|
еЊвЊЃКБОЮФеЙЪОСЫШчКЮЛљгкnolearnЪЙгУвЛаЉОэЛ§ВуКЭГиЛЏВуРДНЈСЂвЛИіМђЕЅЕФConvNetЬхЯЕНсЙЙЃЌвдМАШчКЮЪЙгУConvNetШЅбЕСЗвЛИіЬиеїЬсШЁЦїЃЌШЛКѓдкЪЙгУШчSVMЁЂLogisticЛиЙщЕШВЛЭЌЕФФЃаЭжЎЧАЪЙгУЫќРДНјааЬиеїЬсШЁЁЃ
ОэЛ§ЩёОЭјТчЃЈConvNetsЃЉЪЧЪмЩњЮяЦєЗЂЕФMLPsЃЈЖрВуИажЊЦїЃЉЃЌЫќУЧгазХВЛЭЌРрБ№ЕФВуЃЌВЂЧвУПВуЕФЙЄзїЗНЪНгыЦеЭЈЕФMLPВувВгаЫљВювьЁЃШчЙћФуЖдConvNetsИааЫШЄЃЌетРягаИіКмКУЕФНЬГЬCS231n ЈC Convolutional Neural Newtorks for Visual RecognitionЁЃCNNsЕФЬхЯЕНсЙЙШчЯТЫљЪОЃК
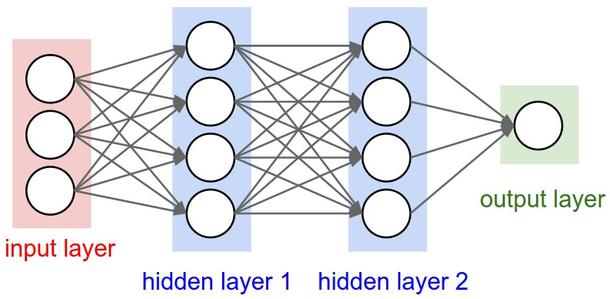
ГЃЙцЕФЩёОЭјТчЃЈРДздCS231nЭјеОЃЉ
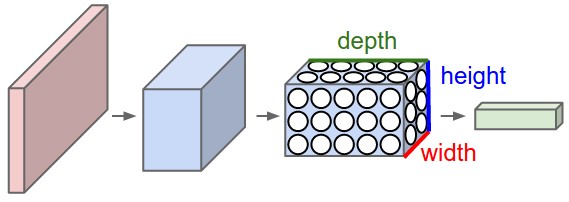
ConvNetЭјТчЬхЯЕНсЙЙЃЈРДздCS231nЭјеОЃЉ
ШчФуЫљМћЃЌConvNetsЙЄзїЪБАщЫцзХ3DОэЛ§ВЂЧвдкВЛЖЯзЊБфзХетаЉ3DОэЛ§ЁЃЮвдкетЦЊЮФеТжаВЛЛсдйжиИДећИіCS231nЕФНЬГЬЃЌЫљвдШчЙћФуецЕФИааЫШЄЃЌЧыдкМЬајдФЖСжЎЧАЯШЛЈЕуЪБМфШЅбЇЯАвЛЯТЁЃ
Lasagne КЭ nolearn
LasagneКЭnolearnЪЧЮвзюЯВЛЖЪЙгУЕФЩюЖШбЇЯАPythonАќЁЃLasagneЪЧЛљгкTheanoЕФЃЌЫљвдGPUЕФМгЫйНЋДѓгаВЛЭЌЃЌВЂЧвЦфЖдЩёОЭјТчДДНЈЕФЩљУїЗНЗЈвВКмгаАяжњЁЃnolearnПтЪЧвЛИіЩёОЭјТчШэМўАќЪЕгУГЬађМЏЃЈАќКЌLasagneЃЉЃЌЫќдкЩёОЭјТчЬхЯЕНсЙЙЕФДДНЈЙ§ГЬЩЯЁЂИїВуЕФМьбщЕШЖМФмЙЛИјЮвУЧКмДѓЕФАяжњЁЃ
дкетЦЊЮФеТжаЮввЊеЙЪОЕФЪЧЃЌШчКЮЪЙгУвЛаЉОэЛ§ВуКЭГиЛЏВуРДНЈСЂвЛИіМђЕЅЕФConvNetЬхЯЕНсЙЙЁЃЮвЛЙНЋЯђФуеЙЪОШчКЮЪЙгУConvNetШЅбЕСЗвЛИіЬиеїЬсШЁЦїЃЌдкЪЙгУШчSVMЁЂLogisticЛиЙщЕШВЛЭЌЕФФЃаЭжЎЧАЪЙгУЫќРДНјааЬиеїЬсШЁЁЃДѓЖрЪ§ШЫЪЙгУЕФЪЧдЄбЕСЗConvNetФЃаЭЃЌШЛКѓЩОГ§зюКѓвЛИіЪфГіВуЃЌНгзХДгImageNetsЪ§ОнМЏЩЯбЕСЗЕФConvNetsЭјТчЬсШЁЬиеїЁЃетЭЈГЃБЛГЦЮЊЪЧЧЈвЦбЇЯАЃЌвђЮЊЖдгкВЛЭЌЕФЮЪЬтФуПЩвдЪЙгУРДздЦфЫќЕФConvNetsВуЃЌгЩгкConvNetsЕФЕквЛВуЙ§ТЫЦїБЛЕБзіЪЧвЛИіБпдЕЬНВтЦїЃЌЫљвдЫќУЧПЩвдгУРДзїЮЊЦфЫќЮЪЬтЕФЦеЭЈЬиеїЬНВтЦїЁЃ
МгдиMNISTЪ§ОнМЏ
MNISTЪ§ОнМЏЪЧгУгкЪ§зжЪЖБ№зюДЋЭГЕФЪ§ОнМЏжЎвЛЁЃЮвУЧЪЙгУЕФЪЧвЛИіУцЯђPythonЕФАцБОЃЌЕЋЯШШУЮвУЧЕМШыашвЊЪЙгУЕФАќЃК
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.cm as cm
from urllib import urlretrieve
import cPickle as pickle
import os
import gzip
import numpy as np
import theano
import lasagne
from lasagne import layers
from lasagne.updates import nesterov_momentum
from nolearn.lasagne import NeuralNet
from nolearn.lasagne import visualize
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix |
е§ШчФуЫљПДЕНЕФЃЌЮвУЧЕМШыСЫгУгкЛцЭМЕФmatplotlibАќЃЌвЛаЉгУгкЯТдиMNISTЪ§ОнМЏЕФдЩњPythonФЃПщЃЌnumpyЃЌ theanoЃЌlasagneЃЌnolearn вдМА scikit-learnПтжагУгкФЃаЭЦРЙРЕФвЛаЉКЏЪ§ЁЃ
ШЛКѓЃЌЮвУЧЖЈвхвЛИіМгдиMNISTЪ§ОнМЏЕФКЏЪ§ЃЈетИіЙІФмгыLasagneНЬГЬЩЯЪЙгУЕФЗЧГЃЯрЫЦЃЉ
def load_dataset():
url = 'http://deeplearning.net/data/mnist/mnist.pkl.gz'
filename = 'mnist.pkl.gz'
if not os.path.exists(filename):
print("Downloading MNIST dataset...")
urlretrieve(url, filename)
with gzip.open(filename, 'rb') as f:
data = pickle.load(f)
X_train, y_train = data[0]
X_val, y_val = data[1]
X_test, y_test = data[2]
X_train = X_train.reshape((-1, 1, 28, 28))
X_val = X_val.reshape((-1, 1, 28, 28))
X_test = X_test.reshape((-1, 1, 28, 28))
y_train = y_train.astype(np.uint8)
y_val = y_val.astype(np.uint8)
y_test = y_test.astype(np.uint8)
return X_train, y_train, X_val, y_val, X_test, y_test |
е§ШчФуПДЕНЕФЃЌЮвУЧе§дкЯТдиДІРэЙ§ЕФMNISTЪ§ОнМЏЃЌНгзХАбЫќВ№ЗжЮЊШ§ИіВЛЭЌЕФЪ§ОнМЏЃЌЗжБ№ЪЧЃКбЕСЗМЏЁЂбщжЄМЏКЭВтЪдМЏЁЃШЛКѓжижУЭМЯёФкШнЃЌЮЊжЎКѓЕФLasagneЪфШыВузізМБИЃЌгыДЫЭЌЪБЃЌгЩгкGPU/theanoЪ§ОнРраЭЕФЯожЦЃЌЮвУЧЛЙАбnumpyЕФЪ§ОнРраЭзЊЛЛГЩСЫuint8ЁЃ
ЫцКѓЃЌЮвУЧзМБИМгдиMNISTЪ§ОнМЏВЂМьбщЫќЃК
X_train, y_train, X_val, y_val, X_test, y_test = load_dataset()
plt.imshow(X_train[0][0], cmap=cm.binary) |
етИіДњТыНЋЪфГіЯТУцЕФЭМЯёЃЈЮвгУЕФЪЧIPython NotebookЃЉ

вЛИіMNISTЪ§ОнМЏЕФЪ§зжЪЕР§ЃЈИУЪЕР§ЪЧ5ЃЉ
ConvNetЬхЯЕНсЙЙгыбЕСЗ
ЯждкЃЌЖЈвхЮвУЧЕФConvNetЬхЯЕНсЙЙЃЌШЛКѓЪЙгУЕЅGPU/CPUРДбЕСЗЫќЃЈЮвгавЛИіЗЧГЃСЎМлЕФGPUЃЌЕЋЫќКмгагУЃЉ
net1 = NeuralNet(
layers=[('input', layers.InputLayer),
('conv2d1', layers.Conv2DLayer),
('maxpool1', layers.MaxPool2DLayer),
('conv2d2', layers.Conv2DLayer),
('maxpool2', layers.MaxPool2DLayer),
('dropout1', layers.DropoutLayer),
('dense', layers.DenseLayer),
('dropout2', layers.DropoutLayer),
('output', layers.DenseLayer),
],
# input layer
input_shape=(None, 1, 28, 28),
# layer conv2d1
conv2d1_num_filters=32,
conv2d1_filter_size=(5, 5),
conv2d1_nonlinearity=lasagne.nonlinearities.rectify,
conv2d1_W=lasagne.init.GlorotUniform(),
# layer maxpool1
maxpool1_pool_size=(2, 2),
# layer conv2d2
conv2d2_num_filters=32,
conv2d2_filter_size=(5, 5),
conv2d2_nonlinearity=lasagne.nonlinearities.rectify,
# layer maxpool2
maxpool2_pool_size=(2, 2),
# dropout1
dropout1_p=0.5,
# dense
dense_num_units=256,
dense_nonlinearity=lasagne.nonlinearities.rectify,
# dropout2
dropout2_p=0.5,
# output
output_nonlinearity=lasagne.nonlinearities.softmax,
output_num_units=10,
# optimization method params
update=nesterov_momentum,
update_learning_rate=0.01,
update_momentum=0.9,
max_epochs=10,
verbose=1,
)
# Train the network
nn = net1.fit(X_train, y_train) |
ШчФуЫљЪгЃЌдкlayersЕФВЮЪ§жаЃЌЮвУЧЖЈвхСЫвЛИігаВуУћГЦ/РраЭЕФдЊзщзжЕфЃЌШЛКѓЖЈвхСЫетаЉВуЕФВЮЪ§ЁЃдкетРяЃЌЮвУЧЕФЬхЯЕНсЙЙЪЙгУЕФЪЧСНИіОэЛ§ВуЃЌСНИіГиЛЏВуЃЌвЛИіШЋСЌНгВуЃЈГэУмВуЃЌdense layerЃЉКЭвЛИіЪфГіВуЁЃдквЛаЉВужЎМфвВЛсгаdropoutВуЃЌdropoutВуЪЧвЛИіе§дђЛЏОиеѓЃЌЫцЛњЕФЩшжУЪфШыжЕЮЊСуРДБмУтЙ§ФтКЯЃЈМћЯТЭМЃЉЁЃ

DropoutВуаЇЙћЃЈРДздCS231nЭјеОЃЉ
ЕїгУбЕСЗЗНЗЈКѓЃЌnolearnАќНЋЛсЯдЪОбЇЯАЙ§ГЬЕФзДЬЌЃЌЮвЕФЛњЦїЪЙгУЕФЪЧЕЭЖЫЕФЕФGPUЃЌЕУЕНЕФНсЙћШчЯТЃК
# Neural Network with 160362 learnable parameters
## Layer information
# name size
--- -------- --------
0 input 1x28x28
1 conv2d1 32x24x24
2 maxpool1 32x12x12
3 conv2d2 32x8x8
4 maxpool2 32x4x4
5 dropout1 32x4x4
6 dense 256
7 dropout2 256
8 output 10
epoch train loss valid loss train/val valid acc dur
------- ------------ ------------ ----------- --------- ---
1 0.85204 0.16707 5.09977 0.95174 33.71s
2 0.27571 0.10732 2.56896 0.96825 33.34s
3 0.20262 0.08567 2.36524 0.97488 33.51s
4 0.16551 0.07695 2.15081 0.97705 33.50s
5 0.14173 0.06803 2.08322 0.98061 34.38s
6 0.12519 0.06067 2.06352 0.98239 34.02s
7 0.11077 0.05532 2.00254 0.98427 33.78s
8 0.10497 0.05771 1.81898 0.98248 34.17s
9 0.09881 0.05159 1.91509 0.98407 33.80s
10 0.09264 0.04958 1.86864 0.98526 33.40s |
е§ШчФуПДЕНЕФЃЌзюКѓвЛДЮЕФОЋЖШПЩвдДяЕН0.98526ЃЌЪЧет10ИіЕЅдЊбЕСЗжаЕФвЛИіЯрЕБВЛДэЕФадФмЁЃ
дЄВтКЭЛьЯ§Оиеѓ
ЯждкЃЌЮвУЧЪЙгУетИіФЃаЭРДдЄВтећИіВтЪдМЏЃК
preds = net1.predict(X_test) |
ЮвУЧЛЙПЩвдЛцжЦвЛИіЛьЯ§ОиеѓРДМьВщЩёОЭјТчЕФЗжРрадФмЃК
cm = confusion_matrix(y_test, preds)
plt.matshow(cm)
plt.title('Confusion matrix')
plt.colorbar()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show() |
ЩЯУцЕФДњТыНЋЛцжЦЯТУцЕФЛьЯ§ОиеѓЃК
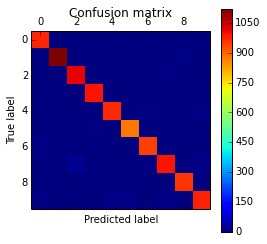
ЛьЯ§Оиеѓ
ШчФуЫљЪгЃЌЖдНЧЯпЩЯЕФЗжРрИќУмМЏЃЌБэУїЮвУЧЕФЗжРрЦїгавЛИіСМКУЕФадФмЁЃ
Й§ТЫЦїЕФПЩЪгЛЏ
ЮвУЧЛЙПЩвдДгЕквЛИіОэЛ§ВужаПЩЪгЛЏ32ИіЙ§ТЫЦїЃК
visualize.plot_conv_weights(net1.layers_['conv2d1']) |
ЩЯУцЕФДњТыНЋЛцжЦЯТУцЕФЙ§ТЫЦїЃК

ЕквЛВуЕФ5x5x32Й§ТЫЦї
ШчФуЫљЪгЃЌnolearnЕФplot_conv_weightsКЏЪ§дкЮвУЧжИЖЈЕФВужаЛцжЦГіСЫЫљгаЕФЙ§ТЫЦїЁЃ
TheanoВуЕФЙІФмКЭЬиеїЬсШЁ
ЯждкПЩвдДДНЈtheanoБрвыЕФКЏЪ§СЫЃЌЫќНЋЧАРЁЪфШыЪ§ОнЪфЫЭЕННсЙЙЬхЯЕжаЃЌЩѕжСЪЧФуИааЫШЄЕФФГвЛВужаЁЃНгзХЃЌЮвЛсЕУЕНЪфГіВуЕФКЏЪ§КЭЪфГіВуЧАУцЕФГэУмВуКЏЪ§ЁЃ
dense_layer = layers.get_output(net1.layers_['dense'], deterministic=True)
output_layer = layers.get_output(net1.layers_['output'], deterministic=True)
input_var = net1.layers_['input'].input_var
f_output = theano.function([input_var], output_layer)
f_dense = theano.function([input_var], dense_layer) |
ШчФуЫљЪгЃЌЮвУЧЯждкгаСНИіtheanoКЏЪ§ЃЌЗжБ№ЪЧf_outputКЭf_denseЃЈгУгкЪфГіВуКЭГэУмВуЃЉЁЃЧызЂвтЃЌдкетРяЮЊСЫЕУЕНетаЉВуЃЌЮвУЧЪЙгУСЫвЛИіЖюЭтЕФНазіЁАdeterministicЁБЕФВЮЪ§ЃЌетЪЧЮЊСЫБмУтdropoutВугАЯьЮвУЧЕФЧАРЁВйзїЁЃ
ЯждкЃЌЮвУЧПЩвдАбЪЕР§зЊЛЛЮЊЪфШыИёЪНЃЌШЛКѓЪфШыЕНtheanoКЏЪ§ЪфГіВужаЃК
instance = X_test[0][None, :, :]
%timeit -n 500 f_output(instance)
500 loops, best of 3: 858 ІЬs per loop |
ШчФуЫљЪгЃЌf_outputКЏЪ§ЦНОљашвЊ858ІЬsЁЃЮвУЧЭЌбљПЩвдЮЊетИіЪЕР§ЛцжЦЪфГіВуМЄЛюжЕНсЙћЃК
pred = f_output(instance)
N = pred.shape[1]
plt.bar(range(N), pred.ravel()) |
ЩЯУцЕФДњТыНЋЛцжЦГіЯТУцЕФЭМЃК

ЪфГіВуМЄЛюжЕ
е§ШчФуЫљПДЕНЕФЃЌЪ§зжБЛШЯЮЊЪЧ7ЁЃЪТЪЕЪЧЮЊШЮКЮЭјТчВуДДНЈtheanoКЏЪ§ЖМЪЧЗЧГЃгагУЕФЃЌвђЮЊФуПЩвдДДНЈвЛИіКЏЪ§ЃЈЯёЮвУЧвдЧАвЛбљЃЉЕУЕНГэУмВуЃЈЪфГіВуЧАвЛИіЃЉЕФМЄЛюжЕЃЌШЛКѓФуПЩвдЪЙгУетаЉМЄЛюжЕзїЮЊЬиеїЃЌВЂЧвЪЙгУФуЕФЩёОЭјТчзїЮЊЬиеїЬсШЁЦїЖјВЛЪЧЗжРрЦїЁЃЯждкЃЌШУЮвУЧЮЊГэУмВуЛцжЦ256ИіМЄЛюЕЅдЊЃК
pred = f_dense(instance)
N = pred.shape[1]
plt.bar(range(N), pred.ravel()) |
ЩЯУцЕФДњТыНЋЛцжЦЯТУцЕФЭМЃК

ГэУмВуМЄЛюжЕ
ЯждкЃЌФуПЩвдЪЙгУЪфГіЕФет256ИіМЄЛюжЕзїЮЊЯпадЗжРрЦїШчLogisticЛиЙщЛђжЇГжЯђСПЛњЕФЬиеїСЫЁЃ
зюКѓЃЌЮвЯЃЭћФуЛсЯВЛЖетИіНЬГЬЁЃ |






