9.1
并发程序的概念
大家知道,进程具有并发性。在单处理机环境下,各进程交替占用CPU从而提高了CPU的利用率。在多处理机环境下,各进程可独自在自己占用的处理机上与其它进程在指令级上实现真正的并行。
应用问题的解决过程一般是先对问题进行分析,找出求解问题的先后顺序,然后按此顺序编写程序。但是,更好的做法是对已排出的先后顺序作进一步整理,看看哪些步骤是可以并行执行的,哪些步骤是必须顺序执行的。
例如,有这样一个问题:读入4个数,对第1个数(x1)经变换后得A,然后A分别与第2个数(x2)、第3个数(x3)、第4个数(x4)经函数f234生成B、C、D,最后把B、C、D作为参数经函数g生成最终的结果。
解此问题的顺序程序和并发程序如下所示
Begin
read x1;
A=f1(x1);
read x2;
B=f234(A , x2);
read x3;
C=f234(A , x3);
read x4;
D=f234(A , x4);
result=f(B,C,D);
End
(a)顺序程序 |
Begin
cobegin
read x1;
read x2;
read x3;
read x4;
coend
A=f1(x1);
cobegin
B=f234(A , x2);
C=f234(A , x3);
D=f234(A , x4);
coend
result=g(B,C,D)
End
(b)并发程序 |
| 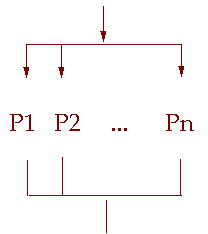
并发关系 |
顺序/并发关系 |
| (其中图中p1,p2,...为可执行的成分) |
9.2 操作系统提供的支持
为实现并发程序设计,操作系统应当提供必要的支持:主要有创建进程/子进程机制,进程间通信,以及支持线程机制。它们均以系统调用命令的形式为上层软件服务。
9.2.1 创建进程/子进程机制
创建子进程的机制有多种,下面给出几种常见的形式:
1、fork机制:
在UNIX系统中,fork( )表示创建一个子进程,在管道通信部分已见过fork( )的使用例子。此外还有join语句用于汇合进程。
2、cobegin/coend机制:
表示从cobegin到coend之间的每条语句包括嵌套cobegin/coend和复合语句,都以子进程的形式运行。也就是说,操作系统为最外层的cobegin/coend创建一个进程,然后为其内的每条语句分别创建各自的子进程。当所有子进程并发地执行完毕时,父进程才结束运行。
3、显式进程说明:
某些高级语言中提供有关进程的显式说明语句,被说明的进程显式启动后才开始并发执行。一般形式如下:
process p <说明部分> begin … end;
其中保留字process表示“进程”,p为进程名,<说明部分>定义进程内部使用的常量、类型、变量、过程、函数以及其它进程。begin与end之间的语句即为进程内部的语句,表示该进程所执行的活动。进程p启动以后进程内部的语句及子进程也同时被启动。
为了提高灵活性,引入了进程类型的概念。进程类型如同整型、数组类型一样说明一个标识符所属类型。有了进程类型,可以通过new命令创建新的进程。下面的例子说明进程类型的用法:
process p
process p1 <p1的说明> begin…end ;
process type p2 <p2的说明> begin…end ;
<p的其它说明>
begin
……
q=new (p2);//创建新进程q,它的类型同p2
……
end ;
9.2.2 进程间通信
并发运行的程序必然要求各进程之间保持互斥、同步、通信关系。我们认为,互斥是一种特殊的同步,而同步又是比较低级的通信。因此可以说,进程间通信(IPC)是操作系统对并发程序设计提供的最强支持。
在集中式系统中,操作系统为并发程序设计提供的支持有:PV操作、条件临界区、管程、开放路径表达式、消息传递,在进程管理部分已作过介绍。
在分布式环境下、操作系统提供通信顺序进程(CSP)、Ada的会合机制、分布进程(DP)、远程过程调用(RPC)。
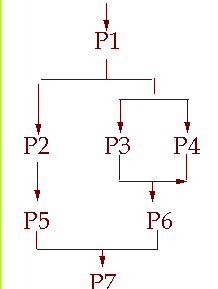
例如,用cobegin/coend机制和PV操作写出如右图所示代码关系的并发程序如下:
begin
s25-7 , s3-6 , s4-6 , s6-7=0;// 信号量置初值
P1的代码;
cobegin
begin p2的代码;p5的代码;V(s25-7);end
begin p3的代码;V(s3-6);end
begin p4的代码;V(s4-6);end
begin P(s3-6);P(s4-6);p6的代码;V(s6-7);end
begin P(s25-7);P(s6-7);p7的代码;end
coend
end
9.2.3 支持线程机制
进程与进程间的耦合关系差,并发粒度过于粗糙,并发实现也不太容易。现代计算机多采用多处理机结构,为多线程并发奠定了硬件基础。线程也称为轻量级进程,其并发粒度小于进程。
为了支持线程并发,现代操作系统提供创建线程/子线程的命令、提供线程同步与通信机制。这部分内容本书已有介绍。
9.3 并发程序设计语言
并发程序设计语言可以分成3类:面向过程的语言、面向消息的语言和面向操作的语言。这3类语言在表达能力上是等价的,是可互换的,即可把用某类语言编写的程序转换成另一类语言编写的程序,而不影响该程序的性能。当然,每类语言强调了不同的程序设计风格。
本小节介绍了并发PASCAL,并发C及Ada语言。远程过程调用留在联网支持部分讨论。
9.3.1 并发PASCAL
并发PASCAL提供进程、管程、类程3种成分和一套组织原则。并发程序是按一定的原则把进程、管程、类程组织起来而得到的。这些组织原则是:
1、进程
进程可以通过参变量方式说明对管程的调用。可以通过申报局部变量的方式说明对类程的调用;
2、管程
管程可通过参变量方式说明对其他管程的调用,可以通过申报局部变量的方式说明对其他类程的调用;
3、类程
类程可以通过申报局部变量方式说明对其他类程的调用,一类程也可以参变量形式传 递给另一类程,但不能传递给进程和管程。
实例的图
下面举一个完整的批处理系统的例子,说明并发PASCAL语言的应用:从卡片机上读入卡片数据到输入缓冲区,经格式变换后拷贝到输出缓冲区,由打印机打印出来。
由于缓冲区是临界资源,所以设置一个管程负责缓冲区的读写管理。从卡片机上读入数据和打印数据分别由2个进程完成。从输入缓冲区到输出缓冲区的拷贝工作由拷贝进程担当,拷贝过程中进行格式变换。格式变换由1个类程负责。考虑到格式变换比较复杂,再设计2个类程,支持格式变换。实例的图如下:
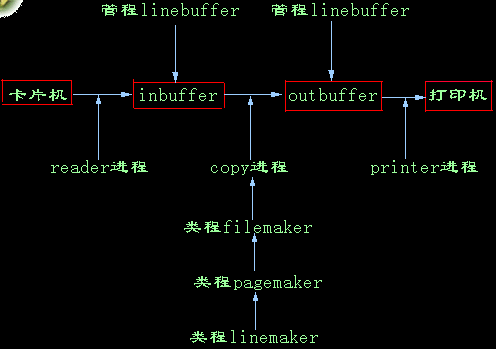
实例程序
下面举一个完整的批处理系统的例子,说明并发PASCAL语言的应用:从卡片机上读入卡片数据到输入缓冲区,经格式变换后拷贝到输出缓冲区,由打印机打印出来。
由于缓冲区是临界资源,所以设置一个管程负责缓冲区的读写管理。从卡片机上读入数据和打印数据分别由2个进程完成。从输入缓冲区到输出缓冲区的拷贝工作由拷贝进程担当,拷贝过程中进行格式变换。格式变换由1个类程负责。考虑到格式变换比较复杂,再设计2个类程,支持格式变换。
下面是并发PASCAL程序清单
************************
* input/output types *
************************
type iodevice = (typedevice, diskdevice, tapedevice, printdevice,
carddevice);
type iooperation = (input, output, move, control);
type ioresult = (complete, intervention, transmission, failure,
endfile,
endmedium,startmedium);
type ioparam = record
operation: iooperation;
status: ioresult;
arg: integer
end;
const linelength = 132;
type line = array (.1..linelength.) of char;
const nl = '(:10:)'; ff = '(:12:)';
************************ 返 回
* initial process * ** 初启进程,相当于主程序 **
************************
var inbuffer, outbuffer: linebuffer;
reader: cardprocess;
copier: copyprocess;
printer: printerprocess;
begin
init inbuffer, outbuffer; ** 输入/出缓冲区初始化 **
reader(inbuffer);
copier(inbuffer, outbuffer);
printer(outbuffer);
end;
************************
* linebuffer * ** 管程,管理缓冲区的读写 **
************************
type linebuffer =
monitor
var contents: line; full: boolean;
sender, receiver: queue; ** 并发PASCAL的标准队列类型,只能在管程使用 **
procedure entry receive(var text: line);
begin
if not full then delay(receiver); ** delay,continue,empty是并发PASCAL的队列函数
**
text := contents; full := false;
continue(sender);
end;
procedure entry send(text:line);
begin
if full then delay(sender);
contents := text; full := true;
continue(receiver);
end;
begin full := false end; 返 回
************************
* linemaker * ** 类程,负责“行”,为pagemaker调用 **
************************
type linemaker =
class (buffer:linebuffer);
var image: line; charno: integer;
procedure entry write(text:line);
begen
for charno := 27 to 106 do
image(.charno.) := text(.charno-26.);
buffer.send(image);
end;
begin
for charno := 1 to 26 do
image(.charno.) := ' ';
image(.107.) := n1;
end; 返 回
************************
* pagemaker * ** 类程,负责“页面”更新,满60行为一新页 **
************************
type pagemaker =
class (buffer: linebuffer);
var consumer: linemaker; lineno: integer;
procedure newpage;
var text:line;
begin
text(.1.) := ff; consumer.write(text);
text(.1.) := n1; consumer.write(text);
lineno := 1;
end;
procedure entry skip;
begin newpage end;
procedure entry write(text:line);
begin
consumer.write(text);
if lineno = 60 then newpage else
lineno := lineno + 1;
end;
begin init consumer(buffer); newpage end;
************************ 返 回
* filemaker * ** 类程,负责格式变换,它调用pagemaker类程 **
************************ ** 中的过程skip和write定义自已的write过程 **
type filemaker =
class (buffer: linebuffer);
var consumer, pagemaker, eof, boolean;
function more(text:line): boolean;
var charno: integer;
begin
if text(.1.)<>'#' then
more := true else
begin
charno := 80;
while text(.charno.) = ' ' do
charno := charno - 1;
more := (charno <>1);
end;
end;
procedure entry write(text:line);
begin
if eof then
begin consumer.skip; eof := false end;
if more(text) then
consumer.write(text) else
begin consumer.skip; eof := true end;
end;
begin init consumer(buffer); eof := true end; 返 回
************************
* cardprocess * ** 读卡进程 **
************************
type cardprocess =
process (buffer: linebuffer);
var param: ioparam; text, error:line;
charno: integer;
begin
for charno := 1 to 80 do error(.charno.) := '?';
param.operation := input;
with param do
cycle
repeat io(text, param, carddevice)
until status<>intervention;
if status<>complete then text := error;
buffer.send(text);
end;
end;
************************
* copyprocess * ** 拷贝进程 **
************************
type copyprocess =
process (inbuffer,outbuffer:linebuffer);
var consumer: filemaker; text: line;
begin
init consumer(outbuffer);
with inbuffer,consumer do
cycle receive(text); write(text)
end; ** 重复执行语句cycle,在操作系统或实时系统设计 ** 返 回
end; ** 中该语句是经常被使用的 **
************************
* printerprocess * ** 打印进程 **
************************
type printerprocess =
process (buffer:linebuffer);
var param: ioparam; text: line;
begin
param.operation := output;
cycle
buffer.receive(text);
repeat io(text, param, printdevice)
until param.status = complete;
end;
end;
对上述程序有几点说明
9.3.2 并发C
1、CSP有如下几种基本操作命令:
(1)输入命令:
<进程名> ? <目标变量> 其功能是由执行进程接受来自<进程名>指定的进程的消息,该消息送入执
行程序的<目标变量>;
(2)输出命令:
<进程名> ! <表达式> 其功能是输出命令中的<表达式>所表示的消息输出到由<进程名>指定的进
程。
(3)选择命令:
[G1→C1 G2→C2 ... Gn→Cn] 其功能是,如果所有的G为“失败”则该选择命令失败,执行该命令的进程夭折。如果至少有一个G为“成功”,则非确定性地选择其中之一。
(4)重复命令:
*<选择命令> 其功能是重复执行选择命令直至所有警卫条件都失败为止,控制转向后继命令;
(5)进程定义命令:
<进程名>::<进程的命令表>;
(6)平行命令:
[<进程> {|| <进程>}] 用于表示进程的并发执行。
2、并行C语言的五种机制
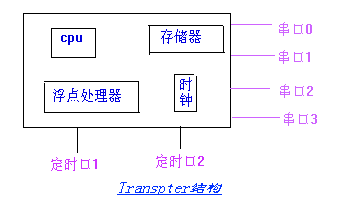
(1)配置
包括硬件配置和软件配置,硬件配置的说明如下例所示:
processor host
processor root
wire ? host[0] root[0]
其中,processor语句说明了2个处理机一个是host,另一个是Transputer root;wire语句说明了真实的物理连线,在此例中root的0号端口与host的0号端口相连。
软件配置说明哪些软件应运行于哪些处理机上,其中task语句指明了任务所拥有的输入输出端口的个数。例如:
task upper ins=2,outs=2
说明名叫upper的任务,它有2个输入端口,有2个输出端口。plase语句把任务分配到具体的处理机上。例如:
place upper root
place filter root
place afserver host
将3个任务分别分配到处理机root和host上。任务间的通信通道由connect语句建立,如果需要双向通信,则要建立2条通道。例如:
connect ? filter[0] afserver[0]
connect ? afserver[0] filter[0]
在任务filter和afserver之间的端口0上建立了2条通道,用于双向通信。由此可见,并发C语言支持多个任务在多个Transputer上并发运行。
(2)线程机制
并发C语言的库函数中的thread package(线程软件包)支持创建、挂起、中止、运行线程。各线程可以共享代码和数据。线程与创建它的任务之间借助内部通道或外部变量交换数据。任务可以包含1个或多个线程,各线程在任务中并发执行。
线程机制保证同一个任务的各线程运行在同一处理机上。
(3)通信机制
并发C语言中的通信是以chan package(通道软件包)来实现的,该软件包定义了通道类型CHAN、通道初始化过程、通道接受和传送信息的过程等。例如4个过程:
chan_in_byte 从通道输入1个字节
chan_out_byte 从通道输出1个字节
chan_in_message 从通道输入1个消息
chan_out_message 从通道输出1个消息
(4)互斥机制
sema软件包中的函数和过程允许并发C程序创建信号量,用于控制各线程的同步与互斥。例如:
sema_init 对信号量置初值
sema_signal 唤醒等待在信号量上的线程
sema_wait 使调用线程挂在信号量上等待唤醒
(5)处理机场(processor farm)
通常将任务按照事先写好的配置文件分配到各处理机上,但有时需要任务本身自动地配置到任意的处理机上。处理机场能实现这一功能。应用中的主任务负责划分作业成为几个独立运行的子任务。子任务作为工作包,根据编译器提供的路径软件,自动地分配到任意的处理机上去。工作包接受数据,进行处理,然后按原路径返回结果。
实例1(五哲学家吃通心粉)
下面是五位哲学家吃通心粉的例子。每位哲学家都要进入餐厅(room),拿起叉子(fork)然后思考(THINK),进食(EAT),最后离开。我们设置餐厅进程room,叉子进程fork,哲学家进程phil,它们的命令表分别为ROOM,FORK,PHIL,那么3个进程并发执行的命令是:
[room || fork || phil]
其中ROOM,FORK,PHIL的描述如下:
ROOM = occu := 0 integer;
*[(i:0..4); phil(i) ? enter()→occu := occu +1
(i:0..4); phil(i) ? exit()→occu := occu -1]
** 主要记录哲学家的进入和退出餐厅。 **
FORK=*[phil(i) ? pickup ()→phil(i) ? putdown()
phil((i-1) mod 5) ? pickup ()→phil((i-1) mod 5) ? putdown()]
** 对每把叉子来说,不是被右边的哲学家拿起,然后放下,就是被左边的哲学家拿起,然后放下。这是一条重复命令。 **
PHIL=*[THINK;
room ! enter();
for (i) ! pickup(); fork((i+1) mod 5) ! pickup();
EAT;
fork(i) ! putdown(); fork((i+1) mod 5) ! putdown();
room ! exit()]
** 哲学家在思考,当感到饥饿时走进餐厅坐下,拿起左边的叉子,再拿起右边的叉子,便可进食通心粉。吃完后先放下左边 叉子,再放下右边叉子,离开餐厅。
**
由上例可见,CSP程序结构简练,表达清晰,然而,C.Hoare的意图不是设计一个完整的语言,而是提出一种简单有效的程序构造模型。
实例2(并发C实现矩阵乘法)
用并发C语言编写矩阵乘法c=a*b (其中a,b,c均为阶数为ASIZE的方矩,ASIZE为偶常量,ASIZED2=ASIZE/2)的并发程序,可将a,
b分别分解成
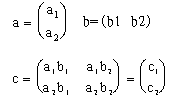
图 解
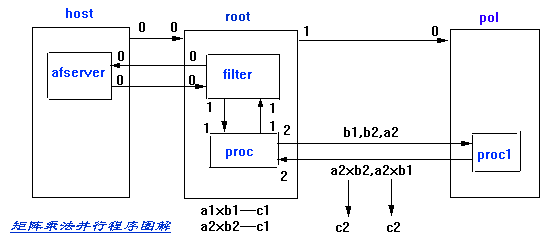
该程序由任务proc0和proc1组成,proc0计算a1b1和a1b2 , proc1计算a2b1和a2b2。
proc0中所定义的主要数据结构和程序步骤如下(非主要步骤以注释形式给出):
float a[ASIZE][ASIZE],b[ASIZE][ASIZE],
c[ASIZE][ASIZE],
a1[ASIZED2][ASIZE],a2[ASIZED2][ASIZE],
b1[ASIZE][ASIZED2],b2[ASIZE][ASIZED2],
c1[ASIZED2][ASIZE],c2[ASIZED2][ASIZE];
/* 将a,b赋初值,然后再将值赋给相应的a1, b1, a2, b2 */
/* 以下向proc1任务发送a2, b2, 让proc1去计算a2′b2 */
chan_out_message(sizeof(a2),a2,out_ports[2]);
chan_out_message(sizeof(b2),b2,out_ports[2]);
/* proc0计算a1′b1 */
/* proc0从proc1接收a2*b2的结果,存于c2中 */
chan_in_message(sizeof(c2),c2,in_ports[2]);
/* 将b1的值传给proc1,让它去计算a2′b1 */
chan_out_message(sizeof(b1),b1,out_ports[2]);
/* proc0计算a1′b2的值 */
/* 等待从proc1输入a2′b1的结果,存于c2中 */
chan_in_message(sizeof(c2),c2,in_ports[2])
/* 至此a1b1,a1b2,a2b1,a2b2的结果均已算出,便可以得到c的最后解答了 */
proc1所定义的主要数据结构和程序步骤如下:
float a2[ASIZED2][ASIZE],b1[ASIZE][ASIZED2],
b2[ASIZE][ASIZED2],c2[ASIZED2][ASIZE];
/* proc1首先接收来自proc0的a2,b2 */
chan_in_message(sizeof(a2),a2,in_ports[0]);
chan_in_message(sizeof(b2),b2,in_ports[0]);
/* 计算a2′b2的结果,存于c2中 */
/* 将c2返回proc0 */
chan_out_message(sizeof(c2),c2,out_ports[0]);
/* 接收从proc0传来的b1 */
chan_in_message(sizeof(b1),b1,in_ports[0]);
/* 计算a2′b1,存于c2中 */
/* 将c2返回给proc0*/
chan_out_message(sizeof(c2),c2,out_ports[0]);
本例的配置程序如下:
processor host
processor root
processor pol
wire ? host[0] root[0]
wire ? root[1] pol[0]
task afserver ins=1 outs=1
task filter ins=2 outs=2 data=10k
task proc0 ins=3 outs=3
task proc1 ins=1 outs=1
place afserver host
place proc0 root
place proc1 pol
place filter root
connect ? afserver[0] filer[0]
connect ? filter[0] afserver[0]
connect ? filter[1] proc0[1]
connect ? proc0[1] filter[1]
connect ? proc0[2] proc1[0]
connect ? proc1[0] proc0[2]
9.3.3 Ada语言
Ada是按美国国防部1975年的建议而设计和研制的三军公用军用计算机语言,1985年10月,Ada成为美国联邦信息处理标准(FIPS)。最新版本为Ada
95,它是面向对象的,支持分布式系统设计,具有强大并发功能的语言。Ada语言有4种程序单元:子程序、程序包、类属单元和任务。前3种用于顺序程序设计,任务用于并发进程的同步和通信。
会合机制
任务T1调用任务T2的入口过程E(...),其程序描述如下:
task T1 is
┇
T2.E(A1,A2); 该入口调用语句调用任务T2的过程E(...)
┇
end
task T2 is
enter E(F1: in类型,F2: out类型);
┇
end
task body T2 is
<局部实体说明>
begin
┇
accept E(F1: in类型,F2: out类型) do
<实现E过程的语句序列>
end; 该接受语句accept的语句结束符号end
┇ 其他语句
end 任务T2的body部分结束。
会合机制对上述程序的任务T1和T2作如下规定:
A.若T1的入口调用T2.E(A1,A2)先到达,T2的accept E(...) do...end尚末到达,则T1等待直到T2执行到accept
E(...)do...end才能把参数A1传递给F1(注意,这是输入类型),执行完accept后传F2(注意,这是输出类型)到入口调用的A2。至此,会合结束,T1,T2各自独立前进。
B.若T2的accept E(...)do...end先到达,情况正好与上述的相反。
C.当有多个任务使用T2.E(...)时,可以想象在accept语句面前形成了一个“入口队列”,此时T2作为服务任务,每次只能会合一个入口调用,即以互斥方式传递消息。当入口队列为空时,T2才能继续执行accept语句的后继语句。
思考与习题
1. 在单处理机环境下,顺序执行与并发执行一个用户程序,哪种方式能先完成作业?说明其原因,在分布式或多处机环境下,又将如何?
2.在集中式环境下,有哪几种用于进程同步和通信的机制?在分布式环境下,有哪几种用于进程同步和通信的机制? 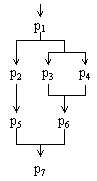
3.操作系统为了支持并发程序运行,应提供哪几种机制?
4.有哪几类支持并发程序设计的语言,各类的代表性语言是什么?
5.若给定一如左图那样的复合关系,你能单用cobegin-coend或单用PV操作或合用两者写出并发程序框架吗?
6.试用并发PASCAL编写如下问题的程序:3个工作站点的服务员接受托运行李后磅称重量,并从终端打入班次、旅客姓名、目的地等数据。显然3个工作站是彼此完全独立的、并行工作的,但他们却共用一台计算机,用以收集和加工来自3个工作站的数据,并把数据存入磁盘。计算机上只连1台打印机,列印行李托运清单。该系统的结构如图:
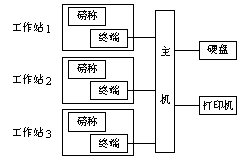
3个工作站的工作次序是完全随机的。工作速度也不一致,但都必须满足以下2个条件:(1)数据写盘应一次完成,不允许写盘过程中断;(2)数据打印也应一次完成。这2条保证数据的一致性。[提示:3个工作站进程,每个进程的程序都是相同的。就一个进程而言,主要干两件事,一是收集数据(接受终端录入),二是数据写盘和数据打印。收集数据用一个私有类程完成。硬盘和打印机是临界资源,设置一个管程管理它们,管程控制一个写盘类程和二个写打印机类程(一个写行/页,另一个控制打印I/O)]。
7.利用矩阵乘法的并发C语言程序,试给出解线性方程组的并行算法。
8.试用Ada任务机制,实现开放路径表达式path (E, F); 1: (C, D; G)
end,假定过程E, F, C, D, G的代码已经存在。
9.能用PV信号量机制实现Ada的会合机制吗?如能,请写出实现过程。如不能请说明理由。
|