ǰ��:�ж�ʱ��û��дASP.NET�Ķ�����,�������Ǿ���ȱ����ʲô,�Ͼ��Լ���ASP.NET�������ж��ӵ�.
�ڱ�ϵ��������,���Ƚ�ȫ��Ľ���ASP.NET�����ܵ��Ż�,��ǰ̨����̨,�Ժ�����Ҳ����Ϊ��ҵ�һ���ֲ�����ѯ!
ϵ����������:
����������ASP.NETվ�� ��ƪ
����������ASP.NETվ��֮һ ����ҳ��Ĵ������̣�ǰ�ˣ�
����������ASP.NETվ��֮�� �Ż�HTTP����(ǰ��)
����������ASP.NETվ��֮�� ϸ�ھ����ɰ�
��ƪ
��վ�Ż���Ҫ���ǵķ���
����ASP.NET������վ��ʱ��,��������Զ��Ҫ���Ǻ�ע������,���ܲ�����ֻ�dz������ִ��ʱ����ٶȣ������漰����������Ķ�����
����ASP.NET��һ����������������������������ASP.NET��վ��������ʼһֱ���������ҳ�������������ǰ������������ÿһ�����裬�����в�ͬ�ĵ��ŷ�ʽ�ģ����ҵ��õķ���Ҳ�ܶ࣬������ֻ�dz����ģ����棬���̣߳��첽�ȡ�
��ϵ�е����¾�����������ķ������������ţ�
ǰ̨���ţ���Ҫ������ξ����ļ���http����http����ʼ������μ���js, css�����ѹ����������ݵȡ�
��̨���ţ�����ASP.NET����Ĵ������̣�����ÿһ��������Ӧ�ĵ��ŷ����������ڴ�����֯���ܹ������ݿ�IJ�������������ŵķ�����
�ǵ��ڸոտ�����վ��ʱ��һ�ᵽ������ܣ�������Ҳ������뵽�ľ��ǻ��棬���������ٷ���Best Practice��һЩ�ĵ���Ҳ�ǽ��飺��㻺��(�����ݴ洢�㣬DAL,BLL,UI�ȶ�Ҫ����)��Ȼ������վ�о͡������ؿ�����������ȷʵ�������⡣
�����һ���������Ż�������ݿ�ģ��羡�������Ӳ�ѯ��ʹ��join���ӣ��ڳ�����Ҫ��ѯ���ֶ����潨��������ȷʵ����Щ�Ǻ�ͨ�ã�Ҳ������һЩ����
���һ���һ�������ǣ����Ż����ܵ�ʱ�����ѡ���Ż���������ݿ⣬�����Ż����ݿ��һЩ����������Ч������ӵĺã��ܿ�ϧ���ǣ�����Ŀ��(�������ҿ�����һЩ��Ŀ��)�����ݿ������ֻ��һ�����ݵĴ洢�豸���ѣ����˶��ѣ�û�з��ӳ����ݿ��ǿ�����á����Ի��ǽ�������ݿ���ڲ���ѯ�ʹ洢�Ļ���Ҫ��Ϥ���Ͼ��ܶ�ʱ����ԱҲ������DBA�Ĺ������ܶ˾û����ʽ��DBA��
��������Ŀ������������ݿ��ʱ���ر��DZ��ֶε�ʱ������Ҫ��Щ���ǵģ��ܶ��˽�����ֶεij��Ȳ�Ҫ̫������Ҳ�Ǵ�ҳ����Ľ��飬����Ϊʲô����ʵ�������Ҫ����һЩ���ݿ���ڲ��洢�����ˣ������ݿ�(SQL
SERVER )�����ʱ���������ԡ�ҳ��Ϊ��С�ĵ�λ�ģ�ÿһҳ��8K�Ĵ�С��������һ�����е����ݳ���8K����ô����������ݾ�Ҫ�ּ���ҳ�汣�棬�����ڶ����ݽ��в�ѯ��ʱ��Ҫ��ҳ��ѯ�ˣ���ҳ����Ҫ�������ĵģ�������ݶ���һ��ҳ���ϣ���ô�ٶȿ϶���Щ��
���ԣ�Ҫ�Ż���վ���͵�֪���������������
���Ż���һ����վ��ʱ����äĿ��һ�Ŷ��۵ģ�һ����˵�����������
1�� ��վ�Ѿ������ˣ����������ˣ�����Ҫ�Ż���
2�� ���ڴ�ͷ����һ���µ���վ��
����ǵ�һ���������ô����Ҫ�ҳ���վ���ܵ�ƿ������ǰ̨������ĵ���̨����������һֱ�����ҳ��ij��֣���Ҫһ��������顣
����ǵڶ���������������������һ�㣬������վ������ȫ�����ǿ��ƣ������ڿ�������ƵĹ����оͿ��Բ��úܶ���Ż�ԭ�����Ż���
�Ż���һ�����Ǵ�����д������Щ�ܴ�ĸĶ����Ż�ʱһ�����ۻ��ģ��ͺñȴ�����ع�һ��������һ�����۵�Ч�������磬����ҳ��һ��ʼ��ʱ������js�ű�������������ҳ����������js�ű�����ʱ��������ֻ�Ǽĵ���һ��������ļ��������첽������ű�������ͨ��CDN����ű��ȵȷ��������ܾ������ˡ����ܵ�����Ҳ����û�д��۵ģ��еĴ��ۺ�С������ֻ�ǰѽű����������ҳ�����Ĵ��۾��ǣ�������Щ�������豸����Content
Delivery Network(CDN)���Ѿ�̬���ļ�(js,css,image)���͵��ͻ��ˡ�����˵���Ż���ҪȨ����ԡ�
��֪������Ƿ��й����������������Լ�����������ϵͳ���ܺܺõ�ʱ���Լ��Ǻ����ŵģ��෴�����ϵͳ��������ʱ�治��˵���ϵͳ���Լ����ġ�
��ƪ��ʼ�����ǾͿ�ʼ�Ż�֮�ã������ע�� ����
һ ����ҳ��Ĵ������̣�ǰ�ˣ�
��ƪ��Ҫ�������̣��ô���и�ȫ����˽⣬��һƪ�Ϳ�ʼ�ֲ������ˡ�
����ҳ��Ľ�������
ҳ��Ľ������̣�����˵�Ĺ��̲������dz�˵��ASP.NETҳ����������ڵĹ��̣��������������һ��ҳ�棬Ȼ�����������ҳ��Ĺ��̡�
�ڱ�ƪ�������У��һ��Ȳ���ҳ��Ľ������̣���ʾ�������ϲ�����Ȼ����ÿһ����������Ż��ķ����������壬��ֲ���
�������������һ��Webҳ���Ǵ�URL��ʼ�ġ�������ǹ���������
1�� ����URL��ַ���ߵ��URL��һ������
2�� ���������URL��ַ�����DNS��������URL��Ӧ��IP��ַ
3�� ����HTTP����
4�� ��ʼ��������ķ���������������ص����ݣ���������ʱ��ô�������ģ�����������ʱ�����ۣ�ֻ�Ǻ��������Ҫ���۵����⣩
5�� ����������ӷ������˷��ص����ݣ����Ұ�ҳ�����ֳ�����ͬʱҲ������������������
��������Ͼ���һ��ҳ�汻������ʵ�Ĺ��̡��������ǾͿ�ʼ����������̡�
������URL֮���������Ҫ֪�����URL��Ӧ��IP��ʲô��ֻ��֪����IP��ַ��������������İ������͵�ָ���ķ������ľ���IP�Ͷ˿ں����档
�������DNS�����������URL����Ϊ��ȷ��IP��ַ����������Ĺ�����Ҫ��ʱ��ģ��������������ʱ����ڣ�����������ܴӷ������������ص��κεĶ����ġ�������������Ĺ����ǿ����Ż��ġ����룬���ÿ�������ÿ������һ��URL����Ҫ��������ôÿ�ε�������һ���ʱ�����ģ��������ʱ�����ḷ́ܶ��������ܵ���������һ���ġ����������ġ�����Ѷ�ӦURL��IP��ַ������������ô���ٴ�������ͬ��URLʱ��������Ͳ���ȥ����������ֱ�Ӷ�ȡ���棬�����Ʊػ��һ�㡣
��ʵ������Ͳ���ϵͳ���ṩ��������֧�ֵġ�
�������IP��ַ֮����ô������������������HTTP�������������Ǿ����������������������ô�������͵ģ�
1�� �����ͨ������һ��TCP�İ���Ҫ�������������
2�� ������Ҳͨ������һ������Ӧ��ͻ��˵��������������������ӿ��ˡ�
3�� ���������һ��HTTP��GET���������������˺ܶ�Ķ����ˣ��������dz�����cookie��������headͷ��Ϣ��
������һ����������Ƿ���ȥ�ˡ�
������ȥ֮��֮����Ƿ������������ˣ��������˵ij������磬�����������ļ���һ��ASP.NET��ҳ�棬��ô�������˾Ͱ�����ͨ��IIS����ASP.NET
����ʱ��������һϵ�еĻ֮�����Ľ������Ȼ��һ����������html����ʽ���͵��ͻ��ˡ�
