| 编辑推荐: |
本文详细论述了该方案TaskMaker、 Calculator、 Checker等各个模块的设计实现,最终实现了用户无需额外开发,只需要简单的配置即可完成监控指标的计算和推送,避免了人力浪费,提升效能。
本文来自于腾讯大讲堂,由Alice编辑、推荐。 |
|
背景
在金融业务上,质量和稳定是生命线,我们需要对所有已经上线的风控要素,如策略、模型、标签、特征等构建监控。在过去,我们部署监控的方式为:
风控要素负责同学在要素上线前,通过spark\sql完成对监控指标的运算并例行化;
将监控指标运算结果出库mysql\tbase,用于指标的展示和告警;
告警系统轮询指标是否异常,如异常则通过企业微信等推送告警消息。
这种模式主要的问题在于:
开发门槛高,要素负责同学需要掌握spark离线计算、mysql等数据库的增删数据,还需要手动配置例行化任务,在告警系统上登记注册等,耗时费力;
重复工作多,要素指标相似、重合度很高,如多数风控要素都涉及PSI计算,只是告警阈值不一样;指标出库、配置告警等同样是重复相似操作。
为了解决上述问题,我们设计开发了一套“统一监控计算检查工具”(以下简称监控工具),将监控计算拆解成计算任务生成、监控指标计算、监控指标衍生与检查等模块,实现用户无需额外开发,只需要简单的配置即可完成监控指标的计算和推送,避免了人力浪费,提升效能。
整体设计
系统交互视图
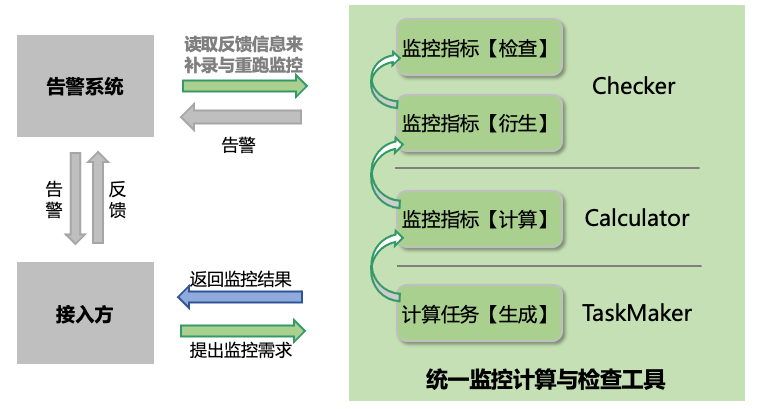
与统一监控计算与检查工具交互的主要有接入方和告警系统,所有的监控由接入方发起,接入方可以是特征、标签、模型、策略的兜底检查同学,也可以是具体业务同学。接入方提出监控需求(填写配置),统一监控计算与检查工具根据需求生成计算任务完成计算,如果触发告警则通过告警系统将告警发送给接入方,接入方接受告警后及时修复并反馈登记,监控工具会读取用户的告警反馈重新完成相关计算,直至监控指标在告警阈值内。
为了完成监控指标的计算,统一监控计算与检查工具可以细分为三个核心模块,分别为:
计算任务生成模块 TaskMaker: 根据配置和被监控表调度周期(hour/day/month)、时间偏置生成监控指标计算任务,TaskMaker解决了不同计算任务例行化周期不同的问题,使得下游模块可以专注于计算本身。
监控指标计算模块 Calculator: 读取未完成的计算任务,计算相关监控指标。Calculator通过生成执行计划并优化的方式,合并不同业务同学对同一表的监控计算需求,提升计算效率。
