摘要
WebLogic Event Server (WL EvS)是一个用于开发和部署事件驱动型应用程序的平台。分布式缓存技术可以提供众多好处,比如说使处理实时事件的应用程序具有高可用性(HA)、高性能和可伸缩性。本文将探讨开发人员如何使用WebLogic
Event Server和分布式缓存一起在事件驱动型应用程序中实现这些特性。文章还将提供完整的救命应用程序和示例代码。
简介
WebLogic Event Server (WL EvS)是一款模块化的轻量级应用服务器,用于开发事件处理应用程序。事件处理应用程序的基本关注点是处理实时的事件流,并且常常有很苛刻的低延时要求。事件处理应用程序通常应用于金融、电信、制造和零售行业,等等。比如说,金融领域的事件处理应用程序可以处理市场数据提要,以便于寻找买卖机会。
分布式缓存是一项相对比较成熟的技术。各种形形色色的缓存产品已经进入了消费者市场,其中包括GemStone的GemFire、Tangosol的Coherence和GigaSpaces的Data
Grid。分布式缓存即缓存在分布式系统各节点内存中的缓存数据。分布式缓存产品通常可以支持许多种内存缓存拓扑,比如说复制缓存(replicated
cache)、分配缓存(partitioned cache)和多层缓存(tiered cache)。分布式缓存解决方案还支持将缓存数据写入持久性存储器(如关系数据库),以及从中读取缓存数据。
分布式缓存技术可以为事件驱动型应用程序提供许多重要价值。其中最重要的一点就是高可用性。比如说,事件处理应用程序可以将输出事件发布到一个重复式的(replicated)分布式缓存,从而保证其计算结果具有高可用性。分布式缓存还可以提高事件驱动型应用程序的性能和可伸缩性。比如说,许多事件驱动型应用程序都需要结合使用流数据和外部数据,例如从持久性存储器中检索出来的数据。缓存可用于提高访问非流式数据的速度,从而动态地提高应用程序的性能。
本文将介绍事件驱动型财务应用程序的一个示例――“in-play”应用程序――该示例将演示如何在WebLogic Event Server中使用GemFire分布式缓存。示例应用程序将具体演示如何使用分布式缓存为事件驱动型应用程序提供高可用性和可伸缩性等优点。应用程序还将演示如何在Spring中使用门面设计模式将特定分布式缓存解决方案的依赖关系降到最低。我们还将演示如何使用Event
Server 的可扩展配置系统将分布式缓存的配置元数据与其余服务器的配置集成在一起。虽然示例应用程序中使用的是GemFire,但是这种通用的集成方法也适用于其他缓存系统。
首先,本文本将介绍WebLogic Event Server的总体概念以及分布式缓存技术在事件驱动型应用程序中的应用。其余章节将详细研究示例应用程序并归纳出一些结论。
WebLogic Event Server概述
WebLogic Event Server是专门针对实时事件驱动型应用程序而设计的一种应用平台。事件驱动型应用程序的关注点是处理事件流,通常由外部源将事件流交付给Event
Server实例。比如说,在图1演示的场景中,事件驱动型应用程序正在处理来自多个证券市场的证券交易事件。当应用程序在交易事件中检测到一个特定的模式时,便会向事件订阅者或其他外部系统发出通知。通常,从外部源接收到的事件要比应用程序生成的事件高几个数量级。.
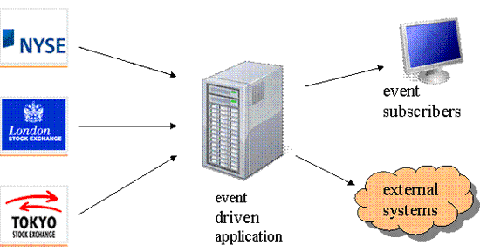
图1:典型的事件驱动型应用程序场景
就其本质而言,WebLogic Event Server是一个基于BEA微服务架构(microServices Architecture,mSA)的、模块化的轻量级应用服务器。图2是Event
Server软件栈的高级结构图。图2显示Event Server运行于BEA的实时JVM之上,该实时JVM提供了确定性垃圾收集机制(deterministic
garbage collection,DGC)。这种平台适合在确定性行为和低延时方面具有苛刻要求的应用程序,比如说各种财务应用程序。但是,Event
Server是纯Java应用程序,因此它也可以运行在其他JVM之上。
从图2中还可以看出,Event Server使用OSGi提供其模块化架构的核心。如果对OSGi还不甚了解,也不用担心。我们将在演示过程中穿插介绍OSGi的基本概念。此处,有一点值得大家重点注意,即服务器子系统(例如事件记录和配置子系统)和开发人员编写的应用程序都将封装为OSGi模块――在OSGi中,模块也称作“程序包(bundle)”。这也意味着开发人员需要对OSGi有足够的理解,才能够将自己编写的应用程序封装为OSGi程序包。
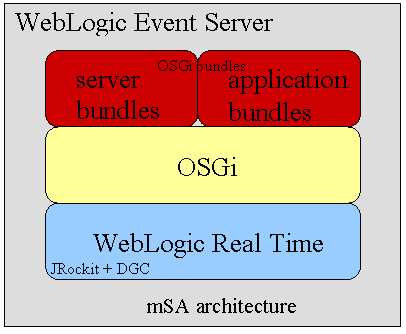
图2. WebLogic Event Server架构
WebLogic Event Server是一个功能全面的应用服务器,它为事件驱动型应用程序提供了一整套必备的服务。图3显示了Event
Server所提供的一些比较重要的服务模块(或程序包)。比如说,Event Server支持通过JDBC访问关系数据库。Event
Server可充当JMS客户机的角色。身份验证和授权服务可用于指定一组允许执行管理操作的用户。Event Server还支持工作管理人员处理与线程有关的事项。
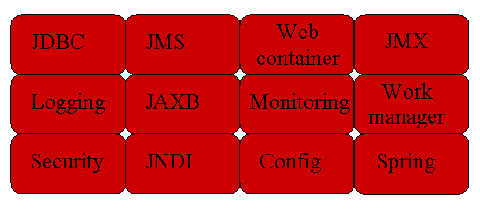
图3. WebLogic Event Server服务
让我们仔细查看一下Event Server应用程序的结构。Event Server编程模型基于Spring Framework。Event
Server应用程序由一个应用程序组件网络组成,这些应用程序组件形成了一个事件处理网络。共有四种主要的组件类型:Adapter、Stream、Processor和POJO。Event
Server提供了Stream和Processor组件的实现,因此开发人员只需要配置组件的类型便可以使用它们。但是,Adapter和POJO组件是由应用程序开发人员编写的。图4显示了事件处理网络的一个例子。

图4.示例事件处理网络
如图4所示,Adapter组件负责提供与各种外部事件源的连通性,比如说市场数据提要。从本质上说,Adapter组件将传入的事件流数据转化为事件对象,以供事件处理网络中的下游组件使用和处理。Event对象可以是公开集合类型属性的JavaBean,也可以是条目表示属性名称/值对的Map。
Stream组件实际上就是内存中的一个队列。Stream组件的目的是为事件提供缓冲,以及控制应用程序的线程行为。在默认情况下,Stream组件的容量是1024,也就是说一个Stream组件可以缓冲1024个事件。在图4的事件处理网络中,Adapter组件生成事件而Processor组件使用这些事件,Stream组件就在两这者之间提供了解耦的作用。Adapter组件创建事件对象并将其发送给Stream组件之后,控制可立即返回Adapter组件(假设Stream组件未满),并且Adapter组件可以继续从外部事件源读取数据然后产生其他事件。Stream组件从队列中取出事件,然后通过单独的线程将事件发送给Processor组件。负责从Stream组件中移除事件的线程数量是可以动态配置的,即Stream组件的容量。换句话说,可以在运行应用程序的时候动态调节这些Stream参数,从而提高应用程序的性能。
在许多事件处理应用程序中,绝大多数工作都是在Processor组件中执行的。为了有效地支持筛选和合并事件流之类的操作,Event
Server提供了声明式事件处理语言(EPL)――声明式EPL是一种基于SQL的查询语言,它在实时事件处理方面扩展了一些特殊特性。Processor组件配置了一组EPL查询语句,因此可以不间断地对新到的事件执行操作。还可以在应用程序运行时对Processor组件的EPL查询进行动态修改。EPL查询生成的输出事件将发送给下游的组件,比如说图4中的POJO。
POJO组件由用户自己编写,因此可以包含任意的业务逻辑。POJO使应用程序开发人员可以在创建事件驱动型应用程序时利用Java的强大功能。POJO可以是一些简单的组件,用于将事件转发给外部系统,也可以是一些复杂的组件,用于执行一些比较复杂的事件处理。
分布式缓存概述
分布式缓存提供的数据内存缓存可以分布于大量单独的物理机器中。换句话说,分布式缓存所管理的机器实际上就是一个集群。它负责维护集群中成员列表的更新,并负责执行各种操作,比如说在集群成员发生故障时执行故障转移,以及在机器重新加入集群时执行故障恢复。
分布式缓存支持一些基本配置:重复(replicated)、分配(partitioned)和分层(tiered)。重复(Replication)用于提高缓存数据的可用性。在这种情况下,数据将重复缓存在分布式系统的多台成员机器上,这样只要有一个成员发生故障,其他成员便可以继续处理该数据的提供。另一方面,分配(Partitioning)是一种用于实现高可伸缩性的技巧。通过将数据分配存放在许多机器上,内存缓存的大小加随着机器的增加而呈线性增长。结合分配和重复这两种机制创建出的缓存可同时具备大容量和高可伸缩的特性。分层缓存也称作客户机-服务器(client-server)缓存,它是一种拓扑结构,在该结构中缓存功能将集中于一组机器上。缓存客户机通常并不会亲自执行任何缓存操作,而是连接到缓存并检索或更新其中的数据。分层缓存架构可以包含多层结构。
WebLogic Event Server可以很容易与第三方分布式缓存解决方案集成在一起,从而提供分布式缓存的各种优点,比如说高可用性。在图5的示例架构中,分布式缓存结合Event
Server为Event Server应用程序的计算结果提供了高可用性。
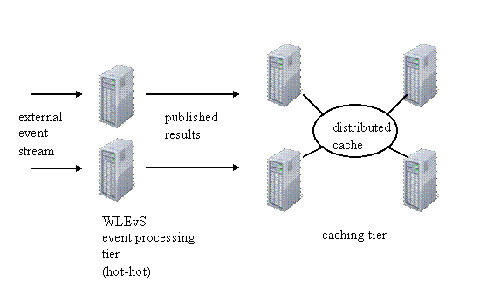
图5.使用分布式缓存提供高可用性
在图5的示例架构中,事件处理层由两个并发运行的Event Server实例组成,两个实例处理相同的输入事件流。事件处理应用程序先应用一些筛选或匹配标准,然后将结果事件发布给分布式缓存层(caching
tier)。随后,这些结果立刻可以供应用程序客户机访问,并且稍后便可进行离线处理。
此架构假定可以允许多个Event Server实例将相同的事件发布到缓存中。事件与缓存中的惟一键关联在一起,因此多次发布结果将导致初始事件实例被后续相同事件的实例替换掉。另一种方案是,各个实例可以先检查缓存中是否存在该事件,然后再选择是否发布该事件。如果该架构中的某个Event
Server实例发生故障,其他实例将继续发布事件,从而保证缓存状态的一致性。注意,Event Server层与缓存层的特定配置是相互独立的。也就是说,我们可以修改缓存层中的分配数和重复数,而不会影响到事件处理层。
事件处理应用程序常常会将其他源(比如说关系数据库)的数据合并到事件流中。分布式缓存可以帮助实现这一场景,方法是加快关系数据库的访问速度。在图6的示例应用程序架构中,分布式缓存位于事件处理应用程序和关系数据库之间,并提供了对存储数据的快速和可伸缩式访问。本节介绍了两种技巧:将数据发布到分布式缓存和在分布式缓存中合并数据。我们可以在相同的应用程序架构中结合使用这两种技巧。
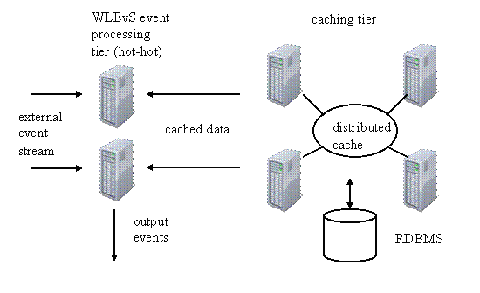
图6.加速访问持久性数据的速度
In-play示例应用程序
本节将介绍一个示例财务应用程序,我们将在其中使用上文所讨论的缓存技巧。示例应用程序将演示如何将Event Server与分布式缓存产品(在本例中为GemStone
Systems的GemFire)集成在一起。我将介绍如何使用Spring Framework创建门面设计模式,从而消除应用程序代码与底层缓存实现的依赖关系。示例应用程序还将演示如何使用Event
Server的可扩展配置系统对GemFire进行配置。
图7显示了该应用程序架构的高级视图。该应用程序是一个连接到模拟市场数据提要的示例财务应用程序。市场数据提要将生成一些证券交易事件。每个证券交易事件都含有一个股票代号、交易股数和交易价格。示例应用程序将使用WebLogic
Event Server加载生成程序,生成程序是封装在Event Server中的一个工具,用于模拟数据提要。
事件从加载生成程序流向in-play应用程序,然后由in-play应用程序进行处理。输出事件将发布给重复GemFire缓存,然后重复GemFire缓存将这些事件分发给应用程序的客户机。在本例中,客户机是运行在单独Event
Server流程中的另一个Event Server应用程序。客户机POJO将注册为缓存的监听程序,以便于接收输出事件的通知。
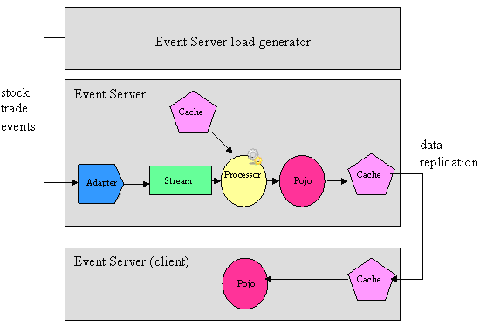
图7. In-play应用程序架构
示例应用程序的事件处理网络相对比较简单。其中只有一个Adapter是CSV adapter的实例。CSV adapter附带在Event
Server中,其设计目的是与加载生成程序工具相互协作。Adapter接收传入事件然后生成一些TradeEvent对象并将其转发给Stream组件。图8给出了TradeEvent类的代码。不难看出,TradeEvent是一个普通的JavaBean或POJO。
package com.bea.wlevs.example.caching.event;
public class TradeEvent {
private String symbol;
private Double price;
private Long volume;
public String getSymbol() {
return symbol;
}
public void setSymbol(String symbol) {
this.symbol = symbol;
}
public Double getPrice() {
return price;
}
public void setPrice(Double price) {
this.price = price;
}
public Long getVolume() {
return volume;
}
public void setVolume(Long volume) {
this.volume = volume;
}
public String toString (){
return "[Symbol: " + symbol + ", Price: "+ price
+
", Volume: "+ volume + "]";
}
}
图8.TradeEvent类
The stream in our 示例应用程序中的Stream是与Processor组件连接在一起的。而示例应用程序中的大多数工作都发生在Processor组件中。Processor组件使用EPL查询计算当前交易日各个股票交易的积累成交量。图9显示了所使用的EPL查询。
insert into CumulativeVolumeEvent
select symbol, sum(volume) as cumulativeVolume
from TradeEvent
retain 8 hours
group by symbol
图9. 用于计算积累成交量的EPL
EPL查询的结构类似于SQL。select语句用于从传入TradeEvents中选择股票代号和积累成交量,并使用group
by语句对TradeEvents按符号进行分组。retain语句是EPL中的新元素。在本例中,它指定我们希望在证券市场开市的8个小时内跟踪各个股票代号的积累成交量。insert语句也是一个新元素。它指定应该使用select语句选择的属性创建一个类型为CumulativeVolumeEvent的新事件。图10显示了CumulativeVolumeEvent类的代码。需要注意,其中的属性必须与图9中的select语句选择的属性名称相匹配。
package com.bea.wlevs.example.caching.event;
public class CumulativeVolumeEvent {
private String symbol;
private Long cumulativeVolume;
public String getSymbol() {
return symbol;
}
public void setSymbol(String symbol) {
this.symbol = symbol;
}
public Long getCumulativeVolume() {
return cumulativeVolume;
}
public void setCumulativeVolume(Long cumulativeVolume) {
this.cumulativeVolume = cumulativeVolume;
}
public String toString() {
return "[Symbol: " + symbol + ", CumulativeVolume: " + cumulativeVolume
+ "]";
}
}
图10. CumulativeVolumeEvent类
使用缓存提高数据访问速度
接下来,应用程序将计算股票是否为“in play”。这时,缓存将开始发挥其作用。“in-play”计算将使用另一个EPL查询来实现,如图11所示。
insert into InPlayEvent
select symbol, cumulativeVolume, CompanyHelper.getOutstandingShares(symbol)
as outstandingShares
from CumulativeVolumeEvent
retain 8 hours
where cumulativeVolume>
( CompanyHelper.getOutstandingShares (symbol)* .1)
图11. 用于计算in-play股票的EPL
这里的查询代码将操作前面查询所生成的CumulativeVolumeEvents。它将选择当前交易日的代码、积累成效量,以及股票的已发行股份总量。已发行股份总量将通过一个自定义函数计算出来,该函数使用股票代号作为参数。如图11所示,in-play股票在示例应用程序中的定义为积累交易量大于已发行股份总量十分之一的股票。
package com.bea.wlevs.example.caching.functions;
public class CompanyHelper {
public static Long getOutstandingShares(String symbol) {
Company company = singleton.getCompanyMap().get(symbol);
return company.getOutstandingShares();
}
}
图12. getOutstandingShares自定义函数
请注意,getOutstandingShares()方法只是一个静态方法。getOutstandingShares()方法的参数为股票代码,作用是计算该股票代码的已发行股份总量。实现方法是检索某个公司对象,然后返回调用Company.getOutstandingShares()的结果。
静态方法会将检索含有公司信息的Map对象的操作委托给一个singleton对象,singleton对象是CompanyHelper类的一个实例。调用singleton.getCompanyMap()的结果是一个java.util.Map,它将代号映射到Company对象。但是在本例中,返回的Map将备份到GemFire缓存中。将Map封装到singleton对象的目的是我们可以使用Spring将这个singleton对象作为普通Spring
bean进行配置,并使用依赖性注入功能将GemFire引用注入到这个bean中。
package com.bea.wlevs.example.caching.functions;
public class CompanyHelper {
private static CompanyHelper singleton = null;
private Map<String, Company> companyMap = null;
private Cache cache;
private String mapName;
private boolean activated = false;
public static synchronized CompanyHelper createInstance() {
if (singleton == null) {
singleton = new CompanyHelper();
}
return singleton;
}
private CompanyHelper() {
}
public void afterConfigurationActive() {
companyMap = cache.getMap(mapName);
activated = true;
}
public static Long getOutstandingShares(String symbol) {
Company company = singleton.getCompanyMap().get(symbol);
return company.getOutstandingShares();
}
public void setCache(Cache cache) {
this.cache = cache;
}
public void setMapName(String mapName) {
this.mapName = mapName;
}
public Map<String, Company> getCompanyMap() {
if (!activated) {
afterConfigurationActive();
}
return companyMap;
}
图13.CompanyHelper类
图13显示了CompanyHelper类的完整代码清单,而图14显示了CompanyHelper bean的Spring配置
<bean id="CompanyHelper"
class="com.bea.wlevs.example.caching.functions.CompanyHelper"
factory-method="createInstance">
<property name="cache" ref="cache" />
<property name="mapName" value="/root/company" />
</bean>
图14. CompanyHelper bean的Spring配置
如图14所示,Spring已配置为使用静态方法(即CompanyHelper.createInstance(),)实例化bean。这使CompanyHelper类可以将singleton实例的引用保存在一个静态变量中,以便稍后由实现自定义EPL函数的静态方法使用。
请注意,缓存对象引用将被注入CompanyHelper类。Cache对象是门面设计模式的一部分,示例应用程序使它封装对GemFire分布式缓存的访问。mapName可用于标识了一组特定的缓存值,在本例中为GemFire缓存系统中的Company对象。请注意,实际上CompanyHelper类与GemFire类之间是没有依赖关系的。就CompanyHelper类而言,缓存不过是一个java.util.Map对象。在应用程序类中避免与缓存系统的依赖关系有利于将来切换到不同的缓存实现。避免依赖关系的能力是使用Spring依赖性注入支持的关键优点之一。
还有一点值得注意,CompanyHelper类会受到Event Server 2.0发行版的类加载限制。在2.0发行版中,实现自定义EPL函数的类需要放置在Java
VM的启动或扩展类路径下,而不是封装在应用程序的程序包中。这意味着自定义函数不能引用启动/扩展类加载程序不可见的类。由于受到这种限制,CompanyHelper类将无法实现
com.bea.wlevs.ede.api.ActivatableBean 接口。通常,需要实现该接口以从客器接收afterConfigurationActive生命周期回调。CompanyHelper类已经解决了这一限制,方法是在getCompanyMap()方法中调用,如图13如示。
将事件发布到分布式缓存
In-play事件将由Processor组件输出给POJO。然后,POJO会将in-play事件发布给分布式缓存,从而实现高可用性。股票经纪人等感兴趣的人可以注册一个分布式缓存监听程序,从而获取in-play状态的股票的通知。图15显示了POJO
(InPlayBean)类的示例代码。图16含有Spring配置。
package com.bea.wlevs.example.caching.pojo;
public class InPlayBean implements EventSink, ActivatableBean, Stage {
private Map<String, InPlayEvent> map;
private Cache cache;
private String mapName;
public InPlayBean() {
}
public void afterConfigurationActive() {
map =cache.getMap(mapName);
}
public void onEvent(List newEvents) throws EventRejectedException {
for (Object event : newEvents) {
if (event instanceof InPlayEvent) {
InPlayEvent inPlayEvent = (InPlayEvent) event;
System.out.println("publishing InPlayEvent: " + inPlayEvent);
try {
map.put(inPlayEvent.getSymbol(), inPlayEvent);
} catch (Exception exception) {
exception.printStackTrace ();
}
} else {
System.out.println("Event: " + event);
}
}
}
public void setCache(Cache cache) {
this.cache = cache;
}
public void setMapName(String mapName) {
this.mapName = mapName;
}
}
图15. InPlayBean类
<bean id="inPlayBean"
class="com.bea.wlevs.example.caching.pojo.InPlayBean">
<property name="cache" ref="cache" />
<property name="mapName" value="/root/inplay" />
</bean>
图16.InPlayBean的Spring配置
InPlayBean是一个普通的Spring bean。它调用公有构造函数进行实例化,并使用setter注入的方法注入其依赖关系。类似于CompanyHelper
bean,inPlayBean中注入了一个到分布式缓存系统的引用,以及一个名称,用于在缓存中识别特定的信息(Map)集合。在本例中,in-play股票保存在映射中。
需要注意InPlayBean.afterConfigurationActive()方法。应用程序中的所有bean中都注入各自的动态配置之后,容器将调用这个生命周期方法。InPlayBean将使用该方法在缓存系统中查找映射。我们将在下节看到,代表缓存的Spring
bean将使用动态配置,因此一定要等到bean生命周期的afterConfigurationActive阶段再使用该方法,不然将抛出异常。
调用InPlayBean.onEvent()方法时,bean只是简单地将in-play事件放到分布式映射中去。同样,需要注意Example
Bean与GemFire类之间没有直接的依赖关系。Example Bean将与分布式缓存进行交互,就像是一个普通的java.util.Map对象。还有一点值得注意,InPlayBean实现了
com.bea.wlevs.ede.api.Stage 接口。这是当前Event Server编程模型的要求,因为bean需要接收与动态配置相关的生命周期回调,如afterConfigurationActive。
集成Event Server配置系统
Spring bean封装了应用程序的GemFire缓存系统。图17显示了缓存门面bean所实现的Cache接口。
package com.bea.wlevs.example.caching.cache;
public interface Cache {
public Map getMap (String name);
public void registerListener (String name, Object listener);
public void setLoader (String name, Object loader);
}
图17. Cache接口
在上面的代码中,缓存façade将一些方法公开给应用程序的其余部分。我们已经知道getMap()方法用于检索缓存系统中的指定映射。registerListener()方法用于注册需要在对缓存事件的响应中调用的对象,比如说在缓存中插入一个新元素。客户Event
Server应用程序将调用该方法,用于为缓存中的新in-play事件注册回调。setLoader()方法用于为自定义缓存加载程序注册映射。当缓存中的数据丢失时,缓存加载程序负责将数据加载到缓存中。示例应用程序将使用这一功能将数据加载到公司映射中去,上文已经讨论了这种方法。有关详细信息,请参见com.bea.wlevs.example.caching.loader.CompanyLoader类。
接下来,我们将讨论缓存façade的实现。请查看GemfireCache类的完整代码清单。当然,GemfireCache类实现了一个Cache
façade接口。除了实现此接口的方法之外(只需一行代码),这个类的主要责任是读取其配置元数据并使用这些元数据正确地实例化GemFire。因此,配置是这个类的一个重要方面。
GemfireCache类的配置将使用Spring和Event Server的动态配置系统来完成。请看Spring和GemfireCache的动态配置元数据,如图18和图19所示。
<bean id="cache"
class="com.bea.wlevs.example.caching.gemfire.GemfireCache"
destroy-method="destroy">
</bean>
图18.缓存 façade的Spring配置。
<cache-system>
<name>cache</name>
<multi-cast-port>0</multi-cast-port>
<locators>localhost[10987]</locators>
<log-level>warning</log-level>
<cache-xml-file>applications/caching/cache/cache.xml</cache-xml-file>
<license-file>applications/caching/cache/gemfireLicense.zip</license-file>
<lock-timeout>15</lock-timeout>
</cache-system>
图19.缓存 façade的Spring配置
我们注意到,Spring配置的主要职责只是实例化facade bean。实际上,Bean的配置元数据中含有动态配置文件。配置元数据可以分为两个类别。第一类是需要由应用程序管理员或部署人员进行配置的元数据,但是这种元数据不需要在应用程序运行时进行修改。其中含有一些路径信息,比如说GemFire许可文件和GemFire
cache.xml文件的路径(这个文件配置了GemFire的partitioning和replication缓存机制)。第二种元数据是可能需要在应用程序运行时修改的元数据,比如说锁请求超时(lock
timeout),它指定了分布式缓存将等待锁的时间(单位为秒)。
应用程序外部配置或动态配置的这两种元数据可以帮助在管理员或部署人员与应用程序开发人员之间创建一个定义良好的约定。比如说,这一技巧允许应用程序开发人员将其他角色分离开,使他们不必理解应用程序的Spring配置。这种技巧的好处在于,Spring配置很有可能会含有一些应用程序开发人员不想让其他角色修改的信息。因为随意修改这些信息可能会造成应用程序崩溃。
虽然缓存façade的元数据是特定于与此应用程序的,但是它也是服务器配置的一部分,就如Processor和Stream组件的内建配置一样。这意味着可以将缓存元数据作为通用配置的一部分进行修改和更新,通用配置需要修改应用程序的许多部分。比如说,由于锁请求超时(lock
timeout)是动态配置的一部分,因此可以在应用程序运行时通过JMX对它进行更新――比如说使用Admin工具。Event Server将自动生成JMX
MBean。
下载
结束语
在本文中,我介绍了如何利用分布式缓存提高WebLogic Event Server应用程序的性能和可用性。使用Spring进行依赖性注入,并使用Event
Server的可扩展动态配置工具存储缓存系统所需的元数据,我们可以将分布式缓存与Event Server应用程序巧妙地集成在一起。
本文介绍了如何使用自定义函数在EPL中访问分布式缓存。由于缓存配置封装在XML配置元数据中,因此所使用的底层缓存拓扑可以完全独立于事件驱动型应用程序代码。本文研究了示例应用程序中许多有趣的方面,但是应用程序代码还引申了许多其他话题,比如说第三方库的封装,自动化应用程序包的创建过程,以及集成缓存监听程序和缓存加载程序。务必要下载示例应用程序并仔细查看。
参考资料
|