| 摘要:本文讨论了如何使用C#2.0实现抓取网络资源的网络蜘蛛。使用这个程序,可以通过一个入口网址(如http://www.comprg.com.cn)来扫描整个互联网的网址,并将这些扫描到的网址所指向的网络资源下载到本地。然后可以利用其他的分析工具对这些网络资源做进一步地分析,如提取关键词、分类索引等。也可以将这些网络资源作为数据源来实现象Google一样的搜索引擎。
关键词:C#2.0,Html,网络蜘蛛, 键树,正则表达式
一、引言
在最近几年,以Google为首的搜索引擎越来越引起人们的关注。由于在Google出现之前,很多提供搜索服务的公司都是使用人工从网络上搜集信息,并将这些信息分类汇总后作为搜索引擎的数据源。如yahoo公司一开始就是通过数千人不停地从网上搜集供查询的信息。这样做虽然信息的分类会很人性化,也比较准确,但是随着互联网信息爆炸式地增长,通过人工的方式来搜集信息已经不可能满足网民对信息的需求了。然而,这一切随着Google的出现而得到了彻底改变。Google一反常规的做法,通过程序7*24地从网上不停地获取网络资源,然后通过一些智能算法分析这些被下载到本地的网络资源,最后将这些分析后的数据进行索引后就形成了一套完整的基本上不需要人工干预的搜索引擎。使用这种模式的搜索引擎甚至可以在几天之内就可获取Internet中的所有信息,同时也节省了大量的资金和时间成本。而这种搜索引擎最重要的组成部分之一就是为搜索引擎提供数据源的网络蜘蛛。也就是说,实现网络蜘蛛是实现搜索引擎的第一步,也是最重要的一步。
二、网络蜘蛛的基本实现思想和实现步骤
网络蜘蛛的主要作用是从Internet上不停地下载网络资源。它的基本实现思想就是通过一个或多个入口网址来获取更多的URL,然后通过对这些URL所指向的网络资源下载并分析后,再获得这些网络资源中包含的URL,以此类推,直到再没有可下的URL为止。下面是用程序实现网络蜘蛛的具体步骤。
1. 指定一个(或多个)入口网址(如http://www.comprg.com.cn),并将这个网址加入到下载队列中(这时下载队列中只有一个或多个入口网址)。
2. 负责下载网络资源的线程从下载队列中取得一个或多个URL,并将这些URL所指向的网络资源下载到本地(在下载之前,一般应该判断一下这个URL是否已经被下载过,如果被下载过,则忽略这个URL)。如果下载队列中没有URL,并且所有的下载线程都处于休眠状态,说明已经下载完了由入口网址所引出的所有网络资源。这时网络蜘蛛会提示下载完成,并停止下载。
3. 分析这些下载到本地的未分析过的网络资源(一般为html代码),并获得其中的URL(如标签<a>中href属性的值)。
4. 将第3步获得的URL加入到下载队列中。并重新执行第2步。
三、实现数据的输入输出
从实现网络蜘蛛的步骤中我们可以看出,下载队列的读、写URL的操作一直贯穿于整个系统中。虽然这个下载队列可以用.Queue类实现,但是各位读者要清楚地知道,在互联网上的URL可不是几十个、几百个这么少。而是以千万计的。这么多的URL显然不能保存在内存中的Queue对象中。因此,我们需要将它保存在容量更大的存储空间中,这就是硬盘。
本文采用了一个普通的文本文件来保存需要下载和分析的URL(这个文本文件也就是下载队列)。存储格式是每一行为一个URL。既然将URL都保存在了文本文件中,就需要对这个文本文件进行读写。因此,在本节实现了一个用于操作这个文本文件的FileIO类。
在实现FileIO类之前,先来说一下要如何操作这个文本文件。既然要将这个文件作为队列使用,那么就需要对这个文件进行追加行和从文件开始部分读取数据操作。让我们首先来实现向文件中追加行操作。实现代码如下:
向文件中追加行的实现代码
// 这两个变量为类全局变量
private FileStream fsw;
private StreamWriter sw;
// 创建用于向文件中追加行的文件流和StreamWriter对象
public void OpenWriteFile(string file)
{
if (!File.Exists(file)) // 如果文件不存在,先创建这个文件
File.Create(file).Close();
// 以追加模式打开这个文件
fsw = new FileStream(file, FileMode.Append ,FileAccess.Write, FileShare.ReadWrite);
// 根据创建的FileStream对象来创建StreamWriter对象
sw = new StreamWriter(fsw);
}
// 关闭写文件流
public void CloseWriteFile()
{
if (fsr != null)
fsw.Close();
}
// 向文件中追加一行字符串
public void WriteLine(string s)
{
sw.WriteLine(s);
sw.Flush(); // 刷新写入缓冲区,使这一行对于读文件流可见
}
在实现上述的代码时要注意,在创建FileStream对象时,必须使用FileShare.ReadWrite,否则这个文件无法被两个或两个以上的Stream打开,也就是说下面要介绍的读文件流将无法操作这个被写文件流打开的文件。从文件中读取行的实现代码如下:
从文件中读取行的实现代码
// 这两个变量为类全局变量
private FileStream fsr;
private StreamReader sr;
// 创建用于读取文件行的文件流和StreamWriter对象
public void OpenReadFile(string file)
{
if (!File.Exists(file)) // 如果文件不存在,首先创建这个文件
File.Create(file).Close();
fsr = new FileStream(file, FileMode.OpenOrCreate, FileAccess.Read,
FileShare.ReadWrite);
sr = new StreamReader(fsr);
}
// 关闭读文件流
public void CloseReadFile()
{
if(fsr != null)
fsr.Close();
}
// 从文件中读取一行
public string ReadLine()
{
if(sr.EndOfStream) // 如果文件流指针已经指向文件尾部,返回null
return null;
return sr.ReadLine();
}
除了上述的读写文件的代码外,FileIO还提供了一个IsEof方法用来判断文件流指针是否位于文件尾部。IsEof方法的实现代码如下如下:
IsEof方法的实现代码
// 用于判断文件流指针是否位于文件尾部
public bool IsEof()
{
return sr.EndOfStream;
}
FileIO类不仅仅用于对下载队列的读写。在后面我们还会讲到,网络蜘蛛通过多线程下载网络资源时,每一个线程将自己下载的网络资源保存在属于自己的一个目录中。每个这样的目录都有一个index.txt文件,这个文件保存了当前目录的网络资源的URL。向index.txt文件中追加URL也用到了FileIO(index.txt不需要读取,只需要不断地追加行)。
四、线程类的实现
要想使网络蜘蛛在有限的硬件环境下尽可能地提高下载速度。最廉价和快捷的方法就是使用多线程。在.net framework2.0中提供了丰富的线程功能。其中的核心线程类是Thread。一般可使用如下的代码创建并运行一个线程:
在C#中使用线程的演示代码
private void fun()
{
// 线程要执行的代码
}
public void testThread()
{
Thread thread;
thread = new Thread(fun); // 创建一个Thread对象,并将fun设为线程运行的方法
thread.Start(); // 运行一个线程
}
虽然上面的代码比较简单地创建并运行了一个线程,但是这段代码看起来仍然不够透明,也就是客户端在调用线程时仍然需要显式地使用Thread类。下面我们来实现一个用于创建线程的MyThread类。C#中的任何类只需要继承这个类,就可以自动变成一个线程类。MyThread类的代码如下:
MyThread类的实现代码
// 任何C#类继承MyThread后,就会自动变成一个线程类
class MyThread
{
private Thread thread;
public MyThread()
{
thread = new Thread(run); // 创建Thread对象
}
// 用于运行线程代码的方法,MyThread的子类必须覆盖这个方法
public virtual void run()
{
}
public void start()
{
thread.Start(); // 开始运行线程,也就是开始执行run方法
}
// 使当前线程休眠millisecondsTimeout毫秒
public void sleep(int millisecondsTimeout)
{
Thread.Sleep(millisecondsTimeout);
}
}
我们可参照如下的代码使用MyThread类:
测试的ThreadClass类的代码
class ThreadClass : MyThread
{
public override void run()
{
// 要执行的线程代码
}
}
// 测试ThreadClass类
public void testThreadClass()
{
ThreadClass tc = new ThreadClass();
tc.start(); // 开始运行线程,也就是执行run方法
}
各位读者可以看看,上面的代码是不是要比直接使用Thread类更方便、直观、易用,还有些面向对象的感觉!
五、用多线程下载网络资源
一般来说,网络蜘蛛都是使用多线程来下载网络资源的。至于如何使用多线程来下载,各个版本的网络蜘蛛不尽相同。为了方便和容易理解,本文所讨论的网络蜘蛛采用了每一个线程负责将网络资源下载到一个属于自己的目录中,也就是说,每一个线程对应一个目录。而在当前目录中下载的网络资源达到一定的数目后(如5000),这个线程就会再建立一个新目录,并从0开始计数继续下载网络资源。在本节中将介绍一个用于下载网络资源的线程类DownLoadThread。这个类的主要功能就是从下载队列中获得一定数量的URL,并进行下载和分析。在DownLoadThread类中涉及到很多其他重要的类,这些类将在后面的部分介绍。在这里我们先看一下DownLoadThread类的实现代码。
DownLoadThread类的代码
class DownLoadThread : MyThread
{
// ParseResource类用于下载和分析网络资源
private ParseResource pr = new ParseResource();
private int currentCount = 0; // 当前下载目录中的网页数
// 用于向每个线程目录中的index.txt中写当前目录的URL
private FileIO fileIO = new FileIO();
private string path; // 当前的下载目录(后面带“\")
private string[] patterns; // 线程不下载符合patterns中的正则表达式的URL
public bool stop = false; // stop为true,线程退出
public int threadID; // 当前线程的threadID,用于区分其他的线程
public DownLoadThread(string[] patterns)
{
pr.findUrl += findUrl; // 为findUrl事件赋一个方法
this.patterns = patterns;
}
// 这是一个事件方法,每获得一个URL时发生
private void findUrl(string url)
{
Common.addUrl(url); // 将获得的URL加到下载队列中
}
private void openFile() // 打开下载目录中的index.txt文件
{
fileIO.CloseWriteFile();
fileIO.OpenWriteFile(path + Common.indexFile);
}
public override void run() // 线程运行方法
{
LinkedList<string> urls = new LinkedList<string>();
path = Common.getDir(); // 获得下载目录
openFile();
while (!stop)
{
// 当下载队列中没有URL时,进行循环等待
while (!stop && urls.Count == 0)
{
Common.getUrls(urls, 20); // 从下载队列中获得20个url
if (urls.Count == 0) // 如果未获得url
{
// 通知系统当前线程已处于等待状态,
// 如果所有的线程都处于等待状态,
// 说明所有的网络资源都被下载完了
Common.threadWait(threadID);
sleep(5000); // 当前线程休眠5秒
}
}
StringBuilder sb = new StringBuilder();
foreach (string url in urls) // 循环对这20个url进行循环下载分析
{
if (stop) break;
// 如果当前下载目录的资源文件数大于等于最大文件数目时,
// 建立一个新目录,并继续下载
if (currentCount >= Common.maxCount)
{
path = Common.getDir();
openFile();
currentCount = 0; // 目录
}
// 每个下载资源文件名使用5位的顺序号保存(没有扩展名),
// 如00001、00002。下面的语句是格式化文件名
string s = string.Format("{0:D5}", currentCount + 1);
sb.Remove(0, sb.Length);
sb.Append(s);
sb.Append(":");
sb.Append(url);
try
{
// 下载和分析当前的url
pr.parse(url, path + s, patterns);
Common.Count++;
// 将当前的url写入index.txt
fileIO.WriteLine(sb.ToString());
currentCount++;
}
catch (Exception e)
{
}
}
urls.Clear();
}
}
}
}
六、分析网络资源
对下载的网络资源进行分析是网络蜘蛛中最重要的功能之一。这里网络资源主要指的是html代码中<a>标签的href属性值。状态和状态之间会根据从html文件中读入的字符进行切换。下面是状态之间切换的描述。
状态0:读入'<'字符后切换到状态1,读入其他的字符,状态不变。
状态1:读入'a'或'A',切换到状态2,读入其他的字符,切换到状态0。
状态2:读入空格或制表符(\t),切换到状态3,读入其他的字符,切换到状态0。
状态3:读入'>',成功获得一个<a>,读入其他的字符,状态不变。为了更容易说明问题。在本文给出的网络蜘蛛中只提取了html代码中<a>中的href属性中的url。本文中所采用的分析方法是分步进行提取href。首先将html代码中的<a>标签整个提出来。不包括</a>和前面的字符,如<a
href="http://www.comprg.com.cn">comprg</a>中只提取<a
href="http://www.comprg.com.cn">,而comprg</a>将被忽略,因为这里并没有url。
本文使用了一个状态机来的提取<a>,这个状态机分为五个状态(0 至 4)。第一个状态是初始态,最后一个状态为终止态,如果到达最后一个状态,说明已经成功获得了一个<a>
状态机如图1所示。
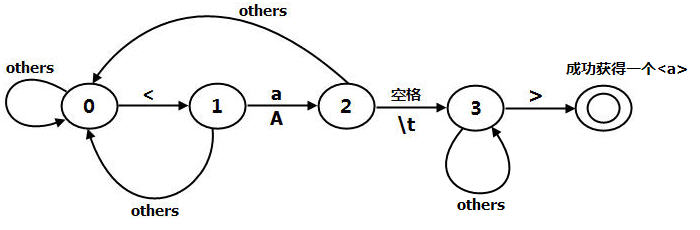
图1
最后一个双环的状态是最终态。下面让我们来看看获得<a>的实现代码。
getA方法的实现
// 获得html中的<a>
private void getA()
{
char[] buffer = new char[1024];
int state = 0;
String a = "";
while (!sr.EndOfStream)
{
int n = sr.Read(buffer, 0, buffer.Length);
for (int i = 0; i < n; i++)
{
switch (state)
{
case 0: // 状态0
if (buffer[i] == '<') // 读入的是'<'
{
a += buffer[i];
state = 1; // 切换到状态1
}
break;
case 1: // 状态1
if (buffer[i] == 'a' || buffer[i] == 'A') // 读入是'a'或'A'
{
a += buffer[i];
state = 2; // 切换到状态2
}
else
{
a = "";
state = 0; // 切换到状态0
}
break;
case 2: // 状态2
if (buffer[i] == ' ' || buffer[i] == '\t') // 读入的是空格或'\t'
{
a += buffer[i];
state = 3;
}
else
{
a = "";
state = 0; // 切换到状态0
}
break;
case 3: // 状态3
if (buffer[i] == '>') // 读入的是'>',已经成功获得一个<a>
{
a += buffer[i];
try
{
string url = getUrl(getHref(a)); // 获得<a>中的href属性的值
if (url != null)
{
if (findUrl != null)
findUrl(url); // 引发发现url的事件
}
}
catch (Exception e)
{
}
state = 0; // 在获得一个<a>后,重新切换到状态0
}
else
a += buffer[i];
break;
}
}
}
}
在getA方法中除了切换到状态0外,其他的状态切换都将已经读入的字符赋给String变量a,如果最后发现变量a中的字符串不可能是<a>后,就将a清空,并切换到状态0后重新读入字符。
在getA方法中使用了一个重要的方法getHref来从<a>中获得href部分。getHref方法的实现如下:
getHref方法的实现
// 从<a>中获得Href
private String getHref(string a)
{
try
{
string p = @"href\s*=\s*('[^']*'|""[^""]*""|\S+\s+)";
// 获得Href的正则表达式
MatchCollection matches = Regex.Matches(a, p,
RegexOptions.IgnoreCase |
RegexOptions.ExplicitCapture);
foreach (Match nextMatch in matches)
{
return nextMatch.Value; // 返回href
}
return null;
}
catch (Exception e)
{
throw e;
}
}
在getHref方法中使用了正则表达式从<a>中获得href。在<a>中正确的href属性格式有三种情况,这三种情况的主要区别是url两边的符号,如单引号、双引号或没有符号。这三种情况如下所示:
情况1: <a href = "http://www.comprg.com.cn" > comprg</a>
情况2: <a href = 'http://www.comprg.com.cn' > comprg</a>
情况3: <a href = http://www.comprg.com.cn > comprg</a>
getHref方法中的p存储了用于过滤这三种情况的href,也就是说,使用正则表达式可以获得上述三种情况的href如下:
从情况1获得得的href:href = "http://www.comprg.com.cn"
从情况2获得得的href:href = 'http://www.comprg.com.cn'
从情况3获得得的href:href = http://www.comprg.com.cn
在获得上述的href后,需要将url提出来。这个功能由getUrl完成,这个方法的实现代码如下:
getUrl方法的实现
// 从href中提取url
private String getUrl(string href)
{
try
{
if (href == null) return href;
int n = href.IndexOf('='); // 查找'='位置
String s = href.Substring(n + 1);
int begin = 0, end = 0;
string sign = "";
if (s.Contains("\"")) // 第一种情况
sign = "\"";
else if (s.Contains("'")) // 第二种情况
sign = "'";
else // 第三种情况
return getFullUrl(s.Trim());
begin = s.IndexOf(sign);
end = s.LastIndexOf(sign);
return getFullUrl(s.Substring(begin + 1, end - begin - 1).Trim());
}
catch (Exception e)
{
throw e;
}
}
在获得url时有一点应该注意。有的url使用的是相对路径,也就是没有“http://host”部分,但将url保存时需要保存它们的完整路径。这就需要根据相对路径获得它们的完整路径。这个功能由getFullUrl方法完成。这个方法的实现代码如下:
getFullUrl方法的实现代码
// 将相对路径变为绝对路径
private String getFullUrl(string url)
{
try
{
if (url == null) return url;
if (processPattern(url)) return null; // 过滤不想下载的url
// 如果url前有http://或https://,为绝对路径,按原样返回
if (url.ToLower().StartsWith("http://") || url.ToLower().StartsWith("https://"))
return url;
Uri parentUri = new Uri(parentUrl);
string port = "";
if (!parentUri.IsDefaultPort)
port = ":" + parentUri.Port.ToString();
if (url.StartsWith("/")) // url以"/"开头,直接放在host后面
return parentUri.Scheme + "://" + parentUri.Host + port
+ url;
else // url不以"/"开头,放在url的路径后面
{
string s = "";
s = parentUri.LocalPath.Substring(0, parentUri.LocalPath.LastIndexOf("/"));
return parentUri.Scheme + "://" + parentUri.Host + port
+ s + "/" + url;
}
}
catch (Exception e)
{
throw e;
}
}
在ParseResource中还提供了一个功能就是通过正则表达式过滤不想下载的url,这个功能将通过processPattern方法完成。实现代码如下:
processPattern方法的实现代码
// 如果返回true,表示url符合pattern,否则,不符合模式
private bool processPattern(string url)
{
foreach (string p in patterns)
{
if (Regex.IsMatch(url, p, RegexOptions.IgnoreCase | RegexOptions.ExplicitCapture)
&& !p.Equals(""))
return true;
}
return false;
}
ParseResource类在分析html代码之前,先将html下载到本地的线程目录中,再通过FileStream打开并读取待分析的数据。ParseResource类其他的实现代码请读者参阅本文提供的源代码。
七、键树的实现
在获取Url的过程中,难免重复获得一些Url。这些重复的Url将大大增加网络蜘蛛的下载时间,以及会导致其他的分析工具重复分析同一个html。因此,就需要对过滤出重复的Url,也就是说,要使网络蜘蛛下载的Url都是唯一的。达到这个目的的最简单的方法就是将已经下载过的Url保存到一个集合中,然后在下载新的Url之前,在这个集合中查找这个新的Url是否被下载过,如果下载过,就忽略这个Url。
这个功能从表面上看非常简单,但由于我们处理的是成千上万的Url,要是将这些Url简单地保存在类似List一样的集合中,不仅会占用大量的内存空间,而且当Url非常多时,如一百万。这时每下载一个Url,就要从这一百万的Url中查找这个待下载的Url是否存在。虽然可以使用某些查找算法(如折半查找)来处理,但当数据量非常大时,任何查找算法的效率都会大打折扣。因此,必须要设计一种新的存储结构来完成这个工作。这个新的数据存储结构需要具有两个特性:
1. 尽可能地减少存储Url所使用的内存。
2. 查找Url的速度尽可能地快(最好的可能是查找速度和Url的数量无关)。
下面先来完成第一个特性。一般一个Url都比较长,如平均每个Url有50个字符。如果有很多Url,每个Url占50个字符,一百万个Url就是会占用50M的存储空间。而我们保存Url的目的只有一个,就是查找某一个Url是否存在。因此,只需要将Url的Hashcode保存起来即可。由于Hashcode为Int类型,因此,Hashcode要比一个Url字符串使用更少的存储空间。
对于第二个特性,我们可以使用数据结构中的键树来解决。假设有一个数是4532。首先将其转换为字符串。然后每个键树节点有10个(0至9)。这样4532的存储结构如图2所示:
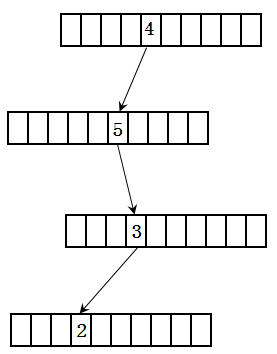
图2
从上面的数据结构可以看出,查找一个整数只和这个整数的位数有关,和整数的数量无关。这个键树的实现代码如下:
KeyTree的实现代码
class KeyTreeNode // 键树节点的结构
{
// 指向包含整数下一个的结点的指针
public KeyTreeNode[] pointers = new KeyTreeNode[10];
// 结束位标志,如果为true,表示当前结点为整数的最后一位
public bool[] endFlag = new bool[10];
}
class KeyTree
{
private KeyTreeNode rootNode = new KeyTreeNode(); // 根结点
// 向键树中添加一个无符号整数
public void add(uint n)
{
string s = n.ToString();
KeyTreeNode tempNode = rootNode;
int index = 0;
for (int i = 0; i < s.Length; i++)
{
index = int.Parse(s[i].ToString()); // 获得整数每一位的值
if (i == s.Length - 1) // 在整数的最后一位时,将结束位设为true
{
tempNode.endFlag[index] = true;
break;
}
if (tempNode.pointers[index] == null) // 当下一个结点的指针为空时,新建立一个结点对象
tempNode.pointers[index] = new KeyTreeNode();
tempNode = tempNode.pointers[index];
}
}
// 判断一个整数是否存在
public bool exists(uint n)
{
string s = n.ToString();
KeyTreeNode tempNode = rootNode;
int index = 0;
