| UML软件工程组织 | |||
| |
|||
|
|||
数据挖掘结果契合度的评测方法探索
2008-04-16 出处:网络
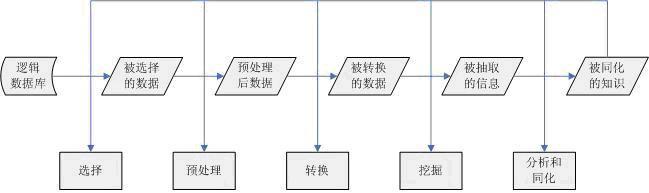
| 数据挖掘(Data Mining)是从海量的随机的实际应用数据中,提取隐含在其中的潜在有用的信息和知识的过程。随着数据挖掘在计算机系统中越来越广泛地运用,对其运算的结果契合度评测势必日益收到重视。本文通过对数据挖掘过程阶段的分析入手,探讨了对评测其结果契合度的一些体会。 1 数据挖掘过程概述 随着数据库技术的迅速发展以及数据库管理系统的广泛应用,人们积累的数据越来越多。激增的数据背后隐藏着许多重要的信息,人们希望能够对其进行更高层次的分析,以便更好地利用这些数据。数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。完整的数据挖掘过程中各步骤的大体内容如下: 1) 确定业务对象 清晰地定义出业务问题,认清数据挖掘的目的是数据挖掘的重要一步.挖掘的最后结构是不可预测的,但要探索的问题应是有预见的,为了数据挖掘而数据挖掘则带有盲目性,是不会成功的。 2) 数据准备 数据的选择。搜索所有与业务对象有关的内部和外部数据信息,并从中选择出适用于数据挖掘应用的数据。 数据的预处理。研究数据的质量,为进一步的分析作准备.并确定将要进行的挖掘操作的类型。 数据的转换。将数据转换成一个分析模型,这个分析模型是针对挖掘算法建立的.建立一个真正适合挖掘算法的分析模型是数据挖掘成功的关键。 3) 数据挖掘 对所得到的经过转换的数据进行挖掘.除了完善从选择合适的挖掘算法外,其余一切工作都能自动地完成。 4) 结果分析 解释并评估结果.其使用的分析方法一般应作数据挖掘操作而定,通常会用到可视化技术。 5) 知识的同化 将分析所得到的知识集成到业务信息系统的组织结构中去。如下图所示:
图:数据挖掘过程的步骤 2 评测的要点与难点 从数据挖掘的几个阶段来看,每个阶段对算法的依赖程度不一。对于确定业务对象和数据准备中的数据选择阶段,基本是以人工方式作出规范,为下面数据准备另两个阶段和数据挖掘应用阶段提供分析对象。而在最后的结果分析和知识同化阶段,则通常是在系统将挖掘的结果以可视化形式呈现给用户后,由用户再次以主观方式进行再分析与再分类,为下一次的数据挖掘提供修正,以使整个挖掘系统更强壮。由此可见,评测人员最关注的阶段,集中在对数据准备后两个阶段和数据挖掘结果的评测上。由于数据准备的结果会直接运行在数据挖掘阶段,我们又可以进一步把评测的核心集中在对数据挖掘结果契合度的评测上。 契合度评测,就是数据挖掘算法的结果与实际情况,或者说是与用户希望的结果的吻合程度。与传统的数据分析(如查询、报表、联机应用分析)相比,数据挖掘与其本质的区别在于数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。换言之,数据挖掘作为一种人工智能的手段,其结果带有系统本身的“主观色彩”,又没有一个完全正确的预先的分析结果可以作为依据与数据挖掘的结果进行比较,以计算挖掘结果的契合度,同时也没有任何仪器可以倚仗,这可能就是契合度评测的难点所在。 3 评测方法初探 如上文所述,事先并没有一个客观公正的数据处理结果是我们可以用来与数据挖掘结果做比较的,所以作为评判依据的,必然得是由人工的主观评测得到的正确结果。