| 前言:本人于
2014 年底开始供职于百度贴吧(以下简称“贴吧”)。贴吧作为中国最大规模的 UGC 产品之一,在PC和移动端上承载了数亿用户的访问。在过去十几年的运营中,贴吧积累了十分复杂的业务模式。在
Web 前端,一度有超过40名工程师同时开发、提交和上线,为此,贴吧建设了非常复杂和完备的开发体系。但随着业界技术的不断进步,贴吧的技术架构也在不断尝试和调整,我们在此过程中也不断遭遇了新的挑战,相应地也就引出了本文的内容,而它的意义远远不限于贴吧这一产品本身。
一、背景
项目构建,或者称之为编译,早已经成为了 Web 前端项目在发布过程中的一个必不可少的环节。从最早的 JavaScript
与 CSS 压缩合并,发展到今天 ES2015、ES2016、Less、Sass 等预处理语言的转换,构建的压力越来越大,其流程也越来越复杂,简单的
Shell、Make、Ant 等单纯的任务处理工具早已经不能很好地满足需求,一个是效率问题,一个是可扩展性问题。因此,业界依托
NodeJS,发展出了多个优秀的开源构建工具,它们有的专注于 Web 前端项目集成化,提供简单易用的编程接口,有的专注于柔韧性,容易扩展,已经不再仅仅局限于能处理特定的项目类型。
但是,随着项目复杂度的提升,这些构建工具也会慢慢暴露出一些不足,主要体现在性能和效率上,这会让原本已经由于复杂的流程导致的慢构建雪上加霜。本文以一个同构
JavaScript 应用为例,来说明典型的大型复杂前端项目构建中遇到的效率瓶颈以及解决问题的一些思路。同构
JavaScript 应用的特点是,同一份 JavaScript 源代码既需要运行在 NodeJS 服务端,又需要运行在浏览器客户端,同时还要考虑到其它静态资源如
CSS、图片和多媒体。
下图是该项目构建流程的一个简化版本,可以看到,不同来源的 JavaScript 文件都有两个构建分支,即流程分解,并且还存在不同源文件的构建流程合并的情况。此外,对于不需要任何构建环节的其它(遗留的)文件,比如可能的配置文件、二进制静态资源文件、自定义文件类型等等,我们要求它们只有拷贝到目标目录就可以了。以此为例,并考虑到性能和效率问题,我们对构建工具的最低要求包括:
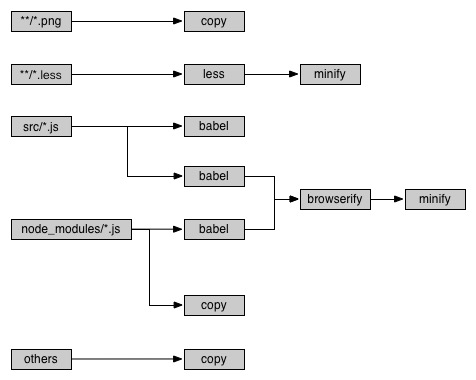
支持对任意文件的任意数量、任意流程的构建:Web 前端项目的架构变幻无穷,相对应的构建流程可能是任意的,并且无法预测,事实是,我们的前端架构确实多种多样。如上图中,不同文件的构建流程已经不再是单纯的平行序列图,而是一个有向的拓扑图。这就要求构建工具对流程的定制非常灵活,只要是合理的(包括但不限于不含有向环),就应该可以实现。
支持文件级别的构建增量:构建分为全量构建和增量构建,顾名思义,全量构建是完全从源文件读取后进行构建,增量构建为仅构建最少的必要文件,是全量构建之后应对部分文件被其它进程修改的策略。相比于全量构建,增量构建在速度上有显著的优势,通常用于开发者本地的实时预览和部署,提升开发效率。增量构建要求尽可能避免不必要的文件构建,同时要求对于可能受影响的所有文件,都必须连带构建,保证实时性。
支持遗留文件的提取:构建一般是针对特定类型的文件的,这通过枚举来实现。在项目中,往往还存在着一些难以枚举的文件资源,这些资源可能不需要任何处理,只要保证在项目构建之后保留原样即可,包括文件内容和文件路径。如何需要对它们也进行构建操作,则不必挨个执行文件选择,因为这可能非常繁琐。
下面我们先讨论现有开源构建工具在满足以上需求时的不足之处,再想方设法予以改进。
二、现有方案
Web 前端领域常用的几款构建工具,包括 Grunt、Gulp、Webpack。
Grunt 资历最深,因此也发展出了非常繁荣的插件生态。它基于 glob 选择文件集合并执行配置好的构建流程。Grunt
是基于文件构建的,因此在构建中的每一个环节都必须读取和写入磁盘文件,这是 Grunt 最为人诟病的地方,因为这意味你要想办法为每一个构建环节设计文件的输入输出目录,保证不与其它流程发出冲突;再一点就是读取写入磁盘文件过于消耗时间,导致
Grunt 在构建大型复杂项目时比较缓慢。在增量构建上,Grunt大多以“任务”为单位,这其中会包含很多不必要文件的构建。除非在必要的环节中手动设计缓存,否则
Grunt 也不显式支持缓存。此外,Grunt 不能提取遗留文件。
Gulp 与 Grunt 比较类似,定位也近乎相同,与 Grunt 的最大的不同是 Gulp 是基于流(Stream)构建的而不是文件。这个特性节省了对文件的大量磁盘读写操作,使得
Gulp 的构建速度有了明显的提升。更重要的是,Gulp 可以让构建流程配置起来更清晰简单,支持流程分解,但不支持流程合并。Gulp
也有与 Grunt 一样的增量构建粒度的问题,同时也不能提取遗留文件。
Webpack 与其说是构建工具,倒不如说是模块打包器,官方的说法是叫做 “Module Bundler”。它与
Gulp 和 Grunt 并没有太多可比性,也不能很好地完成我们的任务。但 Webpack 有两个能力是值得借鉴的,即
“loader” 中缓存单个文件构建结果的能力,以及对文件之间依赖关系的定制能力。熟悉编写 Webpack
loader 的人可能会对addDependency 方法比较熟悉,这个方法用于声明文件之间的依赖关系。这在增量构建时非常有用,例如
a 依赖于b,那么如果 b 文件需要重新构建,那么显然,a 也必须舍弃缓存,重新构建
可见 Grunt、Gulp 和 Webpack 虽然都是 Web 前端构建常用的优秀开源工具,但在应用于复杂项目时,仍存在一些可优化之处。构建工具本身的能力、效率和性能提升将让任意架构更加容易实现,不再让大胆的设计受限于工具。
三、关键改进
基于同构 JavaScript 应用的实际构建需要,针对我们刚刚分析的现存构建工具的不足,我们实施了从以下几点出发的改进。为便于语义表述,本文使用
TypeScript 语言编写代码示例,但在实际实现时一般直接由 JavaScript 语言来承担所有任务。
1. 节点缓存
项目构建的本质是对文件变换操作的有序排列集合。变换一般是针对文件内容的,如空白压缩、语法转换,于是,我们将变换抽象为一个函数
transform,它的输入是文件的的内容,可以是二进制的 Buffer,也可以是文本的字符串(String),输出则是转换后新的文件内容。用接口语法表示即如下面的代码块。将多个
Transformer 串联起来就是常规的构建过程。
interface Transformer {
transform (content: string): string;
} |
显然,对于相同 content 的值,如果 transform 的返回值一直保持相同,那么第一次以后的操作都是不必要的,因为无论重复多少遍返回都是一样。如果熟悉
redux,那么一定对其中的 reducer 概念印象深刻,它是一个“纯函数(pure function)”,无论什么时候,同样的输入总是有同样的输出。该特性也是
Transformer 能够实现缓存的基础,也就是说,以 content 为索引,只要索引不变,缓存就可以一直有效,构建速度也会大幅度提升。在实际的操作中,可以取content
的 md5 值作为实际的索引,于是一个典型的可缓存 Transformer 可以是这样的:
class FooTransformer implements Transformer {
transform (content: string) {
let key = md5(content);
if(cache.has(key)) {
return cache.get(key);
} else {
const newContent = this._transform(content);
key = md5(newContent);
cache.set(key, newContent);
return newContent;
}
}
} |
然而并非所有 transform 方法都有一个入参,例如 Transformer 可能需要一个 options
构造参数,它极有可能导致在相同的 content 上产生不一致的输出。在这情况下,不建议再使用缓存机制,如果一定要使用的话,那么
key 值的算法将会开始变得复杂起来,并且容易导致出错。所以,明确你的 transform 到底做了什么,再使用缓存机制提升构建速度。
另外, transform 方法的入参很可能不是仅仅一个 content,而是一个集合,这种情况下,文件名也要用来区分它们,你需要的不是一个
transform,而是一个 transformAll,入参则是 File 的集合 FileCollection,而
File 对象,至少必须包括 filename 和 content 两个属。Transformer 接口的定义则为:
interface File {
filename: string;
content: any;
}
interface FileCollection {
[index: number]: File;
}
interface Transformer {
transform (file: File): File;
transformAll (files: FileCollection): FileCollection;
} |
针对这两种类型的 Transformer,我们以一个属性来做区分:
interface Transformer {
isTorrential(): boolean;
} |
在 isTorrential() 方法返回真时,transformAll 方法将代替 transform
被调用。显然,由于入参变得非常多,设置缓存也变得困难重重,索性直接抛弃不要。需要指出的是,transformAll
的内部可以调用 transform。
最后,transform 和 transformAll 可能都不是同步的,返回一个 Promise 比返回一个
String 或 File 对象更合适。
总结一下,本节分析了项目构建的实质和基本单元,在基本单元 Tranformer 中设置缓存可以有限提升构建的速度。但要清楚地知道什么时候该使用缓存,什么时候不该使用,始终让构建行为符合预期。
2. 拓扑路径
前面提到,项目构建是由 Transformer 的有序集合构成的,Transformer 可以分解也可以合并,这非常像水流,因此我们形象地称之为
Stream。每一个 Stream 对象内部维护最多一个 Transformer 实例成员,并以 File
对象的集合作为Stream 的有效载荷,一般地,它们往往在某种意义上是同类型的文件。
interface Stream {
tranformer: Transformer;
} |
由于流与流之间的关系构成了一个有向的拓扑图,因此 Stream 对象需要维护与其它 Stream 之间的关系,添加
uprivers和 downrivers 成员以实现,分别称为直属“上游流”和直属“下游流”:
interface Stream {
uprivers: StreamCollection;
downrivers: StreamCollection;
}
interface StreamCollection {
[index: number]: Stream;
push(stream: Stream):number;
} |
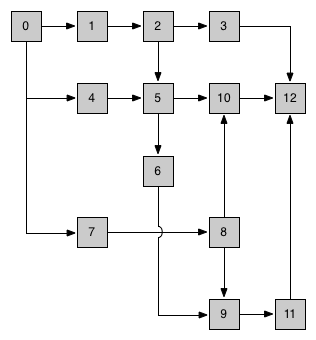
以下图为例,图中序号 ① 的 downrivers 为 [②,⑤], ② 的 uprivers 为 [①,④],依此类推。

downrivers 数量大于1的流称为“分解流”,uprivers 数量大于1的流称为“合并流”。上图中,①
为分解流,② 为合并流。顾名思义,分解流是一个以上构建流程具有相同上游公共部分的简单表述,但合并流却并不总是代表一个以上的构建流程具有相同的下游公共部分,更重要的是,合并流的输入是其所有上游流的输出。对于合并流来讲,它的输入文件极有可能有着不同的来源。举一个现实的例子,输入
browserify 的文件极有可能来自 node_modules 目录内,但更多来自于你在 src 目录编写的源代码。显然,这两种来源的文件很容易有着不同的前期构建流程,比如源代码是由
ES2015 编写的,但 node_moduels 则为 ES5 语法。
