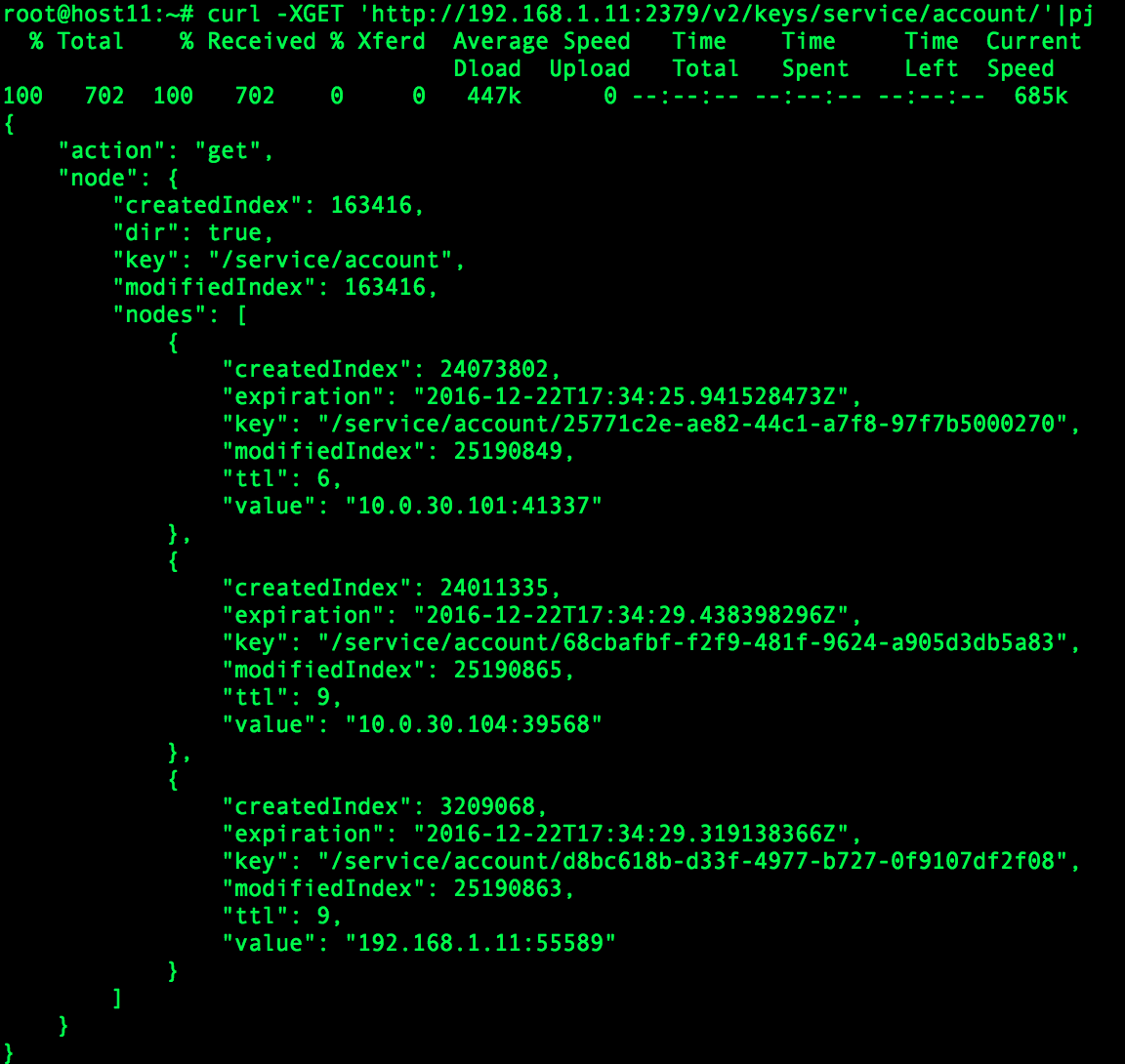
ЕБвЛИіЗўЮёЪЕР§ЯђetcdаДШыЕижЗГЩЙІЪБЮвУЧОЭПЩвдШЯЮЊЕБЧАЗўЮёЪЕР§вбОзЂВсГЩЙІЃЌФЧУДЕБетИіЗўЮёЪЕР§гЩгкжжжждвђdownЕєСЫжЎКѓЃЌЗўЮёЕижЗздШЛвВашвЊЪЇаЇЃЌФЧУДдкetcdжавЊШчКЮЪЕЯжФиЃП
зЂвтЃЌЭМжаЕФУПИіЮФМўгавЛИіttlжЕЃЌЕЅЮЛЪЧУыЃЌЕБttlЕФжЕЮЊ0ЪБЖдгІЕФЮФМўНЋЛсБЛetcdздЖЏЩОГ§ЁЃЕБУПИіЗўЮёЪЕР§ЦєЖЏжЎКѓЕквЛДЮзЂВсЪБЛсАбДцЛюЪБМфМДttlжЕГѕЪМЛЏЮЊ10sЃЌШЛКѓУПИєвЛЖЮЪБМфШЅЫЂаТttlЃЌгУРДЯёЯђetcdЛуБЈздМКЕФДцЛюЃЌБШШч7sЃЌдкетжжЧщПіЯТЛљБОЩЯПЩвдБЃжЄЗўЮёгааЇадЕФИќаТЕФМАЪБадЁЃШчЙћдквЛИіttlФкЗўЮёdownЕєСЫЃЌдђЛсга10sжгЕФЪБМфЪЧЗўЮёЕижЗгааЇЃЛЖјЗўЮёБОЩэВЛПЩгУЃЌетОЭашвЊЗўЮёЕФЕїгУЗНзіЯргІЕФДІРэЃЌБШШчжиЪдЛђетбЁдёЦфЫќЗўЮёЪЕР§ЕижЗЁЃ
ЮвУЧЗўЮёЗЂЯжЕФЛњжЦЪЧУПИіЗўЮёздзЂВсЃЌМДУПИіЗўЮёЦєЖЏЕФЪБКђЯШЕУЕНЫожїЛњЦїЩЯУцЕФПеЯаЖЫПкЃЛШЛКѓЫцЛњвЛИіЛђЖрИіИјздМКВЂМрЬ§ЃЌЕБЗўЮёЦєЖЏЭъБЯЪБПЊЪМЯђetcdМЏШКзЂВсздМКЕФЗўЮёЕижЗЃЌЖјЗўЮёЕФЪЙгУепдђДгetcdжаЛёШЁЫљашЗўЮёЕФЫљгаПЩгУЕижЗЃЌДгЖјЪЕЯжЗўЮёЗЂЯжЁЃ
ЭЌЪБЃЌЮвУЧетбљЕФЛњжЦвВЮЊШнЦївдHOSTЕФЭјТчФЃЪНЦєЖЏЬсЙЉСЫБЃжЄЁЃвђЮЊBRIDGEФЃЪНШЗЪЕЖдгкЭјТчЕФЫ№КФЬЋДѓЃЌдкзюПЊЪМОЭБЛЮвУЧЗёОіСЫЃЌВЩгУСЫHOSTФЃЪНжЎКѓЭјТчЗНУцЕФгАЯьШЗЪЕВЛЪЧКмДѓЁЃ
2.3 МрПиЃЌШежОгыБЈОЏ
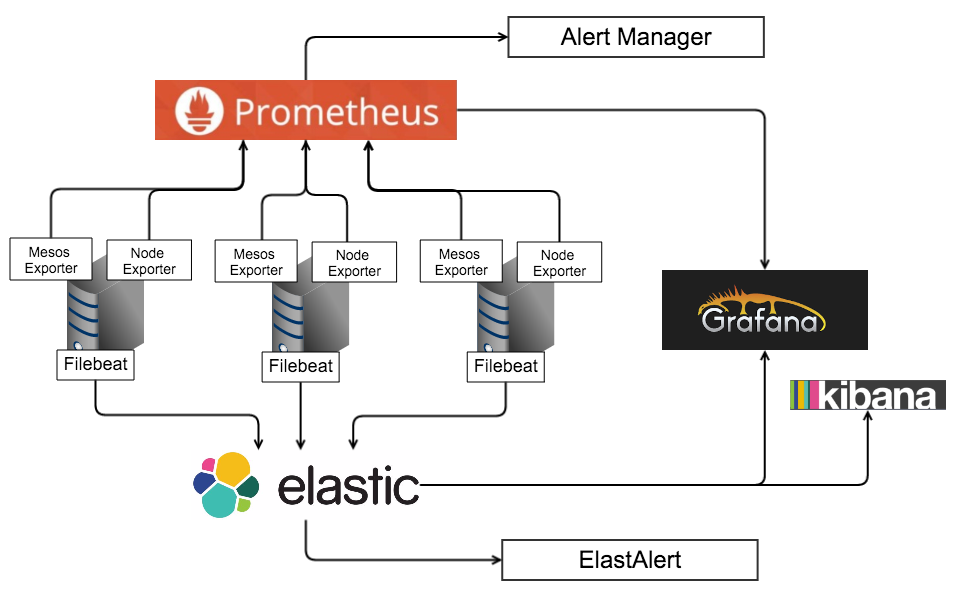
ЮвУЧбЁдёPrometheusЛузмМрПиЪ§ОнЃЌгУElasticSearchЛузмШежОЃЌжївЊЕФдвђгаЃК
1.ЩњЬЌЯрЖдГЩЪьЃЌЯрЙиЮФЕЕКмШЋУцЃЌДгЭЈгУЕФЕНзЈгУЕФИїжжexporterвВКмЗсИЛЁЃ
2.ВщбЏгяОфКЭХфжУМђЕЅвзЩЯЪжЁЃ
3.дЩњОпгаЗжВМЪНЪєадЁЃ
4.ЫљгазщМўЖМПЩвдВПЪ№дкDockerШнЦїФкЁЃ
Mesos ExporterЃЌЪЧPrometheusПЊдДЕФЯюФПЃЌПЩвдгУРДЪеМЏШнЦїЕФИїЯюдЫаажИБъЁЃЮвУЧжївЊЪЙгУСЫЖдгкDockerШнЦїЕФМрПиетВПЗжЙІФмЃЌеыЖдУПИіЗўЮёЦєЖЏЕФШнЦїЪ§СПЃЌУПИіЫожїЛњЩЯЦєЖЏЕФШнЦїЪ§СПЃЌУПИіШнЦїЕФCPUЁЂФкДцЁЂЭјТчIOЁЂДХХЬIOЕШЁЃВЂЧвБОЩэЫћЯћКФЕФзЪдДвВКмЩйЃЌУПИіШнЦїЗжХф0.2CPUЃЌ128MBФкДцвВКСЮобЙСІЁЃ
дкбЁдёMesos ExporterжЎЧАЃЌЮвУЧвВПМТЧЙ§ЪЙгУcAdvisorЁЃcAdvisorЪЧвЛИіGoogleПЊдДЕФЯюФПЃЌИњMesos
ExporterЪеМЏЕФаХЯЂАЫГЩвдЩЯЖМЪЧРрЫЦЕФЃЛЖјЧввВПЩвдЭЈЙ§imageзжЖЮвВПЩвдБфЯрЪЕЯжЙиСЊЗўЮёгыШнЦїЃЌжЛЪЧMesos
exporterРяУцЕФsourceзжЖЮПЩвджБНгЙиСЊЕНmarathonЕФapplication idЃЌИќМгжБЙлвЛаЉЁЃЭЌЪБcAdvisorЛЙПЩвдЭГМЦвЛаЉздЖЈвхЪТМўЃЌЖјЮвУЧИќЖрЕФгУШежОШЅЪеМЏРрЫЦЪ§ОнЃЌдйМгЩЯMesos
ExporterвВПЩвдЭГМЦвЛаЉMesosБОЩэЕФжИБъЃЌБШШчвбЗжХфКЭЮДЗжХфЕФзЪдДЃЌЫљвдЮвУЧзюжебЁдёСЫMesos
ExporterЁЃ
ШчЯТЭМЃЌОЭЪЧЮвУЧМрПиЕФВПЗжШнЦїЯрЙижИБъдкGrafanaЩЯУцЕФеЙЪОЃК
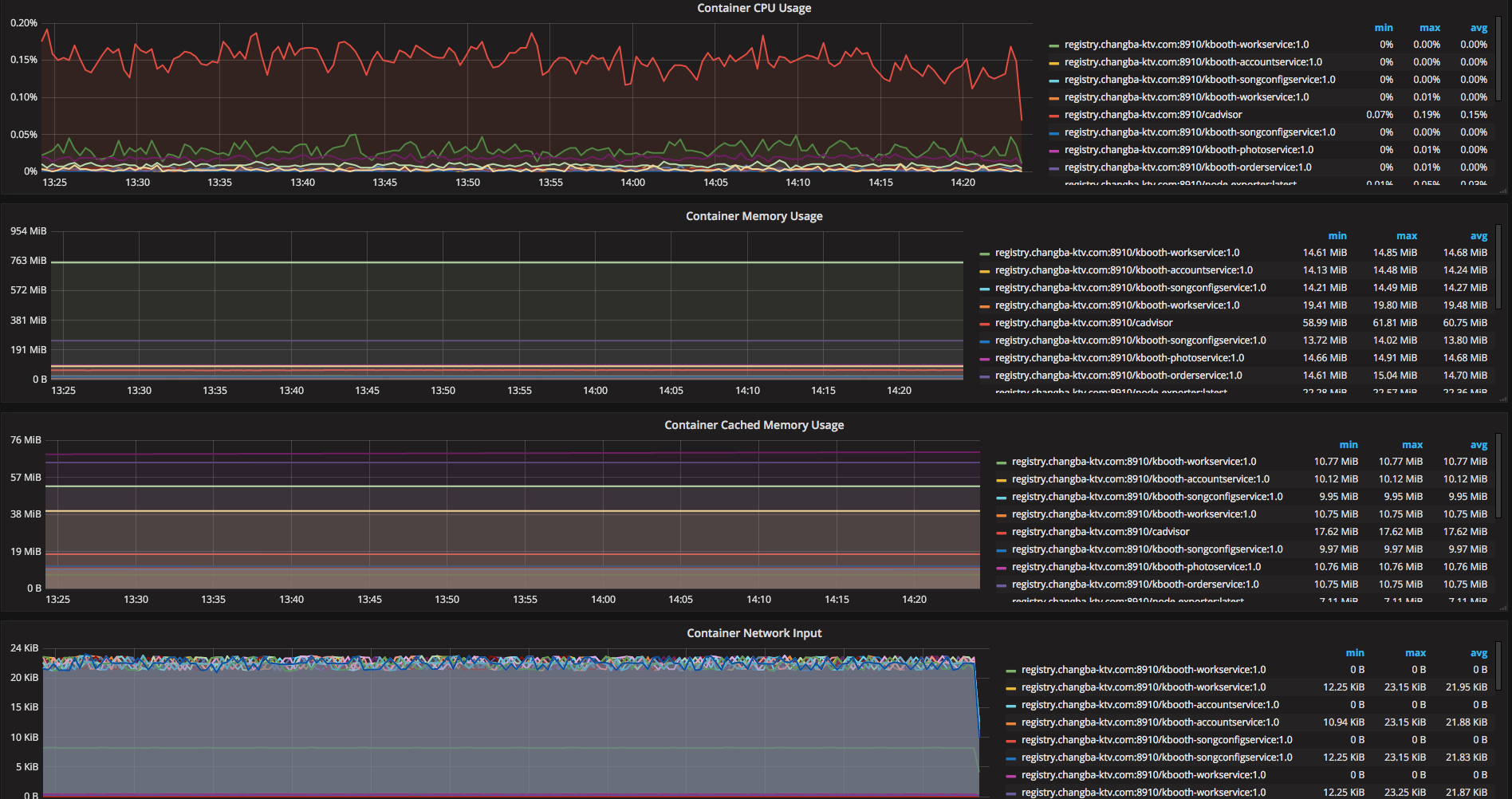
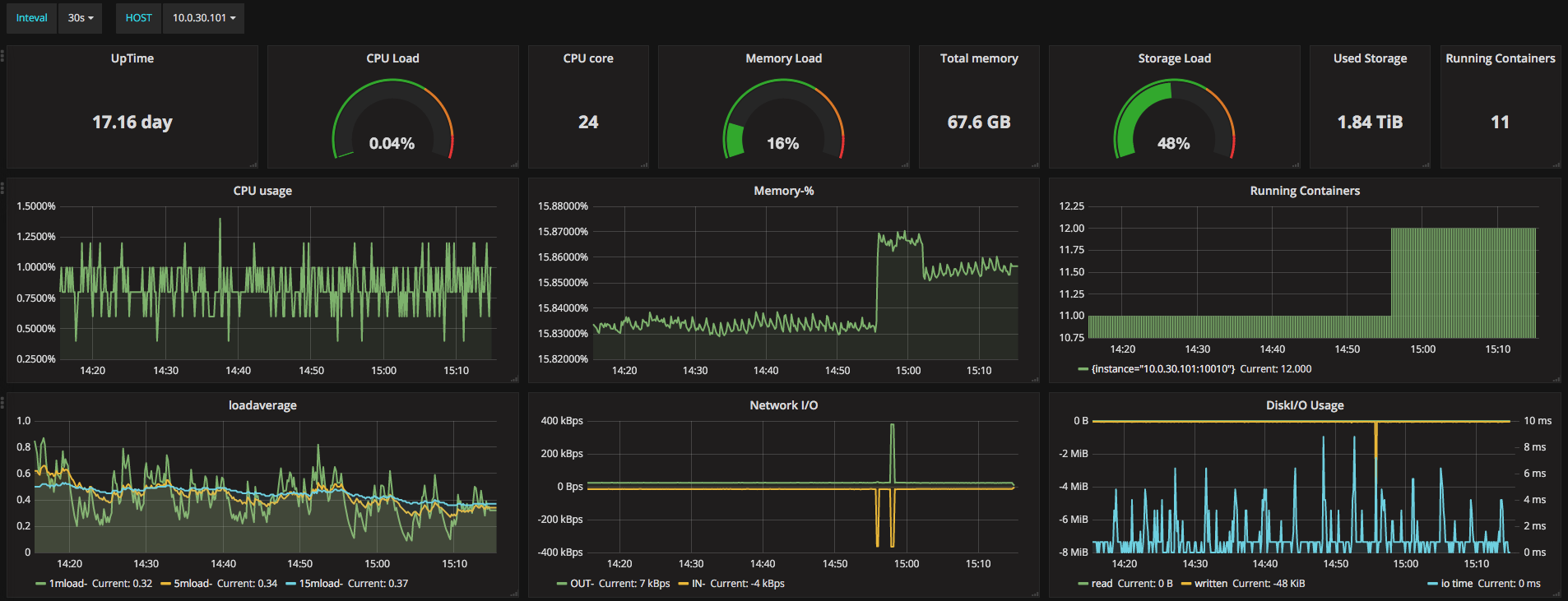
Node exporterЃЌЪЧPrometheusПЊдДЕФЯюФПЃЌгУРДЪеМЏЮяРэЛњЦїЩЯУцЕФИїЯюжИБъЁЃжЎЧАвЛжБЪЙгУZabbixРДМрПиЮяРэЛњЦїЕФИїЯюжИБъЃЌетДЮЪЙгУNodeExporter+PrometheusжївЊЪЧГігкаЇТЪКЭЖдгкШнЦїЩњЬЌЕФжЇГжСНЗНУцПМТЧЁЃЪБађЪ§ОнПтдкМрПиЪ§ОнЕФДцДЂКЭВщбЏЕФаЇТЪЗНУцНЯЙиЯЕЪ§ОнПтЕФгХЪЦШЗЪЕЗЧГЃУїЯдЃЌОпЬхеЙЪОдкGrafanaЩЯУцШчЯТЭМЃК
FilebeatЪЧгУРДЬцЛЛLogstash-forwarderЕФШежОЪеМЏзщМўЃЌПЩвдЪеМЏЫожїЛњЩЯУцЕФИїжжШежОЁЃЮвУЧЫљгаЕФЗўЮёЖМЛсЙвдиЫожїЛњЕФБОЕиТЗОЖЃЌУПИіЗўЮёШнЦїЕФЛсАбздМКЕФGUIDаДШыШежОРДЧјЗжРДдДЁЃШежООгЩElasticSearchЛузмжЎКѓЃЌОлКЯЕФDashboardЮвУЧЭГвЛЖМЛсЗХдкGrafanaЩЯУцЃЌОпЬхХХВщЯпЩЯЮЪЬтЕФЪБКђЃЌЛсгУKibanaШЅВщПДШежОЁЃ
PrometheusХфжУКУСЫБЈОЏжЎКѓПЩвдЭЈЙ§AlertManagerЗЂЫЭЃЌЕЋЪЧЖдгкБЈОЏЕФОлКЯЕФжЇГжЛЙЪЧКмШѕЕФЁЃдкЯТвЛНзЖЮЮвУЧЛсв§ШывЛаЉMessage
QueueРДздМКЕФБЈОЏЯЕЭГЃЌМгЧПЖдгкБЈОЏЕФОлКЯКЭДІРэЁЃ
ElastAlertЪЧYelpЕФвЛИіPythonПЊдДЯюФПЃЌжївЊЕФЙІФмЪЧЖЈЪБТжбЏElasticSearchЕФAPIРДЗЂЯжЪЧЗёДяЕНБЈОЏЕФСйНчжЕЃЌЫќЕФвЛИіЬиЩЋЪЧдЄЖЈвхСЫИїжжБЈОЏЕФРраЭЃЌБШШчfrequencyЁЂchangeЁЂflatlineЁЂcardinalityЕШЃЌЗЧГЃСщЛюЃЌвВНкЪЁСЫЮвУЧКмЖрЖўДЮПЊЗЂЕФГЩБОЁЃ
2.4 ЪТЮёзЗзйЯЕЭГЁЊЁЊKTrace
ЖдгквЛЬзЮЂЗўЮёЕФЯЕЭГНсЙЙРДЫЕЃЌзюДѓЕФФбЕуВЂВЛЪЧЪЕМЪвЕЮёДњТыЕФБраДЃЌЖјЪЧЗўЮёЕФМрПиКЭЕїЪдвдМАШнЦїЕФБрХХЁЃЮЂЗўЮёЯрЖдгкЦфЫћЗжВМЪНМмЙЙЕФЩшМЦРДЫЕЛсАбЗўЮёЕФСЃЖШВ№ЕНИќаЁЃЌвЛДЮЧыЧѓЕФТЗОЖВуМЖЛсБШЦфЫћНсЙЙИќЩюЃЌЭЌвЛИіЗўЮёЕФЪЕР§ВПЪ№КмЗжЩЂЃЌЕБГіЯжСЫадФмЦПОБЛђепbugЪБШчКЮЕквЛЪБМфЖЈЮЛЮЪЬтЫљдкЕФНкЕуМЋЮЊживЊЃЌЫљвдЖдгкЮЂЗўЮёРДЫЕЃЌЭъЩЦЕФtraceЛњжЦЪЧЯЕЭГЕФКЫаФжЎвЛЁЃ
ФПЧАКмЖрГЇЩЬЪЙгУЕФtraceЖМЪЧВЮПМ2010ФъGoogleЗЂБэЕФвЛЦЊТлЮФЁЖDapper, a
Large-Scale Distributed Systems Tracing InfrastructureЁЗРДЪЕЯжЕФЃЌЦфжазюжјУћЕФЕБЪєtwitterЕФzipkinЃЌЙњФкЕФШчЬдБІЕФeagle
eyeЁЃгЩгкгУЛЇЙцФЃСПМЖЕФж№ФъЬсЩ§ЃЌЗжВМЪНЩшМЦЕФЯЕЭГРэФюдНРДдНЮЊИїГЇЩЬЫљНгЪмЃЌгкЪЧЕЎЩњСЫtraceЕФвЛИіЪЕЯжБъзМopentracing
ЃЌopentracingБъзМФПЧАжЇГжGoЁЂJavaScriptЁЂJavaЁЂ PythonЁЂObjective-CЁЂC++СљжжгябдЁЃ
гЩsourcegraphПЊдДЕФappdashЪЧвЛПюЧсСПМЖЕФЃЌжЇГжopentracingБъзМЕФПЊдДtraceзщМўЃЌЪЙгУGoгябдПЊЗЂKИшЭЄФПЧАЖдappdashНјааСЫЖўДЮПЊЗЂЃЌВЂНЋЦфзїЮЊЦфКѓЖЫtraceЗўЮёЃЈЯТЮФжБНгНЋЦфГЦжЎЮЊKtraceЃЉЃЌжївЊдвђЪЧappdashзуЙЛЧсСПЃЌаоИФЦ№РДБШНЯШнвзЁЃГЊАЩKИшЭЄвЕЮёЕФНКЫЎВуЪЙгУPHPРДЪЕЯжЃЌappdashЬсЙЉСЫЖдprotobufЕФжЇГжЃЌетбљжЛашвЊЮвУЧздМКдкPHPВуЪЕЯжmiddlewareМДПЩЁЃ
дкtraceЯЕЭГжагаШчЯТМИИіИХФю
ЃЈ1ЃЉAnnotation
вЛИіannotationЪЧгУРДМДЪБЕФМЧТМвЛИіЪТМўЕФЗЂЩњЃЌвдЯТЪЧвЛЯЕСадЄЖЈвхЕФгУРДМЧТМвЛДЮЧыЧѓПЊЪМКЭНсЪјЕФКЫаФannotation
1.cs - Client StartЁЃ ПЭЛЇЖЫЗЂЦ№вЛДЮЧыЧѓЪБМЧТМ
2.sr - Server ReceiveЁЃ ЗўЮёЦїЪеЕНЧыЧѓВЂПЊЪМДІРэЃЌsrКЭcsЕФВюжЕОЭЪЧЭјТчбгЪБКЭЪБжгЮѓВю
3.ss - Server Send: ЗўЮёЦїЭъГЩДІРэВЂЗЕЛиИјПЭЛЇЖЫЃЌssКЭsrЕФВюжЕОЭЪЧЪЕМЪЕФДІРэЪБГЄ
4.cr - Client Receive: ПЭЛЇЖЫЪеЕНЛиИДЪБНЈСЂЁЃ
БъжОзХвЛИіspanЕФНсЪјЁЃЮвУЧЭЈГЃШЯЮЊвЛЕЋcrБЛМЧТМСЫЃЌвЛИіRPCЕїгУвВОЭЭъГЩСЫЁЃ
ЦфЫћЕФannotationдђдкећИіЧыЧѓЕФЩњУќжмЦкРяНЈСЂвдМЧТМИќЖрЕФаХЯЂ ЁЃ
ЃЈ2ЃЉSpan
гЩЬиЖЈRPCЕФвЛЯЕСаannotationЙЙГЩSpanађСаЃЌspanМЧТМСЫКмЖрЬиЖЈаХЯЂШч traceIdЃЌ
spandIdЃЌ parentIdКЭRPC nameЁЃ
SpanЭЈГЃЖМКмаЁЃЌР§ШчађСаЛЏКѓЕФspanЭЈГЃЖМЪЧkbМЖБ№ЛђепИќаЁЁЃ ШчЙћspanГЌЙ§СЫkbСПМЖФЧОЭЛсгаКмЖрЦфЫћЕФЮЪЬтЃЌБШШчГЌЙ§СЫkafkaЕФЕЅЬѕЯћЯЂДѓаЁЯожЦ(1M)ЁЃ
ОЭЫуФуЬсИпkafkaЕФЯћЯЂДѓаЁЯожЦЃЌЙ§ДѓЕФspanвВЛсдіДѓПЊЯњЃЌНЕЕЭtraceЯЕЭГЕФПЩгУадЁЃ вђДЫЃЌжЛДцДЂФЧаЉФмБэЪОЯЕЭГааЮЊЕФаХЯЂМДПЩЁЃ
ЃЈ3ЃЉTrace
вЛИіtraceжаЫљгаЕФspanЖМЙВЯэвЛИіИљspanЃЌtraceОЭЪЧвЛИігЕгаЙВЭЌtraceidЕФspanЕФМЏКЯЃЌЫљгаЕФspanАДееspanidКЭИИspanidРДећКЯГЩЪїаЮЃЌДгЖјеЙЯжвЛДЮЧыЧѓЕФЕїгУСДЁЃ
ФПЧАУПДЮЧыЧѓгЩPHPЖЫЩњГЩtraceidЃЌВЂНЋspanаДШыKtraceЃЌбиЕїгУСДДЋЕнtraceidЃЌУПИіserviceздМКдкгаашвЊЕФЕиЗНТёЕуВЂаДШыKtraceЁЃОйР§ШчЯТЭМ:
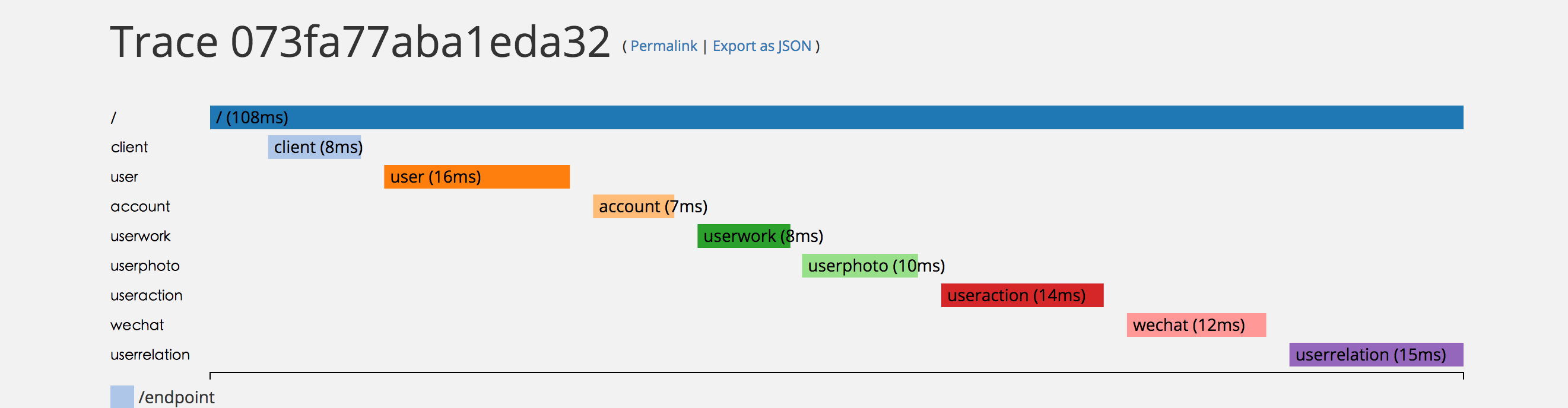
УПИіЩЋПщЪЧвЛИіspanЃЌБэУїСЫЪЕМЪЕФжДааЪБМфЃЌЭЈГЃЕФЕїгУВуМЖВЛЛсГЌЙ§10ЃЌЕуЛїspanдђЛсПДЕНУПИіspanРяЕФannotationМЧТМЕФКмЖрИНМгаХЯЂЃЌБШШчЗўЮёЪЕР§ЫљдкЕФЮяРэЛњЕФIPКЭЖЫПкЕШЃЌtraceЯЕЭГЕФЯћКФвЛАуВЛЛсЖдЯЕЭГЕФБэЯжгАЯьЬЋДѓЃЌЭЈГЃЧщПіЯТПЩвдКіТдЃЌЕЋЪЧЕБQPSКмИпЪБtraceЕФПЊЯњОЭвЊМгвдПМСПЃЌЭЈГЃЛсЕїећВЩбљТЪЛђепЪЙгУЯћЯЂЖгСаЕШРДвьВНДІРэЁЃВЛЙ§ЃЌвьВНДІРэЛсгАЯьtraceМЧТМЕФЪЕЪБадЃЌашвЊеыЖдВЛЭЌвЕЮёМгвдШЁЩсЁЃ
ФПЧАKИшЭЄдкЩњВњЛЗОГРяЕФQPSВЛГЌЙ§1kЃЌЫљвдДѓВПЗжЕФМЧТМЪЧжБНгаДЕНktraceРяЕФЃЌжЛгаИшЧњЫбЫїЗўЮёГЂЪдадЕФаДдкkafkaРяЃЌгЩmqcollectorЪеМЏВЂМЧТМЃЌktraceЕФДцДЂФПЧАжЛжЇГжMySQLЁЃвЛИіКУЕФtraceЩшМЦПЩвдМЋПьЕФАяФуЖЈЮЛЮЪЬтЃЌХаЖЯЯЕЭГЕФЦПОБЫљдкЁЃ
2.5 здЖЏРЉШн
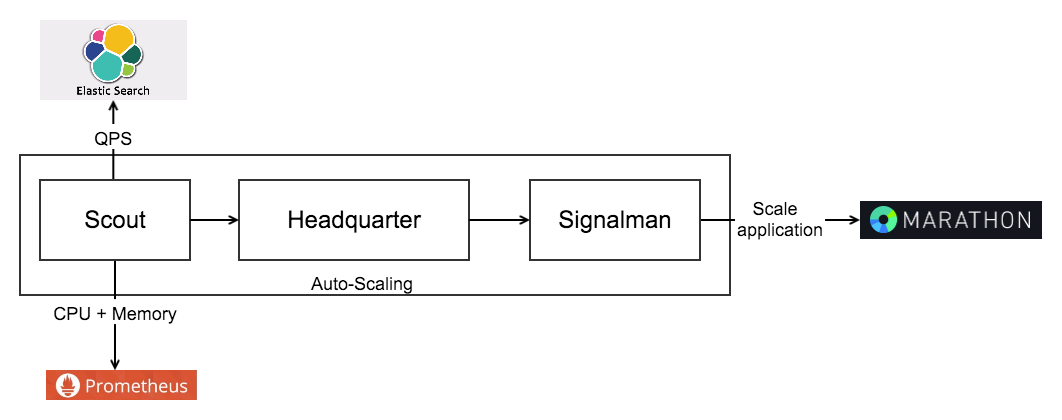
дкЗўЮёЗУЮЪЗхжЕЕФГіЯжЪБЃЌЭљЭљашвЊСйЪБРЉШнРДгІЖдИќЖрЕФЧыЧѓЁЃГ§СЫЪжЖЏЭЈЙ§MarathonдіМгШнЦїЪ§СПжЎЭтЃЌЮвУЧвВЩшМЦЪЕЯжСЫвЛЬзздЖЏРЉЫѕШнЕФЯЕЭГРДгІЖдЁЃЮвУЧРЉЫѕШнЕФДЅЗЂЛњжЦКмжБНгЃЌИљОнИїИіЗўЮёЕФQPSЁЂCPUеМгУЁЂФкДцеМгУетШ§ИіжИБъРДКтСПЃЌШчЙћШ§ИіжИБъгаСНИіжИБъДяЕНЃЌМДЦєЖЏздЖЏРЉШнЁЃЮвУЧЕФздЖЏРЉШнЯЕЭГАќРЈ3ИіФЃПщЃК
1.ScoutЃКгУгкДгИїИіЪ§ОндДШЁЕУздЖЏРЉШнЫљашвЊЕФЪ§ОнЁЃгЩгкЮвУЧЕФШежОШЋВПЖМЛузмдкElasticSearchРяУцЃЌШнЦїЕФдЫаажИБъЖМЛузмЕНPrometheusРяУцЃЌЫљвдЮвУЧЕФздЖЏРЉШнЯЕЭГЛсЖЈЪБЕФЧыЧѓЖўепЕФAPIЃЌЕУЕНУПИіЗўЮёЕФЪЕЪБQPSЁЂCPUКЭФкДцаХЯЂЃЌШЛКѓЫЭИјHeadquarterЁЃ
2.HeadquarterЃКгУгкЪ§ОнЕФДІРэКЭЪЧЗёДЅЗЂРЉЫѕШнЕФХаЖЯЁЃАбДгScoutЪеЕНЕФИїЯюЪ§ОнгыБОЕидЄЯШЖЈвхКУЕФЙцдђНјааБШЖдЃЌШчЙћгаСНИіжИБъГЌЙ§ЖЈвхКУЕФЙцдђЃЌдђЭЈжЊЕНSignalmanФЃПщЁЃ
3.SignalmanЃКгУгкЕїгУИїИіЯТгЮзщМўжДааОпЬхРЉЫѕШнЕФЖЏзїЁЃФПЧАЮвУЧжЛЛсЕїгУMarathonЕФ/v2/apps/{app_id}НгПкЃЌШЅЭъГЩЖдгІЗўЮёЕФРЉШнЁЃвђЮЊЮвУЧЕФЗўЮёдкШнЦїЦєЖЏжЎКѓЛсздМКЯђetcdзЂВсЃЌЫљвдВщбЏЭъШнЦїзДЬЌжЎКѓЃЌРЉЫѕШнЕФШЮЮёОЭЭъГЩСЫЁЃ
3ЁЂЛљгкMesos+MarathonЕФCI/CD
3.1 ГжајМЏГЩгыШнЦїЕїЖШ
дкГЊАЩЃЌЮвУЧЪЙгУJenkinsзїЮЊГжајМЏГЩЕФЙЄОпЁЃжївЊдвђЪЧЮвУЧЯыдкздМКЕФЛњЗПЮЌЛЄГжајМЏГЩЕФКѓЖЫЃЌЫљвдЗХЦњСЫTravisжЎРрЕФЯЕЭГЁЃ
дкЪЕЪЉГжајМЏГЩЕФЙЄзїЙ§ГЬжаЃЌЮвУЧХіЕНСЫЯТСаЮЪЬтЃК
1.Jenkins MasterЕФЙмРэЮЪЬтЁЃЖрИіЭХЖгЙВЯэвЛИіMasterЃЌЛсЕМжТШЈЯоЙмРэРЇФбЃЌХфжУИФЖЏЁЂЩ§МЖУХМїКмИпЃЌJobДДНЈКЭаоИФгаКмЖрЙцдђЃЛУПИіЭХЖггУздМКЕФMasterЃЌЛсЕМжТИїИіMasterжЎМфЕФВхМўЁЂИќаТЁЂЛЗОГЮЌЛЄгаКмЖрЕФжиИДЙЄзїЁЃ
2.Jenkins Slave зЪдДЗжХфВЛЦНОљЃКУІЪБJenkins
slaveЪ§СПВЛзуЃЌJobдЫааашвЊХХЖгЃЛЯаЪБJenkins SlaveгжГіЯжПеЯаЃЌЗЧГЃРЫЗбзЪдДЁЃ
3.Jenkins jobдЫааашвЊЕФЛЗОГЖржжЖрбљЃЌБШШчЮвУЧОЭгаPHPЃЌjavaЃЌmavenЃЌGoЃЌpythonЕШЖржжБрвыдЫааЛЗОГЃЌДюНЈКЭЮЌЛЄslaveЗЧГЃЗбЪБЁЃ
4.ЖрИіПЊЗЂШЫдБЕФЭЌЪБЬсНЛЃЌИїздЕФДњТыЗХЕНИїздЖРСЂЕФВтЪдЛЗОГНјааВтЪдЁЃ
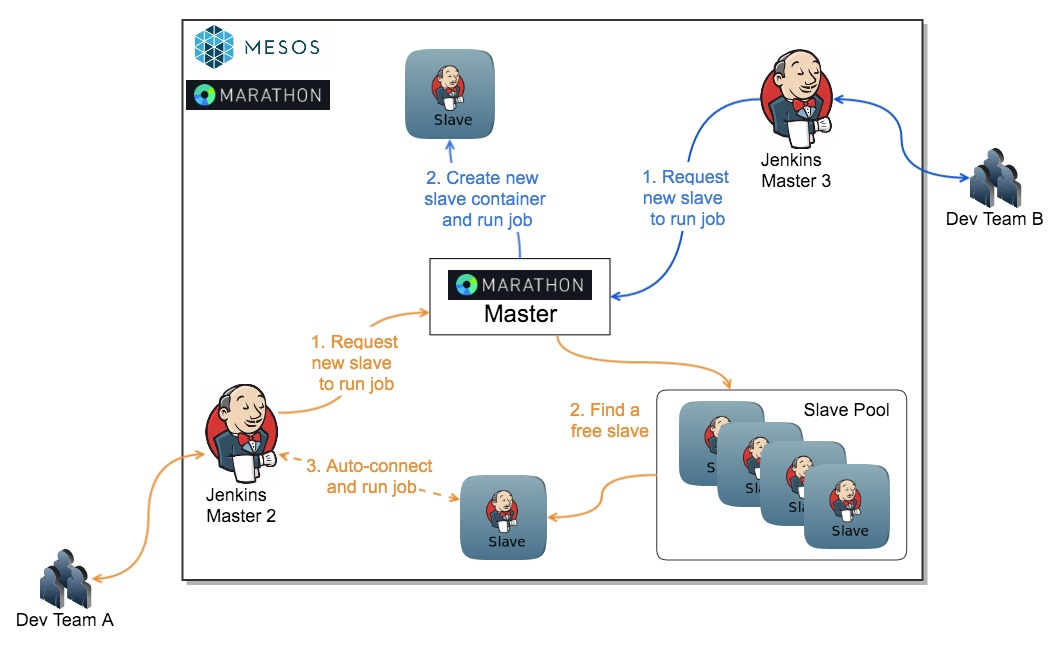
ЛљгквдЩЯЮЪЬтЃЌЮвУЧбЁдёЪЙгУMesosКЭMarathonРДЙмРэJenkinsМЏШКЃЌАбJenkins
MasterКЭJenkins SlaveЖМЗХЕНDockerШнЦїРяУцЃЌПЩвдЗЧГЃгааЇЕФНтОівдЩЯЮЪЬтЁЃЛљДЁМмЙЙШчЯТЭМЃК
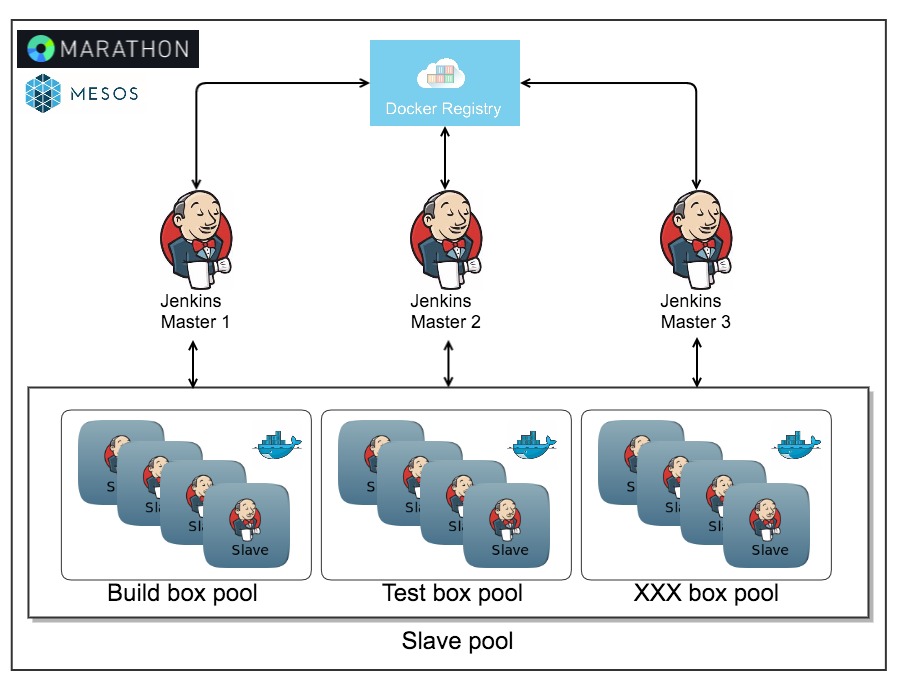
1.ВЛЭЌПЊЗЂЭХЖгжЎМфЪЙгУВЛЭЌЕФJenkins MasterЁЃАбЙЋгУЕФШЈЯоЁЂЩ§МЖЁЂХфжУКЭВхМўИќаТЕНЫНгаJenkins
MasterОЕЯёРяУцЃЌЭЦЕНЫНгаОЕЯёВжПтЃЌШЛКѓЭЈЙ§MarathonВПЪ№аТЕФMasterОЕЯёЃЌаТЭХЖгФУЕНЕФJenkins
MasterОЭдЄАВзАКУСЫИїжжВхМўЃЌИїИіЯжгаЭХЖгПЩвдЮоЗьНгЪеЕНећЬхJenkinsЕФЩ§МЖЁЃ
2.ИїжжВЛЭЌЛЗОГЕФJenkins SlaveЃЌзіГЩSlaveОЕЯёЁЃАДееашвЊЃЌПЩвдЭЈЙ§Swarm
PluginздЖЏзЂВсЕНJenkins masterЃЌДгЖјзщжЏГЩslave poolЕФаЮЪНЃЛвВПЩвдУПИіjobздМКШЅЦєЖЏздМКЕФШнЦїЃЌШЛКѓдкШнЦїРяУцШЅжДааШЮЮёЁЃ
3.Jenkins jobДгШнЦїЕїЖШЕФНЧЖШЗжГЩСНРрЃЌШчЯТЭМЃК
ЛЗОГУєИааЭЃКБШШчБрвыШЮЮёЃЌашвЊУПДЮБрвыЕФЛЗОГЭъШЋИЩОЛЃЌЮвУЧЛсДгОЕЯёВжПтРШЁвЛИіШЋаТЕФОЕЯёЦєЖЏШнЦїЃЌШЅжДааJobЃЌШЛКѓдйJobжДааЭъГЩжЎКѓЙиБеШнЦїЁЃ
ЪБМфУєИааЭЃКБШШчжДааВтЪдЕФJobЃЌашвЊОЁПьЕУЕНВтЪдНсЙћЃЌЕЋЪЧВтЪдЛњЦїЕФЛЗОГЖдгкВтЪдНсЙћУЛЪВУДгАЯьЃЌЮвУЧОЭЛсДгвбОЦєЖЏКУЕФSlave
PoolРяУцШЅРШЁвЛИіПеЯаЕФSlaveШЅжДааJobЁЃШЛКѓдйИљОнSlaveБЛЪЙгУЕФЦЕТЪШЅЖЏЬЌЕФРЉЫѕШнSlave
poolЕФДѓаЁОЭКУСЫЁЃ
3.2 CI/CDСїГЬ
ЛљгкЩЯЪіЕФЛљДЁМмЙЙЃЌЮвУЧЖЈвхСЫЮвУЧздМКЕФГжајМЏГЩгыГжајНЛИЖЕФСїГЬЁЃЦфжаГ§СЫДѓЙцФЃЪЙгУJenkinsгывЛаЉздЖЈжЦЕФJenkinsВхМўжЎЭтЃЌЮвУЧвВздМКбаЗЂСЫздМКЕФВПЪ№ЯЕЭГЁЊЁЊHAWAIIЁЃ
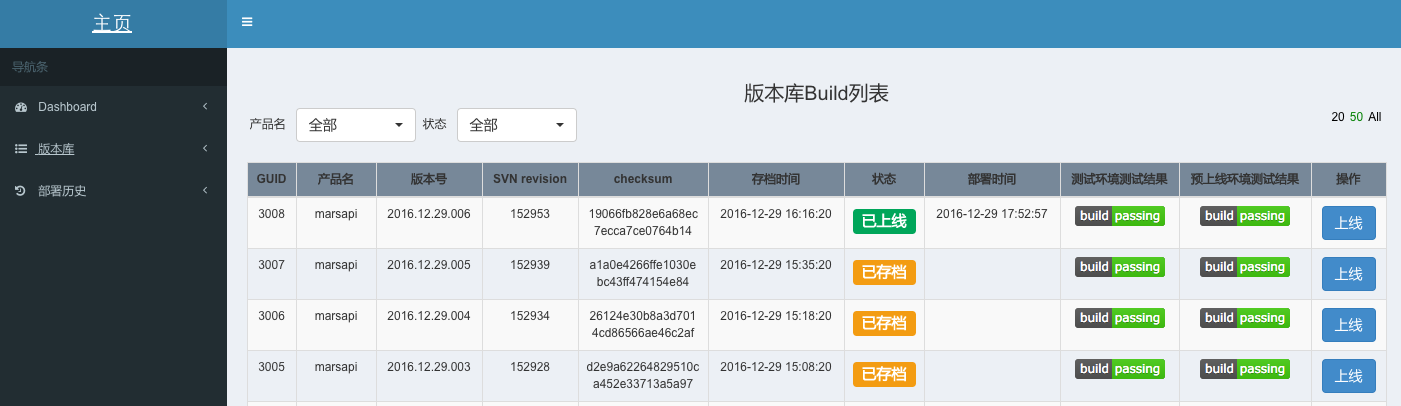
дкHAWAIIжаПЩвдКмжБЙлЕФВщПДИїИіЗўЮёгыФЃПщЕФГжајМЏГЩНсЙћЃЌАќРЈзюаТЕФАцБОЃЌSCM revisionЃЌВтЪдНсЙћЕШаХЯЂЃЌШЛКѓбЁдёЯргІЕФАцБОШЅВПЪ№ЩњВњЛЗОГЁЃ
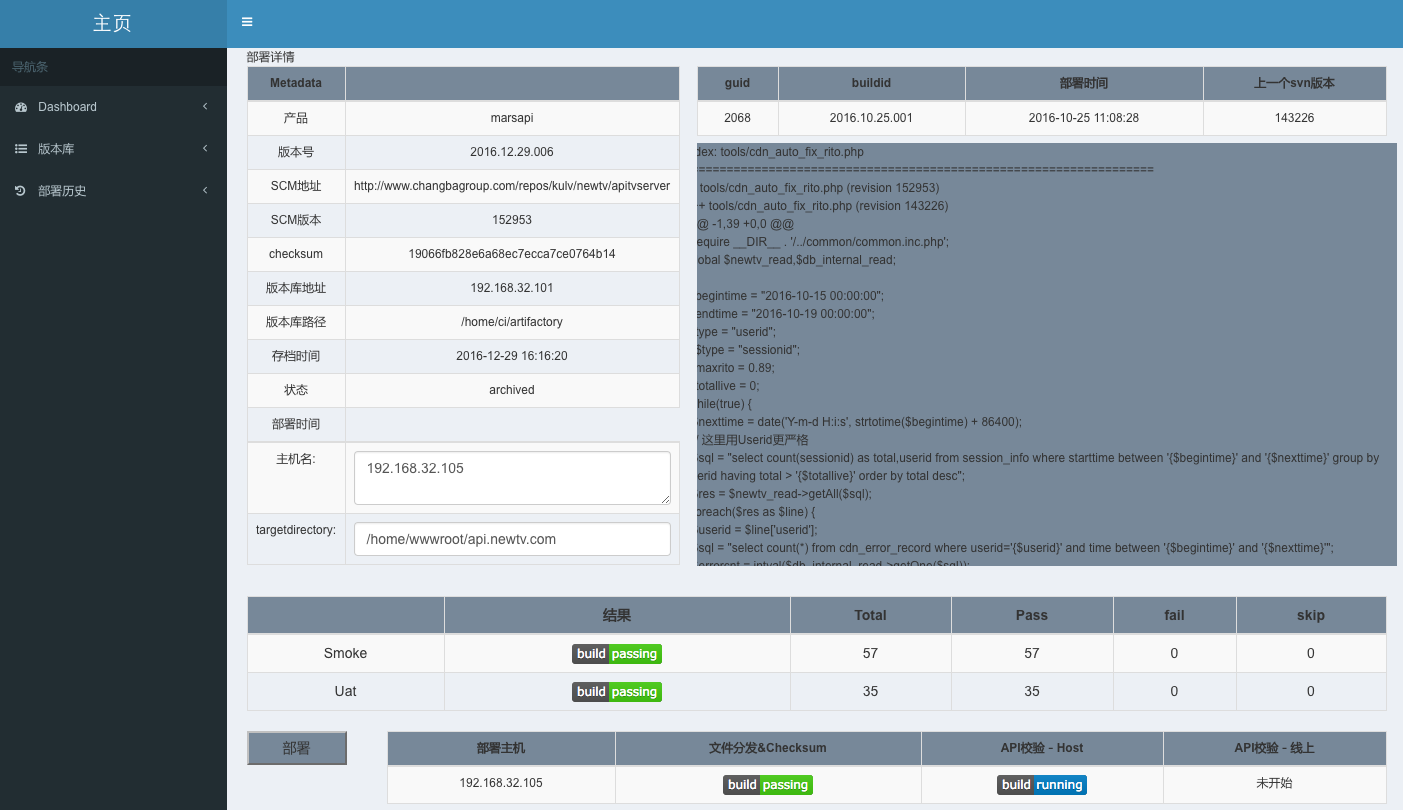
дкВПЪ№жЎЧАЃЌПЩвдВщПДЯъЯИЕФВтЪдНсЙћКЭгыЯпЩЯАцБОЕФЧјБ№ЃЌвдМАЩЯЯпЙ§ГЬжаЕФИїИіВНжшдЫааЕФзДЬЌЁЃ
ЛљгкЩЯЪіЛљДЁМмЙЙЃЌЮвУЧЕФCI/CDСїГЬШчЯТЃК
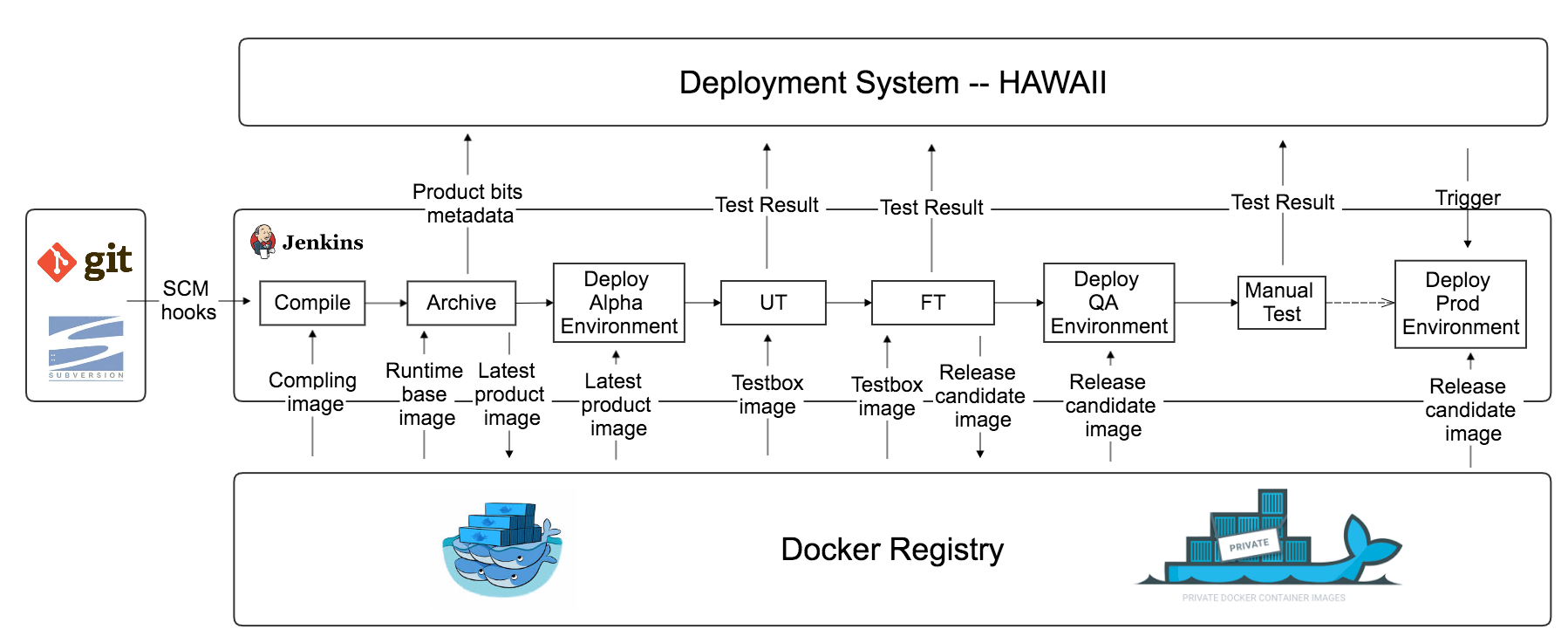
1.SVNЛђепGITЪеЕНаТЕФДњТыЬсНЛжЎКѓЃЌЛсЭЈЙ§hookЦєЖЏЯргІЕФJenkins
jobЃЌДЅЗЂећИіCIСїГЬЁЃ
2.JenkinsДгЫНгаОЕЯёВжПтРШЁЯрЖдгІЕФБрвыЛЗОГЃЌЭъГЩДњТыЕФБрвыЁЃ
3.JenkinsДгЫНгаОЕЯёВжПтРШЁЯрЖдгІЕФдЫааЪБЛЗОГЃЌАбЩЯвЛВНБрвыКУЕФВњЦЗАќДђЕНОЕЯёРяУцЃЌВЂЩњГЩвЛИіаТАцБОЕФВњЦЗОЕЯёЁЃВњЦЗОЕЯёЪЧзюжеПЩвдВПЪ№ЕНЯпЩЯЛЗОГЕФОЕЯёЃЌИУОЕЯёЕФmetadataвВЛсБЛЬсНЛЕНВПЪ№ЯЕЭГHAWAIIЃЌАќРЈGUIDЃЌSCM
revisionЃЌCommitterЃЌЪБМфДСЕШаХЯЂ
4.НЋВНжш3жаЩњГЩЕФВњЦЗОЕЯёВПЪ№ЕНAlphaЛЗОГЃЈИУЛЗОГжївЊгУгкздЖЏЛЏЛиЙщВтЪдЃЌЪЕМЪЦєЖЏЕФШнЦїЦфЪЕЪЧвЛИіЭъећЛЗОГЃЌАќРЈЪ§ОнШнЦїЃЌвРРЕЕФЗўЮёЕШЃЉЁЃ
5.JenkinsДгЫНгаОЕЯёВжПтРШЁЯрЖдгІЕФUTКЭFTЕФВтЪдЛњОЕЯёЃЌНјааВтЪдЁЃВтЪдЭъГЩжЎКѓЃЌЛсЯњЛйAlphaЛЗОГКЭЫљгаЕФВтЪдЛњШнЦїЃЌВтЪдНсЙћЛсБЃДцЕНВПЪ№ЯЕЭГHAWAIIЃЌВЂЛсгЪМўЭЈжЊЕНЯрЙиШЫдБЁЃ
6.ШчЙћВтЪдЭЈЙ§ЃЌЛсНЋЕк3ВНЩњГЩЕФВњЦЗОЕЯёВПЪ№ЕНQAЛЗОГЃЌНјаавЛЯЕСаИќДѓЗЖЮЇЕФЛиЙщВтЪдКЭМЏГЩВтЪдЁЃВтЪдНсЙћвВЛсМЧТМЕНHAWAIIЃЌгаВтЪдВЛЭЈЙ§ЕФЕиЗНЛсДгЕк1ВНДгЭЗПЊЪМЕќДњЁЃ
7.ШЋВПВтЪдЭЈЙ§КѓЃЌОЭПЊЪМЪЙгУHAWAIIАбВНжш3жаЩњГЩЕФВњЦЗОЕЯёВПЪ№ЕНЯпЩЯЛЗОГЁЃ
4ЁЂаЁНс
ЫцзХЛЅСЊЭјЕФИпЫйЗЂеЙЃЌИїИіЙЋЫОЖМУцСйзХОоДѓЕФВњЦЗЕќДњбЙСІЃЌШчКЮИќПьЕФЗЂВМИпжЪСПЕФВњЦЗЃЌвВЪЧУПИіЛЅСЊЭјЙЋЫОЖМУцСйЕФЮЪЬтЁЃдкетИіДѓЧїЪЦЯТЃЌЮЂЗўЮёгыDevOpsЕФИХФюгІдЫЖјЩњЃЌдкЕЭёюКЯЕФЭЌЪБЪЕЯжИпОлКЯЃЌвВЖдаТЪБДњЕФDevOpsЬсГіСЫИќИпЕФММЪѕгыРэФювЊЧѓЁЃ
етвВЪЧЮвУЧЙЋЫОдкетИіаТЕФвЕЮёЯпЩЯУцНјааЃЌНјааГЂЪдЕФжївЊдвђжЎвЛЁЃЖдгкЮЂЗўЮёЁЂШнЦїБрХХЁЂащФтЛЏЁЂDevOpsетаЉСьгђЃЌЮвУЧвЛВНвЛВНОРњСЫДгЮоЕНгаЕФЙ§ГЬЃЌЫљвдКмЖрЗНУцЖМЪЧБОзХДгТњзувЕЮёЕФФПБъРДОЁСПбЯНїЕФПЊеЙЃЌАќРЈЫљгаЕФЗўЮёгыЛљДЁМмЙЙЖМНјааСЫИпВЂЗЂЧвГЄЪБМфЕФбЙСІВтЪдЁЃ |









