| ���Ż������IJ��Ϸ�չ���ճ�������Խ��Խ�������ͨ��������ʵ�֣�����ʳס�е����ڽ������ӿڴ������ݣ�������ʱ�̲����������磬����Խ��Խ�����ͨ������������Լ�������
��Ϊֱ��������Կͻ������Web����ˣ�����Ҫͬʱ���ܸ��������Ϊ�û��ṩ���õ����顣���ʱ��Web�˵����ܳ������Ϊҵ��չ��ƿ�����������̲ܿ��ݻ������������ڿ����������ܽ���һЩ����Web��������ܵľ��飬���ҷ�����
�������
����Web��������ܣ��������Ƿ���һ�����ָ�ꡣ���û��ǶȽ����û�����Web����ʱ������ʱ��Խ�̣��û�����Խ�á��ӷ���˽ǶȽ���ͬһʱ���ܳ����û�������Խ��������ܾ�Խǿ���ۺ������棬�����ܽ������Ż�����������
1. ���ӷ��������֧�Ų�����������������
2. ���ÿ���������ٶȡ�
��ȷ���Ż��������Ƚ���һ�ַ����ͨ���ļܹ�ģʽ�����������������App��Webһ�������ڷ���˾����ļ���ṹ�����������صġ�
�ܹ�ģʽ��IP���ؾ���->���������->�������->Ӧ�÷�����->���ݿ�
��ͼ1��ʾ��Ϊ��˵�����㣬�������ٸ�ʵ�ʵ�����: LVS(Keepalived)->Squid->nginx->Go->MySQL
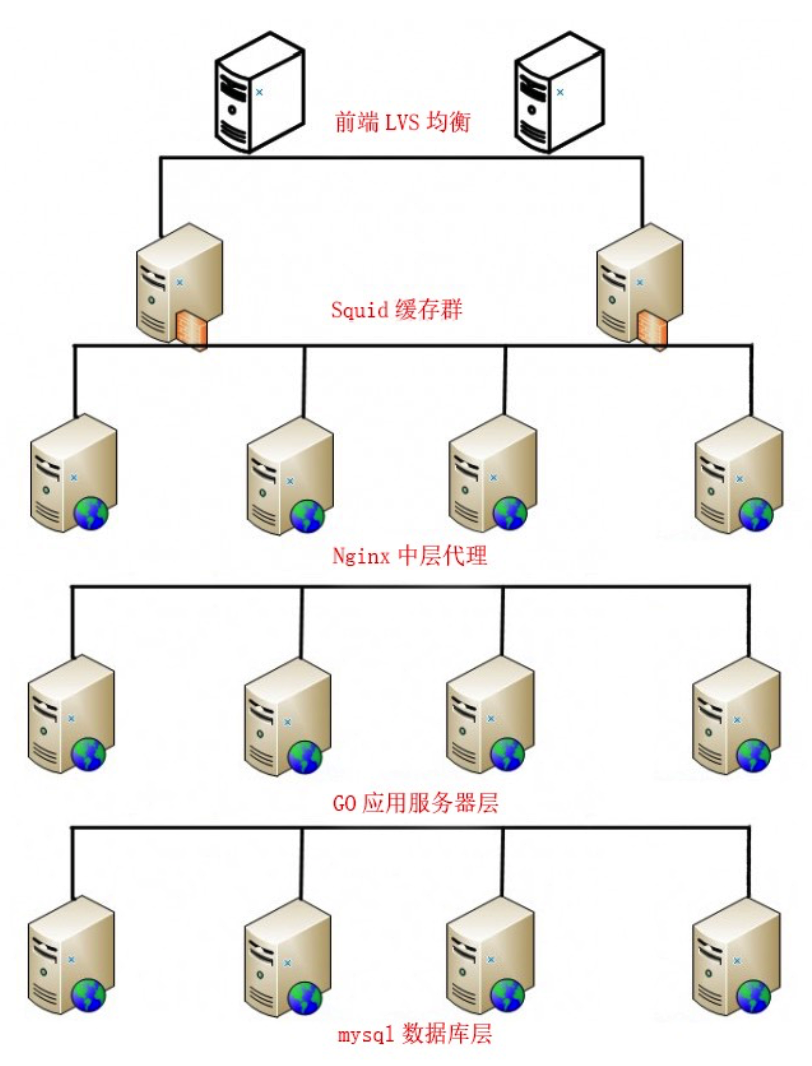
ͼ1������˼ܹ�
���Ƕ�������ÿ�����ַ���������������ʹ��һ���ṹ�ж����֧ͬʱ�����������������������
��ϼܹ�������������ͨ������Щ�������������ܵĺ��ȣ��Լ��ҳ���Ӧ�Ľ��������
��������£�IP���ؾ��⣬�����������nginx�����⼸����Ҫ�Ǽ�Ⱥ�ȶ������⡣���׳�������ƿ���ĵط�������Ӧ�÷�����������ݿ�㣬�����������оټ������ӣ�
1. ������Ӱ��
��1�����⣺
��Web�������������ʵģ���һ��������ʱ�����̾ͻᱻ����ռ��CPU��ֱ��������ɡ��ڴ��������£�Web������ɵ��㹻�죬����������Ⲣ������ע��Ȼ����������Щ��Ӧʱ������ɵ����������������������ⲿAPI��������ζ��Ӧ�ó�������ֱ���������������ڼ䣬���������ᱻ�����������ԣ���Щ��Ч�ĵȴ�ʱ���˷ѵ��ˣ�����ռ��ϵͳ��Դ�����ص�Ӱ�������ǿ��Ը����IJ��������������
��2������취��
Web������ڵȴ���һ���������Ĺ����У����ǿ�����I/Oѭ�����Ա㴦������Ӧ������ֱ���������ʱ����һ�������跴�����������ǵȴ�������ɵĹ����й�����̡����������ǿ��Խ�ʡһЩû�б�Ҫ�ĵȴ�ʱ�䣬����Щʱ��ȥ��������������������ǾͿ��Դ�������������������Ҳ�����ں������������ǿɴ����IJ�����������
��3������
����������Python��һ��Web���Tornado������˵���ı�������ʽ��߲������ܡ�
���������ǹ���һ����Զ�ˣ�ij��ʮ���ȶ�����վ������HTTP����ļ�WebӦ�á����ڼ䣬���紫���ȶ������Dz���������������Ӱ�졣
����������У�����ʹ��Siege��һ��ѹ�������������Է������10����ִ�д�Լ10����������
��ͼ2��ʾ�����ǿ��Ժ������������������������ÿ�������������ض�ô�죬��������Զ�˵ķ�������������������㹻����ͺ���Ϊ����ֱ��������ɲ������ݱ�����ǰ��һֱ����ǿ�ƹ���״̬����һ��������ʱ�����һ�����⣬���ﵽ100��������10�����û�ʱ������ζ�������������ͼ������10��ʱ��10�������û���ƽ����Ӧʱ��ﵽ��1.99�룬����29�Ρ��������ֻչʾ�˷dz������������Ҫ��������ҵ���������ݿ�ĵ��õĻ�����������⡣���Ӹ�����û�����ʱ��ͬʱ�ɱ�����������ͻ�����������������Щ����ᷢ����ʱ��ʧ�ܡ�
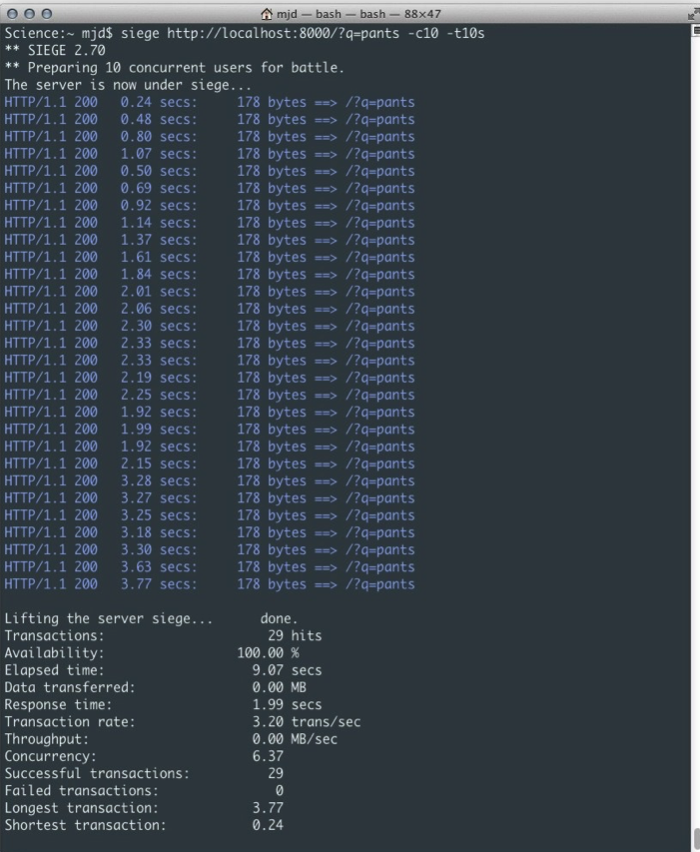
ͼ2������ʽ��Ӧ
����������Tornadoִ�з�������HTTP����
��ͼ3��ʾ�����Ǵ�ÿ��3.20��������������12.59������ͬ��ʱ�����ܹ��ṩ��118������������һ���dz���ĸ��ƣ�������������ģ������û���������Ͳ���ʱ������ʱ�������ܹ��ṩ�������ӣ����Ҳ�����������汾���ܵı��������⡣�Ӷ��ȶ�������˿ɸ��صIJ�����������
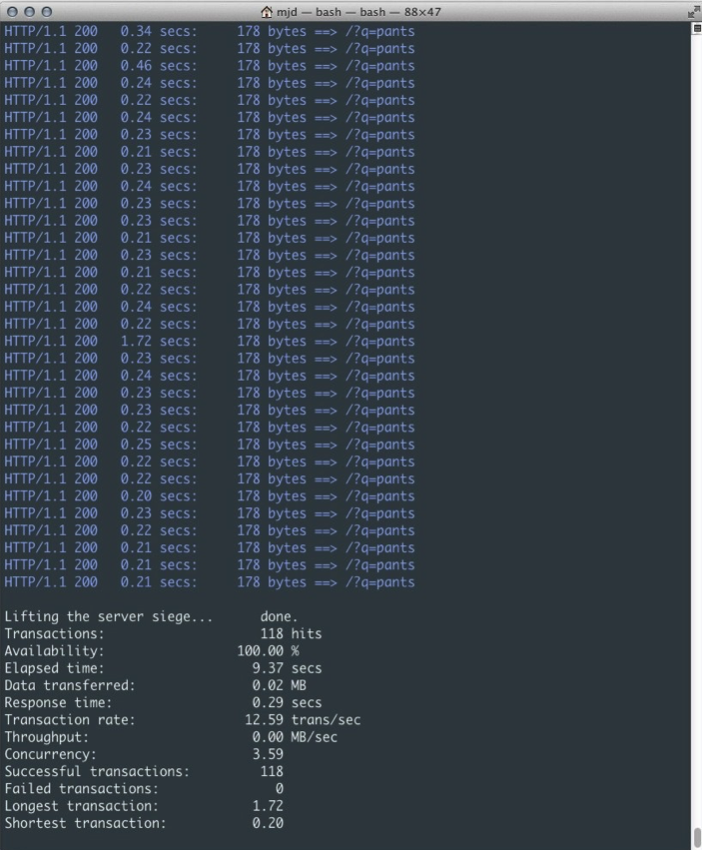
ͼ3��������ʽ��Ӧ
2. ����Ч�ʶ���Ӧʱ��Ͳ�������Ӱ��
��������һ�»���֪ʶ��һ��Ӧ�ó����������ڻ����ϵ�һ�����̣�������һ���������Լ��ڴ��ַ�ռ���Ķ���ִ���塣һ��������һ����������ϵͳ�߳���ɣ���Щ�߳���ʵ�ǹ���ͬһ���ڴ��ַ�ռ��һ������ִ���塣
��1������
��ͳ���㷽ʽ���߳����У�Ч�ʵͣ�������������
��2������취
һ�ֽ���취������ȫ����ʹ���̡߳����磬����ʹ�ö�����̽��ص���������ϵͳ�����������ǣ��и����ƾ��ǣ����DZ��봦�����н��̼�ͨ�ţ�ͨ����ȹ����ڴ�IJ���ģ���и���Ŀ�����
��һ�ְ취���ö��̹߳��������������ϵģ�ʹ�ö��̵߳�Ӧ����������ȷ��ͬ����ͬ���̣߳������ݼ���������ͬʱ��ֻ��һ���߳̿��Ա�����ݡ�������ȥ������������������������������ߵĸ��Ӷȣ�������ʹ��������Լ����͵����ܡ�
��������Ҫ���������ڴ��е����ݹ��������ǻᱻ���߳�����Ԥ֪�ķ�ʽ���в���������һЩ�����ֻ�������Ľ������������̬�����������������ķ������Բ����ʺ��ִ����/�ദ������̣�thread-per-connection
ģ�Ͳ�����Ч�������ȽϺ��ʵķ�ʽ�У��и������� Communicating Sequential Processes��˳��ͨ�Ŵ�������CSP,
C. Hoare �����ģ�����һ������ message-passing-model����Ϣ���ݣ����Ѿ������������������У�����
Erlang����
��������ʹ�ð취�����ò��еļܹ�����������һ���������������һ�������������ں���ʹ�ö���߳���ִ��������ֻ��ͬһ��������ij��ʱ���ͬʱ�����ڶ�˻��߶ദ�����ϲ��������IJ��С�
������һ��ͨ��ʹ�öദ����������ٶȵ����������Բ�����������Dz��еģ�Ҳ���Բ��ǡ�
����ģʽ����ͬʱʹ�ö��̡߳���ˡ��ദ�����������������������ɿ��Ե���������Դ���Ӷ�ѹ����Ӧʱ�䣬��������Ч�ʣ��������ǿ�˷���˵����ܡ�
��3������
������Go�����е�Goroutine������˵����
��Go�����У�Ӧ�ó��������IJ��ֱ����� goroutines��Э�̣��������Խ��и���Ч�IJ������㡣��Э�̺Ͳ���ϵͳ�߳�֮�䲢��һ��һ�Ĺ�ϵ��Э���Ǹ���һ�������̵߳Ŀ����ԣ�ӳ�䣨��·���ã�ִ���ڣ�������֮�ϵģ�Э�̵�������
Go ����ʱ�ܺõ���������������Э���������ģ����̸߳��ᡣ���Ǻۼ��dz������ԣ�ʹ���������ڴ����Դ����ʹ��
4K ��ջ�ڴ�Ϳ����ڶ��д������ǡ���Ϊ�����dz����ۣ���Ҫ��ʱ��������ɴ��������д�����Э�̣���ͬһ����ַ�ռ���
100,000 ��������Э�̣����������Ƕ�ջ�����˷ָ�Ӷ���̬�����ӣ����������ڴ��ʹ�ã�ջ�Ĺ������Զ��ģ������������������������ģ�������Э���˳����Զ��ͷš�Э�̿��������ڶ������ϵͳ�߳�֮�䣬Ҳ�����������߳�֮�ڣ�������Ժ�С���ڴ�ռ�þͿ��Դ����������������ڲ���ϵͳ�߳��ϵ�Э��ʱ��Ƭ�������ʹ�������IJ���ϵͳ�߳̾���ӵ���������ṩ�����Э�̣�����
Go ����ʱ���Դ�������ʶ����ЩЭ�̱������ˣ���ʱ�������Dz���������Э�̡���������������ڲ�ͬ�Ĵ������ͼ������ͬʱִ�в�ͬ�Ĵ���Ρ�
����ͨ���뽫һ������������зֳɼ��飬Ȼ����ÿ��goroutine���Ը���һ�鹤�����������ڵ�һ�������Ӧʱ���гɱ���������
�ٸ����ӣ���һ�������3���Σ�a��ȥ���ݿ�a��ȡ���ݣ�b��ȥ���ݿ�b��ȡ���ݣ�c�κϲ����ݷ��ء���������goroutine�Ժ�a��b�ο���һ����У��������������Ӧʱ�䡣
˵���˾��Dz��ּ�������ɴ���ת��Ϊ���У�һ��������Ҫ�ȴ������ص�����ִ������ִ�У�ʵ�ʼ����г���IJ���ִ�л�����ô���
�����ⲿ����֤�����ݾͲ�����߹��������ˣ�����Ȥ��ͬѧ�����Լ���һ���ⷽ������ϡ�����Web�������Ruby�л�ΪGo��������15�����Ϲ��£�Rubyʹ�õ�����ɫ�̣߳���ֻ��һ��CPU�õ����ã�����Ȼ������¿����е����Dz��д��������������Ǻ������ʵġ���Ruby�л�ΪGo��http://www.vaikan.com/how-we-went-from-30-servers-to-2-go/����
3. ����I/O�����ܵ�Ӱ��
(1) ����
���̶�ȡ���ݿ����ǻ�е�˶���ÿ�ζ�ȡ���ݻ��ѵ�ʱ����Է�ΪѰ��ʱ�䡢��ת�ӳ١�����ʱ���������֣�Ѱ��ʱ��ָ���Ǵű��ƶ���ָ���ŵ�����Ҫ��ʱ�䣬��������һ����5ms���£���ת�ӳپ������Ǿ�����˵�Ĵ���ת�٣�����һ������7200ת����ʾÿ������ת7200�Σ�Ҳ����˵1������ת120�Σ���ת�ӳپ���1/120/2
= 4.17ms������ʱ��ָ���ǴӴ��̶���������д����̵�ʱ�䣬һ������㼸���룬�����ǰ����ʱ����Ժ��Բ��ơ���ô����һ�δ��̵�ʱ�䣬��һ�δ���I/O��ʱ��Լ����9ms��5ms+4.17ms�����ң���������ͦ�����ģ���Ҫ֪��һ̨500
-MIPS�Ļ���ÿ�����ִ��5����ָ���Ϊָ���������ǵ�����ʣ����仰˵ִ��һ��I/O��ʱ�����ִ��40����ָ����ݿ��ʮ���������ǧ�����ݣ�ÿ��9�����ʱ�䣬��Ȼ�Ǹ����ѡ�
(2) ����취
����I/O�Է��������ܵ�Ӱ��û�и����Ľ���취��������Ѵ����ӵ������ɱ�Ķ������������������ѵ����ִ洢���ʵ���Ӧ�ٶ���۸��������Ǯ����Ϳ������Եĸ����洢���ʡ�
�ڲ������洢���ʵ������£����ǿ��Լ���Ӧ�ó���Դ��̵ķ��ʴ������������û��棬�����Ѳ��ִ���I/O�ŵ����������⣬�����ö��к�ջ���������ݵ�I/O�ȡ�
4. �Ż����ݿ��ѯ
����ҵ��ģʽ�ı仯������ʽ������Խ��Խ����ŶӲ��ã�����Խ��Խ�̣��ܶ����ݿ��ѯ��䶼�ǰ���ҵ������д��ʱ����˳����ͺ�����SQL��ѯ�ĸ�ʽ���⣬������ݿ�ѹ�������ӣ�ʹ���ݿ��ѯ����Ӧ�������������MySQL���ݿ��У����������Ǻ��Եij���������Ż���ʽ��
1.����ǰƥ��ԭ�dz���Ҫ��ԭ��MySQL��һֱ����ƥ��ֱ��������Χ��ѯ(>��<��between��like)��ֹͣƥ�䣬����a
= 1 and b = 2 and c > 3 and d = 4 �������(a,b,c,d)˳���������d���ò��������ģ��������(a,b,d,c)�����������õ���a,b,d��˳��������������
2.����ѡ�����ֶȸߵ�����Ϊ���������ֶȵĹ�ʽ��count(distinct
col)/count(*)����ʾ�ֶβ��ظ��ı���������Խ������ɨ��ļ�¼��Խ�٣�Ψһ�������ֶ���1����һЩ״̬���Ա��ֶο����ڴ�������ǰ���ֶȾ���0���ǿ������˻��ʣ����������ʲô����ֵ��ʹ�ó�����ͬ�����ֵҲ����ȷ����һ����Ҫjoin���ֶ����Ƕ�Ҫ����0.1���ϣ���ƽ��1��ɨ��10����¼��
3.����ʹ���������ֶΣ���ֻ����ֵ��Ϣ���ֶξ�����Ҫ���Ϊ�ַ��ͣ���ή�Ͳ�ѯ�����ӵ����ܣ��������Ӵ洢������������Ϊ�����ڴ�����ѯ������ʱ������Ƚ��ַ�����ÿһ���ַ��������������Ͷ���ֻ��Ҫ�Ƚ�һ�ξ��ˡ�
4.�����в��ܲ�����㣬�����С��ɾ���������from_unixtime(create_time)
= ��2014-05-29���Ͳ���ʹ�õ�������ԭ��ܼ�b+���д�Ķ������ݱ��е��ֶ�ֵ�������м���ʱ����Ҫ������Ԫ�ض�Ӧ�ú������ܱȽϣ���Ȼ�ɱ�̫���������Ӧ��д��create_time
= unix_timestamp(��2014-05-29��);Ӧ���������� where �Ӿ��ж��ֶν���
null ֵ�жϣ��������������ʹ�á�
5.����������ȫ��ɨ�裬�磺
select id from t where num is null
������num������Ĭ��ֵ0��ȷ������num��û��nullֵ��Ȼ��������ѯ��
select id from t where num=0
6.Ӧ���������� where �Ӿ���ʹ�� or �������������������������ʹ������������ȫ��ɨ�裬�磺?
select id from t where num=10 or num=20?
����������ѯ��
select id from t where num=10? union all? select id
from t where num=20
7.����IJ�ѯҲ������ȫ��ɨ��(����ǰ�ðٷֺ�)��
select id from t where name like ��%abc%�� ��Ҫ���Ч�ʣ����Կ���ȫ�ļ�����
8.in �� not in ҲҪ���ã�����ᵼ��ȫ��ɨ�裬�磺
select id from t where num in(1,2,3)
������������ֵ������ between �Ͳ�Ҫ�� in �ˣ�
select id from t where num between 1 and 3
�ܽ�
����һ��Web���������оٳ��˼����������ֵ����⣬ϣ�����Ķ��ĸ�λ������������Ȼ����в�ͬ���뷨��ӭһ����̽�֡� |






