| ±ύΦ≠ΆΤΦω: |
| ±ΨΈΡά¥Ή‘”ΎΆχ¬γΘ§±ΨΈΡœξœΗΫι…ήΝΥΆ®”Ο÷ΊΕ®œρΓΔ¥ζάμ÷ΊΕ®œρΓΔΜΚ¥φ÷ΊΕ®œρ“‘ΦΑΗΚ‘ΊΨυΚβΒ»œύΙΊ÷Σ ΕΓΘ |
|
«ΑΟφΒΡΜΑ
HTTP≤Δ≤Μ «ΕάΉ‘‘Υ––‘ΎΆχ…œΒΡΓΘΚήΕύ–≠“ιΕΦΜα‘ΎHTTP±®ΈΡΒΡ¥Ϊ δΙΐ≥Χ÷–Ε‘Τδ ΐΨίΫχ––ΙήάμΓΘHTTP÷ΜΙΊ–Ρ¬Ο≥ΧΒΡΕΥΒψ(ΖΔΥΆ’ΏΚΆΫ” ’’Ώ)Θ§ΒΪ‘ΎΑϋΚ§”–ΨΒœώΖΰΈώΤςΓΔWeb¥ζάμΚΆΜΚ¥φΒΡΆχ¬γ άΫγ÷–Θ§HTTP±®ΈΡΒΡΡΩΒΡΒΊ≤Μ“ΜΕ® «÷±Ϋ”Ω…¥οΒΡ
÷ΊΕ®œρΦΦ θΆ®≥ΘΩ…“‘”Οά¥»ΖΕ®±®ΈΡ «Ζώ÷’Ϋα”ΎΡ≥Ηω¥ζάμΓΔΜΚ¥φΜρΖΰΈώΤςΦ·»Κ÷–Ρ≥Χ®ΧΊΕ®ΒΡΖΰΈώΤςΓΘ÷ΊΕ®œρΦΦ θΩ…“‘ΫΪ±®ΈΡΖΔΥΆΒΫΩΆΜßΕΥΟΜ”–œ‘ Ϋ«κ«σΒΡΒΊΖΫ»ΞΓΘ±ΨΈΡΫΪœξœΗΫι…ή÷ΊΕ®œρΦΦ θ“‘ΦΑΗΚ‘ΊΨυΚβ
Ήήά®
”…”ΎHTTP”Π”Ο≥Χ–ρ–η“ΣΩ…ΩΩΒΊ÷¥––HTTP ¬ΈώΘ§Ήν–ΓΜ· ±―”Θ§≤Δ«“ΫΎ‘ΦΆχ¬γ¥χΩμΘ§Υυ“‘‘Ύœ÷¥ζΆχ¬γ÷–÷ΊΕ®œρ «Τ’±ι¥φ‘ΎΒΡ
≥ω”Ύ’β–©‘≠“ρΘ§WebΡΎ»ίΆ®≥ΘΖ÷≤Φ‘ΎΚήΕύΒΊΖΫΓΘ’βΟ¥Ήω «≥ω”ΎΩ…ΩΩ–‘ΒΡΩΦ¬«ΓΘ’β―υΘ§»γΙϊ“ΜΗωΈΜ÷Ο≥ωΈ ΧβΝΥΘ§ΜΙ”–ΤδΥϊΒΡΩ…”ΟΘ§»γΙϊΩΆΜßΕΥΡή»ΞΖΟΈ ΫœΫϋΒΡΉ ‘¥Θ§ΨΆΩ…“‘ΗϋΩλΒΊ ’ΒΫΥυ«κ«σΒΡΡΎ»ίΘ§“‘ΫΒΒΆœλ”Π ±ΦδΘΜΫΪΡΩ±ξΖΰΈώΤςΖ÷…ΔΘ§ΜΙΩ…“‘Φθ…ΌΆχ¬γ”Β»ϊΓΘΩ…“‘ΫΪ÷ΊΕ®œρΒ±Ής“ΜΉι”–÷ζ”Ύ’“ΒΫΓΑΉνΦ―Γ±Ζ÷≤Φ ΫΡΎ»ίΒΡΦΦ θ
¥σΕύ ΐ÷ΊΕ®œρ≤Ω πΕΦΑϋΚ§Ρ≥–©–Έ ΫΒΡΗΚ‘ΊΨυΚβΓΘ“≤ΨΆ «ΥΒΘ§ΥϋΟ«Ω…“‘ΫΪ δ»κ±®ΈΡΒΡΗΚ‘ΊΖ÷Χ·ΒΫ“ΜΉιΖΰΈώΤς÷–»ΞΓΘΖ¥÷°Θ§“ρΈΣ δ»κ±®ΈΡ“ΜΕ®Μα‘ΎΖ÷ΒΘΗΚΚ…ΒΡΖΰΈώΤς÷°ΦδΫχ––Ρ≥÷÷Ζ÷≤ΦΘ§Υυ“‘»Έ“β–Έ ΫΒΡΗΚ‘ΊΨυΚβΕΦΑϋΚ§ΝΥ÷ΊΕ®œρ
¥”ΩΆΜßΕΥœρΡΩ±ξΖΔΥΆHTTP«κ«σΘ§ΡΩ±ξΕ‘ΤδΫχ––¥ΠάμΒΡΫ«Ε»ά¥Ω¥Θ§ΖΰΈώΤςΓΔ¥ζάμΓΔΜΚ¥φΚΆΆχΙΊΕ‘ΩΆΜßΕΥά¥ΥΒΕΦ «ΖΰΈώΤςΓΘΚήΕύ÷ΊΕ®œρΦΦ θΕΦΩ…”Ο”ΎΖΰΈώΤςΓΔ¥ζάμΓΔΜΚ¥φΚΆΆχΙΊΘ§“ρΈΣΥϋΟ«ΨΏ”–Ι≤Ά§ΒΡΘ§”κΖΰΈώΤςάύΥΤΒΡΧΊ’ςΓΘΤδΥϊ“Μ–©÷ΊΕ®œρΦΦ θ «Ή®Ο≈ΈΣΧΊΕ®άύ–ΆΒΡΕΥΒψ…ηΦΤΒΡΘ§ΟΜ”–Ά®”Ο–‘
WebΖΰΈώΤςΜαΗυΨίΟΩΗωIPά¥¥Πάμ«κ«σΓΘΫΪ«κ«σΖ÷Χ·ΒΫΗ¥÷ΤΒΡΖΰΈώΤς÷–»ΞΘ§ΨΆ“βΈΕΉ≈”ΠΗΟΑ―Ε‘Ρ≥ΧΊΕ®URLΒΡΟΩΧθ«κ«σΕΦΖΔΥΆΒΫΉνΦ―ΒΡWebΖΰΈώΤς…œ»Ξ(ΉνΩΩΫϋΩΆΜßΕΥΒΡΓΔΜρΗΚ‘ΊΉν«αΒΡΜρ≤…”ΟΤδΥϊ”≈Μ·≤Ώ¬‘―Γ‘ώΒΡΖΰΈώΤς)ΓΘ÷ΊΕ®œρΒΫΡ≥Χ®ΖΰΈώΤςΨΆœώΫΪΥυ”––η“ΣΗχΤϊ≥ΒΦ””ΆΒΡΥΨΜζΕΦΥΆΒΫΉνΫϋΒΡΦ””Ά’Ψ»Ξ“Μ―υ
¥ζάμœΘΆϊΗυΨίΟΩΗω–≠“ιά¥¥Πάμ«κ«σΓΘ‘Ύάμœκ«ιΩωœ¬Θ§Ρ≥Ηω¥ζάμΗΫΫϋΒΡΥυ”–HTTPΝςΝΩΕΦ”ΠΗΟΆ®Ιΐ’βΗω¥ζάμ¥Ϊ δΓΘ±»»γΘ§»γΙϊΡ≥¥ζάμΜΚ¥φΩΩΫϋΗς÷÷≤ΜΆ§ΒΡΩΆΜßΕΥΘ§Ρ«Ο¥άμœκ«ιΩωœ¬Θ§Υυ”–«κ«σΕΦ”ΠΝςΨ≠’βΗω¥ζάμΜΚ¥φΘ§“ρΈΣ¥ζάμΜΚ¥φ…œΜα¥φ¥Δ≥Θ”ΟΒΡΈΡΒΒΘ§Ω…“‘÷±Ϋ”ΧαΙ©Θ§¥”Εχ±ήΟβΆ®ΙΐΗϋ≥ΛΓΔΗϋΑΚΙσΒΡ¬ΖΨΕΝ§Ϋ”ΒΫ‘≠ ΦΖΰΈώΤςΓΘ÷ΊΕ®œρΒΫ¥ζάμΨΆœώ¥”“ΜΧθ÷ς“ΣΆ®¬Ζ(Έό¬έΥϋΆ®ΆυΚΈ¥Π)…œΫΪΝςΝΩΖ÷ΝςΒΫ“ΜΧθ±ΨΒΊΩλΫί¬ΖΨΕ…œ»Ξ“Μ―υ
÷ΊΕ®œρΒΡΡΩ±ξ «ΨΓΩλΒΊΫΪHTTP±®ΈΡΖΔΥΆΒΫΩ…”ΟΒΡWebΖΰΈώΤς…œ»ΞΓΘ‘Ύ¥©Ιΐ“ρΧΊΆχΒΡ¬ΖΨΕ…œΘ§HTTP±®ΈΡ¥Ϊ δΒΡΖΫœρΜα ήΒΫHTTP”Π”Ο≥Χ–ρΚΆ±®ΈΡΨ≠”…ΒΡ¬Ζ”……η±ΗΒΡ”Αœλ
≈δ÷Ο¥¥Ϋ®ΩΆΜßΕΥ±®ΈΡΒΡδ·άάΤς”Π”Ο≥Χ–ρΘ§ ΙΤδΫΪ±®ΈΡΖΔΥΆΗχ¥ζάμΖΰΈώΤςΘΜDNSΫβΈω≥Χ–ρΜα―Γ‘ώ”Ο”Ύ±®ΈΡ―Α÷ΖΒΡIPΒΊ÷ΖΓΘΕ‘≤ΜΆ§ΈοάμΒΊ”ρΒΡ≤ΜΆ§ΩΆΜßΕΥά¥ΥΒΘ§’βΗωIPΒΊ÷ΖΩ…Ρή≤ΜΆ§ΘΜ±®ΈΡΨ≠ΙΐΆχ¬γ¥Ϊ δ ±Θ§Μα±ΜΜ°Ζ÷ΈΣ“Μ–©¥χ”–ΒΊ÷ΖΒΡΖ÷ΉιΘ§ΫΜΜΜΜζΚΆ¬Ζ”…ΤςΜαΦλ≤ιΖ÷Ήι÷–ΒΡTCP/IPΒΊ÷ΖΘ§≤ΔΨί¥Υά¥»ΖΕ®Ζ÷ΉιΒΡΖΔΥΆ¬ΖœΏΘΜWebΖΰΈώΤςΩ…“‘Ά®ΙΐHTTP÷ΊΕ®œρΫΪ«κ«σΖ¥Β·Ηχ≤ΜΆ§ΒΡWebΖΰΈώΤςΘΜδ·άάΤς≈δΝDΓΔDNSΓΔTCP/IP¬Ζ”…“‘ΦΑHTTPΕΦΧαΙ©ΝΥ÷ΊΕ®œρ±®ΈΡΜζ÷Τ
[ΉΔ“β]”––©ΖΫΖ®Θ§±»»γδ·άάΤς≈δ÷ΟΘ§÷Μ”–‘ΎΫΪΝςΝΩ÷ΊΕ®œρΒΫ¥ζάμΒΡ ±Κρ≤≈”–“β“εΘ§ΕχΤδΥϊ“Μ–©ΖΫΖ®(±»»γDNS÷ΊΕ®œρ)Θ§‘ρΩ…”Ο”ΎΫΪΝςΝΩΖΔΥΆΗχ»Έ“βΖΰΈώΤς
÷Ί–¥œρΖΫΖ®Αϋά®Ά®”Ο÷ΊΕ®œρΓΔ¥ζάμ÷ΊΕ®œρΦΑΜΚ¥φ÷ΊΕ®œρΒ»
Ά®”Ο÷ΊΕ®œρ
Ω…“‘Ά®ΙΐΆ®”Ο÷ΊΕ®œρΖΫΖ®ΫΪΝςΝΩ÷ΊΕ®œρΒΫ≤ΜΆ§ΒΡ(Ω…ΡήΗϋ”≈ΒΡ)ΖΰΈώΤςΘ§Μρ’ΏΆ®Ιΐ¥ζάμά¥ΉΣΖΔΝςΝΩΓΘΨΏΧεά¥ΥΒΘ§Αϋά®HTTP÷ΊΕ®œρΓΔDNS÷ΊΕ®œρΓΔ»Έ≤Ξ―Α÷ΖΓΔIP
MACΉΣΖΔ“‘ΦΑIPΒΊ÷ΖΉΣΖΔ
ΓΨHTTP ÷ΊΕ®œρΓΩ
WebΖΰΈώΤςΩ…“‘ΫΪΕΧΒΡ÷ΊΕ®œρ±®ΈΡΖΔΜΊΗχΩΆΜßΕΥΘ§ΗφΥΏΥϊΟ«»ΞΤδΥϊΒΊΖΫ ‘ ‘ΓΘ”––©Web’ΨΒψΜαΫΪHTTP÷ΊΕ®œρΉςΈΣ“Μ÷÷ΦρΒΞΒΡΗΚ‘ΊΨυΚβ–Έ Ϋά¥ Ι”ΟΓΘ¥Πάμ÷ΊΕ®œρΒΡΖΰΈώΤς(÷ΊΕ®œρΖΰΈώΤς)’“ΒΫΩ…”ΟΒΡΗΚ‘ΊΉν–ΓΒΡΡΎ»ίΖΰΈώΤςΘ§≤ΔΫΪδ·άάΤς÷ΊΕ®œρΒΫΡ«Χ®ΖΰΈώΤς…œ»Ξ
Ε‘ΙψΖΚΖ÷≤ΦΒΡWeb’ΨΒψά¥ΥΒΘ§»ΖΕ®ΓΑΉνΦ―Γ±ΒΡΩ…”ΟΖΰΈώΤςΜαΗϋΗ¥‘”“Μ–©Θ§≤ΜΫω“ΣΩΦ¬«ΒΫΖΰΈώΤςΒΡΗΚ‘ΊΘ§ΜΙ“ΣΩΦ¬«ΒΫδ·άάΤςΚΆΖΰΈώΤς÷°ΦδΒΡ“ρΧΊΆχΨύάκΓΘ”κΤδΥϊ“Μ–©–Έ ΫΒΡ÷ΊΕ®œρœύ±»Θ§HTTP÷ΊΕ®œρΒΡ”≈Βψ÷°“ΜΨΆ «÷ΊΕ®œρΖΰΈώΤς÷ΣΒάΩΆΜßΕΥΒΡIPΒΊ÷ΖΘ§άμ¬έ…œά¥Ϋ≤Θ§ΥϋΩ…“‘Ήω≥ωΗϋΚœάμΒΡ―Γ‘ώ
œ¬Οφ «HTTP÷ΊΕ®œρΒΡΙΛΉςΙΐ≥Χ
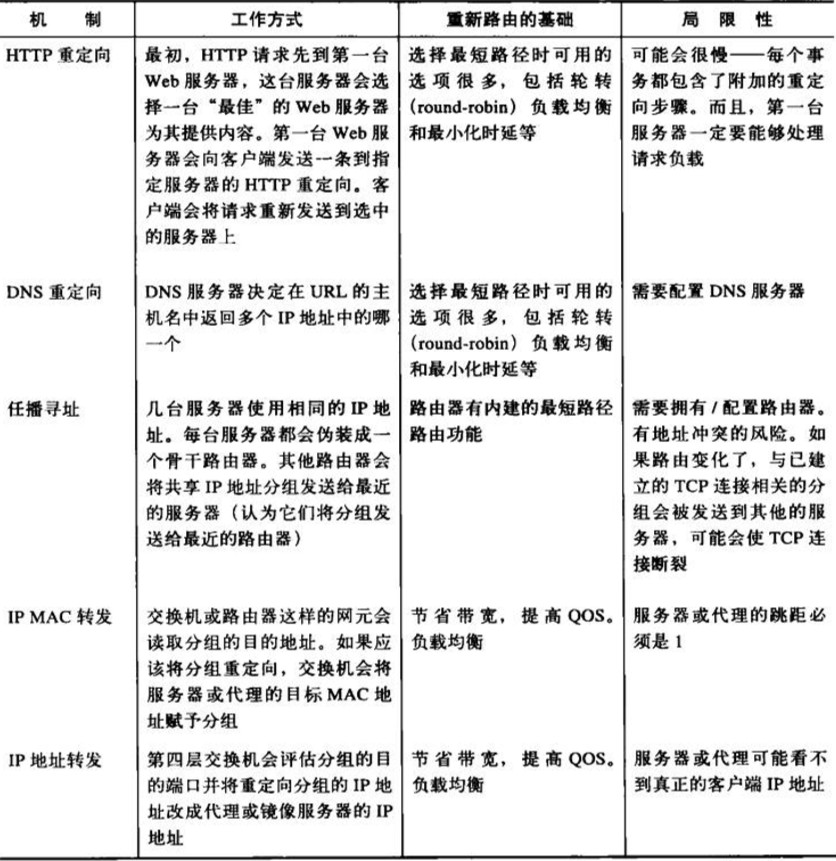
‘ΎΆΦa÷–Θ§Aliceœρwww.joes-hardware.comΖΔΥΆΝΥ“ΜΧθ«κ«σ
GET /hammers.html
HTTP/1.0
Host: www.joes-hardware.com
User-Agent: Mozilla/4.51 [en] (X11; U; IRIX 6.2
IP22) |
‘ΎΆΦb÷–Θ§ΖΰΈώΤςΟΜ”–ΜΊΥΆ¥χ”–HTTPΉ¥Χ§¬κ200ΒΡWeb“≥Οφ÷ςΧεΘ§Εχ «ΜΊΥΆΝΥ“ΜΗω¥χ”–HTTPΉ¥Χ§¬κ302ΒΡ÷ΊΕ®œρ±®ΈΡ
HTTP/1.0 302
Redirect
Server: Stronghold/2.4.2 Apache/1.3.6
Location: http://161.58.228.45/hammers.html |
œ÷‘ΎΘ§‘ΎΆΦc÷–Θ§δ·άάΤςΜα”Ο÷ΊΕ®œρURL÷Ί–¬ΖΔΥΆ«κ«σΘ§’β¥ΈΜαΖΔΥΆΗχ÷ςΜζ161.58.228.45
GET /hammers.html
HTTP/1.0
Host: 161.58.228.45
User-Agent: Mozilla/4.51 [en] (X11; U; IRIX 6.2
IP22) |
