| 1
ЮЊЪВУДашвЊЗўЮёЗЂЯж
МђЕЅРДЫЕЃЌЗўЮёЛЏЕФКЫаФОЭЪЧНЋДЋЭГЕФвЛеОЪНгІгУИљОнвЕЮёВ№ЗжГЩвЛИівЛИіЕФЗўЮёЃЌЖјЮЂЗўЮёдкетИіЛљДЁЩЯвЊИќГЙЕзЕиШЅёюКЯЃЈВЛдйЙВЯэDBЁЂKVЃЌШЅЕєжиСПМЖESBЃЉЃЌВЂЧвЧПЕїDevOpsКЭПьЫйбнЛЏЁЃетОЭвЊЧѓЮвУЧБиаыВЩгУгывЛеОЪНЪБДњЁЂЗКSOAЪБДњВЛЭЌЕФММЪѕеЛЃЌЖјSpring
CloudОЭЪЧЦфжаЕФйЎйЎепЁЃ
DevOpsЪЧгЂЮФDevelopmentКЭOperationsЕФКЯЬхЃЌЫћвЊЧѓПЊЗЂЁЂВтЪдЁЂдЫЮЌНјаавЛЬхЛЏЕФКЯзїЃЌНјааИќаЁЁЂИќЦЕЗБЁЂИќздЖЏЛЏЕФгІгУЗЂВМЃЌвдМАЮЇШЦгІгУМмЙЙРДЙЙНЈЛљДЁЩшЪЉЕФМмЙЙЁЃетОЭвЊЧѓгІгУГфЗжЕФФкОлЃЌвВЗНБудЫЮЌКЭЙмРэЁЃетИіРэФюгыЮЂЗўЮёРэФюВЛФБЖјКЯЁЃ
НгЯТРДЮвУЧДгЗўЮёЛЏМмЙЙбнНјЕФНЧЖШРДПДПДЮЊЪВУДSpring CloudИќЪЪгІЮЂЗўЮёМмЙЙЁЃ
1.1 ДгЪЙгУnginxЫЕЦ№
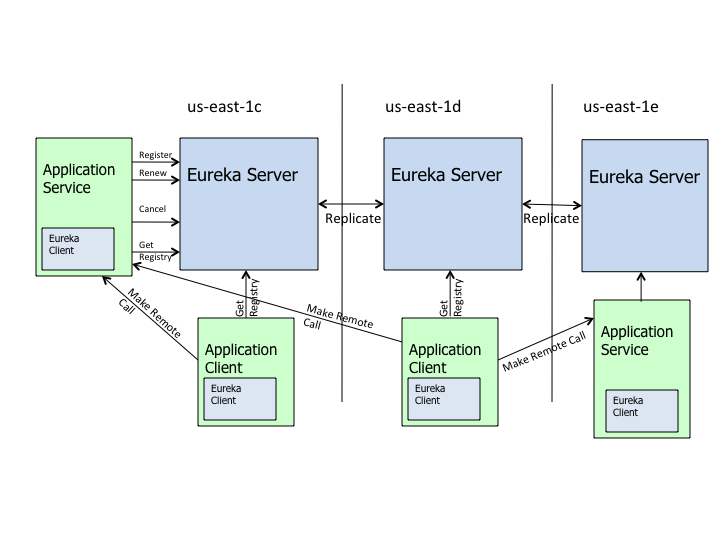
зюГѕЕФЗўЮёЛЏНтОіЗНАИЪЧИјЬсЙЉЯрЭЌЗўЮёЬсЙЉвЛИіЭГвЛЕФгђУћЃЌШЛКѓЗўЮёЕїгУепЯђетИігђУћЗЂЫЭHTTPЧыЧѓЃЌгЩNginxИКд№ЧыЧѓЕФЗжЗЂКЭЬјзЊЁЃNginxArch.png
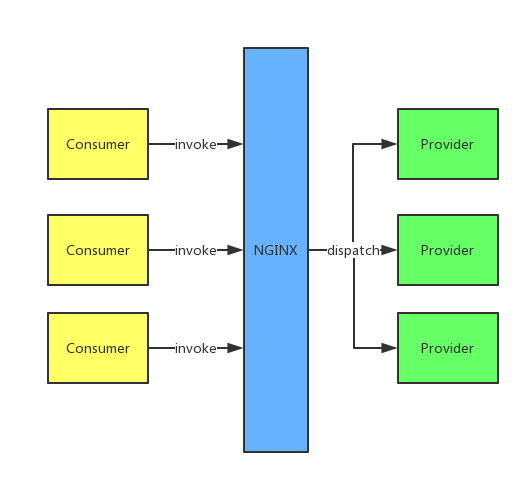
етжжМмЙЙДцдкКмЖрЮЪЬт:
NginxзїЮЊжаМфВуЃЌдкХфжУЮФМўжаёюКЯСЫЗўЮёЕїгУЕФТпМЃЌетЯїШѕСЫЮЂЗўЮёЕФЭъећадЃЌвВЪЙЕУNginxдквЛЖЈГЬЖШЩЯБфГЩСЫвЛИіжиСПМЖЕФESBЁЃ
ЗўЮёЕФаХЯЂЗжЩЂдкИїИіЯЕЭГЃЌЮоЗЈЭГвЛЙмРэКЭЮЌЛЄЁЃУПвЛДЮЕФЗўЮёЕїгУЖМЪЧвЛДЮГЂЪдЃЌЗўЮёЯћЗбепВЂВЛжЊЕРгаФФаЉЪЕР§дкИјЫћУЧЬсЙЉЗўЮёЁЃетВЛЗћКЯDevOpsЕФРэФюЁЃ
ЮоЗЈжБЙлЕФПДЕНЗўЮёЬсЙЉепКЭЗўЮёЯћЗбепЕБЧАЕФдЫаазДПіКЭЭЈаХЦЕТЪЁЃетвВВЛЗћКЯDevOpsЕФРэФюЁЃ
ЯћЗбепЕФЪЇАмжиЗЂЃЌИКдиОљКтЕШЖМУЛгаЭГвЛВпТдЃЌетМгДѓСЫПЊЗЂУПИіЗўЮёЕФФбЖШЃЌВЛРћгкПьЫйбнЛЏЁЃ
ЮЊСЫНтОіЩЯУцЕФЮЪЬтЃЌЮвУЧашвЊвЛИіЯжГЩЕФжааФзщМўЖдЗўЮёНјааећКЯЃЌНЋУПИіЗўЮёЕФаХЯЂЛузмЃЌАќРЈЗўЮёЕФзщМўУћГЦЁЂЕижЗЁЂЪ§СПЕШЁЃЗўЮёЕФЕїгУЗНдкЧыЧѓФГЯюЗўЮёЪБЪзЯШЭЈЙ§жааФзщМўЛёШЁЬсЙЉетЯюЗўЮёЕФЪЕР§ЕФаХЯЂЃЈIPЁЂЖЫПкЕШЃЉЃЌдйЭЈЙ§ФЌШЯЛђздЖЈвхЕФВпТдбЁдёИУЗўЮёЕФФГвЛЬсЙЉепжБНгНјааЗУЮЪЁЃЫљвдЃЌЮвУЧв§ШыСЫDubboЁЃ
1.2 ЛљгкDubboЪЕЯжЮЂЗўЮё
DubboЪЧАЂРяПЊдДЕФвЛИіSOAЗўЮёжЮРэНтОіЗНАИЃЌЮФЕЕЗсИЛЃЌдкЙњФкЕФЪЙгУЖШЗЧГЃИпЁЃ
ЪЙгУDubboЙЙНЈЕФЮЂЗўЮёЃЌвбОПЩвдБШНЯКУЕиНтОіЩЯУцЬсЕНЕФЮЪЬтЃКDubboArch.png
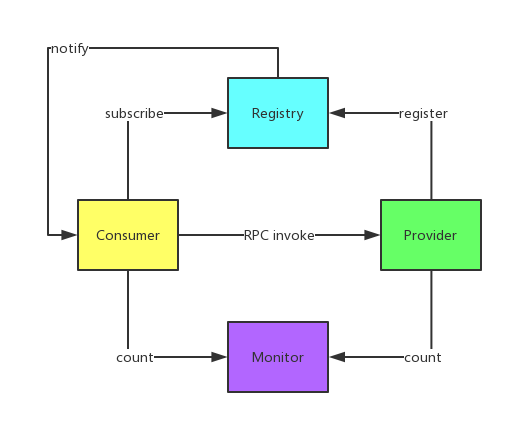
ЕїгУжаМфВуБфГЩСЫПЩбЁзщМўЃЌЯћЗбепПЩвджБНгЗУЮЪЗўЮёЬсЙЉепЁЃ
ЗўЮёаХЯЂБЛМЏжаЕНRegistryжаЃЌаЮГЩСЫЗўЮёжЮРэЕФжааФзщМўЁЃ