for (int i = 0; i < s.Length; i++)
{
if (tempNode != null)
{
index = int.Parse(s[i].ToString());
// 当整数的最后一位的结束标志为true时,表示n存在
if((i == s.Length - 1)&& (tempNode.endFlag[index] == true))
return true;
else
tempNode = tempNode.pointers[index];
}
else
return false;
}
return false;
}
}
上面代码中的KeyTreeNode之所以要使用结束标志,而不根据指针是否为空判断某个整数的存在,是因为可能存在长度不相等的整数,如4321和432。如果只使用指针判断。保存4321后,432也会被认为存在。而如果用结束标志后,在值为2的节点的结束标志为false,因此,表明432并不存在。下面的UrlFilter使用了上面的键树来处理Url。
UrlFilter类的实现代码
// 用于将url重新组合后再加到键树中
// 如http://www.comprg.com.cn和http://www.comprg.com.cn/是一样的
// 因此,它们的hashcode也要求一样
class UrlFilter
{
public static KeyTree urlHashCode = new KeyTree();
private static object syncUrlHashCode = new object();
private static string processUrl(string url) // 重新组合Url
{
try
{
Uri uri = new Uri(url);
string s = uri.PathAndQuery;
if(s.Equals("/"))
s = "";
return uri.Host + s;
}
catch(Exception e)
{
throw e;
}
}
private static bool exists(string url) // 判断url是否存在
{
try
{
lock (syncUrlHashCode)
{
url = processUrl(url);
return urlHashCode.exists((uint)url.GetHashCode());
}
}
catch (Exception e)
{
throw e;
}
}
public static bool isOK(string url)
{
return !exists(url);
}
// 加处理完的Url加到键树中
public static void addUrl(string url)
{
try
{
lock (syncUrlHashCode)
{
url = processUrl(url);
urlHashCode.add((uint)url.GetHashCode());
}
}
catch (Exception e)
{
throw e;
}
}
}
八、其他部分的实现
到现在为止,网络蜘蛛所有核心代码都已经完成了。下面让我们做一个界面来使下载过程可视化。界面如图3所示。
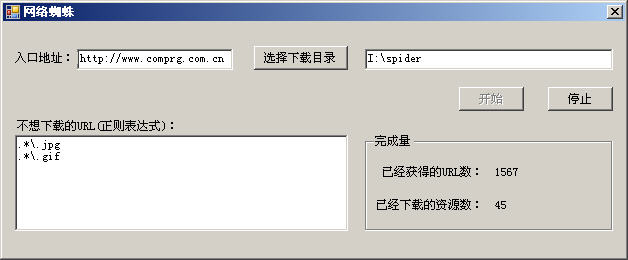
图3
这个界面主要通过一个定时器每2秒钟获得个一次网络蜘蛛的下载状态。包括获得的URL数和已经下载的网络资源数。其中这些状态信息都保存在一个Common类的静态变量中。Common类和主界面的代码请读者参阅本文提供的源代码。
九、结束语
至此,网络蜘蛛程序已经全部完成了。但在实际应用中,光靠一台机器下载整个的网络资源是远远不够的。这就需要通过多台机器联合下载。然而这就会给我们带来一个难题。就是这些机器需要对已经下载的Url进行同步。读者可以根据本文提供的例子,将其改成分布式的可多机同时下载的网络蜘蛛。这样网络蜘蛛的下载速度将会有一个质的飞跃。
参考文献:
1. Programming C#, 4th Edition By Jesse Liberty
2. Professional C# 2005 byChristian Nagelet al.
3. Core C# and .NET By Stephen C. Perry
4. Working with Microsoft Visual Studio 2005 by Craig Skibo, Marc
YoungandBrian Johnson
5. Professional C# 2005 with .NET 3.0 by Christian Nagel, Bill
Evjen, Jay Glynn, Morgan SkinnerandKarl |