| 2)、聚合关联(Aggregation Association)
聚合关联描述的是由低层次的概念类型组成高层次的实体类型。其组成类用作描述实体的属性域。聚合关联实际是属性的归类或聚合,故称为聚合关联,由A(Aggregation)表示。A关联的成员称为实体事件。
(1) 结构特性
聚合类型表示由组成概念类型集合的叉积形成的概念集合。每个聚合事件是叉积的一个成员。
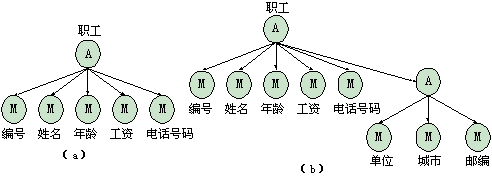
与成员关联不同,在聚合关联类型中包括的组成概念类型可以是成员关联形成的属性类型,或者是由其他的聚合关联形成的实体类型,以及由其他关联类型形成的属性类型。因此,聚合关联可以构造聚合关联层次,用于描述数据库的层次结构。例如(图3-12),职工的属性类型有职工编号、姓名、年龄、工资、工作单位和电话号码。其中职工编号是职工的唯一标识。每个职工对象是所包含的属性类型叉积的一个成员。职工的属性类型可以是不同的数据类型。例如,职工的电话号码可以是一个集合。而职工在最近10年工作过的单位是由一个聚合关联形成的实体集合。该实体本身是非原子类型,用以描述职工的特性。
图 3-12 聚合关联
(2) 操作特性
在聚合关联中,由于实体概念是由其他组成概念来描述的,对一个聚合关联事件的操作是增加、删除、更新和提取其组成概念。对非关键字的组成概念可以是空值。在聚合关联层次中增加或删除实体事件应遵循存在性约束。
聚合类型事件的集合服从于集合操作和关系操作,如选择、连接、投影等操作。增加组成概念类型的操作也是合理的、有意义的。
(3) 语义约束
首先是存在性约束。在聚合关联层次中实体事件的存在依赖于实体双亲的存在。就是说,除根结点以外,所有其他结点的数据都必须有引用它们的双亲。根结点称为独立的实体类型,孩子结点称为非独立的实体类型。
其次是关键字约束。就是说在定义实体类型的组成概念中,总存在某些概念的值是唯一标识该实体事件的。例如,职工的编号。当构成聚合关联的概念不是成员关联类型时,可能有重复事件出现,必须使用选项MULTIPLE说明。例如,一个职工在最近10年中的工作单位由三部分组成。假如职工不是每年换一个单位工作,就会有重复事件。有重复事件在图中用双箭头表示。对于成员类型,不必使用选项MULTIPLE指定,可以定义该成员类型为复杂数据类型的集合。因此,在一个聚合关联事件中可包含原子概念的集合。
3)、概括关联(Generalization Association)
把组成概念类型的共同特性进行概括、抽象成更一般的概念,称为概括类型。概括关联体现了共性与个性之间的语义关系。形成概括类型的所有组成概念的联合构成全体概括事件。概括类型要包含组成它的所有概念类型的共同特性,称为超级类型。组成它的成分类型称为子类型。子类型要继承超类型的所有属性。概括关联由G(Generalization)表示。
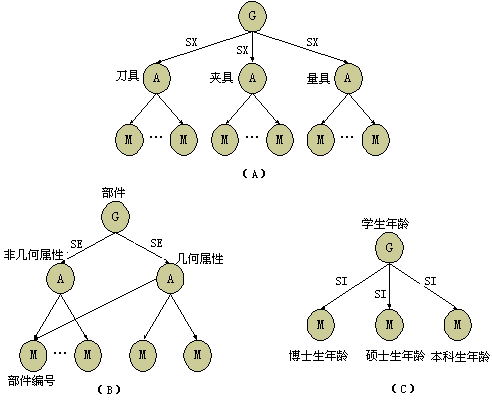
图3-13说明概括关联的例子。图4-13a由三个实体类型形成:加工工具包括刀具、量具和夹具。图4-13b是由部件的几何和非几何属性组成的概括层次。图4-13c是学生年龄的概括。
图 3-13 概括关联
(1) 结构特性
概括类型的事件是通过联合(Union)组成它的概念类型事件。子类型只能是实体类型,而且可以形成G关联层次,即一个超类又可以是另一个G关联的组成对象类,这种嵌套关系称为概括层次。一个子类同时可以有多个超类。
形成概括关联的 n(n>l)个概念可以由相同的或不同的概念类型的集合定义。
(2) 操作特性