这是因为,否则假设我们有一套预知的正确的结果来自另外一套自动化的挖掘算法,我们就必须对这另一套挖掘算法的结果契合度进行评估。而要对它进行评估,我们就需要第三套挖掘算法……这时,我们就陷入了鸡生蛋,蛋生鸡的逻辑怪圈。 而么用人工的主观评测结果来做比较对象是否就可以呢?答案通常还是否定的。对于一个实际应用的数据挖掘系统来说,通常其处理的数据是海量的,如果完全对所有数据进行人工的分析统计,其工作量是巨大的,通常是测试部门难以承受的。而且人工分析统计带有主观色彩,不同的测试人员的分析结果很可能因人而异,这就会对评测结果的客观性和公正性产生影响。所以,除非是面对足够小的数据量和拥有足够多的测试人力资源,人工分析结果的比对测试是很困难的。 但是,如果据此就认为数据挖掘结果的契合度无法评测的,这种观点也是不正确的。如果把注意力从契合度评测的阶段抽出,将会发现之前的确定业务对象和数据选择阶段才是 真正应该关注的地方。测试人员应该评测的是整个系统的挖掘结果准确度,而不是某一次挖掘结果效果如何。与其用巨大的人力资源去评测某一次的挖掘结果,不如从一开始就人工设计测试数据。这是因为:首先,自己设计数据的工作量要小于分析实际的随机离散数据,不用设计大量的重复性数据;其次,人工设计的数据更有针对性,不必劳神于判别一些模棱两可的边缘数据,使结果相对更客观。 所以,对于挖掘结果的契合度测试,应该从直接人工分析挖掘结果的泥沼中抽身出来,直接着眼于设计测试数据,将整个数据库作为测试用例,设计出一个结果比较客观的数据库供挖掘系统分析,再将挖掘系统自动生成的结果与设计数据时得到的预先结果进行对比.这样得到的评测结果是针对整个系统的挖掘结果契合度,这胜过对某一次挖掘结果的契合度的评测。 4 评测实例分析与总结 具体将这种思想运用到实践中来,不妨以测试案例作为分析对象。在年中的某一次测试中,客户开发的某系统运用数据挖掘算法,对几千条新闻数据进行采集和分析,并将新闻数据按关键词分为不同的主题,再将新闻按主题分别列出。但是特殊之处在于系统的数据源不可以自行控制,只能进行人工的局部修改。而客户要求我们对整个系统的结果契合度都进行评价。 因此,在分析整个数据关系后,我们将契合度评价的指标列出两个:
在实际测试过程中,我们也审时度势,针对无法控制数据源的客观情况,对测试方法做了调整。 对于主题信息完全度,我们采用修改数据的方法,而不是人工查看所有中是否含有某个主题,那是不现实的。首先我们找到几个在测试当前的数据库中没有的冷僻词条作为关键词,在若干条新闻中穿插地插入这些词条。然后交给系统分析,计算系统得出的该关键词的主题中含有已修改的新闻的数量,再除以总的修改新闻数,这个比率就是主题信息完全度。 对于关键词契合度,最科学的方法应该是完全采用自定制的数据库,将系统测试结果与预设数据的结果进行比对。但是受限于数据源无法控制,我们采用了最直接的人工分析挖掘结果的方法。虽然比较辛苦,而且要力求客观,但好在这个数据库的规模在人工可以承受的范围内。将系统生成结果与人工分析的结果相比,得出的就是关键词契合度。 总结这次测试任务,我们得出了本文的主题结论:在对数据挖掘结果的契合度进行评测时,最好能够自己设计测试数据,将整个数据库作为测试用例进行设计,再将系统自动生成的结果与预设数据的结果进行比较。当受制于数据无法控制时,再考虑与人工分析数据进行比较的方法,但一定要注意力求客观,亦不失为一个务实有效的测试方法。 |
组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |