| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫДњТыДѓЪ§ОнжњСІбаЗЂаЇФмЬсЩ§ЃЌДгЮЪЬтЗжЮіЁЂећЬхЩшЯыМАЪЕМљЬНЫїШ§ИіЗНУцРДеЙПЊЕФЁЃЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкЮЂаХЙЋжкКХDevOpsЪБДњ ЃЌгЩЛ№СњЙћШэМўLindaБрМЃЌЭЦМіЁЃ |
|
вЛЁЂЮЪЬтЗжЮі
ЕБЧАЮвУЧШэМўбаЗЂаЇФмЗНУцДцдквЛЯЕСаЕФеЯАЃЌЮвУЧШЯЮЊШэМўжЦЦЗМАПЊЗЂЙ§ГЬЕФВЛПЩМћадЪЧЕМжТетвЛЯЕСаеЯАЕФИљБОдвђЁЃ
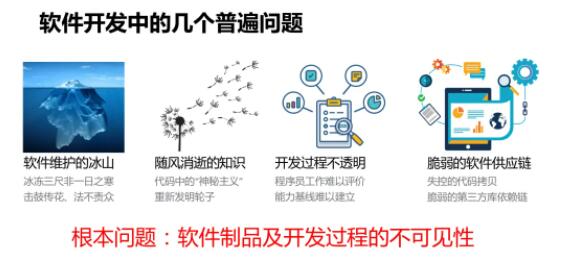
ЮвдкШЅФъ DevOps ЙњМЪЗхЛсБЈИцЕБжадјОзмНсСЫМИИіШэМўПЊЗЂжаЕФЦеБщЮЪЬтЃЌЪзЯШЪЧШэМўЮЌЛЄЕФБљЩНЃЌЮвУЧШэМўДњТыЕБжаДцдкКмЖржЪСПЮЪЬтЃЌетаЉЮЪЬтаЮГЩКмЖрЖМЪЧБљЖГШ§ГпЗЧвЛШежЎКЎЃЌЖјЧвЮвУЧГЬађдБдкГЄЦкШэМўПЊЗЂКЭЮЌЛЄЙ§ГЬжааЮГЩЛїЙФДЋЛЈЁЂЗЈВЛд№жкЕФаФЬЌЁЃ
ЦфДЮЪЧЫцЗчЯћЪХЕФжЊЪЖЁЃЮвУЧКмЖргагУЕФШэМўПЊЗЂжЊЪЖЁЂШэМўзЪВњвдМАгавтвхЕФЫМПМЙ§ГЬЖМУЛгаЕУЕНгааЇЕФМЧТМКЭРћгУЃЌдьГЩДњТыДцдкФГжжЩёУижївхЃЌКмЖрДњТыФбвдРэНтЃЌЮоЗЈзМШЗАбЮеДњТывтЭМЃЌЭЌЪБЦеБщДцдкжиаТЗЂУїТжзгЕФЮЪЬтЁЃ
ШЛКѓЪЧПЊЗЂЙ§ГЬВЛЭИУїЃЌКмФбШЅЖДВьвЛИіЭХЖгКЭПЊЗЂШЫдБЪЕМЪПЊЗЂЕФаЇФмЃЌГЬађдБЕФЙЄзїФбвдЦРМлЃЌФмСІЛљЯпФбвдНЈСЂЁЃ
зюКѓЪЧДрШѕЕФШэМўЙЉгІСДЃЌДѓСПДцдкДњТыПНБДвдМАЖдгкЕкШ§ЗНПтЕФвРРЕЃЌетбљгаКмЖрЗчЯеЁЃ
вдЩЯетМИЕуЖМдДздгквЛИіИљБОадЮЪЬтЃЌМДШэМўжЦЦЗвдМАШэМўПЊЗЂЙ§ГЬЕФИпЖШВЛПЩМћадЁЃ
етаЉЮЪЬтЖдгкШэМўбаЗЂаЇФмЬсЩ§дьГЩСЫжюЖреЯАЃЌЪЙЕУДњТыжаДцдкКмЖрЗчЯеЕуЁЃетаЉЗчЯеЕувЊУДФбвдБЛЮвУЧМАЪБЗЂЯжКЭЖДВьЃЌвЊУДгавЛаЉЙЄОпПЩвдИјЮвУЧвЛаЉМьВтНсЙћКЭЗДРЁЃЌЕЋЪЧДцдкЮѓБЈТЪЙ§ИпвдМАЦфЫћЮЪЬтЃЌЪЙЕУЦфНсЙћКмФбБЛЮвУЧРћгУЁЃ
ШэМўжЊЪЖФбвдЛ§РлЁЃИїжжШэМўЯюФПжаАќКЌКмЖрЭЈгУДњТызЪВњЃЌЕЋЪЧКмФбБЛЪЖБ№КЭгааЇРћгУЁЃЛЙгаКмЖрШэМўПЊЗЂЮЪЬтзмЪЧЗДИДГіЯжЃЌЕЋЪЧЦфНтОіЗНАИКмФбНјааВЖзНКЭЛ§РлЁЃЮФЕЕКЭЦфЫћДњТыжЊЪЖФбвдБЛгааЇРћгУЁЃ
гХауЪЕМљФбвдШЗСЂЁЃГЬађдБЛљгкШШЧщКЭд№ШЮаФЛсПЊеЙвЛаЉКмКУЕФПЊЗЂЪЕМљЃЌР§ШчОЋаФЪщаДДњТыКЭЬсНЛзЂЪЭЃЌЕЋЪЧетаЉКУЕФПЊЗЂааЮЊФбвдБЛЗЂЯжКЭШЯПЩЁЃЯюФПКЭШЫдБЕФПЊЗЂФмСІЛљЯпФбвдНЈСЂЃЌКмФбЭЈЙ§ЖдПЊЗЂЪБМфвдМАДњТыжЪСПЕФКтСПЖдКЯРэЕФФмСІЛљЯпНјааЙРМЦЁЃ

ЫЕЕНбаЗЂаЇФмЃЌДѓМвКмздШЛОЭЛсЯыЕНЖШСПЁЃе§ШчКмЖрШЫЫљаХЗюЕФЁАШчЙћФуВЛФмЖШСПЫќЃЌФуОЭЮоЗЈИФНјЫќЁБЁЃШЛЖјЃЌдкЯжЪЕжаКмЖрЦѓвЕЫљПЊеЙЕФШэМўПЊЗЂЖШСПКмШнвзЯнШывЛжжРЇОГЃЌЪЙЕУЖШСПжИБъГЩЮЊвЛжжНЬЬѕжївхЁЃЖШСПжИБъЕФЭЦааепЭљЭљЭќМЧСЫЖШСПЕФГѕаФЪЧЪВУДЃЌЛсКіТдШэМўПЊЗЂЩЯЯТЮФВювьЕФгАЯьЃЌКіТдСЫЖШСПжИБъдкВЛЭЌФЃПщжаЕФКЌвхгаЫљВювьЁЃетбљвдвЛЕЖЧаЕФЗНЪНШЅЭЦааЖШСПВЂИНМгвЛаЉЧПжЦЪжЖЮОЭЛсГіЯжКмЖрЮЪЬтЁЃ
ПЊЗЂШЫдБДѓЖрЖМЪЧКмДЯУїЕФЃЌОГЃЛсЧїРћБмКІЃЌЫљвдОГЃЬ§ЕНетбљЕФЫЕЗЈЃКЁАФуКтСПЪВУДОЭЕУЕНЪВУДЁБвдМАЁАвЛзЅОЭЫРЃЌвЛЗХОЭТвЁБЁЃБШШчгаЕФЦѓвЕгУДњТыжиИДТЪзїЮЊжИБъШЅвЊЧѓПЊЗЂШЫдБНЕЕЭДњТыжиИДТЪЃЌгЩДЫдьГЩЕФНсЙћЪЧКмЖрПЊЗЂШЫдБЙЪвтАбздМКЕФКЏЪ§ЛђепЗНЗЈвЛЗжЮЊЖўЃЌЩѕжСЗжНтГіРДЕФЗНЗЈКЭКЏЪ§УќУћЖМДјгаЪ§зжЃЌетжжЛњаЕКЭЮяРэЪНЕФДњТыВ№ЗжДПДтОЭЪЧЮЊСЫНЕЕЭСЌајДњТыЕФжиИДТЪЁЃетбљЕУЕНЕФНсЙћЗДЖјЪЙДњТыПЩЮЌЛЄадЁЂПЩЖСадБфЕУИќВюСЫЃЌетИіВЛЪЧЮвУЧЯыПДЕНЕФНсЙћЁЃ
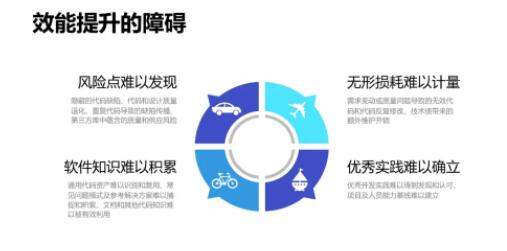
ЖўЁЂећЬхЩшЯы
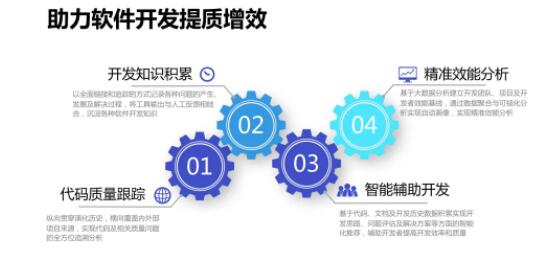
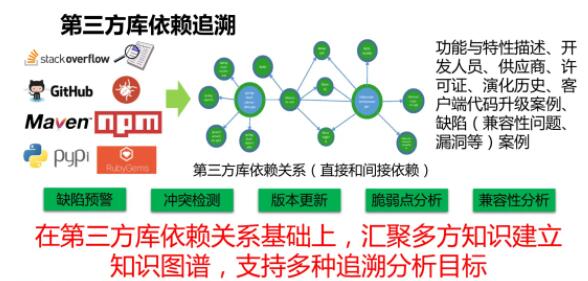
еыЖдвдЩЯетаЉЮЪЬтЃЌЮвУЧЬсГіЕФЫМТЗЪЧНЈСЂвЛжжШэМўПЊЗЂЕФжЪСПзЗЫнЬхЯЕЃЌвдДњТыДѓЪ§ОнЗжЮіжњСІбаЗЂаЇФмЕФЬсЩ§ЁЃ

етвЛЫМЯыЪмЕНСЫжЦдьвЕЁЂЪГЦЗвЕЕШСьгђГЩЙІОбщЕФЦєЗЂЁЃетаЉаавЕжавбОЙуЗКНЈСЂСЫВњЦЗжЪСПзЗЫнЬхЯЕЃЌПЩвдЪЕЯжРДдДПЩЫмЁЂШЅЯђПЩВщЁЂд№ШЮПЩзЗЁЂжЪСППЩПиЕФжЪСПЙмРэФПБъЁЃ
ВЮееетжжЫМЯыНЈСЂШэМўПЊЗЂжЪСПзЗЫнЬхЯЕЪЧКмФбЕФЃЌвђЮЊШэМўжЦЦЗМАШэМўПЊЗЂЙ§ГЬЪЧИпЖШВЛПЩМћЕФЃЌЖјЧвзщГЩШэМўЕФГЩЗжКмЖрЖМФбвдБцЪЖЃЌВЂЧвБпНчЗЧГЃВЛЧхГўЁЃ
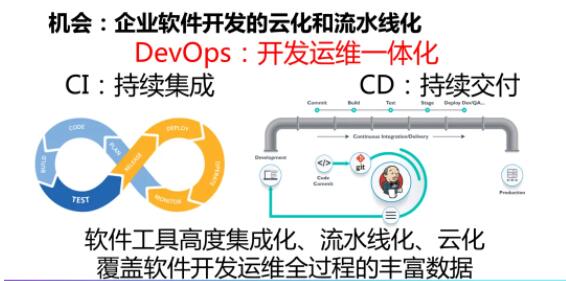
етаЉФъвдРДЃЌDevOps КЭдЦЛЏПЊЗЂЦНЬЈгаСЫГЄзуЗЂеЙЃЌВЂЧвЕУЕНЙуЗКЕФгІгУЁЃЛљгкдЦЕФDevOps ПЊЗЂЦНЬЈжаШэМўЙЄОпИпЖШМЏГЩЛЏЁЂСїЫЎЯпЛЏКЭдЦЛЏЃЌЪЙЕУЮвУЧПЩвдЕУЕНЗДгГПЊЗЂдЫЮЌШЋЙ§ГЬжаЕФЗсИЛЪ§ОнЃЌЪЙЕУЙЙдьЛљгкДњТыДѓЪ§ОнЕФШэМўПЊЗЂжЪСПзЗзйЬхЯЕГЩЮЊПЩФмЁЃ

ЮвУЧЫљЫЕЕФДњТыДѓЪ§ОнЦфЪЕИВИЧСЫвдДњТыЮЊжааФЕФШэМўПЊЗЂбнЛЏЙ§ГЬЕБжаЕФИїжжШэМўжЦЦЗКЭЙ§ГЬЪ§ОнЁЃ
ЪзЯШЃЌЮвУЧПЩвдЖдДњТыПьееПЩвдНјааДњТыГЩЗжМьВтЃЌАќРЈзщГЩДњТыЕФЮФМўЁЂРрЁЂЗНЗЈЕШДњТыЕЅдЊвдМАЯрЙиЕФДњТыЖШСПЁЂЭЈЙ§ОВЬЌЩЈУшЗЂЯжЕФДњТыШБЯнЕШЁЃЦфДЮЃЌвдДњТыЬсНЛ
Commit ЮЊзЅЪжЃЌПЩвдЖдДњТыбнЛЏЙ§ГЬНјааСЌајЕФзЗзйЁЃ
еыЖдУПИі COMMIT ПЩвдЗжЮіЖдгІЕФПЊЗЂепЪЧЫЃЌЖдгІЕФПЊЗЂШЮЮёЃЈР§ШчЫЕЮЪЬтЕЅЃЉЪЧФФИіЃЌвдМА COMMIT
жаЕФДњТыаоИФФкШнЃЌетИіПЩвдЭЈЙ§ДњТыВювьБШНЯРДЪЖБ№ЁЃНјвЛВНПЩвдАбВЛЭЌАцБОжаЕФДњТыЕЅдЊгыЦфЫќЮЪЬтЃЈШчОВЬЌЩЈУшЙЄОпЗЂЯжЕФОВЬЌШБЯнЃЉНјаазЗзйЃЌЭЈЙ§бнЛЏзЗЫнШЅСЫНтЯрЙиЮЪЬтзюдчдкФФИіПьееЕБжав§ШывдМАКѓајећИіЗЂеЙЙ§ГЬЪЧдѕУДбљЕФЁЃ
ЛЙгаЧАУцЬсЕНЙ§ЕФДњТыжаЫљДцдкЕФЭтВПРДдДЃЌПЩвдЭЈЙ§ИпаЇЕФПЫТЁМьВтРДЗЂЯжЫљв§гУЕФЭтВПДњТыЃЌЭЈЙ§вРРЕЗжЮіЗЂЯжЕкШ§ЗНПтвРРЕвдМАБГКѓЫљвўВиЕФМфНгЕїгУСДЃЌдкДЫЛљДЁЩЯПЩвдаЮГЩШэМўЙЉгІСДЕФзЗзйЗжЮіЁЃЛЙгаВњЦЗЙЙНЈКЭЗЂВМЃЌПЩвдЭЈЙ§ЙЙНЈШежОЗжЮіЖдгкЙЙНЈЕФЙ§ГЬвдМАЙЙНЈЙ§ГЬЕБжаЪЙгУЕФДњТыдЊЫиАцБОЁЂЙЄОпЛЗОГЕШНјаавЛИізЗзйКЭМЧТМЁЃ
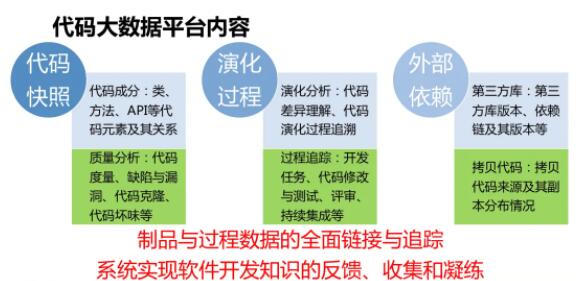
ЭЈЙ§етжжЗНЪНЙЙНЈЕФДњТыДѓЪ§ОнЦНЬЈАќКЌШ§ИіЗНУцФкШнЁЃ
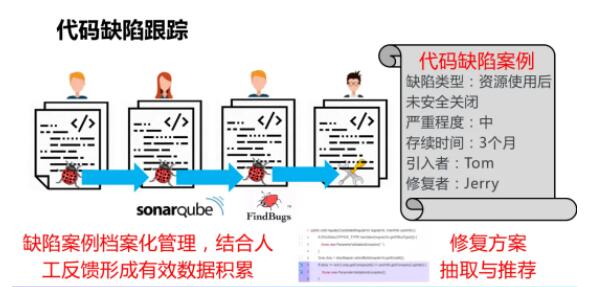
ЪзЯШЪЧДњТыПьееЃЌЦфжаАќКЌДњТыЕФГЩЗжаХЯЂЃЈАќРЈРрЁЂЗНЗЈЁЂAPI ДњТыдЊЫивдМАЫќУЧжЎМфЙиЯЕЃЉЃЌЛЙгаИїжжжЪСПЗжЮіЁЂДњТыЖШСПЁЂШБЯнТЉЖДЁЂДњТыПЫТЁЁЂДњТыЛЕЮЖаХЯЂЕШЁЃ
ЕкЖўЪЧбнЛЏЙ§ГЬЃЌЭЈЙ§бнЛЏЙ§ГЬПЩвдСЫНтДњТыВювьРэНтЃЌЛЙгаДњТыбнЛЏзЗЫнЃЌдкетИіЛљДЁЭЈЙ§Й§ГЬзЗзйАбДњТыаоИФгыЖдгІЕФПЊЗЂШЮЮёвдМАКѓајЕФДњТыВтЪдЁЂЦРЩѓЁЂГжајМЏГЩЛюЖЏЕШНјаазЗзйЙиЯЕЁЃ
ЕкШ§ВПЗжЪЧЭтВПвРРЕЃЌАќРЈЕкШ§ЗНПтвРРЕЃЌЛЙгажиИДДњТывдМАДњТыЕФРДдДвдМАжиИДДњТыИББОЕФЗжВМЧщПіЁЃ
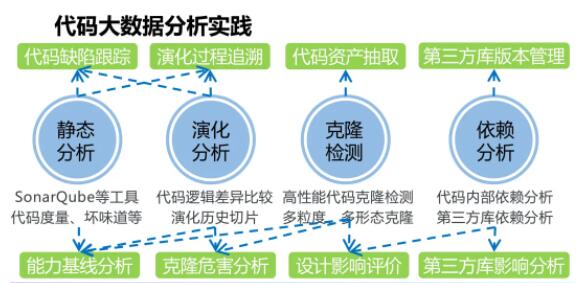
змЕФРДЫЕДњТыДѓЪ§ОнЦНЬЈЪЧНЈСЂдкШэМўПЊЗЂжЦЦЗКЭЙ§ГЬЪ§ОнШЋУцСДНгКЭзЗзйЛљДЁжЎЩЯЕФЃЌЭЈЙ§ДњТыДѓЪ§ОнЦНЬЈФмЙЛЯЕЭГадЕиЪЕЯжШэМўПЊЗЂЙ§ГЬЕФЗДРЁЪ§ОнЫбМЏКЭРћгУЁЃ
ЭЈЙ§ДњТыДѓЪ§ОнЦНЬЈЃЌЮвУЧЯЃЭћФмЙЛЯЕЭГадЪЕЯжДњТыжЪСПзЗзйКЭПЊЗЂжЊЪЖЛ§РлЁЃдкДњТыжЪСПзЗзйЗНУцЯЃЭћЭЈЙ§знЯђЙсДЉбнЛЏРњЪЗЃЌКсЯђИВИЧЭтВПЯюФПРДдДЕФЗНЪНРДЪЕЯжДњТывдМАЯрЙиЕФжЪСПЮЪЬтШЋЗНЮЛзЗЫнЗжЮіЁЃдкПЊЗЂжЊЪЖЛ§РлЗНУцЃЌЯЃЭћвдШЋУцСДНгКЭзЗзйЕФЗНЪНРДМЧТМИїРрЮЪЬтЕФВњЩњЁЂЗЂеЙКЭНтОіЙ§ГЬЃЌНЋЙЄОпЕФЪфГігыШЫЙЄЕФЗДРЁЯрНсКЯЃЌГСЕэИїжжШэМўПЊЗЂжЊЪЖЁЃЛљгкДњТыжЪСПзЗзйКЭПЊЗЂжЊЪЖЛ§РлЃЌЮвУЧЯЃЭћФмЙЛУцЯђПЊЗЂШЫдБвдМАжЪСПБЃеЯКЭЙмРэШЫдБЬсЙЉОЋзМаЇФмЗжЮіЃЌДгЖјРДжњСІШэМўПЊЗЂЕФЬсжЪдіаЇЁЃ
Ш§ЁЂЪЕМљЬНЫї
ДњТыДѓЪ§ОнЗжЮіЪЕМљвдвЛЯЕСаДњТыЗжЮіММЪѕЮЊЛљДЁЃЌАќРЈвдЯТМИИіЗНУцЁЃ
ОВЬЌЗжЮіЃЌР§ШчДњТыОВЬЌШБЯнЩЈУшЁЂДњТыЖШСПКЭЛЕЮЖЕРЗжЮіЕШЃЌетЗНУцПЩвдМЏГЩЯжгаЕФSonarQubeЕШЕкШ§ЗНЗжЮіЙЄОпЕФЪфГіНсЙћЁЃ
бнЛЏЗжЮіММЪѕЃЌАќРЈДњТыЕФТпМВювьБШНЯЃЌвтЮЖзХЖдгкУПвЛИіCommitПЩвдЗжЮіДњТыТпМВювьЃЌЖјВЛЪЧЮяРэДњТыааЕФВювьЁЃТпМВювьАќРЈБШШчЫЕЪЧВЛЪЧаТдіСЫвЛИіЗНЗЈЃЌЪЧВЛЪЧаоИФСЫЗНЗЈЕФВЮЪ§ЃЌЪЧВЛЪЧаТдіСЫAPIЕїгУЕШЁЃДЫЭтЛЙПЩвдЭЈЙ§бнЛЏРњЪЗЧаЦЌММЪѕАбЫљЙиаФЕФДњТыЕЅдЊЛђепЪЧДњТыЮЪЬтЯрЙиЕФЗЂеЙБфЛЏРњЪЗЧаШЁГіРДНјааеыЖдадЕФЗжЮіЁЃ
ПЫТЁМьВтЃЌетЗНУцЮвУЧздМКбаЗЂСЫвЛжжИпадФмЕФДњТыПЫТЁМьВтММЪѕЃЌПЩвджЇГжЖрСЃЖШЁЂЖраЮЬЌЕФДњТыПЫТЁЗжЮіЁЃ
вРРЕЗжЮіЃЌАќРЈФкВПКЭЭтВПДњТывРРЕЗжЮіЃЌР§ШчФкВПВЛЭЌЕФФЃПщЛђепЪЧВЛЭЌЕФЮФМўжЎМфЕФвРРЕвдМАЕкШ§ЗНПтвРРЕЗжЮіЁЃ
дквдЩЯетаЉЗжЮіФмСІЛљДЁЩЯПЩвдПЊеЙЗсИЛЖрВЪЕФДњТыДѓЪ§ОнЗжЮігІгУЃЌетРяЭЈЙ§МИИіЕфаЭЗжЮіЗНЪННјааОйР§ЫЕУїЁЃ
ЪзЯШПДДњТыШБЯнИњзйЃЌЪЧжИЭЈЙ§ИїжжОВЬЌЩЈУшЙЄОпФмЙЛМьВтЗЂЯжЧБдкДњТыжЪСПЮЪЬтЃЌАќРЈДњТыЕФЛЕЮЖЕРвдМАЧБдкЕФТЉЖДКЭЙІФмадЕФШБЯнЕШЕШЁЃеыЖдДњТыЕФАцБОПьееЃЌЮвУЧПЩвдЪЙгУ
SonarQube ЛђепЪЧ FindBugs етбљЕФОВЬЌЗжЮіЙЄОпРДЗЂЯжЧБдкЕФДњТыШБЯнЁЃШчЙћУЛгаДѓЪ§ОнЗжЮіФмСІЃЌНіНіФУЕНетаЉЙЄОпЕФЗжЮіНсЙћКмФбгааЇРћгУЃЌЙЄОпМьВтНсЙћКмФбГЩЮЊШэМўПЊЗЂЕФЪ§ОнЛ§РлЁЃ

ЪЙгУДњТыДѓЪ§ОнЗжЮіЖдгкЕБЧАЮФМўРњЪЗАцБОГжајПЊеЙМьВтКЭМрПиЃЌВЂЧвЭЈЙ§ЮвУЧЕФбнЛЏзЗЫнММЪѕАбУПИіАцБОЩЈУшЕНЕФЮЪЬтНЈСЂзЗзйЙиЯЕЃЌДгЖјШУЮвУЧжЊЕРАцБОПьееЫљЩЈУшДњТыШБЯнЦфЪЕвбОВЛЪЧаТЮЪЬтЃЌЖјЪЧвбОДцдквЛЖЈЪБМфЕФРЯЮЪЬтЁЃЭЌЪББЃГжзЗзйЙ§ГЬПЩФмЗЂЯжЕНФГвЛИіАцБООЙ§вЛДЮДњТыЬсНЛжЎКѓЮЪЬтвбОВЛИДДцдкСЫЃЌетЫЕУїЖдгІЕФГЬађдБПЩФмвбОАбетИіЮЪЬтаоЕєСЫЁЃ
ЭЈЙ§етжжДњТыШБЯнзЗЫнЙ§ГЬЃЌПЩвдеыЖдЕБЧАДњТыШБЯнНЈСЂвЛИіАИР§МЧТМЃЌОЭЯёЙЋАВВПУХеыЖдвЛИіАИзгПЊСЫвЛИіЕЕАИвЛбљЃЌФЧУДетИіАИР§ВЛЪЧеыЖдФГвЛИіАцБОПьееЩЯЕФЮЪЬтЃЌЖјЪЧеыЖддкСЌајЕФДњТыбнЛЏЙ§ГЬжаЃЌдкЭЌбљДњТыЕФЮЛжУЩЯДњТыШБЯнЕФСЌајАИР§ЕФМЧТМЁЃ
БШШчЫЕеыЖдДњТыЕФШБЯнАИР§ПЩвдМЧТМШБЯнЕФРраЭЁЂФкШнЁЂбЯжиГЬЖШЁЂДцајЕФЪБМфЃЌШБЯнДгЪзДЮв§ШыЕНзюКѓвЦГ§ЕФМфИєЪБМфЃЌвдМАЫв§ШыЁЂЫаоИДЕФЁЃ
етжжЕЕАИЛЏЕФЙмРэЛЙПЩвдНсКЯШЫЙЄЗДРЁаЮГЩгааЇЕФЪ§ОнЛ§РлЁЃШЫЙЄЗДРЁЪЧжИГЬађдБдкФГаЉЪБКђЭЈЙ§ДњТыЪ§ОнЦНЬЈШЅВщПДЕБЧАДњТыШБЯнИјГіЦРТлКЭЗДРЁЃЌБШШчЫЕЪЧВЛЪЧЮѓБЈЃЌЮЪЬтбЯжиГЬЖШШчКЮЕШЁЃетжжШЫЙЄЗДРЁПЩвдГЩЮЊДњТыДѓЪ§ОнЕФвЛВПЗжЁЃдкДЫЛљДЁЩЯПЩвдЭЈЙ§ДњТыВювьБШНЯЗЂЯжаоИДЭЌРрШБЯнЕФДњТыаоИФФЃЪНЃЌетбљГщШЁШБЯнаоИДЗНАИжЎКѓОЭПЩвдаЮГЩгааЇЕФжЊЪЖЛ§РлЃЌдкгаашвЊЕФЪБКђНЋШБЯнаоИДЗНАИЭЦМіИјЦфЫћПЊЗЂШЫдБЪЙгУЁЃ
ЮвУЧЕФбаЗЂЙ§ГЬзЗзйЗжЮіФмСІПЩвдЖдгкДњТыЮЪЬтНјаагааЇзЗЫнЗжЮіЮЪЬтЃЌБШШчеыЖдДњТыжаДцдкЕФЛЕЮЖЕРвдМАЙ§ИпЕФИДдгЖШЕШЮЪЬтЃЌПЩвдШЅзЗЫнВЂЗжЮіЦфГЩвђМАЯрЙиЕФШЫдБЁЃР§ШчЃЌЕБЧАетИіЗНЗЈЕФШІИДдгЖШЗЧГЃЁЃЭЈЙ§бнЛЏЙ§ГЬЕФзЗзйЃЌПЩвдНЋЖдгкЕБЧАЗНЗЈЕФШІИДдгЖШгАЯьБШНЯДѓЕФМИДЮДњТыаоИФИјбЁШЁГіРДЃЌетИіПЩЭЈЙ§бнЛЏЧаЦЌММЪѕРДЪЕЯжЁЃПЩвдПДЕНЃЌгаШ§ДЮДњТыаоИФЖдгкЕБЧАЕФЗНЗЈЕФШІИДдгЖШгаБШНЯДѓЕФгАЯьЃЌЕквЛДЮЪЧгаЫљЯТНЕЃЌДг9ЕН5ЃЌЕкЖўДЮгаБШНЯДѓЬсЩ§ЃЌЕНзюКѓЪЧБфГЩ23ЁЃ
дкДЫЛљДЁЩЯПЩвдВщПДШ§ДЮЕФОпЬхДњТыаоИФЁЃЕквЛДЮзіСЫРрЫЦгкжиЙЙЕФВйзїЃЌАбвЛаЉДІРэТпМНјааСЫГщШЁЃЌЫљвдЪЙЕУШІИДдгЖШгаЫљЯТНЕЁЃЖјКѓУцСНДЮЖМЪЧНјааЦфЫћЕФаоИФВйзїЃЌдьГЩШІИДдгЖШЕФЩЯЩ§ЃЌУПДЮаоИФЖдгІЕФЪБМфвдМАПЊЗЂепЖМПЩвдЭЈЙ§ЗжЮіРДжЊЕРЁЃ
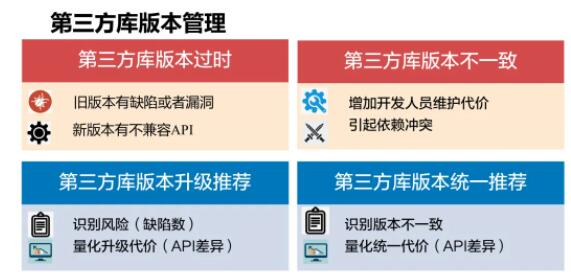
ДњТыПЫТЁЮЃКІЗжЮіЁЃДњТыПЫТЁвВОЭЪЧжиИДДњТыЃЌЦеБщДцдкгкПЊдДКЭЦѓвЕЯюФПЕБжаЃЌгавЛаЉЯюФППДЕНДњТыжиИДТЪИуЕН30%ЕН50%ЩѕжСИќИпЃЌетУДЖрДњТыПЫТЁЭъШЋЯћГ§ЪЧМИКѕВЛПЩФмЁЃФЧУДШчКЮЦРЙРДњТыПЫТЁЕФЮЃКІЖШЃЌетМўЪТЧщгІИУзЗИљЫндДЁЃ
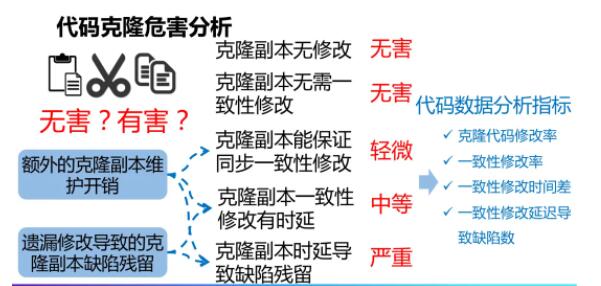
ПМТЧвЛЯТЮвУЧЮЊЪВУДОГЃЫЕДњТыПЫТЁЪЧгаКІЁЃЪзЯШЪЧвђЮЊЖюЭтПЫТЁИББОЮЌЛЄПЊЯњЃЌгаКмЖржиИДИББОЃЌШчЙћашвЊЖдетаЉИББОНјаавЛжТадЕФаоИФЃЌУПДЮаоИФвЊаоИФКмЖрДЮВЛЭЌЕФЕиЗНЃЌФЧУДОЭЛсДјРДЖюЭтЕФЮЌЛЄПЊЯњЁЃЦфДЮЃЌвХТЉФГаЉПЫТЁИББОЕФаоИФПЩФмЕМжТЦфжаЮЪЬтЕФВаСєЃЌДгЖјЕМжТжЪСПЮЪЬтЁЃДЫЭтЃЌДњТыПЫТЁЛЙЛсЖдЩшМЦдьГЩгАЯьЁЃ
ЛљгкДњТыДѓЪ§ОнЗжЮіЕФДњТыПЫТЁЮЃКІЦРМлЗжЮЊвдЯТМИИіРрБ№ЃЌЪзЯШЪЧДњТыПЫТЁИББОЮоашаоИФЃЌв§ШыжЎКѓЖрИіИББОвЛжББЃГжВЛБфЁЃЕкЖўжжЧщПіЪЧПЫТЁИББОашвЊНјаааоИФЃЌЕЋЪЧВЛашвЊБЃГжвЛжТЃЌОЭЪЧЫЕПЫТЁИББОгааоИФЕЋЪЧДѓМвИїздаоИФВЛашвЊБЃГжвЛжТЁЃ
ЕкШ§жжЧщПіЪЧПЫТЁИББОБЃГжвЛжТадаоИФЃЌЕЋЪЧБШНЯКУБЃГжЭЌВНЃЌПЩвддкЕквЛЪБМфЭъГЩЫљгаПЫТЁИББОЕФаоИФЁЃ
ЕкЫФжжЧщПіЪЧПЫТЁИББОашвЊНјаавЛжТадаоИФЃЌЖјЧвВЛЭЌПЫТЁИББОжЎМфЕФвЛжТадаоИФДцдкЪБбгЁЃ
зюКѓвЛжжЧщПіЪЧПЫТЁИББОДцдквЛжТадаоИФЪБбгЃЌВЂЧветжжвЛжТадаоИФЕФЭЯбгЕМжТСЫШБЯнЕФВаСєЁЃ
ПЩвдПДЕНИеВХНВЕНетСНжжПЫТЁЕФЮЃКІЧщаЮжївЊЖдгІКѓУцШ§жжЧщПіЁЃЛљгкЮвУЧЖдгкДњТыПЫТЁЮЃКІЕФНтЖСЃЌПЩвдЗЂЯжетРя5жжЧщПіЕФПЫТЁЮЃКІЖШИїВЛЯрЭЌЁЃ
ЕквЛжжКЭЕкЖўжжЪЧЮоКІЕФЃЌПЫТЁИББОв§ШыВЂУЛгаЮЊЮвУЧДјРДЖюЭтЕФЮЌЛЄПЊЯњвВУЛгаДјРДШБЯнЕФВаСєЁЃЕкШ§жжгаЧсЮЂЮЃКІЃЌвђЮЊЪЙЙЄзїСПгаЫљЩЯЩ§ЃЌЕЋЪЧДгРњЪЗЪ§ОнЗжЮіРДПДЛЙЪЧФмЙЛКмКУШЅНтОівЛжТадаоИФЕФЮЪЬтЁЃ
ЕкЫФжжЧщПігажаЕШЕФЗчЯеЃЌетИіЪБКђПЫТЁИББОвЛЖЈаоИФгаЫљбгГйЕФЃЌЪЙЕУЮвУЧЖдгкЮДРДШБЯнЕФГіЯжПЩФмЛсгавЛЖЈЕФЗчЯеЃЌЫљвдЪЧжаЕШЕФЮЃКІЁЃзюКѓвЛжжЪЧбЯжиЗчЯеЃЌвђЮЊРњЪЗЩЯвђЮЊгаДњТыПЫТЁИББОЕФбгГйаоИФЖјЕМжТШБЯнЕФВаСєЁЃ
ЛљгкетМИИіЗжМЖПЩвдЖЈвхвЛЬзДњТыЪ§ОнЗжЮіжИБъРДАяжњЮвУЧШЅЗжЮіДњТыПЫТЁЕФЮЃКІЃЌБШШчЫЕПЩвдаЮГЩвдЯТвЛЯЕСаЕФЗжЮіжИБъЃЌАќРЈПЫТЁДњТыаоИФТЪЁЂвЛжТадаоИФТЪЁЂвЛжТадаоИФЪБМфВюЁЂЛЙгавЛжТадаоИФбгГйЕМжТШБЯнЪ§ЕШЁЃЛљгкетбљДњТыДѓЪ§ОнЗжЮіЮЊДњТыПЫТЁЕФЮЃКІИјГіЯрЖдЖЈСПЕФЦРМлЁЃ
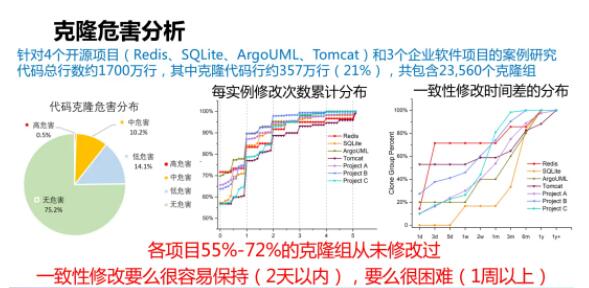
ЛљгквдЩЯЫљНщЩмЕФЛљгкДњТыДѓЪ§ОнЕФДњТыПЫТЁЮЃКІЗжЮіЗНЗЈЃЌЮвУЧеыЖд4ИіПЊдДЕФЯюФПКЭ3ИіЦѓвЕШэМўЯюФППЊеЙСЫАИР§баОПЁЃЫљЩцМАЕФДњТызмааЪ§дМ
1700 ЭђааЃЌЦфжаПЫТЁДњТыдМ 357 ЭђааЃЌЙВАќКЌ 23,560 ИіПЫТЁзщЁЃПЩвдПДЕНетаЉДњТыПЫТЁжаЃЌГЌЙ§
75% ЕФЖМУЛгаЮЃКІЃЌЖјДцдкЕЭЁЂжаЁЂИпЮЃКІЕФДњТыПЫТЁЗжБ№еМ 14.1%ЁЂ10.2%ЁЂ0.5%ЁЃ
дкЗжЮіАИР§ЕБжаЪЕМЪЗЂЯжСЫгыДњТыПЫТЁЯрЙиЕФДњТыШБЯнЁЃдк SQLITE жа FTS3ICUC КЭFTS2ICUC
СНИіЮФМўжаДцдкЯрЫЦЕФКЏЪ§ ICUOPENЁЃ2008Фъ9дТ2ШеЯюФПдіМгСЫвЛИіЙІФмЃЌЦфжа FTS3ICUC
ЮФМўжаЕФ ICUOPEN КЏЪ§НјааЩЯЪіаоИФЃЌ2008Фъ12дТНјааСЫ FTS2ICUC ЮФМўжаЭЌУћКЏЪ§вВНјааСЫЭЌбљЕФаоИФЃЌФПБъЪЧаоИДЭЌбљЮЪЬтЁЃетРяЕФвЛжТадаоИФбгГйЪЕМЪЕМжТСЫДњТыШБЯнВаСєЁЃвђДЫЃЌашвЊЖдДњТыПЫТЁВњЩњКЭбнЛЏЙ§ГЬБЃГжГжајЙмРэКЭМрПиЁЃ

ДњТыПЫТЁвВдЬКЌвЛаЉЭЈгУЕФДњТызЪВњЃЌЫљвдЮвУЧвВНјааСЫвЛаЉЛљгкДњТыПЫТЁЕФДњТызЪВњГщШЁЪЕМљЬНЫїЁЃЭЈЙ§баОПЮвУЧЗЂЯждкПчЯюФПЕФДњТыПЫТЁРяУцДцдквдЯТМИжжГЃМћЙЋЙВДњТызЪВњЕФРраЭЃЌАќРЈВтЪдДњТыЃЈКмЖрВтЪдДњТыЙ§ГЬЪЧЯрЫЦЃЉЃЌЛЙгаЭЈгУММЪѕЙІФмЃЌБШШчЫЕJSONДІРэЯрЙиЕФЭЈгУДњТыЕШЕШЁЃ
етРяЮвУЧПЩвдПДЕНвЛаЉР§згЃЌАќРЈдкВЛЭЌЯюФПжаЗЂЯжЕФFTPЮФМўДЋЪфВЛЭЌЕФЪЕЯжДњТыИББОЃЌЛЙгаЙигк BASE64
МгУмжиИДИББОЕШЁЃЭЈЙ§жиИДДњТыПЫТЁДњТыЕФЗжЮіЃЌЮвУЧПЩвдМАЪБЗЂЯжжиИДЕФДњТыЃЌВЂЧвМАЪБНјааЙЋЙВДњТызЪВњЕФГщШЁЁЃ
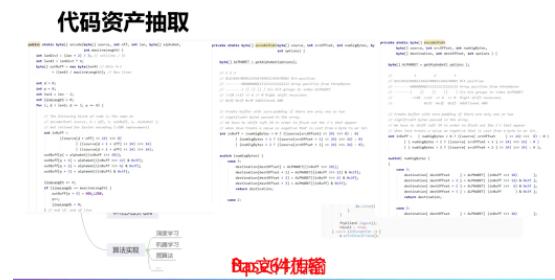
ЮвУЧЛЙПЩвдАбДњТыПЫТЁЕФЗжЮігыДњТывРРЕЗжЮіЯрНсКЯЃЌЖдгкећИіЩшМЦжЪСПНјааЦРМлЃЌЭЈЙ§ПчЯюФПЁЂПчФЃПщПЫТЁМьВтЪЖБ№ЭЈЙ§ЙІФмЪЕЯжЃЌШЛКѓЗжЮіЦфжадкИїздДњТывРРЕНсЙЙжаЕФЮЛжУЁЃ
ЮвУЧПЩвдПДДђдкЕБЧАетСНИіЯюФПЕБжаЃЌЮвУЧПЩвдЗЂЯжгавЛаЉЭЈгУЕФЙІФмЪЕЯжЃЌР§ШчЪ§ОнПтВйзїЮФМўВйзїБЈБэЕФВйзїЭјТчДђгЁЕШЕШЃЌетаЉЪЧЭЈгУЙІФмЪЕЯжЃЌЭЈЙ§ДњТыПЫТЁЕФМьВтРДЗЂЯжЫћУЧдкВЛЭЌЕФЯюФПРяУцЪЕЯжЕФИББОЁЃ
СэЭтЮвУЧБОЩэЖдетСНИіЯюФПИїздДњТывРРЕНсЙЙЃЌМ§ЭЗДњБэЫћУЧЕФвРРЕЕїгУЕФЙиЯЕЃЌетбљаЮГЩСЫвРРЕЕФВуДЮНсЙЙЃЌдкетИіВуДЮНсЙЙПЩвдАбжиИДДњТыЕЅдЊПЩвдАбЮЛжУБъзЂЩЯЃЌЭЈЙ§етбљЕўМгЗжЮіПЩвдЗЂЯжЩшМЦЩЯЕФЮЪЬтЁЃ
ЕквЛИіЯюФПЖдгкЭЈгУЙІФмНјааЭГвЛЗжзАЃЌБмУтжиИДЪЕЯжЃЌВЂЧвЭЈгУЕФЙІФмдквРРЕНсЙЙЩЯУцЪЧвЛИіБШНЯКЯЪЪЕФВуМЖЃЌЮЛгкЕзВуЃЌЗтзАСЫЭЈгУЕФЙІФмЪЙЕУЩЯУцЕФЙЋгУЕїгУЫќЃЌРрЫЦЪЕЯжЩЂВНЕФИїДІЃЌЫљДІЕФвдРДНсЙЙВуМЖвВВЛКЯЪЪЁЃ
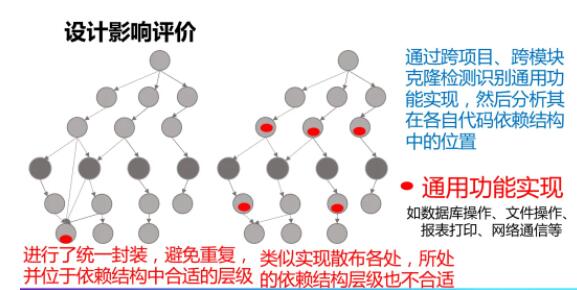
ЮвУЧЧАУцвВЬсЕНЙ§ШэМўЫљжБНгЛђепМфНгвРРЕЕкШ§ЗНПтдЬКЌКмЖржЪСПКЭЦфЫћЗНУцЕФЗчЯеЁЃетЦфжажївЊАќКЌСНИіЮЪЬтЃК
ЕкШ§ЗНПтАцБОЙ§ЪБЃЌПЩФмгаШБЯнКЭТЉЖДЃЌЕЋЪЧПМТЧаТАцБОВЛМцШнAPIЃЌПЩФмВЛЯыШЅЩ§МЖЛђепВЛжЊЕРвЊЩ§МЖЃЌвђЮЊашвЊИЖГіЩ§МЖЕФДњМлЁЃДгЕБЧАЕкШ§ЗНПтАцБОЩ§МЖИќИпАцБОПЩФмДцдкAPIВювьЃЌвтЮЖзХЩ§МЖЛсИЖГівЛЖЈЕФДњМлЁЃ
ЕкШ§ЗНПтАцБОВЛвЛжТЃЌШэМўАќКЌКмЖрФЃПщЃЌВЛЭЌФЃПщЖМЛсвРРЕЭЌвЛИіЕкШ§ЗНПтЩѕжСВЛЭЌЕФАцБОЃЌетжжАцБОВЛвЛжТдіМгПЊЗЂШЫдБЮЌЛЄДњМлЛЙв§Ц№вРРЕГхЭЛЃЌетИіЗНУцЬсЙЉЕкШ§ЗНАцБОЭГвЛЕФЭЦМіЁЃ
ЪзЯШЪЕЯжАцБОВЛвЛжТЃЌЕБЧАЯюФПдкЕБЧАвРРЕТЗОЖЕБжаДцдкВЛвЛжТЕкШ§ЗНПтЕФАцБОЃЌСэЭтвВЛсСПЛЏЭГвЛДњМлЭЈЙ§APIВювьРДЪЕЯжЃЌдкЕкШ§ЗНПтвРРЕзЗЫнЃЌSTACK
OVERFLOW НјаажБНгвРРЕКЭЗжЮіЃЌдкетИіЛљДЁЩЯдіМгЖюЭтЕФУшЪіЃЌЕкШ§ЗНПтЙІФмАќРЈПЊЗЂШЫдБЁЂаэПЩжЄЁЂбнЛЏРњЪЗЁЂПЭЛЇЖЫДњТыЩ§МЖАИР§ЃЌаЮГЩСЫЕкШ§ЗНПтЛљДЁЩЯЛуМЏЖрЗНжЊЪЖНЈСЂжЊЪЖЭМЦзЃЌжЇГжЖржжзЗЫнЗжЮіФПБъЁЃ
ЖјЧвЮвУЧвВНсКЯвРРЕЗжЮіЕФММЪѕРДЪЕЯжЖдгкЕкШ§ЗНПтгАЯьЕФЗжЮіЃЌгаЕкШ§ЗНПтБЈГіРДФГИіТЉЖДЃЌЕЋЪЧетИіТЉЖДЖдгкЕБЧАгАЯьгаУЛгагАЯьЃЌПЩвдИљОнЕБЧАЗжЮіЕУЕНЗжЮігАЯьЃЌТЉЖД1ЭЈЙ§гАЯьЗжЮіЗЂЯжгАЯьФГвЛИіЕкШ§ЗНПтЖдЭтAPIЃЌЕЋЪЧЖдЭтAPIУЛгагУЕНЃЌЫљвдТЉЖД1ЖдгкгІгУЯюФПУЛгагАЯьЁЃ
ФЧУДЗжЮіТЉЖД 2ЃЌЭЈЙ§вРРЕСДЬѕЗЂЯжЖдгкгІгУЯюФПЕФФЃПщ 2 ЪЧгагАЯьЃЌЫљвдАВШЋТЉЖД 2ЖдгкгІгУЪЧгагАЯьЃЌЛЙгаЕкШ§ЗНПтЛЙгаДцдкМфНгЕФвРРЕЃЌдкЕБЧАЦЌзгЕкШ§ЗНПтвдРДЕкШ§ЗНПтЃЌетбљМфНгвРРЕвВПЩФмЕМжТМфНгЕФгАЯьЃЌМфНгвРРЕПЩФмДцдкЯргІЕФТЉЖДЃЌетИіТЉЖДПЩФмЛсЖдЮвУЧЕБЧАгІгУЯюФПВњЩњМфНггАЯьЃЌФЧУДЗЂЯжАВШЋТЉЖД2ЖдгкЕБЧАЕФгІгУЯюФПвВЪЧгагАЯьЁЃ
ЫФЁЂзмНсгыеЙЭћ
ЮвУЧдкЗжЮіШэМўбаЗЂаЇФмЬсЩ§еЯАЕФЛљДЁЩЯЃЌНщЩмСЫЮвУЧДњТыДѓЪ§ОнЦНЬЈЕФЫМЯыЃЌЮвУЧДњТыДѓЪ§ОнЦНЬЈАќРЈДњТыПьеебнЛЏЙ§ГЬЭтВПвРРЕЕШЕШЖрИіФкШнЃЌКЫаФЪЧЪгЦЕгыЙ§ГЬЪ§ОнШЋУцСЌНггызЗзйЃЌЯЕЭГЪЕЯжШэМўПЊЗЂжЊЪЖЕФЗДРЁЪеМЏКЭФ§СЗЃЌЭЈЙ§ЖрЮЌЖШЁЂгазЗЫнДњТыДѓЪ§ОнЗжЮіжњСІШэМўПЊЗЂЬсжЪдіаЇЁЃ
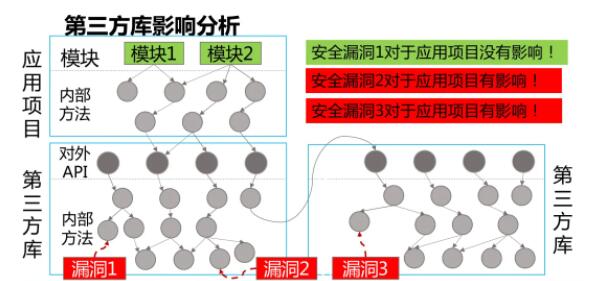
зюКѓеЙЭћвЛЯТЃЌЮвУЧЯЃЭћЭЈЙ§газЗЫнДњТыДѓЪ§ОнЗжЮіРДЪЕЯжгааЇЖШСПКЭЗжЮіЃЌЮЇШЦзХЯждкШэМўЕФПЊЗЂепвдМАШэМўПЊЗЂЭХЖгдкПЊеЙвЛЯЕСаЛљгкШэМўДѓЪ§ОнЩюВуДЮПЊЗЂЃЌЗжЮіУПИіПЊЗЂШЫдБЙБЯзЖШЃЌЗжЮіШБЯнв§ШыКЭХХГ§ЕФБШТЪЁЃ
ЮвУЧЛЙЛсЗжЮіДњТыЕФДДаТЖШЃЌКтСПДњТыжагаЖрДѓДДаТадПМТЧЕНДњТыжиИДЖШAPIЭЈгУГЬЖШЁЃЛЙЛсЗжЮіДњТыгааЇЕФДњТыСПЃЌвтЮЖзХФуЕФДњТызюКѓОЙ§вЛИіГЄЪБМфбнЛЏжЎКѓзюКѓДцЛюВЂЧвБЃСєдкДњТыжаЁЃЛЙгаДњТыЫ№КФТЪЃЌдкбнЛЏЙ§ГЬЕБжадјОаДЙ§ЃЌЕЋЪЧВЂУЛгаЗЂЛгаЇФмЃЌетИіЪЧЫљЮНЕФДњТыЫ№КФЁЃ
ЛЙгаЬиадЪЕЯжФбЖШгыДДаТЖШЃЌетИіЖМЪЧЪЕМљЬНЫїЃЌЭЈЙ§ДњТыДѓЪ§ОнГЪЯжИќМгЩюВуДЮЖШСПКЭЗжЮіЕФНсЙћЃЌДгЖјНтОіЧАУцЬсЕНЕБЧАШэМўбаЗЂЪЕМљЕБжаЮвУЧШэМўЖШСПЫљУцСйЕФРЇОГЁЃ
|