在提取和存储操作中,假如引用了一个概括类型的事件,要搜索和操纵所有的概括事件,它们是概括层次中子类型成员的联合。搜索条件可以是不同的属性类型。可以提取和操纵在不同的属性类型上定义的事件。在单个事件或事件集合上的操纵依赖于形成Union的关联类型。
(3) 语义约束
概括关联的子类型之间有四种类型的约束:
- 集合互斥约束(SX)
- 集合相等约束(SE)
- 集合相交约束(SI)
- 集合一子集合约束(SS)。
前面的三个约束指出组成G关联的对象集合之间的约束关系。集合一子集合约束是指超类和子类集合之间的约束关系。通常在图中的有向边上标出子集合的语义约束符号。这四种类型约束的含义:
1) 集合互斥SX:指一个子类型的事件不能是多个子类型的成员,即在一个子类型中出现的对象不能在另一个子类型对象集合中出现。子类型的对象集合是互斥的。如图3-18a所示。
2) 集合相等SE:在一个子类型对象集合中出现的对象,也必须在另一个子类型的对象集合中出现,反之亦然。捕捉的语义是相同对象的不同观察点集合。如图3-18b所示。
3) 集合相交SI:子类型的对象集合相交,即一个子类型中的对象可以存在于另一个子类型的对象集合中,也可以不存在其中。两个子类型的对象集合是相交关系。如图3-18b所示。
4) 集合一子集合SS:描述超类和子类集合之间的关系。当超类的对象集合是其子类对象集合的并集时,即超类中的每个对象至少存在于它的一个子类的对象集合中,如图3-18a所示。在插人和删除操作中必须严格地维持集合一子集合的关系。
4)、交互关联(Interaction Association)
交互关联是描述两个或两个以上的实体类型之间的相互作用或联系。独立的实体类型组成所描述的事件或事实集合,该集合是这些独立实体类型中的对象相互作用的结果。所描述的事件或事实的命名集合称为关系类型,而事实称为关系事件。交互关联用I(Interaction)表示。
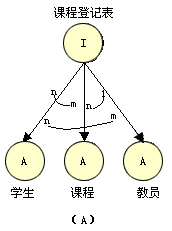
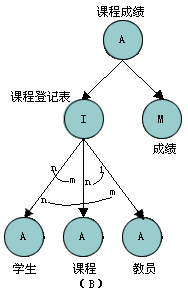
图3-14说明学生、课程和教员三种实体类型相互关联形成的关系类型"课程登记表"。在每一对实体类型之间映射为一对一、一对多和多对多的关系。而"成绩"和"课程登记表"构成一个A关联。其中"课程登记表"是唯一的标识。
图 3-14 交互关联
(1) 结构特性
交互关联的组成对象类只能是两个或两个以上的实体类。其组成对象类可以是I关联、A关联或G关联类型。
(2) 操作特性
一个关系事件与两个或两个以上的组成概念事件相关。因此,对关系事件的操作可以有连接(插入)或分离(删除)两个概念事件。通过指定部分或全部组成概念类型事件的唯一标识可以提取一个关系类型的事件。在一个数据库中关系事件的集合如同实体对象集合一样遵循一般的集合、关系和存储操作。
(3) 语义约束
每个关系事件必须是唯一的。一个关系类型的唯一标识可以由组成概念类型的唯一标识来形成。当数据库中存在一个关系事件时,定义该关系事件的概念类型的事件也必须存在于该数据库中,称为引用约束。
两个概念类型的事件之间的映射关系是一对一、一对多和多对多约束。例如,一个教员教多个学生,一个学生听多个教员的授课,在学生和教员之间构成多对多关系。一个教员可教多门课,但一门课只能由一个教员教,表示一对多的关系。
聚合关联和交互关联的主要区别是:交互关联是描述两个或多个独立的实体类型之间 的联系,并且要遵循交互关联的所有约束和操作。交互关联实体类的属性不能为空值。例如,
没有学生的课表是没有意义的。聚合关联描述的是实体类型的独立属性的聚合和归类,而属 性实体类型没有独立的状态,但在数据库中这类属性可以为空值,因为属性之间没有联系。
5)、组合关联(Composition Association)
