| 编辑推荐: |
本文主要是介绍了Git 的本质以及他的存储实现的相关原理,希望本文对您的学习有所帮助。
本文来自于知乎,由火龙果软件Linda编辑、推荐。 |
|
摘要:Git 是目前最流行的版本控制系统,从本地开发到生产部署,我们每天都在使用
Git 进行我们的版本控制,除了日常使用的命令之外,如果想要对 Git 有更深一步的了解,那么研究下
Git 的底层存储原理将会对理解 Git 及其使用非常有帮助,就算你不是一个 Git 开发者,也推荐你了解下
Git 的底层原理,你会对 Git 的强大有一个全新的认识,并且将会在日常的 Git 使用过程中更加得心应手。

这篇文章面向的读者主要是对 Git 有一定的了解的群体,并不会介绍具体 Git 的作用及其使用,也不会介绍与其它版本控制系统如
Subversion 之间的差异,主要是介绍下 Git 的本质以及他的存储实现的相关原理,旨在帮助
Git 使用者更加清晰的了解在使用 Git 进行版本控制的时候其内部实现。
Git 本质是什么
Git 本质上是一个内容寻址的 Key-Value 数据库,我们可以向 Git 仓库内插入任意类型的内容,Git
会返回给我们一个唯一的键值,可以通过这个键取出当时我们插入的值,我们可以通过底层命令git hash-object命令来尝试:
➜ Zoker git:(master)
✗ cat testfile
Hello Git
➜ Zoker git:(master) ✗ git hash-object testfile
-w
9f4d96d5b00d98959ea9960f069585ce42b1349a |
可以看到我们目录下有一个名为testfile的文件,内容是Hello Git! 我们使用git hash-object命令将这个文件的内容写入到
Git 仓库,-w 选项告诉 Git 把这个内容写到 Git 的.git/objects对象数据库目录,并且
Git 返回了一个 SHA 值,这个 SHA 值就是后续我们要取出这个文件的键值:
| ➜
Zoker git:(master) ✗ git cat-file -p 9f4d96d5b00d98959ea9960f069585ce42b1349a
Hello Git |
我们使用了git cat-file命令取回刚刚存入到 Git 仓库的内容,虽然不像Redis的命令get
set 那么直观,但是它确实是一个 KV 数据库,不是吗?
我们刚刚尝试插入的这种数据是基础的blob类型的对象,Git 还有其它如 tree、commit等对象类型,这些不同的对象类型之间有特定的关联关系,它们将不同的对象有逻辑的关联起来,才能够帮我们进行不同版本的控制和检出。稍后会展开讲解这几种不同的对象类型,我们先来了解下
Git 的目录结构,看看在 Git 中数据是如何存放的。
Git 目录结构
通过上一节的介绍,我们知道了 Git 本质就是一个 KV 数据库,而且还提到了内容都是写到 .git/objects对象目录,那么这个目录放在哪里?Git
又是如何存储这些数据的呢?本节我们重点介绍一下 Git 的存储目录结构,了解下 Git 是如何存放不同类型的数据的。
更详细的介绍参见
通过 git init 我们可以在当前目录初始化一个空的 Git 仓库,Git 会自动生成 .git
目录,这个 .git 目录就是后续所有的 Git 元数据的存储中心,我们来看一下它的目录结构:
| ➜
Zoker git init
Initialized empty Git repository
in /Users/zoker/tmp/Zoker/.git/
➜ Zoker git:(master) ✗ tree
.git
.git
├── HEAD // 是一个符号引用,指明
当前工作目录的版本引用信息,我们平时执行
checkout 命令时就会改变 HEAD 的内容
├── config // 配置当前存储库的一些信息,
如:Proxy、用户信息、引用等,
此处的配置项相对于全局配置权重更高
├── description // 仓库描述信息
├── hooks // 钩子目录,执行 Git 相关命令后的回调脚本
,默认会有一些模板
│ ├── update.sample
│ ├── pre-receive.sample
│ └── ...
├── info // 存储一些额外的仓库信息如 refs、exclude、attributes
等
│ └── exclude
├── objects // 元数据存储中心
│ ├── info
│ └── pack
└── refs // 存放引用信息,也就是分支、标签
├── heads
└── tags |
默认初始化生成的 Git 仓库就只有这些文件,除此之外还存在一些其它类型的文件和目录如packed-refs
modules logs等,这些文件都有特定的用途,都是在特定的操作或者配置后才会出现,这里我们只关注核心存储的实现,这些额外文件或目录的作用及使用场景再可自行翻阅文档,这里仅介绍核心的一些文件。
hooks 目录
hooks 目录主要存储的是 Git 钩子,Git 钩子可以在很多事件发生后或者发生前触发,能够提供给我们非常灵活的使用方式,默认情况下全部都是带.sample后缀的,需要移除这个后缀并赋予可执行权限方可生效,下面列举下常用的一些钩子及其常见的用途:
客户端钩子
pre-commit:提交前触发,比如检查提交信息是否规范,测试是否运行完毕,代码格式是否符合要求
post-commit:相反,这个是整个提交完成后触发,可以用来发通知
服务端钩子
pre-receive:服务端接收推送请求首先被调用的脚本,可以检测这些被推送的引用是否符合要求
update:与 pre-receive 相似,但是 pre-receive 只会运行一次,而 update
将会为每一个推送的分支分别运行一次
post-receive:整个推送过程完成后触发,可以用来发送通知、触发构建系统等
objects 目录
如上一节我们提到的,Git 将所有接收到的内容生成对象文件存储在这个目录下,我们通过git hash-object生成了一个对象并写入了
Git 仓库,这个对象的键值是9f4d96d5b00d98959ea9960f069585ce42b1349a,这个时候我们来查看下
objects 目录的结构:
| ➜
Zoker git:(master) ✗ git hash-object testfile
-w
9f4d96d5b00d98959ea9960f069585ce42b1349a
➜ Zoker git:(master) ✗ tree
.git/objects
.git/objects
├── 9f
│ └── 4d96d5b00d98959ea9960f069585ce42b1349a
├── info
└── pack |
可以看到objects目录已经有了新的内容,多了一个9f的文件夹以及其中的文件,这个文件就是插入到
Git 仓库的内容的对象文件,Git 取其键值的前两个字母作为文件夹,将后面的字母作为对象文件的文件名进行存储,这里(也就是objects/[0-9a-f][0-9a-f])所存储的对象我们一般称为loose
objects或者unpacked objects,也就是松散对象。
除了对象的存储文件夹,细心的同学应该已经注意到了objects/pack文件夹的存在,这里对应的是打包后的文件,为了节省空间和提升效率,当存储库中有过多的松散对象文件或者手动执行git
gc命令时,亦或是推送拉取的传输过程中,Git 都会将这些松散的对象文件打包成pack文件来提升效率,这里存放的就是这些打包后的文件:
| ➜
objects git:(master) git gc
...
Compressing objects: 100% (75/75),
done.
...
➜ objects git:(master) tree
.
├─ pack
├── pack-fe24a22b0313342a6732cff4759bedb25c2ea55d.idx
└── pack-fe24a22b0313342a6732cff4759bedb25c2ea55d.pack
└── ... |
可以看到objects目录已经没有了松散对象,取而代之的是pack目录的两个文件,一个是打包后的文件,另一个是对这个打包的内容进行索引的idx文件,方便查询某个对象是否在这个对应的pack包内。
需要注意的是,如果在刚刚我们手动创建的一个blob对象的仓库进行 GC,将不会产生任何效果,因为这个时候整个
Git 仓库并没有任何一个引用指向这个对象,我们说这个对象是游离的,下面我们来介绍下存储引用的目录。
refs 目录
refs 目录存储我们的引用(references),引用可以看做是对一个版本号的别名,它存储的实际就是某一个
Commit 的 SHA 值,上面我们用来测试的仓库并没有任何一个提交,所以只有一个空的目录结构
| └──
refs
├── heads
└── tags |
我们随便找一个包含提交的仓库查看他的默认分支master
| ➜
.git git:(master) cat refs/heads/master
87e917616712189ecac8c4890fe7d2dc2d554ac6 |
可以看到这个master的引用只是存储了一个 Commit 的 SHA 值,好处当然就是我们不需要记着那长长的一串
SHA 值,我们只需要用master这个别名就可以获取到这个版本。同样的 tags 目录下存储的就是我们的标签,与分支不同的是,标签的所记录的引用值一般是不会变化的,而分支可以我们的版本变化而变化。除此之外,还可能会看到refs/remotes
refs/fetch 等目录,这些里面存储的是特定命名空间的引用。
还有一种情况,就是上面我们讲到的 GC 机制,如果一个仓库执行了 GC,那么不仅objects目录下的松散对象会被打包,refs下面的引用同样也会被打包,只不过它存放在裸仓库的根目录下.git/packed-refs
| ➜
.git git:(master) cat packed-refs
# pack-refs with: peeled fully-peeled
sorted
87e917616712189ecac8c4890fe7d2dc2d554ac6
refs/heads/master |
当我们需要访问分支master的时候,Git 会首先去refs/heads里面进行查找,如果找不到就会前往.git/packed-refs进行查找,将所有的引用打包到一个文件无疑提升了不少效率。需要注意的是,如果我们在这个时候往master分支上更新了一些提交,这个时候
Git 并不会直接修改 .git/packed-refs文件,它会直接在refs/heads/下重新创建一个master引用,包含最新的提交的
SHA 值,根据刚刚我们介绍的 Git 的机制,Git 会首先在refs/heads/查找,找不到才会去.git/packed-refs查找。
那么引用里面存储的 Commit 的 这串 SHA 值到底是指向什么内容呢,我们可以使用之前查看blob对象内容的cat-file命令进行查看:
| ➜
.git git:(master) git cat-file -p 87e917616712189ecac8c4890fe7d2dc2d554ac6
tree aab1a9217aa6896ef46d3e1a90bc64e8178e1662
// 指向的tree对象
parent 7d000309cb780fa27898b4d103afcfa95a8c04db
// 父提交
author Zoker <kaixuanguiqu@gmail.com>
1607958804 +0800
// 作者信息
committer Zoker <kaixuanguiqu@gmail.com>
1607958804 +0800
// 提交者信息
test ssh // 提交信息 |
它是一个commit类型的对象,主要的属性是它指向的tree对象,它的父提交(如果它是第一个提交,那么这里是0000000...),以及作者和提交信息。
那么commit对象是什么?它所指向的tree对象又是什么?与之前我们手工创建的blob对象有什么差别?接下来我们来谈谈
Git 存储对象。
Git 存储对象
在 Git 的世界里,一共有四种类型的存储对象:文件(blob)、树(tree)、提交(commit)、标签(tag),这里我们主要探讨头三种类型,因为这三种是最基础的
Git 元数据,而标签对象只是一个包含了额外属性信息的 Tag 而已,也就是附注标签(annotated
tag),这里不再过多的介绍。
轻量标签(lightweight)与附注标签(annotated)介绍:
Blob 对象
在介绍 Git 本质的时候,为了演示 Git 是一个基于内容寻址的 KV 数据库,我们向 Git 仓库插入了一个文件的内容:
| ➜
Zoker git:(master) ✗ cat testfile
Hello Git
➜ Zoker git:(master) ✗ git
hash-object testfile -w
9f4d96d5b00d98959ea9960f069585ce42b1349a |
这个 Key 为9f4d96d5b00d98959ea9960f069585ce42b1349a的
Git 对象实际上就是一个 Blob 对象,他存储了这个testfile文件的值,我们可以使用cat-file命令来进行查看:
| ➜
Zoker git:(master) ✗ git cat-file -p 9f4d96d5b00d98959ea9960f069585ce42b1349a
Hello Git |
每一次我们修改文件,Git 都会完整的保存一份这个文件的快照而非记录差异,所以如果我们修改了testfile文件的内容再次存入到
Git 仓库中的时候,Git 会基于当前最新的内容来生成它的 Key,需要注意的是当内容不变的时候,它的
Key 值是固定的,毕竟我们前面也说了,Git 是一个基于内容寻址的 KV 数据库。
另外,这里的 Blob 对象存储的是文本内容,它还可以是二进制内容,但是这里并不建议使用 Git
管理二进制文件的版本。我们 Gitee 平台在日常运营过程中遇到最多的问题就是用户仓库过大,这种情况一般都是用户提交了大的二进制文件导致的,因为每次文件的变更记录的是快照,所以这个二进制文件如果变更频繁,它占用的空间是倍增的。而且对于文本内容的
Blob,Git 在 GC 的过程中会只保存两次提交之间的文件差异,是可以达到节省空间的效果的,但是对于二进制内容的
Blob 是无法像文本内容的 Blob 那样处理的,所以尽量不要把频繁变动的二进制内容存储到 Git
仓库,可以使用 LFS 的方式进行存储。如果已经存在了大量的二进制文件,可以使用filter-branch进行瘦身,新加入的同事在首次
Clone 仓库的时候肯定会感激你的。
LFS 的使用:https://gitee.com/help/articles/4235 大仓库的瘦身:参见
到了这里是不是觉得哪里不对劲?没错,这个 Blob 对象只存储了这个文件的内容,却没有记录文件名,那我们该怎么知道这个内容是属于哪个文件的啊?答案是
Git 的另外一个重要的对象:Tree 对象。
Tree 对象
在 Git 中,Tree 对象主要的作用是将多个 Blob 或者 子 Tree 对象组织到一起,所有的内容都是通过
Tree 和 Blob 类型的对象进行存储的。一个 Tree 对象包含了一个或者多个 Tree Entry(树对象记录),每个树对象记录都包含了一个指向
Blob 或者子 Tree SHA 值的指针,还有它们对应的文件名等信息,其实就可以理解为索引文件系统中的`inode`和`block`的关系,图示一个
Tree 对象的话,如下图:
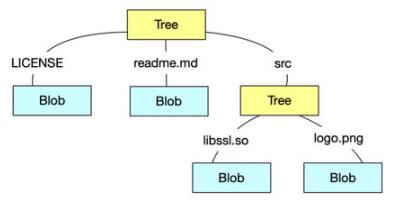
这个 Tree 对象对应的目录结构就是下面这样的:
| ├──
LICENSE
├── readme.md
└── src
├── libssl.so
└── logo.png |
.
通过这种方式,我们可以像组织 Linux 下目录的方式一样来结构化的存储我们仓库的内容,把
Tree 看作目录结构,把 Blob 看作具体的文件内容。
那么该如何创建一个 Tree 对象呢?在 Git 中是根据暂存区的状态来创建对应的 Tree 对象的,这里的暂存区其实就是我们日常在使用
Git 的过程中所理解的暂存区(Staged),一般我们使用git add命令将某些文件添加到暂存区待提交。在没有任何提交的空仓库里,这个暂存区的状态就是你通过git
add所添加的那些文件,如:
| ➜
Zoker git:(master) ✗ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached
<file>..." to unstage)
new file: LICENSE
new file: readme.md
Untracked files:
(use "git add <file>..."
to include in what will be committed)
src/ |
这里当前的暂存区状态就是在根目录有两个文件,暂存区的状态是保存在.git/index文件的,我们使用file命令来看看它是什么:
| ➜
Zoker git:(master) ✗ file .git/index
.git/index: Git index, version
2, 2 entries |
可以发现在index文件中有两个entry,也就是根目录的两个文件LICENSE和readme.md。对于已经有提交的仓库,如果暂存区没有任何内容,那么这个index表示的就是当前版本的目录树状态,如果修改或者增删了文件,并且加入了暂存区,那么index就会发生改变,将相关文件的指针指向该文件新的
Blob 对象的 SHA 值。
所以如果想要创建一个 Tree 对象,我们需要往暂存区放点东西,除了使用git add,我们还可以使用底层命令update-index来创建一个暂存区。接下来我们根据上面已经创建好的testfile文件来创建一个树对象,首先就是将文件testfile加入到暂存区:
| ➜
Zoker git:(master) ✗ git update-index --add
testfile // 与 git add testfile 一样
➜ Zoker git:(master) ✗ git
status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached
<file>..." to unstage)
new file: testfile |
这个过程 Git 主要是先把testfile的内容以 Blob 的形式插入到 Git 仓库,然后将返回的这个
Blob 的 SHA 值记录到index中,告诉暂存区目前这个文件的内容是哪个。
| ➜
Zoker git:(master) ✗ tree .git/objects
.git/objects
├── 9f
│ └── 4d96d5b00d98959ea9960f069585ce42b1349a
├── info
└── pack
3 directories, 1 file
➜ Zoker git:(master) ✗ git
cat-file -p 9f4d96d5b00d98959ea9960f069585ce42b1349a
Hello Git |
Git 在执行update-index命令的时候,把指定文件的内容存储为 Blob 对象,并且记录在index文件状态内。由于在之前我们已经通过git
hash-object命令将这个文件的内容插入过了,并且我们可以发现因为内容不变,所以生成的这个 Blob
对象的 SHA 值也是一致的,如果像我们这样已经做过插入的动作,下面的命令是等效的:
| git update-index
--add --cacheinfo 9f4d96d5b00 d98959ea9960f069585ce42b1349a
testfile |
这个命令其实就是把之前已经生成的 Blob 对象放到暂存区,并且指定它的文件名字是testfile。由于我们的暂存区已经有一个文件testfile,所以我接下来我们可以使用git
write-tree命令来基于当前暂存区的状态来创建一个 Tree 对象了:
| ➜
Zoker git:(master) ✗ git write-tree
aa406ee8804971cf8edfd8c89ff431b0462e250c
➜ Zoker git:(master) ✗ tree
.git/objects
.git/objects
├── 9f
│ └── 4d96d5b00d98959ea9960f069585ce42b1349a
├── aa
│ └── 406ee8804971cf8edfd8c89ff431b0462e250c
├── info
└── pack |
执行完命令后,Git 会基于当前暂存区的状态生成一个 SHA 值为aa406ee8804971 cf8edfd8c89ff431b0462e250c的
Tree 对象,并把这个 Tree 对象像 Blob 对象一样存储在.git/objects目录下。
| ➜
Zoker git:(master) ✗ git cat-file -p aa406ee8804971cf8edfd8c89ff431b0462e250c
100644 blob 9f4d96d5b00d98959ea 9960f069585ce42b1349a
testfile |
使用cat-file命令查看这个 Tree 对象,可以看到这个对象下只有一个文件,名为testfile

我们继续创建第二个 Tree 对象,我们需要第二个 Tree 对象下有修改后的testfile文件,有新增的
testfile2文件,并且需要把第一个 Tree 对象作为 第二个 Tree 对象的duplicate目录。首先我们先把修改后的testfile和新增的testfile2文件加入到暂存区:
| ➜
Zoker git:(master) ✗ git update-index testfile
➜ Zoker git:(master) ✗ git
update-index --add testfile2
➜ Zoker git:(master) ✗ git
status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached
<file>..." to unstage)
new file: testfile
new file: testfile2 |
紧接着我们需要把第一个 Tree 对象挂到duplicate目录下,我们可以使用read-tree命令来实现:
| ➜
Zoker git:(master) ✗ git read-tree --prefix=duplicate
aa406ee8804971cf8edfd8c89ff431b0462e250c
➜ Zoker git:(master) ✗ git
status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached
<file>..." to unstage)
new file: duplicate/testfile
new file: testfile
new file: testfile2 |
然后我们执行write-tree并通过cat-file查看第二个 Tree 对象:
| ➜
Zoker git:(master) ✗ git write-tree
64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
➜ Zoker git:(master) ✗ git
cat-file -p 64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
040000 tree aa406ee8804971cf8edfd8c89ff431b0462e250c
duplicate
100644 blob 106287c47fd25ad9a0874670a0d5c6eacf1bfe4e
testfile
100644 blob 098ffe6f84559f4899edf119c25d276dc70607cf
testfile2 |
成功完成了,我们不仅修改了testfile的文件内容,还新增了一个testfile2文件,并且还把第一个
Tree 对象当作第二个 Tree 对象的duplicate目录了,这个时候 Tree 对象看起来应该是这样的:
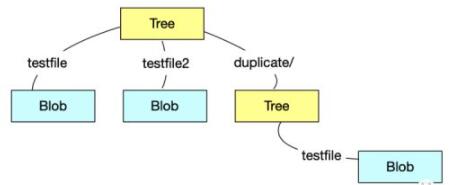
至此,我们知道了如何手动创建一个 Tree 对象,但是后面如果我需要这两个不同的 Tree 的快照该怎么办?总不能都记住这三个
Tree 对象的 SHA 值吧?没错,记起来费老大劲了,关键是还不知道是谁在什么时间为了什么而创建的这个快照,而
Commit 对象(提交对象)就能够帮我们解决这个问题。
Commit 对象
Commit 对象主要是为了记录快照的一些附加信息,并且维护快照之间的线性关系。我们可以通过git
commit-tree命令来创建一个提交,这个命令看字面意思就知道,它是用来将 Tree 对象提交为一个
Commit 对象的命令:
| ➜
Zoker git:(master) ✗ git commit-tree -h
usage: git commit-tree [(-p
<parent>)...] [-S[<keyid>]] [(-m
<message>)...] [(-F <file>)...]
<tree>
-p <parent> id of a parent
commit object
-m <message> commit message
-F <file> read commit
log message from file
-S, --gpg-sign[=<key-id>]
GPG sign commit |
关键的两个参数是-p和-m,-p是指定这个提交的父提交,如果是初始的第一个提交,那这里可以忽略;-m则是指定本次提交的信息,主要是用来描述提交的原因。我们来把第一个
Tree 对象作为我们的初始提交:
| ➜
Zoker git:(master) ✗ git commit-tree -m "init
commit" aa406ee8804971cf8edfd8c89ff431b0462e250c
17ae181bd6c3e703df7851c0f7ea01d9e33a675b |
使用cat-file来查看这个提交:
| tree
aa406ee8804971cf8edfd8c89ff431b0462e250c
author Zoker <kaixuanguiqu@gmail.com>
1613225370 +0800
committer Zoker <kaixuanguiqu@gmail.com>
1613225370 +0800
init commit |
Commit 所存储的内容是一个 Tree 对象,并且记录了提交者、提交时间以及提交信息。我们基于这个
Commit 将第二个 Tree 对象作为引用:
| ➜
Zoker git:(master) ✗ git commit-tree -p 17ae181bd
-m "add dir" 64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
de96a74725dd72c10693c4896cb74e8967859e58
➜ Zoker git:(master) ✗ git
cat-file -p de96a74725dd72c10693c4896cb74e8967859e58
tree 64d62cef754e6cc995ed8d34f0d0e233e1dfd5d1
parent 17ae181bd6c3e703df7851c0f7ea01d9e33a675b
author Zoker <kaixuanguiqu@gmail.com>
1613225850 +0800
committer Zoker <kaixuanguiqu@gmail.com>
1613225850 +0800
add dir
我们可以使用git log来查看这两个提交,这里添加--stat参数查看文件变更记录:
commit de96a74725dd72c10693c4896cb74e8967859e58
Author: Zoker <kaixuanguiqu@gmail.com>
Date: Sun Feb 13 22:17:30 2021
+0800
add dir
duplicate/testfile | 1 +
testfile | 2 +-
testfile2 | 1 +
3 files changed, 3 insertions(+),
1 deletion(-)
commit 17ae181bd6c3e703df7851c0f7ea01d9e33a675b
Author: Zoker <kaixuanguiqu@gmail.com>
Date: Sun Feb 13 22:09:30 2021
+0800
init commit
testfile | 1 +
1 file changed, 1 insertion(+) |
这个时候整个对象的结构如下图:
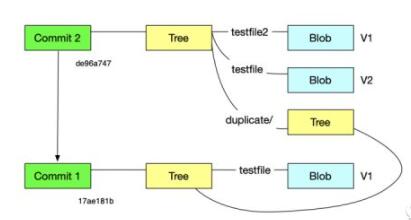
练习:使用底层命令创建一个提交
仅使用我们上面提到的hash-object write-tree read-tree commit-tree等底层命令来创建一个提交,思考哪些过程是与git
add git commit等价的。
对象存储方式
我们通过前面的介绍,知道了 Git 是将数据以不同的对象类型归纳,并且根据内容计算出一个 SHA 值用来作为寻址,那么到底是如何计算的呢?以
Blob 对象为例,Git 主要是做了如下几步:
识别对象的类型,构造头部信息,以类型+内容字节数+空字节作为头部信息如blob 151\u0000
将头部信息与内容拼接,并且计算 SHA-1 校验和
通过 zlib 压缩内容
通过 SHA 值将其内容放到对应的objects目录
整个过程就做了这些事情,Tree 对象和 Commit 对象也差不多,只是头部类型有所差异而已,这里不再赘述,《Pro
Git 2》在 Git 内部原理章节中有介绍如何使用 Ruby 来实现同等的逻辑,感兴趣的可以自行翻阅。
Git-内部原理
Git 引用
我们在上面通过git log --stat 17ae181b能够查看第一个版本的相关信息,并且可以通过这串
SHA 值拿到这个快照的内容,但是还是挺麻烦的,因为我们要记住一串毫无意义的字符串,这个时候 Git
的引用就派上用场了,在 Git 目录结构章节我们已经介绍了refs目录,我们知道在引用中存储的就是
Commit 对象的键值,也就是这个对象的 SHA 值,既然如此,我们就给我们当前的版本起一个有意义的名字,一般我们会拿master作为默认分支引用:
| ➜
Zoker git:(master) ✗ echo "17ae181bd6c 3e703df7851c0f7ea01d9e33a675b"
>> .git/refs/heads/master
➜ Zoker git:(master) ✗ tree
.git/refs
.git/refs
├── heads
│ └── master
└── tags |
这个时候,master里面存储了我们的第一个 Commit 的 SHA 值,我们可以使用master来代替17ae181b这串毫无意义的字符串了
| ➜
Zoker git:(master) ✗ git cat-file -p master
tree aa406ee8804971cf8edfd8c89ff431b0462e250c
author Zoker <kaixuanguiqu@gmail.com>
1613916447 +0800
committer Zoker <kaixuanguiqu@gmail.com>
1613916447 +0800
init commit |
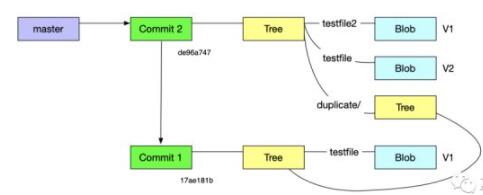
但是,这个并不是我们最新的版本,我们最新的版本是第二个提交de96a74725dd72c 10693c4896cb74e8967859e58,同样的,我们可以把refs/heads/master的内容更改为这个提交的
SHA 值,但是这里我们使用一个底层命令来完成
| ➜
Zoker git:(master) ✗ git update-ref refs/heads/master
de96a74725dd72c10693c4896cb74e8967859e58
➜ Zoker git:(master) ✗ cat
.git/refs/heads/master
de96a74725dd72c10693c4896cb74e8967859e58 |
这个时候,分支master就指向了我们最新的版本
总结
以上主要讨论了 Git 基础的存储原理以及一些实现,还有一些如 Pack 的打包、传输协商机制以及存储格式等,限于篇幅并没有说到,后面根据一些场景再另行讨论。
|







 订阅
订阅