| ΈΔΖΰΈώ“―Ψ≠≥…ΈΣ‘Ϋά¥‘ΫΕύΤσ“ΒIT≤ΩΟ≈―–ΨΩΒΡΕ‘œσΘ§÷π≤Ϋ«ςœρ”ΎΜπ»»Θ§ ΐ»Υ‘Τ÷°«ΑΗχ¥σΦ“Ζ÷œμΙΐΘΚΓΕ Β¬Φ|ΈΔΖΰΈώΤσ“ΒΦΕ¬δΒΊΫΪΜα¥χά¥ΡΡ–©ΉΣ±δΘΩΓΖ…ν»κΒΊ≤ϊ ωΝΥΈΔΖΰΈώΡήΙΜ¥χά¥ΒΡάϊ“φΘ§ΒΪ «ΉςΈΣ“Μœν–¬–ΥΒΡΦΦ θΘ§ΉήΡ―ΟβΜα”ωΒΫ’β―υΜρΡ«―υΒΡΡ―ΧβΘ§ΫώΧλΨΆά¥“ΜΤπΩ¥Ω¥ΈΔΖΰΈώΒΡΡ―Βψ÷°“ΜΘΚΖΰΈώΒς”ΟΒΡΫβΨωΖΫΑΗΓΘ
ΈΔΖΰΈώ”–ΚήΕύΡ―ΒψΘ§±»»γΖ÷≤Φ ΫœΒΆ≥ΘΚ
±ΨΈΡΉς’Ώ”κΚλΟ±ΒΡΕΞΦΕ’Ϋ¬‘ΩΆΜßΫτΟήΚœΉςΘ§Αο÷ζΤδ≥…ΙΠΒΊΦί‘Π’β–©άßΡ―ΒΡ≤ΩΖ÷Θ§ Βœ÷ΖΰΈώΩρΦή“‘±Θ≥÷ΨΚ’υΝΠΘ§ΗυΨί¥¥–¬»Ξ¥¥‘λ…Χ“ΒΦέ÷ΒΘ§Ής’Ώ“≤Ζ«≥ΘΫ”Ϋϋ”ΎΩΣ‘¥…γ«χ÷–ΦΦ θΒΡΩλΥΌΖΔ’ΙΓΘ
Β±ΦΧ–χ‘ΎΖΰΈώΦήΙΙΒΡ’β–©Η≈Ρν…œΫχ––ΧΫΧ÷ ±Θ§≤ΜΩ…±ήΟβΒΡΜαΕ‘“Μ–©Ρ―ΧβΫχ––Χ÷¬έΘ§Ής’ΏœΘΆϊ‘ΎΧΫΥς≤Δ Βœ÷ΈΔΖΰΈώ ±Θ§“―Ψ≠Ω¥ΒΫ≤ΔœϊΜ·ΝΥΖ÷≤Φ ΫΦΤΥψΒΡ¥μΈσΘ§Ά§ ±Ής’Ώ“≤ΆΤΦωΝΥJeff
HodgesΒΡΓΕNotes on Distributed Systems for Young Bloods
ΓΖΓΘ
¥σ≤ΩΖ÷“Μ÷±‘Ύ”ΟΙΐ ±ΒΡΖΫΖ®»ΞΫβΨω’β–©Έ ΧβΘ§≤Δ“Μ÷±‘Ύ―Α’“ΓΑ»γΚΈ»ΟΩΣΖΔ’Ώ±ύ–¥ΡήΙΜΫΜΗΕΦέ÷Β≤Δ≥Δ ‘≥ιœσΖ÷≤Φ ΫœΒΆ≥ΒΡ“ΒΈώ¬ΏΦ≠Γ±ΒΡΫβΨωΖΫΑΗΓΘΥυΉωΒΡ ¬«ι «ΈΣΝΥ»ΟΖΰΈώΒς”ΟΩ¥Τπά¥»γ±ΨΒΊΒς”ΟΆ®Ιΐ≥ιœσΒΡΆχ¬γ”κ±ΨΒΊΫ”ΩΎΘ®CORBAΓΔDCOMΓΔejb»»ȩȧΒΪΚσά¥ΖΔœ÷’β≤Δ≤Μ «“ΜΗωΚΟΖΫΖ®Θ§»ΜΚσ«–ΜΜΒΫWSDL/SOAP/¥ζ¬κ…ζ≥…άύΥΤΒΡΕΪΈςΘ§“‘ΑΎΆ―’β–©ΤδΥϊ–≠“ιΒΡ¥ύ»θ–‘Θ§ΒΪ»‘»Μ Ι”ΟœύΆ§ΒΡ ΒΦυΘ®SOAPΩΆΜßΜζ¥ζ¬κ…ζ≥…Θ©Θ§”––©»Υ»Ζ »ϒ▩ΖΫΖ®Ήύ–ßΝΥΘ§ΒΪ“≤”–ΚήΕύ≤ΜΉψ÷°¥ΠΘ§œ¬Οφά¥Ω¥Ω¥Β±ΦρΒΞΒΊΒς”ΟΖΰΈώ ±Μα”ωΒΫΒΡ“Μ–©Έ ΧβΘΚ
¥μΈσΜρ―”≥Ό
÷Ί ‘
¬Ζ”…
ΖΰΈώΖΔœ÷
Ω…Ιέ≤λ–‘

¥μΈσΜρ―”≥Ό
Β±Έ“Ο«œρΖΰΈώΖΔΥΆœϊœΔ ±ΜαΖΔ…ζ ≤Ο¥ΘΩ≥ω”Ύ’βΗωΧ÷¬έΒΡΡΩΒΡΘ§’βΗω«κ«σ±ΜΖ÷≥…–ΓΩι≤ΔΆ®ΙΐΆχ¬γ¬Ζ”…ΓΘ
“ρΈΣ’βΗωΓΑΆχ¬γΓ±Θ§Έ“Ο«¥ΠάμΖ÷≤Φ ΫΦΤΥψ¥μΈσœκΖ®Θ§”Π”Ο≥Χ–ρΆ®Ιΐ“λ≤ΫΆχ¬γΫχ––Ά®–≈Θ§’β“βΈΕΉ≈Ε‘ ±ΦδΟΜ”–ΒΞ“Μ«“Ά≥“ΜΒΡάμΫβΘ§ΖΰΈώ“‘Ή‘ΦΚΕ‘ΓΑ ±ΦδΒΡΚ§“εΓ±άμΫβ»ΞΙΛΉςΘ§’βΩ…Ρή”κΤδΥϊΖΰΈώ≤ΜΆ§Θ§Ηϋ÷Ί“ΣΒΡ «Θ§’β–©“λ≤ΫΆχ¬γ¬Ζ”… ΐΨίΑϋΗυΨίΩ…”Ο–‘ΒΡ¬ΖΨΕΓΔ”ΒΕ¬ΓΔ”≤ΦΰΙΡ’ΤΒ»Θ§ΟΜ”–±Θ÷ΛœϊœΔ‘Ύ”–œόΒΡ ±ΦδΡΎΫΪΤδΫ” ή’ΏΘ®ΉΔ“βΘ§’βΗωœύΆ§ΒΡœ÷œσΖΔ…ζ‘ΎΓΑΆ§≤ΫΓ±Άχ¬γΟΜ”–“ΜΗωΆ≥“ΜΒΡάμΫβ ±ΦδΘ©ΓΘ
’βΤδ ΒΚή‘ψΗβΘ§œ÷‘Ύ≤ΜΩ…Ρή»ΖΕ®¥μΈσΜρ÷Μ «ΜΚ¬ΐΘ§»γΙϊΩΆΜß“Σ«σ‘Ύ έΤ±Άχ’Ψ…œΥ―Υς―ί≥ΣΜαΘ§Ω…≤ΜœκΒ»ΒΫΧλΜΡΒΊάœΘ§œΘΆϊΡήΒΟΒΫœλ”ΠΘ§‘ΎΡ≥Ηω ±ΚρΘ§«κ«σ ßΑήΘ§Υυ“‘–η“Σ‘ωΦ”ΖΰΈώΒΡ≥§ ± ±ΦδΘ§ΒΪ“≤≤ΜΫωœό”Ύ‘ωΦ”ΖΰΈώ ±ΦδΓΘ
‘Ύ¥Πάμœ¬”Έ«κ«σ ±Θ§≤ΜΡή“ρΈΣDown-StreamΆχ¬γΫΜΜΞΥΌΕ»Εχ¬ΐœ¬ά¥Θ§“Σ”–“Μ–© ±Φδ»ΞΩΦ¬«…η÷ΟΘΚ
Ϋ®ΝΔΒΫœ¬”ΈΖΰΈώΒΡΝ¥Ϋ”–η“ΣΕύ≥Λ ±ΦδΘ§’β―υ≤≈Ρή»ΞΖΔΥΆ«κ«σ
«Ζώ ’ΒΫΜΊΗ¥
≤Ι≥δΥΒΟςΘΚΙΙΫ®œΒΆ≥ΉςΈΣΖΰΈώΦήΙΙΒΡΨό¥σ”≈ Τ «ΥΌΕ»Θ§Αϋά®Ε‘œΒΆ≥Ϋχ––ΗϋΗΡΒΡΥΌΕ»Θ§÷Ί ”Ή‘÷ΈΚΆœΒΆ≥ΒΡΤΒΖ±≤Ω πΘ§ΒΪΒ±»Ξ’β―υΉωΒΡ ±ΚρΜαΚήΩλΖΔœ÷Θ§‘Ύ“Μ«–ΤφΙ÷ΒΡ«ιΩωœ¬Θ§≥§ ±ΙΛΉςΘ§≤Δ≤ΜΡήΚήΚΟΒΊΫχ––ΓΘ
ΩΦ¬«ΒΫΩΆΜßΜζ”Π”Ο…η÷ΟΝΥ3Ηω≥§ ±Θ§¥”ΆΤΦω“ΐ«φ÷–ΒΟΒΫœύ”ΠΘ§ΒΪΆΤΦω“ΐ«φ“≤Ή…―·œύΙΊ“ΐ«φΘ§“ρ¥ΥΘ§ΥϋΖΔ≥ωΝΥ“ΜΗω…η÷ΟΈΣ2SΒΡ≥§ ±Βς”ΟΘ§’βΗω”ΠΗΟΟΜ”–Έ ΧβΘ§“ρΈΣ…–”–ΖΰΈώΒς”ΟΫΪΒ»¥ΐΉνΕύ3ΗωΘ§ΒΪ»γΙϊΙΊΝΣ“ΐ«φ±Ί–κ”κ¥ΌœζΖΰΈώΫχ––Ε‘ΜΑΗΟ‘θΟ¥ΑλΡΊΘΩ»γΙϊ≥§ ±…η÷ΟΈΣ5SΡΊΘΩΈ“Ο«ΒΡ≤β ‘Θ®ΒΞ‘ΣΓΔ±ΨΒΊΓΔΦ·≥…Θ©ΒΡΙΊΝΣ“ΐ«φΥΤΚθΆ®ΙΐΝΥΥυ”–ΒΡ≤β ‘Θ§…θ÷Ν‘Ύ«±‘ΎΒΡ≤ΌΉςœ¬Θ§“ρΈΣ≥§ ±…η÷ΟΈΣ5SΘ§ΆΤΙψΖΰΈώ“≤≤ΜΜαΜ®Ρ«Ο¥≥ΛΒΡ ±ΦδΘ§Μρ’Ώ‘Ύ≥§ ±Ϋα χΚσΘ§ΙΊΝΣ“ΐ«φ Β±ΒΊΫα χΝΥΒς”ΟΓΘ
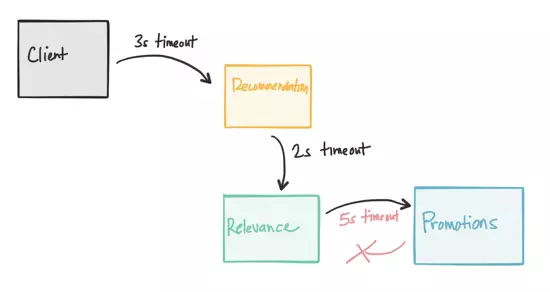
Ήν÷’ΒΟΒΫΒΡ «“ΜΗωΖ±ΥωΒΡΘ§ΚήΡ―Βς ‘ΚήΕύΒγΜΑΫχά¥ ±ΒΡΉ¥Χ§Θ®’βΩ…ΡήΖΔ…ζ‘Ύ»ΈΚΈ ±ΦδΘ§“ρΈΣΆχ¬γ «ΓΑ“λ≤ΫΓ±ΒΡΘ©Θ§≥§ ± «Κή÷Ί“ΣΒΡ“ΜΗωΧθΦΰΓΘ
÷Ί ‘
”…”Ύ»Ζ ΒΟΜ”–‘ΎΖ÷≤Φ ΫœΒΆ≥÷–”–»ΈΚΈΒ·–‘ΒΡ ±Φδ±Θ÷ΛΘ§Υυ“‘–η“Σ‘Ύ»ΈΈώΜ®Ζ―ΧΪ≥Λ ±Φδ ±≥§ ±Θ§œ÷‘ΎΒΡ«ιΩω «ΓΑ≥§ ±Κσ“ΣΉω ≤Ο¥ΘΩΓ± «≤Μ «œρά¥Βγ’Ώ≈Ή≥ω“ΜΗω‘ψΗβΒΡHTTP
5XXΘΩ «ΖώΫ” ή“Μ–©Ϋ®“ιΘ§»ΟΈΔΖΰΈώ±δΒΟ”–Β·–‘Θ§≥–≈Βάμ¬έΚΆΜΊΒςΘΩΜΙ «Έ“Ο«÷Ί ‘ΘΩ
»τ“Σ÷Ί ‘Θ§»γΙϊΒς”ΟΝΥΗϋΗΡœ¬”ΈΖΰΈώΒΡ ΐΨίΜα‘θ―υΘΩΉς’Ώ‘ΎΤδΥϊΈΡ’¬ΧαΒΫΙΐΘ§ΈΔΖΰΈώΉνΡ―ΒΡ≤ΩΖ÷÷°“Μ“≤ « ΐΨίΖΫΟφΓΘ
ΒΪΗϋ”–“βΥΦΒΡ «Θ§»γΙϊœ¬”ΈΖΰΈώΩΣ Φ ßΑήΘ§Ήν÷’Μα÷Ί–¬≥Δ ‘Υυ”–ΒΡ«κ«σΡΊΘΩ»γΙϊ”–10ΗωΜρ100Ηω ΒάΐΒΡΆΤΦω“ΐ«φΒς”ΟΙΊΝΣ“ΐ«φΘ§ΒΪΙΊΝΣ“ΐ«φ≥§ ±ΝΥ‘θΟ¥ΑλΘΩΉνΚσΒΟΒΫΝΥThundering
Herd ProblemΒΡ“ΜΗω±δ÷÷Θ§Β± ‘ΆΦ≤ΙΨ»Θ§≤Δ¬ΐ¬ΐΒΊΜ÷Η¥ ή”ΑœλΒΡΖΰΈώ ±Θ§’βΨΆΫα χΝΥDDoSΒΡΖΰΈώΘ§Φ¥ ΙΈ“Ο« ‘ΆΦ≤ΙΨ»ΚΆΜΚ¬ΐΒΊΖΒΜΊ ή”ΑœλΒΡΖΰΈώΓΘ
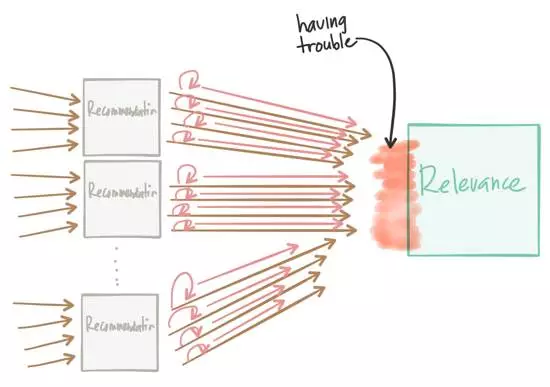
–η“ΣΉΔ“β÷Ί ‘≤Ώ¬‘ΓΘ÷Η ΐ÷Ί ‘ΒΡΜΊΆΥΜα”–ΥυΑο÷ζΘ§ΒΪΩ…Ρή»‘»ΜΜα”ωΒΫΆ§―υΒΡΈ ΧβΓΘ
¬Ζ”…
“ρΈΣΖΰΈώ «‘ΎΩΦ¬«Β·–‘ΒΡ«ιΩωœ¬≤Ω πΒΡΘ§Υυ“‘‘ΎάμœκΒΡ«ιΩωœ¬Θ§‘Ύ≤ΜΆ§ΒΡ»ί¥μ«χ”ρ÷–‘Υ––ΕύΗω ΒάΐΘ§’β―υ“Μ–©«χ”ρ‘Ύ≤ΜΫΒΒΆΖΰΈώΒΡΩ…”Ο–‘«ιΩωœ¬ΨΆΜα ßΑήΘ§ΒΪΒ± ¬ΦΰΩΣ Φ ßΑή ±Θ§–η“Σ“Μ÷÷ΖΫΖ®»Ξ»ΤΙΐ’β–© ßΑήΘ§ΒΪ‘Ύ»ί¥μ«χ”ρ÷¥ΫΘΘ§Ω…Ρή”–ΤδΥϊΒΡΖΰΈώ¬Ζ”…―Γ‘ώ‘≠“ρΓΘ“≤–μΡ≥–©ΓΑ«χ”ρΓ±±Μ Βœ÷ΉςΈΣ±ΗΖίΒΡΖΰΈώΒΡΒΊάμ≤Ω πΘΜ“≤–μ¥”―”≥ΌΒΡΫ«Ε»»ΞΩ¥Θ§»ΟΈ“Ο«ΒΡΝςΝΩ‘Ύ’ΐ≥Θ‘Υ–– ±ΖΟΈ ±ΗΖί ΒάΐΧΪΙσΝΥΓΘ
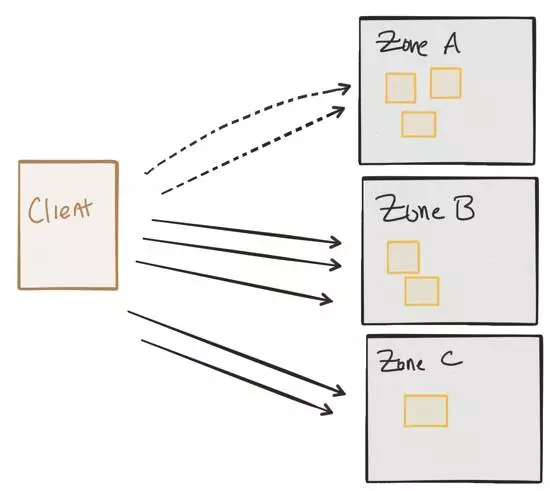
“≤–μœκ“Σœώ’β―υ¬Ζ”…ΩΆΜßΕΥΝςΝΩΘ§ΒΪΖΰΈώΦδΆ®–≈ΡΊΘΩΈΣΝΥ¬ζΉψΩΆΜßΕΥ«κ«σΘ§±Ί–κ‘ΎΖΰΈώ÷°ΦδΫχ––Ζ¥œρΕ‘ΜΑΘ§Ρ«Ο¥¬Ζ”…”÷»γΚΈ―Γ‘ώΡΊΘΩ
»ί¥μ–‘«χ”ρ÷¥ΫΘΒΡ¬Ζ”…±δΜ·Ω…Ρή «¬Ζ”…ΚΆΗΚ‘ΊΨυΚβ«κ«σΘ§Εχ’β–©«κ«σ «‘ΎΩ…Ρή≥ωœ÷÷ήΤΎ–‘ΒΡ“λ≥ΘΖΰΈώΒΡ«ιΩωœ¬Ϋχ––ΒΡΘ§œΘΆϊΫΪ¬Ζ”…Βς’ϊΒΫΡήΙΜ”κΖΰΈώΒς”Ο±Θ≥÷“Μ÷¬ΒΡΖΰΈώΘ§ΫΪΝςΝΩΖΔΥΆΒΫΈόΖ®Ηζ…œΒΡΖΰΈώ…œ «ΟΜ”– ≤Ο¥“β“εΒΡΓΘ
Β±Χ÷¬έ»γΚΈ≤Ω πΖΰΈώΒΡ–¬Αφ±Ψ ±Θ§”ΠΗΟ»ΞΩΦ¬«ΗϋΦ§ ÷ΒΡΈ ΧβΘ§’ΐ»γ«ΑΟφΥυΥΒΘ§œΘΆϊ‘ΎΖΰΈώ÷°Φδ±Θ≥÷Ρ≥÷÷≥ΧΕ»…œΒΡΉ‘÷ΈΘ§’β―υΨΆΩ…“‘ΩλΥΌΒϋ¥ζΚΆΆΤΕ·ΗϋΗΡΘ§≤ΜœΘΆϊΤΤΜΒ“άάΒΖΰΈώΘ§“ρ¥ΥΘ§»γΙϊΩ…“‘ΫΪΡ≥–©ΝςΝΩ¬Ζ”…ΒΫ–¬Αφ±ΨΘ§≤ΔΫΪΤδΑσΕ®ΒΫΙΙΫ®ΚΆΖΔ≤Φ≤Ώ¬‘Θ®Φ¥άΕ/¬ΧΘ§A/B≤β ‘Θ§CanaryΖΔ––ΑφΘ©Θ§’β―υΚήΩλΨΆ±δΒΟΗ¥‘”ΝΥΘ§»γΚΈ»ΖΕ®¬ΖœΏΘΩ“≤–μ’ΐ‘ΎΉωΒΡ «‘Ύ“ΜΗωΧΊ βΒΡΓΑΒ«Χ®ΜΖΨ≥Γ±÷–Ϋχ––≤β ‘Θ§“≤–μ÷Μ «‘ΎΉω“ΜΗωΈ¥Ψ≠–ϊ≤ΦΒΡDark
LaunchΘ§“≤–μ «A/B≤β ‘Θ§ΒΪ»γΙϊ”–Ρ≥÷÷Ή¥Χ§Θ§–η“ΣΩΦ¬« ΐΨίΡΘ Ϋ―ίΜ·ΓΔΕύΑφ±Ψ ΐΨίΩβ Βœ÷Β»ΓΘ
ΖΰΈώΖΔœ÷
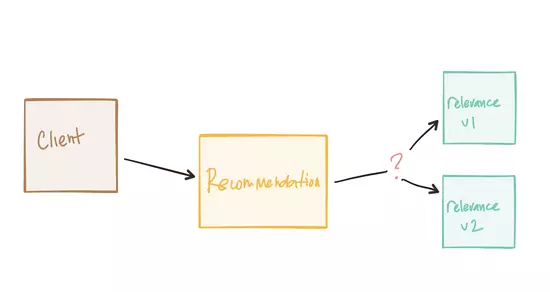
≥ΐΝΥ«ΑΟφΧ÷¬έΒΡ“Μ–©Β·–‘ΩΦ¬«÷°ΆβΘ§‘ΎExpect ßΑήΒΡΜΖΨ≥÷–Θ§»γΚΈΖΔœ÷–≠ΉςΖΰΈώΘΩ‘θΟ¥÷ΣΒάΥϋΟ«‘ΎΡΡάοΘ§»γΚΈΚΆΥϋΟ«Ϋχ––Ά®–≈ΘΩ‘Ύ≤“Ά¥ΒΡΨ≤Χ§ΆΊΤΥ÷–Θ§”Π”ΟΫΪ±Μ≈δ÷ΟΈΣ–η“ΣΧ÷¬έΖΰΈώΒΡURL/IPsΘ§ΜΙΫΪΙΙΫ®’β–©“άάΒΖΰΈώΘ§“‘ΓΑ”Ο”ά≤Μ ßΑήΓ±ΒΪ≤ΜΩ…±ήΟβΒΡ «Θ§ΥϋΟ«Μα“‘“Μ–©≤ΜΡήΫ” ήΒΡΖΫ Ϋ ßΑήΘ®Μρ≤ΩΖ÷ ßΑήΘ©Θ§ΒΪ‘Ύ“ΜΗωΒ·–‘ΒΡΜΖΨ≥÷–Θ§œ¬”ΈΒΡΖΰΈώΩ…“‘Ή‘Ε·…λΥθΘ§Ε‘≤ΜΆ§ΒΡ»ί¥μ«χ”ρΫχ––ΗΡ‘λΘ§ΜρΦρΒΞΒΊ±Μ“Μ–©Ή‘Ε·Μ·œΒΆ≥»Ξ≥ΐΚΆ÷Ί–¬ΤτΕ·Θ§’β–©ΖΰΈώΒΡΩΆΜßΕΥ–η“ΣΡήΙΜ‘Ύ‘Υ–– ±ΖΔœ÷ΥϋΟ«Θ§≤Δ«“≤ΜΙήΆΊΤΥ « ≤Ο¥―υΉ”ΕΦΩ…“‘ Ι”ΟΥϋΟ«ΓΘ
’β≤Μ «“ΜΗω“Σ–¬ΫβΨωΒΡΈ ΧβΘ§Εχ‘ΎΒ·–‘ΜΖΨ≥÷–±δΒΟάßΡ―Θ§»γDNS’β―υΒΡΕΪΈς «Τπ≤ΜΒΫΉς”ΟΒΡΘ®≥ΐΖ«‘ΎKubernetes÷–‘Υ––Θ©ΓΘ
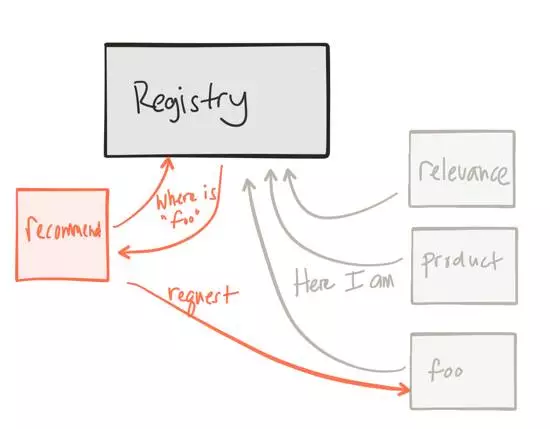
–≈»ΈΉ‘ΦΚΒΡΖΰΈώΦήΙΙ
±ΨΈΡΫΪΉν÷Ί“ΣΒΡΩΦ¬«/Έ ΧβΝτΒΫΉνΚσΘ§ΈΔΖΰΈώΩ…“‘ΩλΥΌΗΡ±δœΒΆ≥ΦήΙΙΘ§»γΙϊΡψ≤ΜΡή–≈»ΈΉ‘ΦΚΒΡœΒΆ≥Θ§Ρ«Ο¥ΡψΨΆΜα”Χ‘Ξ «Ζώ“ΣΕ‘ΥϋΫχ––ΗΡ‘λΘ§’β―υΨΆΜαΖ≈¬ΐΖΔ≤ΦΥΌΕ»Θ§»γΙϊ≤Ω π±δ¬ΐΘ§ΫΪ“βΈΕΉ≈Μα–η“ΣΗϋ≥ΛΒΡ÷ήΤΎ ±ΦδΘ§ΒΦ÷¬ΝΥΩ…Ρή≥Δ ‘≤Ω πΗϋ¥σΒΡΗϋΗΡΘ§Ά≈Ε”÷°Φδ–η“ΣΗϋΕύΒΡ–≠ΒςΘ§‘ΎΕσ…±Τσ“ΒITΡήΝΠ÷°«ΑΘ§ΡψΫΪΜαΨθΒΟΓΑ’βΨΆ «Έ“Ο«ΒΡ“ΜΙαΧ§Ε»Γ±Θ§ΧΐΤπά¥ «≤Μ «Κή λœΛΘΩ
–η“ΣΕ‘Ή‘ΦΚΒΡœΒΆ≥”––≈–ΡΘ§»Ξ–≈»ΈΥϋΘ§Ω…Ρή”––©Μυ¥Γ…η ©ΒΡΗ¥‘”ΉιΚœΘ®Έοάμ/–ιΡβ/ΥΫ”–‘Τ/ΙΪ”–‘Τ/ΜλΚœ‘Τ/»ίΤςΘ©Θ§”–¥σΝΩΒΡ÷–ΦδΦΰΓΔΖΰΈώΓΔΩρΦήΓΔ”ο―‘ΚΆΟΩΗωΖΰΈώΒΡ≤Ω πΘ§»γΙϊ“ΜΗω«κ«σ «ΜΚ¬ΐΒΡΘ§Ρ«Ο¥“Σ¥”ΡΡάοΩΣ ΦΡΊΘΩ
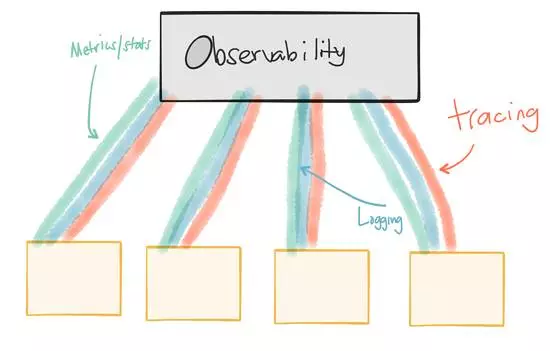
‘ΎœΒΆ≥÷–Θ§–η“ΣΚή«ΩΒΡΓΑΙέ≤λ–‘Γ±Θ§–η“Σ”–”Ο«“”––ßΒΡ»’÷ΨΦ«¬ΦΓΔΕ»ΝΩΚΆΗζΉΌΘ§»γΙϊΩλΥΌΒΊΒϋ¥ζΚΆΖΔ≤ΦΖΰΈώΘ§–η“Σ ΐΨί«ΐΕ·Θ§άμΫβΗϋΗΡΒΡ”ΑœλΘ§ΜΊΙωΒΡ“β“εΘ§Μρ’ΏΩλΥΌΖΔ≤Φ–¬ΒΡΑφ±Ψ»Ξ¥ΠάμΗΚΟφΒΡ”ΑœλΘ§œΒΆ≥ΒΡΥυ”–≤ΩΖ÷ΕΦ–η“ΣΡήΙΜΧαΙ©Ω…ΩΩΒΡΩ…Ιέ≤λ–‘Θ®»’÷Ψ/÷Η±ξ/ΦύΩΊΘ©Θ§‘Ϋ «œύ–≈’β–© ΐΨίΘ§‘Ϋ «Ρή–≈»ΈΉ‘ΦΚΒΡΖΰΈώΦήΙΙΘ§“≤ΨΆ‘Ϋ”––≈–Ρ»ΞΗυΨί«ιΩωΫχ––ΗΡΫχΓΘ
ΜΊΙΥ
ΜΊΙΥ“Μœ¬Θ§Β±ΖΰΈώΒς”ΟΤδΥϊΖΰΈώ ±Θ§–η“Σ»ΞΫβΨωΒΡΈ ΧβΘΚ
ΖΰΈώΖΔœ÷
Ή‘Ε· ”Π¬Ζ”…/ΩΆΜßΕΥΗΚ‘ΊΨυΚβ
Ή‘Ε·÷Ί ‘
≥§ ±ΩΊ÷Τ
ΥΌΕ»œό÷Τ
÷Η±ξ/Ά≥ΦΤ ΐΨί ’Φ·
ΦύΩΊ
A/B≤β ‘
ΖΰΈώ÷ΊΙΙ/«κ«σΗζΉΌ
ΩγΖΰΈώΒς”ΟΒΡΖΰΈώΤΎœό/≥§ ±÷¥––
Α≤»ΪΖΰΈώ
±Ώ‘ΒΆχΙΊ/¬Ζ”…Τς
«Ω÷ΤΖΰΈώΗτάκ/άκ»ΚΦλ≤β
ΡΎ≤ΩΑφ±Ψ/ΑΒΤτΕ·
ΫβΨωΖΫΑΗ
Ϋ”œ¬ά¥Ω¥Ω¥Ρ«–©ΨόΆΖΙΪΥΨ «»γΚΈΉωΒΡΘ§»γΙϊΡψΩ¥Ω¥Google/Twitter / Amazon / NetflixΒΡ»ΥΫβΨωΝΥ’βΗωΈ ΧβΘ§ΡψΜαΩ¥ΒΫΥϋΟ«Τδ ΒΚή±©ΝΠΒΡΨΆΫβΨωΝΥ’βΗωΈ ΧβΘ§ΥϋΟ«Μυ±Ψ…œΜαΥΒΘΚΈ“Ο«ΫΪ Ι”ΟJava/c++/PythonΘ§±χΆΕ»κ ΐ≤Μ«εΒΡ«Ω¥σΙΛ≥ΧΝΠΝΩ»ΞΙΙΫ®ΩβΘ§“‘Αο÷ζΩΣΖΔ»Υ‘±»ΞΫβΨω’βΗωΈ ΧβΓΘΓ±“ρ¥ΥGoogle¥¥Ϋ®ΝΥStubbyΘ§Twitter¥¥Ϋ®ΝΥFinagleΘ§Netflix¥¥Ϋ®ΚΆΩΣ‘¥ΝΥNetflix
OSS»»ȧΤδΥϊΒΡ»Υ“≤ΕΦ «’β―υΉωΒΡΓΘ
ΒΪΕ‘”ΎΤδΥϊ»Υά¥ΥΒΘ§’β÷÷ΖΫ ΫΤδ Β¥φ‘Ύ“ΜΗω÷Ί¥σΒΡΈ ΧβΘΚ
Ρψ≤Δ≤Μ «’β–©ΨόΆΖΙΪΥΨΓΘ
ΆΕ»κ¥σΝΩΒΡ»ΥΝΠΉ ±ΨΉ ‘¥»ΞΫβΨω’β–©Έ Χβ «≤Μ«– ΒΦ ΒΡΘ§“Μ–©Ε‘ΈΔΖΰΈώΗ––Υ»ΛΒΡΙΪΥΨΤδ ΒΗ––Υ»ΛΒΡΖΫœρ «Ε‘Φέ÷ΒΚΆ¥¥–¬ΒΡΥΌΕ»Θ§ΒΪΥϋΟ«≤ΔΟΜ”–Ή®“ΒΝλ”ρΒΡ÷Σ ΕΓΘ
“≤–μΩ…“‘÷Ί–¬ Ι”ΟΥϋΟ«ΒΡΫβΨωΖΫΑΗΘΩΒΪ“≤”÷“ΐ≥ωΝΥΝμΆβ“ΜΗωΈ ΧβΘΚ‘ΎΉνΚσΘ§ΫΪΜαΒΟΒΫ“ΜΗωΖ«≥ΘΗ¥‘”ΓΔΧΊ±πΓΔ÷ΜΡή Βœ÷≤ΩΖ÷ΒΡΫβΨωΖΫΑΗΓΘ
ΨΌάΐΥΒΟςΘ§Ής’Ώ”κ–μΕύΩΆΜßΫΜΜΞΒΡ «Java…ΧΒξΘ§ΥϋΟ«ΩΦ¬«ΫβΨωJavaΖΰΈώΒΡ’βΗωΈ ΧβΘ§ΚήΉ‘»ΜΒΊΘ§Μα±ΜNetflixΒΡOSSΜρSpring
CloudΥυΈϋ“ΐΘ§ΒΪ «NodeJSΖΰΈώΡΊΘΩPythonΖΰΈώΡΊΘΩ“≈Ντ”Π”ΟΡΊΘΩPerlΫ≈±ΨΡΊΘΩ
ΟΩ÷÷”ο―‘ΕΦ”–Ή‘ΦΚΕ‘”Ύ’β–©Έ ΧβΒΡ Βœ÷Θ§ΟΩ“Μ÷÷ΕΦ±Μ÷¥––ΒΫ≤ΜΆ§ΒΡ÷ ΝΩΘ§Υϋ≤ΜœώΉΞ»ΓΩΣ‘¥Ωβ≤ΔΫΪΤδΧν≥δΒΫ”Π”Ο÷–Ρ«―υΦρΒΞΘ§±Ί–κ≤β ‘≤Δ«“―ι÷ΛΟΩΗω Βœ÷Θ§–η“ΣΗΚ‘π «≤Μ «’β–©ΩβΘ§Εχ «ΖΰΈώΧεœΒΫαΙΙΘ§Ω…Ρή Βœ÷ά©…Δ/”ο―‘/Αφ±ΨΚήΩλΨΆΜα≥…ΈΣ“ΜΗω≤ΜΩ…”β‘ΫΒΡΗ¥‘”–‘ΓΘ
Ής’Ώ’ΐ‘Ύ”Π”Ο≤ψ Βœ÷ΫœΒΆΦΕ±πΒΡΆχ¬γΙΠΡήΘ§±»Ϋœœ≤ΜΕOliver Gould‘ΎΧαΒΫ’β–©Έ Χβ ±Θ®»γ¬Ζ”…ΓΔ÷Ί ‘ΓΔœόΥΌΓΔΕœ¬ΖΒ»Θ©Θ§’β–©ΕΦ «5≤ψΩΦ¬«ΒΡΈ ΧβΙέΒψΘΚ
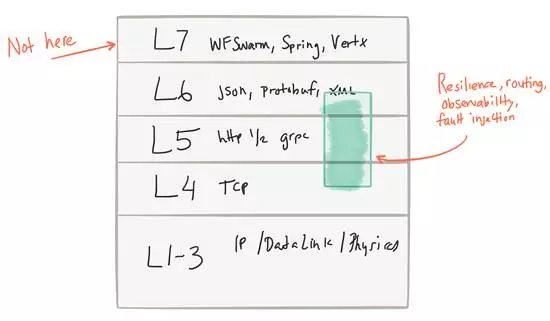
Ρ«Ο¥ΈΣ ≤Ο¥“ΣΑ―’β–©ΕΪΈςΗ¥‘”Μ·ΘΩ“Μ÷±‘Ύ ‘ΆΦΫβΨω’β–©Έ ΧβΒΡ”Π”ΟΆ®Ιΐ¥¥Ϋ®ΩβΘ®ΖΰΈώΖΔœ÷Θ§ΗζΉΌΘ§≤ΜΆ§ΒΡ ΐΨίΦ·ΚœΘ§ΉωΗϋΗ¥‘”ΒΡ¬Ζ”…Β»Θ©ΚΆΗ…»≈ΒΫΒΡ”Π”ΟΩ’ΦδΘ®“άάΒΙΊœΒΓΔ¥ΪΒί“άάΒΩβΒς”Ο»»ȩȧ»γΙϊΖΰΈώΩΣΖΔ’ΏΆϋΦ«ΧμΦ”ΗΟ Βœ÷ΒΡ“Μ≤ΩΖ÷Θ®άΐ»γΗζΉΌΘ©Θ§ΜαΖΔ…ζ ≤Ο¥«ιΩωΘΩ“ρ¥ΥΘ§ΟΩΗωΩΣΖΔ’ΏΕΦ”–‘π»Έ»Ξ Βœ÷’β–©ΙΠΡήΘ§“ΐ»κΒΫ’ΐ»ΖΒΡΩβΘ§‘Ύ¥ζ¬κ÷–±ύ–¥Υϋϫ»»ΓΘ
Ηϋ≤Μ”ΟΥΒ‘ΎJavaΜΖΨ≥÷– Ι”ΟΉΔ ΆΒΡ≈δ÷Ο»ΞΜΚΫβ’β–©«ιΩωΒΡ“Μ–©ΩρΦήΘ§–≈»ΈΓΔΩ…Ιέ≤λ–‘ΓΔΒς ‘–‘Β»ΒΡΡΩ±ξ±Μ’β―υΒΡΖΫΖ®ΥυΚω¬‘ΓΘ
Ής’ΏΗϋΤΪΑ°“Μ÷÷ΡήΙΜ“‘Ηϋ”≈―≈ΒΡΖΫ Ϋ»Ξ Βœ÷’β“ΜΒψΘΚ
IMHO’β «ΖΰΈώ¥ζάμ/SidecarΡΘ ΫΩ…“‘ΧαΙ©Αο÷ζΒΡΒΊΖΫΘ§»γΙϊΡήΫβ≥ω’β–©‘Φ χΧθΦΰΘΚ
»γΙϊ”–ΒΡΜΑΘ§ΫΪ»ΈΚΈ”Π”ΟΦΕ±πΒΡΗ–÷ΣΦθ…ΌΒΫΥωΥιΒΡΩβ
‘Ύ“ΜΗωΒΊΖΫ Βœ÷Υυ”–ΒΡ’β–©ΧΊ–‘Θ§Εχ≤Μ «…Δ≤Φ“άάΒœνΒΡ«ψ–Ε«χ
ΙΩ…Ιέ≤λ–‘≥…ΈΣ“ΜΝςΒΡ…ηΦΤΡΩ±ξ
ΙΥϋΕ‘Αϋά®“≈ΝτΖΰΈώ‘ΎΡΎΒΡΖΰΈώΆΗΟς
Ζ«≥ΘΒΆΒΡΩΣœζ/Ή ‘¥”Αœλ
ΈΣ»ΈΚΈΜρΥυ”–ΒΡ”ο―‘/ΩρΦήΙΛΉς
ΫΪ’β–©ΩΦ¬«“ρΥΊΆΤΒΫΫœΒΆΒΡΕ―’ΜΦΕ±πΘ®Φϊ…œΈΡΘ©
‘ΎΉνΫϋΒΡ“Μ–©ΈΔΖΰΈώΒΡ«Α―ΊΙΪΥΨΘ§Ής’ΏΩ¥ΒΫΝΥ“Μ–©”–»ΛΒΡΦΦ θΘ§ Β ©ΖΰΈώ¥ζάμΒΡSidecarΡΘ ΫΘ§Αϋά®ΘΚ
https://buoyant.io Linkerd
https://containo.us Traeffik
“‘…œ «–Γ ΐΫώΧλΗχ¥σΦ“Ζ÷œμΒΡΈΡ’¬Θ§Ϋη”Ο ΐ»Υ‘ΤΝΥΗγΒΡΙέΒψΘ§ΈΔΖΰΈώΤδ ΒΖ«≥ΘΗ¥‘”Θ§≤Δ≤Μ «Υυ”–ΒΡ»ΥΓΔΤσ“ΒΕΦΩ…“‘ΗψΕ®Θ§»κΩ”÷°«Α“ΜΕ®“ΣΫχ––Άξ’ϊ«“…ς÷ΊΒΡΩΦ¬«ΓΘ |