ЭЈЙ§MonitorМрПиЯЕЭГЃЌПЩвджБЙлЕиеЙЪОЗўЮёЕїгУЕФЭГМЦаХЯЂЁЃ
ConsumerПЩвдНјааИКдиОљКтЁЂЗўЮёНЕМЖЕФбЁдёЁЃ
ЕЋЪЧЖдгкЮЂЗўЮёМмЙЙЖјбдЃЌDubboвВВЂВЛЪЧЪЎШЋЪЎУРЕФЃК
RegistryбЯживРРЕЕкШ§ЗНзщМўЃЈzookeeperЛђепredisЃЉЃЌЕБетаЉзщМўГіЯжЮЪЬтЪБЃЌЗўЮёЕїгУКмПьОЭЛсжаЖЯЁЃ
DUBBOжЛжЇГжRPCЕїгУЁЃЪЙЕУЗўЮёЬсЙЉЗНгыЕїгУЗНдкДњТыЩЯВњЩњСЫЧПвРРЕЃЌЗўЮёЬсЙЉепашвЊВЛЖЯНЋАќКЌЙЋЙВДњТыЕФjarАќДђАќГіРДЙЉЯћЗбепЪЙгУЁЃвЛЕЉДђАќГіЯжЮЪЬтЃЌОЭЛсЕМжТЗўЮёЕїгУГіДэЁЃ
зюЮЊживЊЕФЪЧЃЌDUBBOЯждквбОЭЃжЙЮЌЛЄСЫЃЌЖдгкММЪѕЗЂеЙЕФаТашЧѓЃЌашвЊгЩПЊЗЂепздааЭиеЙЩ§МЖЁЃетЖдгкКмЖрЯывЊВЩгУЮЂЗўЮёМмЙЙЕФжааЁШэМўзщжЏЃЌЯдШЛЪЧВЛЬЋКЯЪЪЕФЁЃ
ФПЧАGithubЩчЧјЩЯгавЛИіDUBBOЕФЩ§МЖАцЃЌНаDUBBOXЃЌЬсЙЉСЫИќИпаЇЕФRPCађСаЛЏЗНЪНКЭRESTЕїгУЗНЪНЁЃЕЋЪЧИУЯюФПвВЛљБОЭЃжЙЮЌЛЄСЫЁЃ
1.3 аТЕФбЁдёЁЊЁЊSpring Cloud
зїЮЊаТвЛДњЕФЗўЮёПђМмЃЌSpring CloudЬсГіЕФПкКХЪЧПЊЗЂЁАУцЯђдЦЛЗОГЕФгІгУГЬађЁБЃЌЫќЮЊЮЂЗўЮёМмЙЙЬсЙЉСЫИќМгШЋУцЕФММЪѕжЇГжЁЃ
НсКЯЮвУЧвЛПЊЪМЬсЕНЕФЮЂЗўЮёЕФЫпЧѓЃЌЮвУЧАбSpring CloudгыDUBBOНјаавЛЗЌЖдБШЃК
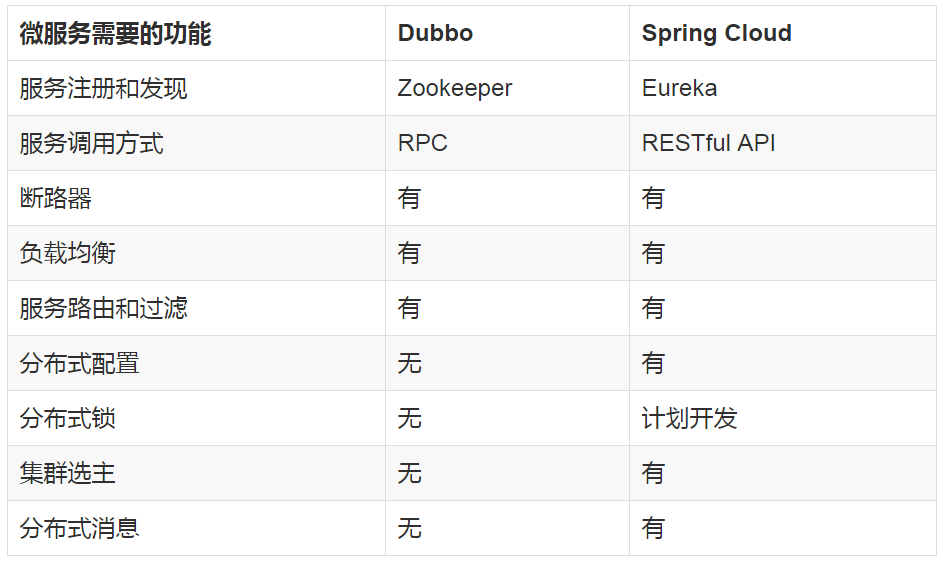
Spring CloudХзЦњСЫDubboЕФRPCЭЈаХЃЌВЩгУЕФЪЧЛљгкHTTPЕФRESTЗНЪНЁЃбЯИёРДЫЕЃЌетСНжжЗНЪНИїгагХСгЁЃЫфШЛДгвЛЖЈГЬЖШЩЯРДЫЕЃЌКѓепЮўЩќСЫЗўЮёЕїгУЕФадФмЃЌЕЋвВБмУтСЫЩЯУцЬсЕНЕФдЩњRPCДјРДЕФЮЪЬтЁЃЖјЧвRESTЯрБШRPCИќЮЊСщЛюЃЌЗўЮёЬсЙЉЗНКЭЕїгУЗНЕФвРРЕжЛвРППвЛжНЦѕдМЃЌВЛДцдкДњТыМЖБ№ЕФЧПвРРЕЃЌетдкЧПЕїПьЫйбнЛЏЕФЮЂЗўЮёЛЗОГЯТЃЌЯдЕУИќМгКЯЪЪЁЃ
КмУїЯдЃЌSpring CloudЕФЙІФмБШDUBBOИќМгЧПДѓЃЌКИЧУцИќЙуЃЌЖјЧвзїЮЊSpringЕФШЭЗЯюФПЃЌЫќвВФмЙЛгыSpring
FrameworkЁЂSpring BootЁЂSpring DataЁЂSpring BatchЕШЦфЫћSpringЯюФПЭъУРШкКЯЃЌетаЉЖдгкЮЂЗўЮёЖјбдЪЧжСЙиживЊЕФЁЃЧАУцЬсЕНЃЌЮЂЗўЮёБГКѓвЛИіживЊЕФРэФюОЭЪЧГжајМЏГЩЁЂПьЫйНЛИЖЃЌЖјдкЗўЮёФкВПЪЙгУвЛИіЭГвЛЕФММЪѕПђМмЃЌЯдШЛБШАбЗжЩЂЕФММЪѕзщКЯЕНвЛЦ№ИќгааЇТЪЁЃИќживЊЕФЪЧЃЌЯрБШгкDubboЃЌЫќЪЧвЛИіе§дкГжајЮЌЛЄЕФЁЂЩчЧјИќМгЛ№ШШЕФПЊдДЯюФПЃЌетОЭБЃжЄЪЙгУЫќЙЙНЈЕФЯЕЭГЃЌПЩвдГжајЕиЕУЕНПЊдДСІСПЕФжЇГжЁЃ
2. Spring Cloud Netflix зщМў
NetflixКЭSpring CloudЪЧЪВУДЙиЯЕФиЃПNetflixЪЧвЛМвГЩЙІЪЕМљЮЂЗўЮёМмЙЙЕФЛЅСЊЭјЙЋЫОЃЌМИФъЧАЃЌNetflixОЭАбЫќЕФМИКѕећИіЮЂЗўЮёПђМмеЛПЊдДЙБЯзИјСЫЩчЧјЁЃSpringБГКѓЕФPivotalдк2015ФъЭЦГіЕФSpring
CloudПЊдДВњЦЗЃЌжївЊЖдNetflixПЊдДзщМўЕФНјвЛВНЗтзАЃЌЗНБуSpringПЊЗЂШЫдБЙЙНЈЮЂЗўЮёЛљДЁПђМмЁЃ
ЖдгкЮЂЗўЮёЕФжЮРэЖјбдЃЌКЫаФОЭЪЧЗўЮёЕФзЂВсКЭЗЂЯжЁЃЫљвдбЁдёФФИізщМўЃЌКмДѓГЬЖШЩЯвЊПДЫќЖдгкЗўЮёзЂВсгыЗЂЯжЕФНтОіЗНАИЁЃдкетИіСьгђЃЌПЊдДМмЙЙКмЖрЃЌзюГЃМћЕФЪЧZookeeperЃЌЕЋетВЂВЛЪЧвЛИізюМббЁдёЁЃ
дкЗжВМЪНЯЕЭГСьгђгаИіжјУћЕФCAPЖЈРэЃКCЁЊЁЊЪ§ОнвЛжТадЃЌAЁЊЁЊЗўЮёПЩгУадЃЌPЁЊЁЊЗўЮёЖдЭјТчЗжЧјЙЪеЯЕФШнДэадЁЃетШ§ИіЬиаддкШЮКЮЗжВМЪНЯЕЭГжаВЛФмЭЌЪБТњзуЃЌзюЖрЭЌЪБТњзуСНИіЁЃ
ZookeeperЪЧжјУћHadoopЕФвЛИізгЯюФПЃЌКмЖрГЁОАЯТZookeeperвВзїЮЊServiceЗЂЯжЗўЮёНтОіЗНАИЁЃZookeeperБЃжЄЕФЪЧCPЃЌМДШЮКЮЪБПЬЖд
ZookeeperЕФЗУЮЪЧыЧѓФмЕУЕНвЛжТЕФЪ§ОнНсЙћЃЌЭЌЪБЯЕЭГЖдЭјТчЗжИюОпБИШнДэадЃЌЕЋЪЧЫќВЛФмБЃжЄУПДЮЗўЮёЧыЧѓЕФПЩгУадЁЃДгЪЕМЪЧщПіРДЗжЮіЃЌдкЪЙгУZookeeperЛёШЁЗўЮёСаБэЪБЃЌШчЙћzookeeperе§дкбЁжїЃЌЛђепZookeeperМЏШКжаАыЪ§вдЩЯЛњЦїВЛПЩгУЃЌФЧУДНЋОЭЮоЗЈЛёЕУЪ§ОнСЫЁЃЫљвдЫЕЃЌZookeeperВЛФмБЃжЄЗўЮёПЩгУадЁЃ
ГЯШЛЃЌЖдгкДѓЖрЪ§ЗжВМЪНЛЗОГЃЌгШЦфЪЧЩцМАЕНЪ§ОнДцДЂЕФГЁОАЃЌЪ§ОнвЛжТадгІИУЪЧЪзЯШБЛБЃжЄЕФЃЌетвВЪЧzookeeperЩшМЦГЩCPЕФдвђЁЃЕЋЪЧЖдгкЗўЮёЗЂЯжГЁОАРДЫЕЃЌЧщПіОЭВЛЬЋвЛбљСЫЃКеыЖдЭЌвЛИіЗўЮёЃЌМДЪЙзЂВсжааФЕФВЛЭЌНкЕуБЃДцЕФЗўЮёЬсЙЉепаХЯЂВЛОЁЯрЭЌЃЌвВВЂВЛЛсдьГЩджФбадЕФКѓЙћЁЃвђЮЊЖдгкЗўЮёЯћЗбепРДЫЕЃЌФмЯћЗбВХЪЧзюживЊЕФЁЊЁЊФУЕНПЩФмВЛе§ШЗЕФЗўЮёЪЕР§аХЯЂКѓГЂЪдЯћЗбвЛЯТЃЌвВКУЙ§вђЮЊЮоЗЈЛёШЁЪЕР§аХЯЂЖјВЛШЅЯћЗбЁЃЫљвдЃЌЖдгкЗўЮёЗЂЯжЖјбдЃЌПЩгУадБШЪ§ОнвЛжТадИќМгживЊЁЊЁЊAPЪЄЙ§CPЁЃЖјSpring
Cloud NetflixдкЩшМЦEurekaЪБзёЪиЕФОЭЪЧAPддђЁЃ
EurekaБОЩэЪЧNetflixПЊдДЕФвЛПюЬсЙЉЗўЮёзЂВсКЭЗЂЯжЕФВњЦЗЃЌВЂЧвЬсЙЉСЫЯргІЕФJavaЗтзАЁЃдкЫќЕФЪЕЯжжаЃЌНкЕужЎМфЪЧЯрЛЅЦНЕШЕФЃЌВПЗжзЂВсжааФЕФНкЕуЙвЕєвВВЛЛсЖдМЏШКдьГЩгАЯьЃЌМДЪЙМЏШКжЛЪЃвЛИіНкЕуДцЛюЃЌвВПЩвде§ГЃЬсЙЉЗЂЯжЗўЮёЁЃФФХТЪЧЫљгаЕФЗўЮёзЂВсНкЕуЖМЙвСЫЃЌEureka
ClientsЩЯвВЛсЛКДцЗўЮёЕїгУЕФаХЯЂЁЃетОЭБЃжЄСЫЮвУЧЮЂЗўЮёжЎМфЕФЛЅЯрЕїгУЪЧзуЙЛНЁзГЕФЁЃ
Г§ДЫжЎЭтЃЌSpring Cloud NetflixБГКѓЧПДѓЕФПЊдДСІСПЃЌвВДйЪЙЮвУЧбЁдёСЫSpring
Cloud NetflixЃК
ЧАЮФЬсЕНЙ§ЃЌSpring CloudЕФЩчЧјЪЎЗжЛюдОЃЌЦфдквЕНчЕФгІгУвВЪЎЗжЙуЗКЃЈгШЦфЪЧЙњЭтЃЉЃЌЖјЧвећИіПђМмвВОЪмзЁСЫNetflixбЯПсЩњВњЛЗОГЕФПМбщЁЃ
Г§СЫЗўЮёзЂВсКЭЗЂЯжЃЌSpring Cloud NetflixЕФЦфЫћЙІФмвВЪЎЗжЧПДѓЃЌАќРЈRibbonЃЌhystrixЃЌFeignЃЌZuulЕШзщМўЃЌНсКЯЕНвЛЦ№ЃЌШУЗўЮёЕФЕїгУЁЂТЗгЩвВБфЕУвьГЃШнвзЁЃ
Spring Cloud NetflixзїЮЊSpringЕФжиСПМЖећКЯПђМмЃЌЪЙгУЫќвВвтЮЖзХЮвУЧФмДгSpringЛёШЁЕНОоДѓЕФБуРћЁЃSpring
CloudЕФЦфЫћзгЯюФПЃЌБШШчSpring Cloud StreamЁЂSpring Cloud ConfigЕШЕШЃЌЖМЮЊЮЂЗўЮёЕФИїжжашЧѓЬсЙЉСЫвЛеОЪНЕФНтОіЗНАИЁЃ
3. Spring Cloud ЗўЮёЗЂЯж
Spring Cloud NetflixЕФКЫаФЪЧгУгкЗўЮёзЂВсгыЗЂЯжЕФEurekaЃЌНгЯТРДЮвУЧНЋвдEurekaЮЊЯпЫїЃЌНщЩмEurekaЁЂRibbonЁЂHystrixЁЂFeignетаЉSpring
Cloud NetflixжївЊзщМўЁЃ
3.1 ЗўЮёзЂВсгыЗЂЯжЁЊЁЊEureka
EurekaетИіДЪРДдДгкЙХЯЃРАгяЃЌвтЮЊЁАЮвевЕНСЫЃЁЮвЗЂЯжСЫЃЁЁБЃЌОнДЋЃЌАЂЛљУзЕТдкЯДдшЪБЗЂЯжИЁСІдРэЃЌИпаЫЕУРДВЛМАДЉЩЯПузгЃЌХмЕННжЩЯДѓКАЃКЁАEureka(ЮвевЕНСЫ)ЃЁ"ЁЃ
EurekaгЩЖрИіinstance(ЗўЮёЪЕР§)зщГЩЃЌетаЉЗўЮёЪЕР§ПЩвдЗжЮЊСНжжЃКEureka ServerКЭEureka
ClientЁЃЮЊСЫБугкРэНтЃЌЮвУЧНЋEureka clientдйЗжЮЊService ProviderКЭService
ConsumerЁЃШчЯТЭМЫљЪОЃКEurekaRole.png
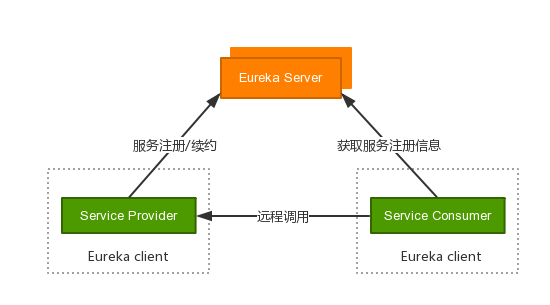
Eureka ServerЃКЗўЮёЕФзЂВсжааФЃЌИКд№ЮЌЛЄзЂВсЕФЗўЮёСаБэЁЃ
Service ProviderЃКЗўЮёЬсЙЉЗНЃЌзїЮЊвЛИіEureka ClientЃЌЯђEureka ServerзіЗўЮёзЂВсЁЂајдМКЭЯТЯпЕШВйзїЃЌзЂВсЕФжївЊЪ§ОнАќРЈЗўЮёУћЁЂЛњЦїipЁЂЖЫПкКХЁЂгђУћЕШЕШЁЃ
Service ConsumerЃКЗўЮёЯћЗбЗНЃЌзїЮЊвЛИіEureka ClientЃЌЯђEureka ServerЛёШЁService
ProviderЕФзЂВсаХЯЂЃЌВЂЭЈЙ§дЖГЬЕїгУгыService ProviderНјааЭЈаХЁЃ
Service ProviderКЭService ConsumerВЛЪЧбЯИёЕФИХФюЃЌService ConsumerвВПЩвдЫцЪБЯђEureka
ServerзЂВсЃЌРДШУздМКБфГЩвЛИіService ProviderЁЃ
Spring CloudеыЖдЗўЮёзЂВсгыЗЂЯжЃЌНјааСЫвЛВуГщЯѓЃЌВЂЬсЙЉСЫШ§жжЪЕЯжЃКEurekaЁЂConsulЁЂZookeeperЁЃФПЧАжЇГжЕУзюКУЕФОЭЪЧEurekaЃЌЦфДЮЪЧConsulЃЌзюКѓЪЧZookeeperЁЃ
3.1.1 Eureka Server
Eureka ServerзїЮЊвЛИіЖРСЂЕФВПЪ№ЕЅдЊЃЌвдREST APIЕФаЮЪНЮЊЗўЮёЪЕР§ЬсЙЉСЫзЂВсЁЂЙмРэКЭВщбЏЕШВйзїЁЃЭЌЪБЃЌEureka
ServerвВЮЊЮвУЧЬсЙЉСЫПЩЪгЛЏЕФМрПивГУцЃЌПЩвджБЙлЕиПДЕНИїИіEureka ServerЕБЧАЕФдЫаазДЬЌКЭЫљгавбзЂВсЗўЮёЕФЧщПіЁЃ
3.1.1.1 Eureka ServerЕФИпПЩгУМЏШК
Eureka ServerПЩвддЫааЖрИіЪЕР§РДЙЙНЈМЏШКЃЌНтОіЕЅЕуЮЪЬтЃЌЕЋВЛЭЌгкZooKeeperЕФбЁОйleaderЕФЙ§ГЬЃЌEureka
ServerВЩгУЕФЪЧPeer to PeerЖдЕШЭЈаХЁЃетЪЧвЛжжШЅжааФЛЏЕФМмЙЙЃЌЮоmaster/slaveЧјЗжЃЌУПвЛИіPeerЖМЪЧЖдЕШЕФЁЃдкетжжМмЙЙжаЃЌНкЕуЭЈЙ§БЫДЫЛЅЯрзЂВсРДЬсИпПЩгУадЃЌУПИіНкЕуашвЊЬэМгвЛИіЛђЖрИігааЇЕФserviceUrlжИЯђЦфЫћНкЕуЁЃУПИіНкЕуЖМПЩБЛЪгЮЊЦфЫћНкЕуЕФИББОЁЃ
ШчЙћФГЬЈEureka ServerхДЛњЃЌEureka ClientЕФЧыЧѓЛсздЖЏЧаЛЛЕНаТЕФEureka
ServerНкЕуЃЌЕБхДЛњЕФЗўЮёЦїжиаТЛжИДКѓЃЌEurekaЛсдйДЮНЋЦфФЩШыЕНЗўЮёЦїМЏШКЙмРэжЎжаЁЃЕБНкЕуПЊЪМНгЪмПЭЛЇЖЫЧыЧѓЪБЃЌЫљгаЕФВйзїЖМЛсНјааreplicateToPeerЃЈНкЕуМфИДжЦЃЉВйзїЃЌНЋЧыЧѓИДжЦЕНЦфЫћEureka
ServerЕБЧАЫљжЊЕФЫљгаНкЕужаЁЃ
вЛИіаТЕФEureka ServerНкЕуЦєЖЏКѓЃЌЛсЪзЯШГЂЪдДгСкНќНкЕуЛёШЁЫљгаЪЕР§зЂВсБэаХЯЂЃЌЭъГЩГѕЪМЛЏЁЃEureka
ServerЭЈЙ§getEurekaServiceUrls()ЗНЗЈЛёШЁЫљгаЕФНкЕуЃЌВЂЧвЛсЭЈЙ§аФЬјајдМЕФЗНЪНЖЈЦкИќаТЁЃФЌШЯХфжУЯТЃЌШчЙћEureka
ServerдквЛЖЈЪБМфФкУЛгаНгЪеЕНФГИіЗўЮёЪЕР§ЕФаФЬјЃЌEureka ServerНЋЛсзЂЯњИУЪЕР§ЃЈФЌШЯЮЊ90УыЃЌЭЈЙ§eureka.instance.lease-expiration-duration-in-secondsХфжУЃЉЁЃЕБEureka
ServerНкЕудкЖЬЪБМфФкЖЊЪЇЙ§ЖрЕФаФЬјЪБЃЈБШШчЗЂЩњСЫЭјТчЗжЧјЙЪеЯЃЉЃЌФЧУДетИіНкЕуОЭЛсНјШыздЮвБЃЛЄФЃЪНЁЃЯТЭМЮЊEurekaЙйЭјЕФМмЙЙЭМ
ЪВУДЪЧздЮвБЃЛЄФЃЪНЃПФЌШЯХфжУЯТЃЌШчЙћEureka ServerУПЗжжгЪеЕНаФЬјајдМЕФЪ§СПЕЭгквЛИіуажЕЃЈinstanceЕФЪ§СП*(60/УПИіinstanceЕФаФЬјМфИєУыЪ§)*здЮвБЃЛЄЯЕЪ§ЃЉЃЌОЭЛсДЅЗЂздЮвБЃЛЄЁЃдкздЮвБЃЛЄФЃЪНжаЃЌEureka
ServerЛсБЃЛЄЗўЮёзЂВсБэжаЕФаХЯЂЃЌВЛдйзЂЯњШЮКЮЗўЮёЪЕР§ЁЃЕБЫќЪеЕНЕФаФЬјЪ§жиаТЛжИДЕНуажЕвдЩЯЪБЃЌИУEureka
ServerНкЕуОЭЛсздЖЏЭЫГіздЮвБЃЛЄФЃЪНЁЃЫќЕФЩшМЦембЇЧАУцЬсЕНЙ§ЃЌФЧОЭЪЧФўПЩБЃСєДэЮѓЕФЗўЮёзЂВсаХЯЂЃЌвВВЛУЄФПзЂЯњШЮКЮПЩФмНЁПЕЕФЗўЮёЪЕР§ЁЃИУФЃЪНПЩвдЭЈЙ§eureka.server.enable-self-preservation
= falseРДНћгУЃЌЭЌЪБeureka.instance.lease-renewal-interval-in-secondsПЩвдгУРДИќИФаФЬјМфИєЃЌeureka.server.renewal-percent-thresholdПЩвдгУРДаоИФздЮвБЃЛЄЯЕЪ§ЃЈФЌШЯ0.85ЃЉЁЃ
3.1.1.2 Eureka ServerЕФRegionЁЂZone
EurekaЕФЙйЗНЮФЕЕЖдReginЁЂZoneМИКѕУЛгаЬсМАЃЌгЩгкИХФюГщЯѓЃЌаТЪжКмФбРэНтЁЃвђДЫЃЌЮвУЧЯШРДСЫНтвЛЯТRegionЁЂZoneЁЂEurekaМЏШКШ§епЕФЙиЯЕЃЌШчЯТЭМЫљЪОЃК
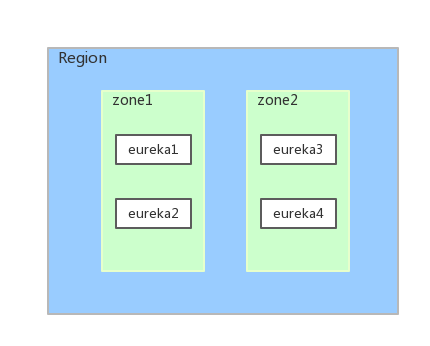
regionКЭzoneЃЈЛђепAvailability ZoneЃЉОљЪЧAWSЕФИХФюЁЃдкЗЧAWSЛЗОГЯТЃЌЮвУЧПЩвдЯШМђЕЅЕиНЋregionРэНтЮЊEurekaМЏШКЃЌzoneРэНтГЩЛњЗПЁЃЩЯЭМОЭПЩвдРэНтЮЊвЛИіEurekaМЏШКБЛВПЪ№дкСЫzone1ЛњЗПКЭzone2ЛњЗПжаЁЃ
3.1.2 Service Provider
3.1.2.1 ЗўЮёзЂВс
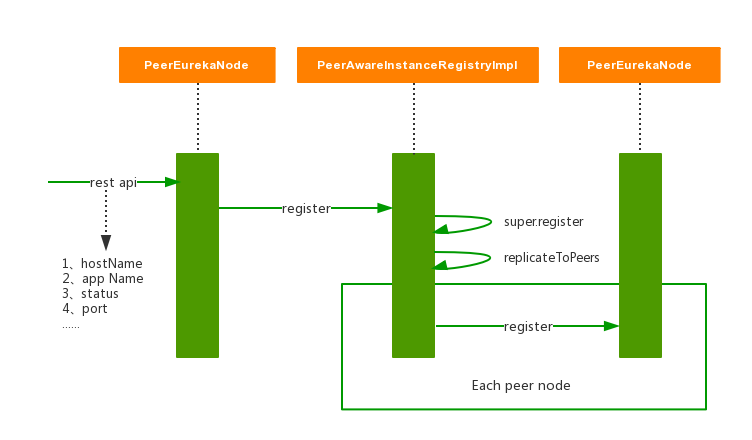
Service ProviderБОжЪЩЯЪЧвЛИіEureka ClientЁЃЫќЦєЖЏЪБЃЌЛсЕїгУЗўЮёзЂВсЗНЗЈЃЌЯђEureka
ServerзЂВсздМКЕФаХЯЂЁЃEureka ServerЛсЮЌЛЄвЛИівбзЂВсЗўЮёЕФСаБэЃЌетИіСаБэЮЊвЛИіЧЖЬзЕФhash
mapЃК
ЕквЛВуЃЌapplication nameКЭЖдгІЕФЗўЮёЪЕР§ЁЃ
ЕкЖўВуЃЌЗўЮёЪЕР§МАЦфЖдгІЕФзЂВсаХЯЂЃЌАќРЈIPЃЌЖЫПкКХЕШЁЃ
ЕБЪЕР§зДЬЌЗЂЩњБфЛЏЪБЃЈШчздЩэМьВтШЯЮЊDownЕФЪБКђЃЉЃЌвВЛсЯђEureka ServerИќаТздМКЕФЗўЮёзДЬЌЃЌЭЌЪБгУreplicateToPeers()ЯђЦфЫќEureka
ServerНкЕузізДЬЌЭЌВНЁЃ
![Uploading EurekaServerEvict_655129.png . .
.]
3.1.2.2 ајдМгыЬоГ§
ЧАУцЬсЕНЙ§ЃЌЗўЮёЪЕР§ЦєЖЏКѓЃЌЛсжмЦкадЕиЯђEureka ServerЗЂЫЭаФЬјвдајдМздМКЕФаХЯЂЃЌБмУтздМКЕФзЂВсаХЯЂБЛЬоГ§ЁЃајдМЕФЗНЪНгыЗўЮёзЂВсЛљБОвЛжТЃКЪзЯШИќаТздЩэзДЬЌЃЌдйЭЌВНЕНЦфЫќPeerЁЃ
ШчЙћEureka ServerдквЛЖЮЪБМфФкУЛгаНгЪеЕНФГИіЮЂЗўЮёНкЕуЕФаФЬјЃЌEureka
ServerНЋЛсзЂЯњИУЮЂЗўЮёНкЕуЃЈздЮвБЃЛЄФЃЪНГ§ЭтЃЉЁЃ
3.1.3 Service Consumer
Service ConsumerБОжЪЩЯвВЪЧвЛИіEureka ClientЃЈЫќвВЛсЯђEureka ServerзЂВсЃЌжЛЪЧетИізЂВсаХЯЂЮоЙиНєвЊАеСЫЃЉЁЃЫќЦєЖЏКѓЃЌЛсДгEureka
ServerЩЯЛёШЁЫљгаЪЕР§ЕФзЂВсаХЯЂЃЌАќРЈIPЕижЗЁЂЖЫПкЕШЃЌВЂЛКДцЕНБОЕиЁЃетаЉаХЯЂФЌШЯУП30УыИќаТвЛДЮЁЃЧАЮФЬсЕНЙ§ЃЌШчЙћгыEureka
ServerЭЈаХжаЖЯЃЌService ConsumerШдШЛПЩвдЭЈЙ§БОЕиЛКДцгыService ProviderЭЈаХЁЃ
ЪЕМЪПЊЗЂEurekaЕФЙ§ГЬжаЃЌгаЪБЛсгіМћService ConsumerЛёШЁЕНServer ProviderЕФаХЯЂгабгГйЃЌдкEureka
WikiжагаетУДвЛЖЮЛА:
All operations from Eureka client may take some time
to reflect in the Eureka servers and subsequently
in other Eureka clients. This is because of the caching
of the payload on the eureka server which is refreshed
periodically to reflect new information. Eureka clients
also fetch deltas periodically. Hence, it may take
up to 2 mins for changes to propagate to all Eureka
clients.
зюКѓвЛОфЛАЬсЕНЃЌЗўЮёЖЫЕФИќИФПЩФмашвЊ2ЗжжгВХФмДЋВЅЕНЫљгаПЭЛЇЖЫЃЌжСгкдвђВЂУЛгаНщЩмЁЃетЪЧвђЮЊEurekaгаШ§ДІЛКДцКЭвЛДІбгГйдьГЩЕФЁЃ
Eureka ServerЖдзЂВсСаБэНјааЛКДцЃЌФЌШЯЪБМфЮЊ30sЁЃ
Eureka ClientЖдЛёШЁЕНЕФзЂВсаХЯЂНјааЛКДцЃЌФЌШЯЪБМфЮЊ30sЁЃ
RibbonЛсДгЩЯУцЬсЕНЕФEureka ClientЛёШЁЗўЮёСаБэЃЌНЋИКдиОљКтКѓЕФНсЙћЛКДц30sЁЃ
ШчЙћВЛЪЧдкSpring CloudЛЗОГЯТЪЙгУетаЉзщМў(Eureka, Ribbon)ЃЌЗўЮёЦєЖЏКѓВЂВЛЛсТэЩЯЯђEurekaзЂВсЃЌЖјЪЧашвЊЕШЕНЕквЛДЮЗЂЫЭаФЬјЧыЧѓЪБВХЛсзЂВсЁЃаФЬјЧыЧѓЕФЗЂЫЭМфИєФЌШЯЪЧ30sЁЃSpring
CloudЖдДЫзіСЫаоИФЃЌЗўЮёЦєЖЏКѓЛсТэЩЯзЂВсЁЃ
ЛљгкService ConsumerЛёШЁЕНЕФЗўЮёЪЕР§аХЯЂЃЌЮвУЧОЭПЩвдНјааЗўЮёЕїгУСЫЁЃЖјSpring
CloudвВЮЊService ConsumerЬсЙЉСЫЗсИЛЕФЗўЮёЕїгУЙЄОпЃК
RibbonЃЌЪЕЯжПЭЛЇЖЫЕФИКдиОљКтЁЃ
HystrixЃЌЖЯТЗЦїЁЃ
FeignЃЌRESTful Web ServiceПЭЛЇЖЫЃЌећКЯСЫRibbonКЭHystrixЁЃ
НгЯТРДЮвУЧОЭвЛвЛНщЩмЁЃ
3.2 ЗўЮёЕїгУЖЫИКдиОљКтЁЊЁЊRibbon
RibbonЪЧNetflixЗЂВМЕФПЊдДЯюФПЃЌжївЊЙІФмЪЧЮЊRESTПЭЛЇЖЫЪЕЯжИКдиОљКтЁЃЫќжївЊАќРЈСљИізщМўЃК
ServerListЃЌИКдиОљКтЪЙгУЕФЗўЮёЦїСаБэЁЃетИіСаБэЛсЛКДцдкИКдиОљКтЦїжаЃЌВЂЖЈЦкИќаТЁЃЕБRibbonгыEurekaНсКЯЪЙгУЪБЃЌServerListЕФЪЕЯжРрОЭЪЧDiscoveryEnabledNIWSServerListЃЌЫќЛсБЃДцEureka
ServerжазЂВсЕФЗўЮёЪЕР§БэЁЃ
ServerListFilterЃЌЗўЮёЦїСаБэЙ§ТЫЦїЁЃетЪЧвЛИіНгПкЃЌжївЊгУгкЖдService ConsumerЛёШЁЕНЕФЗўЮёЦїСаБэНјаадЄЙ§ТЫЃЌЙ§ТЫЕФНсЙћвВЪЧServerListЁЃRibbonЬсЙЉСЫЖржжЙ§ТЫЦїЕФЪЕЯжЁЃ
IPingЃЌЬНВтЗўЮёЪЕР§ЪЧЗёДцЛюЕФВпТдЁЃ
IRuleЃЌИКдиОљКтВпТдЃЌЦфЪЕЯжРрБэЪіЕФВпТдАќРЈЃКТжбЏЁЂЫцЛњЁЂИљОнЯьгІЪБМфМгШЈЕШЁЃ
ЮвУЧвВПЩвдздМКЖЈвхИКдиОљКтВпТдЃЌБШШчЮвУЧОЭРћгУздМКЪЕЯжЕФВпТдЃЌЪЕЯжСЫЗўЮёЕФАцБОПижЦКЭжБСЌХфжУЁЃЪЕЯжКУжЎКѓЃЌНЋЪЕЯжРржиаТзЂШыЕНRibbonжаМДПЩЁЃ
ILoadBalancerЃЌИКдиОљКтЦїЁЃетвВЪЧвЛИіНгПкЃЌRibbonЮЊЦфЬсЙЉСЫЖрИіЪЕЯжЃЌБШШчZoneAwareLoadBalancerЁЃЖјЩЯВуДњТыЭЈЙ§ЕїгУЦфAPIНјааЗўЮёЕїгУЕФИКдиОљКтбЁдёЁЃвЛАуILoadBalancerЕФЪЕЯжРржаЛсв§гУвЛИіIRuleЁЃ
RestClientЃЌЗўЮёЕїгУЦїЁЃЙЫУћЫМвхЃЌетОЭЪЧИКдиОљКтКѓЃЌRibbonЯђService ProviderЗЂЦ№RESTЧыЧѓЕФЙЄОпЁЃ
RibbonЙЄзїЪБЛсзіЫФМўЪТЧщЃК
гХЯШбЁдёдкЭЌвЛИіZoneЧвИКдиНЯЩйЕФEureka ServerЃЛ
ЖЈЦкДгEurekaИќаТВЂЙ§ТЫЗўЮёЪЕР§СаБэЃЛ
ИљОнгУЛЇжИЖЈЕФВпТдЃЌдкДгServerШЁЕНЕФЗўЮёзЂВсСаБэжабЁдёвЛИіЪЕР§ЕФЕижЗЃЛ
ЭЈЙ§RestClientНјааЗўЮёЕїгУЁЃ
3.3 ЗўЮёЕїгУЖЫШлЖЯЁЊЁЊHystrix
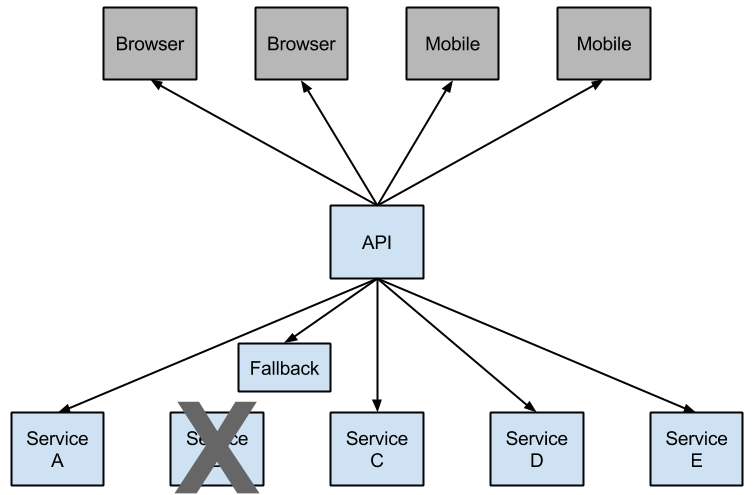
NetflixДДНЈСЫвЛИіУћЮЊHystrixЕФПт,ЪЕЯжСЫЖЯТЗЦїЕФФЃЪНЁЃЁАЖЯТЗЦїЁББОЩэЪЧвЛжжПЊЙизАжУЃЌЕБФГИіЗўЮёЕЅдЊЗЂЩњЙЪеЯжЎКѓЃЌЭЈЙ§ЖЯТЗЦїЕФЙЪеЯМрПиЃЈРрЫЦШлЖЯБЃЯеЫПЃЉЃЌЯђЕїгУЗНЗЕЛивЛИіЗћКЯдЄЦкЕФЁЂПЩДІРэЕФБИбЁЯьгІЃЈFallBackЃЉЃЌЖјВЛЪЧГЄЪБМфЕФЕШД§ЛђепХзГіЕїгУЗНЮоЗЈДІРэЕФвьГЃЃЌетбљОЭБЃжЄСЫЗўЮёЕїгУЗНЕФЯпГЬВЛЛсБЛГЄЪБМфЁЂВЛБивЊЕиеМгУЃЌДгЖјБмУтСЫЙЪеЯдкЗжВМЪНЯЕЭГжаЕФТћбгЃЌФЫжСбЉБРЁЃ
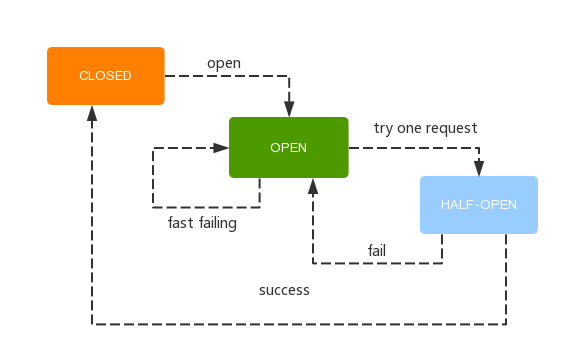
ЕБШЛЃЌдкЧыЧѓЪЇАмЦЕТЪНЯЕЭЕФЧщПіЯТЃЌHystrixЛЙЪЧЛсжБНгАбЙЪеЯЗЕЛиИјПЭЛЇЖЫЁЃжЛгаЕБЪЇАмДЮЪ§ДяЕНуажЕЃЈФЌШЯдк20УыФкЪЇАм5ДЮЃЉЪБЃЌЖЯТЗЦїДђПЊВЂЧвВЛНјааКѓајЭЈаХЃЌЖјЪЧжБНгЗЕЛиБИбЁЯьгІЁЃЕБШЛЃЌHystrixЕФБИбЁЯьгІвВЪЧПЩвдгЩПЊЗЂепЖЈжЦЕФЁЃHystrixFallback.png
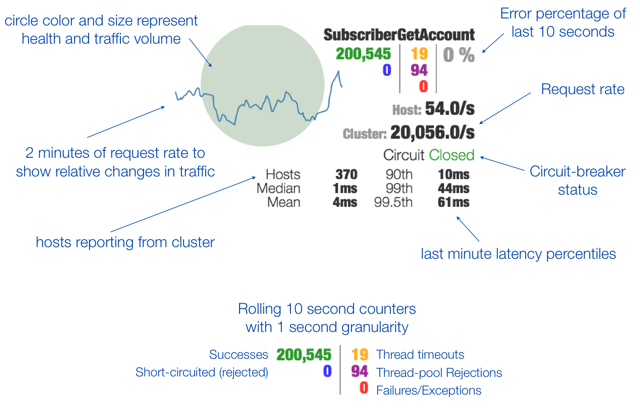
Г§СЫИєРывРРЕЗўЮёЕФЕїгУвдЭтЃЌHystrixЛЙЬсЙЉСЫзМЪЕЪБЕФЕїгУМрПиЃЈHystrix
DashboardЃЉЃЌHystrixЛсГжајЕиМЧТМЫљгаЭЈЙ§HystrixЗЂЦ№ЕФЧыЧѓЕФжДаааХЯЂЃЌВЂвдЭГМЦБЈБэКЭЭМаЮЕФаЮЪНеЙЪОИјгУЛЇЃЌАќРЈУПУыжДааЖрЩйЧыЧѓЖрЩйГЩЙІЃЌЖрЩйЪЇАмЕШЁЃNetflixЭЈЙ§hystrix-metrics-event-streamЯюФПЪЕЯжСЫЖдвдЩЯжИБъЕФМрПиЁЃSpring
CloudвВЬсЙЉСЫHystrix DashboardЕФећКЯЃЌЖдМрПиФкШнзЊЛЏГЩПЩЪгЛЏНчУцЃЌHystrix
Dashboard WikiЩЯЯъЯИЫЕУїСЫЭМЩЯУПИіжИБъЕФКЌвхЁЃ
3.4 ЗўЮёЕїгУЖЫДњТыГщЯѓКЭЗтзАЁЊЁЊFeign
FeignЪЧвЛИіЩљУїЪНЕФWeb ServiceПЭЛЇЖЫЃЌЫќЕФФПЕФОЭЪЧШУWeb ServiceЕїгУИќМгМђЕЅЁЃЫќећКЯСЫRibbonКЭHystrixЃЌДгЖјШУЮвУЧВЛдйашвЊЯдЪНЕиЪЙгУетСНИізщМўЁЃFeignЛЙЬсЙЉСЫHTTPЧыЧѓЕФФЃАхЃЌЭЈЙ§БраДМђЕЅЕФНгПкКЭВхШызЂНтЃЌЮвУЧОЭПЩвдЖЈвхКУHTTPЧыЧѓЕФВЮЪ§ЁЂИёЪНЁЂЕижЗЕШаХЯЂЁЃНгЯТРДЃЌFeignЛсЭъШЋДњРэHTTPЕФЧыЧѓЃЌЮвУЧжЛашвЊЯёЕїгУЗНЗЈвЛбљЕїгУЫќОЭПЩвдЭъГЩЗўЮёЧыЧѓЁЃ
FeignОпгаШчЯТЬиадЃК
ПЩВхАЮЕФзЂНтжЇГжЃЌАќРЈFeignзЂНтКЭJAX-RSзЂНт
жЇГжПЩВхАЮЕФHTTPБрТыЦїКЭНтТыЦї
жЇГжHystrixКЭЫќЕФFallback
жЇГжRibbonЕФИКдиОљКт
жЇГжHTTPЧыЧѓКЭЯьгІЕФбЙЫѕ
вдЯТЪЧвЛИіFeignЕФМђЕЅЪОР§ЃК
@SpringBootApplication
@EnableDiscoveryClient //ЦєгУFeign
@EnableFeignClients
public class Application
{
public static void main(String[] args)
{
SpringApplication.run(Application.class, args);
}
}
@FeignClient(name = "elements", fallback
= ElementsFallback.class) //жИЖЈfeignЕїгУЕФЗўЮёКЭHystrix
FallbackЃЈnameМДeurekaЕФapplication nameЃЉ
public interface Elements
{
@RequestMapping(value = "/index")
String index();
}
//Hystrix Fallback
@Component
public class ElementsFallback implements Elements
{
@Override
public String index()
{
return "**************";
}
}
//ВтЪдРр
@Component
public class TestController {
@Autowired
Elements elements;
@RequestMapping(value = "/testEureka",
method = RequestMethod.GET)
public String testeureka()
{
return elements.index();
}
}
|
|