Νμ“ΜΗωΩΆΜßΕΥΩ…ΡήΜα±Μ÷ΊΕ®œρΒΫΝμ“ΜΧ®ΖΰΈώΤς…œ»ΞΓΘ‘ΎΆΦd-f÷–Θ§BobΒΡ«κ«σΜα±Μ÷ΊΕ®œρΒΫ161.58.228.46
HTTP÷ΊΕ®œρΩ…“‘‘ΎΖΰΈώΤςΦδΒΦ“ΐ«κ«σΘ§ΒΪΥϋ”–“‘œ¬ΦΗΗω»±ΒψΘΚ–η“Σ‘≠ ΦΖΰΈώΤςΫχ––¥σΝΩ¥Πάμά¥≈–Εœ“Σ÷ΊΕ®œρΒΫΡΡΧ®ΖΰΈώΤς…œ»ΞΓΘ”– ±Θ§ΖΔ≤Φ÷ΊΕ®œρΥυ–ηΒΡ¥ΠάμΝΩΦΗΚθ”κΧαΙ©“≥Οφ±Ψ…μΥυ–ηΒΡ¥ΠάμΝΩ“Μ―υΘΜ‘ωΦ”ΝΥ”ΟΜß ±―”Θ§“ρΈΣΖΟΈ “≥Οφ ±“ΣΫχ––ΝΫ¥ΈΆυΖΒΘΜ»γΙϊ÷ΊΕ®œρΖΰΈώΤς≥ωΙ ’œΘ§’ΨΒψΨΆΜαΧ±ΜΨ
”…”Ύ¥φ‘Ύ’β–©»θΒψΘ§HTTP÷ΊΕ®œρΆ®≥ΘΕΦΜα”κΤδΥϊ“Μ÷÷ΜρΕύ÷÷÷ΊΕ®œρΦΦ θΫαΚœ Ι”Ο
ΓΨDNS÷ΊΕ®œρΓΩ
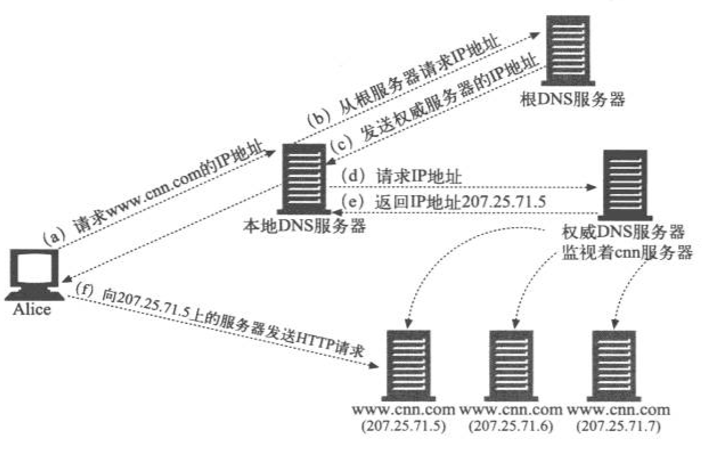
ΟΩ¥ΈΩΆΜßΕΥ ‘ΆΦΖΟΈ JoeΒΡΈεΫπ…ΧΒξΒΡΆχ’Ψ ±Θ§ΕΦ±Ί–κΫΪ”ρΟϊwww.joes-hardware.comΫβΈωΈΣIPΒΊ÷ΖΓΘDNSΫβΈω≥Χ–ρΩ…Ρή «ΩΆΜßΕΥΉ‘ΦΚΒΡ≤ΌΉςœΒΆ≥Θ§Ω…Ρή «ΩΆΜßΕΥΆχ¬γ÷–ΒΡ“ΜΧ®DNSΖΰΈώΤςΘ§Μρ’Ώ «“ΜΧ®‘ΕΨύάκΒΡDNSΖΰΈώΤς
DNS‘ –μΫΪΦΗΗωIPΒΊ÷ΖΙΊΝΣΒΫ“ΜΗω”ρ÷–Θ§Ω…“‘≈δ÷ΟDNSΫβΈω≥Χ–ρΘ§ΜρΕ‘ΤδΫχ––±ύ≥ΧΘ§“‘ΖΒΜΊΩ…±δΒΡIPΒΊ÷ΖΓΘΫβΈω≥Χ–ρΖΒΜΊIPΒΊ÷Ζ ±ΥυΜυ”ΎΒΡ‘≠‘ρΩ…“‘ΚήΦρΒΞ(¬÷ΉΣ)Θ§“≤Ω…“‘ΚήΗ¥‘”(±»»γ≤ιΩ¥ΦΗΧ®ΖΰΈώΤς…œΒΡΗΚ‘ΊΘ§≤ΔΖΒΜΊΗΚ‘ΊΉν«αΒΡΖΰΈώΤςΒΡIPΒΊ÷Ζ)
‘Ύœ¬ΆΦ÷–Θ§JoeΈΣwww.joes-hardware.com‘Υ––ΝΥ4Χ®ΖΰΈώΤςΓΘDNSΖΰΈώΤς“ΣΨωΕ®ΈΣwww.joes-hardware.comΖΒΜΊ4ΗωIPΒΊ÷Ζ÷–ΒΡΡΡ“ΜΗωΓΘΉνΦρΒΞΒΡDNSΨω≤ΏΥψΖ®ΨΆ «¬÷ΉΣ
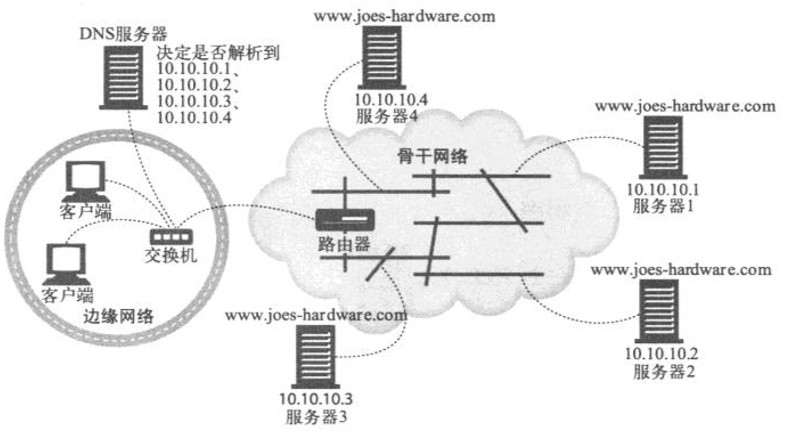
1ΓΔDNS¬÷ΉΣ
DNS¬÷ΉΣ «Ήν≥ΘΦϊΒΡ÷ΊΕ®œρΦΦ θ÷°“Μ“≤ «ΉνΦρΒΞΒΡ÷ΊΕ®œρΦΦ θ÷°“ΜΓΘDNS¬÷ΉΣ Ι”ΟΝΥDNS÷ςΜζΟϊΫβΈω÷–ΒΡ“ΜœνΧΊ–‘Θ§‘ΎWebΖΰΈώΤςΦ·»Κ÷–ΤΫΚβΗΚ‘ΊΓΘ’β «“Μ÷÷ΒΞ¥ΩΒΡΗΚ‘ΊΨυΚβ≤Ώ¬‘Θ§ΟΜ”–ΩΦ¬«»ΈΚΈ”κΩΆΜßΕΥΚΆΖΰΈώΤςΒΡœύΕ‘ΈΜ÷ΟΘ§Μρ’ΏΖΰΈώΤςΒ±«ΑΗΚ‘Ί”–ΙΊΒΡ“ρΥΊ
Έ“Ο«ά¥Ω¥Ω¥CNN.com ΒΦ …œΕΦΉωΝΥ–© ≤Ο¥ΓΘΈ“Ο«”ΟUnix÷–ΒΡΙΛΨΏnslookupά¥≤ι’“”κCNN.comœύΙΊΒΡIPΒΊ÷ΖΓΘœ¬ΟφΗχ≥ωΝΥΫαΙϊ
% nslookup www.cnn.com
Name: cnn.com
Addresses: 207.25.71.9, 207.25.71.12, 207.25.71.20,
207.25.71.22, 207.25.71.23, 207.25.71.24, 207.25.71.25,
207.25.71.26, 207.25.71.27, 207.25.71.28, 207.25.71.29,
207.25.71.30, 207.25.71.82, 207.25.71.199, 207.25.71.245,
207.25.71.246
Aliases: www.cnn.com |
Άχ’Ψwww.cnn.com ΒΦ …œ «20Ηω≤ΜΆ§ΒΡIPΒΊ÷ΖΉι≥…ΒΡΦ·»ΚΓΘΟΩΗωIPΒΊ÷ΖΆ®≥ΘΕΦ“βΈΕΉ≈“ΜΧ®≤ΜΆ§ΒΡΈοάμΖΰΈώΤς
2ΓΔΕύΗωΒΊ÷ΖΦΑ¬÷ΉΣΒΊ÷ΖΒΡ―≠ΜΖ
¥σΕύ ΐDNSΩΆΜßΕΥ÷ΜΜα Ι”ΟΕύΒΊ÷ΖΦ·÷–ΒΡΒΎ“ΜΗωΒΊ÷ΖΓΘΈΣΝΥΨυΚβΗΚ‘ΊΘ§¥σΕύ ΐDNSΖΰΈώΤςΕΦΜα‘ΎΟΩ¥ΈΆξ≥…≤ι―·÷°ΚσΕ‘ΒΊ÷ΖΫχ––¬÷ΉΣΓΘ’β÷÷ΒΊ÷Ζ¬÷ΉΣΆ®≥Θ≥ΤΉςDNS¬÷ΉΣ
άΐ»γΘ§Ε‘www.crni.comΫχ––»ΐ¥ΈΝ§–χΒΡDNS≤ι’“Ω…ΡήΜαΖΒΜΊœ¬ΟφΗχ≥ωΒΡIPΒΊ÷Ζ¬÷ΉΣΝ–±μ
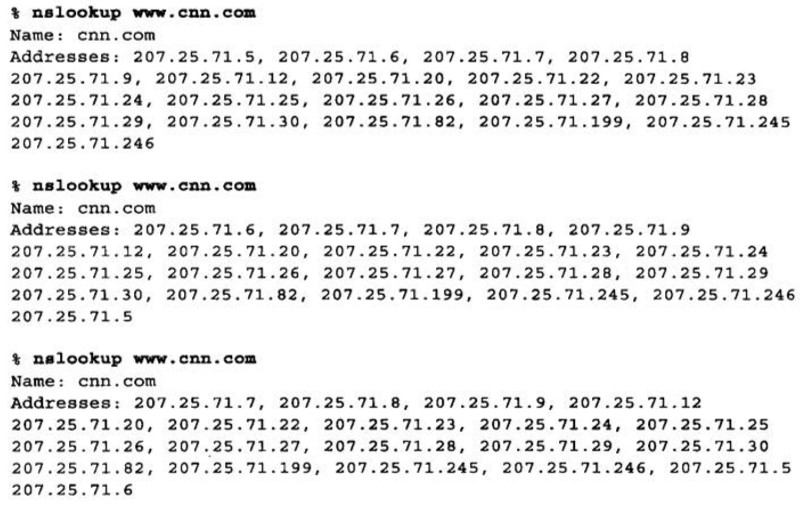
ΒΎ“Μ¥ΈDNS≤ι’“ ±ΒΡΒΎ“ΜΗωΒΊ÷ΖΈΣ207.25.71.5ΘΜΒΎΕΰ¥ΈDNS≤ι’“ ±ΒΡΒΎ“ΜΗωΒΊ÷ΖΈΣ207.25.71.6ΘΜΒΎ»ΐ¥ΈDNS≤ι’“ ±ΒΡΒΎ“ΜΗωΒΊ÷ΖΈΣ207.25.71.7
3ΓΔ”Οά¥ΤΫΚβΗΚ‘ΊΒΡDNS¬÷ΉΣ
”…”Ύ¥σΕύ ΐDNSΩΆΜßΕΥ÷Μ Ι”ΟΒΎ“ΜΗωΒΊ÷ΖΘ§Υυ“‘DNS¬÷ΉΣΩ…“‘‘ΎΕύΧ®ΖΰΈώΤςΦδΧαΙ©ΗΚ‘ΊΨυΚβΓΘ»γΙϊDNSΟΜ”–Ε‘ΒΊ÷ΖΫχ––¬÷ΉΣΘ§¥σ≤ΩΖ÷ΩΆΜßΕΥΨΆΉή «ΜαΫΪΗΚ‘ΊΖΔΥΆΗχΒΎ“ΜΧ®ΖΰΈώΤς
œ¬ΆΦΥΒΟςΝΥDNS¬÷ΉΣ―≠ΜΖ «»γΚΈΤΫΚβΗΚ‘ΊΒΡ
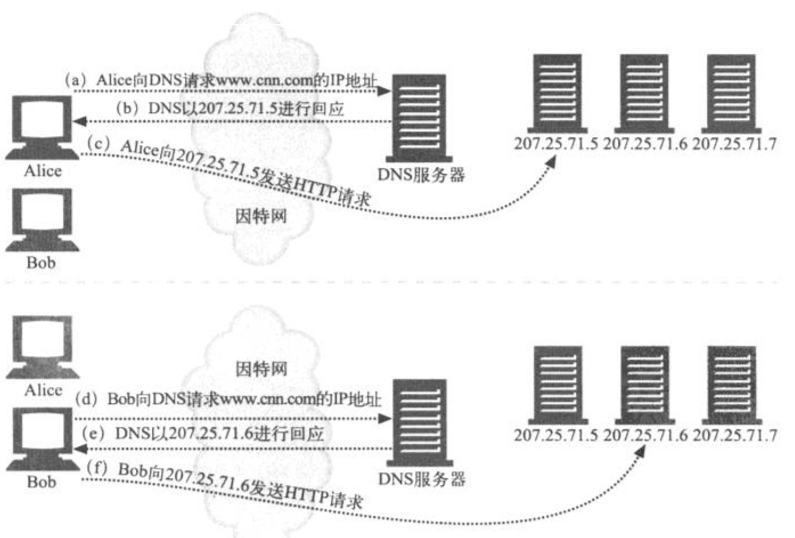
Alice ‘ΆΦΝ§Ϋ”www.cnn.com ±Θ§Μα”ΟDNS≤ι’“IPΒΊ÷ΖΘ§ΒΟΒΫ207.25.71.5Ής
ΈΣΒΎ“ΜΗω1PΒΊ÷ΖΓΘ‘ΎΆΦc÷–Θ§AliceΝ§Ϋ”ΒΫWebΖΰΈώΤς207.25.71.5
BobΥφΚσ ‘ΆΦΝ§Ϋ”www.cnn.com ±Θ§“≤Μα”ΟDNS≤ι’“IPΒΊ÷ΖΘ§ΒΪ”…”ΎΒΊ÷ΖΝ–±μ‘ΎAlice…œ¥Έ«κ«σΒΡΜυ¥Γ…œ¬÷ΉΣΝΥ“ΜΗωΈΜ÷ΟΘ§Υυ“‘ΥϊΜαΒΟΒΫ“ΜΗω≤ΜΆ§ΒΡΫαΙϊΓΘBobΒΟΒΫ207.25.71.6ΉςΈΣΒΎ“ΜΗωIPΒΊ÷ΖΘ§‘ΎΆΦf÷–ΥϋΝ§Ϋ”ΒΫΝΥ’βΧ®ΖΰΈώΤς…œ
4ΓΔ DNSΜΚ¥φ¥χά¥ΒΡ”Αœλ
DNSΕ‘ΖΰΈώΤςΒΡΟΩ¥Έ≤ι―·ΕΦΜαΒΟΒΫ≤ΜΆ§ΒΡΖΰΈώΤςΒΊ÷Ζ–ρΝ–Θ§Υυ“‘DNSΒΊ÷Ζ¬÷ΉΣΜαΫΪΗΚ‘ΊΖ÷Χ·ΓΘΒΪ «’β÷÷ΗΚ‘ΊΨυΚβ≤Δ≤ΜΆξΟάΘ§“ρΈΣDNS≤ι’“ΒΡΫαΙϊΩ…ΡήΜα±ΜΦ«ΉΓΘ§≤Δ±ΜΗς÷÷”Π”Ο≥Χ–ρΓΔ≤ΌΉςœΒΆ≥ΚΆ“Μ–©Φρ“ΉΒΡΉ”DNSΖΰΈώΤς÷Ί”ΟΓΘΚήΕύWebδ·άάΤςΕΦΜαΕ‘÷ςΜζΫχ––DNS≤ι’“Θ§»ΜΚσ“Μ¥Έ¥ΈΒΊ Ι”ΟœύΆ§ΒΡΒΊ÷ΖΘ§“‘Φθ…ΌDNS≤ι’“ΒΡΩΣœζΘ§Εχ«“”––©ΖΰΈώΤς“≤Ηϋ‘Η“β±Θ≥÷”κΆ§“ΜΧ®ΩΆΜßΕΥΒΡΝΣœΒΓΘΝμΆβΘ§ΚήΕύ≤ΌΉςœΒΆ≥ΕΦΜαΉ‘Ε·Ϋχ––DNS≤ι’“Θ§≤ΔΫΪΫαΙϊΜΚ¥φΘ§ΒΪ≤Δ≤ΜΜαΕ‘ΒΊ÷ΖΫχ––¬÷ΉΣΓΘ“ρ¥ΥΘ§DNS¬÷ΉΣΆ®≥ΘΕΦ≤ΜΜαΤΫΚβΒΞΗωΩΆΜßΕΥΒΡΗΚ‘ΊΓΣΓΣ“ΜΗωΩΆΜßΕΥΆ®≥ΘΜα‘ΎΚή≥Λ ±ΦδΡΎΝ§Ϋ”ΒΫ“ΜΧ®ΖΰΈώΤς…œ
ΨΓΙήDNSΟΜ”–Ε‘ΒΞΗωΩΆΜßΕΥΒΡ ¬ΈώΫχ––ΩγΖΰΈώΤςΗ±±ΨΒΡ¥ΠάμΘ§ΒΪ‘ΎΖ÷…ΔΕύΗωΩΆΜßΕΥΒΡΉήΗΚΚ…ΖΫΟφΥϋΉωΒΟœύΒ±ΚΟΓΘ÷Μ“Σ”–¥σΝΩΨΏ”–œύΆ§–η«σΒΡΩΆΜßΕΥΘ§ΨΆΩ…“‘ΫΪΗΚ‘ΊΚœάμΒΊΖ÷…ΔΒΫΗςΗωΖΰΈώΤς…œ»Ξ
5ΓΔΤδΥϊΜυ”ΎDNSΒΡ÷ΊΕ®œρΥψΖ®
«ΑΟφΧ÷¬έΝΥDNS «»γΚΈΕ‘ΟΩΧθ«κ«σΫχ––ΒΊ÷ΖΝ–±μ¬÷ΉΣΒΡΓΘΒΪ «Θ§”––©‘ω«ΩΒΡDNSΖΰΈώΤςΜα Ι”ΟΤδΥϊ“Μ–©ΦΦ θά¥―Γ‘ώΒΊ÷ΖΒΡΥ≥–ρ
aΓΔΗΚ‘ΊΨυΚβΥψΖ®
”––©DNSΖΰΈώΤςΜαΗζΉΌWebΖΰΈώΤς…œΒΡΗΚ‘ΊΘ§ΫΪΗΚ‘ΊΉν«αΒΡWebΖΰΈώΤςΖ≈‘ΎΝ–±μΒΡΉν«ΑΟφ
bΓΔΝΎΫ”¬Ζ”…ΥψΖ®
WebΖΰΈώΤςΦ·»Κ‘ΎΒΊάμ…œΖ÷…Δ ±Θ§DNSΖΰΈώΤςΜα≥Δ ‘Ή≈ΫΪ”ΟΜßΒΦœρΉνΫϋΒΡWeb
ΖΰΈώΤς
cΓΔΙ ’œΤΝ±ΈΥψΖ®
DNSΖΰΈώΤςΩ…“‘Φύ ”Άχ¬γΒΡΉ¥ΩωΘ§≤ΔΫΪ«κ«σ»ΤΙΐ≥ωœ÷ΖΰΈώ÷–ΕœΜρΤδΥϊΙ ’œΒΡ
ΒΊΖΫ
Ά®≥ΘΘ§‘Υ––Η¥‘”ΖΰΈώΤςΗζΉΌΥψΖ®ΒΡDNSΖΰΈώΤςΨΆ «‘ΎΡΎ»ίΧαΙ©’ΏΩΊ÷Τ÷°œ¬ΒΡ“ΜΗω»®ΆΰΖΰΈώΤς
”–“Μ–©Ζ÷≤Φ Ϋ÷ςΜζΖΰΈώΜα Ι”Ο’βΗωDNS÷ΊΕ®œρΡΘ–ΆΓΘΕ‘”ΎΡ«–©“Σ≤ι’“ΗΫΫϋΖΰΈώΤςΒΡΖΰΈώά¥ΥΒΘ§’βΗωΡΘ–ΆΒΡ“ΜΗω»±ΒψΨΆ «Θ§»®ΆΰDNSΖΰΈώΤς÷ΜΡή”Ο±ΨΒΊDNSΖΰΈώΤςΒΡIPΒΊ÷ΖΘ§Εχ≤ΜΡή”ΟΩΆΜßΕΥΒΡIPΒΊ÷Ζά¥ΉωΨωΕ®
ΓΨ»Έ≤Ξ―Α÷ΖΓΩ
‘Ύ»Έ≤Ξ―Α÷Ζ÷–Θ§ΦΗΗωΒΊάμ…œΖ÷…ΔΒΡWebΖΰΈώΤς”Β”–Άξ»ΪœύΆ§ΒΡIPΒΊ÷ΖΘ§Εχ«“ΜαΆ®ΙΐΙ«Η…¬Ζ”…ΤςΒΡΓΑΉνΕΧ¬ΖΨΕΓ±¬Ζ”…ΙΠΡήΫΪΩΆΜßΕΥΒΡ«κ«σΖΔΥΆΗχάκΥϋΉνΫϋΒΡΖΰΈώΤς
“Σ Ι’β÷÷ΖΫΖ®ΙΛΉςΘ§ΟΩΧ®ΖΰΈώΤςΕΦ“ΣœρΝΎΫϋΒΡΙ«Η…¬Ζ”…ΤςΙψΗφΘ§±μΟςΉ‘ΦΚ «“ΜΧ®¬Ζ”…ΤςΓΘWebΖΰΈώΤςΜαΆ®Ιΐ¬Ζ”…ΤςΆ®–≈–≠“ι”κΤδΝΎΫϋΒΡΙ«Η…¬Ζ”…ΤςΆ®–≈ΓΘΙ«Η…¬Ζ”…Τς ’ΒΫΖΔΥΆΗχ»Έ≤ΞΒΊ÷ΖΒΡΖ÷Ήι ±Θ§Μα(œώΤΫ≥Θ“Μ―υ)―Α’“Ϋ” ήΡ«ΗωIPΒΊ÷ΖΒΡΉνΫϋΒΡ
ΓΑ¬Ζ”…ΤςΓ±ΓΘ”…”ΎΖΰΈώΤς «ΫΪΉ‘ΦΚΉςΈΣΡ«ΗωΒΊ÷ΖΒΡ¬Ζ”…ΤςΙψΗφ≥ω»ΞΒΡΘ§Υυ“‘Ι«Η…¬Ζ”…ΤςΜαΫΪΖ÷ΉιΖΔΥΆΗχΖΰΈώΤς
œ¬ΆΦ÷–Θ§»ΐΧ®ΖΰΈώΤςΈΣΆ§“ΜΗωIPΒΊ÷Ζ10.10.10.1ΖΰΈώΓΘ¬ε…ΦμΕ(LA)ΖΰΈώΤςΫΪ¥ΥΒΊ÷ΖΙψΗφΗχLA¬Ζ”…ΤςΘ§≈Π‘Φ(NY)ΖΰΈώΤςΆ§―υΫΪ¥ΥΒΊ÷ΖΙψΗφΗχNY¬Ζ”…ΤςΘ§“‘¥ΥάύΆΤΓΘΖΰΈώΤςΜαΆ®Ιΐ¬Ζ”…Τς–≠“ι”κ¬Ζ”…ΤςΫχ––Ά®–≈ΓΘ¬Ζ”…ΤςΜαΫΪΡΩ±ξΈΣ10.10.10.1ΒΡΩΆΜßΕΥ«κ«σΉ‘Ε·ΒΊΉΣΖΔΒΫΙψΗφ’βΗωΒΊ÷ΖΒΡΉνΫϋΒΡΖΰΈώΤς…œ»ΞΓΘΕ‘IPΒΊ÷Ζ10.10.10.1ΒΡ«κ«σΜα±ΜΉΣΖΔΗχΖΰΈώΤς3
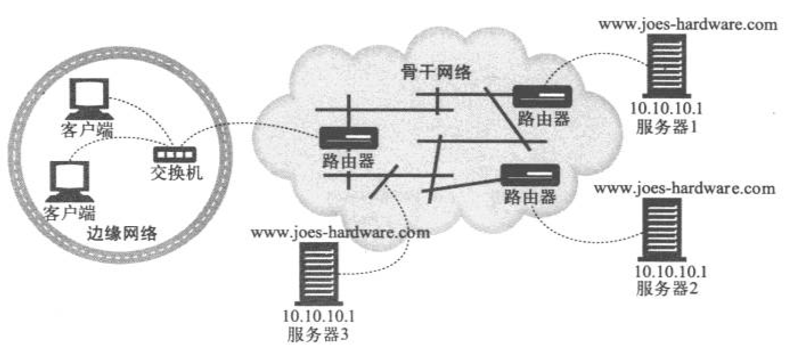
»Έ≤Ξ―Α÷Ζ»‘»Μ «œν Β―ι–‘ΦΦ θΓΘ“Σ Ι”ΟΖ÷≤Φ Ϋ»Έ≤ΞΦΦ θΘ§ΖΰΈώΤςΨΆ±Ί–κΓΑ Ι”Ο¬Ζ”…Τς”ο―‘Γ±Θ§Εχ«“¬Ζ”…Τς±Ί–κΡήΙΜ¥ΠάμΩ…Ρή≥ωœ÷ΒΡΒΊ÷Ζ≥εΆΜΘ§“ρΈΣ“ρΧΊΆχΒΊ÷ΖΜυ±Ψ…œΕΦ «ΦΌΕ®“ΜΧ®ΖΰΈώΤς÷Μ”–“ΜΗωΒΊ÷ΖΒΡΓΘ(»γΙϊΟΜ”–’ΐ»ΖΒΊ Βœ÷Θ§Ω…ΡήΜα‘λ≥…Κή―œ÷ΊΒΡ
ΓΑ¬Ζ”…–Ι¬ΕΓ±Έ ΧβΓΘ)Ζ÷≤Φ Ϋ»Έ≤Ξ «“Μ÷÷–¬–ΥΦΦ θΘ§Ω…“‘ΈΣΡ«–©Ή‘ΦΚΩΊ÷ΤΙ«Η…Άχ¬γΒΡΡΎ»ίΧαΙ©…ΧΧαΙ©“Μ÷÷ΫβΨωΖΫΑΗ
ΓΨIP MACΉΣΖΔΓΩ
‘Ύ“‘ΧΪΆχ÷–Θ§HTTP±®ΈΡΕΦ «“‘–·¥χΒΊ÷ΖΒΡ ΐΨίΖ÷ΉιΒΡ–Έ ΫΖΔΥΆΒΡΓΘΟΩΗωΖ÷ΉιΕΦ”–“ΜΗωΒΎΥΡ≤ψΒΊ÷ΖΘ§”…‘¥IPΒΊ÷ΖΓΔΡΩΒΡIPΒΊ÷Ζ“‘ΦΑTCPΕΥΩΎΚ≈Ήι≥…Θ§Υϋ «ΒΎΥΡ≤ψ…η±ΗΥυΙΊΉΔΒΡΒΊ÷ΖΓΘΟΩΗωΖ÷ΉιΜΙ”–“ΜΗωΒΎΕΰ≤ψΒΊ÷ΖΘ§MAC(Media
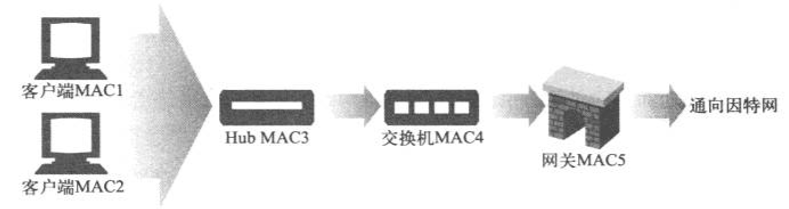
Access Control,ΟΫΧεΖΟΈ ΩΊ÷Τ)ΒΊ÷ΖΘ§’β «ΒΎΕΰ≤ψ…η±Η(Ά®≥Θ «ΫΜΜΜΜζΚΆHub)ΥυΙΊΉΔΒΡΒΊ÷ΖΓΘΒΎΕΰ≤ψ…η±ΗΒΡ»ΈΈώ «Ϋ” ’ΨΏ”–ΧΊΕ® δ»κMACΒΊ÷ΖΒΡΖ÷ΉιΘ§»ΜΚσΫΪΤδΉΣΖΔΒΫΧΊΕ®ΒΡ δ≥ωMACΒΊ÷Ζ…œ»Ξ
±»»γΘ§œ¬ΆΦΫΜΜΜΜζΒΡ≥Χ–ρΜαΫΪά¥Ή‘MACΒΊ÷ΖMAC3ΒΡΥυ”–ΝςΝΩΕΦΖΔΥΆΒΫMACΒΊ÷ΖMAC4…œ»Ξ
ΒΎΥΡ≤ψΫΜΜΜΜζΡήΙΜΦλ≤β≥ωΒΎΥΡ≤ψΒΊ÷Ζ(IPΒΊ÷ΖΚΆTCPΕΥΩΎΚ≈)Θ§≤ΔΨί¥Υά¥―Γ‘ώ¬Ζ”…ΓΘ±»»γΘ§“ΜΧ®ΒΎΥΡ≤ψΫΜΜΜΜζΩ…“‘ΫΪΥυ”–ΡΩΒΡΈΣΕΥΩΎ80ΒΡWebΝςΝΩΕΦΖΔΥΆΒΫΡ≥Ηω¥ζάμ…œ»ΞΓΘ‘Ύœ¬ΆΦ÷–Θ§±ύ–¥ΫΜΜΜΜζ≥Χ–ρΘ§ΫΪMAC3…œΥυ”–ΕΥΩΎ80ΒΡΝςΝΩΕΦΉΣΖΔΒΫMAC6(¥ζάμΜΚ¥φ)…œ»ΞΓΘMAC3…œΥυ”–ΤδΥϊΝςΝΩΕΦΜα±ΜΉΣΖΔΒΫMAC5…œ»Ξ
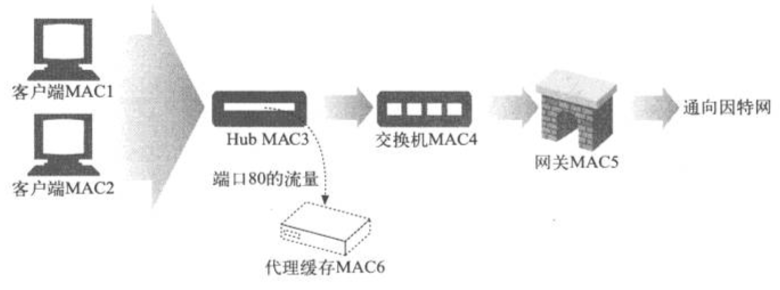
Ά®≥ΘΘ§»γΙϊΜΚ¥φ÷–”–Υυ«κ«σΒΡHTTPΡΎ»ίΘ§Εχ«“ «–¬œ ΒΡΘ§Ρ«Ο¥ΨΆ”…¥ζάμΜΚ¥φά¥ΧαΙ©ΡΎ»ίΓΘΖώ‘ρΘ§¥ζάμΜΚ¥φΨΆΜα¥ζ±μΩΆΜßΕΥœρ¥ΥΡΎ»ίΒΡ‘≠ ΦΖΰΈώΤςΖΔΥΆ“ΜΧθHTTP«κ«σΓΘΫΜΜΜΜζΜαΫΪΕΥΩΎ80ΒΡ«κ«σ¥”¥ζάμ(MAC6)ΖΔΥΆΗχ“ρΧΊΆχΆχΙΊ(MAC5)
÷ß≥÷MACΉΣΖΔΒΡΒΎΥΡ≤ψΫΜΜΜΜζΆ®≥ΘΜαΫΪ«κ«σΉΣΖΔΗχΦΗΗω¥ζάμΜΚ¥φΘ§≤Δ‘ΎΥϋΟ«÷°ΦδΤΫΚβΗΚ‘ΊΓΘάύΥΤΒΊΘ§“≤Ω…“‘ΫΪHTTPΝςΝΩΉΣΖΔΗχ±Η”ΟHTTPΖΰΈώΤςΓΘ“ρΈΣMACΒΊ÷ΖΉΣΖΔ÷Μ «ΒψΕ‘ΒψΒΡΘ§Υυ“‘ΖΰΈώΤςΜρ¥ζάμ÷ΜΡήΈΜ”ΎάκΫΜΜΜΜζ“ΜΧχ‘ΕΒΡΒΊΖΫ
ΓΨIPΒΊ÷ΖΉΣΖΔΓΩ
‘ΎIPΒΊ÷ΖΉΣΖΔ÷–Θ§ΫΜΜΜΜζΜρΤδΥϊΒΎΥΡ≤ψ…η±ΗΜαΦλ≤β δ»κΖ÷Ήι÷–ΒΡTCP/IPΒΊ÷ΖΘ§≤ΔΆ®Ιΐ–όΗΡΡΩΒΡIPΒΊ÷Ζ(≤Μ «ΡΩΒΡMACΒΊ÷Ζ)Θ§Ε‘Ζ÷ΉιΫχ––œύ”ΠΒΡΉΣΖΔΓΘ”κMACΉΣΖΔœύ±»Θ§’βΟ¥ΉωΒΡ”≈Βψ «ΡΩ±ξΖΰΈώΤς≤Μ–η“ΣΈΜ”Ύ“ΜΧχ‘ΕΒΡΒΊΖΫΘΜ÷Μ–η“ΣΈΜ”ΎΫΜΜΜΜζΒΡ…œ”ΈΨΆ––ΝΥΘ§Εχ«“Ά®≥ΘΒΎ»ΐ≤ψΒΡΕΥΒΫΕΥ“ρΧΊΆχ¬Ζ”…ΕΦΜαΫΪΖ÷Ήι¥ΪΥΆΒΫ’ΐ»ΖΒΡΒΊΖΫΓΘ’β÷÷άύ–ΆΒΡΉΣΖΔ“≤±Μ≥ΤΈΣNAT(Network
Address Translation,Άχ¬γΒΊ÷ΖΉΣΜΜ)
ΒΪΜΙ”–“ΜΗωΈ ΧβΘ§ΨΆ «Ε‘≥Τ¬Ζ”…ΓΘ¥”ΩΆΜßΕΥΫ” ή δ»κTCPΝ§Ϋ”ΒΡΫΜΜΜΜζΙήάμΉ≈Ν§Ϋ”Θ§ΫΜΜΜΜζ±Ί–κΆ®ΙΐΡ«ΧθTCPΝ§Ϋ”ΫΪœλ”ΠΜΊΥΆΗχΩΆΜßΕΥΓΘ’β―υΘ§Υυ”–ά¥Ή‘ΡΩ±ξΖΰΈώΤςΜρ¥ζάμΒΡœλ”ΠΕΦ±Ί–κΖΒΜΊΗχΫΜΜΜΜζ
”–“‘œ¬ΝΫ÷÷ΖΫ ΫΩ…“‘ΩΊ÷Τœλ”ΠΒΡΖΒΜΊ¬ΖΨΕ
1ΓΔΫΪΖ÷ΉιΒΡ‘¥IPΒΊ÷ΖΗΡ≥…ΫΜΜΜΜζΒΡIPΒΊ÷ΖΓΘΆ®Ιΐ’β÷÷ΖΫ ΫΘ§Έό¬έΫΜΜΜΜζΚΆΖΰΈώΤς÷°Φδ≤…”ΟΚΈ÷÷Άχ¬γ≈δ÷ΟΘ§œλ”ΠΖ÷ΉιΕΦΜα±ΜΖΔΥΆΗχΫΜΜΜΜζΓΘ’β÷÷ΖΫ Ϋ±Μ≥ΤΈΣΆξ»ΪNAT(full
NAT)Θ§Τδ÷–ΒΡIPΉΣΖΔ…η±ΗΜαΕ‘ΡΩΒΡIPΒΊ÷ΖΚΆ‘¥IPΒΊ÷ΖΕΦΫχ––ΉΣΜΜ
’β―υΉωΒΡ»±Βψ «ΖΰΈώΤς≤Μ÷ΣΒάΩΆΜßΕΥΒΡIPΒΊ÷ΖΘ§Ρ«÷÷–η“Σ»œ÷ΛΚΆΦΤΖ―ΒΡWebΖΰΈώΤςΈόΖ®Μώ÷ΣΩΆΜßΕΥΒΡIPΒΊ÷Ζ
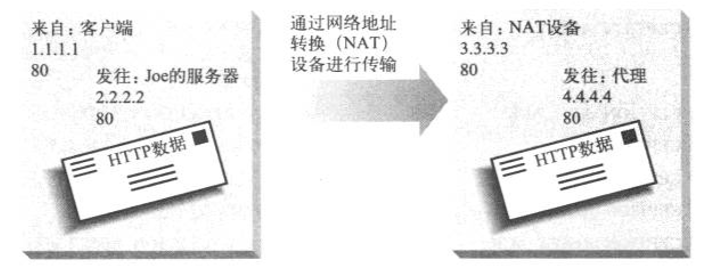
2ΓΔ»γΙϊ‘¥IPΒΊ÷Ζ»‘»Μ «ΩΆΜßΕΥΒΡIPΒΊ÷ΖΘ§ΨΆ“Σ»Ζ±Θ(¥””≤ΦΰΒΡΫ«Ε»ά¥Ω¥)ΟΜ”–¥”ΖΰΈώΤςΒΫΩΆΜßΕΥΒΡ÷±Ϋ”¬Ζ”…(»ΤΙΐΫΜΜΜΜζΒΡ)ΓΘ’β÷÷ΖΫ Ϋ”– ±±Μ≥ΤΈΣΑκNAT(half
NAT)ΓΘ’β÷÷ΖΫΖ®ΒΡ”≈Βψ «ΖΰΈώΤς÷ΣΒάΩΆΜßΕΥΒΡIPΒΊ÷ΖΘ§ΒΪ»±Βψ «“ΣΕ‘ΩΆΜßΕΥΚΆΖΰΈώΤς÷°ΦδΒΡ’ϊΗωΆχ¬γΕΦ”–Ρ≥÷÷≥ΧΕ»ΒΡΩΊ÷Τ
ΓΨΆχ‘ΣΩΊ÷Τ–≠“ιΓΩ
NECP(Network Element Control Protocol,Άχ‘ΣΩΊ÷Τ–≠“ι)‘ –μΆχ‘Σ(NE,¬Ζ”…ΤςΚΆΫΜΜΜΜζΒ»ΗΚ‘πΉΣΖΔIPΖ÷ΉιΒΡ…η±Η)”κΖΰΈώΤς‘ΣΥΊ(SE,WebΖΰΈώΤςΚΆ¥ζάμΜΚ¥φΒ»ΧαΙ©”Π”Ο≤ψ«κ«σΒΡ…η±Η)Ϋχ––ΫΜΜΞΓΘNECP≤ΔΈ¥œ‘ ΫΧαΙ©Ε‘ΗΚ‘ΊΨυΚβΒΡ÷ß≥÷Θ§Υϋ÷Μ «ΈΣSEΧαΙ©ΝΥ“Μ÷÷ΖΔΥΆΗΚ‘ΊΨυΚβ–≈œΔΗχNEΒΡΖΫ ΫΘ§’β―υNEΨΆΩ…“‘‘ΎΥϋ»œΈΣΚœ ΒΡ«ιΩωœ¬Ϋχ––ΗΚ‘ΊΨυΚβΝΥΓΘ”κWCCP“Μ―υΘ§NECP“≤ΧαΙ©ΝΥΦΗ÷÷ΉΣΖΔΖ÷ΉιΒΡΖΫ ΫΘΚMACΉΣΖΔΓΔGREΖβΉΑΚΆNAT
