|

1.1 ЗжВМЪНЪ§ОнЙмРэжЎЭДЕу
ЮЊСЫШЗБЃЮЂЗўЮёжЎМфЫЩёюКЯЃЌУПИіЗўЮёЖМгаздМКЕФЪ§ОнПт, гаЕФЪЧЙиЯЕаЭЪ§ОнПт(SQL)ЃЌгаЕФЪЧЗЧЙиЯЕаЭЪ§ОнПт(NoSQL)ЁЃ
ПЊЗЂЦѓвЕЪТЮёЭљЭљЧЃЩцЕНЖрИіЗўЮёЃЌвЊЯызіЕНЖрИіЗўЮёЪ§ОнЕФвЛжТадВЂЗЧвзЪТЃЌЭЌбљЃЌдкЖрИіЗўЮёжЎМфНјааЪ§ОнВщбЏвВГфТњЬєеНЁЃ
ЮвУЧвдвЛИідкЯпB2BЩЬЕъЮЊР§ЃЌПЭЛЇЗўЮё АќРЈСЫПЭЛЇЕФИїжжаХЯЂЃЌР§ШчПЩгУаХгУЕШЁЃ
ЙмРэЖЉЕЅЃЌЬсЙЉЖЉЕЅЗўЮёЃЌдђашвЊбщжЄФГИіаТЖЉЕЅгыПЭЛЇЕФаХгУЯожЦУЛгаГхЭЛЁЃ
дкЕЅЬхгІгУжаЃЌЖЉЕЅЗўЮёжЛашвЊЪЙгУДЋЭГЪТЮёНЛвзОЭПЩвдвЛДЮадМьВщПЩгУаХгУКЭДДНЈЖЉЕЅЁЃ
ЯрЗДЮЂЗўЮёМмЙЙЯТЃЌЖЉЕЅКЭПЭЛЇБэЗжБ№ЪЧЯргІЗўЮёЕФЫНгаБэЃЌШчЯТЭМЫљЪОЃК
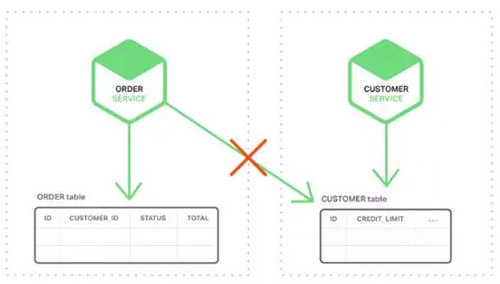
ЖЉЕЅЗўЮёВЛФмжБНгЗУЮЪПЭЛЇБэЃЌжЛФмЭЈЙ§ПЭЛЇЗўЮёЗЂВМЕФAPIРДЗУЮЪЛђепЪЙгУЗжВМЪНЪТЮё,
вВОЭЪЧжкЫљжмжЊЕФСННзЖЮЬсНЛ (2PC)РДЗУЮЪПЭЛЇБэЃЌ2PCвтвхЭМШчЯТЫљЪОЃК
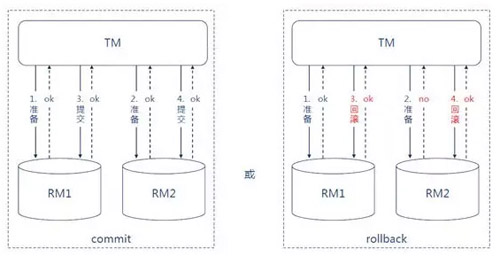
етРяДцдкСНИіЬєеНЃЌЕквЛИіЬєеНЪЧ2PCГ§вЊЧѓЪ§ОнПтБОЩэжЇГжЭтЃЌЛЙвЊЧѓЗўЮёЕФЪ§ОнПтРраЭашвЊБЃГжвЛжТЁЃ
ЕЋЪЧЯждкЕФЮЂЗўЮёМмЙЙжаЃЌУПИіЗўЮёЕФЪ§ОнПтРраЭПЩФмЪЧВЛвЛбљЕФЃЌгаЕФПЩФмЪЧMySQLЪ§ОнПтЃЌгаЕФвВПЩФмЪЧNoSQLЪ§ОнПт;
ЕкЖўИіЬєеНЪЧШчКЮЪЕЯжДгЖрИіЗўЮёжаВщбЏЪ§ОнЁЃМйЩшгІгУГЬађашвЊЯдЪОвЛИіПЭЛЇКЭЫћзюНќЕФЖЉЕЅЁЃШчЙћЖЉЕЅЗўЮёЬсЙЉгУгкМьЫїПЭЛЇЖЉЕЅЕФAPIЃЌФЧУДгІгУГЬађЖЫПЩвдЭЈЙ§JOINЗНЪНРДМьЫїДЫЪ§ОнЃЌМДгІгУГЬађЪзбЁДгПЭЛЇЗўЮёМьЫїПЭЛЇЃЌВЂДгЖЉЕЅЗўЮёМьЫїПЭЛЇЕФЖЉЕЅЁЃ
ШЛЖјЃЌШчЙћЖЉЕЅЗўЮёНіжЇГжЭЈЙ§ЦфжїМќВщевЖЉЕЅ(вВаэЫќЪЙгУНіжЇГжЛљгкжїМќЕФМьЫїЕФNoSQLЪ§ОнПт)ЃЌ
дкетжжЧщПіЯТЃЌОЭУЛгаЗНЗЈРДМьЫїВщбЏЫљашЕФЪ§ОнЁЃ
ЮЊНтОіетСНДѓЭДЕуЃЌОЭашвЊЮвУЧЪЙгУЕНЗжВНЪНЪ§ОнЙмРэСЫЁЃ
1.2 ЗжВМЪНЪ§ОнЙмРэжЎОйДы
дкНщЩмЗжВМЪНЪ§ОнЙмРэ(CRUD)НтОіЗНАИжЎЧАЃЌгаБивЊНщЩмЯТCAPдРэКЭзюжевЛжТадЯрЙиИХФюЁЃ
1.2.1 CAPдРэКЭзюжевЛжТад
1.2.1.1 CAPдРэ(CAP Theorem)
дкзуЧђБШШќРяЃЌвЛИіЧђдБдквЛГЁБШШќжаНјШ§ИіЧђЃЌГЦжЎЮЊУБзгЯЗЗЈ(Hat-trick)ЁЃдкЗжВМЪНЪ§ОнЯЕЭГжаЃЌвВгавЛИіУБзгдРэ(CAP
Theorem)ЃЌВЛЙ§ДЫУБзгЗЧБЫУБзгЁЃCAPдРэжаЃЌгаШ§ИівЊЫиЃК
1)вЛжТад(C onsistency)
2)ПЩгУад(A vailability)
3)ЗжЧјШнШЬад(P artition tolerance)
CAPдРэжИЕФЪЧЃЌетШ§ИівЊЫизюЖржЛФмЭЌЪБЪЕЯжСНЕуЃЌВЛПЩФмШ§епМцЙЫЁЃ
вђДЫдкНјааЗжВМЪНМмЙЙЩшМЦЪБЃЌБиаызіГіШЁЩсЁЃЖјЖдгкЗжВМЪНЪ§ОнЯЕЭГЃЌЗжЧјШнШЬадЪЧЛљБОвЊЧѓ
ЃЌЗёдђОЭЪЇШЅСЫМлжЕЃЌвђДЫЩшМЦЗжВМЪНЪ§ОнЯЕЭГЃЌОЭЪЧдквЛжТадКЭПЩгУаджЎМфШЁвЛИіЦНКтЁЃ
ЖдгкДѓЖрЪ§webгІ гУЃЌЦфЪЕВЂВЛашвЊЧПвЛжТадЃЌвђДЫЮўЩќвЛжТадЖјЛЛШЁИпПЩгУадЃЌЪЧФПЧАЖрЪ§ЗжВМЪНЪ§ОнПтВњЦЗЕФЗНЯђЁЃ
ЕБШЛЃЌЮўЩќвЛжТадЃЌВЂВЛЪЧЭъШЋВЛЙмЪ§ОнЕФвЛжТадЃЌЗёдђЪ§ОнЪЧЛьТвЕФЃЌФЧУДЯЕЭГПЩгУаддйИпЗжВМЪНдйКУвВУЛгаСЫМлжЕЁЃ
ЮўЩќвЛжТадЃЌжЛЪЧВЛдйвЊЧѓЙиЯЕаЭЪ§ ОнПтжаЕФЧПвЛжТадЃЌЖјЪЧжЛвЊЯЕЭГФмДяЕНзюжевЛжТадМДПЩЃЌПМТЧЕНПЭЛЇЬхбщЃЌетИізюжевЛжТЕФЪБМфДАПкЃЌвЊОЁПЩФмЕФЖдгУЛЇЭИУїЃЌвВОЭЪЧашвЊБЃеЯЁАгУЛЇИажЊЕНЕФвЛжТадЁБЁЃ
ЭЈГЃЪЧЭЈЙ§Ъ§ОнЕФЖрЗнвьВНИДжЦРДЪЕЯжЯЕЭГЕФИпПЩгУКЭЪ§ОнЕФзюжевЛжТадЕФЃЌЁАгУЛЇИажЊЕНЕФвЛжТадЁБЕФЪБМфДАПкдђ
ШЁОігкЪ§ОнИДжЦЕНвЛжТзДЬЌЕФЪБМфЁЃ
1.2.1.2 зюжевЛжТад(eventually consistent)
ЖдгквЛжТадЃЌПЩвдЗжЮЊДгПЭЛЇЖЫКЭЗўЮёЖЫСНИіВЛЭЌЕФЪгНЧЁЃ
ДгПЭЛЇЖЫРДПДЃЌвЛжТаджївЊжИЕФЪЧЖрВЂЗЂЗУЮЪЪБИќаТЙ§ЕФЪ§ОнШчКЮЛёШЁЕФЮЪЬтЁЃ
ДгЗўЮёЖЫРДПДЃЌдђЪЧИќаТШчКЮИДжЦЗжВМЕНећИіЯЕЭГЃЌвдБЃжЄЪ§ОнзюжевЛжТЁЃ
вЛжТадЪЧвђЮЊгаВЂЗЂЖСаДВХгаЕФЮЪЬтЃЌвђДЫдкРэНтвЛжТадЕФЮЪЬтЪБЃЌвЛЖЈвЊзЂвтНсКЯПМТЧВЂЗЂЖСаДЕФГЁОАЁЃ
ДгПЭЛЇЖЫНЧЖШЃЌЖрНјГЬВЂЗЂЗУЮЪЪБЃЌИќаТЙ§ЕФЪ§ОндкВЛЭЌНјГЬШчКЮЛёШЁЕФВЛЭЌВпТдЃЌОіЖЈСЫВЛЭЌЕФвЛжТадЁЃ
ЖдгкЙиЯЕаЭЪ§ОнПтЃЌвЊЧѓИќаТЙ§ЕФЪ§ОнФмБЛКѓајЕФ ЗУЮЪЖМФмПДЕНЃЌетЪЧЧПвЛжТад
;ШчЙћФмШнШЬКѓајЕФВПЗжЛђепШЋВПЗУЮЪВЛЕНЃЌдђЪЧШѕвЛжТад ; ШчЙћОЙ§вЛЖЮЪБМфКѓвЊЧѓФмЗУЮЪЕНИќаТКѓЕФЪ§ОнЃЌдђЪЧзюжевЛжТадЁЃ
ДгЗўЮёЖЫНЧЖШЃЌШчКЮОЁПьНЋИќаТКѓЕФЪ§ОнЗжВМЕНећИіЯЕЭГЃЌНЕЕЭДяЕНзюжевЛжТадЕФЪБМфДАПкЃЌЪЧЬсИпЯЕЭГЕФПЩгУЖШКЭгУЛЇЬхбщЗЧГЃживЊЕФЗНУцЁЃ
ФЧУДЮЪЬтРДСЫЃЌШчКЮЪЕЯжЪ§ОнЕФзюжевЛжТадФи?Д№АИОЭдкЪТМўЧ§ЖЏМмЙЙЁЃ
1.2.2 ЪТМўЧ§ЖЏМмЙЙМђНщ
Chris RichardsonзїЮЊЮЂЗўЮёМмЙЙЩшМЦСьгђЕФШЈЭўЃЌИјГіСЫЗжВМЪНЪ§ОнЙмРэЕФзюМбНтОіЗНАИЁЃ
ЖдгкДѓЖрЪ§гІгУЖјбдЃЌвЊЪЕЯжЮЂЗўЮёЕФЗжВМЪНЪ§ОнЙмРэЃЌашвЊВЩгУЪТМўЧ§ЖЏМмЙЙ(event-driven
architecture)ЁЃ
дкЪТМўЧ§ЖЏМмЙЙжаЃЌЕБФГМўживЊЪТЧщЗЂЩњЪБЃЌЮЂЗўЮёЛсЗЂВМвЛИіЪТМўЃЌР§ШчИќаТвЛИівЕЮёЪЕЬхЁЃ
ЕБЖЉдФетаЉЪТМўЕФЮЂЗўЮёНгЪеДЫЪТМўЪБЃЌОЭПЩвдИќаТздМКЕФвЕЮёЪЕЬхЃЌвВПЩФмЛсв§ЗЂИќЖрЕФЪТМўЗЂВМЃЌШУЦфЫћЯрЙиЗўЮёНјааЪ§ОнИќаТЃЌзюжеЪЕЯжЗжВМЪНЪ§ОнзюжевЛжТадЁЃ
ПЩвдЪЙгУЪТМўРДЪЕЯжПчЖрЗўЮёЕФвЕЮёНЛвзЁЃНЛвзвЛАугЩвЛЯЕСаВНжшЙЙГЩЃЌУПвЛВНжшЖМгЩвЛИіИќаТвЕЮёЪЕЬхЕФЮЂЗўЮёКЭЗЂВММЄЛюЯТвЛВНжшЕФЪТМўЙЙГЩЁЃ
1.2.2.1 ЪТМўЧ§ЖЏЪОР§1
ЯТЭМеЙЯжШчКЮЪЙгУЪТМўЧ§ЖЏЗНЗЈЃЌдкДДНЈЖЉЕЅЪБМьВщаХгУПЩгУЖШЃЌЮЂЗўЮёжЎМфЭЈЙ§ЯћЯЂДњРэ(Messsage
Broker)РДНЛЛЛЪТМўЁЃ
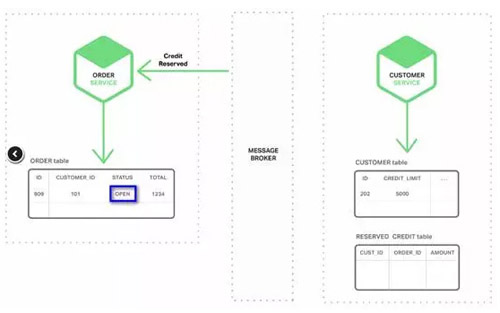
1. ЖЉЕЅЗўЮёДДНЈвЛИіДјгаNEWзДЬЌЕФOrder (ЖЉЕЅ)ЃЌЗЂВМСЫвЛИіЁАOrder
Created Event(ДДНЈЖЉЕЅ)ЁБЕФЪТМўЁЃ
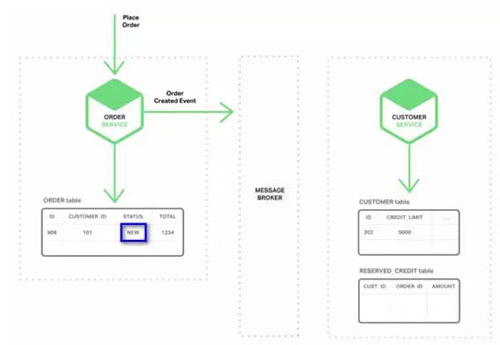
2. ПЭЛЇЗўЮё ЯћЗбOrder Created EventЪТМўЃЌЮЊДЫЖЉЕЅдЄСєаХгУЃЌЗЂВМЁАCredit
Reserved Event(аХгУдЄСє)ЁБЪТМўЁЃ
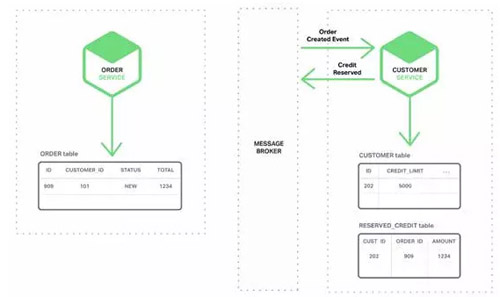
