|
еЊвЊЃКApache SparkЕФГіЯжШУЦеЭЈШЫвВОпБИСЫДѓЪ§ОнМАЪЕЪБЪ§ОнЗжЮіФмСІЁЃМјгкДЫЃЌБОЮФЭЈЙ§ЖЏЪжЪЕеНВйзїбнЪОДјСьДѓМвПьЫйЕиШыУХбЇЯАSparkЁЃБОЮФЪЧApache SparkШыУХЯЕСаНЬГЬЃЈЙВЫФВПЗжЃЉЕФЕквЛВПЗжЁЃ
ApacheSparkЕФГіЯжШУЦеЭЈШЫвВОпБИСЫДѓЪ§ОнМАЪЕЪБЪ§ОнЗжЮіФмСІЁЃМјгкДЫЃЌБОЮФЭЈЙ§ЖЏЪжЪЕеНВйзїбнЪОДјСьДѓМвПьЫйЕиШыУХбЇЯАSparkЁЃБОЮФЪЧApacheSparkШыУХЯЕСаНЬГЬЃЈЙВЫФВПЗжЃЉЕФЕквЛВПЗжЁЃ
ШЋЮФЙВАќРЈЫФИіВПЗжЃК
- ЕквЛВПЗжЃКSparkШыУХЃЌНщЩмШчКЮЪЙгУShellМАRDDs
- ЕкЖўВПЗжЃКНщЩмSparkSQLЁЂDataframesМАШчКЮНсКЯSparkгыCassandraвЛЦ№ЪЙгУ
- ЕкШ§ВПЗжЃКНщЩмSparkMLlibКЭSparkStreaming
- ЕкЫФВПЗжЃКНщЩмSparkGraphxЭММЦЫу
БОЦЊНВНтЕФБуЪЧЕквЛВПЗж ЙигкШЋВПеЊвЊКЭЬсИйВПЗжЃЌЧыЕЧТМЮвУЧЕФЭјеОApacheSparkQuickStartforreal-timedata-analyticsНјааЗУЮЪЁЃ дкЭјеОЩЯФуПЩвдевЕНИќЖретЗНУцЕФЮФеТКЭНЬГЬЃЌР§ШчЃКJavaReactiveMicroserviceTrainingЃЌMicroservicesArchitecture|ConsulServiceDiscoveryandHealthForMicroservicesArchitectureTutorialЁЃЛЙгаИќЖрЕФЦфЫќФкШнЃЌИааЫШЄЕФПЩвдШЅВщПДЁЃ
SparkИХЪі ApacheSparkЪЧвЛИіе§дкПьЫйГЩГЄЕФПЊдДМЏШКМЦЫуЯЕЭГЃЌе§дкПьЫйЕФГЩГЄЁЃApacheSparkЩњЬЌЯЕЭГжаЕФАќКЭПђМмШевцЗсИЛЃЌЪЙЕУSparkФмЙЛНјааИпМЖЪ§ОнЗжЮіЁЃApacheSparkЕФПьЫйГЩЙІЕУвцгкЫќЕФЧПДѓЙІФмКЭвзгкЪЙгУадЁЃЯрБШгкДЋЭГЕФMapReduceДѓЪ§ОнЗжЮіЃЌSparkаЇТЪИќИпЁЂдЫааЪБЫйЖШИќПьЁЃApacheSparkЬсЙЉСЫФкДцжаЕФЗжВМЪНМЦЫуФмСІЃЌОпгаJavaЁЂScalaЁЂPythonЁЂRЫФжжБрГЬгябдЕФAPIБрГЬНгПкЁЃSparkЩњЬЌЯЕЭГШчЯТЭМЫљЪОЃК
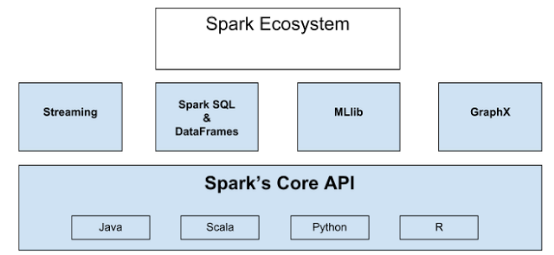
Display-Edit
ећИіЩњЬЌЯЕЭГЙЙНЈдкSparkФкКЫв§ЧцжЎЩЯЃЌФкКЫЪЙЕУSparkОпБИПьЫйЕФФкДцМЦЫуФмСІЃЌвВЪЙЕУЦфAPIжЇГжJavaЁЂScala,ЁЂPythonЁЂRЫФжжБрГЬгябдЁЃStreamingОпБИЪЕЪБСїЪ§ОнЕФДІРэФмСІЁЃSparkSQLЪЙЕУгУЛЇЪЙгУЫћУЧзюЩУГЄЕФгябдВщбЏНсЙЙЛЏЪ§ОнЃЌDataFrameЮЛгкSparkSQLЕФКЫаФЃЌDataFrameНЋЪ§ОнБЃДцЮЊааЕФМЏКЯЃЌЖдгІаажаЕФИїСаЖМБЛУќУћЃЌЭЈЙ§ЪЙгУDataFrameЃЌПЩвдЗЧГЃЗНБуЕиВщбЏЁЂЛцжЦКЭЙ§ТЫЪ§ОнЁЃMLlibЮЊSparkжаЕФЛњЦїбЇЯАПђМмЁЃGraphxЮЊЭММЦЫуПђМмЃЌЬсЙЉНсЙЙЛЏЪ§ОнЕФЭММЦЫуФмСІЁЃвдЩЯБуЪЧећИіЩњЬЌЯЕЭГЕФИХПіЁЃ