组合关联是用不同的对象类来组成一个更大的描述对象类。组合关联类型和其成分关联类型之间的关系是整体与部分的关系。组合类型的一个单个事件是其各成分概念事件集合的集合,就是把集合的集合作为一个单个实体。组合关联由C(Composition)来表示。
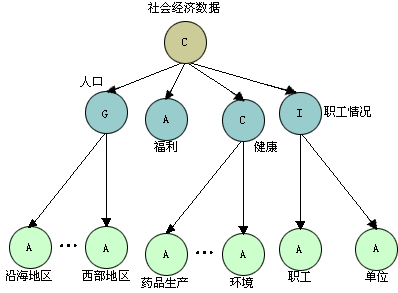
构成组合关联类型的成分概念可以是不同的关联类型。因而可以形成组合关联的层次。组合关联是用于统计分析的(图3-15),图中的社会经济数据由人口、福利、健康、职工情况四类数据组成。其中健康数据是社会经济数据的组成概念类,它是由药品生产和环境等各种数据构成的组合关联类型。福利情况是A关联类型,人口情况是不同地区人口的概括关联类型,职工情况是职工和单位的交互关联类型。
图 3-15 组合关联
(1) 结构特性
组合关联的组成概念类型只能是实体类型。在一个数据库中的任何给定时刻,一个组合类型包含一个单个事件。这个事件的结构是n个集合(S1,S2,…Sn)的集合。N是组成概念类型的数目。
组合通常用于把由不同的概念组成的集合体作为单个实体处理。而且一个组合关联可把任何关联类型的结点作为他的组成概念类型,也可以包括其他的组合关联类型。因此,可把不同的数据库的集合体连接成一个C结点,构成网状数据库。
组合关联与其它关联的不同:
组合关联不同于概括关联。组合关联类型和组成它的成分类型之间的语义是整体与部分的关系。而概括关联与组成它的类型之间的语义"IS_A"的关系,是一般与特殊的关系。后者的组成类(子类)可以继承它的超类的属性、操作和约束。组合关联的结构是集合的集合,概括类型的结构是集合的联合(Union)。不同的语义和结构导致二者具有不同的约束和操作。
组合关联也不同于聚合关联。组合关联的组成概念类型是组合实体的构成部分,而聚合关联的组成概念类型是聚合实体的属性。前者的结构是集合的集合,后者的结构是集合的叉积。
(2) 操作特性
对组合类型的输出操作和查找操作会引起输出和查找它的所有成分数据。从语义的观点看,输出的顺序并不重要,可以由格式化的规范来控制。搜索成分概念的顺序也是无关重要的。同时,在对组成概念类型的操作和约束有控制的基础上可访问和操纵任何组成概念类型数据。
(3) 语义约束
组合关联只有组成成分互斥约束。它的组成对象类的对象集合是互斥的。
6)、叉积关联(Cross-product Association)
把概念类型分组形成另外的概念类型,新概念类型的事件是组成概念类型事件叉积的结果。这结果的概念类型称为叉积类型,其成员称为叉积事件。这种关联类型在统计数据库中是非常有用的。叉积关联中包含的属性类型在统计领域称为分类属性。叉积关联由X表示。
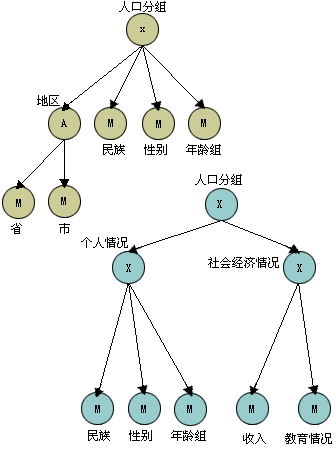
图3-16a 给出叉积的例子。图中省和市形成地区的集合,人口的分组情况是地区、民族、性别和年龄组的叉积。每组人口都是由省、市确定的地区以及民族、性别和年龄组标识的。例如,江苏省、南京市、回族、男性、年龄在18~50岁的人口与湖北省、武汉市、回族、男性、年龄在18~50岁的人口是相同分类的两个不同成员事件。
图3-16b 说明叉积层次。它说明人口分组是由个人情况和社会经济情况定义的事件集合进行叉积构成的实体集合。
图3-16 叉积关联
(1) 结构特性
与聚合关联类似,叉积类型的结构是所有成分概念类型事件的叉积。每个叉积事件是叉积的成员组成的一个集合。而且每个叉积事件由所有组成概念类型事件的组合唯一地标识。叉积关联不同与聚合关联,它是聚合关联的一种特殊情况。因为聚合关联事件由组成概念类型的一个子集或整个集合唯一地标识。
一个叉积类型的每个事件都定义了一个实体集合,并且服从于总计关联。集合关联只定义一个单个实体,因而不服从于总计关联。
(2) 操作特性
在事件级,允许更新和提取部分或整个事件。删除和增加成分概念类型完全不同于删除和增加聚合类型中成分的意义。这是因为由成分概念类型的叉积形成的对象集合随着删除和增加成分概念类型而被改变。例如,图3-16中的人口分布,假如删除年龄组,则必须用地区、民族和性别重新划分人口分布组,有关的各种统计(Counts)要重新计算,这种操作称为聚合(aggregation)。要增加一个成分概念类型,也需要重新划分组和重新统计,这种操作称为分散(disaggregation)。在叉积关联中,统计的聚合和分散这两种操作是很有用的。
叉积类型的事件可根据某些属性类型的值进行聚合或分散产生其他的叉积类型。例如,人口可按地区、民族、性别情况分组产生其他的叉积类型。
在不改变叉积类型语义的情况下,可以改变叉积事件的属性顺序。而且可以按某个属性值进行排序,把某个属性值作为主关键字。
(3) 语义约束
成分概念类型进行叉积的所有成员都包含在一个叉积类型的合法事件中。而且在某个时间,数据库中可以不包含叉积的全部成员。例如,在A省B市、某个民族没有95~100岁的男人,该成员可不存在。由于叉积类型的事件是由所有的成分概念类型形成组合的标识符,所以,任一成分概念类型的值不能是空值。这点又不同于聚合关联。
7)、总计关联(Summarization Association)
概念(IC,S1,S2,…,Sm)的一个集合可以分组形成一个命名为总计类型的概念,其中IC是指概念类型X或C,它的事件是对象的一个集合,而S1,S2,…,Sm是总计或表征该集合的属性。总计类型的每个事件说明对象的一个集合以及该集合的m(m>=0)个属性值。零个属性值表示统计属性被删除了或者还没有输入到数据库中。总计属性的值通常是可测量的数据,在这些数据上实现统计分析。总计关联由S(Summarization)表示。
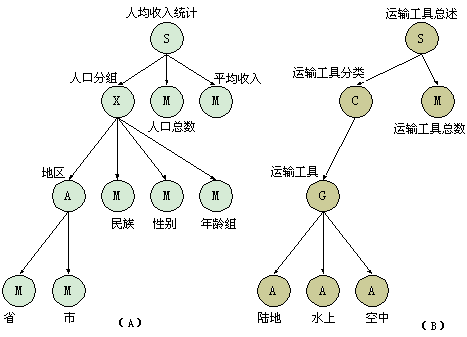
图3-17a 表示人口总计的例子。其中每组人口的人口总数和平均收人称为总计属性。图中的人均收人统计表示事件的一个集合,集合中的每个事件是由一个人口组和该组的两个总计属性标识的。例如,河北省、石家庄市一汉族、妇女、年龄在18~50岁的人口总数和平均收人就是其中的一个事件。
图3-17b 的例子中,G表示所有运输工具,即陆地、水上和空中运输工具集合的联合。C是包含该联合的按单个成员组成的一个集合,而总计属性"运输工具总数"是描述该集合的一个导出值。因此,"运输工具总计"有一个单个事件。
图3-17 总计关联
假如是对实体或事件的一个集合进行总计,而不是对一个单个事件或实体,一个属性类型就可以明确地定义为模型的一个总计属性。这就是为什么只有X关联和C关联才能指定为作S关联的IC概念类型。因为X或C关联的一个事件表示实体或事件的一个集合,所以能接收统计总计。而所有的其他关联类型的事件只表示一个单个实体或事件,因而不能接收统计总计。
(1) 结构特性
S关联类型的结构是ICx(XiSi),其中的 IC可以是叉积关联或组合关联,而Si是总计属性,它可以是M、A或C关联类型。总计关联类型的一个事件有结构(ic,(s1,s2,
…,sm))。其中ic∈IC,si∈Si 。
要想对M、A、G、I 或S关联类型中的事件集合进行统计,必须在S和它们之间增加一个C关联类型。标识概念IC和表示总计属性的概念sl,s2,…,sm在关联类型中都明确地说明。图中IC结点总是放在S结点的最左边。
(2) 操作特性
在事件级,可以增加、删除、修改或提取总计属性。假如标识的概念是叉积类型,聚集和分散操作是有意义的,而且可应用到事件的集合上。在总计事件的集合上可应用传统的集合、关系和存储操作。
(3) 语义约束
统计总计和所涉及的概念集合的事件要始终保持一致,称为总计约束。就是说当删除或增加进行总计的事件时,要重新计算总计属性。通常,对概念类型IC的操作会引起重新计算总计属性。
2、 用关联类型描述数据库
在设计一个复杂的数据库时,首先要进行概念设计。根据所使用的DBMS的组织结构、操作和约束特性,用前面提到的七种关联类型,可递归地和循环地构造各种关联类型,定义任何复杂的数据库,并且可以使用各种关联类型的网结构进行图形化的表示。
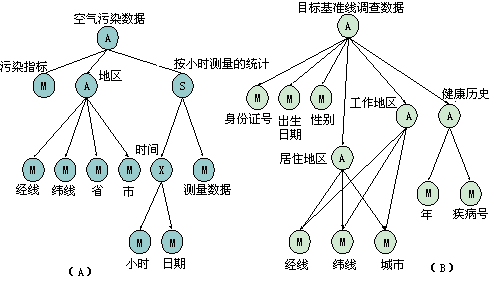
图3-18给出描述空气污染数据库的模型。其中图3-18a是空气污染数据的定义,该数据是由聚合关联类型形成的实体类型。污染标识号是实体的唯一的标识属性。地区是一个聚合实体类型,其组成类包括经线、纬线、省名和城市,它的存在与空气污染数据有关。污染测量数据是一个总计类型的实体,它是按时间统计的测量数据。时间是小时和日期的叉积。
图3-18b是目标基准线调查数据模型。在这个模型中,目标基准线调查数据是聚合类型,生活区和工作区定义为具有相同属性类型的集合:经线、纬线和城市名。健康历史是由年和疾病号码组成的聚合类型。
图 3-18 空气污染数据库的模型
3、 面向对象的语义关联模型OSAM*
在SAM*数据模型中,用概念和关联描述现实世界,它可以把简单的数据类型如整数、实数、字符型、布尔型以及复杂的数据类型如矩阵、集合、向量、有序集等作为概念类型进行处理。而OSAM*数据模型是把SAM*在工程中的应用进行扩展。在OSAM*中把现实世界的所有概念--简单的、复杂的、实际的、抽象的--都描述为对象。对象本身还包括与其相关的约束和操作。
由于在OSAM*模型中,对定义的对象可以施加各种语义约束,以及推理和规则,并封装约束和操作方法,故称其为面向对象的语义关联模型OSAM*。Q.Li在1991年曾提出:
面向对象数据模型 = 面向对象+语义数据模型。
因而 OSAM* 也就是面向对象的数据模型。本节仅从语义模型的角度说明 OSAM* 捕捉的语义特征主要有如下5种:
- 聚合关联语义
- 概括关联语义
- 交互关联语义
- 组合关联语义
- 成员关联语义。
◇ 第五节 典型工程数据库管理系统
1、 IMDAS集成制造数据库系统
2、基于特征的智能数据库系统概念框架
3、 TORNADO系统
4、 ARDBID系统
5、 MLDB系统
6、 IPIP
7、 RMI
8、OSCAR
自80年代以来,国内外已经开发的工程数据库管理系统比较典型的有:IMDAS、IPIP、ARDBID、TORNADO、RMI、OSCAR等。下面仅就这些系统在数据模型、数据库语言、功能和特点给予介绍。
1、 IMDAS集成制造数据库系统
美国国家标准局(NBS)的集成制造数据管理系统(Integrated Manufacturing Data Administration--IMDAS)的主要目标是为了实现在一个制造环境中的信息集成。这个系统采用了一种三模式信息结构体系(Three-Schema
Information Architecture),即它提供三类数据库视图(View):
1)、若干个全局外部视图(Global External View)。这类视图定义为:像一个单用户所看到的集成数据库的一部分。
2)、一个全局概念视图(Global Conceptural View)。它是一个集成数据库,由管理CIMS所要求的所有工厂数据组成。
3)、若干个分段视图(Fragmented View)。它代表物理上分布存储区(Partitionary),或者是子系统引用的概念对象的复制。每个分段视图代表驻留于一个子系统内的数据对象。
其工作原理可以用下例来说明:在一个车间中为了控制产品质量,减少废品,需要定时地报告报废的零件数字。假定这个零件经过三个加工单元加工,并与三项数据有关。一般情况下,为了取得这种数据需要三次查询,然后将查询结果集中,重新格式化,经汇编后交付质量管理员。这个过程在IMDAS中对用户都是隐蔽的,即在外部视图中直接查询。也就是说,用户不需要知道各项数据的复杂的内部信息存取机理以及可共享性。这种结构体系比二模式具有更多的优点,如可以明显地增加系统的可配置性,减少用"自然"格式传递和接收数据时的前、后处理。
2、基于特征的智能数据库系统概念框架
这是美国Rensselaer多技术研究所C.Hhu等人提出的职能数据库系统框架。这个框架与流行的"接口"和"超级数据库管理系统"在原理上完全不同。其核心是一个位于设备层的元数据库(Matadatabase,以下称元DB)。元DB以特征作为建模基元,从而简化了各种制造实体之间共享的信息。也就是说,藉助元DB的特征,提供了一种基本信息源(Basic
Information Root),从而使统计、设计、生产和市场活动中所需的数据发生关系。因此,这个系统必须以基于特征的建模为基础。
元数据库可看成在线仓库。它服务于正在运行的智能监控程序和为了取得实时信息而访问系统中数据流的管理。
图3-44为这个系统的概念框架
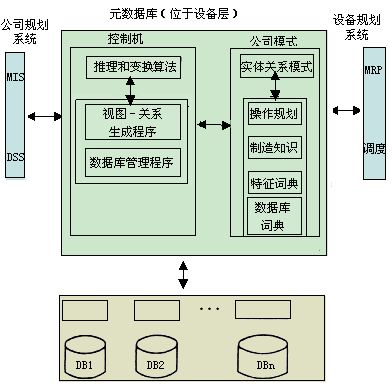
元DB由公司模式(Enterprise Schema)和控制机(Control Engine)组成。公司模式包括:一个概念上统一的分类目录,从这个目录上可以看出,为所有子系统安排的模式,即制造知识和操作规则;特征和数据库词典。特征是将数据和知识以及不同制造实体集成在一起的工具。
控制机包括推理(Inference)、交换(Mapping)和公司模式中隐含的视图的生成算法。
CAD/CAM数据库包括商用数据库和CAD、CAM数据库。每个数据库都由一个单独的数据库管理系统(DBMS)管理,因而形成一个独立的子系统。这些子系统将由原来用户组(即工程设计部门等)单独地运行和维护,但其状态和控制过程由元数据库监视。从这些子系统来的信息由元DB自动地将其转换成其它子系统(如商业DB)所需的格式。这种转换是由预先决定的元DB操作规则和存贮在元DB中的制造知识来完成。
这个系统与其它系统不同之处是MRP--材料要求规则、车间调度以及公司规划(MIS,DDS)都作为数据库系统的用户。它们通过元DB向子系统查询。这种结构的好处是不需要一个公共接口--用于所有用户的数据库语言。也就是说,不要求子系统隐藏到元DB的后面。
为了实现这种系统还需要做很多工作,如建立基于特征的建模框架,利用实体-关系一类方法把特征集成到数据模型中去。另外,面向对象的编程的基于框架(Frame)的知识表达技术都将用来完成这个任务。
由于EDBMS的任务除完成包括图形数据在内的数据操作和管理外,实现信息语义的自动转换也是其重要任务之一。大多数EDBMS都没有考虑这项功能,而这个系统将能较好地解决这个问题。
3、 TORNADO系统
TORNADO是挪威工业中心研究所在小型计算机NORD 10上为CAD/CAM集成系统AUTOKON研制的一种网状模型CAD/CAM工程数据库系统。目前,在挪威、丹麦、瑞典、芬兰、英国、美国和德国已有许多台计算机配有这种数据库系统。它能够处理比较复杂的几何数据结构,如雕塑曲面数据结构。TORNADO用Fortran
Ⅳ编程,约有12000个程序行。整个数据库包括一个数据库初始化程序,一个数据库管理系统(有66个处理子程序)与一个交互式服务系统。其结构体系见图3-45。其主要特点如下:
图3-45 TORNADO系统结构示意图
1)、可变长实体。是一个实体类数据项描述实例的逻辑组合。它由数据头(Header)、名字、数据类型和七个存储不同的数据类型数据的数据区等十项数据组成。数据头中包括了每个数据区的长度、产生数据(Data
Created)的子程序、实体类型和指向数据结构的指针构成。
2)七种数据类型。即整、实、字符、双整、双实、复数和逻辑数据类型。
3)按实体名字存取。每个实体有一个唯一名字。一类实体的名字长度相同,并有一个实体名表。表中记录了所有实体的名称和实体地址指针。通过此表可以用散列法(Hashing)查询和存取。
4)能处理各种实体之间关系。实体之间的单环、双环、一对多关系,一类实体之间的多对多关系,也包括这些关系的各种组合关系的管理,比标准的网状数据库功能还强。
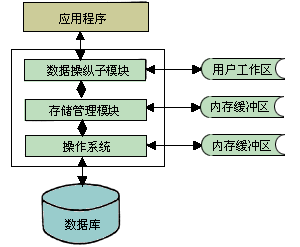
5)动态长度记录。系统在内存和内存缓冲区中的存储格式为动态长度记录,但在外存中是等长页存储方式,即存储管理模块(SAM)利用一般文件系统EASYBAS进行这种内外存之间的转换。而数据管理模块则在动态长度记录上工作。
4、 ARDBID系统
ARDBID系统是印度科学院自动化学院研制,用于交互式设计的EDBMS,用Pascal语言编写。在配有DEC VT-11的图形终端的DEC
1090计算机上运行,系统结构如图3-46所示。ARDBID系统主要由四个核心模块、一个人机接口和一个包括三类数据的数据库系统组成。
四个核心模块是:数据描述语言DDL解释模块DDI、数据操纵语言DML解释模块DMI、查询语言QL处理模块QH和设计辅助模块DA。DDI模块主要功能是解释用户的DDL语句,产生与这个语句描述相一致的实体关系,并将关系存到数据库中。DMI模块解释用户的DML语句,并根据语句要求完成对数据库中某些数据的编辑、复制和删除操作。DDI和DMI模块的功能结构如图3-47所示。QH模块处理一些比较简单的无需计算的查询。DA模块有两类功能:
①处理比较复杂和需要计算才能确定的查询、如查询一个零件的体积是多少。
②利用接入的优化和应用无关的专用子程序辅助优化和结构化设计。
人机接口是一个各类命令解释执行模块CI,它包括在四个核心模块的外面,CI实际上就是数据库管理系统(DBMS)。设计人员通过它与四个核心模块通信,并在任务完成后返回CI等待新的任务输入。
数据库系统中包括三类数据:2D图形数据、3D图形数据和字母一数字型非图形数据。各类数据均用关系数表存放在数据库中。如一个2D图形,可用点关系表、线关系表和面关系表存储,相当于线框模型中的三表结构。对于3D图形只需再加上一个体关系表。由此可见,ARDBID系统是典型的关系型数据库管理系统。与其它EDBMS相比具有简单、灵活、独立性强、理论严密等一些列优点。最近几年,大多数CAD/CAM数据库系统都采用这种关系型数据结构。
◇ 本章小结
本章主要讨论了满足各种应用的几种数据模型。在面向对象技术成熟之前,工程数据模型的研究主要有三种方法:
1)、扩展传统的数据模型,如扩展的网状数据模型、扩展的关系数据模型,以便支持自然界多对多和复杂对象的表示;
2)、研究具有语义的数据模型,如面向领域的对象模型、面向统计的语义数据模型;
3)、面向工程数据表示的通用数据模型,如函数数据模型、版本模型、对象模型等。
虽然这些模型在理论上满足一部分工程数据的表示,但由于没有相应的工具和DBMS的支持,这些数据模型并没有获得商业上的成功(即工程界的认可)。人们应用的最多的还是面向关系的数据概念模型:实体-关系模型。虽然在20世纪90年代出现了商品化面向对象的数据库管理系统OODBMS,但由于OODBMS无论在性能还是在开发工具的支持上都与工程界期望的结果相差较远,因此面向对象的模型只能作为一种系统分析和设计模型。
在讨论了工程数据模型后,本章介绍了工程数据库系统的功能、体系结构、开发方法等。这是所有DBMS系统都必须考虑的。现有的商品化数据库系统如Oracle、DB2、SQL
Server的开发都基本支持了上述的功能,其体系结构也可根据客户的需求由客户配置。特别是在传统的关系数据库系统中增加对象-关系特点,基本解决了工程界在二十世纪八十年代对工程数据库管理系统的需求。在介绍了上述概念后,我们简要回顾了几个主要的工程数据库管理系统。
工程数据库应用系统的开发需要相关的数据库语言。关系数据库语言SQL已经成为国际标准。本章最后讨论了关系数据语言的主要内容,特别是与工程应用开发有关的事务、存储过程、触发器、嵌入式编程等相关概念。
◇ 课后习题
问答题
3.1
- 与传统的数据库管理系统相比,工程数据库管理系统有什么特点?
- 传统的数据模型在表达复杂工程对象方面有什么不足?
3.2
- 数据模型的分类有几种,并列举相关的数据模型?
- 什么叫语义数据模型?它有什么特点?
- 简述工程数据中常用的语义数据模型。
- 比较成员关联、聚合关联、概括关联、组合关联之间的异同点?
- 简述扩展网状数据模型与网状数据模型的异同?
- 扩展关系模型与标准的关系模型有什么不同?
- 在扩展关系数据库管理系统中如何描述复杂对象及对象间的层次管理?
- 什么叫NF2扩展关系数据模型?
- 请用函数数据描述语言DAPLEX表述自行车构成部件的实体说明。
- 版本的静态和动态引用是什么含义?何谓参数化的版本?何为配置?
- 试述三级库结构和版本状态的联系?
- 版本的各种存储方法和各自的有缺点?
- 试述三级库结构和版本状态的联系?
- 版本的各种存储方法和各自的有缺点?
3.3
- 工程数据库管理系统的功能有哪些?
- 工程数据库的体系结构有几种?各有什么特点?
- 多层结构的体系结构有什么特点?
- 分布式体系结构的特点是什么?
3.4
- 实现工程数据库管理系统时需要考虑那些问题?
- 工程数据库管理系统的实现有那些方法?
- 如可选择工程数据库管理系统?
3.5
- 简述几个工程数据库管理系统的特点?
- 简述你熟悉的工程应用对工程数据库管理系统的需求?
3.6
- 试述SQL语言的特点。
- 试述SQL语言的功能
- SQL语言的数据定义功能有那些?
- 试述SQL语言查询语句的基本组成和用途。
- 什么是视图?有什么优点?
- 什么是基本表?什么是视图?两者的区别和联系是什么?
- 企业的合同分为合同描述包括合同号、客户、合同日期、合同额等,合同体包括序号、商品编号、单位、数量、单价等。合同管理还包括合同的更改(更改的序号,更改的商品及其数量与单价等)。试回答下述问题:
(1)、用SQL语言建立上述几张数据库表;
(2)、建立客户的合同金额视图;
(3)、建立商品的合同数量和合同金额视图;
(4)、统计商品的月销售量和销售额;
(5)、统计客户的月订购量;
(6)、建立合同的有效商品视图;
(7)、建立客户的产品订购视图
(8)、找出没用销售活动的商品
(9)、根据商品的销售情况,找出销售最频繁的商品列表;
(10)、客户的编号要调整,如何更新合同中的客户编号。
(11)、如果要进行合同的流程管理,如何修改商品的数据库表?
(12)、假设合同分为录入、审核、发货等状态,如何统计各状态下的商品数量与金额。
- 简述SELECT子句中的ALL和UNION联合中的ALL有什么不同?
- 在SQL语言中,使用空值应注意什么?
- 什么是事务?事务有什么特点?
- 试述游标和游标的用途。
- 试述存储过程的特点及用途。
- 试述数据库触发器的用途及其优缺点。
|