| UML软件工程组织 | |||
| |
|||
|
|||
调优 SQL 过程
作者:Serge Rielau 来源:IBM
您想学习调优 SQL PL 的一些技巧吗?如果是这样的话,本文将描述一些调优 IBM® DB2® Universal Database™(UDB)V8.2 for Linux,UNIX®, and Windows® 中的 SQL 过程的常见例子,并将特别关注从其他数据库管理系统中移植过来的过程。 动机SQL 过程语言(SQL PL)是许多 DB2 开发人员工具箱中的一个流行工具。当将应用程序从 Oracle、Sybase 或 Microsoft® SQL 服务器迁移或移植到 DB2 中时,更是如此。然而,SQL PL 的即时可用性也给它带来了一些问题:
在前面的文章中,我曾描述了分别利用 SQL PL Profiler 和 SQL 过程跟踪 来发现性能和逻辑问题。本文中,我将使用 SQL PL Profiler 来说明一组慢速 SQL PL 的常见例子,并说明 DB2 V8.2 如何独自优化它们,或者您自己如何可以调优 SQL PL。 普通 SQL 过程如果您有 Microsoft SQL Server 或 Sybase 方面的背景知识,那么您就会很好地了解这些过程。除了一条 CALL 语句,这个范例的应用程序中将不存在任何 SQL。通过这个范例所认识到的好处有两个:
为了解决第一个问题,DB2 支持内联 SQL PL 的概念。DB2 允许将简单逻辑或查询封装在 SQL 函数中。当从调用者执行该 SQL 函数时,其主体就是扩展到调用者中的宏。 为了解决第二个问题,DB2 使用了包缓存。该缓存不仅记住最近执行的过程,还记住了以前执行的语句。因此,在第一次编译 SQL 语句之后,后来的调用只要继续执行相同的执行计划即可。我们用一个例子来说明:
注意,您可以从“下载”小节中下载带有完全 DDL 的所有例子。可以从 developerWorks 下载本文全文使用的 SQL PL Profiler。下面的屏幕快照展示了上述普通 SQL 过程的 100 次执行。 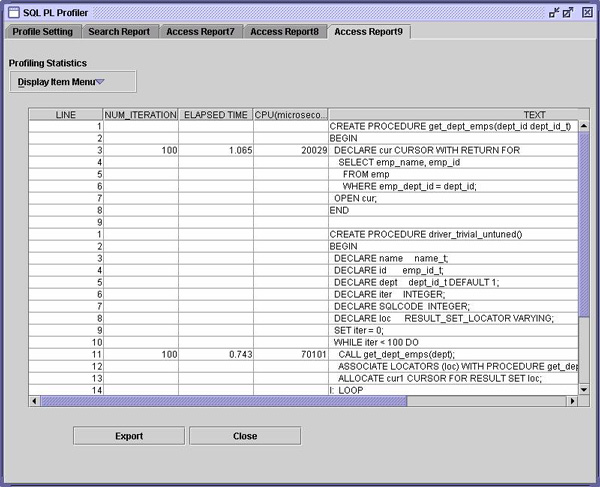
那么,时间消耗在哪些地方了呢?DB2 需要处理这条 CALL 语句。假设以前已经缓存了这个过程,那么,DB2 就需要初始化 SQL 过程,以便执行它。然后,DB2 打开从过程中返回的游标,并处理分配给结果集的定位器。最后,DB2 才可以真正取得所返回的行。做这么多工作仅仅是为了打开一个游标! 现在,让我们使用内联 SQL PL 来取得相同的效果:
我们现在用 DECLARE 游标及其各自的 OPEN 语句来替换驱动程序过程中的 CALL 和所有定位器代码,并测试结果: 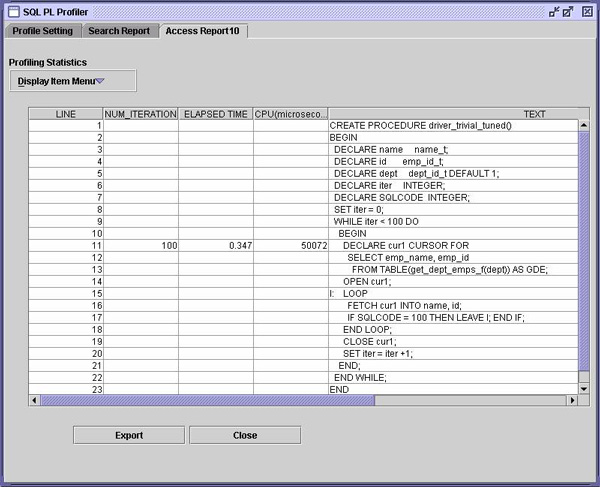
真是令人印象深刻!仅仅通过使用内联 SQL PL 就使所监控代码的运行速度提高了三倍。甚至连不返回结果集的简单 SQL 过程也可以用 SQL 函数取代。对于返回不止一个参数的过程,可以使用 SQL 表函数,它返回一个包含一行的表 ―― 每个输出参数为一列。对于包含一个输出的过程,可以只使用一个标量 SQL 函数。注意,DB2 V8.2 还支持在 SQL 表函数中包含 UPDATE、DELETE、INSERT 和 MERGE。这意味着您甚至可以使用内联 SQL PL 封装数据库更改。 使用临时表DB2 支持已声明的全局临时表(Declared Global Temporary Table,DGTT)。用 SQL 术语来说,DECLARE 表示所定义对象的目录中将不包含条目。因此,它在定义上是私有的。与之相比,DB2 UDB for zOS® 所支持的已创建的全局临时表(Created Global Temporary Table)是在目录中定义的。当然,虽然它们的内容是私有的,但其定义却不是私有的。 具有声明对象的灵活性(只要用户临时表空间是立即可用的,DBA 就不会再关心该应用程序在做什么)也带来了一个不足:对于要进行编译的语句来说,这个对象必须存在。如果连接失败,或者该表已删除,那么每次重新声明这个表时,都需要重新编译引用 DGTT 的任何语句。 同样,我们通过一个例子来说明: 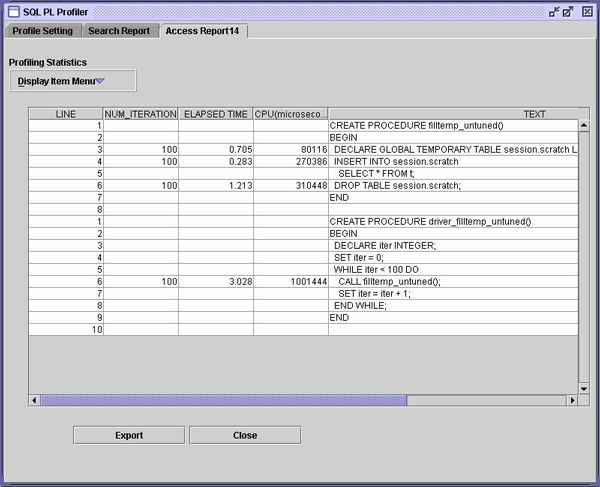
当然,上面的代码是无意义的,但其结构很常见,因此,可以用它来说明这个问题。本例中,将频繁调用该过程,而 DGTT 仅在本地使用。因此,为了进行封装,该过程声明 DGTT 位于临时表上,然后,当不再需要这个临时表时,可以删除它。 这个图有什么问题吗?DECLARE 和 DROP 之间的 insert 语句每次都要重新进行编译,因为 DB2 无法知道该 DGTT 下次是否将具有相同的属性。实际上,DECLARE 和 DROP 之间有许多语句,都可用于处理该临时表结果集的格式,直到它最终满足要求为止。 为了避免这种疯狂编译,将该临时表的声明移至一个单独过程中会更合适一些,该过程只在启动工作负载时执行一次。 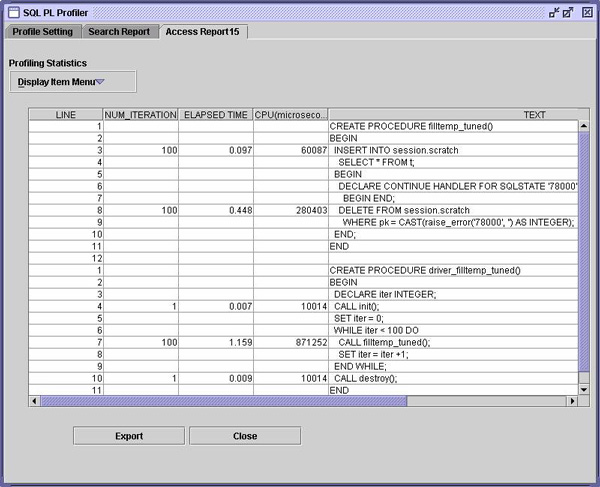
正如您可以在上面看到的,其结果是令人震惊的。但这里将有更多要了解的东西。请观察取代 DROP 语句的 DELETE 语句。它将总是因用户引起的错误而失败,然后,将由一个 continue 处理程序解决这个错误。这里发生了什么事? 为了提高速度,需要优化临时表,因此,当插入行时,DB2 不用费心在临时表中寻找空闲空间,而是将表行为替换为 APPEND ONLY。虽然常规的 DELETE 将删除这些行,但是它不会真正让 DB2 回收这些空间。应用程序将继续消费越来越多的用户临时表空间。 实际上,另外一个因素在这里提供了帮助。那就是,所有 DGTT 都被声明为 NOT LOGGED。毕竟,您可以相当容易地重新构建临时表的内容。如果 NOT LOGGED 表在执行数据修改语句期间碰到了执行错误,那么对于 DB2 来说,就只有一个选择:清空(truncate)该表。而这就是 DELETE 语句所进行的工作。 条件处理程序计算机语言有两种处理错误的常用方法。 第一种方法要求程序在在进行每一个重大操作之后,检查错误。在 DB2 中编写 C-UDF 或 C 存储过程的开发人员已经学会在其代码的每条 EXEC SQL 语句之后检查 SQLCA。 第二种方法就是具有专用的处理程序,“捕捉”各条语句所“抛出”的任何或特定错误条件。Java™ 和 C++ 编程人员都熟悉这一概念。 SQL/PSM 标准为 SQL 过程语言定义了使用处理程序的第二种方法。然而,通常当从 Sybase 或 Microsoft SQL 服务器移植 TSQL 过程时,或当仅仅对 SQL PL 应用 C 技巧时,都可以避免更现代的处理程序方法,而支持更为传统的错误检查方法。 这些情况下要做的事情就是定义一个通用的“万能(catch-all)”处理程序,用于在局部变量中保存所有错误信息。然后,使用过程体中的显式错误处理代码进行错误处理。下面是这种类型的一个简单场景。 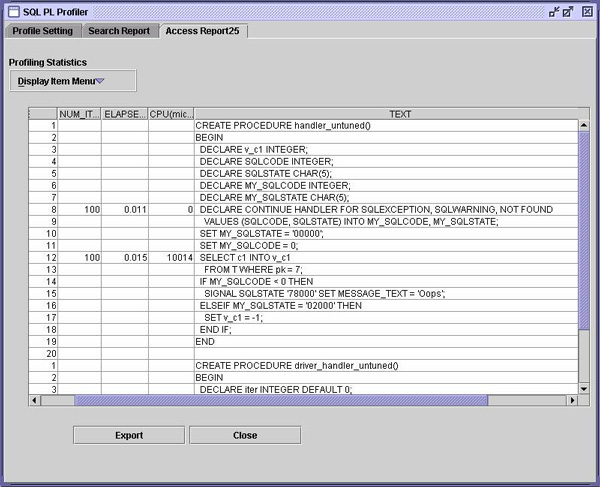