3. ЖЉЕЅЗўЮёЯћЗбCredit Reserved EventЃЌИФБфЖЉЕЅЕФзДЬЌЮЊOPENЁЃ
1.2.2.2 ЪТМўЧ§ЖЏЪОР§2
ЯТЭМеЙЯжШчКЮЪЙгУЪТМўЧ§ЖЏЗНЗЈЃЌдкДДНЈЖЉЕЅЪБДЅЗЂжЇИЖвЕЮёЕФЪ§ОнИќаТЃЌЮЂЗўЮёжЎМфЭЈЙ§ЯћЯЂДњРэ(Messsage
Broker)РДНЛЛЛЪТМўЁЃ
1. ЖЉЕЅЗўЮёДДНЈвЛИіД§жЇИЖЕФЖЉЕЅЃЌЗЂВМвЛИіЁАДДНЈЖЉЕЅЁБЕФЪТМўЁЃ
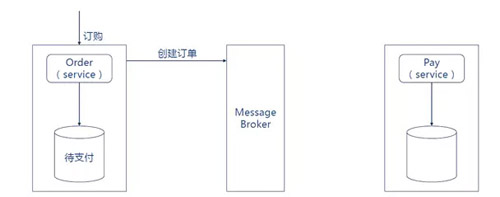
2. жЇИЖЗўЮёЯћЗбЁАДДНЈЖЉЕЅЁБЪТМўЃЌжЇИЖЭъГЩКѓЗЂВМвЛИіЁАжЇИЖЭъГЩЁБЪТМўЁЃ
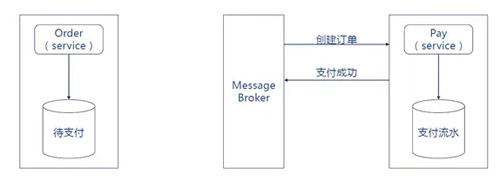
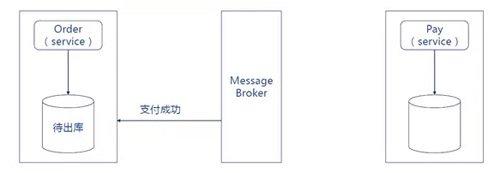
3. ЖЉЕЅЗўЮёЯћЗбЁАжЇИЖЭъГЩЁБЪТМўЃЌЖЉЕЅзДЬЌИќаТЮЊД§ГіПтЁЃ
1.2.3 ЪТМўЧ§ЖЏМмЙЙжЎЗжВМЪНЪ§ОнИќаТ
ЩЯНкЭЈЙ§ЪОР§ИХвЊНщЩмСЫЭЈЙ§ЪТМўЧ§ЖЏЗНЪНЃЌЪЕЯжСЫЗжВМЪНЪ§ОнзюжевЛжТадБЃжЄЁЃзнЙлЮЂЗўЮёМмЙЙЯТЕФЪТМўЧ§ЖЏвЕЮёДІРэТпМЃЌЦфКЫаФвЊЕудкгкЃЌПЩППЕФЪТМўЭЖЕнКЭБмУтЪТМўЕФжиИДЯћЗбЁЃ
ПЩППЪТМўЭЖЕнгавдЯТСНИіЬиадЃК
1) УПИіЗўЮёдзгадЕФЭъГЩвЕЮёВйзїКЭЗЂВМЪТМў;
2) ЯћЯЂДњРэШЗБЃЪТМўЭЖЕнжСЩйвЛДЮ(at least once);
ЖјБмУтЪТМўжиИДЯћЗбдђвЊЧѓЯћЗбЪТМўЕФЗўЮёЪЕЯжУнЕШадЃЌБШШчжЇИЖЗўЮёВЛФмвђЮЊжиИДЪеЕНЪТМўЖјЖрДЮжЇИЖЁЃ
BTWЃКЕБЧАСїааЕФЯћЯЂЖгСаШчKafkaЕШЃЌЖМвбОЪЕЯжСЫЪТМўЕФГжОУЛЏКЭat
least onceЕФЭЖЕнФЃЪНЃЌЫљвдПЩППЪТМўЭЖЕнЕФЕкЖўЬѕЬиадвбОТњзуЃЌетРяОЭВЛеЙПЊЁЃНгЯТРДеТНкНВжиЕуНВЪіШчКЮЪЕЯжПЩППЪТМўЭЖЕнЕФЕквЛЬѕЬиадКЭБмУтЪТМўжиИДЯћЗбЃЌМДЗўЮёЕФвЕЮёВйзїКЭЗЂВМЪТМўЕФдзгадКЭБмУтЯћЗбепжиИДЯћЗбЪТМўвЊЧѓЗўЮёЪЕЯжУнЕШадЁЃ
1.2.3.1 ШчКЮЪЕЯжЪТМўЭЖЕнВйзїдзгад?
ЪТМўЧ§ЖЏМмЙЙЛсХіЕНЪ§ОнПтИќаТКЭЗЂВМЪТМўдзгадЮЪЬтЁЃР§ШчЃЌЖЉЕЅЗўЮёБиаыЯђORDERБэВхШывЛааЃЌШЛКѓЗЂВМOrder
Created eventЃЌетСНИіВйзїашвЊдзгадЁЃБШШчИќаТЪ§ОнПтКѓЃЌЗўЮёЬБСЫ(crashes)дьГЩЪТМўЮДФмЗЂВМЃЌЯЕЭГБфГЩВЛвЛжТзДЬЌЁЃФЧУДШчКЮЪЕЯжЗўЮёЕФвЕЮёВйзїКЭЗЂВМЪТМўЕФдзгадФи?