ApacheSparkЕФЗЂеЙРњЪЗ
- зюГѕгЩМгжнВЎПЫРћДѓбЇЃЈUCBerkeleyЃЉAMPlabЪЕбщЪвПЊЗЂВЂгк2010ФъПЊдДЃЌФПЧАвбОГЩЮЊАЂХСЦцШэМўЛљН№ЛсЃЈApacheSoftwareFoundationЃЉЕФЖЅМЖЯюФПЁЃ
- вбОга12,500ДЮДњТыЬсНЛЃЌетаЉЬсНЛРДзд630ИідДТыЙБЯзепЃЈВЮМћApacheSparkGithubrepoЃЉ
- ДѓВПЗжДњТыЪЙгУScalaгябдБраДЁЃ
- ApacheSparkЕФGoogleаЫШЄЫбЫїСПЃЈGooglesearchinterestsЃЉзюНќГЪОЎХчЪНЕФдіГЄЃЌетБэУїЦфЙизЂЖШжЎИпЃЈGoogleЙуИцДЪЙЄОпЯдЪОЃКНіЦпдТОЭгаЖрДя108,000ДЮЫбЫїЃЌБШMicroservicesЕФЫбЫїСПЖрЪЎБЖЃЉ
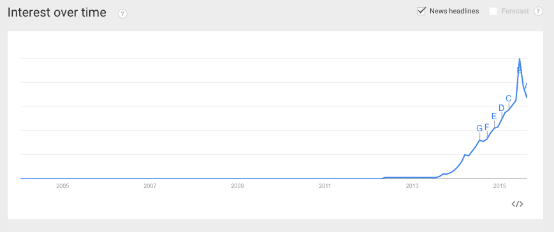
- ВПЗжSparkЕФдДТыЙБЯзепЃЈdistributorsЃЉЗжБ№РДздIBMЁЂOracleЁЂDataStaxЁЂBlueDataЁЂClouderaЁЁ
- ЙЙНЈдкSparkЩЯЕФгІгУАќРЈЃКQlikЁЂTalenЁЂTresataЁЂatscaleЁЂplatforaЁЁ
- ЪЙгУSparkЕФЙЋЫОгаЃКVerizon VerizonЁЂNBCЁЂYahooЁЂSpotifyЁЁ
ДѓМвЖдApacheSparkШчДЫИааЫШЄЕФдвђЪЧЫќЪЙЕУЦеЭЈЕФПЊЗЂОпБИHadoopЕФЪ§ОнДІРэФмСІЁЃНЯжЎгкHadoopЃЌSparkЕФМЏШКХфжУБШHadoopМЏШКЕФХфжУИќМђЕЅЃЌдЫааЫйЖШИќПьЧвИќШнвзБрГЬЁЃSparkЪЙЕУДѓЖрЪ§ЕФПЊЗЂШЫдБОпБИСЫДѓЪ§ОнКЭЪЕЪБЪ§ОнЗжЮіФмСІЁЃМјгкДЫЃЌМјгкДЫЃЌБОЮФЭЈЙ§ЖЏЪжЪЕеНВйзїбнЪОДјСьДѓМвПьЫйЕиШыУХбЇЯАApacheSparkЁЃ
ЯТдиSparkВЂКгбнЪОШчКЮЪЙгУНЛЛЅЪНShellУќСюаа ЖЏЪжЪЕбщApacheSparkЕФзюКУЗНЪНЪЧЪЙгУНЛЛЅЪНShellУќСюааЃЌSparkФПЧАгаPythonShellКЭScalaShellСНжжНЛЛЅЪНУќСюааЁЃ ПЩвдДгетРяЯТдиApacheSparkЃЌЯТдиЪБбЁдёзюНќдЄБрвыКУЕФАцБОвдБуФмЙЛСЂМДдЫааshellЁЃ ФПЧАзюаТЕФApacheSparkАцБОЪЧ1.5.0ЃЌЗЂВМЪБМфЪЧ2015Фъ9дТ9ШеЁЃ
tar -xvzf ~/spark-1.5.0-bin-hadoop2.4.tgz |
дЫааPythonShell
cd spark-1.5.0-bin-hadoop2.4 ./bin/pyspark |
дкБОНкжаВЛЛсЪЙгУPythonShellНјаабнЪОЁЃ ScalaНЛЛЅЪНУќСюаагЩгкдЫаадкJVMЩЯЃЌФмЙЛЪЙгУjavaПтЁЃ
дЫааScalaShell
cd spark-1.5.0-bin-hadoop2.4 ./bin/spark-shell |
жДааЭъЩЯЪіУќСюааЃЌФуПЩвдПДЕНЯТСаЪфГіЃК
ScalaShellЛЖгаХЯЂ
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.5.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_25)
Type in expressions to have them evaluated.
Type :help for more information.
15/08/24 21:58:29 INFO SparkContext: Running Spark version 1.5.0 |
ЯТУцЪЧвЛаЉМђЕЅЕФСЗЯАвдБуАяжњЪЙгУshellЁЃвВаэФуЯждкВЛФмРэНтЮвУЧзіЕФЪЧЪВУДЃЌЕЋдкКѓУцЮвУЧЛсЖдДЫНјааЯъЯИЗжЮіЁЃдкScalaShellжаЃЌжДааЯТСаВйзїЃК
дкSparkжаЪЙгУREADMEЮФМўДДНЈtextFileRDD
val textFile = sc.textFile("README.md") |
ЛёШЁtextFileRDDЕФЕквЛИідЊЫи
textFile.first()
res3: String = # Apache Spark |
ЖдtextFileRDDжаЕФЪ§ОнНјааЙ§ТЫВйзїЃЌЗЕЛиЫљгаАќКЌЁАSparkЁБЙиМќзжЕФааЃЌВйзїЭъГЩКѓЛсЗЕЛивЛИіаТЕФRDDЃЌВйзїЭъГЩКѓПЩвдЖдЗЕЛиЕФRDDЕФааНјааМЦЪ§ ЩИбЁГіАќРЈSparkЙиМќзжЕФRDDШЛКѓНјааааМЦЪ§
val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark.count()
res10: Long = 19 |
вЊевГіRDDlinesWithSparkЕЅДЪГіЯжзюЖрЕФааЃЌПЩвдЪЙгУЯТСаВйзїЁЃЪЙгУmapЗНЗЈЃЌНЋRDDжаЕФИїаагГЩфГЩвЛИіЪ§ЃЌШЛКѓдйЪЙгУreduceЗНЗЈевГіАќКЌЕЅДЪЪ§зюЖрЕФааЁЃ евГіRDDtextFileжаАќКЌЕЅДЪЪ§зюЖрЕФаа
textFile.map(line => line.split(" ").size)
.reduce((a, b) => if (a > b) a else b)
res11: Int = 14 |
ЗЕЛиНсЙћБэУїЕк14ааЕЅДЪЪ§зюЖрЁЃ вВПЩвдв§ШыЦфЫќjavaАќЃЌР§ШчMath.max()ЗНЗЈЃЌвђЮЊmapКЭreduceЗНЗЈНгЪмscalaКЏЪ§зжУцСПзїЮЊВЮЪ§ЁЃ дкscalashellжав§ШыJavaЗНЗЈ
import java.lang.Math
textFile.map(line => line.split(" ").size)
.reduce((a, b) => Math.max(a, b))
res12: Int = 14 |
ЮвУЧПЩвдКмШнвзЕиНЋЪ§ОнЛКДцЕНФкДцЕБжаЁЃ НЋRDDlinesWithSparkЛКДцЃЌШЛКѓНјааааМЦЪ§
linesWithSpark.cache()
res13: linesWithSpark.type =
MapPartitionsRDD[8] at filter at <console>:23
linesWithSpark.count()
res15: Long = 19 |
ЩЯУцМђвЊЕиИјДѓМвбнЪОЕФСЫШчКЮЪЙгУSparkНЛЛЅЪНУќСюааЁЃ
ЕЏадЗжВМЪНЪ§ОнМЏЃЈRDDsЃЉ SparkдкМЏШКжаПЩвдВЂааЕижДааШЮЮёЃЌВЂааЖШгЩSparkжаЕФжївЊзщМўжЎвЛЁЊЁЊRDDОіЖЈЁЃЕЏадЗжВМЪНЪ§ОнМЏ(Resilientdistributeddata,RDD)ЪЧвЛжжЪ§ОнБэЪОЗНЪНЃЌRDDжаЕФЪ§ОнБЛЗжЧјДцДЂдкМЏШКжаЃЈЫщЦЌЛЏЕФЪ§ОнДцДЂЗНЪНЃЉЃЌе§ЪЧгЩгкЪ§ОнЕФЗжЧјДцДЂЪЙЕУШЮЮёПЩвдВЂаажДааЁЃЗжЧјЪ§СПдНЖрЃЌВЂаадНИпЁЃЯТЭМИјГіСЫRDDЕФБэЪОЃК

Display-Edit
ЯыЯёУПСаОљЮЊвЛИіЗжЧјЃЈpartitionЃЉЃЌФуПЩвдЗЧГЃЗНБуЕиНЋЗжЧјЪ§ОнЗжХфИјМЏШКжаЕФИїИіНкЕуЁЃ ЮЊДДНЈRDDЃЌПЩвдДгЭтВПДцДЂжаЖСШЁЪ§ОнЃЌР§ШчДгCassandraЁЂAmazonМђЕЅДцДЂЗўЮёЃЈAmazonSimpleStorageServiceЃЉЁЂHDFSЛђЦфЫќHadoopжЇГжЕФЪфШыЪ§ОнИёЪНжаЖСШЁЁЃвВПЩвдЭЈЙ§ЖСШЁЮФМўЁЂЪ§зщЛђJSONИёЪНЕФЪ§ОнРДДДНЈRDDЁЃСэвЛЗНУцЃЌШчЙћЖдгкгІгУРДЫЕЃЌЪ§ОнЪЧБОЕиЛЏЕФЃЌДЫЪБФуНіашвЊЪЙгУparallelizeЗНЗЈБуПЩвдНЋSparkЕФЬиадзїгУгкЯргІЪ§ОнЃЌВЂЭЈЙ§ApacheSparkМЏШКЖдЪ§ОнНјааВЂааЛЏЗжЮіЁЃЮЊбщжЄетвЛЕуЃЌЮвУЧЪЙгУScalaSparkShellНјаабнЪОЃК ЭЈЙ§ЕЅДЪСаБэМЏКЯДДНЈRDDthingsRDD
val thingsRDD = sc.parallelize(List("spoon", "fork", "plate", "cup", "bottle"))
thingsRDD: org.apache.spark.rdd.RDD[String] =
ParallelCollectionRDD[11] at parallelize at <console>:24 |
МЦЫуRDDthingsRDDжаЕЅЕФИіЪ§
thingsRDD.count()
res16: Long = 5 |
дЫааSparkЪБЃЌашвЊДДНЈSparkContextЁЃЪЙгУSparkShellНЛЛЅЪНУќСюааЪБЃЌSparkContextЛсздЖЏДДНЈЁЃЕБЕїгУSparkContextЖдЯѓЕФparallelizeЗНЗЈКѓЃЌЮвУЧЛсЕУЕНвЛИіОЙ§ЗжЧјЕФRDDЃЌетаЉЪ§ОнНЋБЛЗжЗЂЕНМЏШКЕФИїИіНкЕуЩЯЁЃ
ЪЙгУRDDЮвУЧФмЙЛзіЪВУДЃП ЖдRDDЃЌМШПЩвдНјааЪ§ОнзЊЛЛЃЌвВПЩвдЖдНјааactionВйзїЁЃетвтЮЖзХЪЙгУtransformationПЩвдИФБфЪ§ОнИёЪНЁЂНјааЪ§ОнВщбЏЛђЪ§ОнЙ§ТЫВйзїЕШЃЌЪЙгУactionВйзїЃЌПЩвдДЅЗЂЪ§ОнЕФИФБфЁЂГщШЁЪ§ОнЁЂЪеМЏЪ§ОнЩѕжСНјааМЦЪ§ЁЃ Р§ШчЃЌЮвУЧПЩвдЪЙгУSparkжаЕФЮФБОЮФМўREADME.mdДДНЈвЛИіRDDtextFileЃЌЮФМўжаАќКЌСЫШєИЩЮФБОааЃЌНЋИУЮФБОЮФМўЖСШыRDDtextFileЪБЃЌЦфжаЕФЮФБОааЪ§ОнНЋБЛЗжЧјвдБуФмЙЛЗжЗЂЕНМЏШКжаВЂБЛВЂааЛЏВйзїЁЃ ИљОнREADME.mdЮФМўДДНЈRDDtextFile
val textFile = sc.textFile("README.md") |
ааМЦЪ§
textFile.count()
res17: Long = 98 |
README.md ЮФМўжага98ааЪ§ОнЁЃ ЕУЕНЕФНсЙћШчЯТЭМЫљЪОЃК

Display-Edit
ШЛКѓЃЌЮвУЧПЩвдНЋЫљгаАќКЌSparkЙиМќзжЕФааЩИбЁГіРДЃЌЭъГЩВйзїКѓЛсЩњГЩвЛИіаТЕФRDDlinesWithSparkЃК ДДНЈвЛИіЙ§ТЫКѓЕФRDDlinesWithSpark
val linesWithSpark = textFile.filter(line => line.contains("Spark")) |
дкЧАвЛЗљЭМжаЃЌЮвУЧИјГіСЫtextFileRDDЕФБэЪОЃЌЯТУцЕФЭМЮЊRDDlinesWithSparkЕФБэЪОЃК

Display-Edit
жЕЕУзЂвтЕФЪЧЃЌSparkЛЙДцдкМќжЕЖдRDDЃЈPairRDDЃЉЃЌетжжRDDЕФЪ§ОнИёЪНЮЊМќ/жЕЖдЪ§ОнЃЈkey/valuepaireddataЃЉЁЃР§ШчЯТБэжаЕФЪ§ОнЃЌЫќБэЪОЫЎЙћгыбеЩЋЕФЖдгІЙиЯЕЃК
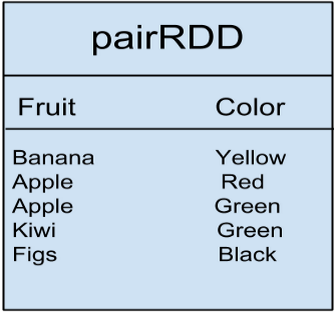
Display-Edit
ЖдБэжаЕФЪ§ОнЪЙгУgroupByKey()зЊЛЛВйзїНЋЕУЕНЯТСаНсЙћЃК groupByKey()зЊЛЛВйзї
pairRDD.groupByKey()
Banana [Yellow]
Apple [Red, Green]
Kiwi [Green]
Figs [Black] |
ИУзЊЛЛВйзїжЛНЋМќЮЊAppleЃЌжЕЮЊRedКЭGreenЕФЪ§ОнНјааСЫЗжзщЁЃетаЉЪЧЕНФПЧАЮЊжЙИјГіЕФзЊЛЛВйзїР§згЁЃ ЕБЕУЕНвЛИіОЙ§Й§ТЫВйзїКѓЕФRDDЃЌПЩвдcollect/materializeЯргІЕФЪ§ОнВЂЪЙЦфСїЯђгІгУГЬађЃЌетЪЧactionВйзїЕФР§згЁЃОЙ§ДЫВйзїКѓЃЌRDDжаЫљгаЪ§ОнНЋЯћЪЇЃЌЕЋЮвУЧШдШЛПЩвддкRDDЕФЪ§ОнЩЯНјааФГаЉВйзїЃЌвђЮЊЫќУЧШдШЛдкФкДцЕБжаЁЃ CollectЛђmaterializelinesWithSparkRDDжаЕФЪ§Он
жЕЕУвЛЬсЕФЪЧУПДЮНјааSparkactionВйзїЪБЃЌР§Шчcount()actionВйзїЃЌSparkНЋжиаТЦєЖЏЫљгаЕФзЊЛЛВйзїЃЌМЦЫуНЋдЫааЕНзюКѓвЛИізЊЛЛВйзїЃЌШЛКѓcountВйзїЗЕЛиМЦЫуНсЙћЃЌетжждЫааЗНЪНЫйЖШЛсНЯТ§ЁЃЮЊНтОіИУЮЪЬтКЭЬсИпГЬађдЫааЫйЖШЃЌПЩвдНЋRDDЕФЪ§ОнЛКДцЕНФкДцЕБжаЃЌетжжЗНЪНЕФЛАЃЌЕБФуЗДИДдЫааactionВйзїЪБЃЌФмЙЛБмУтУПДЮМЦЫуЖМДгЭЗПЊЪМЃЌжБНгДгЛКДцЕНФкДцжаЕФRDDЕУЕНЯргІЕФНсЙћЁЃ ЛКДцRDDlinesWithSpark
ШчЙћФуЯыНЋRDDlinesWithSparkДгЛКДцжаЧхГ§ЃЌПЩвдЪЙгУunpersist()ЗНЗЈЁЃ
НЋlinesWithSparkДгФкДцжаЩОГ§
linesWithSpark.unpersist() |
ШчЙћВЛЪжЖЏЩОГ§ЕФЛАЃЌдкФкДцПеМфНєеХЕФЧщПіЯТЃЌSparkЛсВЩгУзюНќзюОУЮДЪЙгУЃЈleastrecentlyusedlogicЃЌLRU)ЕїЖШЫуЗЈЩОГ§ЛКДцдкФкДцжазюОУЕФRDDЁЃ ЯТУцзмНсвЛЯТSparkДгПЊЪМЕННсЙћЕФдЫааЙ§ГЬЃК
- ДДНЈФГжжЪ§ОнРраЭЕФRDD
- ЖдRDDжаЕФЪ§ОнНјаазЊЛЛВйзїЃЌР§ШчЙ§ТЫВйзї
- дкашвЊжигУЕФЧщПіЯТЃЌЖдзЊЛЛКѓЛђЙ§ТЫКѓЕФRDDНјааЛКДц
- дкRDDЩЯНјааactionВйзїЃЌР§ШчЬсШЁЪ§ОнЁЂМЦЪ§ЁЂДцДЂЪ§ОнЕНCassandraЕШЁЃ
ЯТУцИјГіЕФЪЧRDDЕФВПЗжзЊЛЛВйзїЧхЕЅЃК
- filter()
- map()
- sample()
- union()
- groupbykey()
- sortbykey()
- combineByKey()
- subtractByKey()
- mapValues()
- Keys()
- Values()
ЯТУцИјГіЕФЪЧRDDЕФВПЗжactionВйзїЧхЕЅЃК
- collect()
- count()
- first()
- countbykey()
- saveAsTextFile()
- reduce()
- take(n)
- countBykey()
- collectAsMap()
- lookup(key)
ЙигкRDDЫљгаЕФВйзїЧхЕЅКЭУшЪіЃЌПЩвдВЮПМSparkdocumentation
НсЪјгя БОЮФНщЩмСЫApacheSparkЃЌвЛИіе§дкПьЫйГЩГЄЁЂПЊдДЕФМЏШКМЦЫуЯЕЭГЁЃЮвУЧИјДѓМвеЙЪОСЫВПЗжФмЙЛНјааИпМЖЪ§ОнЗжЮіЕФApacheSparkПтКЭПђМмЁЃЖдApacheSparkЮЊЪВУДЛсШчДЫГЩЙІЕФдвђНјааСЫМђвЊЗжЮіЃЌОпЬхБэЯжЮЊApacheSparkЕФЧПДѓЙІФмКЭвзгУадЁЃИјДѓМвбнЪОСЫApacheSparkЬсЙЉЕФФкДцЁЂЗжВМЪНМЦЫуЛЗОГЃЌВЂбнЪОСЫЦфвзгУадМАвзеЦЮеадЁЃ дкБОЯЕСаНЬГЬЕФЕкЖўВПЗжЃЌЮвУЧЖдSparkНјааИќЩюШыЕФНщЩмЁЃ
|


