| UMLШэМўЙЄГЬзщжЏ | |||
| |
|||
|
|||
зМБИ XML МАЯрЙиММЪѕШЯжЄПМЪдЃЌЕк 4 ВПЗж: XML зЊЛЛ
зїепЃКMark Lorenz ЁЁРДдДЃКIBM
| XML зЊЛЛ зЊЛЛ XML ЭЈГЃЩцМАЕНЯТСаММЪѕЃК
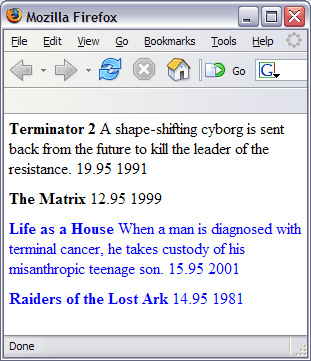
XML ЪЕР§ЮФЕЕ БОНЬГЬМЬајЪЙгУЕк 3 ВПЗжжаЕФ DVD ФПТМЪОР§ XML ЮФЕЕЃЈЧыВЮдФВЮПМзЪСЯЃЉЁЃЮЊСЫЗНБуЦ№МћЃЌЧхЕЅ 1 жиаТСаГіСЫИУЮФЕЕЁЃБОНЬГЬжаБраДЕФДѓВПЗжзЊЛЛЖМЪЧеыЖдетИіЮФЕЕЕФЁЃ ЧхЕЅ 1. DVD ФПТМ XML ЪЕР§ЮФЕЕ
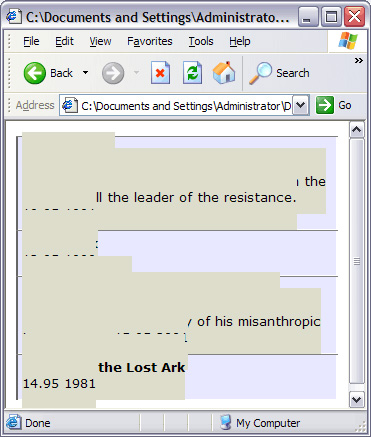
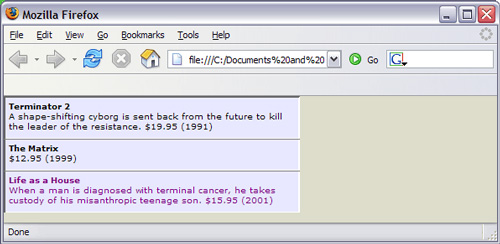
КѓУцЛЙгавЛИіЙигкЭјеОЕиЭМЕФ XML ЪЕР§ЮФЕЕЁЃ ЦцУюЕФЪЧЮвУЧПЩвдПДЕНетаЉЪїЃЌВЛдйИаЕНЮоЫљЪЪДгЁЃ -- Ralph Waldo Emerson гаЪБКђЮвУЧЫЕ XML ВЛЪЧвЛжжБрГЬгябдЁЃШчЙћВЛАќРЈ XSLT етбљЫЕОЭЭъШЋ ЖдСЫ ЁЊЁЊ XSLT БОЩэЪЧ XMLЃЌВЂЧввбОжЄУїЪЧЭМСщЭъећЕФЁЃетОЭЪЧЫЕЃЌФњПЩвдЪЙгУ XSLT жДааЯжДњМЦЫуЛњФмЙЛЭъГЩЕФШЮКЮМЦЫуЁЃ XSLT БОжЪЩЯЪЧвЛжжЩљУїадЯЕЭГЃЌЫќЩљУїСЫдк XML ЮФЕЕжагіЕНЬиЖЈЕФдЊЫиРраЭЪБЛсЗЂЩњЪВУДЁЃXSLT ВЛЪЧБрвыЕФЃЌЯрЗДЃЌЫќвдМА XML ЪфШыЮФЕЕвЛЦ№гЩбљЪНБэДІРэГЬађНтЪЭЃЌБШШч Xalan Лђ Microsoft XML Core Services (MSXML)ЁЃПЩвдАбЫќЕФгУЗЈПДзївЛИіЪ§бЇЙЋЪНЃКXSLT( XML ) = ЪфГіЁЃ гЩгк XSLT ЕФУћГЦжагабљЪНБэ етИіДЪЃЌБрГЬЩчЧјжагаШЫОЭШЯЮЊ XSLT ВЛОпБИБрГЬгябдФЧбљЕФЧПДѓЙІФмЃЌНіНіЪЧФГжжРрЫЦМЖСЊбљЪНБэЃЈCSSЃЉЕФЖЋЮїЁЃВЂВЛЪЧПДВЛЦ№ CSSЃЌВЛЙ§пѕпѕЁЁЫфШЛВЛЯёЦфЫћЖрЪ§гябдФЧбљМђНрЁЊЁЊКмДѓГЬЖШЩЯЪЧвђЮЊБиаыБЃжЄНсЙЙСМКУадЁЊЁЊXSLTЃЈгы XPath ЯрНсКЯЃЌКѓепЬсЙЉСЫЫбЫїКЭБщРњ XML ЪїНсЙЙвдМАжДаазжЗћДЎКЭЪ§бЇВйзїЕФЪжЖЮЃЉвВФмЬсЙЉЗсИЛЕФЙІФмЁЃКѓУцЬжТлЕнЙщЕФЪБКђОЭЛсПДЕНвВПЩвдаДГіЗЧГЃгХУРЕФДњТыЁЃ ЯТУцЕФеТНкНЋЫЕУїШчКЮВЩгУ XSLT КЭ XPath Дг XML ЮФЕЕжаМьЫїЪ§ОнЁЃЖрЪ§Р§згжаЃЌЪ§ОнзюжеБЛИёЪНЛЏЮЊ HTMLЁЃ Web фЏРРЦїФкВПЕФзЊЛЛ ЫфШЛЯТУцЕФЪОР§ДњТыЖММйЖЈзЊЛЛдкЗўЮёЦїЩЯЛђеп XMLSpy жЎРрЕФЛЗОГЯТжДааЃЌВЛЙ§етаЉзЊЛЛжЛвЊЩдМгаоИФЛђепВЛзіаоИФвВФмдкжЇГж XSLT ЕФзюаТАцБОЕФфЏРРЦїжаЭъГЩЃЌБШШч Mozilla Firefox КЭ Microsoft Internet ExplorerЁЃдкетаЉфЏРРЦїжаВщПД XML ЮФЕЕашвЊРрЫЦЯТУцЕФжИСюЃЌетЬѕжИСюгІИУЗХдк XML ЪфШыЮФЕЕЕФЮФЕЕађбджаЃЌ<?xml version="1.0"?> БъЧЉЕФЯТЗНЁЃНЋ href ЪєадИФЮЊЪЪЕБЕФжЕЃЌПЩвдЪЧОјЖдЛђЯрЖд URLЃК
ИљдЊЫи ШЮКЮ XSL зЊЛЛЕФИљдЊЫиЛђЖЅВудЊЫиЁЊЁЊЫљгаЦфЫћзгНкЕуЖМЧЖЬздкЦфжаЃЌЖМЪЧ xsl:stylesheet Лђ xsl:transform дЊЫиЁЃПЩвдЪЙгУЦфжаЕФШЮКЮвЛИіЃЌЫќУЧЕФвтвхвЛбљЁЃПЩвдаДЮЊЃК
ЛђепЃК
ШЛКѓгІИУдкЮФЕЕЕФзюКѓЗжБ№ЪЙгУ </xsl:stylesheet Лђ </xsl:transform> ЙиБеетаЉБъЧЉЁЃвђДЫЃЌБОНЬГЬжаНЛЛЛЪЙгУбљЪНБэ КЭзЊЛЛ СНИіДЪЁЃ ФЃАхдЊЫи xsl:template дЊЫиАќКЌвЛзщЙцдђЃЌПЩгІгУгк XML ЪфШыЮФЕЕжаЕФЬиЖЈдЊЫиЁЃУПИі xsl:stylesheet Лђ xsl:transform БиаыжСЩйАќКЌвЛИі xsl:template дЊЫиЁЃXSLT БрГЬЕФЗсИЛаджївЊдДгкПЩЪЙгУЗжБ№ЗўЮёгкВЛЭЌФПЕФЕФЖрИіФЃАхзїЮЊТпМФЃПщЁЃПЩвдЭЈЙ§ match ЪєадРДДЅЗЂФЃАхдЊЫиЛђепЭЈЙ§ name ЪєаджБНгЕїгУЁЃ match ЪєадЕФгУЗЈКмМђЕЅЁЃгіЕН match ЪєаджЕЫљЙцЖЈЕФЗЖЪНЪБМДжДааИУЙцдђЁЃБШЗНЫЕЃЌПЩЪЙгУЯТСаЙцдђШЗЖЈЮФЕЕжаАќКЌзжЗћДЎЁАAnother DVDЁБЕФУПИі dvd дЊЫиЃК
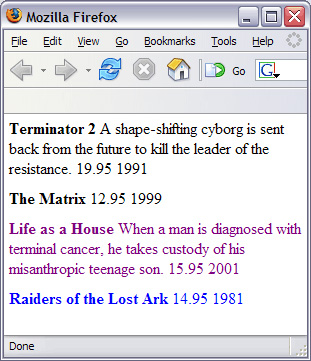
зЊЛЛЕФЪфГіНсЙћШчЯТЃК
вЊзЂвтЃЌЖдЪфШыЮФЕЕжаУПИі dvd дЊЫиЖМЛсжДаавЛДЮФЃАхЙцдђЁЃУПДЮдкЪфШыЮФЕЕжагіЕН dvd дЊЫиЪБЖМЛсЕїгУИУЙцдђЁЃ xsl:apply-templates КЭ xsl:value-of ШчЙћФмНЈСЂгыГ§ dvd жЎЭтЕФЦфЫћдЊЫиЖдгІЕФФЃАхЙцдђНЋЗЧГЃгагУЁЃЪТЪЕЩЯЃЌвВФмНЈСЂгыЦфЫћдЊЫиЦЅХфЕФФЃАхЃК
ЮоТлФФжжЧщПіЃЌ<xsl:value-of/> БъЧЉЕФ select ЪєаджЕЖМЪЧвЛжжЗЖЪНЃЌЫќИјГіСЫЕБЧАЗжЮідЊЫиЛђепЩЯЯТЮФНкЕу ЕФЮФБОжЕЁЃЩЯУц select ЪєаджЕжаЁА.ЁБЫљБъМЧЕФ XPath БэДяЪНЪЧЗДЩэжсЁЃ ФЃАхБъЧЉжаЕФ match ЪєаджЕвВЪЧвЛИі XPath БэДяЪНЁЃетРяЕФЩЯЯТЮФНкЕугЩФЃАхЦЅХфШЗЖЈЁЃЩшжУЩЯЯТЮФНкЕуЕФЦфЫћЗНЪНАќРЈЪЙгУ xsl:apply-templates КЭ xsl:for-eachЁЃ ЩЯУцСНИіФЃАхВЛНіМьЫї title КЭ price ЕФжЕЃЌXML ЪфШыЮФЕЕжаЕФЦфЫћФкШнвВЛсЯдЪОЁЃШчЙћвЊНіНіЯдЪО title КЭ price дЊЫиЕФжЕЃЌЛЙашвЊдіМгвЛЬѕФЃАхЙцдђЃК
