| БрМЭЦМі: |
| БОЮФРДздгкIBM
ЃЌБОЮФНщЩмСЫЮЂЗўЮёзщКЯКмШнвзГіДэЃЌвЊИпаЇжДааЃЌБиаыНјааВЂааЛЏДІРэЁЃ |
|
ЛљгкЮЂЗўЮёЕФМмЙЙНќФъРДдНРДдНЪмЛЖгЁЃИљОнзюНќЕФвЛЯюЕїВщЃЌНЋДѓаЭЯЕЭГЗжНтЮЊЖРСЂПЩВПЪ№ЕЅдЊЕФФмСІЪЧПЊЗЂШЫдБв§жЄЕФзюДѓгХЪЦжЎвЛЁЃЕЋетЪЧгаДњМлЕФЃКЦЕЗББщРњЭјТчБпНчашвЊГщЯѓЛЏЃЌвЛЗНУцПЩвдЗНБуЕиДІРэИпЖШЕФВЂЗЂадЃЌСэвЛЗНУцПЩвдШнДэКЭНјааДэЮѓДІРэЁЃ
ЁАScala ПЩзщКЯЕФ Future РраЭПЩгУгкНЋЮЂЗўЮёЕїгУЗьКЯдквЛЦ№ЃЌВЂЧвЫќЕФвЛаЉШБЕуПЩвдЭЈЙ§ CatsЃЈвЛИі
Scala ПтЃЌПЩЬсЙЉжЇГжРраЭЛЏЁЂКЏЪ§ЪНБрГЬбљЪНЕФГщЯѓЛЏЃЉЕУЕННтОіЁЃЁБ
БОНЬГЬИХЪіСЫ Scala ЧПДѓЕФРраЭЯЕЭГМАКЏЪ§ЪНБрГЬЙІФмШчКЮЬсЙЉвЛИіГіЩЋЕФЛВМЃЌвдДІРэЮЂЗўЮёзщКЯМАЦфВњЩњЕФЮЪЬтЁЃЮвУЧЛЙНЋжиЕуНВЪіФЃаЭЧ§ЖЏЕФПЊЗЂбљЪНЁЃЮЂЗўЮёЭЈГЃЪЕЪЉвЛИігаНчЩЯЯТЮФЃЌетЪЧРДздгђЧ§ЖЏЕФЩшМЦИХФюЃЌЫќНЋгГЩфгђФЃаЭЕФвЛИізЈУХзгМЏЁЃживЊЕФЪЧШЗБЃгђИХФюМЬајБЃГжЧхЮњВЂдкВЂЗЂКЭДэЮѓДІРэР§ГЬЧщПіЯТВЛЛсЪмЕНгАЯьЁЃ
ЮЊСЫБЃГжЪЕгУадЃЌЮвУЧНЋЪзЯШНщЩмвЛИіМђЛЏЕФЮЪЬтгђЁАЮФеТЫбЫїЗўЮёЁБЃЌВЂЯђФњбнЪОШчКЮЪЙгУЪьЯЄЕФ Scala
РраЭНјааЯИЗжЁЃШЛКѓЃЌФњНЋСЫНт Scala ЕФПЩзщКЯ Future РраЭШчКЮгУгкНЋЮЂЗўЮёЕїгУЗьКЯдквЛЦ№ЃЌВЂЧвЫќЕФвЛаЉШБЕуШчКЮЭЈЙ§
CatsЃЈвЛИі Scala ПтЃЌПЩЬсЙЉжЇГжРраЭЛЏЁЂКЏЪ§ЪНБрГЬбљЪНЕФГщЯѓЛЏЃЉЕУЕННтОіЁЃШЛКѓЃЌЮвУЧНЋзЊЯђДэЮѓДІРэЃЌВЂГЂЪдЪЙгУ
Scala ЕФ Either[A, B] РраЭКЭ Cats ЮЊЦфЬсЙЉЕФРЉеЙРДНтОіВйзїДэЮѓжаЕФгђДэЮѓЁЃЮвУЧНЋЭЈЙ§ЯђФњбнЪО
Cats ЕФ monad зЊЛЛГЬађЃЈзщКЯЧЖЬзаЇЙћРраЭЕФЧПДѓЗНЪНЃЉЃЌАяжњФњСЫНтДЫЙ§ГЬЪЧШчКЮЪЇШЅФГаЉБуРћадЕФЁЃ
ЩшжУГЁОАЃКЮФеТЫбЫїЗўЮё
ЭЈЙ§ IBM Cloud Lite ПьЫйЧсЫЩЕиЙЙНЈФњЕФЯТвЛИігІгУГЬађЁЃФњЕФУтЗбеЪЛЇгРВЛЙ§ЦкЃЌЖјЧвФњЛсЛёЕУ
256 MB ЕФ Cloud Foundry дЫааЪБФкДцЃЌвдМААќКЌ Kubernetes МЏШКЕФ 2
GB ДцДЂПеМфЁЃЛёШЁЫљгаЯИНкВЂШЗЖЈШчКЮПЊЪМЁЃШчЙћФњВЛЪьЯЄ IBM CloudЃЌЧыВщдФ developerWorks
ЩЯЕФ IBM Cloud Essentials ПЮГЬЁЃ
дкЩюШыбаОПжЎЧАЃЌФњашвЊЙЙНЈвЛИіЗўЮёЃЌдкДЫР§жаЮЊПЩвдЫбЫїЮФеТПтЃЈШч developerWorks ЕФЮФеТЃЉЕФЗўЮёЁЃЮЊСЫБЃГжПЩЙмРэадЃЌЮвУЧНЋАбжиЕуЗХдкИУЮЪЬтгђЕФаЁЕФЁЂМђЛЏзгМЏЩЯЁЃвдЯТЪЧЮвУЧЯывЊЪЕЪЉЕФЗўЮёЃК