在构筑流的拓扑图的时候,我们可以定义一个 connect 方法来建立它们之间的联系:
interface Stream {
connect(downriver: Stream): Stream;
}
class FooStream implements Stream {
connect (downriver: Stream) {
this.downrivers.push(downriver);
downriver.uprivers.push(this);
return downriver;
}
} |
那么建设上图中的拓扑的代码就可以是:
s1.connect(s2).connect(s6).connect(s3)
s1.connect(s5).connect(s4).connect(s2); |
实际的流拓扑图大多数是二维的,不过达到三维的复杂度也是合理的,请看下图。先不论此图是否反应了项目构建的一个真实流程,至少它表达了构建流程可能达到的复杂度。
下面我们就以上图为例探讨流拓扑图的正确工作方式。首先,基于性能和功能考量,我们的目标包括,在完整的一次构建流程中:
包括分解流在内的所有流,都只能运行一次。这意味着,同一个文件不会被传入 Stream 的 transformer
成员一次以上;
合并流的所有上游流运行完毕后,合并流才能开始运行,原因刚刚已经说明,它需要上游流的所有输出加和同时作为输入
我们把 Stream 的入口 API 方法称为 flow:
interface Stream {
flow (files: FileCollection): Promise;
} |
上一节提到,transform/transfromAll 方法的返回值应该是 Promise,那么 flow
的返回值也同样是 Promise。
每个流在执行 flow 操作时,其实质都是在调用其内部的 transformer 成员,根据 isTorrential()
返回值的不同来决定调用它的 transform 或者 transformAll 方法。从这里可以看到,其实
Transformer 内部的缓存也可以移至 Stream 中存储,在 Transformer 会更灵活一些。由于构建行为的任意性,Transformer
将是非常重要的扩展点,注意保持它的轻量性。
class FooStream implements Stream {
public flow (files: FileCollection) {
if (this.transformer.isTorrential()) {
return this.transformer.transformAll(files);
} else {
return Promise.all(files.map(file => this.transformer.transform(file)));
}
}
} |
但一个流完成后,它可能还要把自身的输出传递给下游流(注意:也可以不传递,但仍然要通知)。因此,在 flow
中,最后还需要依次通知每一个下游流,通知的接口不妨称之为 notify:
interface Stream {
notify (files: FileCollection): Promise;
} |
注意各个下游流是依次被 notify 的,如果能保证下游流之间没有先后的依赖关系,那么它们确实可以并行,这种依赖关系可能不仅仅体现在拓扑图上,因为拓扑图只表达了文件传递方向的关系。除此之外,你还可以实现其它维度的依赖,为此,下游流以串行的方式运行会更保险一些。
注意,传递给下游流的数据一定是拷贝,避免下游流修改上游流的缓存。
当一个流的所有上游流都完成后,它才开始运行,所以,notify 十分有必要在适当的时机激活自身 flow:
class FooStream implements Stream {
public notify (files: FileCollection) {
this.files.push(...files);
if (this.isUpriversAllReady) {
return this.flow(this.files);
}
}
} |
这样,我们能够保证合并流在正确的时机去运行,也就实现了这类特殊的构建任务。回过头来看上面的那张拓扑图,箭头代表了依赖关系,节点的数字就代表了执行的顺序。读者可以自行思考为什么是这样的顺序。需要注意的是,根据依赖关系定义的先后,最终的执行顺序也是不同的,只要分支没有依赖关系,下游流的顺序先后就无所谓了。
总结一下,本节我们讨论的是如何定义和实现 API 以支持任意的构建流程。构建的灵活性始终是本文讨论的重点,因为你无法想象半年甚至三个月后你的项目会复杂到什么程度,构建系统的建设是一个成本很大的投入,并且会经常随着项目架构的变化而变化,保证充分的可扩展性,会让你面对快速变化时伸缩自如。相比于
Grunt 和 Gulp,我们期望以一种更高效和更直观的方式定义自己的构建流程。
3. 依赖图谱
一个项目中所包含的文件类型可能非常多,特别对于 Web 前端而言,HTML、JavaScript、CSS
和各种图片是必不可少的,近年来,Less、Sass、JSX、ES2015 等前处理语法越来越多,每一种都需要特殊的构建流程。而这些流程的顺序显然不是任意的。在配置
Grunt、Gulp 任务时,我们会下意识地先去处理图片等二进制资源,再处理 CSS 和 JavaScript,最后处理
HTML。这是因为不同种类的文件之间有着微妙的依赖关系:现代的前端构建中,对于静态资源,都会采用文件名加时间戳的方式来规避缓存的影响,这个过程一般是该类型文件的之后一个构建步骤,如果要引用它的最终路径,就必须等到它完全构建完毕。眼光放宽广的话,依赖关系远远不止引用路径这一种形式,如果需要的话,你可以把一些构建的结果信息存储于内存中,作为其它类型文件构建的一种输入。总之,不要将文件之间的依赖关系固化,HTML
依赖 JavaScript 不止有 标签这一种形式,CSS 引用图片也不止 background(-image)
这一种。
想达到支持任意的构建流程,定制文件之间的依赖关系是必不可少的,就像 Webpack 的 addDependency方法一样,你可以以任意方式实现这样一个
API:
addDependency('a.css', 'd.png'); |
有了它,你可以自定义多种依赖关系,举个例子,在任意文件中,使用 __uri() 的语法来引用其它静态资源文件的最终线上路径,这不是标准的引用关系,但也许你用得着它。
对于项目初次的全量构建,文件之间的依赖只要人工保证其顺序就可以了,但对于之后的 watch 增量构建,依赖关系就变得极为重要。试想你是如何定义
Grunt 或 Gulp 的 watch 动作的,是不是需要配置监听的目录以及要执行的任务?后面的任务由于无法得知到底是哪些文件被修改了,因而不得不都要重新构建一遍。相比之下,Webpack
的增量构建就要迅速得多,几乎是瞬时的,因为它掌握了哪些文件不需要再构建的信息――被修改的文件以及依赖它的所有其它文件都需要重新构建,其它都不需要再构建。这也是一个比较抽象的拓扑图,幸运地是,这个算法非常简单,你只需要递归地收集各个拓扑图上的节点就可以了。
总结一下,文件之间精确的依赖关系是实现高速增量构建的基石,它将增量的维度控制在了文件级别。实时修改和预览是开发过程中的一个重要特性,尤其对于
Web 前端。如果设计合理的话,全量构建的逻辑也可以弱化为一种增量构建,这样看来,全量和增量并没有本质区别。
4. 全量搜索
我们希望构建工具能够覆盖到项目中的所有文件,而不仅仅是 Grunt 和 Gulp 中任务覆盖的那些。这样做有什么好处呢?答案是你的构建逻辑可以不必维护对这些文件资源细节的处理,同时还能轻易实现它们的发布。举个例子,有一些静态资源,包括各种格式的音频、视频和图片,以及其它自定义的特殊格式,它们不需要经过任何的构建处理,只需要发布到特定的目录下,以供
Web 浏览者访问。在 Grunt 和 Gulp 中,你需要时刻注意你的选择器是否选中了它们,否则就会被遗漏。当文件的路径和类型不可枚举时,维护构建的选择器就成了一项负担,也是一项风险,你不能保证所有文件都被选中了,特别是引用了第三方的组件,比如
node_modules。
gulp.src('assets/*.
{mp4,rmvb,mp3,avi,srt,png,jpg,bmp,ico,webp,zip,rar,gz,pptx,docx,xlsx}') |
为了解决这个问题,我们将项目目录下的所有文件都找出来,包括 node_modules、bower_components、jspm_packages
等依赖,一个都不要落下。由于项目构建还是要基于文件选择器的,毕竟同一类的资源才能走同一个构建流程。我们针对每一个选择器来创建一个文件集合,凡是匹配该选择器的文件都放到这个集合中:
interface MatchPair {
files: FileCollection;
selector: any;
headStream: Stream;
} |
我们这里使用的选择器语法是 multimatch,因此支持数组或字符串。
现在,创建一个新的文件集合,把所有不匹配任何选择器的文件放到里面。这是一个特殊的集合,专用来收集“遗留的”文件。不论是全量还得增量,构建工具都应该始终维护这些
N+1 个文件集合的正确性。headStream 是一个空的流,它没有任何 transformer 成员,它的作用仅仅是衔接其它流。于是,项目构建的实质就变成了
files 通过各自配对的headStream。如果你愿意对遗留文件也进行构建,那么也是可行的。
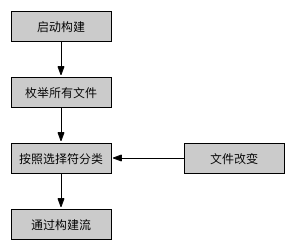
总结一下,本节讨论了一种选择遗留文件的方法。这项功能对于 Grunt 和 Gulp 都不具备,但却是工程实践中非常贴心的,如果你不必关心遗留文件,大可弃之不管,如果需要拷贝等操作,将非常地方便。
四、附加优化与问题
1.磁盘读取优化
显然,读取磁盘文件是构建中比较慢的一环,特别是全量搜索并都读取的话。在初次的构建中,对被选中文件的读取无可厚非,不过,要知道一个文件可以被多个选择器命中,这可能导致一个文件被多次读取。完全优化它其实很简单,向所有读取文件的流传递相同的
File 对象(直接从 MatchPair 的 files 中取出即可),只要 content 属性不为
null,则不必再次读取。当监听到该文件被修改后,清除 content,最先匹配这个文件的读取流就会再次读取磁盘,跟在它后面的则仍然不必再次读取,也保证了文件内容的实时性。
2.内存拷贝优化
从上面的设计可以看到,我们没有使用 NodeJS 的 Stream 对象来在各个 Transformer
之间传递数据(Gulp 是这样做的),不过使用的方式是非常类似的,因为毕竟缓存是以 content 为索引的,即使是流也需要等到全部接收完后才开始处理,这和直接传递全部内容没什么分别。我们在
Transformer 上设置的缓存,可能带来很多的文件拷贝,如果文件内容过大,则内存会被快速消耗。为了优化此问题,我们设置了一个阈值
f,文件体积超过 f ,缓存则由内存写入临时文件。当然,这是基于文件读写要比 transform 快的基础上的。
3.依赖关系的泄露
使用 addDependency() 来声明依赖是不收敛的,也就是说你可以在任意位置(主要是 Transformer
中)调用。我们没有提供一个 clearDependency() 方法是因为它的行为可能是片面的――不能预测其它位置是否有相反的行为。设想下面的路径:
第一次构建,声明 a.css 依赖于 a.png 和 b.png;
a.css 被修改,移除对 b.png 的依赖,第二次构建,声明 a.css 依赖于 a.png;
b.png 被修改,a.css 作为依赖方,第三次构建,声明 a.css 依赖于 a.png
可见,以后 b.png 的所有变化,都会触发 a.css 的重新构建,虽然 a.css已经不再依赖 b.png
了,我们称这是一种依赖关系泄露,就像内存泄露一样。事实上,它也确实造成了轻微的内存泄露。依赖关系泄露的后果就是,带来了不必要的重构建,如果条件合适的话,它可以像多米诺骨牌一样蔓延开来,造成重构风暴。
如果执意要规避这个问题的话,也不是不可能,但我们并没有采取任何手段,因为构建工具的运行周期都不会很长,没有太大必要为了它增加那么复杂的逻辑,何况它并不影响构建的正确性。
五、总结

以上就是我们为了解决当前和以后复杂的前端构建而进行的努力,同构 JavaScript 只是一个应用场景,理论上,我们可以很好地应对任何构建任务,包括
Webpack 的所有功能。与 Grunt、Gulp 类似的是,上面的设计和改进都是非常底层的,如果想真正应用于一个具体的项目架构,可能需要比较多的配置。从这一点上看,这更像是一个构建引擎。附图是该引擎的核心运行架构,我们利用它建设了多个
Web 前端项目,它们在架构上有着非常大的不同,特别是在初期设计时,架构十分不稳定,该引擎很好地支撑了各种差异化的构建任务。针对该引擎的不足和缺陷,我们仍在探索和改进。Grunt
、 Gulp 和 Webpack 依然是功能非常强大的工具,我们从它们身上借鉴了很多,也有许多不谋而合之处。每种工具都有其适合的场景,最重要的不是比较它们的优劣,而是找到最适合的那一个,如果必要,则可以进行适当的改进。 |