NECP÷ß≥÷άΐΆβΓΘSEΩ…“‘ΨωΕ®Υϋ≤ΜΡήΈΣΡ≥–©ΧΊΕ®ΒΡ‘¥IPΒΊ÷ΖΧαΙ©ΖΰΈώΘ§≤ΔΫΪ’β–©ΒΊ÷ΖΖΔΥΆΗχNEΓΘ»ΜΚσΘ§NEΩ…“‘ΫΪά¥Ή‘’β–©IPΒΊ÷ΖΒΡ«κ«σΉΣΖΔΗχ‘≠ ΦΖΰΈώΤς
œ¬±μΟη ωΝΥNECP±®ΈΡ
¥ζάμ÷ΊΕ®œρ
ΒΫΡΩ«ΑΈΣ÷ΙΘ§Έ“Ο«“―Ψ≠Χ÷¬έΙΐΆ®”ΟΒΡ÷ΊΕ®œρΖΫΖ®ΝΥΓΘ≥ω”Ύ«±‘ΎΒΡΑ≤»ΪΩΦ¬«Θ§ΡΎ»ί“≤Ω…Ρή–η“ΣΆ®ΙΐΗς÷÷¥ζάμά¥ΖΟΈ Θ§Μρ’ΏΆχ¬γ÷–Ω…Ρή”–“ΜΗωΩΆΜßΕΥΩ…άϊ”ΟΒΡ¥ζάμΜΚ¥φΘ§“ρΈΣΜώ»Γ“―ΜΚ¥φΒΡΡΎ»ίΚήΩ…Ρή“Σ±»÷±Ϋ”Ν§Ϋ”ΒΫ‘≠ ΦΖΰΈώΤςΩλΒΟΕύ
ΒΪWebδ·άάΤςΩΆΜßΕΥ‘θΟ¥≤≈Μα÷ΣΒά“ΣΝ§Ϋ”ΒΫΡ≥Ηω¥ζάμ…œ»ΞΡΊΘΩΩ…“‘”Ο3÷÷ΖΫΖ®ά¥≈–ΕœΘΚœ‘ Ϋδ·άάΤς≈δ÷ΟΓΔΕ·Χ§Ή‘Ε·≈δ÷Ο“‘ΦΑΆΗΟςάΙΫΊ
¥ζάμΩ…“‘Υ≥¥ΈΫΪΩΆΜßΕΥ«κ«σ÷ΊΕ®œρΒΫΝμ“ΜΗω¥ζάμ…œ»ΞΓΘ±»»γΘ§ΟΜ”–ΜΚ¥φ¥ΥΡΎ»ίΒΡ¥ζάμΜΚ¥φΩ…ΡήΜα―Γ‘ώΫΪΩΆΜßΕΥ÷ΊΕ®œρΒΫΝμ“ΜΗω¥ζάμΜΚ¥φΓΘ’β―υ“Μά¥Θ§œλ”ΠΨΆΜαά¥Ή‘”κΩΆΜßΕΥ«κ«σΉ ‘¥ΒΡΒΊ÷Ζ≤ΜΆ§ΒΡΝμΆβ“ΜΗωΒΊ÷ΖΘ§Υυ“‘Θ§Έ“Ο«ΜΙΜαΧ÷¬έΦΗ÷÷”Ο”ΎΕ‘Β»¥ζάμΓΣΓΣΜΚ¥φ÷ΊΕ®œρΒΡ–≠“ιΘΚICPΓΔCARPΚΆHTCP
ΓΨœ‘ Ϋδ·άάΤς≈δ÷ΟΓΩ
¥σΕύ ΐδ·άάΤςΕΦΩ…“‘≈δ÷ΟΈΣ¥”¥ζάμΖΰΈώΤς…œΜώ»ΓΡΎ»ίΓΣΓΣδ·άάΤς÷–”–“ΜΗωœ¬ά≠≤ΥΒΞΘ§”ΟΜßΩ…“‘‘Ύ’βΗω≤ΥΒΞ÷– δ»κ¥ζάμΒΡΟϊΉ÷ΜρIPΒΊ÷Ζ“‘ΦΑΕΥΩΎΚ≈ΓΘ»ΜΚσδ·άάΤςΒΡΥυ”–«κ«σΕΦΩ…“‘ΖΔΥΆΗχ’βΗω¥ζάμΓΘ”––©ΖΰΈώΧαΙ©…Χ≤Μ‘ –μ”ΟΜß≈δ÷ΟΤ’Ά®δ·άάΤςά¥ Ι”Ο¥ζάμΘ§ΥϋΟ«Μα“Σ«σ”ΟΜßœ¬‘Ί ¬œ»≈δ÷ΟΚΟΒΡδ·άάΤςΓΘ’β–©δ·άάΤς÷ΣΒάΥυ“Σ Ι”ΟΒΡ¥ζάμΒΡΒΊ÷Ζ
œ‘ Ϋδ·άάΤς≈δ÷Ο”–“‘œ¬ΝΫΗω÷ς“ΣΒΡ»±ΒψΘΚ
1ΓΔ≈δ÷ΟΈΣ Ι”Ο¥ζάμΒΡδ·άάΤςΘ§Φ¥ Ι‘Ύ¥ζάμΈόΖ®œλ”ΠΒΡ«ιΩωœ¬Θ§“≤≤ΜΜα»ΞΝΣœΒ‘≠ ΦΖΰΈώΤςΓΘ»γΙϊ¥ζάμ±άάΘΝΥΘ§Μρ’ΏΟΜ”–’ΐ»Ζ≈δ÷Οδ·άάΤςΘ§”ΟΜßΨΆΜα”ωΒΫΝ§Ϋ”ΖΫΟφΒΡΈ Χβ
2ΓΔΕ‘Άχ¬γΦήΙΙΫχ–––όΗΡΘ§≤ΔΫΪ’β–©–όΗΡΆ®÷ΣΗχΥυ”–ΒΡ÷’ΕΥ”ΟΜßΕΦ «ΚήάßΡ―ΒΡΓΘ»γΙϊΖΰΈώΧαΙ©…Χ“ΣΧμΦ”ΗϋΕύΒΡ¥ζάμΖΰΈώΤςΘ§Μρ’Ώ ΙΤδ÷–“Μ–©ΆΥ≥ωΖΰΈώΘ§”ΟΜßΕΦ“Σ–όΗΡδ·άάΤς¥ζάμ…η÷Ο
ΓΨ¥ζάμΉ‘Ε·≈δ÷ΟΓΩ
œ‘ Ϋ≈δ÷Οδ·άάΤς ΙΤδΝΣœΒΧΊΕ®ΒΡ¥ζάμΘ§’β―υΜαœό÷ΤΆχ¬γΦήΙΙΖΫΟφΒΡ±δΕ·Θ§“ρΈΣΥϋ «ΩΩ”ΟΜßά¥Ϋι»κ≤Δ÷Ί–¬≈δ÷Οδ·άάΤςΒΡΓΘΉ‘Ε·≈δ÷ΟΖΫ ΫΩ…“‘Ε·Χ§≈δ÷Οδ·άάΤςΘ§Ν§Ϋ”ΒΫ’ΐ»ΖΒΡ¥ζάμΖΰΈώΤςΘ§“‘ΫβΨω’βΗωΈ ΧβΓΘ’β÷÷ΖΫΖ®“―Ψ≠ Βœ÷ΝΥΘ§±Μ≥ΤΈΣ¥ζάμΉ‘Ε·≈δ
÷Ο(PAC)–≠“ιΓΘPAC «ΆχΨΑΙΪΥΨΕ®“εΒΡΘ§ΆχΨΑΙΪΥΨΒΡNavigatorΚΆΈΔ»μΒΡIEδ·άάΤςΕΦ÷ß≥÷¥Υ–≠“ι
PACΒΡΜυ±ΨΥΦœκ «»Οδ·άάΤς»ΞΜώ»Γ“ΜΗω≥ΤΈΣPACΒΡΧΊ βΈΡΦΰΘ§’βΗωΈΡΦΰΥΒΟςΝΥΟΩΗωURLΥυΙΊΝΣΒΡ¥ζάμΓΘ±Ί–κ≈δ÷Οδ·άάΤςΘ§ΈΣ’βΗωPACΈΡΦΰΙΊΝΣ“ΜΗωΧΊΕ®ΒΡΖΰΈώΤςΓΘ’β―υΘ§δ·άάΤςΟΩ¥Έ÷ΊΤτΒΡ ±ΚρΕΦΩ…“‘Μώ»Γ’βΗωPACΈΡΦΰΝΥ
PACΈΡΦΰ «ΗωJavaScriptΈΡΦΰΘ§Τδ÷–±Ί–κΕ®“εΚ· ΐΘΚ
| function FindProxyForURL(url,
host) |
»γœ¬Υυ ΨΘ§δ·άάΤς“ΣΈΣ«κ«σΒΡΟΩΧθURLΒς”Ο’βΗωΚ· ΐΘΚ
| return_value
= FindProxyForURL(url_of_request, host_in_url); |
ΤδΖΒΜΊ÷ΒΈΣ“ΜΗωΉ÷Ζϊ¥°Θ§”Οά¥ΥΒΟςδ·άάΤς”ΠΗΟΒΫΡΡάο«κ«σ’βΗωURLΓΘΖΒΜΊ÷ΒΩ…“‘ «ΥυΙΊΝΣΒΡ¥ζάμΟϊ≥ΤΝ–±μ(±»»γΘ§PROXY
proxy1.domain.com, PROXY proxy2.domain.com)Θ§Μρ’Ώ «Ή÷Ζϊ¥°"DIRECT"Θ§’βΗωΉ÷Ζϊ¥°ΥΒΟςδ·άάΤς”ΠΗΟ»ΤΩΣΥυ”–ΒΡ¥ζάμΘ§÷±Ϋ”Ν§Ϋ”‘≠ ΦΖΰΈώΤς
œ¬ΆΦΗχ≥ωΝΥδ·άάΤςΕ‘PACΈΡΦΰΒΡ«κ«σ“‘ΦΑœλ”Π¥Υ«κ«σΒΡ≤ΌΉςΥ≥–ρΓΘ‘Ύ±Ψάΐ÷–Θ§ΖΰΈώΤςΜΊΥΆΝΥ¥χ”–JavaScript≥Χ–ρΒΡPACΈΡΦΰΓΘJavaScript≥Χ–ρ÷–”–“ΜΗωFindProxyForURLΚ· ΐΘ§”Οά¥Ηφ÷Σδ·άάΤςΘ§»γΙϊΥυ«κ«σΒΡURLΒΡ÷ςΜζΈΜ”Ύnetscape.com”ρ÷–Θ§ΨΆ÷±Ϋ””κ‘≠ ΦΖΰΈώΤςΝΣœΒΘ§Υυ”–ΤδΥϊ«κ«σΕΦΝ§Ϋ”ΒΫproxy1.joes-cache.comΓΘδ·άάΤςΜαΈΣΥϋΥυ«κ«σΒΡΟΩΗωURLΒς”Ο’βΗωΚ· ΐΘ§≤ΔΗυΨί¥ΥΚ· ΐΖΒΜΊΒΡΫαΙϊΫχ––Ν§Ϋ”
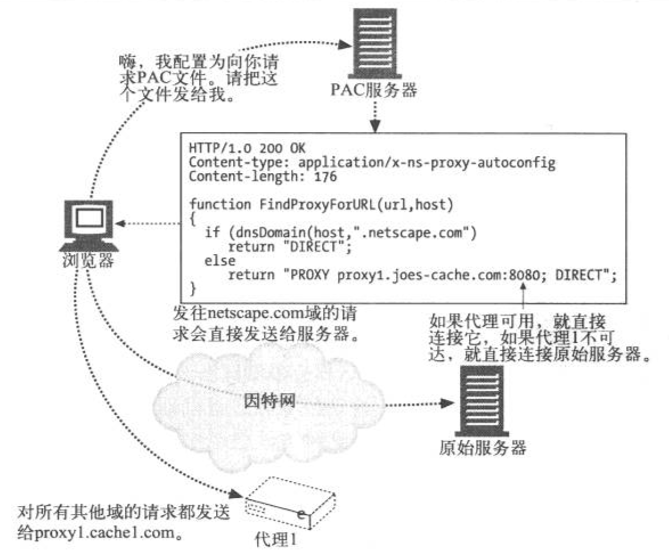
PAC–≠“ι «œύΒ±«Ω¥σΒΡΘΚJavaScript≥Χ–ρΩ…“‘«κ«σδ·άάΤςΗυΨί¥σΝΩ”κ÷ςΜζΟϊœύΙΊΒΡ≤Έ ΐά¥―Γ‘ώ¥ζάμΘ§±»»γDNSΒΊ÷ΖΚΆΉ”ΆχΘ§…θ÷Ν–«ΤΎΦΗΜρΨΏΧε ±ΦδΓΘ÷Μ“ΣΖΰΈώΤς÷–ΒΡPACΈΡΦΰ±Θ≥÷Ηϋ–¬Θ§ΡήΖ¥”≥¥ζάμΈΜ÷ΟΒΡ±δΜ·Θ§PACΨΆ‘ –μδ·άάΤςΗυΨίΆχ¬γΫαΙΙΒΡ±δΜ·Ή‘Ε·”κΚœ ΒΡ¥ζάμΫχ––ΝΣœΒ
PAC¥φ‘ΎΒΡ÷ς“ΣΈ Χβ «±Ί–κ“ΣΕ‘δ·άάΤςΫχ––≈δ÷ΟΘ§»ΟΥϋ÷ΣΒά“Σ¥”ΡΡΗωΖΰΈώΤςΜώ»ΓPACΈΡΦΰΘ§“ρ¥ΥΥϋΨΆ «“ΜΗω»ΪΉ‘Ε·≈δ÷ΟΒΡœΒΆ≥ΓΘΨΆœώΡ«–©‘Λ≈δ÷Οδ·άάΤς“Μ―υΘ§œ÷‘Ύ“Μ–©÷ς“ΣΒΡISPΕΦ‘Ύ Ι”ΟPAC
ΓΨWeb¥ζάμΉ‘Ε·ΖΔœ÷–≠“ιΓΩ
WPAD(Web¥ζάμΉ‘Ε·ΖΔœ÷–≠“ι)ΒΡΡΩ±ξ «‘Ύ≤Μ“Σ«σ÷’ΕΥ”ΟΜß ÷ΙΛ≈δ÷Ο¥ζάμ…η÷ΟΘ§
Εχ«“≤Μ“άάΒΆΗΟςΝςΝΩάΙΫΊΒΡ«ιΩωœ¬Θ§ΈΣWebδ·άάΤςΧαΙ©“Μ÷÷ΖΔœ÷≤Δ Ι”ΟΗΫΫϋ¥ζάμΒΡΖΫ ΫΓΘ”…”ΎΩ…Ι©―Γ‘ώΒΡΖΔœ÷–≠“ι”–ΚήΕύΘ§Εχ«“≤ΜΆ§δ·άάΤςΒΡ¥ζάμ Ι”Ο≈δ÷Ο“≤¥φ‘Ύ≤ν“λΘ§“ρ¥ΥΕ®“εWeb¥ζάμΉ‘Ε·ΖΔœ÷–≠“ι ±Θ§Τ’Ά®ΒΡΈ ν}Μα±ΜΗ¥‘”Μ·
1ΓΔPACΈΡΦΰΉ‘Ε·ΖΔœ÷
WPAD‘ –μHTTPΩΆΜßΕΥΕ®ΈΜ“ΜΗωPACΈΡΦΰΘ§≤Δ Ι”Ο’βΗωPACΈΡΦΰ’“ΒΫ Β±ΒΡ¥ζάμΖΰΈώΤςΒΡΟϊΉ÷ΓΘWPAD≤ΜΡή÷±Ϋ”»ΖΕ®¥ζάμΖΰΈώΤςΒΡΟϊΉ÷Θ§“ρΈΣ’β―υΨΆΈόΖ® Ι”ΟPACΈΡΦΰΧαΙ©ΒΡΗΫΦ”ΙΠΡήΝΥ(ΗΚ‘ΊΨυΚβΘ§«κ«σ¬Ζ”…ΒΫ“ΜΉιΖΰΈώΤς…œ»ΞΘ§Ι ’œ ±Ή‘Ε·ΉΣ“ΤΒΫ±Η”Ο¥ζάμΖΰΈώΤςΒ»)
»γœ¬ΆΦΥυ ΨΘ§WPAD–≠“ιΖΔœ÷ΝΥPACΈΡΦΰURLΘ§’βΗωURL“≤±Μ≥ΤΈΣ≈δ÷ΟURL(CURL)ΓΘPACΈΡΦΰ÷¥––ΝΥ“ΜΗωJavaScript≥Χ–ρΘ§’βΗω≥Χ–ρΜαΖΒΜΊΚœ ΒΡ¥ζάμΖΰΈώΤςΒΊ÷Ζ
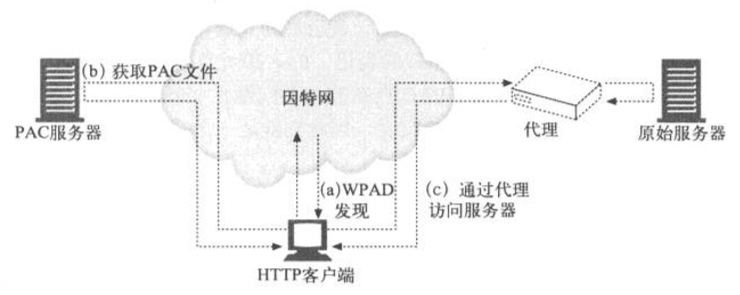
Βœ÷WPAD–≠“ιΒΡHTTPΩΆΜßΕΥ”ΟWPAD’“ΒΫPACΈΡΦΰΒΡCURLΘ§ΗυΨί’βΗωCURLΜώ»ΓPACΈΡΦΰ(”÷Οϊ≈δ÷ΟΈΡΦΰΜρCFILE)Θ§÷¥––PACΈΡΦΰά¥»ΖΕ®¥ζάμΖΰΈώΤςΘ§œρPACΈΡΦΰΖΒΜΊΒΡΡ«Ηω¥ζάμΖΰΈώΤςΖΔΥΆHTTP«κ«σ
2ΓΔWPADΥψΖ®
WPAD Ι”ΟΝΥ“ΜœΒΝ–Ή ‘¥ΖΔœ÷ΦΦ θά¥»ΖΕ® Β±ΒΡPACΈΡΦΰCURLΓΘ≤Δ≤Μ «Υυ”–ΒΡΉι÷·ΕΦΩ…“‘ Ι”ΟΥυ”–ΦΦ θΒΡΘ§Υυ“‘WPAD÷ΗΕ®ΝΥΕύ÷÷ΖΔœ÷ΦΦ θΓΘ‘Ύ≥…ΙΠΜώΒΟCURL÷°«ΑΘ§WPADΩΆΜßΕΥΜα“ΜΗωΗωΒΊ≥Δ ‘ΟΩ÷÷ΦΦ θ
Β±«ΑΒΡWPADΙφΖΕΑ¥–ρΕ®“εΝΥœ¬Ν–ΦΦ θΘΚDHCP(Ε·Χ§÷ςΜζ≈δ÷Ο–≠“ι)ΓΔSLP(ΖΰΈώΕ®ΈΜ–≠“ι)ΓΔDNS÷ΣΟϊ÷ςΜζΟϊΓΔDNS
SRVΦ«¬ΦΓΔDNS TXTΦ«¬Φ÷–ΧαΙ©ΒΡΖΰΈώURL
‘Ύ’β5÷÷Μζ÷Τ÷–Θ§“Σ«σWPADΩΆΜßΕΥ±Ί–κ÷ß≥÷DHCPΚΆDNS÷ΣΟϊ÷ςΜζΟϊΦΦ θ
WPADΩΆΜßΕΥΜαΑ¥Υ≥–ρ”Ο…œΟφΧαΙ©ΒΡΖΔœ÷Μζ÷ΤΖΔΥΆ“ΜœΒΝ–Ή ‘¥ΖΔœ÷«κ«σΓΘΩΆΜßΕΥ÷ΜΜα≥Δ ‘ΥϋΟ«Υυ÷ß≥÷ΒΡΜζ÷ΤΓΘ÷Μ“ΣΡ≥¥ΈΖΔœ÷≥Δ ‘≥…ΙΠΝΥΘ§ΩΆΜßΕΥΨΆΜα”ΟΒΟΒΫΒΡ–≈œΔά¥ΙΙΫ®PAC
CURL
»γΙϊ¥”Ρ«ΗωCURL…œ≥…ΙΠΜώ»ΓΒΫPACΈΡΦΰΘ§’βΗωΙΐ≥ΧΨΆΫα χΝΥΓΘ»γΙϊΟΜ”–Θ§ΩΆΜßΕΥΨΆ¥”Υϋ‘Ύ‘ΛΕ®“εΒΡΉ ‘¥ΖΔœ÷«κ«σœΒΝ–άο÷–ΕœΒΡΒΊΖΫΩΣ ΦΜ÷Η¥ΓΘ»γΙϊ≥Δ ‘ΝΥΥυ”–ΒΡΖΔœ÷Μζ÷ΤΚσΘ§ΕΦΟΜ”–Μώ»ΓΒΫPACΈΡΦΰΘ§WPAD–≠“ιΨΆ ßΑήΝΥΘ§ΩΆΜßΕΥΜα≈δ÷ΟΈΣ≤Μ Ι”Ο¥ζάμΖΰΈώΤς
ΩΆΜßΕΥ Ήœ»Μα≥Δ ‘DHCPΘ§»ΜΚσ «SLPΓΘ»γΙϊΟΜ”–Μώ»ΓΒΫPACΈΡΦΰΘ§ΩΆΜßΕΥΜαΦΧ–χ÷¥––Ρ«–©Μυ”ΎDNSΒΡΜζ÷Τ
ΩΆΜßΕΥΜα‘ΎDNS SRVΓΔ÷ΣΟϊ÷ςΜζΟϊΚΆDNS TXTΦ«¬ΦΒ»ΖΫΖ®÷–―≠ΜΖΕύ¥ΈΓΘΟΩ¥ΈΕΦ ΙDNS≤ι―·ΒΡQNAME±δΒΟ‘Ϋά¥‘Ϋ≤ΜΨΏΧεΓΘΆ®Ιΐ’β÷÷ΖΫ ΫΘ§ΩΆΜßΕΥΨΆΩ…“‘Ε®ΈΜ≥ωΨΓΩ…ΡήΨΏΧεΒΡ≈δ÷Ο–≈œΔΘ§ΒΪ“≤Ω…ΡήΜαΉΣΕχ Ι”Ο“Μ–©≤ΜΧΪΨΏΧεΒΡ–≈œΔΓΘΟΩ¥ΈDNS≤ι’“ΕΦΜα‘ΎQNAME«ΑΦ”…œwpadΘ§”Ο“‘ΥΒΟς«κ«σΒΡΉ ‘¥άύ–Ά
ΩΦ¬«÷ςΜζΟϊΈΣjohns-desktop.development.foo.comΒΡΩΆΜßΕΥΓΘœ¬Οφ «“ΜΗωΆξ’ϊΒΡWPADΩΆΜßΕΥΜα÷¥––ΒΡΖΔœ÷≥Δ ‘Υ≥–ρΘΚDHCPΘΜSLPΘΜ”ΟQNAME=wpad.development.foo.com
Ϋχ––DNS A≤ι’“ΘΜ”ΟQNAME=wpad.development.foo.comΫχ––DNS SRV≤ι’“ΘΜ”ΟQNAME=wpad.devdopment.foo.comΫχ––DNS
TXT≤ι’“ΘΜ”ΟQNAME=wpad.foo.comΫχ––DNS A≤ι’“ΘΜ”ΟQNAME=wpad.foo.comΫχ––
DNS SRV ≤ι’“ΘΜ”ΟQNAME=wpad.foo.comΫχ––DNS TXT≤ι’“
3ΓΔ”ΟDHCPΫχ––CURLΖΔœ÷
“Σ Ι”Ο’β÷÷Μζ÷ΤΘ§ΨΆ±Ί–κΫΪCURL¥φ¥Δ‘ΎWPADΩΆΜßΕΥÖΦ“‘≤ι―·ΒΡDHCPΖΰΈώΤς…œΓΘWPADΩΆΜßΕΥΩ…“‘Ά®ΙΐœρDHCPΖΰΈώΤςΖΔΥΆDHCP≤ι―·ά¥Μώ»ΓCURLΓΘ(»γΙϊDHCPΖΰΈώΤς÷–≈δ÷ΟΝΥ’β÷÷–≈œΔ)Θ§ΨΆΩ…“‘‘ΎDHCPΩ…―Γ¥ζ¬κ252÷–Μώ»ΓCURLΓΘΥυ”–WPADΩΆΜßΕΥ Βœ÷ΕΦ±Ί–κ÷ß≥÷DHCP
»γΙϊWPADΩΆΜßΕΥ“―Ψ≠‘ΎΤδ≥θ ΦΜ·Ιΐ≥Χ÷–÷¥––ΝΥDHCP≤ι―·Θ§DHCPΖΰΈώΤςΩ…ΡήΨΆ“―Ψ≠ΧαΙ©ΝΥΡ«Ηω÷ΒΓΘ»γΙϊΈόΖ®Ά®ΙΐΩΆΜßΕΥOS
APIΜώΒΟ’βΗω÷ΒΘ§ΩΆΜßΕΥΨΆœρDHCPΖΰΈώΤςΖΔΥΆ“ΜΧθDHCPINFORM±®ΈΡΘ§“‘Μώ»Γ’βΗω÷Β
WPADΒΡDHCPΩ…―Γ¥ζ¬κ252ΈΣSTRINGάύ–ΆΘ§Ω…“‘ «»Έ“β≥ΛΕ»ΓΘ’βΗωΉ÷Ζϊ¥°÷–ΑϋΚ§ΝΥ“ΜΗω÷Ηœρ Β±PACΈΡΦΰΒΡURLΓΘ±»»γΘΚ
| "http://server.domain/proxyconfig.pac" |
4ΓΔDNS AΦ«¬Φ≤ι’“
“Σ»Ο’β÷÷Μζ÷ΤΙΛΉςΘ§ΨΆ±Ί–κΫΪΚœ ΒΡ¥ζάμΖΰΈώΤςΒΡIPΒΊ÷Ζ¥φ¥Δ‘ΎWPADΩΆΜßΕΥΩ…“‘≤ι―·ΒΡDNSΖΰΈώΤς…œΓΘWPADΩΆΜßΕΥΜαœρDNSΖΰΈώΤςΖΔΥΆ“ΜΗωAΦ«¬Φ≤ι―·Θ§“‘Μώ»ΓCURLΓΘ≥…ΙΠ≤ι―·ΒΡΫαΙϊ÷–ΜαΑϋΚ§Κœ ΒΡ¥ζάμΖΰΈώΤςΒΡIPΒΊ÷Ζ
WPADΩΆΜßΕΥ Βœ÷±Ί–κ÷ß≥÷’β÷÷Μζ÷ΤΓΘ’β”ΠΗΟ «ΚήΦρΒΞΒΡΘ§“ρΈΣΥϋ÷Μ“Σ«σΜυ±ΨΒΡDNS AΦ«¬Φ≤ι’“ΓΘΕ‘WPADά¥ΥΒΘ§ΙφΖΕ Ι”ΟΝΥΓΑwpadΓ±ΒΡΓΑ÷ΣΟϊ±πΟϊΓ±ά¥Ϋχ––Web¥ζάμΉ‘Ε·ΖΔœ÷
ΩΆΜßΕΥ÷¥––ΝΥœ¬Ν–DNS≤ι’“ΘΚ
| QNAME=wpad.TGTDOM.,
QCLASS=IN, QTYPE=A |
≥…ΙΠΒΡ≤ι’“÷–ΑϋΚ§ΝΥIPΒΊ÷ΖΘ§WPADΩΆΜßΕΥΗυΨί’βΗωΒΊ÷ΖΙΙΫ®CURL
5ΓΔΜώ»ΓPACΈΡΦΰ
÷Μ“Σ¥¥Ϋ®ΝΥΚρ―ΓΒΡCURLΘ§WPADΩΆΜßΕΥΆ®≥ΘΕΦΜαœρCURLΖΔΥΆ“ΜΧθGET«κ«σΓΘΖΔ≥ω«κ«σ ±Θ§WPADΩΆΜßΕΥ±Ί–κ“ΣΖΔΥΆ“Μ–©¥χ”– Β±CFILEΗώ Ϋ–≈œΔΒΡAccept Ή≤ΩΘ§’β–©CFILEΗώ ΫΕΦ «ΥϋΟ«ΥυΡή¥ΠάμΒΡΓΘ±»»γΘΚ
| Accept: application/x-ns-proxy-autoconfig |
Εχ«“Θ§»γΙϊCURLΒΡΫαΙϊ «“ΣΫχ––÷ΊΕ®œρΘ§ΩΆΜßΕΥΨΆ±Ί–κΗζΥφ’β–©÷ΊΕ®œρΒΫΤδΉν÷’ΡΩΒΡΒΊ
6ΓΔΚΈ ±÷¥––WPAD
÷Ν…Ό“Σ‘Ύ≥ωœ÷“‘œ¬«ιΩωΒΡ ±ΚρΫχ––Web¥ζάμΉ‘Ε·ΖΔœ÷ΘΚ
aΓΔ‘ΎWebΩΆΜßΕΥΤτΕ·ΒΡ ±ΚρΓΣΓΣWPAD÷Μ‘ΎΒΎ“ΜΗω ΒάΐΤτΕ·ΒΡ ±Κρ÷¥––ΓΘΚσΟφΒΡ ΒάΐΜαΦΧ≥–’β÷÷…η÷Ο
bΓΔ÷Μ“Σ”–ά¥Ή‘Άχ¬γ’ΜΒΡΆ®÷ΣΘ§ΨΆΥΒΟςΩΆΜßΕΥ÷ςΜζΒΡIPΒΊ÷ΖΗΡ±δΝΥ
ΡΡΗω―Γœν‘ΎΤδΜΖΨ≥÷–”–“β“εΘ§WebΩΆΜßΕΥΨΆΩ…“‘―Γ‘ώΡΡΗωΓΘΕχ«“Θ§ΩΆΜßΕΥΜΙ±Ί–κΗυΨίHTTPΒΡΙΐΤΎ ±ΦδΘ§ΈΣ÷°«Αœ¬‘ΊΒΡPACΈΡΦΰΒΡΙΐΤΎ ±Φδ≥Δ ‘“ΜΗωΖΔœ÷÷ήΤΎΓΘPACΈΡΦΰΙΐΤΎ ±Θ§ΩΆΜßΕΥΉώ―≠ΙΐΤΎ ±ΦδΘ§÷Ί–¬‘Υ––WPADΙΐ≥Χ «Κή÷Ί“ΣΒΡ
»γΙϊPACΈΡΦΰΟΜ”–ΧαΙ©ΧφΜΜΖΫΑΗΘ§‘ΎΒ±«Α≈δ÷ΟΒΡ¥ζάμ ß–ßΒΡ«ιΩωœ¬Θ§ΩΆΜßΕΥΜΙΩ…“‘―Γ‘ώ÷Ί–¬‘Υ––WPADΙΐ≥Χ
÷Μ“ΣΩΆΜßΕΥΨωΕ® ΙΒ±«ΑΒΡPACΈΡΦΰ ß–ßΘ§ΨΆ±Ί–κ÷Ί–¬‘Υ––’ϊΗωWPAD–≠“ιΘ§“‘»Ζ±ΘΥϋΜαΖΔœ÷Β±«Α’ΐ»ΖΒΡCURLΓΘΨΏΧεά¥ΥΒΘ§ΨΆ «–≠“ι≤ΜΡή”–ΧθΦΰΒΊΜώ»ΓPACΈΡΦΰΒΡIf-Modified-Since
WPAD–≠“ιΙψ≤Ξ”κ/ΜρΕύ≤ΞΆ®–≈Ω…Ρή–η“Σ¥σΝΩΒΡΆχ¬γΜΖΜΊ ±ΦδΓΘWPAD–≠“ιΒΡΦΛΜνΤΒ¬ ≤Μ”ΠΗΟΗΏ”Ύ…œΟφ÷ΗΕ®ΒΡΤΒ¬ (±»»γ‘ΎΟΩ¥ΈΜώ»ΓURL ±Ϋχ––“Μ¥Έ)
7ΓΔWPADΤέΤ≠
WPADΒΡIE5 Βœ÷‘ –μWebΩΆΜßΕΥ‘ΎΟΜ”–”ΟΜßΗ…‘ΛΒΡ«ιΩωœ¬Θ§Ή‘Ε·Φλ≤β¥ζάμ…η÷ΟΓΘWPAD Ι”ΟΒΡΥψΖ®Μα‘Ύ»Ϊ≥Τ”ρΟϊ«ΑΦ”…œ÷ςΜζΟϊΓΑWpadΓ±Θ§≤ΔΜα÷πΫΞ³h≥ΐΉ””ρΟϊΘ§÷±ΒΫΥϋ’“ΒΫΡήΙΜœλ”Π÷ςΜζΟϊΒΡWPADΖΰΈώΤςΘ§ΜρΒΫ¥οΒΎ»ΐΦΕ”ρΟϊΓΘ±»»γΘ§”ρa.b.microsoft.com÷–ΒΡWebΩΆΜßΕΥΜαœ»≤ι―·wpad.a.b.microsoftΓΔwpad.b.microsoft.comΘ§»ΜΚσ‘Ό≤ι―·wpad.microsoft.com
’β―υΜᱩ¬Ε≥ω“ΜΗωΑ≤»Ϊ¬©Ε¥Θ§“ρΈΣ‘ΎΙζΦ ”Π”Ο(ΦΑΤδΥϊΧΊΕ®ΒΡ≈δ÷Ο)÷–Θ§ΒΎ»ΐΦΕ”ρΟϊΩ…Ρή «≤ΜΩ…–≈ΒΡΓΘΕώ“β”ΟΜßΩ…“‘Ϋ®ΝΔ“ΜΗωWPADΖΰΈώΤςΘ§≤ΔΧαΙ©Υϊ―Γ÷–ΒΡ¥ζάμ≈δ÷ΟΟϋΝνΓΘΚσΦΧ(5.01ΦΑ“‘Κσ)ΒΡIEΑφ±Ψ–ό’ΐΝΥ’βΗωΈ Χβ
8ΓΔ≥§ ±
WPADΜαΨ≠ΙΐΕύΗωΦΕ±πΒΡΖΔœ÷Θ§ΩΆΜßΕΥ±Ί–κ»Ζ±ΘΟΩΗωΫΉΕΈΕΦ”– ±œό±Θ÷ΛΓΘΩ…ΡήΒΡ«ιΩωœ¬Θ§ΫΪΟΩΗωΫΉΕΈΕΦœό÷Τ‘Ύ10Οκ“‘ΡΎ «±»ΫœΚœάμΒΡΘ§ΒΪ Βœ÷’ΏΩ…ΡήΜα―Γ‘ώΤδΥϊΗϋ ΚœΤδΆχ¬γΧΊ–‘ΒΡ÷ΒΓΘ±»»γΘ§‘Υ––‘ΎΈόœΏΆχ¬γ…œΒΡ…η±Η Βœ÷Θ§”…”Ύ¥χΩμΫœΒΆΜρ ±―”Ϋœ≥ΛΘ§Ω…ΡήΨΆΜα Ι”ΟΗϋ¥σΒΡ ±œό
9ΓΔΙήάμ’ΏΒΡΩΦ¬«
Ιήάμ’Ώ÷Ν…Ό”ΠΗΟ‘ΎΤδΜΖΨ≥÷–≈δ÷ΟDHCPΜρDNS AΦ«¬Φ≤ι’“ΖΫ Ϋ÷–ΒΡ“Μ÷÷Θ§“ρΈΣ÷Μ”–’βΝΫ÷÷ΖΫ Ϋ «Υυ”–Φφ»ίΩΆΜßΕΥΕΦ±Ί–κ Βœ÷ΒΡΓΘ≥ΐ¥Υ÷°ΆβΘ§Ά®Ιΐ≈δ÷ΟΜΖΨ≥ ΙΤδ÷ß≥÷Υ―ΥςΝ–±μ÷–Υ≥–ρΩΩ«ΑΒΡΜζ÷ΤΘ§Ω…“‘ΥθΕΧΩΆΜßΕΥΒΡΤτΕ· ±Φδ
Ι”Ο’β÷÷–≠“ιΫαΙΙΒΡ÷ς“ΣΕ·ΝΠ÷°“Μ «÷ß≥÷ΩΆΜßΕΥΕ®ΈΜΗΫΫϋΒΡ¥ζάμΖΰΈώΤςΓΘ‘ΎΚήΕύΜΖΨ≥÷–Θ§ΕΦΜα”–ΕύΗω¥ζάμΖΰΈώΤς(ΙΛΉςΉιΓΔΙΪΥΨΆχΙΊΘ§ISPΓΔΙ«Η…ΆχΒ»)
‘ΎWPADΩρΦήΫαΙΙ÷–Θ§Ω…“‘‘ΎΚήΕύΒΊΖΫ»ΖΕ®¥ζάμΖΰΈώΤς «ΖώΓΑΝΎΫϋΓ±ΘΚ
aΓΔ≤ΜΆ§Ή”ΆχDHCPΖΰΈώΤςΜαΖΒΜΊ≤ΜΆ§¥πΑΗΓΘΜΙΩ…“‘ΗυΨίΩΆΜßΕΥΒΡcipaddrΉ÷ΕΈΜρΩΆΜßΕΥ±ξ ΕΖϊ―ΓœνΉς≥ωΨωΕ®
bΓΔΩ…“‘Ε‘DNSΖΰΈώΤςΫχ––≈δ÷ΟΘ§ ΙΤδΈΣ≤ΜΆ§ΒΡ”ρΟϊΚσΉΚ(±»»γΘ§QNAME
wpad.marketing.bigcorp.comΚΆwpad.development.bigcorp.com)ΖΒΜΊ≤ΜΆ§ΒΡSRV/A/TXTΉ ‘¥Φ«¬Φ(RR)
cΓΔ¥ΠάμCURL«κ«σΒΡWebΖΰΈώΤςΜαΗυΨίuser-Agent Ή≤ΩΓΔAccept Ή≤ΩΓΔΩΆΜßΕΥIPΒΊ÷Ζ/Ή”Άχ/÷ςΜζΟϊΓΔΗΫΫϋ¥ζάμΖΰΈώΤςΒΡΆΊΤΥΖ÷≤ΦΒ»Ής≥ωΨωΕ®ΓΘΩ…Ρή”…¥ΠάμCURLΒΡCGIΩ…÷¥––ΈΡΦΰΫχ––’β÷÷¥ΠάμΓΘ»γ«ΑΥυ ωΘ§…θ÷ΝΩ…Ρή «Ρ≥Ηω¥ΠάμCURL«κ«σΒΡ¥ζάμΖΰΈώΤςά¥Ής≥ω’β–©ΨωΕ®
dΓΔPACΈΡΦΰΒΡ±μ¥οΡήΝΠΩ…ΡήΉψ“‘‘ΎΩΆΜßΕΥ‘Υ–– ±¥”“ΜΉιΚρ―ΓΒΡ¥ζάμΖΰΈώΤς÷–Ϋχ––―Γ‘ώΓΘCARPΨΆ «‘Ύ¥ΥΜυ¥Γ…œ Βœ÷ΜΚ¥φ’σΝ–ΒΡΓΘPACΈΡΦΰΩ…“‘ΦΤΥψ≥ωΒΫ“ΜΉιΚρ―Γ¥ζάμΖΰΈώΤςΒΡΆχ¬γΨύάκ(ΜρΤδΥϊΚœάμΒΡΕ»ΝΩΖΫ Ϋ)Θ§≤Δ―Γ‘ώΓΑΉνΫϋΓ±ΜρΓΑœλ”ΠΉνΜΐΦΪΓ±ΒΡΖΰΈώΤςΘ§’β≤Δ≤Μ « ≤Ο¥≤ΜΩ…ΥΦ“ιΒΡ ¬«ι
ΜΚ¥φ÷ΊΕ®œρ
Έ“Ο«“―Ψ≠Χ÷¬έΙΐ“Μ–©ΫΪΝςΝΩ÷ΊΕ®œρΒΫΆ®”ΟΖΰΈώΤςΒΡΦΦ θΘ§“‘ΦΑ“Μ–©ΫΪΝςΝΩΒΦœρ¥ζάμΜρΆχΙΊΒΡΉ®”ΟΦΦ θΝΥΓΘœ¬ΟφΜαΫι…ή“Μ–©ΗϋΗ¥‘”ΒΡΓΔ”Ο”ΎΜΚ¥φ¥ζάμΖΰΈώΤςΒΡ÷ΊΕ®œρΦΦ θΓΘ’β–©ΦΦ θ“ΣΨΓΝΩΉωΒΫΩ…ΩΩΓΔΗΏ–ß«“ΡήΗ–÷ΣΡΎ»ίΓΣΓΣ’β―υΩ…“‘ΫΪ«κ«σΖ÷≈δΒΫΩ…ΡήΑϋΚ§ΧΊΕ®ΡΎ»ίΒΡΈΜ÷Ο…œ»ΞΘ§“ρ¥Υ±»«ΑΟφΧ÷¬έΙΐΒΡΡ«–©–≠“ιΗϋΗ¥‘”
ΓΨWCCP÷ΊΕ®œρΓΩ
CiscoœΒΆ≥ΙΪΥΨΩΣΖΔΒΡWCCPΩ…“‘ Ι¬Ζ”…ΤςΫΪWebΝςΝΩ÷ΊΕ®œρΒΫ¥ζάμΜΚ¥φ÷–»ΞΓΘWCCPΗΚ‘π¬Ζ”…ΤςΚΆΜΚ¥φΖΰΈώΤς÷°ΦδΒΡΆ®–≈Θ§’β―υ¬Ζ”…ΤςΨΆΩ…“‘Ε‘ΜΚ¥φΫχ––―ι÷Λ(»Ζ±ΘΥϋΟ«“―ΤτΕ·«“’ΐ‘Ύ‘Υ––)Θ§‘ΎΜΚ¥φ÷°ΦδΫχ––ΗΚ‘ΊΨυΚβΘ§≤ΔΫΪΧΊΕ®άύ–ΆΒΡΝςΝΩΖΔΥΆΗχΧΊΕ®ΒΡΜΚ¥φΝΥΓΘWCCPΑφ±Ψ2(WCCP2) «ΗωΩΣΖ≈ΒΡ–≠“ιΓΘœ¬ΟφΧΫΧ÷WCCP2
1ΓΔWCCP÷ΊΕ®œρΙΛΉςΝς≥Χ
œ¬Οφ «WCCP÷ΊΕ®œρ‘ΎHTTP…œΙΛΉςΙΐ≥ΧΒΡΗ≈ ω(WCCPΕ‘ΤδΥϊ–≠“ιΒΡ÷ΊΕ®œρΙΐ≥Χ“≤ «άύΥΤΒΡ)ΘΚΤτΕ·ΑϋΚ§ΝΥ“Μ–©÷ß≥÷WCCPΒΡ¬Ζ”…ΤςΚΆΜΚ¥φΒΡΆχ¬γΘ§’β–©¬Ζ”…ΤςΚΆΜΚ¥φ÷°ΦδΩ…“‘œύΜΞΆ®–≈ΘΜ“ΜΉι¬Ζ”…ΤςΦΑΤδΡΩ±ξΜΚ¥φΙΙ≥…“ΜΗωWCCPΖΰΈώΉιΓΘΖΰΈώΉιΒΡ≈δ÷ΟΥΒΟςΝΥ“ΣΫΪΚΈ÷÷ΝςΝΩΖΔΆυΚΈ¥ΠΓΔΝςΝΩ «»γΚΈΖΔΥΆΒΡ“‘ΦΑ»γΚΈ‘ΎΖΰΈώΉιΒΡΜΚ¥φ÷°ΦδΫχ––ΗΚ‘ΊΨυΚβΘΜ»γΙϊΖΰΈώΉι≈δ÷ΟΈΣ÷ΊΕ®œρHTTPΝςΝΩΘ§ΖΰΈώΉι÷–ΒΡ¬Ζ”…ΤςΨΆΜαΫΪHTTP«κ«σΖΔΥΆΗχΖΰΈώΉι÷–ΒΡΜΚ¥φΘΜHTTP«κ«σΒ÷¥οΖΰΈώΉι÷–ΒΡ¬Ζ”…Τς ±Θ§¬Ζ”…ΤςΜα(ΗυΨίΕ‘«κ«σIPΒΊ÷ΖΒΡ…ΔΝ–Θ§Μρ’ΏΓΑ―Ύ¬κ/÷ΒΓ±ΒΡ≈δΕ‘≤Ώ¬‘)―Γ‘ώΖΰΈώΉι÷–ΒΡΡ≥ΗωΜΚ¥φΈΣ«κ«σΧαΙ©ΖΰΈώΘΜ¬Ζ”…ΤςœρΜΚ¥φΖΔΥΆ«κ«σΖ÷ΉιΘ§Ω…“‘”ΟΜΚ¥φΒΡIPΒΊ÷Ζά¥ΖβΉΑΖ÷ΉιΘ§“≤Ω…“‘Ά®ΙΐIP
MACΉΣΖΔά¥ Βœ÷ΘΜ»γΙϊΜΚ¥φΈόΖ®ΈΣ«κ«σΧαΙ©ΖΰΈώΘ§ΨΆΫΪΖ÷ΉιΖΒΜΊΗχ¬Ζ”…ΤςΫχ––Τ’Ά®ΒΡΉΣΖΔΘΜΖΰΈώΉι÷–ΒΡ≥…‘±ΜαΜΞœύΫΜΜΜ–ΡΧχ±®ΈΡΘ§≤ΜΕœ―ι÷ΛΕ‘ΖΫΒΡΩ…”Ο–‘
2ΓΔWCCP2±®ΈΡ
WCCP2±®ΈΡ”–4÷÷Θ§»γœ¬±μΥυ Ψ
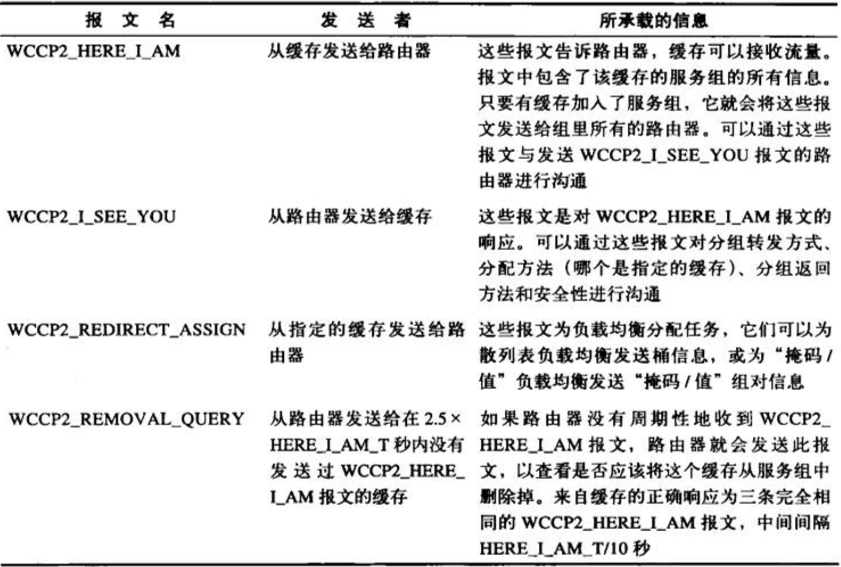
WCCP2_HERE_I_AMΒΡ±®ΈΡΗώ ΫΈΣ
Security Info
Component
Service Info Component
Web-cache Identity Info Component
Web-cache View Info Component
Capability Info Component(Ω…―Γ)
Command Extension Component(Ω…―Γ) |
WCCP2_I_SEE_YOUΒΡ±®ΈΡΗώ ΫΈΣ
WCCP Message
Header
Security Info Component
Service Info Component
Router Identity Info Component
Router View Info Component
Capability Info Component(Ω…―Γ)
Command Extension Component(Ω…―Γ) |
WCCP2_REDIRECT_ASSIGN ΒΡ±®ΈΡΗώ ΫΈΣ
WCCP Message
Header
Security Info Component
Service Info Component
Assignment Info Component, or Alternate Assignment
Component |
WCCP2_REMOVAL_QUERY ΒΡ±®ΈΡΗώ ΫΈΣ
WCCP Message
Header
Security Info Component
Service Info Component
Router Query Info Component |
3ΓΔ±®ΈΡΉιΦΰ
ΟΩΧθWCCP2±®ΈΡΕΦ”…“ΜΗω Ή≤ΩΚΆ“Μ–©ΉιΦΰΙΙ≥…ΓΘWCCP Ή≤Ω–≈œΔΑϋΚ§±®ΈΡάύ–Ά(Here I AmΓΔI
See YouΓΔAssignmentΜρRemoval Query)ΓΔWCCPΑφ±ΨΚΆ±®ΈΡ≥ΛΕ»(≤ΜΑϋά® Ή≤ΩΒΡ≥ΛΕ»)
ΟΩΗωΉιΦΰΕΦ“‘“ΜΗωΟη ωΉιΦΰάύ–ΆΚΆ≥ΛΕ»ΒΡ4Ή÷ΫΎ Ή≤ΩΩΣ ΦΓΘΉιΦΰ≥ΛΕ»≤ΜΑϋά®ΉιΦΰ Ή≤ΩΒΡ≥ΛΕ»ΓΘ±®ΈΡΉιΦΰ»γœ¬±μΥυ ω


4ΓΔΖΰΈώΉι
ΖΰΈώΉι(service group)”…“ΜΉι÷ß≥÷WCCPΒΡ¬Ζ”…ΤςΚΆΜΚ¥φΉι≥…Θ§ΥϋΟ«÷°ΦδΩ…“‘ΫΜΜΜWCCP±®ΈΡΓΘ¬Ζ”…ΤςΜαœρΖΰΈώΉι÷–ΒΡΜΚ¥φΖΔΥΆWebΝςΝΩΓΘΖΰΈώΉιΒΡ≈δ÷Ο»ΖΕ®ΝΥ»γΚΈΫΪΝςΝΩΖ÷≈δΒΫΖΰΈώΉιΒΡΜΚ¥φ÷–»ΞΓΘ¬Ζ”…ΤςΚΆΜΚ¥φΜα‘ΎHere
I AmΚΆI See You±®ΈΡ÷–ΫΜΜΜΖΰΈώΉιΒΡ≈δ÷Ο–≈œΔ
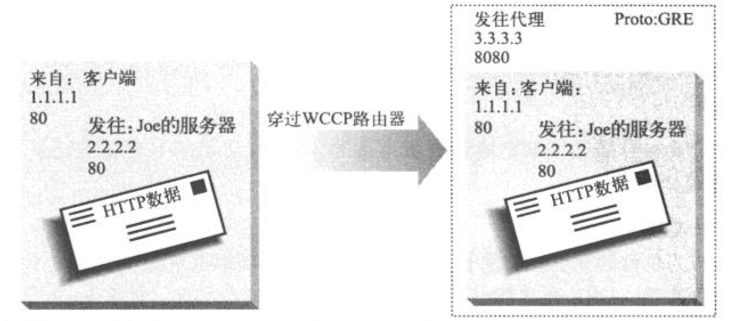
5ΓΔGREΖ÷ΉιΖβΉΑ
÷ß≥÷WCCPΒΡ¬Ζ”…ΤςΜα”ΟΖΰΈώΤςΒΡIPΒΊ÷ΖΫΪHTTPΖ÷ΉιΖβΉΑΤπά¥Θ§ΫΪΤδ÷ΊΕ®œρΒΫΧΊΕ®ΒΡΖΰΈώΤς…œ»ΞΓΘΖ÷ΉιΖβΉΑ÷–ΜΙΑϋΚ§ΝΥIP Ή≤ΩΒΡprotoΉ÷ΕΈΘ§”Οά¥ΥΒΟςΆ®”Ο¬Ζ”…ΤςΖβΉΑ(GRE)ΓΘprotoΉ÷ΕΈΒΡ¥φ‘ΎΗφΥΏΫ” ’¥ζάμΘ§Υϋ”–“ΜΗωΖβΉΑΒΡΖ÷ΉιΓΘΖ÷Ήι±ΜΖβΉΑΤπά¥Θ§ΩΆΜßΕΥΒΡIPΒΊ÷ΖΨΆ≤ΜΜαΕΣ ßΝΥΓΘœ¬ΆΦœ‘ ΨΝΥGREΖ÷ΉιΒΡΖβΉΑΙΐ≥Χ
6ΓΔWCCPΒΡΗΚ‘ΊΨυΚβ
≥ΐΝΥ¬Ζ”…ΙΠΡή÷°ΆβΘ§WCCP¬Ζ”…ΤςΜΙΩ…“‘‘ΎΦΗΗωΫ” ’ΖΰΈώΤς÷°ΦδΫχ––ΗΚ‘ΊΨυΚβΓΘWCCP¬Ζ”…ΤςΦΑΤδΫ” ’ΖΰΈώΤςΜαΫΜΜΜ–ΡΧχ±®ΈΡ(heartbeat
message)Θ§“‘±ψœύΜΞΆ®÷ΣΉ‘ΦΚ¥Π”ΎΤτΕ·‘Υ––Ή¥Χ§ΓΘ»γΙϊΡ≥ΧΊΕ®Ϋ” ’ΖΰΈώΤςΆΘ÷ΙΖΔΥΆ–ΡΧχ±®ΈΡΘ§WCCP¬Ζ”…ΤςΨΆΜαΫΪ«κ«σΝςΉν÷±Ϋ”ΖΔΥΆΒΫ“ρΧΊΆχ…œΘ§Εχ≤ΜΜαΫΪΤδ÷ΊΕ®œρΗχΡ«ΗωΫΎΒψΓΘΫΎΒψ÷Ί–¬ΧαΙ©ΖΰΈώ ±Θ§WCCP¬Ζ”…ΤςΜα‘Ό¥ΈΩΣ ΦΫ” ’–ΡΧχ±®ΈΡΘ§≤ΔΦΧ–χœρΫΎΒψΖΔΥΆ«κ«σΝςΝΩ
ΓΨ“ρΧΊΆχΜΚ¥φ–≠“ιΓΩ
ICP (“ρΧΊΆχΜΚ¥φ–≠“ι)‘ –μΜΚ¥φ‘ΎΤδ–÷ΒήΜΚ¥φ÷–≤ι’“Οϋ÷–ΡΎ»ίΓΘ»γΙϊΡ≥ΗωΜΚ¥φ÷–ΟΜ”–HTTP±®ΈΡΥυ«κ«σΒΡΡΎ»ίΘ§ΥϋΩ…“‘≤ιΟςΡΎ»ί «Ζώ‘ΎΗΫΫϋΒΡ–÷ΒήΜΚ¥φ÷–Θ§»γΙϊ‘ΎΘ§ΨΆ¥”Ρ«άοΜώ»ΓΡΎ»ίΘ§“‘±ήΟβ≤ι―·‘≠ ΦΖΰΈώΤςΕχ¥χά¥ΒΡΗϋΕύΩΣœζΓΘΩ…“‘Α―ICPΒ±Ής“ΜΗωΜΚ¥φΦ·»Κ–≠“ιΓΘHTTP«κ«σ±®ΈΡΒΡΉν÷’ΡΩΒΡΒΊΩ…“‘Ά®Ιΐ“ΜœΒΝ–ΒΡICP≤ι―·»ΖΕ®Θ§¥”’βΗωΫ«Ε»ά¥ΥΒΘ§ΥϋΨΆ «“ΜΗω÷ΊΕ®œρ–≠“ι
ICP «“ΜΗωΕ‘œσΖΔœ÷–≠“ιΓΘΥϋΜαΆ§ ±»Ξ―·Έ ΗΫΫϋΒΡΕύΗωΜΚ¥φΘ§Ω¥Ω¥ΥϋΟ«ΒΡΜΚ¥φ÷– «Ζώ”–ΧΊΕ®ΒΡURLΓΘΗΫΫϋΒΡΜΚ¥φ»γΙϊ”–Ρ«ΗωURLΒΡΜΑΘ§ΨΆΜαΖΒΜΊ“ΜΗωΦρΕΧΒΡ±®ΈΡHITΘ§»γΙϊΟΜ”–Θ§ΨΆΖΒΜΊMISSΓΘ»ΜΚσΘ§ΜΚ¥φΨΆΩ…“‘¥ρΩΣ“ΜΧθΒΫ”Β”–¥ΥΕ‘œσΒΡΝΎΨ”ΜΚ¥φΒΡHTTPΝ§Ϋ”ΝΥ
ICP «ΚήΦρΒΞ÷±Ϋ”ΒΡΓΘICP±®ΈΡ «“ΜΗω“‘Άχ¬γΉ÷ΫΎ–ρ±μ ΨΒΡ32ΈΜΖβΉΑΫαΙΙΘ§’β―υΗϋ±ψ”ΎΫχ––ΫβΈωΓΘΈΣΝΥΧαΗΏ–߬ Θ§Ω…“‘”…UDP ΐΨί±®≥–‘ΊΤδ±®ΈΡΓΘUDP «“Μ÷÷≤ΜΩ…ΩΩΒΡ“ρΧΊΆχ–≠“ιΘ§ΥΒΟς‘Ύ¥Ϊ δΒΡΙΐ≥Χ÷– ΐΨίΩ…ΡήΜα±ΜΤΤΜΒΘ§“ρ¥Υ Ι”ΟICPΒΡ≥Χ–ρ“ΣΨΏ”–≥§ ±ΙΠΡήΘ§“‘Φλ≤βΕΣ ßΒΡ ΐΨί±®
œ¬ΟφΦρ“ΣΟη ω“Μœ¬ICP±®ΈΡ÷–ΒΡ≤ΩΖ÷–≈œΔ
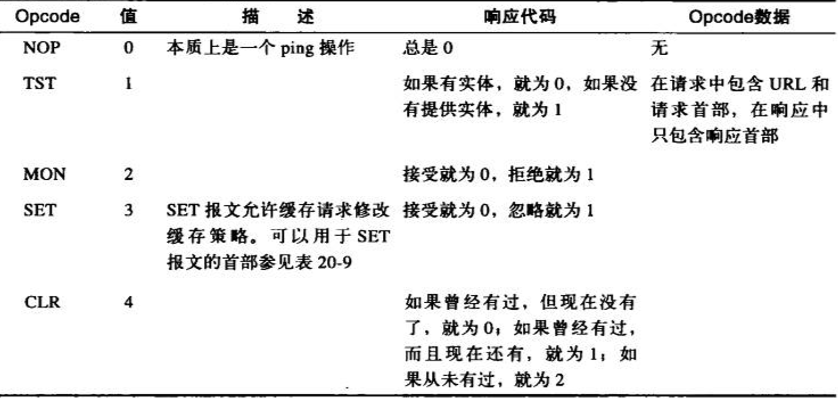
aΓΔOpcode(≤ΌΉς¬κ)
Opcode «Ηω8ΈΜΒΡΕΰΫχ÷Τ÷ΒΘ§”Ο“‘Οη ωICP±®ΈΡΒΡΚ§“εΓΘΜυ±ΨΒΡopcodeΑϋά®ICP_OP_QUERY«κ«σ±®ΈΡΚΆICP_OP_HITΚΆICP_OP_MISSœλ”Π±®ΈΡ
bΓΔΑφ±Ψ
8ΈΜΒΡΑφ±ΨΚ≈Οη ωΝΥICP–≠“ιΒΡΑφ±Ψ±ύΚ≈ΓΘSquid Ι”ΟΒΡICPΑφ±ΨΦ«¬Φ‘ΎRFC
2186ΒΎ2Αφ÷–
cΓΔ±®ΈΡ≥ΛΕ»
“‘Ή÷ΫΎΈΣΒΞΈΜΒΡICP±®ΈΡΉή≥ΛΓΘ“ρΈΣ÷Μ”–16ΈΜΘ§Υυ“‘ICP±®ΈΡΒΡ≥ΛΕ»≤ΜΡή≥§Ιΐ16383Ή÷ΫΎΓΘURLΆ®≥ΘΕΦ–Γ”Ύ16KBΘ§»γΙϊ≥§Ιΐ’βΗω≥ΛΕ»Θ§ΚήΕύWeb”Π”Ο≥Χ–ρΨΆΈόΖ®¥ΠάμΥϋΝΥ
dΓΔ«κ«σ±ύΚ≈
÷ß≥÷ICPΒΡΜΚ¥φΜα”Ο«κ«σ±ύΚ≈ά¥Φ«¬ΦΕύΗωΆ§ ±ΖΔΤπΒΡ«κ«σΚΆœλ”ΠΓΘICP”Π¥π±®ΈΡ ΐ±Ί–κ”κ¥ΞΖΔ”Π¥πΒΡICP«κ«σ±®ΈΡ ΐœύΆ§
eΓΔ―Γœν
32ΈΜΒΡICP―ΓœνΉ÷ΕΈ «ΗωΑϋΚ§ΝΥ»τΗ…±ξΦ«ΒΡΈΜ ΗΝΩΘ§’β–©±ξΦ«ÖΦ”Οά¥–όΗΡICPΒΡ––ΈΣΓΘICPv2Ε®“εΝΥΝΫΗω±ξΦ«Θ§’βΝΫΗω±ξΦ«ΕΦΜα–όΗΡICP_OP_QUERY«κ«σΓΘICP_FLAG_HIT_OBJ±ξΦ«”Οά¥ΤτΕ·ΜρΫϊ÷Ι‘ΎICPœλ”Π÷–ΖΒΜΊΈΡΒΒ ΐΨίΓΘICP_FLAG_SRC_RTT±ξΦ««κ«σ”…–÷ΒήΜΚ¥φ≤βΝΩΒΡΓΔΒΫ‘≠ ΦΖΰΈώΤςΒΡΜΖΜΊ ±ΦδΒΡΙάΦΤ÷Β
fΓΔΩ…―Γ ΐΨί
±ΘΝτΝΥ32ΈΜΒΡΩ…―Γ ΐΨί”Ο”ΎΩ…―ΓΧΊ–‘ΓΘICPv2 Ι”ΟΝΥΩ…―Γ ΐΨίΒΡΒΆ16ΈΜά¥ΉΑ‘Ί¥”–÷ΒήΜΚ¥φΒΫ‘≠ ΦΖΰΈώΤςΒΡΩ…―ΓΜΖΜΊ ±ΦδΒΡΙάΦΤ÷Β
gΓΔΖΔΥΆΕΥ÷ςΜζΒΊ÷Ζ
≥–‘ΊΝΥ±®ΈΡΖΔΥΆΕΥ32ΈΜIPΒΊ÷ΖΒΡ÷χΟϊΉ÷ΕΈΓΘ ΒΦ ÷–≤ΔΈ¥ Ι”Ο
hΓΔΨΜΚ…
ΨΜΚ…ΡΎ»ίΒΡ±δΜ·»ΓΨω”Ύ±®ΈΡΒΡάύ–ΆΓΘΕ‘ICP_OP_QUERYά¥ΥΒΘ§ΨΜΚ… «“ΜΗω4Ή÷ΫΎΒΡ‘≠ Φ«κ«σΕΥ÷ςΜζΒΊ÷ΖΘ§ΚσΟφΗζΉ≈“ΜΗω”…NULΫαΈ≤ΒΡURLΓΘΕ‘ICP_OP_HIT_OBJά¥ΥΒΘ§ΨΜΚ… «“ΜΗω”…NULΫαΈ≤ΒΡURLΘ§ΚσΟφΗζΉ≈“ΜΗω16ΈΜΒΡΕ‘œσ≥ΛΕ»Θ§Ϋ”Ή≈ «Ε‘œσ ΐΨί
ΓΨΜΚ¥φ’σΝ–¬Ζ”…–≠“ιΓΩ
¥ζάμΖΰΈώΤςΆ®ΙΐάΙΫΊά¥Ή‘ΒΞΗω”ΟΜßΒΡ«κ«σΘ§ΧαΙ©Υυ«κ«σWebΕ‘œσΒΡΜΚ¥φΗ±±ΨΘ§ΦΪ¥σΒΊΫΒΒΆΝΥΖΔΆυ“ρΧΊΆχΒΡΝςΝΩΓΘΒΪΥφΉ≈”ΟΜß ΐΒΡ‘ωΦ”Θ§¥σΝΩΝςΝΩΩ…ΡήΜα Ι¥ζάμΖΰΈώΤςΉ‘…μ≥§‘Ί
Ε‘¥ΥΈ ΧβΒΡ“Μ÷÷ΫβΨωΖΫΑΗΨΆ « Ι”ΟΕύΗω¥ζάμΖΰΈώΤςΫΪΗΚ‘ΊΖ÷…ΔΒΫ“ΜΉιΖΰΈώΤς…œΓΘCARP(ΜΚ¥φ’σΝ–¬Ζ”…–≠“ι) «ΈΔ»μΙΪΥΨΚΆΆχΨΑΙΪΥΨΧα≥ωΒΡ“ΜΗω±ξΉΦΘ§Ά®Ιΐ’βΗω–≠“ιά¥Ιήάμ“ΜΉι¥ζάμΖΰΈώΤςΘ§ Ι’βΉι¥ζάμΖΰΈώΤςΕ‘”ΟΜßά¥ΥΒΨΆœώ“ΜΗω¬ΏΦ≠ΜΚ¥φ“Μ―υ
CARP «ICPΒΡ“ΜΗωΧφ¥ζΤΖΓΘCARPΚΆICPΕΦ‘ –μΙήάμ’ΏΆ®Ιΐ Ι”ΟΕύΗω¥ζάμΖΰΈώΤςά¥ΧαΗΏ–‘ΡήΓΘœ¬ΟφΧ÷¬έCARP”κICPΒΡ«χ±πΘ§”ΟCARP¥ζΧφICPΒΡ”≈»±Βψ“‘ΦΑ
CARP–≠“ι Βœ÷…œΒΡ“Μ–©ΦΦ θœΗΫΎ
ICP÷–≥ωœ÷ΜΚ¥φΈ¥Οϋ÷– ±Θ§¥ζάμΖΰΈώΤςΜα”ΟICP±®ΈΡΗώ Ϋά¥≤ι―·ΗΫΫϋΒΡΜΚ¥φΘ§“‘»ΖΕ®WebΕ‘œσ «Ζώ¥φ‘ΎΓΘΗΫΫϋΒΡΜΚ¥φΜα“‘HITΜρMISSΫχ––œλ”ΠΘ§«κ«σ¥ζάμΖΰΈώΤςΜα”Ο’β–©œλ”Πά¥―Γ‘ώΡήΙΜΜώ»ΓΒΫΕ‘œσΒΡΉν Β±ΒΡΈΜ÷ΟΓΘ»γΙϊICP¥ζάμΖΰΈώΤς «“‘≤ψ¥ΈΫαΙΙ≈≈Ν–ΒΡΘ§Έ¥Οϋ÷–ΒΡ≤ι―·Μα±ΜΧαΫΜΗχΤδΗΗ¥ζάμΓΘœ¬ΆΦ“‘ΆΦ–ΈΖΫ Ϋœ‘ ΨΝΥ»γΚΈΆ®ΙΐICPά¥ΫβΨωΟϋ÷–ΚΆΈ¥Οϋ÷–ΒΡΈ Χβ
[ΉΔ“β]Ά®ΙΐICP–≠“ιΝ§Ϋ”Τπά¥ΒΡΟΩΗω¥ζάμΖΰΈώΤςΕΦ «ΫΪΡΎ»ίΫχ––ΝΥ»Ώ”ύΨΒœώΒΡΕάΝΔΜΚ¥φΖΰΈώΤςΘ§’βΨΆΥΒΟς‘Ύ≤ΜΆ§ΒΡ¥ζάμΖΰΈώΤς÷°ΦδΗ¥÷ΤWebΕ‘œσΧθΡΩ «Ω…––ΒΡΓΘœύΖ¥Θ§”ΟCARPΝ§Ϋ”Τπά¥ΒΡ“ΜΉιΖΰΈώΤςΜα±ΜΒ±Ής“ΜΗω¥σ–ΆΒΡΖΰΈώΤςΘ§Τδ÷–ΟΩΗωΉιΦΰΖΰΈώΤςΕΦ÷ΜΑϋΚ§»Ϊ≤ΩΜΚ¥φΈΡΒΒ÷–ΒΡ“Μ≤ΩΖ÷ΓΘΆ®ΙΐΕ‘Ρ≥ΗωWebΕ‘œσΒΡURL”Π”Ο…ΔΝ–Κ· ΐΘ§CARPΨΆΩ…“‘ΫΪ¥ΥΕ‘œσ”≥…δΒΫΧΊΕ®ΒΡ¥ζάμΖΰΈώΤς…œ»ΞΓΘΟΩΗωWebΕ‘œσΕΦ”–“ΜΗωΈ®“ΜΒΡΦ“Θ§Υυ“‘Έ“Ο«Ω…“‘Ά®ΙΐΒΞ¥Έ≤ι’“»ΖΕ®Ε‘œσΒΡΈΜ÷ΟΘ§ΕχΈό–κ»Ξ≤ι―·Φ·Κœ÷–≈δ÷ΟΒΡΟΩΗω¥ζάμΖΰΈώΤςΓΘœ¬ΆΦΉήΫαΝΥCARP÷ΊΕ®œρΒΡΖΫ Ϋ