етРяЛЙдіМгСЫвЛЕу HTML ИёЪНЛЏГЩЗжЃЈ<p/> БъЧЉЃЉЁЃЪфГіНсЙћШчЯТЃК
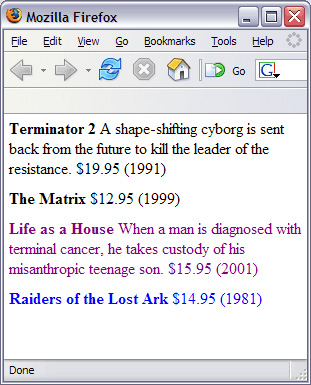
ЕїгУФЃАх Г§ЩЯЪіЗНЗЈвдЭтЃЌЛЙПЩвдУїШЗЕїгУ ЯдЪО dvd ЕФзгдЊЫи title КЭ price ЕФФЃАхЃЌетжжЗНЗЈДјРДСЫаТЕФПЩФмадЁЃетжжЧщПіЯТЃЌЭъећЕФзЊЛЛШчЯТЫљЪОЃК
ЮЊСЫдіМгПЩЖСадЃЌБъЬтжаЕФСЌзжЗћКЭМлИёжаЕФУРдЊЗћКХвЦЕНСЫУќУћФЃАх Title КЭ Price жЎжаЁЃЯТУцЕФЪфГіНсЙћгыЩЯвЛИізЊЛЛЭъШЋЯрЭЌЃК
xsl:call-template БъЧЉЕФ name Ъєадв§гУ name ЪєаджЕгыЦфЯрЭЌЕФФЃАхЃЌВЛТлЪЧЁАTitleЁБЛЙЪЧЁАPriceЁБЁЃЭЈЙ§ name ЪєадЖјВЛЪЧ match ЪєадЕїгУЕФФЃАхГЦЮЊУќУћФЃАхЁЃЭЈЙ§УќУћФЃАхПЩвдЪЕЯжДњТыЕФФЃПщЛЏЁЃКѓУцНЋПДЕНЃЌНсКЯЪЙгУУќУћФЃАхКЭ <xsl:import/> Лђ <xsl:include/>ЃЈгУгкЬэМгЭтВПЮФМўЃЉПЩвдИљОнашвЊАбФЃАхЛЛНјЛЛГіЁЃXSLT жаУќУћФЃАхЕФСэвЛИіживЊгУЭОЪЧЪЕЯжЕнЙщБрГЬЁЃ ЕќДњ МЬајЪЙгУ catalog.xml зїЮЊР§згЪфШыЮФЕЕЃЌЮвУЧПДШчКЮЖдвЛзщдЊЫижиИДЪЙгУвЛИіФЃАхЙцдђЁЃетжжЧщПіЯТЃЌЩЯЯТЮФНкЕуЪЧИљдЊЫи catalogЁЃВЛгУЩЯЪіЭЈЙ§ЦЅХфдЊЫиРДМЄЛюФЃАхЙцдђгІгУЕФЗНЗЈЃЌПЩвдЭЈЙ§ <xsl:for-each/> БъЧЉЪЙгУЕќДњЁЃ ЪзЯШЃЌЮвУЧРДПДПДШчКЮЪЙгУ xsl:for-each бЛЗБщРњФПТМжаЕФУПИі dvd дЊЫиЃК
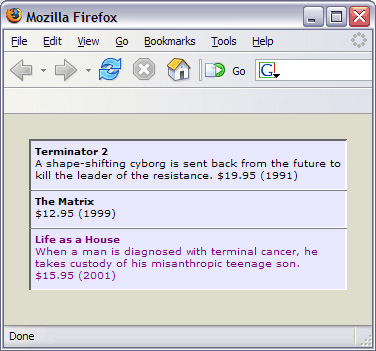
зЂвтЃЌЮЊСЫБугкдкфЏРРЦїжаЯдЪОЃЌЦфжадіМгСЫвЛаЉ HTMLЁЃЙлВь xsl:for-each БъЧЉЕФФкШнЃЌПЩвдПДЕНЕїгУСЫвЛИіУќУћФЃАх DVDЁЃDVD ФЃАхПЩФмАќКЌЯТУцЕФЯдЪОТпМЃК
ЩЯУцЕФР§згв§ГіСЫМИИіаТЕФИХФюЁЃЪзЯШЃЌгавЛИіУћЮЊ label ЕФ xsl:variableЁЃвЊзЂвтЃЌИУБфСПШЁЕУСЫ dvd дЊЫиЕФ code ЪєаджЕЃЌЪЙгУСЫЧАзКЁА@ЁБЁЃДЫЭтЃЌЛЙгІзЂвт xsl:for-each АДееЫГађНЋЩЯЯТЮФНкЕузЊвЦЕНУПИі dvd дЊЫиЁЃетвЛЕуПЩгЩЩЯУцЕФ DVD ФЃАхПДГіРДЃЌвђЮЊФмЙЛжБНгв§гУ @code ЪєадКЭ title дЊЫижЕЃЌетСНИіЖМЪЧ dvd дЊЫиЕФКЂзгЁЃетаЉЯрЖд XPath БэДяЪНБэУїЃЌxsl:for-each НЋЩЯЯТЮФНкЕузЊвЦЕНСЫУПИі dvd дЊЫиЁЃ ЦфДЮЃЌаТНЈЕФ label БфСПгУгкДДНЈ <img/> БъЧЉЃЌСщЛюЕиЩшжУаТЕФ HTML ИёЪНЁЃЃЈетРяМйЩшУПеХ DVD дк images/ ФПТМжаЖМгаЖдгІЕФЭМЦЌЁЃУПЗљЭМЦЌЖМЪЧгУ DVD ЕФ code ЪєаджЕзїЮЊздМКЕФЮФМўУћЁЃЃЉвЊзЂвтЮЊСЫЕУЕНБфСПЕФжЕдкЦфЧАУцМгЩЯСЫУРдЊЗћКХЃЈЁА$ЁБЃЉЃЌВЂЧвКЭ xsl:value-of дЊЫиРрЫЦгУЛЈРЈКХЃЈЁА{ЁБКЭЁА}ЁБЃЉАќЮЇЦ№РДЁЃЃЈЕБШЛЃЌИУР§жаИљБОВЛашвЊДДНЈБфСПЃЌПЩвджБНгдк img БъЧЉжав§гУ @code ЪєадЕФжЕЃК<img src="images/{@code}.gif" alt=""/>ЁЃЃЉ НЋетаЉНсКЯдквЛЦ№ЃК
ЩЯЪізЊЛЛЕУЕНЕФНсЙћШчЯТЃК
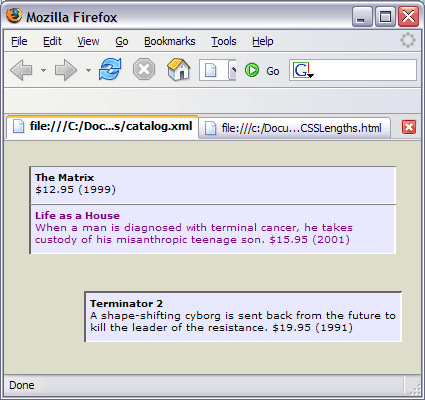
ИёЪНЛЏЪфГі ФњПЩФмзЂвтЕНЃЌЩЯУцЕФЪфГіЧАУцУЛгаСЫ <?xml?> БъЧЉЁЃгаСНИідвђЃЌШЮКЮвЛИіЖМЛсЕМжТЪфГізїЮЊ HTML ДІРэЁЃЪзЯШЃЌНєИњдк <xsl:stylesheet> ПЊЪМБъЧЉжЎКѓдіМгСЫ <xsl:output method="html"/>ЁЃxsl:output ЕФ method ЪєадЭЈГЃШЁжЕЮЊ html Лђ xmlЁЃxsl:output БъЧЉСэЭтвЛИіживЊЕФБъЧЉЪЧ encodingЃЌЫќЖЈвхСЫЪфГіЕФзжЗћМЏЃЌдк method ЪєаджЕЮЊ xml ЪБЪЙгУЁЃ<?xml?> БъЧЉЯћЪЇЕФСэвЛИідвђЪЧЖрЪ§бљЪНБэДІРэГЬађЖМзЂвтЦЅХфФЃАхжаЪЧЗёЪЙгУСЫ HTML БъЧЉЃЌШч <html/> КЭ <body/>ЁЃШчЙћгаЕФЛАЃЌдђАбЪфГі method здЖЏзїЮЊ HTML ДІРэЁЃ ХХађНсЙћ xsl:for-each гавЛИігагУИНМў xsl:sortЁЃЃЈвВПЩгУгк xsl:apply-templatesЁЃЃЉПЩвдЪЙгУИУБъЧЉзїЮЊ xsl:for-each ЕФЕквЛИідЊЫиЃЌИљОнФГИіМќЪЙНсЙћАДееЮФЕЕЫГађ жЎЭтЕФЦфЫћЫГађХХСаЁЃБШЗНЫЕЃЌЩЯР§жаЕФ xsl:for-each ПЩЪЙгУ xsl:sort АДее title ЪєаджЕРДХХСа DVD СаБэЃК
НЋЩЯУцДжЬхЯдЪОЕФЮФБО xsl:sort ВхШыЕНЧАР§жаЃЌПЩЕУЕНШчЯТНсЙћЃК
ПЩвдПДЕН DVD ЯждкАДееБъЬтЕФзжФИЫГађХХСаЁЃдкЕквЛИіжЎКѓЛЙПЩвдМгЩЯЦфЫћ xsl:sort дЊЫиРДЖдНсЙћМЏНјвЛВНХХађЁЃ ЕнЙщ ЭЈЙ§ЕнЙщЪЕЯжЧАУцЕФ DVD СаБэзЊЛЛПДЦ№РДгаЕуЙжЃЌвђЮЊЃК ЩЯЪіЪЙгУ xsl:for-each ЕФЕќДњНтОіЗНАИЃЌЖдгкЪьЯЄ Java? етРрУќСюЪН БрГЬгябдЕФГЬађдБРДЫЕИќжБЙлЁЃ
ИУзЊЛЛКЭЕќДњНтОіЗНАИЕФНсЙћЯрЭЌЃК
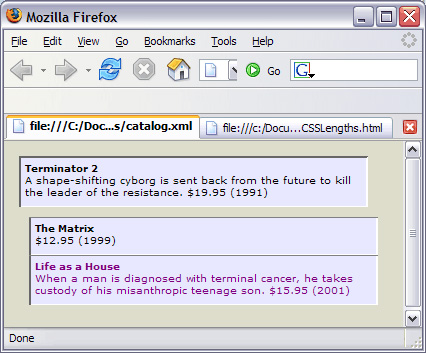
етРяЃЌЦЅХфФЃАхжадкзЊЛЛЕФПЊЪМЭЈЙ§ЕїгУ DVD ФЃАхПЊЪМЕнЙщЁЃШЛКѓ DVD ФЃАхдйЕїгУздЩэЃЌжБЕНДІРэЕНзюКѓвЛИі dvd дЊЫиЁЃ етИіР§згУЛгаЖрЩйжЕЕУзЂвтЕФЕиЗНЁЃжЛгавЛЕуЃЌЩЯЯТЮФНкЕуУЛгазЊвЦЕНШЮКЮвЛИі dvd дЊЫиЩЯЁЃетЪЧвђЮЊ xsl:call-template УЛгаЯё xsl:for-each ФЧбљИФБфЩЯЯТЮФНкЕуЁЃвђДЫЃЌDVD ФЃАхжаЖЈвхЕФБфСПБиаыдк xsl:paramЁЂposition ЕФАяжњЯТв§гУЕБЧА dvd дЊЫиЃЌКѓепБЃДцСЫЕБЧАДІРэЕФ dvd дЊЫиЕФЮЛжУЁЃВЮЪ§ПЩвдЭЈЙ§ <xsl:with-param/> БъЧЉДгФЃАхДЋЕнИјЫќЕїгУЕФУќУћФЃАхЁЃ<xsl:with-param> жЛФмзїЮЊ <xsl:call-template/> БъЧЉЕФзгдЊЫиЁЃБЛЕїгУЕФФЃАхЭЈЙ§ <xsl:param/> БъЧЉЕУЕНетаЉВЮЪ§ЃЌКѓепБиаыНєИњдк <xsl:template/> Ц№ЪМБъЧЉжЎКѓЁЃ ФњПЩФмзЂвтЕНЃЌDVD ФЃАхжаЕФ xsl:paramЁЂposition ДјгаЭЈЙ§ select ЪєадЬсЙЉЕФФЌШЯжЕЁЃвђДЫЃЌЦЅХфФЃАхжаЕквЛДЮЕїгУ DVD ФЃАхЕФЪБКђВЛвЛЖЈвЊЪЙгУЖдгІЕФ xsl:with-paramЁЃЪЙгУ xsl:param БъЧЉЕФФЌШЯжЕЪЧвЛжжКУЯАЙпЃЌПЩвдБмУтдкБЛЕїгУФЃАхжаЗЂЩњвтСЯжЎЭтЕФааЮЊЁЃЃЈШчЙћВЛЪЧЮЊСЫБШНЯСНИіВЮЪ§ЃЌdvdCount вВгІИУгаФЌШЯжЕЁЃЃЉ ДЫЭтвЊзЂвтЃЌдк DVD ФЃАхзюКѓЕФ xsl:call-template жаЃЌНЋ position ВЮЪ§ДЋЕнИјЯТвЛИі DVD ФЃАхЕФЪЕР§жЎЧАдіМгСЫвЛЁЃдк <xsl:if/> ЕФ test ЪєаджаПЩвдПДЕНЃЌетСНИіВЮЪ§ЕФжЕгУдкСЫЕнЙщЭЃжЙЬѕМўжаЁЃ дк DVD ФЃАхжаЛЙЪЙгУ position ВЮЪ§БэУїЕБЧАДІРэЕФЪЧФФвЛИі dvd дЊЫиЁЃетЪЧЭЈЙ§ xsl:variable КЭ xsl:value-of БъЧЉ select ЪєаджагУгкЯоЖЈ dvd ЕФЮНДЪ ЪЕЯжЕФЁЃСНепЖМЪЧ XPath БэДяЪНЃЌБОНЬГЬКѓУцЛЙНЋНјвЛВНЬжТлЁЃXPath ЮНДЪЗХдкЗНРЈКХЃЈЁА[ЁБКЭЁА]ЁБЃЉжЎМфЃЌНєИњдкЫљЯоЖЈЕФдЊЫижЎКѓЁЃИУР§жаЃЌposition ВЮЪ§дкЮНДЪжагУгкБэЪОЕБЧАЫљДІРэЕФ dvd дЊЫиЕФЮЛжУЃКdvd[$position]ЁЃ <xsl:if/> дЊЫиЕФгУЗЈКмМђЕЅЁЃЫќгавЛИіЬѕМўЃЌЭЈЙ§МЦЫуБиашЕФ test ЪєадЕУЕНЃЌНсЙћБиаыЪЧвЛИі Boolean жЕЃЈtrue Лђ falseЃЉЁЃШчЙћЯыжЊЕРЃЌЮвПЩвдИцЫпФњЃЌУЛга <xsl:else/> Лђ <xsl:elseif/> БъЧЉЁЃЕЋЪЧПЩвдЪЙгУ <xsl:choose/>ЃЌКѓУцЛЙвЊНВЕНЁЃзюКѓЃЌвЊзЂвт <xsl:if/> test ЪєаджаЕФаЁгкЗћКХЪЧ XML зЊвхЕФЃЈ<>ЃЉЁЃШчЙћЪЙгУЗЧзЊвхЕФаЁгкКХЃЈ<ЃЉЃЌбљЪНБэДІРэГЬађНЋХзГівьГЃЃЌвђЮЊетИізжЗћвдМАгвМтРЈКХЛђДѓгкКХЃЈ>ЃЉгУгкБэЪО XML дЊЫиЕФПЊЪМКЭНсЪјЁЃ ЭјеОЕиЭМжаЕФЕнЙщ ЯждкПДвЛИіИќЪЪКЯВЩгУЕнЙщЗНЗЈЕФР§згЁЃЧхЕЅ 2 жаЕФ XML ЪОР§ЮФЕЕЯдЪОСЫвЛИіащЙЙЭјеОЕФЕиЭМЁЃЮвУЧашвЊЙЙдьвЛИізЊЛЛРДГЪЯжеОЕуЕиЭМЃЌДгзюЩЯВуЕФвГУцПЊЪМЕнЙщЕиСаГіЫљгазгвГУцЃЌвдМАзгвГУцЕФзгвГУцЁЊЁЊЮоТлЖрЩйВуЁЃзЊЛЛЕФНсЙћЪЧвЛИі HTML ЮФЕЕЁЃ ЧхЕЅ 2. ЭјеОЕиЭМ XML ЪЕР§ЮФЕЕ
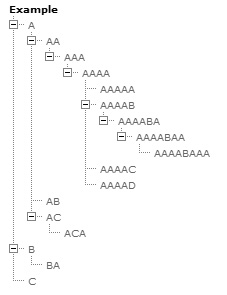
ЧхЕЅ 2 жаЕФЪОР§еОЕуЕиЭМга 4 ВуЩюЃЌВЂАЕЪО HTML вГУцЪЧАДжїЬтзщжЏЕФЁЃзюЩЯВуЕФШ§ИівГУцЃЌlabel ЪєаджЕЗжБ№ЮЊ AЁЂB КЭ CЁЃвГ A гаШ§ИізгвГУцЃЈAAЁЂAB КЭ ACЃЉЃЌЫќЕФЕквЛИізгвГУцгжгаШ§ИізгвГУцЃЈAAAЁЂAAB КЭ AACЃЉЁЃзюКѓЃЌвГУц AAA вВгаздМКЕФзгвГУцЃЈAAAA ЕН AAACЃЉЁЃетПУЪїашвЊГЪЯжЮЊ HTMLЁЃ ЮЊСЫЯдЪОеОЕуЕиЭМЃЌЮвУЧЪзЯШНЈСЂвЛзщЧЖЬзЕФ HTML ЮоађСаБэЃЌЗжБ№ЖдгІУПИіЕМКНВуМЖЁЃДДНЈетИіСаБэЃЌашвЊДгзюЩЯВуПЊЪМЃЌУПДЮЕќДњБщРњвЛИіЕМКНВуЁЃШчЙћЗЂЯжФГИівГУцгазгвГУцЃЌдђНЋЦфзгвГУцЕФСаБэЬэМгЕНЕБЧАвГУцжЎКѓЃЌШЛКѓМЬајбЛЗБщРњЕБЧАЕМКНВуДЮЁЃЫуЗЈЕФЮБДњТыШчЯТЃК
ИУЫуЗЈЪЙгУКмЩйЕФДњТыЃЈжСЩйЖд XSLT РДЫЕЃЉОЭФмДІРэШЮвтЖрВуЩюЕФЕМКНЪїЁЃЫљаш XSLT ДњТыШчДЫМђНрБэУїЫќЗЧГЃЪЪКЯДІРэДЫРрШЮЮёЁЃЯТУцИјГіСЫАДееЩЯЪіТпМБраДЕФзЊЛЛЃЌдіМгСЫвЛЕу HTML гяЗЈЁЃЦфжаЕФзЂЪЭЫЕУїСЫЫуЗЈЕФЫМЯыЃК
вЊзЂвтЧАУцЕФзЊЛЛЪЧЮВЕнЙщЕФЁЃЭЌбљЃЌШчЙћЕБЧАвГУцУЛгазгвГУцЃЌдђТњзуЕнЙщЕФЭЃжЙЬѕМўЃЌгкЪЧОЭВЛдйЕнЙщЕїгУ BuildList ФЃАхСЫЁЃИУзЊЛЛЕФ HTML ЪфГіШчЯТЃК
АбСДНгеЙПЊКѓЃЌHTML ЪфГідкфЏРРЦїжаЕФГЪЯжНсЙћШчЯТЃК
еОЕуЕМКНФЃПщЕФЕнЙщ ПЩвддіМгБШНЯЕБЧАвГУцЃЈЩЯЯТЮФНкЕуЃЉКЭЭјеОЕиЭМжаЫљгадЊЫиЕФТпМЃЌДгЖјАбЩЯЪізЊЛЛзіГЩвЛИіЪїЕМКНФЃПщЁЃетЪЧвђЮЊЭјеОжаЕФУПИівГУцЖМашвЊИљОнздЩэдкЪїжаЕФЮЛжУШЗЖЈздМКЕФЕМКНФЃПщАцБОЁЃЛЙашвЊвЛаЉ JavaScript РДПижЦажЕмвГУцМЏКЯЕФеЙПЊгыелЕўЁЃЭъГЩКѓГЪЯжЕФФЃПщПДЦ№РДРрЫЦгк Microsoft Windows Explorer КЭ Eclipse Navigator ЪгЭМжаЪїПиМўЁЃ ПЊЪМГЪЯжЕФЪБКђЃЌДњБэЖЅВувГУцжЎЭтЕФЫљгаЦфЫћвГУцЕФ HTML дЊЫибљЪНЪєад display ЖМЩшжУЮЊ "none"ЃЈЯъМћКѓУцЕФ CSSЃЉЁЃШЛКѓЪЙгУфЏРРЦїЩЯЕФ JavaScript ТпМеЙПЊДњБэЩЯЯТЮФНкЕуЫљгазцЯШвГУцЕФ HTML БъЧЉЃЌМДНЋЦфбљЪНЪєад display ЕФжЕЩшЮЊЁАblockЁБЁЃЮЊБЃжЄетжжааЮЊЖдУПИівГУцЪЧВЛЭЌЕФЃЌПЩвдМйЩшУПИівГУцдЊЫиЕФ @href ЪєадЖМЪЧЮЉвЛЕФЁЃШЛКѓЪЙгУ xsl:variable БЃДцЩЯЯТЮФНкЕу @href ЪєадЕФжЕЁЃШЛКѓЃЌЕБУПИі page дЊЫиЭЈЙ§УПвЛЕМКНВуЕФЕќДњНгЪеЕНЩЯЯТЮФЪБЃЌОЭПЩвдБШНЯЦф @href ЪєадКЭБЃДцгае§дкГЪЯжЕФвГУц @href ЕФ xsl:variableЁЃетбљЃЌЕБЧАвГУцМАЦфЩЯЫљгавГУцЕФСДНгЖМЛсЯдЪОГіРДЁЃ ШчЙћгаЕФЛАЃЌЫќвВЗЧГЃЪЪКЯЯдЪОЕБЧАвГУцЕФзгвГУцЁЃПЩгУЩЯЪі HTML ЮоађСаБэдЊЫиЛђеп HTML <div/> БъЧЉРДБЃДцУПИіЕМКНВуЁЃетаЉдЊЫивЊЧѓЮЉвЛЕФ id ЪєаджЕЃЌвдБуФмЙЛЭЈЙ§БрГЬЪЙЦфбљЪНЪєаддк display:none КЭ display:block жЎМфЧаЛЛЁЃШчЙћЪЙгУ <div/> БъЧЉЃЌдђашвЊДѓгкСуЕФ padding-left Лђ margin-left бљЪНжЕРДЬсЙЉЫѕНјЁЃетаЉЪЕЯжСєИјЖСепзїЮЊСЗЯАЁЃЮЊСЫУРЙлдіМгМИЗљЭМЦЌжЎКѓЃЌзЊЛЛНсЙћПЩФмПДЦ№РДРрЫЦЭМ 1 жаЫљЪОЕФЪїЕМКНПиМўЁЃИУЭМЪЧЕнЙщ XSLT зЊЛЛЩњГЩ HTML КѓЕФГЪЯжНсЙћЃЌЪЕЯжСЫЧАУцИјГіЕФДѓВПЗжЬсЪОЁЃВЛЙ§ЮвУЛгаЪЙгУЧЖЬздЊЫиЃЌЖјЪЧЭЈЙ§СНИіЪєадгУжИЯђИИНкЕуЕФжИеыРДБэЪОажЕмдЊЫиЁЃЭМ 1 жаЯдЪОЕФЪфГіЪЧдк Internet Explore 6.0 жаЕФГЪЯжНсЙћЁЃ ЭМ 1. ГЪЯжЕФЕМКНФЃПщ дкЯдЪОЕФ HTML жаЃЈВЛЪЧЭМ 1 