��ʵ���ȵ���������ľ���html����Щ�ĵ�����ν��html���ĵ������Ǵ����html���룬������ʲôͼƬ���ű���css�ȵġ�Ҳ����ҳ���html�ṹ����Ϊ��ʱ���ص�ֻ��ҳ���html�ṹ�����html�ĵ��ķ��͵��������ʱ���Ǻ̵ܶģ�һ����ռ������Ӧʱ���10%���ҡ�
����֮����ôҳ��Ļ����ĹǼܾ�����������ˣ���һ���������������ҳ��Ĺ��̣�Ҳ����һ�������ϵ��µĽ���html�ĹǼ��ˡ�
�����ʱ��html�ĵ��У�������img��ǩ����ô������ͻᷢ��HTTP�������img��Ӧ��URL��ַȥ��ȡͼƬ��Ȼ����ֳ����������html�ĵ����кܶ��ͼƬ��flash����ô������ͻ�һ����������Ȼ����֡�
��������Ҳ���о������ַ�ʽ�е����ˡ�ȷʵ���ͼƬ����Դ�ļ�������IJ���Ҳ�ǿ����Ż��ġ��ݲ�˵��ģ����ÿ��ͼƬ��Ҫ������ô��Ҫ����֮ǰ˵����Щ���裺����url����tcp���ӵȵȡ�������Ҳ��Ҫ������Դ�ģ����������ڽ������ݿ����һ��������Ҳ�Ǿ����ܵ��ٿ����ݿ����ӣ��������ӳ��е����ӡ�����һ����tcp����Ҳ�ǿ������õġ���������Ҳ�����⣺�������ͼƬ���ǵ�url��ַ���£�
����
<img src="q1.gif" height="16" width="16" />
<img src="q2.gif" height="16" width="16" />
<img src="q3.gif" height="16" width="16" />
<img src="q4.gif" height="16" width="16" />
<img src="q5.gif" height="16" width="16" />
<img src="q6.gif" height="16" width="16" />
<img src="q7.gif" height="16" width="16" />
<img src="q8.gif" height="16" width="16" />
<img src="q9.gif" height="16" width="16" />
<img src="q10.gif" height="16" width="16" />
������ЩͼƬ��ʱ����������ͼ��

������ȿ���������Ļ��ߵIJ��֣�������߾ʹ���������������ӣ����ߵĺ�벿��Ϊ��ɫ���ͱ�ʾ�����������html���ĵ���
������ĵڶ������߾ͱ�ʾ��һ��ͼƬ�Ѿ������ˣ���ʱ�������ͼƬʹ�û���֮ǰ��һ��tcp�����ӡ�
����ڿ����������ߣ�ǰ�����ǻ�ɫ�ģ���ʾ����ڶ���ͼƬ��ʱ���ֿ���һ��tcp�����ӣ������ߵĺ�벿��Ϊ��ɫ����ʾͼƬ�Ѿ������ˡ�
ʣ�µ�Ҫ�����һЩͼƬ��ʹ����һ��tcp���ӡ�
ȷʵ��tcp������ʱ��ֵı�ʹ���ˣ�����ͼƬ���ص��ٶ�ȷʵ���ˣ���ͼ�п�����ͼƬ��һ������˳������������ġ�����ҳ�����Ӧʱ������֪��
���������һ�ַ�ʽ���磺
���Կ�������ʱ���ˣ�����ͼƬ�ļ������Dz������������ģ���ȶ��ԾͿ���ˡ�
��ʵ�����һ��Ȩ��������ˡ�
ʵ���������Ҳ����������һЩ�Ż���ʽ�ģ����绺��ͼƬ���ű��ȡ����߲��ò�������ͼƬ�ķ�ʽ��̸���������أ�������ͼ�������ģ��Ʊػ����ĸ����������Դ��
������Ҫ��ҳ��Ĺ��̽����˳������������ǵĴ���и�����İ��գ���һƪ���ǾͿ�ʼ���Ż��������ע��Ҳϣ����Ҷ���������ͷ�������л���˰���
����
�� �Ż�HTTP����(ǰ��)
��һƪ������Ҫ����������һ��ҳ��Ĺ���,ͬʱҲ���������������е�һЩ�Ż���,��ƪ�Ϳ�ʼϸ��ҳ���������̲�������Ż��ķ���.ͬʱ,����ƪ������,��������Ҳ�����һЩ����,�ڱ�ƪ��Ҳ����Щ��������˻ش�!
HTTP������Ż�
��һ����ҳ�����������,��ʵ����ҳ���html�ṹ(����ҳ�����Щhtml�Ǽ�)�����ʱ���Ǻ̵ܶ�,һ����ռ����ҳ�������ʱ���10%-20%.��ҳ����ص������ʱ��ʵ���Ͼ����ڼ���ҳ���е���Щflash,ͼƬ,�ű�����Դ.
һֱ�����е���Դ����֮��,����ҳ�����������չ����������ǰ.
����,���Ǿʹ�һ��ҳ�濪ʼ����:
1 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
2 <html xmlns="http://www.w3.org/1999/xhtml">
3 <head>
4 <title>��,������</title>
5
6 <script type="text/javascript" src="../demo.js">
7 </script>
8
9 </head>
10 <body>
11 <div>
12 <img src="../images/1.gif" />
13 <img src="../images/2.gif" />
14 <img src="http://yanyangtian.cnblogs.com/image/3.gif" />
15 <img src="http://yanyangtian.cnblogs.com/image/4.gif" />
16 <img src="http://yanyangtian.cnblogs.com/image/5.gif" />
17 <img src="http://yanyangtian.cnblogs.com/image/6.gif" />
18 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
19 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
20 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
21 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
22 </div>
23 </body>
24 </html>
25
���������������������ҳ��,�ͻ��˵�����������������ݾ���html�Ǽ�,��:
1 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
2 <html xmlns="http://www.w3.org/1999/xhtml">
3 <head>
4 <title>��,������</title>
5
6 <script type="text/javascript" src="../demo.js">
7 </script>
8
9 </head>
10 <body>
11 <div>
12 <img src="../images/1.gif" />
13 <img src="../images/2.gif" />
14 <img src="http://yanyangtian.cnblogs.com/image/3.gif" />
15 <img src="http://yanyangtian.cnblogs.com/image/4.gif" />
16 <img src="http://yanyangtian.cnblogs.com/image/5.gif" />
17 <img src="http://yanyangtian.cnblogs.com/image/6.gif" />
18 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
19 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
20 <img src="http://yanyangtian.cnblogs.com/image/7.gif" />
21 <img src="http://yanyangtian.cnblogs.com/image/8.gif" />
22 </div>
23 </body>
24 </html>
25
�ڴ�֮ǰ,�������ռ�һ��ҳ����ص�С֪ʶ:
��ҳ���html�Ǽ�������֮��,������Ϳ�ʼ����ҳ���б�ǩ,���ϵ��¿�ʼ����.
������head��ǩ�Ľ���,���������head����Ҫ���õ�js�ű�,��ô�������ʱ�Ϳ�ʼ����ű�,��ʱ����ҳ��Ľ������̾�ͣ������,һֱ��js�������.
֮��ҳ��������½���,�����body��ǩ,�����body����img��ǩ,��ô������ͻ�����img��src��Ӧ����Դ,����ж��img��ǩ,��ô�������һ�����Ľ���,����������js�����ȴ���,�������img��url��ַ��ͬһ����ַ,��ô������ͻ��ֵ���������Ѿ���tcp����˳���ȥһ����������ͼƬ,��������е�img��url��ַ��ͬ,��ô�����������tcp����,����http����.
ע��֮ǰ����js������:������Ҫjs,�������һֱ�ȴ�,���ڽ��������html��ǩ
���ǽ�����img��ʱ��,���ܴ�ʱ��Ҫ����ͼƬ,����ҳ��Ľ������̻��ǻ������ȥ��,Ȼ������Ƿ����µ�tcp���Ӽ�����Դ.
��ҿ��ܾ������֮ǰ�Ĵ���Ƭ��һ��,ȷʵ������һ����,����,���ʼ��ʱ��,���͵�������е�ֻ����Щhtml�Ĵ���,�κε�js�ű���ͼƬ��û�з�����.
��html���뵽���������,��ô������Ϳ�ʼһ�����Ľ�����Щ������,ֻҪ��������Ҫ���ص���Դ,������������������http����,�����������Դ.
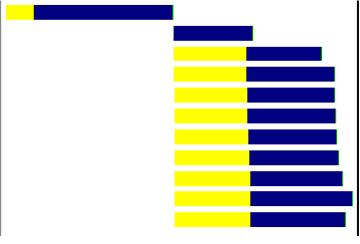
����ҳ��ļ���ʱ��ͼ����:

��Ҵ�ͼ�п��Կ���:
��һ�����з�Ϊһ���ɫ��һ����ɫ,��ʵ��ɫ�IJ��־ʹ����˴�һ��tcp���ӻ���ʱ��,���������ɫ�IJ��־�����������html�Ǽ��ĵ���ʱ��.���Կ���,����html�Ǽܵ�ʱ���Ǻ̵ܶ�.������ɫ���߾ͱ�ʾ��ͼƬ,�ű���Դ����������ʱ��.
����Ȼ,����ҳ�����������ʱ��ͺܳ���.��Ϊҳ��ļ��ؼ�����˳�������,ʱ�����������Դ����ʱ����ܺ�.
�������ǰ������ҳ������Ϊ����:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>��,������</title>
<script type="text/javascript" src="../demo.js">
</script>
</head>
<body>
<div>
<img src="http://demo1.com/images/1.gif" />
<img src="http://demo1.com/images/2.gif" />
<img src="http://demo2.com/image/3.gif" />
<img src="http://demo2.com/image/4.gif" />
<img src="http://demo3.com/image/5.gif" />
<img src="http://demo3/image/6.gif" />
<img src="http://demo4.com/image/7.gif" />
<img src="http://demo4.com/image/8.gif" />
<img src="http://yanyangtian.cnblogs.com/image/7.gif" />
<img src="http://yanyangtian.cnblogs.com/image/8.gif" />
</div>
</body>
</html>
��
������������ҳ��ļ���ʱ��ͼ
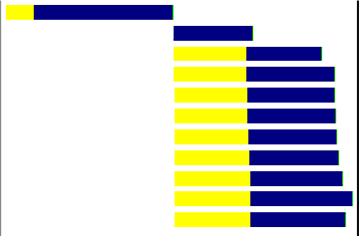
�������ν�ġ����С�������.
�Ƚ�һ�����δ���IJ�ͬ:��ʵ����img��src��������:
��һ��ҳ��Ĵ���:img��src���Զ���ָ��һ��������.
�ڶ���ҳ��Ĵ���:img��src����ָ���˲�ͬ������
�������Ľ����ʲô?
����ע��Ƚ�img��src�IJ�ͬ.
����֮ǰ,��������һ��С�ij�ʶ(����ƪ������Ҳ���):
��ҳ�������������������Դ��ʱ��,���������Ѿ��ڿͻ��˺ͷ�����֮ǰ����һ��tcp����,�����������ԴҲ�ڿ������ӵķ�������,��ô�Ժ���Դ������ͻ��ֵ������������ȥ��ȡ��Դ.
����Ҳ���ǵ�һ��ʱ��ͼ������.
��������ͼƬ�ֱ�λ�ڲ�ͬ�ķ�������վ,�����Ǹ�����ķ�������վ�ж������,��ô��Ϊ������ͻ�Ϊÿһ������ȥ��һ��tcp����,����http����,����,�������ͬʱ���˶�tcp����,��Ҳ�ǵڶ���ʱ��ͼ������.
��Ȼ˵���м���,ȷʵʹ��ҳ���������˲���,����Ҳ����ÿһ��ͼƬ������������Դ��ȥ��һ����ͬ������,��֮ǰ�ĵڶ�����������ͼƬ������,Ҳ��������ͼƬ����һ��tcp����.���ÿ��ͼƬ��ȥ��һ������,����������Ϳ��˺ܶ������,Ҳ�Ǻܷ���Դ��,��������������ܻᡱ������.������ʱ�������ص�Ӱ������.
����,������ҪȨ���.
����������Ż���ʽ,����������ͼƬ�Ż��ļ��ط�ʽ.��Ҫ��ͨ������http������ﵽ�Ż�
��Ҷ�֪����վ��һ��menu�˵�,��Щ�˵�������ͼƬ��������.��

��������ͼƬһ��������,�Ʊ�Ӱ���ٶ�,������������,�е�ò���ʧ.����ͼƬҲ���Ǻܴ�,��ô��һ�ΰ�����menu��Ҫ��ͼƬ��Ϊ����ͼƬ,һ�μ���,Ȼ��ͨ��map�ķ�ʽ,���Ƶ��ͼƬ��λ�����ﵽ������Ч��.
����һ���������:���ͼƬ������,���ܵ���ˡ���ҳ��ͼƬ,Ȼ��ȴ�����ˡ�������ҳ����.
�� ϸ�ھ����ɰ�
���������
���ȣ�����һ�¹��µı�������ϣ��������ĵĹ��¶��꣩
����վ�У���ҳ�еķ�ҳ�ؼ�ÿ����ʾ10�����ݣ�ÿ�ε����һҳ�����ٴ�ȥȡ��һ��10�����ݡ����ڷ�ҳ�ķ����������������кܶ࣬��������Ҷ�֪����
�����������ģ����û��������ݵ�ʱ���ǵ����û��IJ�������վ�ķ��������һ��һ��ȡ��500�����ݣ�Ȼ������ݷ��ڻ����У�Ҳ����˵����ȡ����50ҳ�����ݣ����ڻ����У�����������Ժ��û������һҳ����49ҳ��ʱ��ֱ�Ӵӻ����������ݡ�
����ͼ��

��һ�����ݿ飺
���ü�ֵ�Ե���ʽ���ֵ䱣��
����û�������49ҳ�Ժ���ô���ٴδ����ݿ���ȡ����һ�����ݿ飨����501��1000���ݣ���Ȼ�������ڴ��о�����1000�����ݡ�
���ڻ����ã�����ʲôʧЧ��ʧЧ����ô���������ݲ�̸�ۡ�����վ�����ֻ�����������еĺܺã���
�������£�
List<Product> products=GetDataFromCacheOrDatabase(condition,pageIndex,count��.);
�������˼��������ӻ����������ݣ����������û�ж�Ӧ�����ݣ���ô���ȴ����ݿ�����500�����ݣ�Ȼ����ڻ����У����10�����ݡ�
��������ΪijЩ���ܵ���Ҫ����Ҫ���ص�ǰҳ��ǰ6ҳ���ݺͺ�6ҳ�����ݣ����磺�����ǰҳ�ǵ�12ҳ����ô��Ҫ����12ҳ֮ǰ6ҳProduct��Ҳ���ǵ�6,7,8,9,10,11ҳ�����ݣ����͵�12ҳ���ҳ��Product����13,14,15,16,17,18ҳ�����ݣ���
���£�

��Ȼ�������ǰҳ�ǵ�5ҳ����ô�Ͱ�֮ǰ����5ҳ�����ݶ����أ������ټ��ϵ�5ҳ֮���6ҳ���ݡ�
����Ϳ����漰������ȡ���ݣ��磺
�����ǰҳ�ǵ�48ҳ��ʱ����ô����ǰ6ҳ������û��ʲô����ģ���ô��6ҳ�����ݾͲ����ˣ���Ϊ49,40Ҳ�����ݿ��Դӻ�������ݿ���ȡ��������51,52,53,54ҳ�����ݣ�����Ҫ�ٴδ����ݿ��ж�ȡ��Ȼ���ٴλ��棨�������û�б����棩��

����ڻ����е��������£�

Ȼ����÷�������α�룩
List<Product> products=GetDataFromCacheOrDatabase(condition,42, 126��.);
���洫����Ǵӵ�42ҳ��ʼ�����ݣ�Ҳ���ǵ�48ҳ��ǰ6ҳ�ͺ�6ҳ�����ݡ�
����������ڲ�ʵ���������ģ�
1�� ���ȴӵ�һ�����ݿ���ȡ��42ҳ��50ҳ������
ȡ�����ݺ���һ��List<Product> firstProductList;
2�� �ӵڶ������ݿ���ȡ����51ҳ��54ҳ������ڶ������ݿ��ڻ��治���ڣ���ȥ���ݿ���ȡ501-1000����Ȼ���ٷ��ڻ���ĵڶ������ݿ��У���
�����ڵڶ���List<Product> secondProductList
3. Ȼ�������list�ϲ������ؽ��������
secondProductList.Foreach(u=>firstProductList.Add(u));
������ʵ�־������������������У�Ҳ�Ƚϵĺ��������Ǿ�����Ϊ����������Ӷ����·������ڴ������
������뿴��ʲôԭ��
ϸ�ڵ���Ҫ��
��ʵ��������ݲ��Ǻܶ࣬�Dz������÷������ڴ�����ģ����Ƿ��������dz�����out of memory���쳣��֮ǰһֱ�ܵĺܺã����Ǹ��˴���֮��ų�������ġ�
��ʵ���������һ��������Ĵ�������ģ��������͡�
������������£�
�����Ǵӵ�һ�����ݿ���ȡ�����ݣ�Ȼ����
List<Product> firstProductList ����ָ��ȡ��������
Ȼ��ӵڶ������ݿ���ȡ�����ݣ���
List<Product> secondProductListָ�����ݵ�����
����ͼ
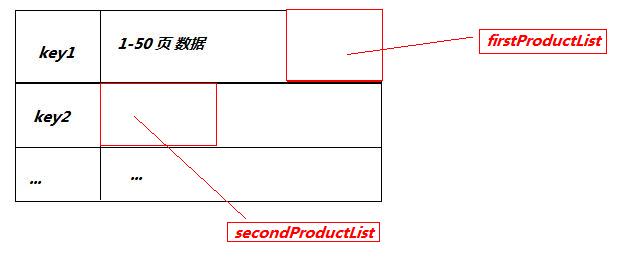
�ڵ������в���
secondProductList.Foreach(u=>firstProductList.Add(u));
��secondProductList�е����ݼ��뵽firstProductList�У�����Ϊ���������ͣ���ʵʵ�ʲ����Ľ���ǣ����ϵ��ڸı��һ�����ݿ��е����ݣ�ʹ�õ�һ�����ݿ��е������ı�ࡣ
���ڵ�ǰҳ��48ҳ����������IJ�������ʹ��һ�����ݿ��е�����������60����
����û��ٴη�ҳ������49ҳ����ô��һ�����ݿ��е�������������60��
�������ƣ�������˷������ڴ�IJ��㣬��ʹ�����������ˡ�ԭ���ġ�������----����ȴ��Ϊ��������ס�
��ʵ�������Ľ����ֻҪ�ı�һ���Ĵ�������ˣ�
List<Product> firstProductList��
List<Product> secondProductList��
Ȼ��
List<Product> resultProductList=new List<Product>������Ȼ��ֱ��firstProductList��secondProductList���������뵽resultProductList�����ˡ�
����ô��
һ��С��ϸ�ڣ������˴�����⡣
��Ҫ����ÿһ��ϸ�ڡ���Ҫ��û�бȽϵ�ѭ���Ȳ�����һ��Ҫ���Ӵ��룬�ع����롣
�����д���������������ô�࣬ϣ���Դ����һ���İ�����
��ȨΪС��Ͳ������У���ӭת�أ�ת����������������ߡ�
http://www.cnblogs.com/yanyangtian
| 

