| ±ύΦ≠ΆΤΦω: |
| ±ΨΈΡά¥Ή‘”ΎcsdnΘ§±ΨΈΡΫι…ήΝΥΫΪlinuxœΒΆ≥ΒΡΜζΤςΉςΈΣΖΰΈώΤςΘ§Β±‘Ύ…œΟφ¥νΫ®ΖΰΈώ ±Θ§»γΚΈΕ‘“Μ–©≥Θ”ΟΒΡ–‘Ρή÷Η±ξΫχ––ΦύΩΊΓΘ |
|
ΖΰΈώΤςΦύΩΊ
‘Ύ¥νΫ®ΖΰΈώΤς ±Θ§≥ΐΝΥ≤Ω πwebapp÷°ΆβΘ§ΜΙ–η“ΣΖΰΈώΒΡ“λ≥Θ–≈œΔ”κΖΰΈώΤς–‘Ρή÷Η±ξΫχ––ΦύΩΊΘ§“ΜΒ©”–“λ≥Θ‘ρΆ®÷ΣΙήάμ‘±ΓΘ
ΖΰΈώΤς Ι”ΟLinux+Nginx-1.9.15+Tomcat7+Java¥νΫ®ΒΡΓΘ
±ύ–¥Ϋ≈±ΨΦλ≤β¥μΈσ»’÷ΨΚΆΖΰΈώΤς–‘Ρή÷Η±ξΘ§“ΜΒ©–¬…ζ¥μΈσ»’÷ΨΜρ’Ώ–‘ΡήΫΒΒΆΒΫ…ηΕ®ΒΡψ–÷Β ±Θ§‘ρ Ι”Ο‘ΤΦύΩΊΫΪ±®Ψ·…œ¥ΪΒΫ‘Τ’ΥΚ≈ΓΘ
ΖΰΈώ‘Υ––ΦύΩΊ
¥μΈσ»’÷ΨΑϋΚ§“‘œ¬»ΐΗωΖΫΟφΘΚ
nginx ¥μΈσ–≈œΔΦύΩΊ(nginx.conf≈δ÷Ο)
${NGINX_HOME}/logs/error.log
tomcat ¥μΈσ–≈œΔΦύΩΊ(server.xml≈δ÷Ο)
${TOMCAT_HOME}/logs/catalina.out
webapp¥μΈσ–≈œΔΦύΩΊ(log4j)
${WEBAPP_HOME}/log/error
ΜζΤς–‘Ρή÷Η±ξ
“ΜΑψΕΦΜα Ι”ΟlinuxœΒΆ≥ΒΡΜζΤςΉςΈΣΖΰΈώΤςȧѫϥ±‘Ύ…œΟφ¥νΫ®ΖΰΈώ ±Θ§–η“ΣΕ‘“Μ–©≥Θ”ΟΒΡ–‘Ρή÷Η±ξΫχ––ΦύΩΊΘ§Ρ«Ο¥“ΜΑψΑϋΚ§ΡΡ–©÷Η±ξΡΊΘΩœ¬ΟφΕ‘ΤδΫχ––“Μ–©ΉήΫαΘ§ΜΕ”≠≤Ι≥δΓ≠
÷Η±ξ
1.CPU(Load) CPU Ι”Ο¬ /ΗΚ‘Ί
2.Memory ΡΎ¥φ
3.Disk ¥≈≈ΧΩ’Φδ
4.Disk I/O ¥≈≈ΧI/O
5.Network I/O Άχ¬γI/O
6.Connect Num Ν§Ϋ” ΐ
7.File Handle Num ΈΡΦΰΨδ±ζ ΐ
Γ≠
CPU
1.ΥΒΟς
ΜζΤςΒΡCPU’Φ”–¬ ‘ΫΗΏΘ§ΥΒΟςΜζΤς¥Πάμ‘ΫΟΠΘ§‘ΥΥψ–Ά»ΈΈώ‘ΫΕύΓΘ“ΜΗω»ΈΈώΩ…Ρή≤ΜΫωΜα”–‘ΥΥψ≤ΩΖ÷Θ§ΜΙΜα”–I/O(¥≈≈ΧI/O”κΆχ¬γI/O)≤ΩΖ÷Θ§Β±‘Ύ¥ΠάμI/O ±Θ§ ±ΦδΤ§Έ¥ΆξΤδCPU“≤Μα ΆΖ≈Θ§“ρ¥ΥΡ≥Ηω ±ΦδΒψΒΡCPU’Φ”–¬ ΟΜ”–ΧΪ¥σΒΡ“β“εΘ§“ρ¥Υ–η“ΣΦΤΥψ“ΜΕΈ ±ΦδΡΎΒΡΤΫΨυ÷ΒΘ§Ρ«Ο¥ΤΫΨυΗΚ‘Ί(Load
Average)’βΗω÷Η±ξ±ψΡήΚήΚΟΒΟΕ‘ΤδΫχ––±μ’ςΓΘΤΫΨυΗΚ‘ΊΘΚΥϋ «ΗυΨί“ΜΕΈ ±ΦδΡΎ’Φ”–CPUΒΡΫχ≥Χ ΐΡΩΚΆΒ»¥ΐCPUΒΡΫχ≥Χ ΐΡΩΦΤΥψ≥ωά¥ΒΡΘ§Τδ÷–Β»¥ΐCPUΒΡΫχ≥Χ≤ΜΑϋά®¥Π”ΎwaitΉ¥Χ§ΒΡΫχ≥ΧΘ§±»»γ‘ΎΒ»¥ΐI/OΒΡΫχ≥ΧΘ§Φ¥÷ΗΡ«–©ΨΆ–ςΉ¥Χ§ΒΡΫχ≥ΧΘ§‘Υ––÷Μ»±CPU’βΗωΉ ‘¥ΓΘΨΏΧε»γΚΈΦΤΥψΩ…“‘≤ΈΦϊLinuxΡΎΚΥ¥ζ¬κΘ§ΦΤΥψ≥ω“ΜΗω ΐ÷°ΚσΘ§»ΜΚσ≥ΐ“‘CPUΚΥ ΐΘ§ΫαΙϊΘΚ
<=3 ‘ρœΒΆ≥–‘ΡήΫœΚΟΓΘ
<=4 ‘ρœΒΆ≥–‘ΡήΩ…“‘Θ§Ω…“‘Ϋ” ’ΓΘ
>5 ‘ρœΒΆ≥–‘ΡήΗΚ‘ΊΙΐ÷ΊΘ§Ω…ΡήΜαΖΔ…ζ―œ÷ΊΒΡΈ ΧβΘ§Ρ«Ο¥ΨΆ–η“Σά©»ίΝΥΘ§“ΣΟ¥‘ωΦ”ΚΥΘ§“ΣΟ¥Ζ÷≤Φ ΫΦ·»ΚΓΘ
2.≤ιΩ¥ΟϋΝν
vmstat
vmstat n m
n±μ ΨΟΩΗτnΟκ≤…Φ·“Μ¥ΈΘ§m±μ Ψ“ΜΙ≤≤…Φ·Εύ…Ό¥ΈΘ§»γΙϊmΟΜ”–Θ§Ρ«Ο¥Μα“Μ÷±≤…Φ·œ¬»Ξ. ‘Ύ÷’ΕΥΦϋ»κ vmstat
5

ΫαΙϊΗςΉ÷ΕΈΫβ Ά»γœ¬(’βάο÷ΜΫβ Ά”κCPUœύΙΊΒΡ)ΘΚ
rΘΚ±μ Ψ‘Υ––Ε”Ν–(ΨΆ «ΥΒΕύ…ΌΗωΫχ≥Χ’φΒΡΖ÷≈δΒΫCPU)Θ§Β±’βΗω÷Β≥§ΙΐΝΥCPU ΐΡΩΘ§ΨΆΜα≥ωœ÷CPUΤΩΨ±ΝΥΓΘ’βΗω“≤ΚΆtopΒΡΗΚ‘Ί”–ΙΊœΒΘ§“ΜΑψΗΚ‘Ί≥§ΙΐΝΥ3ΨΆ±»ΫœΗΏΘ§≥§ΙΐΝΥ5ΨΆΗΏΘ§≥§ΙΐΝΥ10ΨΆ≤Μ’ΐ≥ΘΝΥΘ§ΖΰΈώΤςΒΡΉ¥Χ§ΚήΈΘœ’ΓΘtopΒΡΗΚ‘ΊάύΥΤΟΩΟκΒΡ‘Υ––Ε”Ν–ΓΘ»γΙϊ‘Υ––Ε”Ν–Ιΐ¥σΘ§±μ ΨΡψΒΡCPUΚήΖ±ΟΠΘ§“ΜΑψΜα‘λ≥…CPU Ι”Ο¬ ΚήΗΏΓΘ
bΘΚ±μ ΨΉη»ϊΒΡΫχ≥ΧΘ§»γ‘ΎΒ»¥ΐI/O«κ«σΓΘ
inΘΚΟΩΟκCPUΒΡ÷–Εœ¥Έ ΐΘ§Αϋά® ±Φδ÷–ΕœΓΘ
csΘΚΟΩΟκ…œœ¬ΈΡ«–ΜΜ¥Έ ΐΘ§άΐ»γΈ“Ο«Βς”ΟœΒΆ≥Κ· ΐΘ§ΨΆ“ΣΫχ––…œœ¬ΈΡ«–ΜΜΘ§œΏ≥ΧΒΡ«–ΜΜΘ§“≤“ΣΫχ≥Χ…œœ¬ΈΡ«–ΜΜΘ§’βΗω÷Β“Σ‘Ϋ–Γ‘ΫΚΟΘ§ΧΪ¥σΝΥΘ§“ΣΩΦ¬«ΒςΒΆœΏ≥ΧΜρ’ΏΫχ≥ΧΒΡ ΐΡΩΘ§άΐ»γ‘ΎapacheΚΆnginx’β÷÷webΖΰΈώΤς÷–Θ§Έ“Ο«“ΜΑψΉω–‘Ρή≤β ‘ ±ΜαΫχ––ΦΗ«ß≤ΔΖΔ…θ÷ΝΦΗΆρ≤ΔΖΔΒΡ≤β ‘Θ§―Γ‘ώwebΖΰΈώΤςΒΡΫχ≥ΧΩ…“‘”…Ϋχ≥ΧΜρ’ΏœΏ≥ΧΒΡΖε÷Β“Μ÷±œ¬ΒςΘ§―Ι≤βΘ§÷±ΒΫcsΒΫ“ΜΗω±»Ϋœ–ΓΒΡ÷ΒΘ§’βΗωΫχ≥ΧΚΆœΏ≥Χ ΐΨΆ «±»ΫœΚœ ΒΡ÷ΒΝΥΓΘœΒΆ≥Βς”Ο“≤ «Θ§ΟΩ¥ΈΒς”ΟœΒΆ≥Κ· ΐΘ§Έ“Ο«ΒΡ¥ζ¬κΨΆΜαΫχ»κΡΎΚΥΩ’ΦδΘ§ΒΦ÷¬…œœ¬ΈΡ«–ΜΜΘ§’βΗω «ΚήΚΡΉ ‘¥Θ§“≤“ΣΨΓΝΩ±ήΟβΤΒΖ±Βς”ΟœΒΆ≥Κ· ΐΓΘ…œœ¬ΈΡ«–ΜΜ¥Έ ΐΙΐΕύ±μ ΨΡψΒΡCPU¥σ≤ΩΖ÷άΥΖ―‘Ύ…œœ¬ΈΡ«–ΜΜΘ§ΒΦ÷¬CPUΗ…’ΐΨ≠ ¬ΒΡ ±Φδ…ΌΝΥΘ§CPUΟΜ”–≥δΖ÷άϊ”ΟΘ§ «≤ΜΩ…»ΓΒΡΓΘ
usΘΚ”ΟΜßCPU ±Φδ’Φ±»(%)Θ§άΐ»γ‘ΎΉωΗΏ‘ΥΥψΒΡ»ΈΈώ ±Θ§»γΦ”ΟήΫβΟήΘ§Ρ«Ο¥ΜαΒΦ÷¬usΚή¥σΘ§’β―υΘ§r“≤Μα±δ¥σΘ§‘λ≥…œΒΆ≥ΤΩΨ±ΓΘ
syΘΚœΒΆ≥CPU ±Φδ’Φ±»(%)Θ§»γΙϊΧΪΗΏΘ§±μ ΨœΒΆ≥Βς”Ο ±Φδ≥ΛΘ§»γIOΤΒΖ±≤ΌΉςΓΘ
id ΘΚΩ’œ– CPU ±Φδ’Φ±»(%)Θ§“ΜΑψά¥ΥΒΘ§id + us + sy = 100,“ΜΑψ»œΈΣid «Ω’œ–CPU Ι”Ο¬ Θ§us «”ΟΜßCPU Ι”Ο¬ Θ§sy «œΒΆ≥CPU Ι”Ο¬ ΓΘ
wtΘΚΒ»¥ΐIOΒΡCPU ±ΦδΓΘ
uptime

17:53:46ΈΣΒ±«Α ±Φδ
up 158 days, 6:23ΜζΤς‘Υ–– ±ΦδΘ§ ±Φδ‘Ϋ¥σΥΒΟςΡψΒΡΜζΤς‘ΫΈ»Ε®
2 users”ΟΜßΝ§Ϋ” ΐΘ§Εχ≤Μ «Ήή”ΟΜß ΐ
oad average: 0.00, 0.00, 0.00 ΉνΫϋ1Ζ÷÷”Θ§5Ζ÷÷”Θ§15Ζ÷÷”ΒΡœΒΆ≥ΤΫΨυΗΚ‘ΊΓΘ
ΫΪΤΫΨυΗΚ‘Ί÷Β≥ΐ“‘ΚΥ ΐΘ§»γΙϊΫαΙϊ≤Μ¥σ”Ύ3Θ§Ρ«Ο¥œΒΆ≥–‘ΡήΫœΚΟΘ§»γΙϊ≤Μ¥σ”Ύ4Ρ«Ο¥œΒΆ≥–‘ΡήΩ…“‘Ϋ” ήΘ§»γΙϊ¥σ”Ύ5Θ§Ρ«Ο¥œΒΆ≥–‘ΡήΫœ≤νΓΘ
top
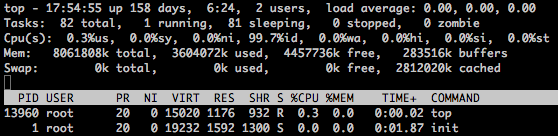
topΟϋΝν”Ο”Ύœ‘ ΨΫχ≥Χ–≈œΔΘ§topœξœΗΦϊhttp://www.cnblogs.com/peida/archive/2012/12/24/2831353.html
’βάο÷ς“ΣΙΊΉΔCpu(s)Ά≥ΦΤΡ«“Μ––:
usΘΚ”ΟΜßΩ’Φδ’Φ”ΟCPUΒΡΑΌΖ÷±»
syΘΚΡΎΚΥΩ’Φδ’Φ”ΟCPUΒΡΑΌΖ÷±»
niΘΚΗΡ±δΙΐ”≈œ»ΦΕΒΡΫχ≥Χ’Φ”ΟCPUΒΡΑΌΖ÷±»
idΘΚ Ω’œ–CPUΑΌΖ÷±»
waΘΚ IOΒ»¥ΐ’Φ”ΟCPUΒΡΑΌΖ÷±»
hiΘΚ”≤÷–ΕœΘ®Hardware IRQΘ©’Φ”ΟCPUΒΡΑΌΖ÷±»
siΘΚ»μ÷–ΕœΘ®Software InterruptsΘ©’Φ”ΟCPUΒΡΑΌΖ÷±»
¥”topΒΡΫαΙϊΩ¥CPUΗΚ‘Ί«ιΩωΘ§÷ς“ΣΩ¥usΚΆsyΘ§Τδ÷–us<=70Θ§sy<=35Θ§us+sy<=70ΥΒΟςΉ¥Χ§ΝΦΚΟΘ§Ά§ ±Ω…“‘ΫαΚœidle÷Βά¥Ω¥Θ§»γΙϊid<=70
‘ρ±μ ΨIOΒΡ―ΙΝΠΫœ¥σΓΘ“≤Ω…“‘ΚΆuptime“Μ―υΘ§Ω¥ΒΎ“Μ––ΓΘ“ΐ”Ο[1]
3.Ζ÷Έω
±μ ΨœΒΆ≥CPU’ΐ≥ΘΘ§÷ς“Σ”–“‘œ¬Ιφ‘ρΘΚ
CPUάϊ”Ο¬ ΘΚus <= 70Θ§sy <= 35Θ§us + sy <= 70ΓΘ“ΐ”Ο[1]
…œœ¬ΈΡ«–ΜΜΘΚ”κCPUάϊ”Ο¬ œύΙΊΝΣΘ§»γΙϊCPUάϊ”Ο¬ Ή¥Χ§ΝΦΚΟΘ§¥σΝΩΒΡ…œœ¬ΈΡ«–ΜΜ“≤ «Ω…“‘Ϋ” ήΒΡΓΘ“ΐ”Ο[1]
Ω…‘Υ––Ε”Ν–ΘΚΟΩΗω¥ΠάμΤςΒΡΩ…‘Υ––Ε”Ν–<=3ΗωœΏ≥ΧΓΘ
Memory
1.ΥΒΟς
ΡΎ¥φ“≤ «œΒΆ≥‘Υ–––‘ΡήΒΡ“ΜΗωΚή÷Ί“ΣΒΡ÷Η±ξΘ§»γΙϊ“ΜΗωΜζΤςΡΎ¥φ≤ΜΉψΘ§Ρ«Ο¥ΫΪΜαΒΦ÷¬Ϋχ≥Χ‘Υ––“λ≥ΘΕχΆΥ≥ωΓΘ»γΙϊΫχ≥ΧΖΔ…ζΡΎ¥φ–Ι¬©Θ§‘ρΜαΒΦ÷¬¥σΝΩΡΎ¥φ±ΜάΥΖ―ΕχΈόΉψΙΜΩ…”ΟΡΎ¥φΓΘΡΎ¥φΦύΩΊ“ΜΑψΑϋά®total(ΜζΤςΉήΡΎ¥φ)ΓΔfree(ΜζΤςΩ…”ΟΡΎ¥φ)ΓΔswap(ΫΜΜΜ«χ¥σ–Γ)ΓΔcache(ΜΚ¥φ¥σ–Γ)Β»ΓΘ
2.≤ιΩ¥ΟϋΝν
vmstat

ΫαΙϊΗςΉ÷ΕΈΫβ Ά»γœ¬(’βάο÷ΜΫβ Ά”κMemoryœύΙΊΒΡ)ΘΚ
swpdΘΚ–ιΡβΡΎ¥φ“― Ι”ΟΒΡ¥σ–ΓΘ§»γΙϊ¥σ”Ύ0Θ§±μ ΨΡψΒΡΜζΤςΈοάμΡΎ¥φ≤ΜΉψΝΥΘ§»γΙϊ≤Μ «≥Χ–ρΡΎ¥φ–Ι¬ΕΒΡ‘≠“ρΘ§Ρ«Ο¥ΡψΗΟ…ΐΦΕΡΎ¥φΝΥΜρ’ΏΑ―ΚΡΡΎ¥φΒΡ»ΈΈώ«®“ΤΒΫΤδΥϊΜζΤςΘ§ΒΞΈΜΈΣKBΓΘ
free ΘΚΩ’œ–ΒΡΈοάμΡΎ¥φΒΡ¥σ–ΓΘ§Έ“ΒΡΜζΤςΡΎ¥φΉήΙ≤8GΘ§ Θ”ύ4457612KBΘ§ΒΞΈΜΈΣKBΓΘ
buffΘΚLinux/UnixœΒΆ≥ά¥¥φ¥ΔΡΩ¬ΦάοΟφ”– ≤Ο¥ΡΎ»ίΘ§»®œόΒ»ΒΡΜΚ¥φΘ§’βάο¥σΗ≈’Φ”Ο280MΘ§ΒΞΈΜΈΣKBΓΘ
cacheΘΚcache÷±Ϋ””Οά¥Φ«“δΈ“Ο«¥ρΩΣΒΡΈΡΦΰΘ§ΗχΈΡΦΰΉωΜΚ≥εΘ§’βάο¥σΗ≈’Φ”Ο280M(’βάο «Linux/UnixΒΡ¥œΟς÷°¥ΠΘ§Α―Ω’œ–ΒΡΈοάμΡΎ¥φΒΡ“Μ≤ΩΖ÷ΡΟά¥ΉωΈΡΦΰΓΔΡΩ¬ΦΚΆΫχ≥ΧΒΊ÷ΖΩ’ΦδΒΡΜΚ¥φΘ§ «ΈΣΝΥΧαΗΏ≥Χ–ρ÷¥––ΒΡ–‘ΡήΘ§Β±≥Χ–ρ Ι”ΟΡΎ¥φ ±Θ§buffer/cachedΜαΚήΩλΒΊ±Μ Ι”Ο)Θ§ΒΞΈΜΈΣKBΓΘ
siΘΚ ΟΩΟκ¥”¥≈≈ΧΕΝ»κ–ιΡβΡΎ¥φΒΡ¥σ–ΓΘ§»γΙϊ’βΗω÷Β¥σ”Ύ0Θ§±μ ΨΈοάμΡΎ¥φ≤ΜΙΜ”ΟΜρ’ΏΡΎ¥φ–Ι¬ΕΝΥΘ§“Σ≤ι’“ΚΡΡΎ¥φΫχ≥ΧΫβΨωΒτΓΘ±ΨΜζΡΎ¥φ≥δ‘ΘΘ§“Μ«–’ΐ≥ΘΘ§ΒΞΈΜΈΣKBΓΘ
soΘΚΟΩΟκ–ιΡβΡΎ¥φ–¥»κ¥≈≈ΧΒΡ¥σ–ΓΘ§»γΙϊ’βΗω÷Β¥σ”Ύ0Θ§Ά§…œΘ§ΒΞΈΜΈΣKBΓΘ
free

ΒΎΕΰ–– «ΡΎ¥φ–≈œΔΘ§totalΈΣΜζΤςΉήΡΎ¥φΘ§usedΈΣΕύ…Ό“―Ψ≠ Ι”ΟΘ§freeΈΣΕύ…ΌΩ’œ–Θ§sharedΈΣΕύΗωΫχ≥ΧΙ≤œμΒΡΡΎ¥φΉήΕνΘ§buffers”κcacheΕΦ «¥≈≈ΧΜΚ¥φΒΡ¥σ–ΓΘ§Ζ÷±πΆ§vmstatάοΟφΒΡbuff”κcache.
ΒΞΈΜΕΦ «M.
ΒΎ»ΐ–– «buffers”κcacheΉήΕνΒΡused”κfree. ΒΞΈΜΕΦ «M.
ΒΎΥΡ–– «ΫΜΜΜ«χswapΒΡΉήΕνΓΔ“―”Ο”κfree. ΒΞΈΜΕΦ «M.
«χ±πΘΚΒΎΕΰ––(mem)ΒΡused/free”κΒΎ»ΐ––(-/+ buffers/cache) used/freeΒΡ«χ±πΓΘ
’βΝΫΗωΒΡ«χ±π‘Ύ”Ύ Ι”ΟΒΡΫ«Ε»ά¥Ω¥Θ§ΒΎΕΰ–– «¥”OSΒΡΫ«Ε»ά¥Ω¥Θ§“ρΈΣΕ‘”ΎOSΘ§buffers/cached
ΕΦ « τ”Ύ±Μ Ι”ΟΘ§Υυ“‘ΥϊΒΡΩ…”ΟΡΎ¥φ «4353M, “―”ΟΡΎ¥φ «3519M, Τδ÷–Αϋά®Θ§ΡΎΚΥΘ®OSΘ© Ι”Ο+Application(X,
oracle,etc) Ι”ΟΒΡ+buffers+cached.
ΒΎ»ΐ––Υυ÷ΗΒΡ «¥””Π”Ο≥Χ–ρΫ«Ε»ά¥Ω¥Θ§Ε‘”Ύ”Π”Ο≥Χ–ρά¥ΥΒΘ§buffers/cached «Β»”ΎΩ…”ΟΒΡΘ§“ρΈΣbuffer/cached «ΈΣΝΥΧαΗΏΈΡΦΰΕΝ»ΓΒΡ–‘ΡήΘ§Β±”Π”Ο≥Χ–ρ–η‘Ύ”ΟΒΫΡΎ¥φΒΡ ±ΚρΘ§buffer/cachedΜαΚήΩλΒΊ±ΜΜΊ ’ΓΘ
Υυ“‘¥””Π”Ο≥Χ–ρΒΡΫ«Ε»ά¥ΥΒΘ§Ω…”ΟΡΎ¥φ=œΒΆ≥free memory+buffers+cachedΓΘ
top
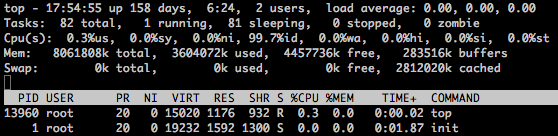
÷ΜΙΊΉΔ”κΡΎ¥φœύΙΊΒΡΆ≥ΦΤ–≈œΔΘ§Φ¥Mem”κSwap––ΓΘΖ÷±π «Mem”κSwapΒΡΉήΕνΓΔ“―”ΟΝΩΓΔΩ’œ–ΝΩΓΔbuffers”κcache.
’βάο±ψ―ι÷ΛΝΥbuffers «ΜΚ¥φΡΩ¬ΦάοΟφ”– ≤Ο¥ΡΎ»ίΘ§»®œόΒ»–≈œΔΒΡΘ§Εχcache «”Οά¥swapΒΡΜΚ¥φΒΡ.
cat /proc/meminfo
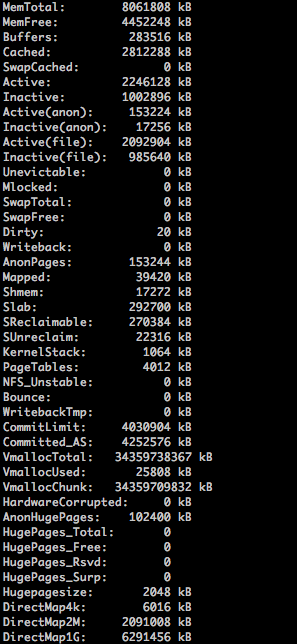
÷ς“Σ’βΦΗΗωΉ÷ΕΈΘΚ
MemTotalΘΚΡΎ¥φΉήΕν
MemFreeΘΚΡΎ¥φΩ’œ–ΝΩ
BuffersΘΚΆ§topΟϋΝνΒΡbuffers
CachedΘΚΆ§topΟϋΝνΒΡcache
SwapToatlΘΚSwap«χΉή¥σ–Γ
SwapFreeΘΚSwap«χΩ’œ–¥σ–Γ
3.Ζ÷Έω
±μ ΨœΒΆ≥Mem’ΐ≥ΘΘ§÷ς“Σ”–“‘œ¬Ιφ‘ρΘΚ
swap in (si) == 0Θ§swap out (so) == 0
Ω…”ΟΡΎ¥φ/ΈοάμΡΎ¥φ >= 30%
¥≈≈Χ
ΥΒΟς
ΜζΤςΒΡ¥≈≈ΧΩ’Φδ“≤ «“ΜΗω÷Ί“ΣΒΡ÷Η±ξΘ§“ΜΒ© Ι”Ο¬ ≥§Ιΐψ–÷ΒΕχ ΙΒΟΩ…”Ο≤ΜΉψΘ§Ρ«Ο¥ΨΆ–η“ΣΫχ––ά©»ίΜρ’Ώ«ε≥ΐ“Μ–©Έό”ΟΒΡΈΡΦΰΓΘ
≤ιΩ¥ΟϋΝν
df

FilesystemΘΚΈΡΦΰœΒΆ≥ΒΡΟϊ≥Τ
1K-blocksΘΚ1KΩιΒΡΈΡΦΰœΒΆ≥
UsedΘΚ“― Ι”ΟΝΩΘ§ΒΞΈΜΈΣKB
AvailableΘΚΩ’œ–ΝΩΘ§ΒΞΈΜΈΣKB
Use%ΘΚ“― Ι”Ο’Φ±»
Mounted onΘΚΙ“‘ΊΒΡΡΩ¬Φ
Ζ÷Έω
±μ ΨœΒΆ≥¥≈≈ΧΩ’Φδ’ΐ≥ΘΘ§÷ς“Σ”–“‘œ¬Ιφ‘ρΘΚ
Use% <= 90%
¥≈≈ΧI/O
ΥΒΟς
ΜζΤςΒΡ¥≈≈ΧΩ’Φδ“≤ «“ΜΗω÷Ί“ΣΒΡ÷Η±ξΘ§“ΜΒ©¥≈≈ΧI/OΙΐ÷ΊΘ§Ρ«Ο¥ΥΒΟς‘Υ––ΒΡΫχ≥Χ‘Ύ¥σΝΩΒΡΈΡΦΰΕΝ–¥≤Δ«“cacheΟϋ÷–¬ ΒΆΓΘΡ«Ο¥“ΜΗωΦρΒΞΒΡΖΫΖ®±ψ «‘ω¥σΈΡΦΰΜΚ¥φ¥σ–Γά¥ΧαΗΏΟϋ÷–¬ ¥”ΕχΫΒΒΆI/OΓΘ
‘ΎLinux÷–Θ§ΡΎΚΥœΘΆϊΡήΨΓΩ…Ρή≤ζ…ζ¥Έ»±“≥÷–ΕœΘ®¥”ΈΡΦΰΜΚ¥φ«χΕΝΘ©Θ§≤Δ«“ΡήΨΓΩ…Ρή±ήΟβ÷ς»±“≥÷–ΕœΘ®¥””≤≈ΧΕΝΘ©Θ§’β―υΥφΉ≈»±“≥÷–ΕœΒΡ‘ωΕύΘ§ΈΡΦΰΜΚ¥φ«χ“≤÷π≤Ϋ‘ω¥σΘ§÷±ΒΫœΒΆ≥÷Μ”–…ΌΝΩΩ…”ΟΈοάμΡΎ¥φΒΡ ±Κρ
Linux ≤≈ΩΣ Φ ΆΖ≈“Μ–©≤Μ”ΟΒΡ“≥ΓΘ“ΐ”Ο[1]
≤ιΩ¥ΟϋΝν
vmstat

bi ΘΚΩι…η±ΗΟΩΟκΫ” ’ΒΡΩι ΐΝΩΘ§’βάοΒΡΩι…η±Η «÷ΗœΒΆ≥…œΥυ”–ΒΡ¥≈≈ΧΚΆΤδΥϊΩι…η±ΗΘ§Ρ§»œΩι¥σ–Γ1024byteΓΘ
boΘΚΩι…η±ΗΟΩΟκΖΔΥΆΒΡΩι ΐΝΩΘ§άΐ»γΈ“Ο«ΕΝ»ΓΈΡΦΰΘ§boΨΆ“Σ¥σ”Ύ0ΓΘbiΚΆbo“ΜΑψΕΦ“ΣΫ”Ϋϋ0Θ§≤Μ»ΜΨΆ «IOΙΐ”ΎΤΒΖ±Θ§–η“ΣΒς’ϊΓΘ
iostat

LinuxΕΈΈΣΜζΤςœΒΆ≥–≈œΔΘΚ œΒΆ≥Οϊ≥ΤΓΔhostnameΓΔΒ±«Α ±ΦδΓΔœΒΆ≥Αφ±Ψ.
avg-cpuΕΈΈΣcpuΒΡΆ≥ΦΤ–≈œΔ(ΤΫΨυ÷Β)ΘΚ
%userΘΚ”ΟΜßΦΕ±π‘Υ––Υυ Ι”ΟΒΡCPUΒΡΑΌΖ÷±».
%niceΘΚnice≤ΌΉςΥυ Ι”ΟΒΡCPUΒΡΑΌΖ÷±».
%sysΘΚ‘ΎœΒΆ≥ΦΕ±π(kernel)‘Υ––Υυ Ι”ΟCPUΒΡΑΌΖ÷±».
%iowaitΘΚCPUΒ»¥ΐ”≤ΦΰI/O ±,Υυ’Φ”ΟCPUΑΌΖ÷±».
%idleΘΚCPUΩ’œ– ±ΦδΒΡΑΌΖ÷±».
DeviceΕΈΕΈΈΣ…η±Η–≈œΔ(…œΆΦ÷–”–ΝΫΗω≈Χvda”κvdb)ΘΚ
tps: ΟΩΟκ÷”ΖΔΥΆΒΫΒΡI/O«κ«σ ΐ.
Blk_read/s: ΟΩΟκΕΝ»ΓΒΡblock ΐ.
Blk_wrtn/s: ΟΩΟκ–¥»κΒΡblock ΐ.
Blk_read: ΕΝ»κΒΡblockΉή ΐ.
Blk_wrtn: –¥»κΒΡblockΉή ΐ.
sar -d 1 1

sar -d±μ Ψ≤ιΩ¥¥≈≈Χ±®Ηφ 1 1 ±μ ΨΦδΗτ1sΘ§‘Υ––1¥Έ
Τδ ΒcpuΓΔΜΚ¥φ«χΓΔΈΡΦΰΕΝ–¥ΓΔœΒΆ≥ΫΜΜΜ«χΒ»–≈œΔΕΦΩ…“‘Ά®ΙΐΗΟΟϋΝν≤ιΩ¥Θ§÷Μ «―Γœν≤ΜΆ§Θ§ΨΏΧε≤ΈΦϊΘΚhttp://blog.chinaunix.net/uid-23177306-id-2531032.html
ΒΎ“ΜΗωΕΈΈΣΜζΤςœΒΆ≥–≈œΔΘ§Ά§iostat
ΒΎΕΰΗωΕΈΈΣΟΩ¥Έ‘Υ––ΒΡdev I/O–≈œΔΘ§’βάο“ρΈΣ÷Μ‘Υ––“Μ¥ΈΘ§≤Δ”–ΝΫΗω…η±Ηdev252-0”κdev252-16ΘΚ
tpsΘΚΟΩΟκ¥”Έοάμ¥≈≈ΧI/OΒΡ¥Έ ΐ.ΕύΗω¬ΏΦ≠«κ«σΜα±ΜΚœ≤ΔΈΣ“ΜΗωI/O¥≈≈Χ«κ«σ,“Μ¥Έ¥Ϊ δΒΡ¥σ–Γ «≤Μ»ΖΕ®ΒΡ.
rd_sec/sΘΚΟΩΟκΕΝ…»«χ ΐ
wr_sec/sΘΚΟΩΟκ–¥…»«χ ΐ
avgrq-szΘΚΤΫΨυΟΩ¥Έ…η±ΗI/O≤ΌΉςΒΡ ΐΨί¥σ–Γ (…»«χ)
avgqu-szΘΚΤΫΨυI/OΕ”Ν–≥ΛΕ»
awaitΘΚΈΣΤΫΨυΟΩ¥Έ…η±ΗI/O≤ΌΉςΒΡΒ»¥ΐ ±Φδ(ΒΞΈΜms)Θ§Αϋά®«κ«σ‘ΎΕ”Ν–÷–ΒΡΒ»¥ΐ ±ΦδΚΆΖΰΈώ ±Φδ
svctmΘΚΈΣΤΫΨυΟΩ¥Έ…η±ΗI/O≤ΌΉςΒΡΖΰΈώ ±Φδ(ΒΞΈΜms)
%utilΘΚ±μ Ψ“ΜΟκ÷–”–ΑΌΖ÷÷°ΦΗΒΡ ±Φδ”Ο”ΎI/O≤ΌΉς
»γΙϊsvctmΒΡ÷Β”κawaitΚήΫ”ΫϋΘ§±μ ΨΦΗΚθΟΜ”–I/OΒ»¥ΐΘ§¥≈≈Χ–‘ΡήΚήΚΟΘ§»γΙϊawaitΒΡ÷Β‘ΕΗΏ”ΎsvctmΒΡ÷ΒΘ§‘ρ±μ ΨI/OΕ”Ν–Β»¥ΐΧΪ≥ΛΘ§œΒΆ≥…œ‘Υ––ΒΡ”Π”Ο≥Χ–ρΫΪ±δ¬ΐΓΘ
»γΙϊ%utilΫ”Ϋϋ100%Θ§±μ Ψ¥≈≈Χ≤ζ…ζΒΡI/O«κ«σΧΪΕύΘ§I/OœΒΆ≥“―Ψ≠¬ζΗΚΚ…ΒΡ‘ΎΙΛΉςΘ§ΗΟ¥≈≈Χ«κ«σ±ΞΚΆΘ§Ω…Ρή¥φ‘ΎΤΩΨ±ΓΘidle–Γ”Ύ70%
I/O―ΙΝΠΨΆΫœ¥σΝΥΘ§“≤ΨΆ «”–ΫœΕύΒΡI/OΓΘ“ΐ”Ο[1]
Ά§ ±Ω…“‘ΫαΚœvmstat ≤ιΩ¥b≤Έ ΐ(Β»¥ΐΉ ‘¥ΒΡΫχ≥Χ ΐ)ΚΆwa≤Έ ΐ(IOΒ»¥ΐΥυ’Φ”ΟΒΡCPU ±ΦδΒΡΑΌΖ÷±»Θ§ΗΏΙΐ30% ±IO―ΙΝΠΗΏ)ΓΘ“ΐ”Ο[1]
Ζ÷Έω
±μ ΨœΒΆ≥¥≈≈ΧΩ’Φδ’ΐ≥ΘΘ§÷ς“Σ”–“‘œ¬Ιφ‘ρΘΚ
I/OΒ»¥ΐΒΡ«κ«σ±»άΐ <= 20%
ΧαΗΏΟϋ÷–¬ ΒΡ“ΜΗωΦρΒΞΖΫ ΫΨΆ «‘ω¥σΈΡΦΰΜΚ¥φ«χΟφΜΐΘ§ΜΚ¥φ«χ‘Ϋ¥σ‘Λ¥φΒΡ“≥ΟφΨΆ‘ΫΕύΘ§Οϋ÷–¬ “≤‘ΫΗΏΓΘ
Linux ΡΎΚΥœΘΆϊΡήΨΓΩ…Ρή≤ζ…ζ¥Έ»±“≥÷–ΕœΘ®¥”ΈΡΦΰΜΚ¥φ«χΕΝΘ©Θ§≤Δ«“ΡήΨΓΩ…Ρή±ήΟβ÷ς»±“≥÷–ΕœΘ®¥””≤≈ΧΕΝΘ©Θ§’β―υΥφΉ≈¥Έ»±“≥÷–ΕœΒΡ‘ωΕύΘ§ΈΡΦΰΜΚ¥φ«χ“≤÷π≤Ϋ‘ω¥σΘ§÷±ΒΫœΒΆ≥÷Μ”–…ΌΝΩΩ…”ΟΈοάμΡΎ¥φΒΡ ±Κρ
Linux ≤≈ΩΣ Φ ΆΖ≈“Μ–©≤Μ”ΟΒΡ“≥ΓΘ“ΐ”Ο[1]
Άχ¬γI/O
ΥΒΟς
»γΙϊΖΰΈώΤςΆχ¬γΝ§Ϋ”ΙΐΕύΘ§Ρ«Ο¥Μα‘λ≥…¥σΝΩΒΡ ΐΨίΑϋ‘ΎΜΚ≥ε«χ≥Λ ±ΦδΒΟ≤ΜΒΫ¥ΠάμΘ§“ΜΒ©ΜΚ≥ε«χ≤ΜΉψΘ§±ψΜα‘λ≥… ΐΨίΑϋΕΣ ßΈ ΧβΘ§Ε‘”ΎTCPΘ§ ΐΨίΑϋΕΣ ß±ψΜαΫχ––÷Ί¥ΪΘ§’β”–ΜαΒΦ÷¬¥σΝΩΒΡ÷Ί¥ΪΘΜΕ‘”ΎUDPΘ§ ΐΨίΑϋΕΣ ß≤ΜΜαΫχ––÷Ί¥ΪΘ§Ρ«Ο¥ ΐΨί±ψΜαΕΣ ßΓΘ“ρ¥ΥΘ§ΖΰΈώΤςΒΡΆχ¬γΝ§Ϋ”≤Μ“ΥΙΐΕύΘ§–η“ΣΫχ––ΦύΩΊΓΘ
ΖΰΈώΤς“ΜΑψΫ” ’UDP”κTCP«κ«σΘ§ΕΦ «ΈόΉ¥Χ§Ν§Ϋ”Θ§TCP(¥Ϊ δΩΊ÷Τ–≠“ι) «“Μ÷÷ΧαΙ©Ω…ΩΩΒΡ ΐΨί¥Ϊ δ–≠“ιΘ§UDP(”ΟΜß ΐΨί±®–≠“ι) «“Μ÷÷ΟφœρΈόΝ§Ϋ”ΒΡ–≠“ιΘ§Φ¥Τδ¥Ϊ δΦρΒΞΒΪ≤ΜΩ…ΩΩΓΘΙΊ”ΎΥϋΟ«Εΰ’Ώ÷°ΦδΒΡ«χ±πΘ§Ω…“‘≤ι‘ΡœύΙΊΉ ΝœΓΘ
≤ιΩ¥ΟϋΝν
netstat
UDP
(1) netstat -ludp | grep udp

ProtoΘΚ–≠“ιΟϊ
Recv-QΘΚ ’ΒΫΒΡ«κ«σΗω ΐ
Send-QΘΚΖΔΥΆΒΡ«κ«σΗω ΐ
Local AddressΘΚ±ΨΒΊΒΊ÷Ζ”κΕΥΩΎ
Foreign AddressΘΚ‘Ε≥ΧΒΊ÷Ζ”κΕΥΩΎ
StateΘΚΉ¥Χ§
PID/Program nameΘΚΫχ≥ΧID”κΫχ≥ΧΟϊ
(2) Ϋχ“Μ≤Ϋ≤ιΩ¥UDPΫ” ’ΒΡ ΐΨίΑϋ«ιΩω netstat -su
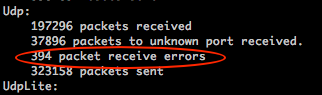
Μ≠»ΠΒΡ±ψ «UDP ΐΨίΑϋΕΣ ßΆ≥ΦΤΘ§ΗΟœν÷Β‘ωΦ”ΝΥΘ§ΥΒΟς¥φ‘Ύudp ΐΨίΑϋΕΣ ßΘ§Φ¥ΆχΩ® ’ΒΫΝΥΘ§ΒΪ «”Π”Ο≤ψΟΜ”–ά¥ΒΟΦΑ¥ΠάμΕχ‘λ≥…ΒΡΕΣΑϋΓΘ
TCP
(1) netstat

ΗςΉ÷ΕΈΚ§“εΆ§UDP
(2) ≤ιΩ¥÷Ί¥Ϊ¬
“ρΈΣTCP «Ω…ΩΩ¥Ϊ δ–≠“ιΘ§»γΙϊ ΐΨίΑϋΕΣ ßΜαΫχ––÷Ί¥ΪΘ§“ρ¥ΥTCP–η“Σ≤ιΩ¥Τδ÷Ί¥Ϊ¬ .
cat /proc/net/snmp | grep Tcp

Ρ«Ο¥÷Ί¥Ϊ¬ ΈΣRetransSegs/OutSegs
Ζ÷Έω
UDPΕΣΑϋ¬ Μρ’ΏTCP÷Ί¥Ϊ¬ ≤ΜΡήΗΏ”ΎΕύ…ΌΘ§’βΝΫΗω÷Β”…œΒΆ≥ΩΣΖΔΕ®“εΘ§¥Υ¥ΠΘ§≈ΡΡ‘¥ϋΨωΕ®UDPΑϋΕΣΑϋ¬ ”κTCPΑϋ÷Ί¥Ϊ¬ ≤ΜΡή≥§Ιΐ1%/sΓΘ
Ν§Ϋ” ΐ
ΥΒΟς
Ε‘”ΎΟΩ“ΜΧ®ΖΰΈώΤςΘ§ΕΦ”ΠΗΟœό÷ΤΆ§ ±Ν§Ϋ” ΐΘ§ΒΪ «’βΗωψ–÷Β”÷≤ΜΚΟ»ΖΕ®Θ§“ρ¥ΥΒ±Φύ≤βΒΫœΒΆ≥ΗΚ‘ΊΙΐ÷Ί ±Θ§»ΜΚσ»ΓΤδΝ§Ϋ” ΐΘ§’βΗω÷Β±ψΩ…ΉςΈΣ≤ΈΩΦ÷ΒΓΘ
ΟϋΝν
netstat
| netstat
-na | sed -n '3,$p' |awk '{print $5}' | grep
-v 127\.0\.0\.1 | grep -v 0\.0\.0\.0 | wc -l
|

Ζ÷Έω
œΒΆ≥ΗΚ‘ΊΙΐ÷Ί ±Θ§ΗΟ÷ΒΉςΈΣΖΰΈώΤςΒΡΖε÷Β≤ΈΩΦ÷ΒΓΘ
»γΙϊ≥§Ιΐ1024±®Ψ·
ΈΡΦΰΨδ±ζ ΐ
ΥΒΟς
ΈΡΦΰΨδ±ζ ΐΦ¥Β±«Α¥ρΩΣΒΡΈΡΦΰ ΐΘ§Ε‘”ΎlinuxΘ§œΒΆ≥Ρ§»œ÷ß≥÷ΒΡΉν¥σΨδ±ζ ΐ «1024Θ§Β±»ΜΟΩΗωœΒΆ≥Ω…“‘≤Μ“Μ―υΘ§“≤Ω…“‘–όΗΡΘ§Ήν¥σ≤ΜΡή≥§ΙΐΈόΖϊΚ≈’ϊ–ΆΉν¥σ÷Β(65535)Θ§Ω…“‘ Ι”Οulimit
-nΟϋΝνΫχ––≤ιΩ¥Θ§Φ¥“ρ¥Υ»γΙϊΆ§ ±¥ρΩΣΒΡΈΡΦΰ ΐ≥§Ιΐ’βΗω ΐ±ψΜαΖΔ…ζ“λ≥ΘΓΘ“ρ¥Υ’βΗω÷Η±ξ“≤–η“ΣΫχ––ΦύΩΊΓΘ
≤ιΩ¥ΟϋΝν
lsof
| lsof
-n | awk '{print $1,$2}' | sort | uniq -c |
sort -nr |
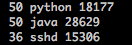
»ΐΝ–Ζ÷±π «¥ρΩΣΒΡΈΡΦΰΨδ±ζ ΐ, Ϋχ≥ΧΟϊΘ§Ϋχ≥ΧΚ≈
Ζ÷Έω
ΫΪΥυ”–ΒΡ––ΒΡΒΎ“ΜΝ–œύΦ”±ψ «œΒΆ≥ΡΩ«Α¥ρΩΣΒΡΈΡΦΰΨδ±ζ ΐnumΘ§»γΙϊnum<=max_num*85%‘ρ±®Ψ·ΓΘ
–‘Ρή÷Η±ξΉήΫα
CPU
CPUάϊ”Ο¬ ΘΚus <= 70Θ§sy <= 35Θ§us + sy <= 70ΓΘ
…œœ¬ΈΡ«–ΜΜΘΚ”κCPUάϊ”Ο¬ œύΙΊΝΣΘ§»γΙϊCPUάϊ”Ο¬ Ή¥Χ§ΝΦΚΟΘ§¥σΝΩΒΡ…œœ¬ΈΡ«–ΜΜ“≤ «Ω…“‘Ϋ” ήΒΡΓΘ
Ω…‘Υ––Ε”Ν–ΘΚΟΩΗω¥ΠάμΤςΒΡΩ…‘Υ––Ε”Ν–<=3ΗωœΏ≥ΧΓΘ
Memory
swap in (si) == 0Θ§swap out (so) == 0
Ω…”ΟΡΎ¥φ/ΈοάμΡΎ¥φ >= 30%
Disk
Use% <= 90%
Disk I/O
I/OΒ»¥ΐΒΡ«κ«σ±»άΐ <= 20%
Network I/O
UDPΑϋΕΣΑϋ¬ ”κTCPΑϋ÷Ί¥Ϊ¬ ≤ΜΡή≥§Ιΐ1%/sΓΘ
Connect Num
<= 1024
File Handle Num
num/max_num <= 90%
ΉήΫα
Ϋ≈±ΨΦλ≤βnginxΓΔtomcat”κwebapp‘Υ––“λ≥Θ»’÷Ψ(Αϋά®nginx”κtomcat «Ζώ’ΐ‘Ύ‘Υ––)”κΖΰΈώΤς–‘ΡήΤΏΗω÷Η±ξΘ§“ΜΒ©ΖΔœ÷“λ≥Θ–≈œΔΚΆ–‘Ρή≥§±ξΘ§Ρ«Ο¥¬μ…œΖΔΥΆ” ΦΰΗχΙήάμ‘±Θ§“≤Ω…“‘ Ι”Ο‘ΤΦύΩΊpushΗχΙήάμ‘±ΒΡ‘Τ’ΥΚ≈ΓΘ
|