在这个场景中,要处理一条 SELECT INTO 语句。在处理这条语句之前,要重新设置本地错误变量,其代价虽然不高,但仍要花费一些 CPU 时间。然而,问题是用于保存错误变量的 VALUES INTO 语句的花费几乎与 SELECT INTO 语句的一样高。 具有讽刺意味的是,在许多情况下,程序甚至可能不在乎检查 SELECT INTO 的结果是什么,因此,条件处理程序的工作是徒劳的。本例中,将完成以下几件事。 首先,可以显式地检查 NOT FOUND 警告(如果想这样做的话),而不必在局部变量中保存 SQLCODE 和 SQLSTATE。事实的确如此,因为该警告可用于 SQL 过程中的下一条语句。 其次,所有错误或意想不到的警告实际上应该由异常处理程序来处理。除了按照发明者所计划的方式来使用该语言之外,这样做可避免复制和重新设置局部变量。 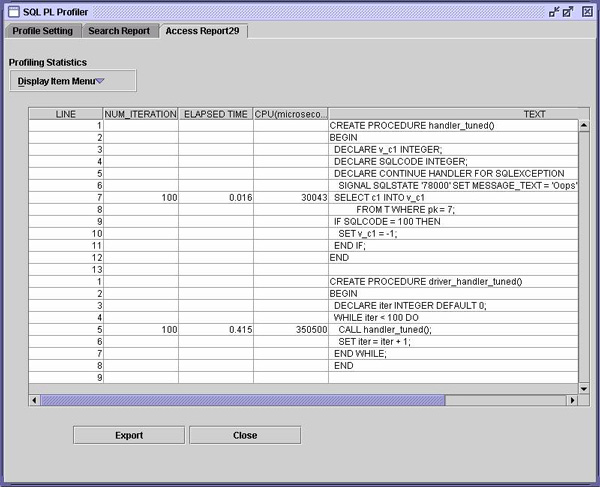
可预测的是,上面的调优版本免除了所有处理程序成本,并使性能提高了一倍。 调优存在谓词我无法理解开发人员为何用下方所示方式编写存在检查(existential check),但是因为他们这样做了,所以我们就来讨论它。 优秀的开发人员有时候似乎害怕执行那些可能导致 NOT FOUND 警告的语句。下面的例子是一条模仿 MERGE 的语句。 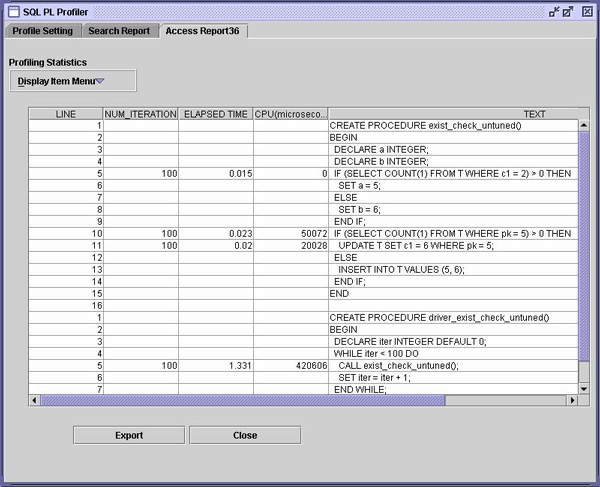
这两个存在检查为何不好? 首先,要求 DB2 回答一个不相关的问题。仅仅为了检查某些行是否存在而迫使 DB2 计算一个表中的行数是一种代价极其高昂的选择。 其次,除非某一个表使用语句级触发器,否则,用显式查询来检查某一行是否存在的代价就与未找到要更新的行就执行 update 语句的代价一样高。在该行没有被查找到的情况下,这两种方式没有什么区别。但是如果已经通过 EXIST 谓词找到了这个行,那么 UPDATE 还是必须再次查找它。 因此,如果没有更多注释,这里有一种更好的方法,可用这种方法来处理通常用来处理条件更新和执行存在检查的显式方式。 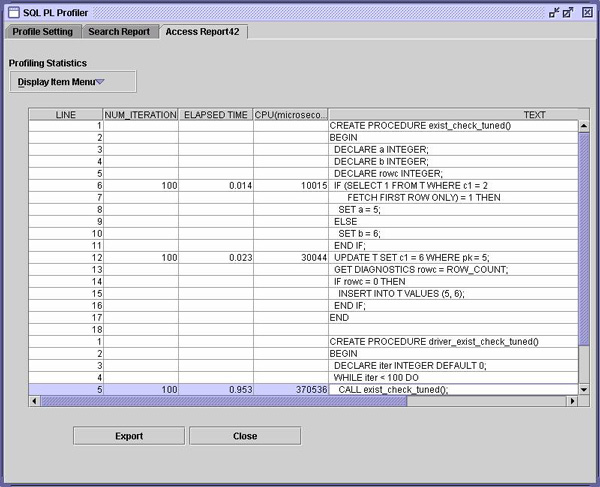
当然,可以总是对单行使用显式 EXISTS 谓词和 MERGE 语句,两者将获得相似的性能。 CALL 回避有许多种在紧凑循环(tight loop)中调用过程的情况。使用队列或关系中间表(staging table)的批处理过程就是一个例子。队列中的每个对象如果满足指定条件,就可能触发特殊处理。对于任何给定对象,这些条件通常很少为真。因此,处理该逻辑的过程有一个最外层的检查,决定是执行主体的其余部分,还是不采取任何动作而返回。 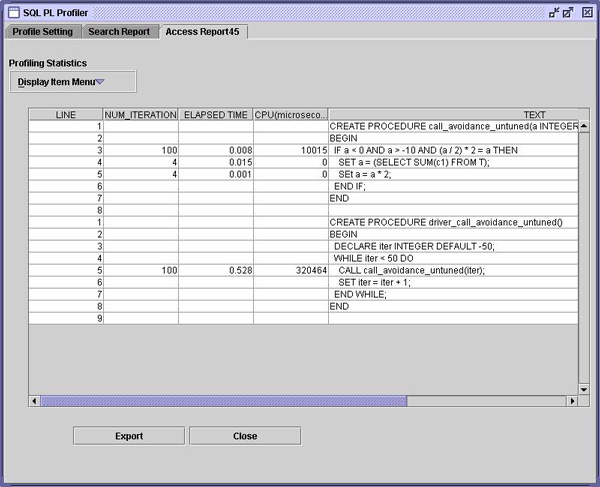