ИјЖЈвЛИіЫбЫїВщбЏЃЈПЩвдЭЈЙ§ЧыЧѓВЮЪ§ЬсЙЉЃЉЃЌФњОЭПЩвдАДееШчЯТдЫааЫбЫїЃК
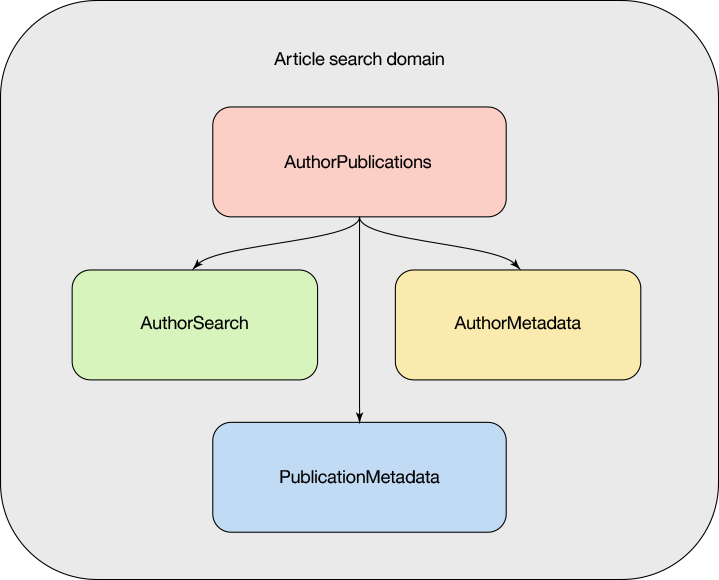
заЯИбаОПИУашЧѓЃЌДцдкЫФИіПЩгГЩфЕНЗўЮёЕФгаНчЩЯЯТЮФЃЈВЮМћЭМ 1ЃЉЃК
1.AuthorPublicationsЃКНЋдкетРяИХЪізмЬхЗўЮёЃЛИјЖЈвЛИіЫбЫїДЪЃЌНЋЗЕЛиЦЅХфЕФзїепЪєадвдМАЫљгаЗЂВМФкШнМАЦфИїздЕФЪєад
2.AuthorSearchЃКНЋЫбЫїДЪгГЩфЕНзїепБъЪЖЕФзїепЗЂЯжЗўЮё
3.AuthorMetadataЃКНЋзїепБъЪЖгГЩфЕНвЛзщЪєадЕФзїепВщевЗўЮё
4.PublicationMetadataЃКНЋзїепБъЪЖгГЩфЕНвЛзщЗЂВМФкШнЪєадЕФЗЂВМФкШнВщевЗўЮё
ЭМ 1. ЮФеТЫбЫїгђ
ШУЮвУЧПДПДПЩЖдДЫНјааНЈФЃЕФКЯЪЪРраЭМЏЁЃОЭгђЧ§ЖЏЕФЩшМЦЖјбдЃЌФњПЩФмЛсЗЂЯжгаСНИіЙиМќЪЕЬх Author
КЭ PublicationЃК
| case
class Author(id: Long, name: String)
case class Publication(id: Long, authorId: Long,
title:String)
|
ФњЛЙашвЊвЛИіНЋзїепМАЦфЗЂВМФкШнАѓЖЈдквЛЦ№ЕФОлМЏЃК
| case
class AuthorPublications(author: Author, publications:
List[Publication]) |
етЯрЕБМђЕЅЁЃЯждкЃЌПДПДгђТпМВЂСЫНтПЩвдШчКЮУшЪіФњашвЊдк AuthorPublications ЩЯЯТЮФжажДааЕФВНжшЁЃвЊЧѓЬсЙЉУћГЦзїЮЊЫбЫїВщбЏЃЌФњашвЊНЋВщбЏНтЮіЮЊЕквЛИіЦЅХфЕФзїепЪЕЬхЁЃдкЪЕМЪЗўЮёжаЃЌИУЕїгУКмПЩФмЛсдк
AuthorSearch зггђжаВщбЏЫбЫїЫїв§ЃЌЯђФњЗЕЛиЪЕЬхБъЪЖЃК
| def
findAuthor(query: String): Future[Long] |
ИУКЏЪ§ЧЉУћЭЈЙ§ЗЕЛи Future[Long] ЖјЗЧ Long РДжИЪОПЩФмЛсвдВЂЗЂЗНЪНдЫааИУЕїгУЁЃДЫДІФњВЛашвЊЙиаФЪЕМЪЪЕЯжЃЌЕЋПЩвдМйЩшДЫЙІФмЃЈМАвдЯТЙІФмЃЉНЋЩцМАЭјТч
I/OЃЌвђДЫгІгыгІгУГЬађЕФжїжДааЯпГЬвдВЂЗЂЗНЪНдЫааЁЃ
ИјЖЈзїепБъЪЖЃЌЯждкашвЊНЋЦфНтЮіЕН Author ЪЕЬхЁЃетИіЙІФмдк AuthorMetadata зггђжаБЛГщЯѓГіРДЃЌВЂЧвПЩФмЙЋПЊвЛИіШчЯТЕФНгПкЃК
|
def getAuthor(id: Long): Future[Author]
|
дкЪЕМЪЯЕЭГжаЃЌДЫКЏЪ§ПЩФмЪЧДцДЂПтЕФвЛВПЗжЃЌНЋвьВНВщбЏЪ§ОнДцДЂПтЛђдЊЪ§ОнЗўЮёвдЖЈЮЛЪЕЬхЁЃ
зюКѓЃЌИјЖЈзїепБъЪЖЃЌФњашвЊдк PublicationMetadata зггђжаИљОнИјЖЈЕФзїепРДВщевЫљгаЗЂВМФкШнЃК
| def
getPublications(authorId: Long): Future[List[Publication]] |
ШУЮвУЧЛиЙЫвЛЯТЃКФњЖЈвхСЫжївЊгђЖдЯѓ ArticleЁЂAuthor КЭ AuthorPublicationsЁЃФњЛЙЬсЙЉСЫКЏЪ§ЃЈfindAuthorЁЂgetAuthor
КЭ getPublicationsЃЉЃЌдЪаэФњЪЙгУ Scala ЕФ Future РраЭДгЩЯгЮЗўЮёЕїгУЗЕЛиетаЉРраЭЕФЪЕР§ЁЃ
ЯждкЮвУЧНЋЯђФњеЙЪОШчКЮНЋетаЉЕїгУЦДНгдквЛЦ№РДЙЙНЈгавтвхЕФЙІФмЁЃ
ЪЙгУ Future ЙЙГЩЗўЮё
гаСЫетаЉКЏЪ§ЃЌФњПЩвдНЋЦфзщКЯдк for-comprehension жаЃЌвдЩњГЩ AuthorPublications
ЕФЪЕР§ЃЌОлМЏЖдЯѓЃК
| def
findPublications(query: String): Future[AuthorPublications]
=
for {
authorId <- findAuthor(query)
author <- getAuthor(authorId)
pubs <- getPublications(authorId)
} yield AuthorPublications(author, pubs)
|
ИјЖЈПЩФмдкЧыЧѓВЮЪ§жаЯђФњЬсЙЉЕФЫбЫїВщбЏЃЌШЛКѓФњПЩвдАДееШчЯТдЫааЫбЫїЃК
| val
query = "matthias k"
val search: Future[Unit] = findPublications(query)
map { authorPubs =>
renderResponse(200, s"Found $authorPubs")
}
Await.result(search, Duration.Inf) |
етаЉЖМЪЧБъзМЕФ ScalaЃЌЕЋДЫДІгаСНИіжЕЕУЧПЕїЕФЪТЯюЃК
1.ОЁЙмУПИіЗўЮёЕїгУПЩФмдкВЛЭЌЕФЯпГЬЩЯжДааЃЌЕЋЖМВЛЛсНЋДЫИДдгадАќКЌдкФњЕФДњТыжаЃЌЧвФњЕФТпМНЋЧхЮњЕиЭЛЯдЁЃFuture
РраЭЕФзщКЯЗНУцЪЧЙиМќЃКScala НЋ for-comprehensions ЬсШЁЕНЖд flatMap
КЭ map ЕФЕїгУжаЃЌЫќУЧГфЕБбгајЃЌЮЊФњжДааБиашЕФКЏЪ§зщКЯЁЃФњНЋЛёЕУаТКЏЪ§ findPublicationsЃЌЫќНЋЗЕЛиаТЕФ
Future вдМАИУзщКЯСДЕФНсЙћЁЃЖдФњДІРэаЇЙћЃЈВЂЗЂЃЉЕФЮЈвЛМЃЯѓЪЧдкЗЕЛиРраЭжаНјааБрТыЁЃ
2.ПМТЧЕНЩЯЪіЧщПіЃЌКмЯдШЛЃЌжБжСФњЪЕМЪЕШД§НсЙћЕФФЧвЛПЬЃЌФњвЛжБдкЙЙаДКЏЪ§ЃЛФњВЂУЛгаЭЃЯТРДЕШД§жаМфНсЙћЃЌЖјЪЧвЛжБвРРЕ
Future зщКЯЁЃетЪЧКЏЪ§ЪНБрГЬЙЄзїЗНЪНЕФжївЊЪОР§ЃКжюШчгЩгкВЂЗЂЖјбгГйЕНДяжЕЕФаЇЙћНЋЭЦЫЭжСЯЕЭГБпНчЁЃетвВЪЧЭЈГЃНјааДэЮѓДІРэЕФЮЛжУЃЌФњКмПьОЭЛсПДЕНЁЃ
днВЛЬИгХЪЦЃЌДЫЪОР§ДцдкЮЪЬтЁЃдк findPublications жаЃЌКѓајЗўЮёЕїгУдкЯШЧАЕФЗўЮёЕїгУЗЕЛиКѓВХЛсПЊЪМжДааЃЌвђДЫФњЛсЪЇШЅвЛаЉживЊЕФЖЋЮїЃКВЂааЛЏбЁЯюЁЃетЪЧвђЮЊ
for-comprehension жаЕФУПвЛааПЩвдБЛШЯЮЊЪЧЖдЯШЧАНсЙћжДааВйзїЕФЛиЕїЃЌШчЭМ 2 ЫљЪОЁЃ
ЭМ 2. findPublications 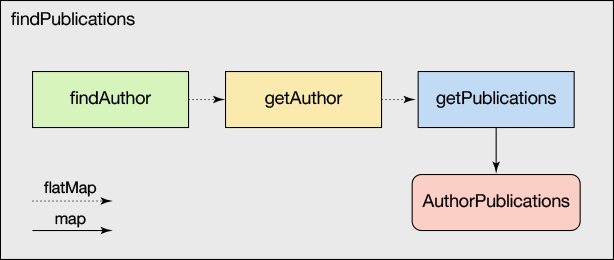
е§ШчФњПЩФмвбзЂвтЕНЕФФЧбљЃЌgetAuthor КЭ getPublications ЖМЪЧдкЕквЛВНжаЗУДцЕФ
authorId ЛљДЁЩЯЙЄзїЕФЁЃвђДЫЃЌgetPublications ВЛашвЊЕШД§ getAuthor
ЭъГЩЃЌЖјПЩвдВЂаажДааетСНИіВйзїЃЌШчЭМ 3 ЫљЪОЁЃ
ЭМ 3. ВЂаажДаа 
ВЛавЕФЪЧЃЌДг Scala 2.12 ПЊЪМЃЌФњУЛгаАьЗЈУїШЗЕиБэДяетИівтЭМЃЌЖјБиаыНшжњгквЛаЉВЛжБЙлЕФзіЗЈЃЌВХФмЪЙетаЉЕїгУЪЕМЪЩЯЭЌЪБдЫааЁЃ
ФЧУДетЪЧЗёвтЮЖзХЮвУЧдкБэДяВЂЗЂадЗНУцвбОДяЕНСЫ Scala ФкжУЙІФмЕФЯожЦЃПЪТЪЕжЄУїЃЌCatsЃЈгУгкКЏЪ§ЪНБрГЬЕФ
Scala ПтЃЉПЩвдЛиД№ДЫЮЪЬтЃЛПЩШУФњСЌНгСНИі FutureЃЌгааЇЕиВЂаадЫааЫќУЧЁЃ
Future БЖдіЃКCats КЭ Semigroupal РраЭ
Cats ВЛЪЧжИУЈпфЃЛЖјЪЧ categories ЕФЫѕаДЃЌЪЧЖдбаОПЪ§бЇБОЩэжаНсЙЙЕФЪ§бЇЗжжЇЕФГЦЮНЁЃРрБ№РэТлЙизЂЕФЪЧдкЪЙгУЧПРраЭгябдЪБЗЧГЃгагУЕФГщЯѓЁЃОпЬхЖјбдЃЌРрБ№РэТлВЩгУОЙ§бщжЄЮЊЁАе§ШЗЁБЕФКЯЗЈЗНЪНЃЌЮЊРраЭЕФБщРњЁЂзЊЛЛКЭзщКЯЬсЙЉСЫРЖЭМЛђХфЗНЁЃ
ЦфжавЛжжРраЭЪЧ SemigroupalЃЈЯШЧАГЦЮЊЁАCartesianЁБЃЉЃЌдЪаэФњЪЙгУЦф product
КЏЪ§МгШы FutureЁЃШчЙћФњдк SQL жаБраДЙ§СЌНгСНеХБэЕФДњТыЃЌФЧУДБэЪОФњвбЪьЯЄЕбПЈЖћГЫЛ§ЁЃSQL
СЌНгашвЊвЛзщдЊзщЃЈМДФњЫљСЌНгЕФБэЕФааЃЉЃЌВЂВњЩњвЛИіаТЕФМЏКЯЃЌУПИідЊЫиЖМЪЧвЛИігЩЫљгадДБэжаЕФжЕзщГЩЕФдЊзщЁЃетНЋгааЇЕиЪЙдДБэБЖдіЁЃФњПЩвдНЋДЫЯыЗЈДЋДяЕНРраЭЯЕЭГЃКУПвЛжжРраЭБэЪОИУРраЭЕФвЛзщПЩФмЕФжЕЃЈОЭРрБ№РэТлЖјбдЃЌЪЧжИОпгаРраЭзїЮЊЖдЯѓЕФРрБ№ЃЉЃЌвђДЫШчЙћФњНЋ
A КЭ B СНжжРраЭЁАЯрГЫЁБЃЌФњЛсЪеЕНвЛИіаТЕФРраЭ (A, B)ЃЌЦфжЕЪЧРДзд A КЭ B ЕФжЕЖдЁЃ
НЋДЫгІгУгкЮвУЧЕФЪОР§ЃЌФњЯждкПЩвдЫЕЃКИјЖЈ Future[Author] КЭ Future[List[Publication]]ЃЌНЋСНепЁАЯрГЫЁБвдЩњГЩдЊзщЛЏЕФ
Future[(Author, List[Publication])]ЃЈВЮМћЭМ 4ЃЉЁЃ
ЭМ 4. дЊзщЛЏЕФ future 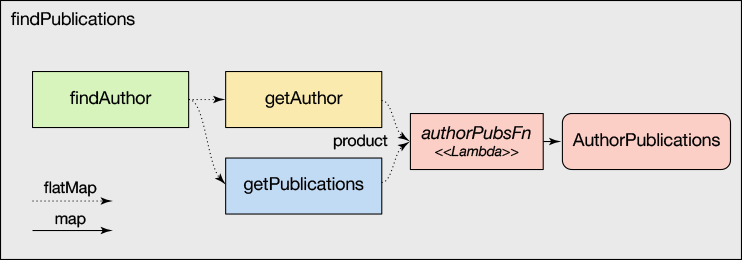
гыЧАУцеТНкжаСНИі Future ЗЕЛиКЏЪ§ f КЭ g СДНгдквЛЦ№ЃЈМДЪЙ g ИљБОВЛвРРЕгк f ЕФЪфГіЃЉВЛЭЌЕФЪЧЃЌдЊзщРраЭЛсИќКУЕиБэУїФњЕФвтЭМЃКжЛгаЕБЫљгажЕЖМвбЩњГЩЪБЃЌжЕЕФдЊзщВХФмДцдкЃЌЕЋЪЧдЪаэвдШЮКЮЫГађЗЂЩњЃЈФњПЩФмжЊЕРетИіЙцдђЕФУћзжЃКНЛЛЛадЃЉЁЃЛЛОфЛАЫЕЃЌзїепЛЙЪЧЗЂВМФкШнЯШЕНДяВЂВЛживЊЃЌЯждкПЩвдВЂаадЫааЫќУЧЃК
| def
findPublications(query: String): Future[AuthorPublications]
=
for {
authorId <- findAuthor(query)
(author, pubs) <- getAuthor(authorId) product
getPublications(authorId)
} yield AuthorPublications(author, pubs)
|
НЋ getAuthor КЭ getPublications гы product КЏЪ§зщКЯНЋЭЌЪБДЅЗЂСНИі
FutureЃЌВЂдкСНИі Future ГЩЙІКѓСЂМДЩњГЩАќКЌСНИіжЕЕФдЊзщЃЌЛђепдкЦфжаШЮвЛЯюЪЇАмЪБЩњГЩДэЮѓЁЃетВЛНіЪЧеыЖдФњЕФЮЪЬтЕФКУНтОіЗНАИЃЌЖјЧввВИќЧхЮњЕиБэДяСЫ
getAuthor КЭ getPublications жаЕФгђТпМВЛБЫДЫвРРЕЁЃ
дкЮвУЧВщПД Cats ЕФЦфЫћгХЪЦжЎЧАЃЌШУЮвУЧЛиЭЗПДПДдчЧАЬсМАЕЋЮДЭъШЋНтОіЕФСэвЛИіЮЪЬтЃКШчКЮгааЇЕиДІРэЮФеТЫбЫїжаГіЯжЕФДэЮѓЁЃ
ДІРэЗўЮёЪЇАм
Future ЫцИНФкжУЕФДэЮѓДІРэЙІФмЁЃЫќУЧЪЙгУ Scala ЕФ Try РраЭВЖЛёЦфМЦЫуЕФНсЙћЃЌПЩвдЪЧГЩЙІЃЈаЏДј
A ЕФжЕЃЉЛђЪЇАмЃЈаЏДјвьГЃЃЉЁЃвьГЃЗЧГЃЪЪКЯДІРэжюШч I/O ЙЪеЯЁЂдЫааЪБЦНЬЈДэЮѓвдМАЮДТњзуЕФЯЕЭГЦкЭћЕШВйзїЮЪЬтЃЌвђДЫ
Try ЫЦКѕЪЧВЖЛё Future ФкВПзДЬЌЕФКЯЪЪбЁдёЁЃ
ФњПЩвдГЂЪдЭъШЋвРРЕИУЛњжЦЃЌЕЋЪЧЕБЩцМАЕНдкЮЪЬтгђжаБэЪОЪЇАмЪБЃЌгІИУБмУтвьГЃЁЃетЪЧвђЮЊгІгУГЬађжаЕФТпМЪЇАмзюКУгЩФњПЩвддкЗЕЛиРраЭжаДЋЕнЕФКЯЪЪжЕРДБэЪОЃЌЖјВЛгІНЋЦфЪгЮЊвьГЃЁЃР§ШчЃЌдкЮФеТЫбЫїв§ЧцжаЮДФмевЕНзїепВЂЗЧвЛИівьГЃЕФЪЇАмЃЌЕЋШЗЪЕЪЧвЛИіЪЇАмЁЃЯывЛЯыЃКШчЙћФњфЏРРжСжИЯђШБЪЇзЪдДЕФ
URLЃЌФњЛсЦкЭћфЏРРЦїЪЇПиТ№ЃПЕБШЛВЛЦкЭћЃЁФњЛсЯЃЭћЫќЗЕЛи 404 вГУцЃЌетЪЕМЪЩЯжЛЪЧФњдРДЯывЊЕФвГУцЕФвЛИіЬцДњжЕЁЃЮвУЧРДПДПДШчКЮдк
Scala жаЪЕЯжетвЛЕуЁЃ
УмЗтЕФРраЭВуДЮНсЙЙ
УмЗтЕФРраЭВуДЮНсЙЙЪЧдк Scala жаБрТыЪЇАмжЕЕФвЛжжМђБуЗНЗЈЁЃгЩгкУмЗтВуДЮНсЙЙВЛФмРЉеЙЕНЦфДЪЗЈЗЖЮЇвдЭтЃЌвђДЫЫќУЧдЪаэБрвыЦїМьВщеыЖдЦфАИР§ЕФФЃЪНЦЅХфЪЧЗёШЋУцЁЃШчЙћФњЭќМЧДІРэЬиЖЈЙЪеЯЃЈПЩФмЛсЧПжЦФњДІРэЫљгаПЩФмЕФЧщПіЃЉЃЌетПЩвдЗРжЙФњдкдЫааЪББРРЃЁЃЯТУцбнЪОСЫШчКЮЪЙгУДЫЙІФмРДБэЪОЮФеТЫбЫїЗўЮёжаЕФЪЇАмЃК
| sealed
trait ServiceError
case object InvalidQuery extends ServiceError
case object NotFound extends ServiceError
|
ЧызЂвтЃЌетаЉЖМЪЧжЕЖдЯѓЃЌгЩгкЫќУЧЕФРраЭзїгУгкЫќУЧздМКЃЌвђДЫФњПЩвдЭЈЙ§КЏЪ§ЗЕЛиЫќУЧЃЌЖјВЛБиЪЙгУЯёХзГівьГЃетбљЕФСюШЫЬжбсЕФЗНЗЈЁЃФњЯждкПЩФмЛсЮЪЃКЮвШчКЮЭЈЙ§ЗўЮёКЏЪ§ЕїгУРДЗЕЛи
ServiceError ЛђИУЕїгУЕФЪЕМЪНсЙћЃПФњздМКЫЕЙ§ЃКЪЙгУ EitherЁЃ
Either РраЭ
Either[L, R] ЪЧдк Scala жаБэЪОЛЅГтбЁдёСНИіжЕЕФЙцЗЖЗНЪНЃКНЋЪЙгУ LЃЈЁАзѓЁБЃЉЛђ
RЃЈЁАгвЁБЃЉЃЌЕЋВЛЛсЭЌЪБЪЙгУЖўепЁЃДг Scala 2.12ЃЈвВЪЙгУдчЦкАцБОЕФРрТЗОЖЩЯЕФ CatsЃЉПЊЪМЃЌEither
РраЭЪЧЫљЮНЁАright-biasedЁБЕФгвЦЋ monadЃЌЁАrightЁБвтЮЖзХФњПЩвдЪЙгУ map КЭ
flatMap ЖдЦфНјаазЊБфвдзёбе§ШЗЕФТЗОЖЁЃетЪЙЕУЫќГЩЮЊБэЪОШЮКЮжжРрМЦЫуЃЈАќРЈЗўЮёЕїгУЃЉЕФНсЙћЕФОјМббЁдёЃЌЦфжазѓЗжжЇНЋЬцЛЛЮЊДэЮѓРраЭЃЌгвЗжжЇНЋЬцЛЛЮЊГЩЙІРраЭЁЃвђДЫЃЌШчФњдк
Future жаПДЕНЕФФЧбљЃЌгвЦЋНЋБфЮЊГЩЙІЦЋЯђЁЃШУЮвУЧЪЕЯж findAuthor КЏЪ§РДЫЕУїПЩФмЛсЩњГЩ
ServiceError ЖјВЛЪЧзїепБъЪЖЕФЪТЪЕЃК
| def
findAuthor(query: String): Future[Either[ServiceError,
Long]] =
Future.successful(
if (query == "matthias k") 42L.asRight
else if (query.isEmpty) InvalidQuery.asLeft
else NotFound.asLeft
) |
ЕБШЛЃЌетВЛЪЧвЛИіЗЧГЃгагУЕФЫбЫїЪЕЯжЃЌЕЋЫќЕФШЗЫЕУїСЫЪЙгУЗЕЛиРраЭРДБэЪОЪЇАмКЭГЩЙІАИР§ЁЃЫфШЛетИіЪЕЯжЪЧУїШЗЕФЃЈЗНЗЈКЯдМдкЧЉУћжаЧхЮњПЩМћЃЉЃЌЫќгаЕуШпГЄЁЃвдДЫЗНЪНЧЖЬзаЇЙћвтЮЖзХФњЯждкОпгаСНИіМЖБ№ЕФЬхЯЕ
Future КЭ EitherЃЌБиаыЗжБ№ДІРэЁЃетПЩФмЛсШУФњКмФбЛёЕУФњбАевЕФжЕЃЌвђЮЊФњашвЊЯШгГЩф Future
вдГщШЁ EitherЃЌШЛКѓгГЩф Either вдЛёШЁе§ШЗЕФжЕЃЌЛђепдкДњТыжаЃК
|
findAuthor("matthias k") map { idOrError
=> idOrError map { id => ...} }
|
ЭМ 5 ЯдЪОСЫЪЙгУАќКЌвўгїЕФетИіаЇЙћЖбЕўЃК
ЭМ 5. АќКЌвўгї 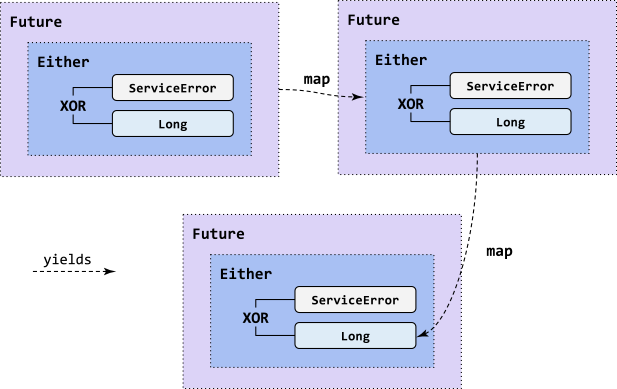
ЪЙгУЖбЕўаЇЙћвВНЋЦЦЛЕ for-comprehensions ЕФБуРћадЃЌвђЮЊЮоЗЈвЛДЮБщРњСНИіаЇЙћЁЃ РэЯыЧщПіЯТЃЌФњашвЊвЛИіНЋСНИіаЇЙћКЯЖўЮЊвЛЕФГщЯѓЃКШчЙћ
Future ГЩЙІВЂЧв Either АќКЌе§ШЗЕФНсЙћЃЌФЧУДгГЩфНсЙћЁЃЪТЪЕжЄУїЃЌCats ОЭЬсЙЉетбљвЛИіГщЯѓЃКmonad
зЊЛЛГЬађЁЃ
НЋаЇЙћЖбЕўгы monad зЊЛЛГЬађКЯВЂ
Monad зЊЛЛГЬађдЪаэФњЖбЕўаЇЙћШчЁАвьВНдЫааЁБ(Future) КЭЁАЖрИіНсЙћЁБ(Either)ЃЌВЂНЋЦфЪгЮЊвЛЬхЁЃЛЛОфЛАЫЕЃЌФњПЩвдМцЕУгуКЭамеЦЃЁCats
ЮЊвЛаЉЯжгаЕФаЇЙћРраЭЃЈШч Option КЭ EitherЃЉЬсЙЉ monad зЊЛЛГЬађЃЌЖдгк EitherЃЌГЦЮЊ
EitherTЁЃШУЮвУЧЪЙгУЫќЖЈвхЖЈжЦ Result РраЭЃЌИУРраЭНЋБэЪОЗўЮёжаЫбЫїНсЙћЕФЪфГіЃК
| //
bind Future and SearchError together while leaving
the inner result type unbound
type Result[A] = EitherT[Future, SearchError,
A]
// this allows you to invoke the companion object
as "Result"
val Result = EitherT |
ЭЈЙ§ИУЗНБуЕФРраЭЖЈвхЃЌФњПЩвдНєДеЧвПЩЖСЕФЗНЪНжиаТЖЈвхЗўЮёЙІФмЃЌВЂЧвВЛЪЇШЅФњЭЈЙ§ЪЙгУ Either ЛёЕУЕФШЮКЮЪЕгУГЬађЃК
| def
findAuthor(query: String): Result[Long] =
if (query == "matthias k") Result.rightT(42L)
else if (query.isEmpty) Result.leftT(InvalidQuery)
else Result.leftT(NotFound) |
ДЫДІЃЌleftT КЭ rightT ЪЧжњЪжКЏЪ§ЃЌЛсНЋИјЖЈЕФжЕЬсЩ§ЕНгУгкЪЕР§ЛЏ EitherTЃЈдкДЫР§жаЮЊ
FutureЃЉЕФаЇЙћРраЭжаЃЌШЛКѓеыЖд EitherЃЌЗжБ№зЊШызѓВрЃЈДэЮѓЃЉКЭгвВрЃЈГЩЙІЃЉЧщПіжаЁЃОЭ Result[Long]
ЖјбдЃЌжиаТБраДИУКЏЪ§ПЩНтОіЩЯУцЬсМАЕФЧЖЬзгГЩфЮЪЬтЃЌШчЭМ 6 ЫљЪОЁЃ
ЭМ 6. НтОіЧЖЬзгГЩф
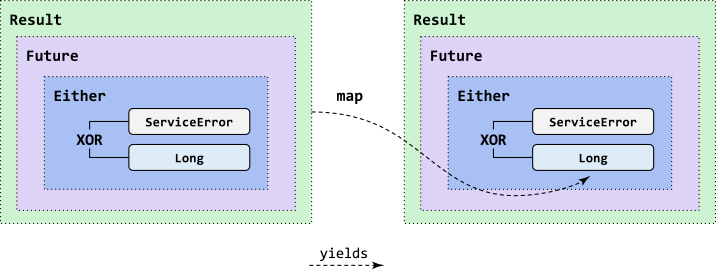
ПЩвдЖд getAuthor КЭ getPublications жДааЭЌбљЕФВйзїЃК
|
def getAuthor(id: Long): Result[Author] =
Result.rightT(Author(id, "Matthias K?ppler"))
def getPublications(authorId: Long): Result[List[Publication]]
=
Result.rightT(List(
Publication(1L, authorId, "Model-First
Microservices with Scala & Cats")
))
|
гЩгк EitherT БОЩэЪЧМђЕЅЖбЕў Future КЭ Either ЕФ monadЃЌвђДЫЙЙГЩетаЉЙІФмЕФЮФеТЫбЫїГЬађЛљБОБЃГжВЛБфЃК
|
def findPublications(query: String): Result[AuthorPublications]
=
for {
authorId <- findAuthor(query)
result <- getAuthor(authorId) product getPublications(authorId)
(author, pubs) = result
} yield AuthorPublications(author, pubs)
|
ЮЈвЛЕФБфЛЏЪЧгЩгк Scala БрвыЦїжаЕФЬиЕуЃЌФњВЛдйФмЙЛжБНгЩњГЩ (author, pubs) дЊзщЃЌЖјЪЧБиаыЯШдкСйЪБНсЙћжаВЖЛёГЫЛ§ЃЌШЛКѓдквЛИіЕЅЖРЕФВНжшжажДааГщШЁЁЃетЪЧвЛЕуаЁДњМлЁЃ
ФњЯждкзМБИдЫааАќКЌИїжжЙІФмЕФЮФеТЫбЫїЃК
| val
query = "matthias k"
val search: Result[Unit] = findPublications(query)
map { authorPubs =>
renderResponse(200, s"Found $authorPubs")
} recover {
case InvalidQuery => renderResponse(400,
s"Not a valid query: '$query'")
case NotFound => renderResponse(404, s"No
results found for '$query'")
}
Await.result(search.value, Duration.Inf) |
дкФњдчЧАЖЈвхЕФГЩЙІТЗОЖжЎЩЯЃЌФњЛЙНЋЪЙгУЖЈжЦДІРэГЬађЕїгУ recoverЃЌЛсНЋФњПЩФмгіЕНЕФДэЮѓгГЩфЕНЯргІЕФЗўЮёЯьгІЁЃгЩгк
search ВЛдйЪЧ Future ЖјЪЧ ResultЃЌвђДЫФњБиаыЕїгУЦфжЕЗНЗЈвдЛёШЁЕзВуЕФ FutureЃЌжЎКѓВХПЩвдЕШД§ЦфНсЙћЁЃ
| val
query = "matthias k"
val search: Result[Unit] = findPublications(query)
map { authorPubs =>
renderResponse(200, s"Found $authorPubs")
} recover {
case InvalidQuery => renderResponse(400,
s"Not a valid query: '$query'")
case NotFound => renderResponse(404, s"No
results found for '$query'")
}
Await.result(search.value, Duration.Inf) |
НсЪјгя
БОНЬГЬЪзЯШГаШЯЮЂЗўЮёзщКЯКмШнвзГіДэЃЌвЊИпаЇжДааЃЌБиаыНјааВЂааЛЏДІРэЃЌШЛКѓЫЕУїСЫПЩзщКЯЕФ Future
ШчКЮГЩЮЊвдКЏЪ§ЗНЪНЖдВЂЗЂЗўЮёЕїгУНјааНЈФЃЕФЧПДѓЙЄОпЁЃФњвВПДЕНСЫВЂаазщКЯЕФгаЯоФмСІЃЌетПЩвдЭЈЙ§ Cats
РЉГф Future РДНтОіЃЛетЪЙФњФмЙЛЩњГЩНсЙћдЊзщЁЃШЛКѓЃЌЮвУЧЯђФњеЙЪОСЫШчКЮЪЙгУУмЗтВуДЮНсЙЙБэЪОгђДэЮѓЃЌвдМАШчКЮЪЙгУ
Either БраДПЩвдЗЕЛиДэЮѓКЭжЕЕФЗўЮёКЏЪ§ЁЃЕЋЪЧЃЌЪЙгУДЫВЛЭЌаЇЙћЕФЖбеЛПЩФмЛсЗЧГЃТщЗГЃЌвђДЫЮвУЧЭЈЙ§НтЪЭШчКЮШУ
monad зЊЛЛГЬађЙЄзїРДЮЊФњЕФДњТыДјРДЧхЮњадЁЂПЩЖСадКЭБуРћадРДНтОіЮЪЬтЁЃећКЯКѓЃЌЫљгавЛЧаЖМдкЫЕУїОпгаЧПДѓРраЭЯЕЭГЕФКЏЪ§ЪНБрГЬбљЪНПЩвдШчКЮЩњГЩИЛгаБэДяСІЕФЮЂЗўЮёЃЌетаЉЮЂЗўЮёЛсНЋФЃаЭЗХдкЕквЛЮЛЃЌЖјВЛЛсгАЯьЦфБГКѓЭљЭљИпМЖЧвИДдгЕФЛњжЦЁЃ
|