监控指标衍生与检查模块 Checker: 读取监控指标计算结果,进行环比变化率等衍生,然后对衍生结果进行检查,返回检查结果。
需要注意的是,我们提出了“监控指标衍生的概念”,将不依赖数据源表只依赖监控指标及其历史记录的一类指标称为“衍生指标”,将衍生指标延迟到检查器Checker上计算,可以节省大量计算资源。具体来看,非衍生指标和衍生指标的不同在于:
非衍生指标。非衍生指标即指标计算仅仅依赖于数据源表,而不依赖与历史的监控指标,例如PSI值、迁移率等,这些指标描述了监控要素分布的变化,其计算只依赖于源表的当前周期和对比周期数据,不需要对监控指标进行衍生,如PSI>0.1即告警。此外任务或表状态监控,如任务完成时间、表分区计数等也只依赖源表,不需要衍生。非衍生指标只能由Calculator完成计算,通常需要多次遍历数据源表,监控所消耗的主要计算资源就是计算非衍生指标所导致。
衍生指标。衍生指标是指对监控指标进行二次运算后得到的监控指标,衍生指标的计算不依赖源表,只依赖监控指标及其历史记录。例如零值、缺失值率,它们是非衍生指标,需要一次遍历表计算得到,但我们通常不直接监控零值、缺失值率,因为不同特征上比率都不一样,A特征可能5%,B特征可能10%,直接对比率配置告警导致每个特征的阈值都不一样,配置复杂,因而我们监控零值缺失值率的波动(即当前周期零值缺失值比率同其他周期的差值),此时它们是衍生指标,因为波动的计算只依赖于当前和对比周期的零值、缺失值比率,同时对比周期的比率在历史任务上就已经完成计算,复用结果可以节省一倍以上的计算资源,提升效率。
除了核心模块,统一监控计算与检查工具还提供了“发出告警指令”、“接受告警反馈重新生成计算任务”等辅助模块。以上共同组成了统一监控计算与检查工具,确保触发的异常告警能够得到及时反馈修正。
部署视图
在实际部署上,统一监控计算与检查工具中TaskMaker(任务生成)、Calculator(计算)、Checker(检查)等模块实际上对应一个Spark节点,各个模块之间依赖关系如下图所示。
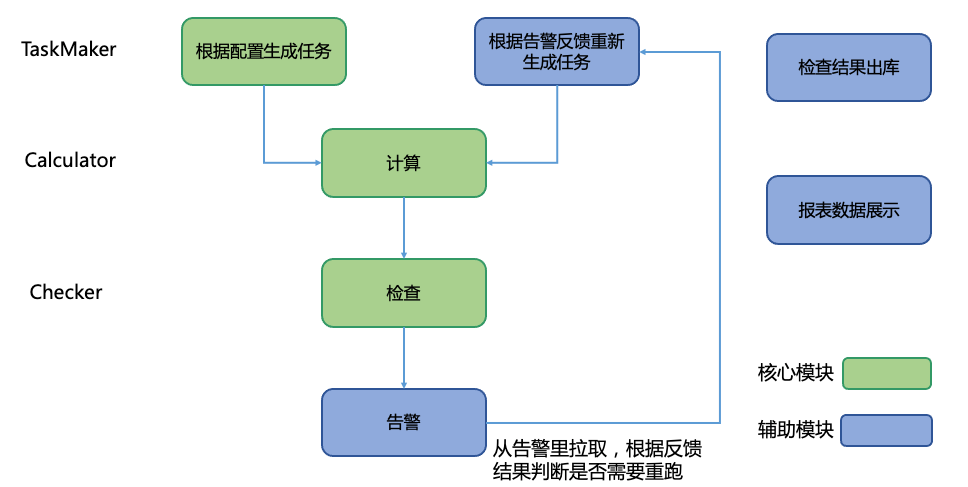
计算任务主要由TaskMaker模块根据用户配置生成,此外用户反馈已经修复的告警也会重新生成计算任务,TaskMaker屏蔽了不同调度周期的数据任务生成周期不一致的问题,例如日表任务每天生成前一天的表监控任务,月表任务只在每月特定一天生成月表的监控任务;Calculator接受计算任务完成监控指标的计算,Calculator完成监控的多数计算,需要较多的计算资源;Checker完成监控指标的衍生和检查。
模块详细设计
接下来,我们讨论监控工具TaskMaker(任务生成)、Calculator(计算)、Checker(检查)等模块的设计难点。
计算任务生成(TaskMaker)模块
计算任务生成(TaskMaker)模块核心逻辑是:
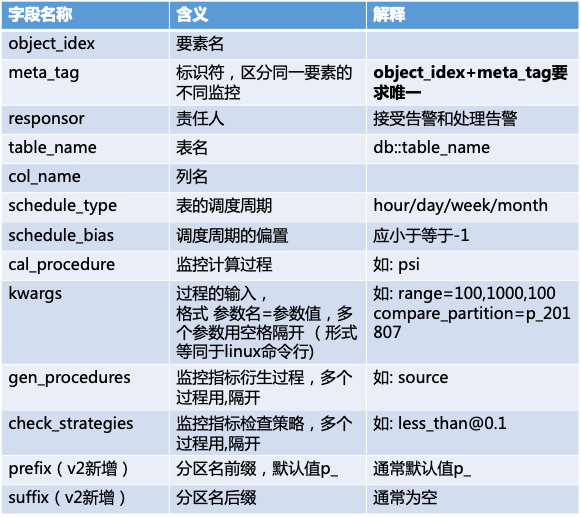
解析配置表 (配置表字段见下表);
根据配置表中schedule_type调度周期和schedule_bias偏置,生成需要检查表的分区(partition_name),将源表信息(table_name、col_name、partition_name)和计算信息(cal_procedure、kwargs)写回。
TaskMaker的主要设计难点在于:需要处理监控任务调度周期与源表计算任务调度周期的差别,适配好hour/day/week/month等不同周期,可以总结为下表:
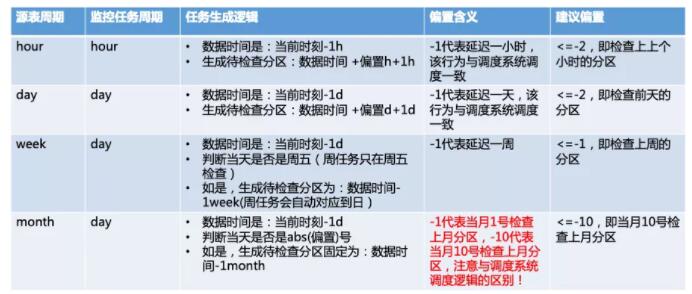
假设当前数据时间是20210210 11:00,因为调度系统对日任务通常有一天的偏移,此时实际执行时间为20210211
11:00,对于不同类型的源表周期,偏置和最终生成分区举例如下:
hour: 如果偏置是-1,则检查分区和当前数据时间一致,为20210210 11:00,如果是-2,则检查分区提前一小时,为20210210
10:00;
day:如果偏置是-1,则检查分区和当前数据时间一致,为20210210,如果是-2,则检查分区提前一天,为20210209;
week: 如果偏置是-1,代表检查上一周,但是因为当天是周三,不生成周计算任务;
month:如果偏置是-10,生成上月计算任务202101,如果不是-10,则不生成月计算任务,注意到区别于小时表、日表、周表,偏置通常表示偏移若干个周期,但是月表例外,月表的偏置代表“几号开始计算任务”。
源表日表、月表等不同调度周期的问题在TaskMaker模块解决,后续模块不再感知源表周期的区别,专注完成监控指标的计算。
监控指标计算(Calculator)模块
监控指标计算(Calculator)模块核心逻辑(如下图)是:
读取未完成的计算任务;
通过生成执行计划并优化的方式,合并不同业务同学对同一表的监控计算需求,提升计算效率,Calculator会产生三个字段,分别为:
cal_time:保存计算时间
cal_outputs:保存计算结果,json格式
cal_errors:保存计算异常错误信息

首先,我们通过实例来解释如何通过执行优化避免重复计算,提升性能:
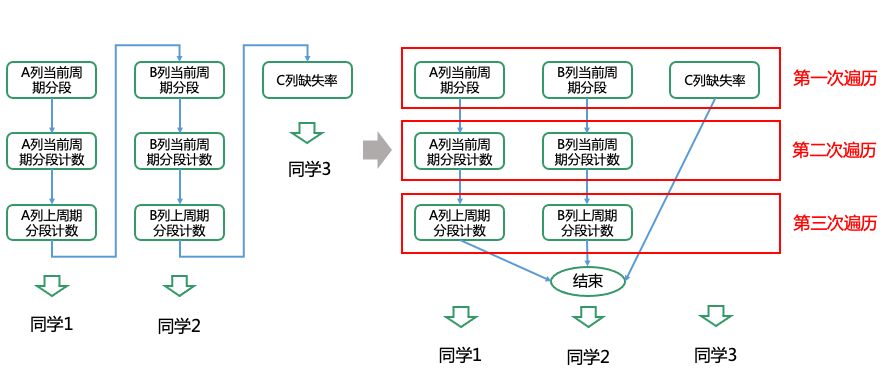
同学1的业务需要检查table表的A列的psi
同学2的业务需要检查table表的B列的psi
同学3的业务需要检查table表的C列缺失率占比
计算psi需要3次遍历表,计算缺失率需要1次遍历表,共计需要3+3+1=7次遍历
而实际上都是对同一table表的遍历,可以合并,如下图,此时只需要3次遍历,可以节省一倍以上的时间
为了实现执行优化,我们需要将一个监控指标的计算过程拆解为若干个最小可执行单元,称之为函数。具体到实现上,函数保存了计算逻辑的实现代码,过程调用若干个函数完成监控指标的最终计算,如下:
# Function
def F:RDD_aggre(...): ...
def F:math_psi(...): ... |
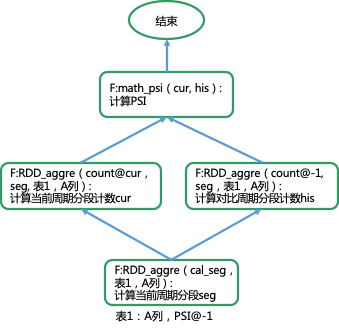
# Procedure
def P:psi(...):
seg = F:RDD_aggre('cal_seg', ...)
cur = F:RDD_aggre('count@cur', seg, ...)
his = F:RDD_aggre('count@-1', seg, ...)
psi = F:math_psi(cur, seg, ...)
return psi |
上述计算过程可以转换成计算图DAG来表示,如下图:
更复杂的,当有多个监控计算过程时,DAG可以表示为:
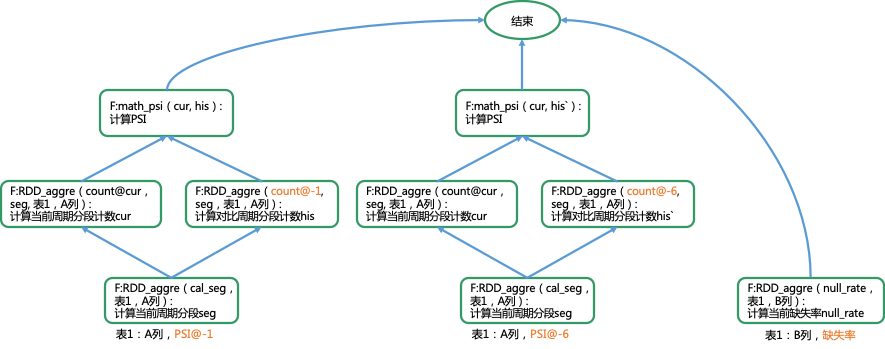
DAG需要执行的部分为叶子节点,为了避免重复计算,
我们对每次执行的叶子节点进行两类类优化:
合并同名函数,当函数名和参数都完全一致时,合并函数,仅执行一次;当函数名一致、参数不一致,生成新的执行函数(主要针对RDD
aggregate操作),同样进执行一次。
缓存计算结果,缓存函数结果,当需要再次计算相同函数时,直接从缓存读取结果。
例如,上述DAG叶子节点表示的可执行函数(叶子节点)为:F:RDD_aggre(cal_seg,表1,A列)、F:RDD_aggre(cal_seg,表1,A列)、F:RDD_aggre(null_rate,表1,B列),其中两个F:RDD_aggre(cal_seg,表1,A列)为同名同参函数,合并为一个执行,又F:RDD_aggre(cal_seg,表1,A列)与F:RDD_aggre(null_rate,表1,B列)是同名函数,可以合并执行F:RDD_aggre([cal_seg,
null_rate],[表1, 表1],[A列, B列]),此时原本需要需要三次遍历表,合并为一次遍历表即可完成。

同样的,在第二层叶子节点函数F:RDD_aggre(count@cur,seg, 表1,A列)可以合并为一次执行,但F:RDD_aggre(count@-1,
seg,表1,A列)、F:RDD_aggre(count@-6, seg,表1,A列)需要分别遍历不同的表分区(上一周期分区、前6周期分区),因而只能分别计算,第二层叶子节点共产生三次遍历表,如下:
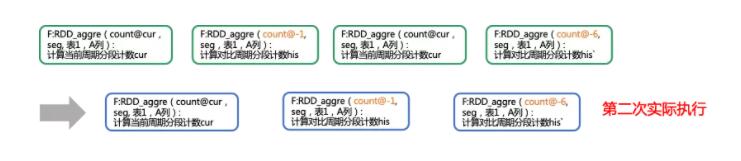
最终,拉取分段计数,在本地完成PSI的计算:

综上,执行优化算法小结如下:
算法: 执行优化算法。
输入:当前全部未执行计算任务对应计算过程。
流程:
- Step1. 将计算过程转化成DAG表示,每个节点为一个执行函数。
- Step2. 如果当前还存在未执行的叶子节点,那么合并叶子节点中的同名函数,当函数名和参数都完全一致时,合并函数;当函数名一致、参数不一致,生成新的执行函数。
- Step3. 执行函数,如果缓存中存在结果,直接拉取结果,否则完成计算后缓存结果。
- Step4. 若还存在未执行的叶子节点,返回Step2,否则终止。
输出:计算过程对应的监控指标结果。
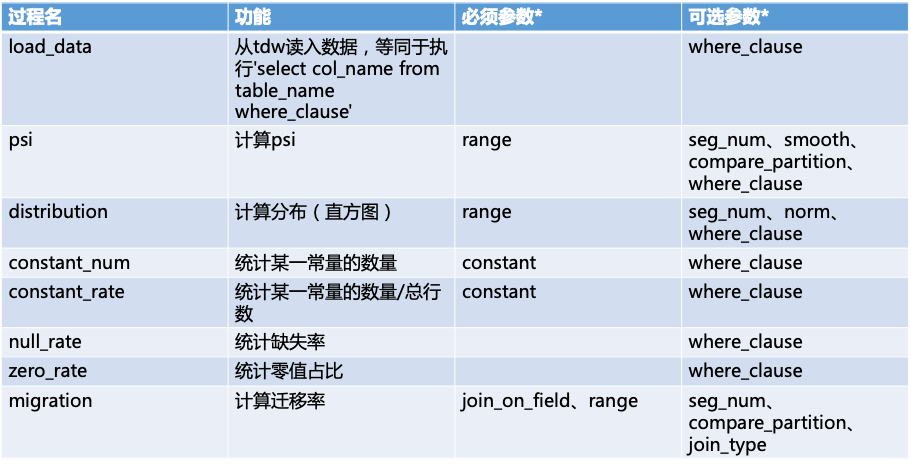
当前,Calcutor支持常见监控指标包括:
通过Calcutor模块可以完成监控指标的计算,但也存在一些监控指标(如空值占比)需要衍生后才能判断是否异常,因而我们设计了Checker模块。
监控指标衍生与检查(Checker)模块
监控指标衍生与检查(Checker)模块核心逻辑为:
读取未检查的监控指标;
按gen_procedures衍生逻辑中配置方法对监控指标衍生后,按check_strategies检查逻辑中配置方法对监控指标检查;
Checker会产生五个字段,分别为:
check_time :保存计算时间
gen_outputs :保存衍生,json格式
gen_errors :保存衍生异常错误信息
check_pass:检查是否通过
check_details:保存未通过原因,接入方同学需关注check_pass、check_details字段

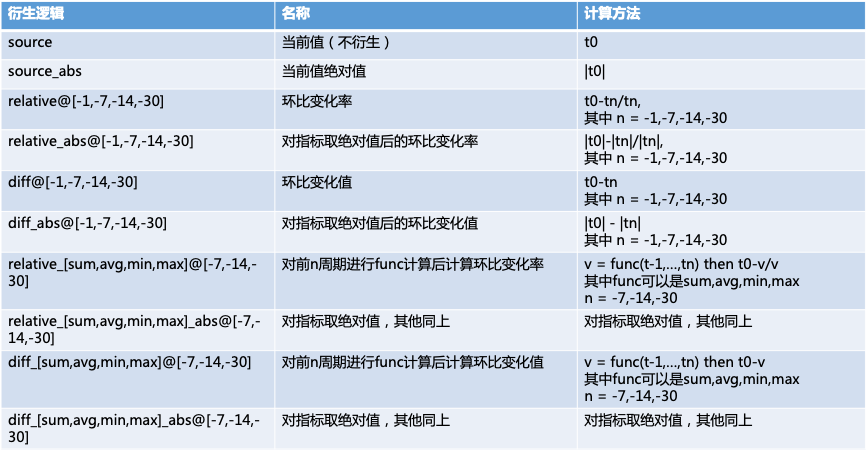
Checker的衍生方法包括:
完成衍生后,需要判断指标是否异常,这是通过检查阈值实现的,常见的检查逻辑有:
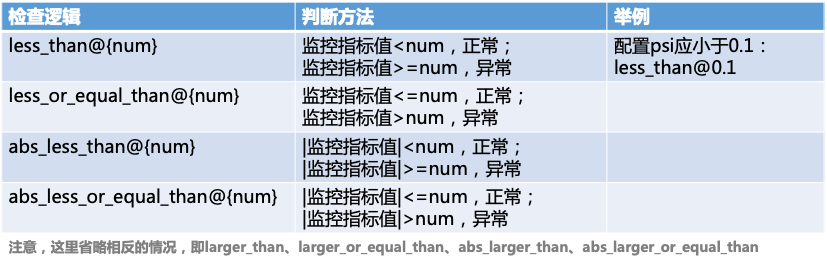
举个例子,如果要对缺失率波动进行监控,要求其变化幅度小于0.1,并且变化率小于0.2,可以将指标衍生配置为
diff@-1、relative@-1,指标检查策略配置为 abs_less_than@0.1 、
abs_less_than@0.2 。
监控计算优化实例 - PSI计算从20h到2h
在我们的实践中,发现对6w个数据列的psi等4个监控指标的计算,仅日表监控计算耗时长达20h+ ,计算耗时过大,长时间占用集群资源也会导致线上任务延迟。我们分析了造成计算时间长的原因有:
部分监控指标如PSI计算涉及多次遍历表;
Pyspark 原生Row属性访问效率差;
部分超大表行数达到20亿+。
针对这些问题,我们提出了下述方案逐一解决。
PSI计算优化:从4次遍历表到一次遍历表
相比缺失值占比、零值占比只需一次遍历表,计算psi@-1、psi@-6总共需要4次遍历表,具体如下:
遍历当前周期获取分段segs;
根据分段segs遍历当前周期获取分段计数;
根据分段segs遍历-1周期获取分段计数,计算psi@-1;
根据分段segs遍历-6周期获取分段计数,计算psi@-6。
为了降低PSI的遍历次数,我们设计了一种基于直方图的PSI估算方法,通过一次遍历表,得到特征分布直方图,再结合历史上计算的其他周期特征分布直方图,就可以估算出PSI。
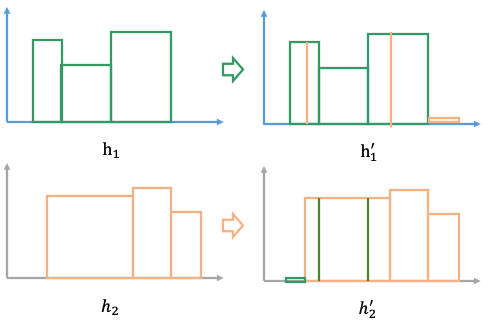
如下图所示,基于直方图的PSI估算方法主要包括4个步骤:
- 步骤一:遍历一次表,使用蓄水池采样数据(>10w),本地计算分段、统计各个分段计数,得到特征的直方图分布h1,如下图;
- 步骤二:从历史结果中拉取-n周期的直方图分布h2;
- 步骤三:由于“分割点”不一致,我们无法直接根据直方图计算PSI,因此对直方图进行分割,使得当前周期直方图和上一周期直方图的分割点一致,取h1、h2直方图分割点的并集作为新分割点,按照新的分割点重新划分直方图得到h1`、h2`;
- 步骤四:根据分隔后的直方图h1`、h2`和PSI计算公式计算PSI即可。
通过PSI计算优化,计算时间从20h -> 7h。
Pyspark Row属性访问优化
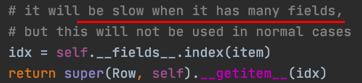
我们发现Pyspark实现的Row访问属性有效率问题(如下图,官方源码注释也承认了这一问题),row['field']需要遍历所有的列名,才能得到正确的下标,其时间复杂度是O(n)。
为了解决row访问速度的问题,我们提出了下述方案:
广播[列名->列下标]Map:field_map = broadcast(field_map)
所有用row['field']的地方, 都改成 row[feld_map.value['field']]
通过使用了少量的内存存储[列名->列下标]映射,即能将Row属性访问复杂度从O(n) ->
O(1),最终实验证明计算时间从7h -> 4h。
超大表的优化:采样与避免序列化
我们观察到,目前存在少量监控表行数达到20亿+,历史原因其格式为format(慢于orcfile),这些表全表遍历计算监控指标的时间达到数个小时。
针对这种超大表,我们提出了采样和避免序列化的优化方法,具体来说:
采样,即对行数大于1亿的表采样,控制行数在一亿内,需要注意的是,为了保证采样效率,我们使用where子句完成采样:where
rand(123) < 一亿/表行数;
避免序列化,即通过DataFrame API where 或 select子句筛选不使用的行或列,避免它们序列化到Python对象。
通过上述优化,对于20亿+行数的大表计算时间从数个小时到几十分钟,并最终实现总体计算时间从20h
-> 2h的优化。
小结
针对金融风控要素监控的“开发门槛高”“重复工作多”等问题,本文提出了“统一监控计算与检查工具”这一解决方案,本文详细论述了该方案TaskMaker、
Calculator、 Checker等各个模块的设计实现,最终实现了用户无需额外开发,只需要简单的配置即可完成监控指标的计算和推送,避免了人力浪费,提升效能。最后,我们还给出了一个“监控计算模块”优化的实例,通过“直方图估算PSI”、“Row列名广播”、“采样与避免序列化”等方式,将监控计算的速率提升了10倍,节省了大量计算资源。 |