正如第一个例子那样,这里的问题是:没有真正执行重要工作的过程的调用成本可能占据了整个作业成本。 为了避免这一点,可以将执行过程体的条件撤出,交给调用者,或者为了维护封装和确保该逻辑的完整性,可以简单地重复它。在上面的例子中,可以按以下方式封装条件:
查找下列结果: 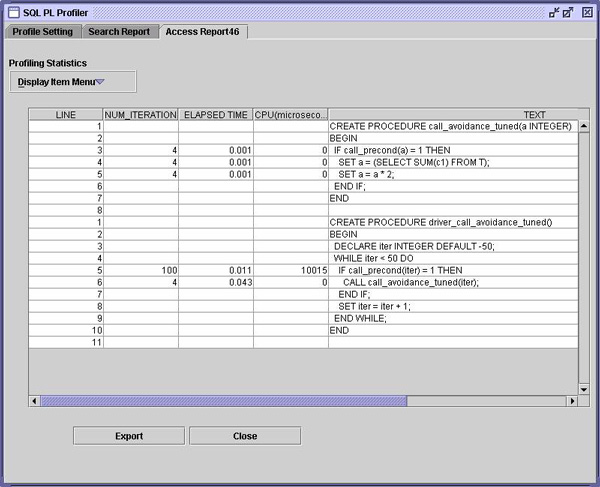
注意,已调优的过程就不会因为没有在外部检查先决条件而失败,因为过程体中会重复这个检查。 这个例子总结了文中一系列的调优提示。在文章的最后,我将通过 DB2 V8.2 中的新 SQL PL Virtual Machine(PVM)调优一个简短的情况列表。 PVM 中的 SQL PL 调优Gustavo Arocena 是 SQL Procedure 的架构师,他于 2003 年出版了 SQL 过程的性能:提示和技巧。从那时起,已经发生了很多变化。DB2 V8.2 使用其 PVM 编译并执行 SQL 过程,不再将 SQL 过程交叉编译成嵌入了 SQL 的 C。在这个过程中,Arocena 所描述的一些提示已经提供了一些初步了解 PVM 优化器的方法。正如您在前面例子的屏幕快照中可以看到的,一些语句没有成本分配。这不是因为它们是免费的,而是因为这些语句在 PVM 优化器中与其他语句进行了组合,或者因为 PVM 可以本机执行这些 SQL 语句。此外,在 DB2 V8.2 中,PVM 还可以完成下列工作:
这些优化的目的是为了可以在任何缩短代码路径的地方,避免调用常规的 SQL 运行时解释器。PVM 仍然很年青,但它通常优于 V8.2 之前版本编译的 SQL 过程,主要是因为上面所展示的那些改进。 结束语在本文中,我提供了针对 SQL 过程领域中常见性能问题的一些调优技巧。DBA 和开发人员常常关注数据库配置、硬件以及用于解决性能瓶颈的模式。虽然所有这些都是好且有效的方法,但是如果逻辑不允许,那么经过完美调优的数据库也仍将无法执行。 通过上述技术,在实际的客户场景中,性能可以提高 30 倍,这足可以区分失败的项目和引以为豪的成功。 致谢感谢 Lee Johnson 和 Gustavo Arocena,以及为 PVM 贡献了智慧的人们。 还要感谢无数开发人员,包括 IBM 的员工和客户们,他们与我分享了他们对 SQL 的疑问。我从他们那里受益匪浅。 下载
参考资料
|
组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |