| UML软件工程组织 | |||
| |
|||
|
|||
Principles and techniques for analyzing
and improving IBM Rational ClearCase performance
2008-08-21 作者:史 新丽 来源:IBM
from The Rational Edge: This article, Part I of a series on principles and techniques for improving IBM Rational ClearCase performance, provides an overview of the principles of performance assessment and advice on how to apply them in a Rational ClearCase environment. On any given day, how many times does your development team check out or check in artifacts from your IBM Rational® ClearCase® versioned object bases (VOBs)? How many builds do they perform? If you pause to consider how many Rational ClearCase operations your team performs over the lifetime of a project, it is easy to see how even a small improvement in the speed of these operations can save a significant amount of time. Over the past eight years, I have worked with development teams of all sizes and geographic distributions, helping them use Rational ClearCase more effectively and efficiently for software configuration management (SCM). I think it is fair to say that all of them appreciated any efforts that would enable them to get more work accomplished in a day, and ultimately complete projects faster. Whether you are a Rational ClearCase administrator facing a performance problem, or you are just looking to improve performance to give your team's productivity a boost, it helps to have a plan. This article, Part I of a series on principles and techniques for improving IBM Rational ClearCase performance, provides an overview of the principles of performance assessment and advice on how to apply them in a Rational ClearCase environment. It presents an approach that I have found useful in diagnosing performance issues and arriving at a solution,1 and uses a case study to illustrate this approach. In an upcoming issue of The Rational Edge, Part II of this series will discuss how to use specific tools and practices to assess and improve the performance of IBM Rational ClearCase in your organization. When I address a performance problem, I start by gathering general information. I try to identify characteristics of the problem and determine how the problem manifested itself. Performance issues can be classified into two broad categories:
Slowdowns that have a sudden onset are usually easier to diagnose and fix, as they are often related to a recent change in the IBM Rational ClearCase operating environment. Performance issues that evolve over a long period of time ? sometimes a year or more ? are more difficult to resolve. In many ways, the questions you ask to diagnose a performance problem are similar to those for tracking down a bug in an application, or those a doctor might ask a patient to locate the source of a pain. Is the problem repeatable or transient? Is it periodic? Does it happen at certain times of day? Is it associated with a specific command or action? For example, with IBM Rational ClearCase, does the problem only happen when a build is performed using clearmake or some other tool? And, as with programming bugs, the performance issues that you can reproduce easily ? such as those associated with specific commands ? are easier to deal with. Intermittent problems are, by nature, more challenging. Once you have a better understanding of how the problem manifests itself, you can start digging deeper to determine what exactly is happening in the various systems that IBM Rational ClearCase relies on. First principle of performance analysis and monitoring Systems are a loose hierarchy of interdependent resources2:
The first principle of performance analysis is that, in most cases, poor performance results from the exhaustion of one or more of these resources. As I investigate the usage of these resources in an IBM Rational ClearCase environment, I look first for obvious pathological symptoms and configurations ? that is, things that just don't belong. As an example, I recently was looking into a performance problem at a customer site. A quick check of the view host revealed that it was running 192 Oracle processes in addition to its Rational ClearCase duties. Whether that was the cause of the performance problem was not immediately obvious, but it clearly pointed to a need to assess whether the resources on the machine were adequate to support that many memory intensive processes. In fact, that leads to another principle of performance analysis: Beware of jumping to conclusions. Often one problem will mask a less obvious issue that is the real cause of the problem. Also, be careful not to let someone lead you to a conclusion if he or she has a notion ahead of time about what is causing the problem. It's important to recognize that this notion is just a hunch and may not really be the explanation for the problem. In performance analysis, I often think of a quote by physicist Richard Feynman: "The first principle is that you must not fool yourself, and you are the easiest person to fool." Essentially, I remind myself not to fall into the trap of believing that the first thing that looks wrong is really the primary problem. A layered approach to investigation Tackling an IBM Rational ClearCase performance problem can be a complex task. I find it a great help to partition the problem into three levels that comprise a "performance stack," as shown in Figure 1. At the lowest level are the operating system and hardware, such as memory, processors, and disks. Above that are IBM Rational ClearCase tunable parameters, such as cache size. At the highest level are applications. In Rational ClearCase, the application space includes scripts that perform Rational ClearCase operations, and Rational ClearCase triggers that execute automatically before or after a Rational ClearCase operation.
In my experience ? and barring any pathological situation ? as you move up each level in the performance stack, you can expect the performance payback from your efforts to increase by an order of magnitude. If you spend a week tweaking and honing parameters in the operating system kernel, you might see some performance gains. But if you spend some time adjusting the IBM Rational ClearCase caching parameters as a heuristic, you'll see about a tenfold performance gain compared to the kernel tweaks. When you move further up and make improvements at the application layer, your performance gains will be about two orders of magnitude greater than those garnered from your lowest-level efforts. If you can optimize scripts and triggers, or eliminate them altogether, there are potentially huge paybacks. In Part II of this series, I'll talk more about how to optimize the application layer to improve performance. With that in mind, you may be tempted to look first at the application layer. But as a matter of principle, when I do a performance analysis, I start at the bottom of the stack. I instrument and measure first at the OS and hardware level, and I look for pathological situations. Then I move up into the tunable database parameters, and I look at the application level last. There are a number of reasons for this order of investigation. First, it is really easy to look at the OS and hardware to see if there is something out of place going on. There are very basic tools you can use that are easy and very quick to run, and anything out of the ordinary tends to jump right out at you ? such as the 192 Oracle processes, for example. Similarly, at the next level up, IBM Rational ClearCase provides utilities that will show you its cache hit rates and let you tune the caches. These utilities are also very simple to use. I look at the application layer last because of the complexities involved. This layer is more complex technically because it has multiple intertwined pieces. It also tends to be more complex politically because scripts and triggers usually have owners who created them for a reason and might not approach problem-solving the same way you do. Some become defensive if there's a hint they've done something wrong ? but often there is nothing "wrong"; it is just that what they have done is, by nature, slow. Another reason for starting at the lowest level is simply due diligence. You do need to verify the fundamental operations of the system. Although it is where I start, I don't necessarily spend a lot of time there ? it's not where you get the most bang for your buck. I don't spend a lot of time with the IBM Rational ClearCase tunable parameters, either. It is usually a very quick exercise to examine the caches, adjust the parameters, and move on. If you were to start at the top, you might tweak on triggers and scripts for a month, and never get to the fact that you are out of memory. If the system is out of memory, then that is issue number one. You should add more ? it is a fast and easy fix. By getting the lower two layers out of the way first, it gives you time to deal with the application layer. If you have enough time to optimize ? or even eliminate ? the application layer, then that's where you will have the greatest impact on improving performance. Performance tuning is an iterative process:
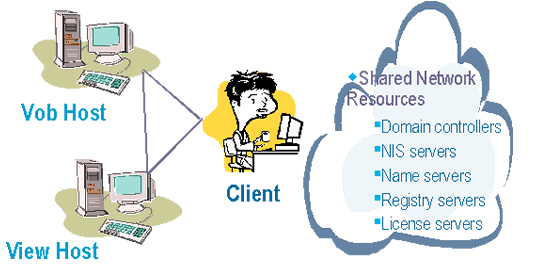
You can keep following this cycle indefinitely, but eventually you'll come to a point of diminishing returns. Once you find yourself tweaking the kernel or looking up esoteric registry settings in the Microsoft knowledge base, you are probably at a good place to stop, because you are not likely to get a big return on your investment of time. As you iterate, keep in mind the hierarchical nature of performance tuning. Remember that memory rules all. Symptoms of a memory shortage include a disk, processor, or network that appears to be overloaded. For example, when a system doesn't have enough memory, it will start paging data out to disk frequently. Once it starts doing that, the processor is burdened because it controls that paging, and the disk is working overtime to store and retrieve all those pages of memory. Adding more processing power or faster disks may help a little, but it will not address the root cause of the problem. Check for and fix memory shortages first, and then look at the other things. IBM Rational ClearCase is a distributed application. Its operations involve multiple host computers as well as several common network resources. For the purposes of solving a performance issue, I like to think of the Rational ClearCase world as a triangle whose vertices are the VOB host (machine running the vob_server process), the view host (machine running the view_server process), and the client(see Figure 2). When I undertake a performance analysis, I inspect each vertex on the triangle. I check the performance stack on each of those hosts, make sure that each has enough memory and other low-level resources, and look for abnormal situations.
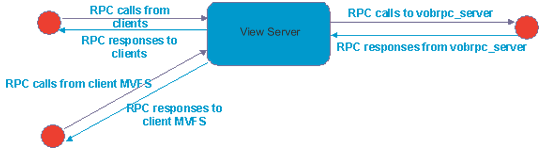
In an IBM Rational ClearCase community, the permanent repository of software artifacts consists of one or more VOBs, which are located on one or more VOB hosts. VOB servers are especially sensitive to memory, because of the performance benefits of caching the VOB database. With more memory, the VOB server can hold more of the database in memory. As a result, it will have to access data from the disk less often, thereby avoiding a process that is thousands of times slower than memory access. For the VOB host, the IBM Rational ClearCase Administrator's Guide recommends a minimum of 128 MB of memory, or half the size of all the VOB databases the host will support, whichever is greater. Heed the advice of the Administrator's Guide: "Adequate physical memory is the most important factor in VOB performance; increasing the size of a VOB host's main memory is the easiest (and most cost-effective) way to make VOB access faster and to increase the number of concurrent users without degrading performance." Typically, there aren't many IBM Rational ClearCase tunable parameters on the VOB host. There are settings you can use to control the number of server processes, but this function is rarely needed. There are other locking (lockmgr) parameters you can change if you notice errors in the Rational ClearCase log. In that case, consult the Rational ClearCase documentation or call IBM Rational technical support, and they will walk you through what you need to do. A view server manages activity in a particular Rational ClearCase view. The view server, in practice, should not run on the same physical machine as a VOB server. In some cases, the view server and client can run on the same box, depending on the configuration. As with the VOB host, the first areas to check are the fundamentals ? memory, other processes running, and so on. But a view server has more Rational ClearCase parameters that can be adjusted. Views have caches associated with them, and you can increase the size of those caches to improve performance. I've been to some customer sites where the VOB host was doing great and the view host was doing great, but the client machines were woefully low on memory. The users complained about build problems because the compiler they were using was consuming all the available resources on the client. So if your check-out and check-in operations are just fine, but builds are slow, the client machines are one good place to look. The VOB host is another, because builds, especially clearmake builds, stress the VOB server for longer periods of time than check-out or check-in operations. As usual, check the OS and hardware level first. Also, if the user is working with dynamic views, the client machine will have MVFS (multiversion file system) caches that you can increase to improve performance.3 I'll talk in more detail about how to check resources and tune IBM Rational ClearCase in Part II of this series. Figure 2 shows a cloud of shared network resources that are also very important to IBM Rational ClearCase performance. These resources include domain controllers, NIS servers, name servers, registry servers, and license servers. Rational ClearCase must authenticate users before it allows operations. If the connection to the shared resources that are required for this authentication is slow, then user authentication in Rational ClearCase will be slow. The registry server and license server are fairly lightweight and are often run on the VOB host, so connectivity to these resources is usually not an issue. When you're trying to save time, don't be latent The edges of the triangle in Figure 2 are important as well. They represent the connectivity between the VOB host, view host, and client. In an IBM Rational ClearCase environment, not all network performance metrics are created equal. Network latency ? time it takes data to arrive at its destination ? has a much greater impact on Rational ClearCase performance than network throughput, the amount of data that can be sent across the network within a given timeframe. That is because in most cases, Rational ClearCase is not moving enormous files around. What it is doing is making a lot of remote procedure calls, or RPCs. As a quick review, an RPC is a particular type of message that functions like a subroutine call between two processes that can be running on different machines. When a client process calls a subroutine on a server, RPC data, including arguments to the subroutine, are sent over a lower-level protocol such as TCP or UDP. The server receives the RPC, executes appropriate code, and responds to the client. Then the client receives the response and continues processing. RPCs are synchronous; that is, the client does not continue processing until it receives the response. It is important to note that there is a call and a return ? every RPC is a two-way street. If it takes 10 ms (milliseconds) for an RPC to flow from the client to the server, then the total RPC "travel-time" is 20 ms, plus processing time. In a typical IBM Rational ClearCase transaction, either the MVFS or a client will send an RPC to the view server. The view server, in turn, calls an RPC on the VOB server. The response must first come back to the view server, and then a second response is sent back to the client.
This process has two layers of RPCs, each with a call and a response. If you have network latency of 10 ms between each of the machines, then this particular transaction will require 40 ms. Although that may not seem like much time, it quickly adds up. A check-out operation may involve more than 200 RPCs, as IBM Rational ClearCase authenticates the user, locates the VOB, locates the view, and so on. So in this case, even with relatively good 10 ms latency, over the course of the entire operation, Rational ClearCase can spend more than a second waiting for data to arrive through the network. Latency increases with every "hop" ? or router ? that data must traverse en route from its source to its destination. Each router must process a packet to determine its destination, and that processing takes time. So, the fewer hops, the better. Remember, with Rational ClearCase performance tuning, it is latency, rather than bandwidth, that really matters. You might have a network with gigabit throughput capabilities, but if an RPC call has to travel through a dozen routers, than you will be paying a significant performance penalty. Part II of this article series will provide details on how to assess network latency and other network issues. To illustrate some of the principles of IBM Rational ClearCase performance analysis and tuning we have just discussed, let's look at a real-life case study. I was working with a customer that had been using Rational ClearCase for about a year. They had implemented their own process, which included additional tracking and authorization ? they were not using UCM (Unified Change Management4). The VOBs were all located on a single Solaris server, which had four processors and four GB of memory. The view server ? which they also used to perform builds ? was on a separate, but essentially identical, machine. Even with these fairly high-powered machines, the customer was complaining of poor performance during check-out and check-in operations. When we talked to the system administrators, they thought that the VOB and view servers were running just fine. They believed that IBM Rational ClearCase was the problem. So we started with the performance stack, moving from the bottom to the top. We did our initial analysis at the bottom layer, looking for pathological things ? such as odd configurations or strange processes running on the machines ? as well as the standard sweep of resource metrics ? memory, processor, disk, and so on. We determined that the VOB host was fine but the view host was not. As it turned out, this was the customer that had 192 Oracle processes running on the view host! These processes were consuming 12 GB of virtual memory on a system with only 4 GB of physical memory. Of course, some of the memory used by each process was shared memory, reducing the total memory used by these processes to something less than 12 GB ? but that was still way more than the system had. Our observations quickly revealed that the system was out of memory, and that the processor utilization was very high? the processor had zero idle time. But the core issue wasn't processing power; it was memory. We recommended that the customer remove the Oracle processes from the view server machine. After that, we suggested adding memory if it was still needed, and changing their user interaction model, so that they were not compiling on the view host. Because the customer had not noticed the performance problems before installing Rational ClearCase (along with some application layer scripts they had developed), they hesitated to make these changes, because they still suspected that Rational ClearCase, not their systems, was causing the problem. Level 2: Rational ClearCase tunable parameters Our next step was to move up the performance stack, looking at ways to tune Rational ClearCase to improve performance. We determined that the MVFS and view caches were undersized. Our second recommendation was to increase the size of these caches, but we warned the customer of the inherent danger in this step. Allocating larger caches would make the memory shortfall greater, because we were essentially setting aside memory that the system already lacked. We went ahead, knowing that we were not addressing the memory issue. Performance did improve, but not substantially. Level 3: The application space Our next step was to examine the application layer. The customer had implemented process scripts that they wrapped around check-out and check-in operations to perform some additional authentication and logging. We instrumented those scripts to find out where the time was being spent, and then we ran them periodically throughout the day. The measurements revealed that the actual Rational ClearCase check-out and check-in times averaged 0.5 seconds, even on a view host that was completely out of memory. The rest of the scripts' processing time clocked in at 17.4 seconds. The logging and other functions performed in the application layer were taking roughly thirty-five times longer than the Rational ClearCase functions. And this was a fairly consistent ratio. At different times of the day, the Rational ClearCase times would be up to .7 seconds, but the script times were then close to 25 seconds. And that's why people were complaining. To summarize, we started at the bottom of the performance stack. At the hardware level, you don't often get a lot of payback, but looking for pathological indicators is something you need to do. We quickly saw the Oracle processes, noticed that the machine was also being used to compile, and determined that the view host was very low on memory. Next, we looked at the IBM Rational ClearCase tunable parameters, and then produced a noticeable ? but not huge ? improvement by adjusting them. The real impact was in the application layer. By rapidly examining the first two layers, we had enough time to fully analyze the application space, and we found that there was a lot of room for improvement. The customer examined the functionality they had achieved with the application layer scripts, and they found that some of the functionality was already being provided by IBM Rational ClearCase. In addition, some of the more complex tracking features they had implemented were embodied in Unified Change Management, so they decided to implement UCM. This made a critical difference in the amount of application-level processing required, so check-in and check-out times dropped significantly ? and people stopped complaining. So far I've talked about what to look for when analyzing and tuning IBM Rational ClearCase performance, and I've talked about where to look. In Part II, I'll discuss how to improve Rational ClearCase performance using tools and utilities you probably already have. Stay tuned! 1 The performance of IBM Rational ClearCase, like that of any application, is dependent upon the environment it is in, including the operating system, the hardware it runs on, and other applications running in the same environment. In addition, each organization will have its own tolerances and expectations of performance. Because of this wide range of potential environments and expectations, it is impossible to give hard-and-fast guidelines on what constitutes an acceptable level of performance. If you need assistance in determining whether your Rational ClearCase performance is reasonable for your specific environment and configuration, you may want to contact IBM Rational technical support. It is also beyond the scope of this article to discuss detailed instructions on how to tweak the operating system kernel, NFS (Network File System), Samba, or other low-level technologies. 2 For an excellent and detailed discussion on this topic, see Configuration and Capacity Planning for Solaris Servers by Brian L. Wong (Sun Microsystems Press, 1997). 3 MVFS is a feature of IBM Rational ClearCase that supports dynamic views. Dynamic views use the MVFS to present a selected combination of local and remote files as if they were stored in the native file system. MVFS also performs auditing of clearmake targets and maintains several caches to maximize performance. 4 Unified Change Management is IBM Rational's "best practices" process for managing change from requirements to release. Enabled by IBM Rational ClearCase and IBM Rational ClearQuest, UCM defines a consistent, activity-based process for managing change that teams can apply to their development projects right away. |

组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |