| в§бд
ДДЪРМЧЕк11еТ1-9ОфМЧТМСЫЁААЭБ№ГЧЁБЕФЙЪЪТЁЃЕБЪБЕиЩЯЕФШЫУЧЖМЫЕЭЌвЛжжгябдЃЌЕБШЫУЧРыПЊЖЋЗНжЎКѓЃЌЫћУЧРДЕНСЫЪОФУжЎЕиЁЃдкФЧРяЃЌШЫУЧЯыЗНЩшЗЈЩезЉКУШУЫћУЧФмЙЛдьГівЛзљГЧКЭвЛзљИпЫЪШыдЦЕФЫўРДДЋВЅздМКЕФУћЩљЃЌвдУтЫћУЧЗжЩЂЕНЪРНчИїЕиЁЃЩЯЕлРДЕНШЫМфКѓПДЕНСЫетзљГЧКЭетзљЫўЃЌЫЕвЛШКжЛЫЕвЛжжгябдЕФШЫвдКѓБуУЛгаЫћУЧзіВЛГЩЕФЪТСЫЃЛгкЪЧЩЯЕлНЋЫћУЧЕФгябдДђТвЃЌетбљЫћУЧОЭВЛФмЬ§ЖЎЖдЗНЫЕЪВУДСЫЃЌЛЙАбЫћУЧЗжЩЂЕНСЫЪРНчИїЕиЃЌетзљГЧЪавВЭЃжЙСЫаоНЈЁЃетзљГЧЪаОЭБЛГЦЮЊЁААЭБ№ГЧЁБЁЃЁЖЧеЖЈАцЪЅОЁЗЪЧетбљУшаДЕФЃК
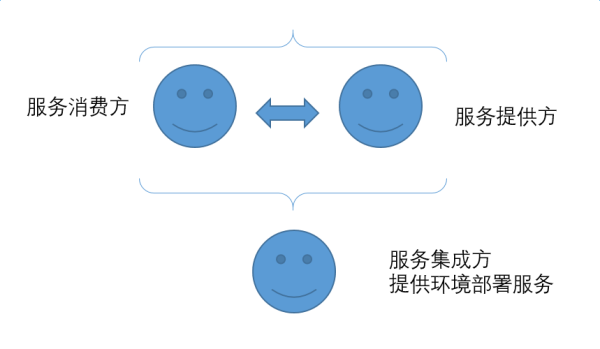
4ЁЂЫћУЧЫЕЃЌЁАРДАЩЃЌЮвУЧвЊНЈдьвЛзљГЧКЭвЛзљЫўЃЌЫўЖЅЭЈЬьЃЌЮЊСЫбяЮвУЧЕФУћЃЌУтЕУЮвУЧБЛЗжЩЂЕНЪРНчИїЕиЁЃЁБ
5ЁЂЕЋЪЧвЎКЭЛЊНЕСйПДЕНСЫЪРШЫЫљНЈдьЕФГЧКЭЫўЁЃ
6ЁЂвЎКЭЛЊЫЕЃЌЁАПДФФЃЌЫћУЧЖМЪЧвЛбљЕФШЫЃЌЫЕзХЭЌвЛжжгябдЃЌШчНёЫћУЧМШШЛФмзіЦ№етЪТЃЌвдКѓЫћУЧЯывЊзіЕФЪТОЭУЛгаВЛГЩЙІЕФСЫЁЃЁБ
7ЁЂШУЮвУЧЯТШЅЃЌдкФЧРяДђТвЫћУЧЕФгябдЃЌШУЫћУЧВЛФмжЊЯўБ№ШЫЕФвтЫМЁЃ
8ЁЂгкЪЧвЎКЭЛЊЪЙЫћУЧЗжЩЂЕНСЫЪРНчИїЕиЃЌЫћУЧвВОЭЭЃжЙНЈдьФЧзљГЧЁЃ
9ЁЂвђЮЊвЎКЭЛЊдкФЧРяДђТвСЫЬьЯТШЫЕФбдгяЃЌЪЙжкШЫЗжЩЂЕНСЫЪРНчИїЕиЃЌЫљвдФЧзљГЧУћНаАЭБ№ЁЃЁЊЁЊGenesis
11:4ЈC9
дИОА
УПШЫЖМПЩвдЫцЪБЛёШЁвЛИіПЊЗЂЛЗОГЁЃдкЦфжазіПЊЗЂЁЃВЂЧвЫцЪБПЩвдбщжЄздМКаДЕФДњТыдкећИіЯЕЭГРяМЏГЩЦ№РДЪЧЗёЙЄзїе§ГЃЁЃЮвПЩвдСЂМДЕУЕНгааЇЗДРЁЃЌДгЖјЬсИпЙЄзїаЇТЪЁЃ
ГЂЪдвЛЃКЪщЭЌЮФ
зюРэЯыЕФЧщПіЪЧЫљгаЕФПЊЗЂепЪЙгУЭъШЋЯрЭЌЕФММЪѕЁЃЫћУЧЪЙгУЭЌбљЕФБрГЬгябдЃЌЫћУЧЪЙгУЭЌбљЕФПЊЗЂПђМмЁЃЫћУЧЪЙгУЭЌбљЕФВйзїЯЕЭГЁЃЫћУЧЪЙгУЭЌбљЕФIDEЁЃЫћУЧЪЙгУЭЌбљЕФЗчИёЙмРэGitВжПтЁЃЫћУЧЪЙгУЭЌвЛжжгябдРДаДЙЙНЈНХБОЁЃШчЙћетвЛаЉЖМЪЧецЕФЃЌЯывЊЛёЕУвЛИіПЊЗЂЛЗОГЃЌФЧЛсЪЧЗЧГЃМђЕЅЕФЪТЧщЁЃ
дјОГЂЪдЙ§ИїжжЗНЪНАбздМКШЯЮЊЁАзюгХЁБЕФПЊЗЂЛЗОГЖЕЪлИјЭЌСХЃЌИјЯТМЖЃЌЩѕжСЪЧИјЮвЕФЙЭдБЁЃЕЋЪЧЖМЪЇАмСЫЁЃШУетАяgeekУЧЪЙгУЭЌбљЕФЗНЪНЙЄзїЃЌетИіФбЬтБШЮвУЧетРявЊНтОіЕФЮЪЬтИќФбЁЃЩЯЕлРДЕНШЫМфКѓПДЕНСЫетзљГЧКЭетзљЫўЃЌЫЕвЛШКжЛЫЕвЛжжгябдЕФГЬађдБвдКѓБуУЛгаЫћУЧзіВЛГЩЕФЪТСЫЁЃгкЪЧЩёДДдьСЫEmacsКЭVimЁЃ
ДђзХЬсИпПЊЗЂаЇТЪЕФЗНЪНШЅЧПМщБ№ШЫЕФПЊЗЂЛЗОГЪЧааВЛЭЈЕФЁЃЮоТлФуЫЕФуаДЕФПтдйКУЃЌЖМВЛШчЮвЕФПтаДЕУКУЁЃЮоТлЮвНёЬьаДЕФПтдкКУЃЌвВВЛШчЮвУїЬьЯыдьЕФЯТвЛИіТжзгКУЁЃетИіЕРРэЦеЪРгкИїжжIDEЙЄОпЕФжДФюЃЌИїжжБрГЬгябдЕФжДФюЁЃ
ВЛвЊжЛПДЕНЪМЛЪЕлзіСЫЪщЭЌЮФЕФЮАвЕЁЃЛЙвЊПДЕНШЫМвЗйЪщПгШхЕФБОЪТЁЃ
ГЂЪдЖўЃКздЖЏЛЏНХБО
ЭЫЖјЧѓЦфДЮЕФАьЗЈЪЧЃЌВЛвЊЧѓЫљгаЕФзщМўЖМЪЧЭЌбљЕФЗНЪНПЊЗЂГіРДЕФЁЃЮвУЧжЛвЊЧѓФуУЧИїИіФЃПщЕФownerЖМЬсЙЉвЛИіЙВЭЌЕФздЖЏЛЏНХБОЁЃЕБЮвУЧАбетаЉНХБОЦДНгЕНвЛЦ№жЎКѓЃЌећИіЯЕЭГОЭЪЕЯжСЫздЖЏЛЏЕФВПЪ№ЁЃ
етЬѕЕРТЗбнНјЕФОЁЭЗОЭЪЧвЛЖбbash/python/msbuildНХБОЃЌМгЩЯвЛИіcmdbЪ§ОнПтзщГЩЕФЙжЪоЁЃЮввбОдкЁЖЯаЬИМЏШКЙмРэФЃЪНЁЗвЛЮФРяУшЪіСЫетИіФЃЪНЕФЮЪЬтЁЃ
ЮоЗЈЩѓВщЕФНХБОЃКИјЖЈвЛИі f()ЃЌФуЮоЗЈжЊЕРетИі f() ЕНЕззіСЫЪВУДЁЃетИіЪЧЫљгаЛљгкНХБОзщКЯЕФЗНЪНЃЈКЏЪ§ЬзКЏЪ§ЃЉзіздЖЏЛЏЕФИљБОЮЪЬтЁЃзюНќетДЮ
S3 ЕФЙЪеЯЃЌОЭЪЧвђЮЊЮѓжДаавЛИі saltstack НХБОЕМжТЕФЁЃЖјШЮКЮдЫааетИіНХБОЕФГЬађЃЌЪЧЮоЗЈдкМгдиНХБОжЎКѓзіШЮКЮЪТЧщРДбщжЄЦфШЈЯоКЭЮЃКІЕФЁЃЖдгкШЮКЮrunnerРДЫЕЃЌf()
ОЭЪЧвЛИіКкКаЕФ f()ЁЃ
зДЬЌЦЏвЦЃКПЊЗЂЛЗОГНХБОдквЛИіаТЕФПЊЗЂЛњЩЯПЩФмдЫааЃЌЕЋЪЧдквЛИівбОАВзАФЃПщAЕФЛњЦїЩЯОЭПЩФмжДааЪЇАмЁЃЛђепдкАВзАСЫAЃЌBЕФЃЌЕЋЪЧУЛгазАCЕФЛњЦїЩЯЛсЪЇАмЁЃНХБОжДааЕФЦ№ЪМзДЬЌПЩФмгаЧЇЧЇЭђЭђЃЌВЛПЩФмВтЪдЦыШЋЁЃНХБОжДааЭъжЎКѓСєЯТЕФЯЕЭГЕФзДЬЌвВЧЇЧЇЭђЭђЁЃ
етСНЕуММЪѕЩЯЕФгВЩЫЃЌЕМжТСЫЛљгквЛЖбНХБОЖбЦіГіРДЕФздЖЏЛЏЗТЗ№ИЁЩГжЎЩЯжўИпЬЈвЛАуЁЃ
ГЂЪдШ§ЃКDocker + зщЭјММЪѕ
дкЗЂЯжСЫНХБОздЖЏЛЏЕФШБЯнжЎКѓЃЌЮвЯнШыСЫЖдDockerММЪѕЕФГеУдЁЃDockerЕФММЪѕЩЯЕФКУДІЯдЖјвзМћЁЃЫќЭъУРЕиАбвЕЮёДњТыЗтзАЕНСЫвЛИіШнЦїРяЃЌЮоТлФуЪЧЪВУДгябдаДЕФЃЌЪВУДПђМмПЊЗЂЕФЃЌзюжеЖМЪЧвЛИіDockerжДааУќСюЁЃЗХЗ№АЭБ№ЫўЮЪЬтНтОіСЫЃЌжЛвЊгаСЫDockerЃЌЪВУДЖЋЮїЖМЪЧвЛбљВПЪ№ЕФЁЃDockerОЕЯёгЩФЃПщownerЬсЙЉЃЌЫћУЧдѕУДХЊГіРДЪЧЫћУЧздМКЕФЪТЧщЁЃФуЯыгУNode.jsЃЌЛЙЪЧHaskellЃЌЫцБуЁЃЖјЧвDockerЭъУРНтОіСЫЛљгкНХБОММЪѕЕФзДЬЌРлЛ§ЦЏвЦЮЪЬтЁЃЫљЮНimmutable
infrastructureЁЃ
DockerЛЙЩдЮЂгавЛаЉЮЪЬтЃЌФЧОЭЪЧЛЙашвЊАбЖрИіЗўЮёЭЈЙ§ЭјТчзщзАЕНвЛЦ№ЁЃетИівВВЛЪЧЪВУДДѓЮЪЬтЁЃЫфШЛЭЈЙ§ЗўЮёЗЂЯжетбљЕФЗНЪНЭЦЙуЦ№РДгаФбЖШЃЌЕЋЪЧЮвУЧЛЙгаЭјТчДњРэЕФДѓеаЁЃБШШчжИЖЈ100.64.0.1ДњБэMySQLЃЌ100.64.0.2ДњБэRedisЁЃЭЈЙ§ЭјТчВуРЙНиетаЉIPЕФЧыЧѓЃЌЮвУЧПЩвдВЛаоИФвЕЮёДњТыЕФЧщПіЯТЃЌАбетаЉDockerШнЦїИјзщзАЦ№РДЁЃ
DockerЛљгкСЫLinux ABIЃЌДњРэАцБОЕФЗўЮёЗЂЯжЛљгкСЫTCP/IPЁЃетСНИіЖЋЮїдкАЭБ№ЫўЕФЪБДњОЭЪЧвЛИіbugМЖБ№ЕФДцдкЃЌЕЋЪЧБОжЪЩЯЛЙЪЧЪщЭЌЮФЁЃЩЯЕлСєСЫвЛИіПкзгЃЌИјЮвУЧзъСЫТЉЖДЁЃгкЪЧЮвУЧгжПЩвдАбетаЉТвЦпАЫдуЕФЖЋЮїдмвЛЦ№СЫЁЃ
Docker вВЮоЗЈНтОіЪщЭЌЮФЕФЮЪЬт
етжжЗНЪНЭъУРСЫТ№ЃПЮвУЧдйДЮЗЂЯжСЫАЭБ№ЫўЮЪЬтЁЃЪЕМЪЩЯЕФШэМўЪЧетбљЙЄзїЕФЃК
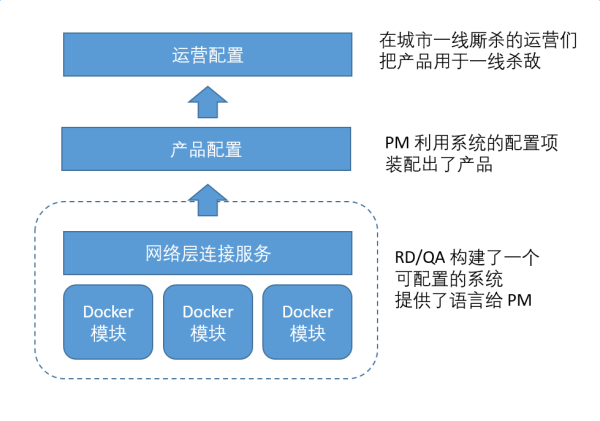
ФГжжГЬЖШЩЯРДЫЕЃЌЮвУЧЭЈЙ§DockerЃЌЭЈЙ§зщЭјЃЌЙЙНЈГіРДЕФЯЕЭГжЛЪЧвЛИіПеПЧЖјвбЁЃЫќжЛЪЧвЛУХПЊЗЂгябдЃЌЫќЭЈЙ§ИїжжХфжУНчУцЬсЙЉСЫздМКЕФПЊЗЂЙЄОпЁЃPM
ЭЈЙ§ВњЦЗХфжУЃЌХфжУГіСЫВњЦЗЃЌЖјдЫгЊдйЛљгкВњЦЗЃЌХфжУГіСЫеце§дЫааЦ№РДПЩвдзЌЧЎЕФЯЕЭГЁЃ
DockerПЩвдРћгУLinux ABI етИіЁАЪщЭЌЮФЁБЕФНгПкЃЌећКЯСЫКѓЬЈЗўЮёЁЃЭјТчДњРэРћгУ TCP/IP
етИіЁАЪщЭЌЮФЁБЕФНгПкАбетаЉЗўЮёДЎСЊСЫЦ№РДЁЃЕЋЪЧЖдгкИїИіФЃПщздМКЬсЙЉЕФВњЦЗХфжУКЭдЫгЊХфжУЃЌЮвУЧОЭУЛгаетУДавдЫСЫЁЃгаЕФФЃПщЪЙгУСЫCSVЃЌгаЕФЪЙгУСЫJsonЃЌгаЕФЪЙгУСЫЪ§ОнПтЁЃЕБФувЊжиЯжвЛИіЁАЛЗОГЁБЕФЪБКђЁЃЫќВЛНіНіЪЧвтЮЖзХНјГЬЕФЦєЖЏЃЌвтЮЖзХЭјТчЕФСЌНгЁЃЫќЛЙашвЊАбИїжжХфжУЪ§ОнЙрШыЕНЯЕЭГЁЃЖјИуЧхГўгаФФаЉХфжУЃЌШУетаЉФЃПщЪЙгУЭъШЋЯрЭЌЕФЗНЪНРДЖЈвхКЭЪЙгУХфжУЃЌЮвУЧОЭгжЛиЕНСЫЕквЛВНЃЌЪщЭЌЮФЕФТЗЪ§РяСЫЁЃЪщЭЌЮФЕФГЩЙІЪЕЪЉЃЌРДздгкЧПДѓЕФжабыШЈЭўЁЃШчЙћгЕгаЧПДѓЕФжабыШЈЭўЃЌЭъШЋПЩвдДгвЛПЊЪМОЭЧПЭЦЪщЭЌЮФЕФПЊЗЂФЃЪНЃЈБШШчЖМЪЧJavaЃЌБШШчЖМЪЧFinagleЃЉЁЃетОЭаЮГЩуЃТлСЫЁЃ
ЮЂЗўЮёМмЙЙЕФд№ШЮРЇОГ
Й§ШЅЕФПЊЗЂФЃЪНЪЧетбљЕФЁЃЮвИКд№вЛИіЗўЮёЃЌЫќДгDBЭљЩЯЖМЪЧЮвЕФЁЃВњЦЗОРэЕФашЧѓЃЌЮвШЋВПИКд№ЁЃжаМфЛсгаЩйСПЕФЕїгУЭтВПНгПкНјаажЇИЖЃЌгЪМўШКЗЂжЎРрЕФЪТЧщЁЃЕЋЪЧетаЉЕїгУвЛАуДІгкСїГЬЕФФЉЖЫЃЌВЛВЮгыжївЊЕФвЕЮёТпМВЂЧвНгПкЧхЮњЁЃ
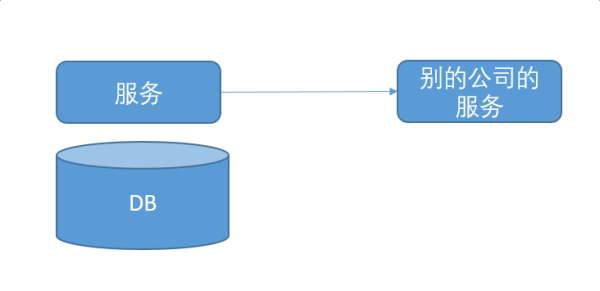
етИіФъДњЕФВтЪдЗЧГЃЧхГўЃЌmockЕєЭтВПвРРЕЃЈжЇИЖЃЌЖЬаХЭјЙиЃЌftpНгПкЃЉЃЌЦєЖЏецЪЕЕФЪ§ОнПтЃЌДггУЛЇЕФНгПкВтЪдЮвЕФЗўЮёЁЃЮвжБНгЯђгУЛЇИКд№ЁЃетжжЙЄзїФЃЪНЃЌЮвжСНёШЯЮЊЪЧаЇТЪзюИпЕФЗНЪНЁЃ
ЯждкЕФЮЂЗўЮёЕФФЃЪНЪЧЕўТоККЪНЕФЁЃЮвИКд№СЫBЃЌЩЯУцгаAЃЌЯТУцЛЙгаCЁЃAвРРЕBКЭCВХФмХмЦ№РДЃЌBвРРЕAКЭCВХФмКЭПЭЛЇЖЫЭъећНЛЛЅЁЃ
дкетжжВ№ЗжЯТЃЌЮвУЧЧПЕїСЫУПИіЭХЖгЕФзджїадЁЃЖјЧвДѓМвЙВЭЌГаЕЃСЫзюжеЕФвЕЮёУєНнадКЭЮШЖЈадЕФвЊЧѓЁЃЖдгкЩњВњЛЗОГЃЌШЗЪЕЪЧетбљЕФЁЃШчЙћCЙвСЫЃЌCЛсСЂМДШЅаоЃЌвђЮЊгАЯьСЫЩњВњЛЗОГЁЃШчЙћBЙвСЫЃЌBвВЛсСЂМДШЅаоЁЃ
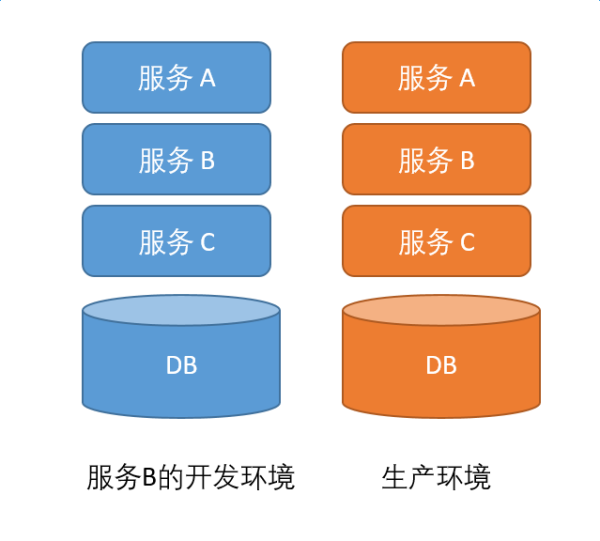
ЕЋЪЧАбетИіЮЪЬтИФГЩЯпЯТКЭЯпЯТЗжПЊФиЃПШчЙћЪЧдкЗўЮёBЕФПЊЗЂЛЗОГРяЃЌЗўЮёCГіЮЪЬтСЫЃЌгавЛИіЩшжУУЛгаХфжУЖдЁЃЛђепетИіЩшжУИФСЫЃЌBУЛгаИќаТДњТыЁЃФуШЯЮЊCЛсЛ§МЋЕиАяBНтОіЮЪЬтУДЃПФуШЯЮЊBЛсНјШыЕНCЕФДњТыФПТМЯТЃЌПДЫћУЧДђЕФШежОУДЃЌШЛКѓздМКОЭжЊЕРдѕУДаоИДЮЪЬтСЫЃПМДБуПЩвдНтОіЃЌBвВЛсгіЕНОоДѓЕФЯргІбгГйЕФЮЪЬтЁЃCПЩФмдкПЊЛсЃЌCПЩФмдкУІБ№ЕФЪТЧщЁЃ
ФЧУДНтЗЈЪЧЪВУДЃПЯпЯТЛЗОГжБНгРћгУЩњВњЛЗОГЕФВПЪ№НХБОЃПвЛЬзНХБОЃЌПЩЫцЪБИДжЦЛЗОГЃПЧАУцвбОЬжТлЙ§етаЉздЖЏЛЏВПЪ№НХБОЃЌвдМАDockerЕШФЃЪНЕФММЪѕШБЯнСЫЁЃЪТЪЕЩЯЃЌВПЪ№СНЬзвЛФЃвЛбљЕФЛЗОГЪЧЯрЕБРЇФбЕФЁЃЖјЧвв§ШыИДдгЕФВПЪ№ЙЄОпЃЌвдМАзЈжАЕФЭХЖгЛЙгавЛИіИќМггаШЄЕФЯжЯѓЃЌЫќАбСНЗНЕФЙиЯЕЃЌБфГЩСЫШ§ЗНЕФЛЅЖЏЃК
етШ§ЗНЕФЙиЯЕЪЧЛЅЯрВЛаХШЮЕФЃЌвђЮЊДњТыВЛЪЧздМКаДЕФЁЃЗўЮёЯћЗбЗНгіЕНСЫРЇФбЃЌШЅевЗўЮёМЏГЩЗНЁЃМЏГЩЗНЛсШЯЮЊПЩФмЪЧЬсЙЉЗНЕФДњТыгаЮЪЬтЁЃгкЪЧАбЬсЙЉЗНРНјРДЖЈЮЛЮЪЬтЁЃЬсЙЉЗНЛсОѕЕУЮвЕФЗўЮёдкЯпЩЯЪЧКУКУЕФЃЌ
ЮЊЪВУДдкЯпЯТОЭВЛааСЫФиЃПЪЧВЛЪЧФуВПЪ№ЕУгаЮЪЬтЃЌGCCАцБОЪЧВЛЪЧВЛЖдЁЃетжжд№ШЮЕФСДЪНДЋЕМКмПьОЭЛсШУЛЗОГЕФЪЙгУЗНОѕЕУЃЌФмгУОЭгУЃЌВЛФмгУЮввВУЛЗЈЭЦЖЏШЅЖЈЮЛЮЪЬтЁЃ
ДгИљБОЩЯРДЫЕЃЌетИіРЇОГдкгкФЃПщЕФownerЃЌжЛЖдЩњВњЛЗОГИКд№ЃЌВЛЖдБ№ШЫЪЙгУЕФПЊЗЂЛЗОГРяздМКЕФЗўЮёИКд№ЁЃЛЈЪБМфАяБ№ШЫНтОіЮЪЬтЃЌЬсИпЭХЖгЕФећЬхаЇТЪЃЌЖдгкФЃПщЕФownerРДЫЕВЛЪЧзюгХНтЁЃвђЮЊЫћЛЈЗбСЫЖюЭтЕФЪБМфШЅАяБ№ШЫЭъГЩKPIЃЌЖјВЛЪЧзЈзЂгкСьЕМВМжУЕФЯТвЛИіШЮЮёЁЃ
ЖјЗўЮёЕФМЏГЩЗНЃЌМШВЛжЊЕРЗўЮёЪЧШчКЮЯћЗбЕФЃЌвВВЛжЊЕРЗўЮёЪЧШчКЮЬсЙЉЕФЁЃЫћВЛПЩФмгазуЙЛЕФОЋСІЃЌЪБМфгыЖЏЛњШЅЩюШыСЫНтЫљгаЕФФЃПщЕФЙЄзїЯИНкЁЃМДБугавтдИАбетИіМЏГЩЙЄзїзіКУЃЌвВУЛгаФмСІдкЭбРыФЃПщownerЕФЧщПіЯТАбЙЄзїеце§зіКУЁЃ
НтЗЈвЛЃКПЩИДжЦЕФЛЗОГСаШыKPI
вЛжжНтЗЈЪЧАбЛЗОГЕФПЩИДжЦадБфГЩУПИіШЫЕФKPIЁЃетбљУПИіФЃПщВЛНіНіИКд№вЛИіЛЗОГЃЈЩњВњЛЗОГЃЉЕФЙЄзїе§ГЃЁЃЫћЛЙвЊИКд№БЃГжетжжПЩИДжЦадЁЃШчЙћФуЕФвЕЮёФЃЪНЧЁКУвРРЕгкетвЛЕуЃЌдђПЩвдХЌСІЭЦЖЏЁЃБШШчФувЊШЅМгФУДѓдЫгЊвЛЬзЖРСЂЕФЯЕЭГЃЌЖјФмЙЛвЛМќВПЪ№вЛЬзЛЗОГИјМгФУДѓЕФдЫгЊЪЙгУЃЌдђБфГЩСЫвЛМўгавЕЮёЪевцЕФЪТЧщЁЃ
етжжзіЗЈОЭЪЧвЊАбШЋСїГЬЕФГжајМЏГЩСаЮЊЫљгаШЫЕФKPIЁЃШчЙћдкЯпЯТЛЗОГМЏГЩЪЇАмЃЌССКьЕЦЃЌЫљгаШЫИКд№РДЖЈЮЛЮЪЬтЁЃОЭКЭЩњВњЛЗОГГіИцОЏСЫвЛбљРДЖдД§ЁЃШчЙћзіВЛЕНетвЛЕуЃЌЫљЮНПЩИДжЦЕФЛЗОГОЭЪЧОЕЛЈЫЎдТСЫЁЃ
НтЗЈЖўЃКЩњВњЛЗОГздМь
ШчЙћДѓМвЖМжЛШЯЭЌЮвжЛашвЊЮЊЩњВњЛЗОГИКд№ЃЌФЧОЭАбЩњВњЛЗОГБфЕУИќЧПДѓКУСЫЁЃИДдгЕФЛњЦїЖМгаЁАздМьЁБЕФЙІФмЁЃЮвУЧвЊзіЕФОЭЪЧШУЩњВњЛЗОГПЩвдХмВтЪдЕФСїСПЪЕЯжздМьЃЌРрЫЦгкWindows
ЁАДђгЁВтЪдвГЁБ етбљЕФЙІФмЁЃЫФЩЋНЈФЃРяЕФparty/place/thing/moment intervalЃЌДѓВПЗжвЊВтЕФааЮЊЖМЪЧmoment
intervalЁЃЭЈЙ§АбpartyетИіжїЬхИјЛЛЕєЃЌАб place/thing етСНИіЮЌЖШЕФДњТыМгвдИФдьЃЈБШШчвЛаЉЗжГЧЪаЭГМЦТпМЃЉЃЌПЩвдЪЕЯжmoment
intervalЕФжиЗХЁЃ
етжжЗНЪНЕФЪЕжЪЪЧШдШЛЪЧЭЦЖЏШЋСїГЬЕФМЏГЩЁЃвђЮЊШЋСїГЬГжајМЏГЩдкЯпЯТЭЦааЪЇАмЃЌЖјЭЫЖјЧѓЦфДЮЃЌбЁдёдкЩњВњЛЗОГРДзіЁЃ
НтЗЈШ§ЃКЛљгкНгПкЦѕдМЕФПЊЗЂ
ЧПЛЏНгПкЦѕдМЕФзїгУЁЃЭЈЙ§MockЕєЫљгаЕФЭтВПвРРЕЃЌЕЅЖРВтЪдЮвздМКИКд№ЕФФЃПщЁЃЭЈЙ§ЯпЩЯTcpdumpЕФЗНЪНЃЌЗНБуЙЙдьетаЉmockЕФЧыЧѓКЭЯьгІЃЌМѕЩйMockЕФЙЄзїСПЃЌвдМАШУMockецЪЕПЩаХЁЃБмУтВщСЫАыЬьЮЪЬтЃЌНсЙћЗЂЯжЪЧMockНгПкКЭЯпЩЯЪЕМЪааЮЊВЛвЛжТЃЌетбљЕФЮкСњЮЪЬтЁЃ
ЭЌЪБНјааНгПкЕФаЮЪНЛЏЖЈвхЃЌВЂЧвЭЈЙ§consumer driven contractЕФЗНЪНАбЕїгУЗНЕФMockЃЌБфГЩЬсЙЉЗНЕФВтЪдЁЃ
етжжзіЗЈОЭЪЧГаШЯЮЂЗўЮёМмЙЙЕФЪЕжЪЪЧРћгУзщжЏБпНчРДЧПЛЏШэМўМмЙЙЕФБпНчЁЃМШШЛШЫЮЊЙЙНЈСЫзщжЏЧНЃЌгыЦфКіЪгЦфДцдкЃЌЛЙВЛШчЖдЫќКУКУЖдД§ЁЃМШШЛЮвЕїгУЖдЗНЃЌЖдЗНВЛдИвтАяЮвНтОіЛЗОГЮЪЬтЃЌЮввВУЛгаФмСІЖРСЂАбЖдЗНЕФДњТыХмЦ№РДЁЃФЧВЛШчЮвУЧОЭЛЎНчЖјжЮАЩЁЃДѓМвАбНгПкдМЖЈКУЃЌЮвгУМйЕФЪЕЯжРДЬцДњФуЕФецЪЕЪЕЯжРДзіПЊЗЂЁЃетжжзіЗЈКЭЮвУЧЕїгУЙњЦѓвјааЕФНгПкЃЌЫЋЗНСЊЕїЕФЗНЪНВЂЮоБОжЪВЛЭЌЁЃ
ПЬЖШГп

дкжабыЭўШЈЧПЕФГЁОАЃЌЪщЭЌЮФЕФЗНЪНЪЧзюОМУЕФЗНЪНЁЃЮоТлЪЧЭГвЛПЊЗЂгябдЃЌЛЙЪЧЭГвЛRPCПђМмЃЌЛЙЪЧЭГвЛЗўЮёЗЂЯжЁЃБОжЪЩЯРДздгкЪщЭЌЮФДјРДЕФЪевцДѓгкЭўШЈЭЦНјЕФГЩБОЁЃ
дкдНЫЩЩЂЕФзщжЏЯТЃЌдНЛсЧїЯђгкУцЯђНгПкПЊЗЂЁЃ
КѓМЧ
ДгЭГвЛЕФздЖЏЛЏНХБОЃЌPuppet/Chef/SaltStackЕНDocker + ЭјТчДњРэЕНЯпЩЯTcpdumpЯпЯТСїСПЛиЗХЃЌЛљгкНгПкЦѕдМЕФПЊЗЂЃЌММЪѕФбЖШж№ВНЩ§МЖЁЃЭЈЙ§ММЪѕЩЯЕФММЧЩЃЈБШШчDockerРћгУСЫДѓМвЖМЪЧЛљгкЭГвЛЕФВйзїЯЕЭГНгПкЃЉШЗЪЕПЩвдНтОівЛаЉЮЪЬтЁЃЕЋЪЧММЪѕдйдѕУДЩ§МЖЃЌвВЮоЗЈНтОіЫљгаЮЪЬтЁЃБЯОЙЃЌЫљЮНЛЗОГЮЪЬтЃЌЫљЮНВтЪдЮЪЬтЃЌЫљЮНЮвЕФДњТыХмВЛЦ№РДЕФЮЪЬтЃЌЖМЪЧШЫгыШЫжЎМфШчКЮећЬхЕиИпаЇазїЕФЮЪЬтЁЃММЪѕЕФОЁЭЗЃЌЪЧеўжЮЁЃ |