ΉςΈΣΩΆΜßΕΥΚΆ¥ζάμΖΰΈώΤς÷–Φδ»ΥΒΡΜΚ¥φ¥ζάμΩ…“‘‘ΎΗςΗω¥ζάμΖΰΈώΤς÷°ΦδΖ÷≈δΗΚ‘ΊΘ§ΒΪ’βœνΙΠΡή“≤Ω…“‘”…ΩΆΜßΕΥΉ‘…μΧαΙ©ΓΘΩ…“‘≈δ÷Οδ·άάΤςΘ§“‘≤εΦΰΒΡ–Έ ΫΦΤΥψ…ΔΝ–Κ· ΐΘ§ά¥»ΖΕ®”ΠΗΟΑ―«κ«σΖΔΥΆΗχΡΡΗω¥ζάμΖΰΈώΤς
CARPΕ‘¥ζάμΖΰΈώΤςΉω≥ωΒΡ»ΖΕ®–‘ΫβΈωΥΒΟςΥϋΈό–κœρΥυ”–ΝΎΨ”ΖΔΥΆ≤ι―·Θ§’β“≤ΨΆ“βΈΕΉ≈’β÷÷ΖΫΖ®Υυ–ηΖΔΥΆΒΡΜΚ¥φΦδ±®ΈΡΜα±»Ϋœ…ΌΓΘΥφΉ≈‘Ϋά¥‘ΫΕύΒΡ¥ζάμΖΰΈώΤςΧμΦ”ΒΫ≈δ÷ΟœΒΆ≥÷–ά¥Θ§ΜΚ¥φœΒΆ≥Φ·»ΚΒΡΙφΡΘΜα±δΒΟœύΒ±¥σΓΘΒΪCARPΒΡ“ΜΗω»±ΒψΨΆ «Θ§»γΙϊΡ≥Ηω¥ζάμΖΰΈώΤς≤ΜΩ…”ΟΝΥΘ§ΨΆ“Σ÷Ί–¬–όΗΡ…ΔΝ–±μ“‘Ζ¥”≥’β÷÷±δΜ·Θ§Εχ«“±Ί–κ÷Ί–¬≈δ÷Οœ÷¥φ¥ζάμΖΰΈώΤς…œΒΡΡΎ»ίΓΘ»γΙϊ¥ζάμΖΰΈώΤςΨ≠≥Θ±άάΘΒΡΜΑΘ§’βΟ¥ΉωΒΡΩΣœζΩ…ΡήΜαΚήΗΏΓΘœύΖ¥Θ§ICP¥ζάμΖΰΈώΤς÷–¥φ‘ΎΒΡ»Ώ”ύΡΎ»ίΨΆ±μ ΨΥϋ≤Μ–η“Σ÷Ί–¬≈δ÷ΟΓΘΝμ“ΜΗω«±‘ΎΒΡΈ Χβ «Θ§”…”ΎCARP «Ηω–¬–≠“ιΘ§CARPΦ·»Κ÷–Ω…Ρή≤ΜΜαΑϋΚ§Ρ«–©œ÷¥φΒΡΓΔ÷Μ‘Υ––ICP–≠“ιΒΡ¥ζάμΖΰΈώΤς
CARP÷ΊΕ®œρΖΫΖ®“ΣΆξ≥…œ¬Ν–»ΈΈώΘΚ±Θ¥φ“ΜΗω≤Έ”κCARPΒΡ¥ζάμΖΰΈώΤςΝ–±μΓΘ÷ήΤΎ–‘ΒΊ≤ι―·’β–©¥ζάμΖΰΈώΤςΘ§Ω¥Ω¥ΥϋΟ« «Ζώ»‘»ΜΜν‘ΨΘΜΈΣΟΩΗω≤Έ”κΒΡ¥ζάμΖΰΈώΤςΦΤΥψ“ΜΗω…ΔΝ–Κ· ΐΓΘ…ΔΝ–Κ· ΐΒΡΖΒΜΊ÷Β“ΣΩΦ¬«¥Υ¥ζάμΥυΡή¥ΠάμΒΡΗΚ‘ΊΝΩΘΜΕ®“ε“ΜΗωΕάΝΔΒΡ…ΔΝ–Κ· ΐΘ§’βΗωΚ· ΐΜαΗυΨίΥυ«κ«σWebΕ‘œσΒΡURLΖΒΜΊ“ΜΗω ΐΉ÷ΘΜΫΪURL…ΔΝ–Κ· ΐΒΡΫαΙϊ¥ζ»κ¥ζάμΖΰΈώΤςΒΡ…ΔΝ–Κ· ΐΘ§ΒΟΒΫ“ΜΗω ΐΉ÷’σΝ–ΓΘ’β–© ΐΉ÷÷–ΒΡΉν¥σ÷ΒΨωΕ®ΝΥ“ΣΈΣ’βΗωURL Ι”ΟΒΡ¥ζάμΖΰΈώΤςΓΘ”…”ΎΥψ≥ωά¥ΒΡ÷Β «»ΖΕ®ΒΡΘ§Υυ“‘Ε‘Ά§“ΜΗωWebΕ‘œσΒΡΚσΦΧ«κ«σΜα±ΜΉΣΖΔΗχΆ§“ΜΧ®¥ζάμΖΰΈώΤς
“‘…œ4œν»ΈΈώΩ…“‘”…δ·άάΤςΓΔ≤εΦΰ÷¥––Θ§“≤Ω…“‘‘Ύ“ΜΗω÷–ΦδΖΰΈώΤς…œΦΤΥψΓΘΈΣΟΩΗω¥ζάμΖΰΈώΤςΦ·»Κ¥¥Ϋ®“ΜΗω±μΘ§±μ÷–Ν–≥ωΝΥΦ·»Κ÷–ΒΡΥυ”–ΖΰΈώΤςΓΘ±μ÷–ΒΡΟΩΗωΧθΡΩΕΦ”ΠΗΟΑϋΚ§»ΪΨ÷≤Έ ΐΒΡœύΙΊΒΡ–≈œΔΓΘ±»»γΘ§ΗΚ‘Ί“ρΉ”ΓΔ…ζ¥φ ±Φδ(TTL)ΓΔΒΙΦΤ ΐ÷ΒΚΆ”ΠΗΟ“‘ΚΈΤΒ¬ ≤ι―·≥…‘±÷°άύΒΡ»ΪΨ÷≤Έ ΐΓΘΗΚ‘Ί“ρΉ”ΥΒΟςΜζΤςΩ…“‘¥ΠάμΕύ…ΌΗΚ‘ΊΘ§’β»ΓΨω”ΎΡ«Χ®ΜζΤςΒΡCPUΥΌΕ»ΚΆ”≤≈Χ»ίΝΩΓΘΩ…“‘Ά®ΙΐRPCΫ”ΩΎΕ‘¥Υ±μΫχ––‘Ε≥ΧΈ§ΜΛΓΘ÷Μ“Σ±μ÷–ΒΡΉ÷ΕΈ±ΜRPC–όΗΡΝΥΘ§ΨΆΩ…“‘ ΙΤδΕ‘œ¬”ΈΒΡΩΆΜßΕΥΚΆ¥ζάμΩ…ΦϊΘ§ΜρΫΪΤδΖΔ≤ΦΗχΥϋΟ«ΓΘ’βœνΖΔ≤ΦΙΛΉς «‘ΎHTTP÷–Ϋχ––ΒΡΘ§’β―υΘ§Υυ”–ΒΡΩΆΜßΕΥΜρ¥ζάμΖΰΈώΤςΨΆΕΦΩ…“‘‘Ύ≤Μ“ΐ»κΝμ“Μ÷÷¥ζάμΦδ–≠“ιΒΡΜυ¥Γ…œœϊΜ·±μΗώ–≈œΔΝΥΓΘΩΆΜßΕΥΚΆ¥ζάμΖΰΈώΤς÷Μ”ΟΝΥ“ΜΗω÷ΣΟϊURLά¥Μώ»Γ’β’≈±μ
Υυ Ι”ΟΒΡ…ΔΝ–Κ· ΐ±Ί–κΡήΙΜ»Ζ±ΘWebΕ‘œσ‘Ύ≤Έ”κΒΡ¥ζάμΖΰΈώΤςΦδ «Ά≥ΦΤΖ÷≤ΦΒΡΓΘ”ΠΗϔϥζάμΖΰΈώΤςΒΡΗΚ‘Ί“ρΉ”ά¥»ΖΕ®Ζ÷≈δΗχΡ«Χ®¥ζάμΒΡWebΕ‘œσΒΡΆ≥ΦΤΗ≈¬
Ήή÷°Θ§CARP–≠“ι‘ –μΫΪ“ΜΉι¥ζάμΖΰΈώΤςΩ¥≥…ΒΞΗωΒΡΦ·»ΚΜΚ¥φΘ§Εχ≤Μ «(œώICP÷–Ρ«―υΒΡ)“ΜΉιœύΜΞΚœΉςΒΪ”÷œύΜΞΕάΝΔΒΡΜΚ¥φΖΰΈώΤςΓΘ»ΖΕ®ΒΡ«κ«σΫβΈω¬ΖΨΕΜα‘Ύ“ΜΧχΡΎ’“ΒΫΡ≥ΗωΧΊΕ®ΒΡWebΕ‘œσΒΡΦ“ΓΘ’β―υΜαΫΒΒΆICP‘Ύ“ΜΉι¥ζάμΖΰΈώΤς÷–≤ι’“WebΕ‘œσ ±≥ΘΜα≤ζ…ζΒΡ¥ζάμΦδΝςΝΩΓΘCARPΜΙΩ…“‘±ήΟβ‘Ύ≤ΜΆ§ΒΡ¥ζάμΖΰΈώΤς…œ¥φ¥ΔWebΕ‘œσΒΡΕύΗωΗ±±ΨΒΡΈ ΧβΘ§’β―υΉωΒΡ”≈Βψ «ΜΚ¥φœΒΆ≥Φ·»ΚΒΡWebΕ‘œσ¥φ¥Δ»ίΝΩΫœ¥σΘ§»±Βψ «»Έ“β“ΜΗω¥ζάμΒΡΙ ’œΕΦ“ΣΗΡ–¥œ÷¥φ¥ζάμΒΡ≤ΩΖ÷ΜΚ¥φΡΎ»ί
ΓΨ≥§ΈΡ±ΨΜΚ¥φ–≠“ιΓΩ
«ΑΟφΈ“Ο«Χ÷¬έΝΥICPΘ§’βΗω–≠“ι‘ –μ¥ζάμΜΚ¥φœρ–÷ΒήΜΚ¥φ≤ι―·ΈΡΦΰ «Ζώ¥φ‘ΎΓΘΒΪ…ηΦΤICP ±ΩΦ¬«ΒΡ «HTTP/0.9–≠“ιΓΘ“ρ¥ΥΘ§œρ–÷ΒήΜΚ¥φ≤ι―·Ή ‘¥ «Ζώ¥φ‘Ύ ±Θ§÷Μ‘ –μΜΚ¥φΖΔΥΆURLΓΘHTTPΑφ±Ψ1.0ΚΆ1.1“ΐ»κΝΥΚήΕύ–¬ΒΡ«κ«σ Ή≤ΩΘ§’β–© Ή≤ΩΩ…“‘ΚΆURL“ΜΤπ”Οά¥»ΖΕ®ΈΡΦΰ «ΖώΤΞ≈δΓΘ“ρ¥ΥΘ§÷Μ‘Ύ«κ«σ÷–ΖΔΥΆURLΩ…ΡήΈόΖ®ΒΟΒΫΨΪ»ΖΒΡœλ”Π
HTCP(≥§ΈΡ±ΨΜΚ¥φ–≠“ι)‘ –μ–÷ΒήΜΚ¥φ÷°ΦδΆ®ΙΐURLΚΆΥυ”–ΒΡ«κ«σΦΑœλ”Π Ή≤Ω
ά¥œύΜΞ≤ι―·ΈΡΒΒ «Ζώ¥φ‘ΎΘ§“‘ΫΒΒΆ¥μΈσΟϋ÷–ΒΡΩ…ΡήΓΘΕχ«“HTCP‘ –μ–÷ΒήΜΚ¥φΦύ ”Μρ«κ«σ‘ΎΕ‘ΖΫΒΡΜΚ¥φ÷–ΧμΦ”Μρ…Ψ≥ΐΥυ―Γ÷–ΒΡΈΡΒΒΘ§≤Δ–όΗΡΕ‘ΖΫ“―ΜΚ¥φΈΡΒΒΒΡΜΚ¥φ≤Ώ¬‘
HTCP ¬Έώ «Νμ“ΜΗωΕ‘œσΖΔœ÷–≠“ιΓΘ»γΙϊΗΫΫϋΒΡΜΚ¥φ÷–”–’βΗωΈΡΒΒΘ§ΖΔΤπ«κ«σΒΡΜΚ¥φΩ…“‘¥ρΩΣ“ΜΧθΒΫ¥ΥΜΚ¥φΒΡHTTPΝ§Ϋ”Θ§“‘Μώ»ΓΡ«ΗωΈΡΒΒΒΡΗ±±ΨΓΘICPΚΆHTCP ¬Έώ÷°ΦδΒΡ«χ±πΧεœ÷‘Ύ«κ«σΚΆœλ”ΠœΗΫΎ…œ
HTCP±®ΈΡΒΡΫαΙΙ»γœ¬ΆΦΥυ ΨΘ§ Ή≤Ω÷–ΑϋΚ§ΝΥ±®ΈΡΒΡ≥ΛΕ»ΚΆ±®ΈΡΑφ±ΨΓΘ ΐΨί≤ΩΖ÷ΩΣ Φ « ΐΨί≥ΛΕ»Θ§ΑϋΚ§ΝΥopcodeΓΔœλ”Π¥ζ¬κΓΔ“Μ–©±ξΦ«ΦΑIDΘ§ΉνΚσ « ΒΦ ΒΡ ΐΨίΓΘΩ…―ΓΒΡ»œ÷Λ≤ΩΖ÷Ηζ‘ΎData–ΓΫΎΒΡΚσΟφ
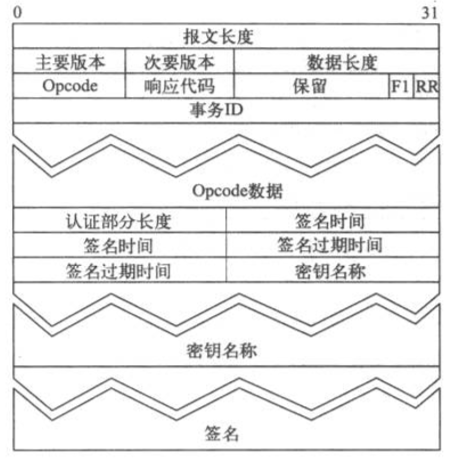
±®ΈΡΉ÷ΕΈΒΡœξœΗΡΎ»ί»γœ¬Υυ ω
aΓΔ Ή≤Ω
Header≤ΩΖ÷ΑϋΚ§32ΈΜΒΡ±®ΈΡ≥ΛΕ»Θ§8ΈΜΒΡ÷ς“Σ–≠“ιΑφ±ΨΚΆ8ΈΜΒΡ¥Έ“Σ–≠“ιΑφ±ΨΓΘ±®ΈΡ≥ΛΕ»ΑϋΚ§Υυ”– Ή≤ΩΓΔ ΐΨίΚΆ»œ÷Λ≤ΩΖ÷ΒΡ≥ΛΕ»
bΓΔ ΐΨί
Data≤ΩΖ÷ΑϋΚ§ΝΥHTCP±®ΈΡΓΘ ΐΨίΉιΦΰ»γœ¬±μΥυ Ψ

œ¬±μΝ–≥ωΝΥHTCP Opcode¥ζ¬κΦΑΤδœύ”ΠΒΡ ΐΨίάύ–Ά
HTCP±®ΈΡΒΡ»œ÷Λ≤ΩΖ÷ «Ω…―ΓΒΡΘ§œ¬±μΝ–≥ωΝΥΥϋΒΡ»œ÷ΛΉιΦΰ

SET±®ΈΡ‘ –μΜΚ¥φ«κ«σΕ‘“―ΜΚ¥φΈΡΒΒΒΡΜΚ¥φ≤Ώ¬‘Ϋχ–––όΗΡΓΘœ¬±μΗχ≥ωΝΥΩ…“‘‘ΎSET±®ΈΡ÷– Ι”ΟΒΡ Ή≤Ω

HTCP‘ –μΆ®Ιΐ≤ι―·±®ΈΡΫΪ«κ«σΚΆœλ”Π Ή≤ΩΖΔΥΆΗχ–÷ΒήΜΚ¥φΘ§’β―υΩ…“‘ΫΒΒΆΜΚ¥φ≤ι―·÷–ΒΡ¥μΈσΟϋ÷–¬ ΓΘΆ®ΙΐΫχ“Μ≤Ϋ‘ –μ‘Ύ–÷ΒήΜΚ¥φΦδΫΜΜΜ≤Ώ¬‘–≈œΔΘ§HTCPΜΙΩ…“‘ΧαΗΏ–÷ΒήΜΚ¥φ÷°ΦδΒΡΚœΉςΡήΝΠ |