1.2.3.1.1 ЪЙгУБОЕиЪТЮёЗЂВМЪТМў
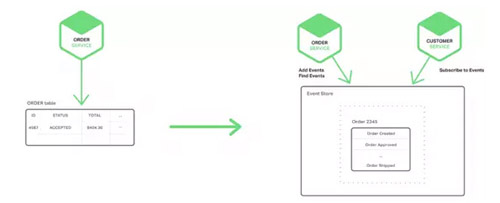
ЛёЕУдзгадЕФвЛИіЗНЗЈЪЧНЋЗўЮёЕФвЕЮёВйзїКЭЗЂВМЪТМўЗХдквЛИіБОЕиЪ§ОнПтЪТЮёРяЃЌвВОЭЪЧЫЕЃЌашвЊдкБОЕиНЈСЂвЛИіEVENTБэЃЌДЫБэдкДцДЂвЕЮёЪЕЬхЪ§ОнПтжаЦ№ЕНЯћЯЂСаБэЙІФмЁЃЕБгІгУЗЂЦ№вЛИі(БОЕи)Ъ§ОнПтНЛвзЃЌИќаТвЕЮёЪЕЬхзДЬЌЪБЃЌЛсЯђEVENTБэжаВхШывЛИіЪТМўЃЌШЛКѓЬсНЛДЫДЮНЛвзЁЃСэЭтвЛИіЖРСЂгІгУНјГЬЛђепЯпГЬВщбЏДЫEVENTБэЃЌЯђЯћЯЂДњРэЗЂВМЪТМўЃЌШЛКѓЪЙгУБОЕиНЛвзБъжОДЫЪТМўЮЊвбЗЂВМЃЌШчЯТЭМЫљЪОЃК

ЖЉЕЅЗўЮёЯђORDERБэВхШывЛааЃЌШЛКѓЯђEVENTБэжаВхШыOrder
Created eventЃЌЪТМўЗЂВМЯпГЬЛђепНјГЬВщбЏEVENTБэЃЌЧыЧѓЮДЗЂВМЪТМўЃЌЗЂВМЫћУЧЃЌШЛКѓИќаТEVENTБэБъжОДЫЪТМўЮЊвбЗЂВМЁЃ
ДЫЗНЗЈвВЪЧгХШБЕуЖМгаЁЃгХЕуЪЧПЩвдШЗБЃЪТМўЗЂВМВЛвРРЕгк2PCЃЌгІгУЗЂВМвЕЮёВуМЖЪТМўЖјВЛашвЊЭЦЖЯЫћУЧЗЂЩњСЫЪВУД;ЖјШБЕудкгкДЫЗНЗЈгЩгкПЊЗЂШЫдББиаыРЮМЧЗЂВМЪТМўЃЌвђДЫгаПЩФмГіЯжДэЮѓЁЃ
1.2.3.1.2 ЪЙгУЪТМўдД
Event sourcing (ЪТМўдД)ЭЈЙ§ЪЙгУвдЪТМўжааФЕФЪ§ОнДцДЂЗНЪНРДБЃжЄвЕЮёЪЕЬхЕФвЛжТадЁЃЪТМўдДБЃДцСЫУПИівЕЮёЪЕЬхЫљгазДЬЌБфЛЏЕФЪТМўЃЌЖјВЛЪЧДцДЂЪЕЬхЕБЧАЕФзДЬЌЁЃгІгУПЩвдЭЈЙ§жиЗХЪТМўРДжиНЈЪЕЬхЯждкЕФзДЬЌЁЃжЛвЊвЕЮёЪЕЬхЗЂЩњБфЛЏЃЌаТЪТМўОЭЛсЬэМгЕНЪТМўБэжаЁЃвђЮЊБЃДцЪТМўЪЧЕЅвЛВйзїЃЌвђДЫПЯЖЈЪЧдзгадЕФЁЃ
ЮЊСЫРэНтЪТМўдДЙЄзїЗНЪНЃЌПМТЧвдЪТМўЪЕЬхзїЮЊвЛИіР§згЫЕУїЁЃДЋЭГЗНЪНжаЃЌУПИіЖЉЕЅгГЩфЮЊORDERБэжавЛааЁЃЕЋЪЧЖдгкЪТМўдДЗНЪНЃЌЖЉЕЅЗўЮёвдЪТМўзДЬЌИФБфЗНЪНДцДЂвЛИіЖЉЕЅЃКДДНЈЕФЃЌвбХњзМЕФЃЌвбЗЂЛѕЕФЃЌШЁЯћЕФ;УПИіЪТМўАќРЈзуЙЛаХЯЂРДжиНЈЖЉЕЅЕФзДЬЌЁЃ
ЪТМўдДЗНЗЈгаКмЖргХЕуЃКНтОіСЫЪТМўЧ§ЖЏМмЙЙЙиМќЮЪЬтЃЌЪЙЕУвЕЮёЪЕЬхИќаТКЭЪТМўЗЂВМдзгЛЏЃЌЕЋЪЧвВДцдкШБЕуЃЌвђЮЊЪЧГжОУЛЏЪТМўЖјВЛЪЧЖдЯѓЃЌЕМжТЪ§ОнВщбЏЪБЃЌБиаыЪЙгУ
Command Query Responsibility Segregation (CQRS) РДЭъГЩВщбЏвЕЮёЃЌДгПЊЗЂНЧЖШПДЃЌДцдквЛЖЈЬєеНЁЃ
1.2.3.2 ШчКЮБмУтЪТМўжиИДЯћЗб?
вЊБмУтЪТМўжиИДЯћЗбЃЌашвЊЯћЗбЪТМўЕФЗўЮёЪЕЯжЗўЮёУнЕШЃЌвђЮЊДцдкжиЪдКЭДэЮѓВЙГЅЛњжЦЃЌВЛПЩБмУтЕФдкЯЕЭГжаДцдкжиИДЪеЕНЯћЯЂЕФГЁОАЃЌЗўЮёУнЕШФмЬсИпЪ§ОнЕФвЛжТадЁЃдкБрГЬжа,вЛИіУнЕШВйзїЕФЬиЕуЪЧЦфШЮвтЖрДЮжДааЫљВњЩњЕФгАЯьОљгывЛДЮжДааЕФгАЯьЯрЭЌЃЌвђДЫашвЊПЊЗЂШЫдБдкЙІФмЩшМЦЪЕЯжЪБЃЌашвЊЬиБ№зЂвтЗўЮёЕФУнЕШадЁЃ
1.2.4 ЪТМўЧ§ЖЏМмЙЙжЎЗжВМЪНЪ§ОнВщбЏ
ЮЂЗўЮёМмЙЙЯТЃЌгЩгкЗжВМЪНЪ§ОнПтЕФДцдкЃЌЕМжТдкжДаагУЛЇвЕЮёЪ§ОнВщбЏЪБЃЌЭЈГЃашвЊПчЖрИіЮЂЗўЮёЪ§ОнПтНјааЪ§ОнВщбЏЃЌвВОЭЪЧЗжВМЪНЪ§ОнВщбЏЁЃФЧУДЮЪЬтРДСЫЃЌгЩгкУПИіЮЂЗўЮёЕФЪ§ОнЖМЪЧЫНгаЛЏЕФЃЌжЛФмЭЈЙ§ИїздЕФRESTНгПкЛёШЁЃЌШчЙћИКд№вЕЮёВщбЏЕФЙІФмФЃПщЃЌЭЈЙ§ЕїгУИїИіЮЂЗўЮёЕФRESTНгПкРДЗжБ№ЛёШЁЛљДЁЪ§ОнЃЌШЛКѓдкФкДцжадйНјаавЕЮёЪ§ОнЦДзАКѓЃЌдйЗЕЛиИјгУЛЇЁЃИУЗНЗЈЮоТлДгГЬађЩшМЦЛђЪЧВщбЏадФмНЧЖШПДЃЌЖМВЛЪЧвЛИіКмКУЕФЗНЗЈЁЃФЧУДШчКЮНтОіЮЂЗўЮёМмЙЙЯТЕФЗжВМЪНЪ§ОнВщбЏЮЪЬтФи?
дкИјГіНтОіЗНАИжЎЧАЃЌашвЊЖСепЪзЯШСЫНтЯТЮяЛЏЪгЭМКЭУќСюВщбЏжАд№ЗжРыЕШЯрЙиИХФюЁЃ
1.2.4.1 ЪВУДЪЧЮяЛЏЪгЭМ(merialized views)?
ЮяЛЏЪгЭМЪЧАќРЈвЛИіВщбЏНсЙћЕФЪ§ОнПтЖдЯёЃЌЫќЪЧдЖГЬЪ§ОнЕФЕФБОЕиИББОЃЌЛђепгУРДЩњГЩЛљгкЪ§ОнБэЧѓКЭЕФЛузмБэЁЃЮяЛЏЪгЭМДцДЂЛљгкдЖГЬБэЕФЪ§ОнЃЌвВПЩвдГЦЮЊПьееЁЃетИіЛљБОЩЯОЭЫЕГіСЫЮяЛЏЪгЭМЕФБОжЪЃЌЫќЪЧвЛзщВщбЏЕФНсЙћЃЌетбљЪЦБиЮЊНЋРДдйДЮашвЊетзщЪ§ОнЪБДѓДѓЬсИпВщбЏадФмЁЃЮяЛЏЪгЭМгаСНжжЫЂаТФЃЪНON
DEMANDКЭON COMMITЃЌгУЛЇПЩИљОнЪЕМЪЧщПіНјааЩшжУЁЃ
ЮяЛЏЪгЭМЖдгкгІгУВуЪЧЭИУїЕФЃЌВЛашвЊгаШЮКЮЕФИФЖЏЃЌжеЖЫгУЛЇЩѕжСЖМИаОѕВЛЕНЕзВуЪЧгУЕФЮяЛЏЪгЭМЁЃзмжЎЃЌЪЙгУЮяЛЏЪгЭМЕФФПЕФвЛИіЪЧЬсИпВщбЏадФмЃЌСэвЛИіЪЧгЩгкЮяЛЏЪгЭМАќКЌЕФЪ§ОнЪЧдЖГЬЪ§ОнПтЕФЪ§ОнПьееЛђПНБДЃЌЮЂЗўЮёПЩЭЈЙ§ЮяЛЏЪгЭМКЭУќСюВщбЏжАд№ЗжРы(CQRS)ММЪѕ(ВЮМћвдЯТеТНк)ЪЕЯжЗжВМЪНЪ§ОнВщбЏЁЃ
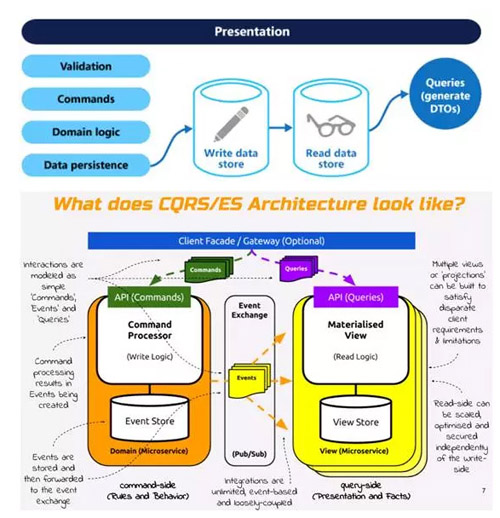
1.2.4.2 ЪВУДЪЧУќСюВщбЏжАд№ЗжРы(CQRS)?
дкГЃгУЕФЕЅЬхгІгУМмЙЙжаЃЌЭЈГЃЖМЪЧЭЈЙ§Ъ§ОнЗУЮЪВуРДаоИФЛђепВщбЏЪ§ОнЃЌвЛАуаоИФКЭВщбЏЪЙгУЕФЪЧЯрЭЌЕФЪЕЬхЁЃдквЛаЉвЕЮёТпММђЕЅЕФЯЕЭГжаПЩФмУЛгаЪВУДЮЪЬтЃЌЕЋЪЧЫцзХЯЕЭГТпМБфЕУИДдгЃЌгУЛЇдіЖрЃЌетжжЩшМЦОЭЛсГіЯжвЛаЉадФмЮЪЬт;СэЭтИќживЊЕФЪЧЃЌдкЮЂЗўЮёМмЙЙЯТЃЌЭЈГЃашвЊПчЖрИіЮЂЗўЮёЪ§ОнПтРДВщбЏЪ§ОнЃЌДЫЪБЃЌЮвУЧПЩНшжњУќСюВщбЏжАд№ЗжРы(CQRS)РДгааЇНтОіетаЉЮЪЬтЁЃ
CQRSЪЙгУЗжРыЕФНгПкНЋЪ§ОнВщбЏВйзї(Queries)КЭЪ§ОнаоИФВйзї(Commands)ЗжРыПЊРДЃЌетвВвтЮЖзХдкВщбЏКЭИќаТЙ§ГЬжаЪЙгУЕФЪ§ОнФЃаЭвВЪЧВЛвЛбљЕФЁЃетбљЖСКЭаДТпМОЭИєРыПЊРДСЫЁЃЪЙгУCQRSЗжРыСЫЖСаДжАд№жЎКѓЃЌПЩвдЖдЪ§ОнНјааЖСаДЗжРыВйзїРДИФНјадФмЃЌЭЌЪБЬсИпПЩРЉеЙадКЭАВШЋЁЃШчЯТЭМЃК
жїЪ§ОнПтДІРэCUDЃЌДгПтДІРэRЃЌДгПтЕФЕФНсЙЙПЩвдКЭжїПтЕФНсЙЙЭъШЋвЛбљЃЌвВПЩвдВЛвЛбљЃЌДгПтжївЊгУРДНјаажЛЖСЕФВщбЏВйзїЁЃдкЪ§СПЩЯДгПтЕФИіЪ§вВПЩвдИљОнВщбЏЕФЙцФЃНјааРЉеЙЃЌдквЕЮёТпМЩЯЃЌвВПЩвдИљОнзЈЬтДгжїПтжаЛЎЗжГіВЛЭЌЕФДгПтЁЃДгПтвВПЩвдЪЕЯжГЩReportingDatabaseЃЌИљОнВщбЏЕФвЕЮёашЧѓЃЌДгжїПтжаГщШЁвЛаЉБивЊЕФЪ§ОнЩњГЩвЛЯЕСаВщбЏБЈБэРДДцДЂЁЃ
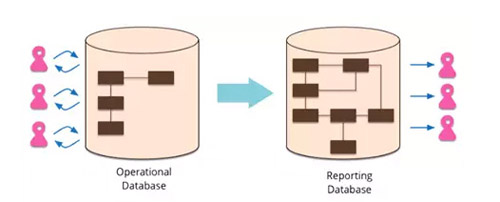
ЪЙгУReportingDatabaseЕФвЛаЉгХЕуЭЈГЃПЩвдЪЙЕУВщбЏБфЕУИќМгМђЕЅИпаЇЃК
ЁЄ ReportingDatabaseЕФНсЙЙКЭЪ§ОнБэЛсеыЖдГЃгУЕФВщбЏЧыЧѓНјааЩшМЦЁЃ
ЁЄ ReportingDatabaseЪ§ОнПтЭЈГЃЛсШЅе§ЙцЛЏЃЌДцДЂвЛаЉШпгрЖјМѕЩйБивЊЕФJoinЕШСЊКЯВщбЏВйзїЃЌЪЙЕУВщбЏМђЛЏКЭИпаЇЃЌвЛаЉдкжїЪ§ОнПтжагУВЛЕНЕФЪ§ОнаХЯЂЃЌдкReportingDatabaseПЩвдВЛгУДцДЂЁЃ
ЁЄ ПЩвдЖдReportingDatabaseжиЙЙгХЛЏЃЌЖјВЛгУШЅИФБфВйзїЪ§ОнПтЁЃ
ЁЄ ЖдReportingDatabaseЪ§ОнПтЕФВщбЏВЛЛсИјВйзїЪ§ОнПтДјРДШЮКЮбЙСІЁЃ
ЁЄ ПЩвдеыЖдВЛЭЌЕФВщбЏЧыЧѓНЈСЂВЛЭЌЕФReportingDatabaseПтЁЃ
1.2.4.3 ШчКЮЪЕЯжЪТМўЧ§ЖЏМмЙЙЯТЕФЪ§ОнВщбЏЗўЮё?
ЪТМўЧ§ЖЏВЛНіПЩвдгУгкЗжВМЪНЪ§ОнвЛжТадБЃжЄЃЌЛЙПЩвдНшжњЮяЛЏЪгЭМКЭУќСюВщбЏжАд№ЗжРыММЪѕЃЌЪЙгУЪТМўРДЮЌЛЄВЛЭЌЮЂЗўЮёгЕгаЪ§ОндЄСЌНг(pre-join)ЕФЮяЛЏЪгЭМЃЌДгЖјЪЕЯжЮЂЗўЮёМмЙЙЯТЕФЗжВМЪНЪ§ОнВщбЏЁЃЮЌЛЄЮяЛЏЪгЭМЕФЗўЮёЖЉдФСЫЯрЙиЪТМўВЂдкЪТМўЗЂЩњЪБИќаТЮяЛЏЪгЭМЁЃР§ШчЃЌПЭЛЇЖЉЕЅЪгЭМИќаТЗўЮё(ЮЌЛЄПЭЛЇЖЉЕЅЪгЭМ)ЛсЖЉдФгЩПЭЛЇЗўЮёКЭЖЉЕЅЗўЮёЗЂВМЕФЪТМў(ФњЛЙПЩвдЪЙгУЪТМўРДЮЌЛЄгЩЖрИіЮЂЗўЮёгЕгаЕФЪ§ОнзщГЩЕФЮяЛЏЪгЭМЁЃ
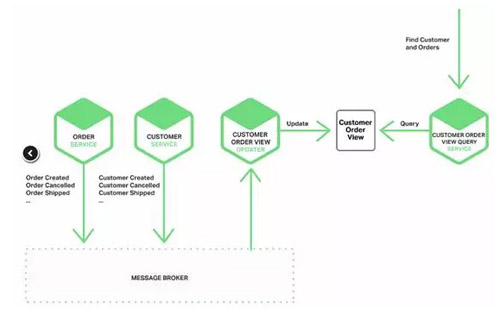
Р§ШчЩЯЭМжаМфЕФ ЁАПЭЛЇЖЉЕЅЪгЭМИќаТЁБЗўЮёЃЌжївЊИКд№ПЭЛЇЖЉЕЅЪгЭМЕФИќаТЁЃИУЗўЮёЖЉдФСЫПЭЛЇЗўЮёКЭЖЉЕЅЗўЮёЗЂВМЕФЪТМўЁЃЕБЁАПЭЛЇЖЉЕЅЪгЭМИќаТЁБЗўЮёЪеЕНСЫЩЯЭМзѓВрЕФПЭЛЇЛђепЖЉЕЅИќаТЪТМўЃЌдђЛсДЅЗЂИќаТПЭЛЇЖЉЕЅЮяЛЏЪгЭМЪ§ОнМЏЁЃетРяПЩвдЪЙгУЮФЕЕЪ§ОнПт(Р§ШчMongoDB)РДЪЕЯжПЭЛЇЖЉЕЅЪгЭМЃЌЮЊУПИігУЛЇДцДЂвЛИіЮФЕЕЁЃЖјЩЯЭМгвВрЕФПЭЛЇЖЉЕЅЪгЭМВщбЏЗўЮёИКд№ЯьгІЖдПЭЛЇвдМАзюНќЖЉЕЅ(ЭЈЙ§ВщбЏПЭЛЇЖЉЕЅЪгЭМЪ§ОнМЏ)ЕФВщбЏЁЃ
змжЎЃЌЩЯЭМЫљЪОвЕЮёТпМЃЌгУЕНСЫЪТМўЧ§ЖЏЁЂЮяЛЏЪгЭМКЭУќСюВщбЏжАд№ЗжРыЕШММЪѕЃЌгааЇНтОіСЫЮЂЗўЮёМмЙЙЯТЗжВМЪНЪ§ОнВщбЏЕФЮЪЬтЁЃ
1.2.5 ЪТМўЧ§ЖЏМмЙЙгХШБЕу
ЪТМўЧ§ЖЏМмЙЙМШгагХЕувВгаШБЕуЃЌДЫМмЙЙПЩвдЪЕЯжПчЖрИіЗўЮёЕФЪТЮёЪЕЯжЃЌЧвЬсЙЉзюжеЪ§ОнвЛжТадЃЌВЂЧвЪЙЕУЗўЮёФмЙЛздЖЏЮЌЛЄВщбЏЪгЭМ;ЖјШБЕудкгкБрГЬФЃЪНБШДЋЭГЛљгкЪТЮёЕФНЛвзФЃЪНИќМгИДдгЃЌБиаыЪЕЯжВЙГЅЪТЮёвдБуДггІгУГЬађМЖЙЪеЯжаЛжИДЃЌР§ШчЃЌШчЙћаХгУМьВщВЛГЩЙІдђБиаыШЁЯћЖЉЕЅ;СэЭтЃЌгІгУБиаыгІЖдВЛвЛжТЕФЪ§ОнЃЌБШШчЕБгІгУЖСШЁЮДИќаТЕФзюжеЪгЭМЪБвВЛсгіМћЪ§ОнВЛвЛжТЮЪЬтЁЃСэЭтвЛИіШБЕудкгкЖЉдФепБиаыМьВтКЭКіТдШпгрЪТМўЃЌБмУтЪТМўжиИДЯћЗбЁЃ
1.3 змНс
дкЮЂЗўЮёМмЙЙжаЃЌУПИіЮЂЗўЮёЖМгаздМКЫНгаЕФЪ§ОнМЏЁЃВЛЭЌЮЂЗўЮёПЩФмЪЙгУВЛЭЌЕФSQLЛђепNoSQLЪ§ОнПтЁЃОЁЙмЪ§ОнПтМмЙЙгаКмЧПЕФгХЪЦЃЌЕЋЪЧвВУцЖдЪ§ОнЗжВМЪНЙмРэЕФЬєеНЁЃЕквЛИіЬєеНОЭЪЧШчКЮдкЖрЗўЮёжЎМфЮЌЛЄвЕЮёЪ§ОнвЛжТад;ЕкЖўИіЬєеНЪЧШчКЮДгЖрЗўЮёЛЗОГжаЛёШЁвЛжТадЪ§ОнЁЃ
зюМбНтОіАьЗЈЪЧВЩгУЪТМўЧ§ЖЏМмЙЙЁЃЦфжаХіЕНЕФвЛИіЬєеНЪЧШчКЮдзгадЕФИќаТзДЬЌКЭЗЂВМЪТМўЁЃгаМИжжЗНЗЈПЩвдНтОіДЫЮЪЬтЃЌАќРЈНЋЪ§ОнПтЪгЮЊЯћЯЂЖгСаКЭЪТМўдДЕШЁЃ
ДгФПЧАММЪѕгІгУЗЖЮЇКЭГЩЪьЖШПДЃЌЭЦМіЪЙгУЕквЛжжЗНЪН(БОЕиЪТЮёЗЂВМЪТМў)ЃЌРДЪЕЯжЪТМўЭЖЕндзгЛЏЃЌМДПЩППЪТМўЭЖЕнЁЃ
ашвЊЬсабЃК!!!Ъ§ОнвЛжТадЪЧЮЂЗўЮёМмЙЙЩшМЦжаЮЈПжБмжЎВЛМАШДгжВЛЕУВЛПМТЧЕФЛАЬтЁЃЭЈЙ§БЃжЄЪТМўЧ§ЖЏЪЕЯжзюжеЪ§ОнЕФвЛжТадЃЌДЫЗНАИЕФгХСгЃЌвВВЛФмМђЕЅЕФвЛбдЖјИХжЎЃЌЖјЪЧгІИУИљОнГЁОАЖЈЖсЃЌЪЪКЯЕФВХЪЧзюКУЕФЁЃСэЭтЃЌЮвУЧдкЖдЮЂЗўЮёНјаавЕЮёЛЎЗжЕФЪБКђОЭОЁПЩФмЕФБмУтЁАПЩФмЛсВњЩњвЛжТадЮЪЬтЁБЕФЩшМЦЁЃШчЙћетжжЩшМЦЙ§ЖрЃЌвВаэЪЧЪБКђПМТЧИФИФЩшМЦСЫЁЃ |