ЫљЪОЕФЭМЦЌЃЉЃЌЕЅЛїЭМ 1 жаПДЕНЕФМгКХКЭМѕКХПЩвделЕўКЭеЙПЊЯргІЕФзгЪїЃЌЕЅЛїНкЕуЮФБОдђЕМКНЕНЖдгІЕФвГУцЁЃЃЈЮЊСЫЯдЪОећПУЪїЃЌЭМ 1 жаЕФНкЕуШЋВПеЙПЊСЫЁЃЃЉФПБъвГУцМгдиЕНфЏРРЦїжавдКѓЃЌзюГѕЫљгаЕФНкЕуЖМЪЧелЕўЕФЃЌвђДЫжЛФмПДЕНзюЩЯВуЕФвГУцЁЃШЛКѓЃЌДгЕБЧАвГУцПЊЪМЯђЩЯЃЈЪЕМЪЩЯЪЧЯђзѓЃЉеЙПЊЪїжБЕНЖЅВуЃЌЯдЪОГіЕБЧАвГУцЕФЫљгазцЯШвГУцЁЃШчЙћгазгвГУцЃЌДгЕБЧАвГеЙПЊЪївВНЋЭЌЪБЯдЪОЦфзгвГУцЁЃ гЩгк XML ЮФЕЕЕФЧЖЬзЬиадЃЌдйМгЩЯ xsl:variable дЊЫиЪЧВЛПЩБфЕФЃЌПЩвдЗЂЯжЖд XSLT ЕФДѓЖрЪ§ЮЪЬтАДееЕнЙщЕФЗНЗЈЫМПМКЭБраДДњТыДѓгаёдвцЁЃвЛАуРДЫЕЃЌВЩгУЕнЙщЗНЗЈЕФЙиМќдкгкЩшМЦЕФФЃАхЃЌЯё BuildList ФЃАхФЧбљзуЙЛвЛАуЛЏЃЌФмгУгкЫљвЊНтОіЮЪЬтЕФШЮКЮЧщПіЁЃжЛвЊзіЕНетвЛЕуЃЌОЭПЩвддкашвЊЕФЪБКђЕїгУздЩэЁЃ ЬѕМўТпМ дйЛиЕН DVD ФПТМЕФР§згЃЌМйЩшашвЊИљОнМлИёБраДЙигкПтДц DVD ЕФБЈБэЁЃЕЋФПЕФВЛЪЧЯдЪОМлИёЃЌЖјЪЧашвЊАДееМлИёЖд DVD ЗжРрЁЃЮЊДЫашвЊгУЕН xsl:chooseЁЃ ЮвУЧРДаоИФЩЯУцЪЙгУЕФЕќДњНтОіЗНАИЃЌЭЈЙ§ЕїгУЧАУцБраДЕФ Price ФЃАхРДЯдЪОУПИі dvd дЊЫиЃК
ЯждкаоИФ Price ФЃАхЃЌШУЫќЯдЪОШ§ИіаЮШнДЪЃЈЁАЙѓЃЁЁБЁЂЁАБувЫЃЁЁБКЭЁАвЛАуАуЁБЃЉЖјВЛЪЧЪЕМЪМлИёЃК
xsl:choose гаСНИізгдЊЫиЃКвЛИіЪЧБиашЕФЃЌМД xsl:whenЃЌгы xsl:if КмЯрЫЦЃЛСэвЛИіЪЧПЩбЁЕФ xsl:otherwiseЁЃетИіЪЙгУ xsl:choose ЕФзЊЛЛЪфГіНсЙћШчЯТЃК
гыДѓЖрЪ§ XSLT БраДепвЛбљЃЌФњПЩФмВЛЛсИаЕНКмаЫЗмЃЌвђЮЊУЛга xsl:else КЭ xsl:else-if дЊЫиЃЌЖј xsl:choose гжетУДТорТЁЃXSLT 2.0 ЬсЙЉСЫвЛжжНтОіЗНЗЈЃЌЕЋЮвВЛзМБИдкБОНЬГЬжаЬжТлЁЃXML in a Nutshell, 3rd EditionЃЈЧыВЮдФВЮПМзЪСЯЃЉгаКмЖреТНкзЈУХЬжТлXSLT КЭ XPath 1.0 гы 2.0 АцЕФЧјБ№ЁЃ ЕМШыКЭАќКЌЦфЫћЮФМўжаЕФФЃАх xsl:import гы xsl:include етСНИідЊЫиПЩвддкзЊЛЛжаВхШыЦфЫћЮФМўжаЕФФЃАхЁЃетСНИідЊЫижЛФмзїЮЊ <xsl:stylesheet/> Лђ <xsl:transform/> дЊЫиЕФКЂзгГіЯжЃЌЖјЧвБиаыГіЯждкШЮКЮЦфЫћЖЅВудЊЫижЎЧАЁЃгяЗЈШчЯТЃК
КЭ
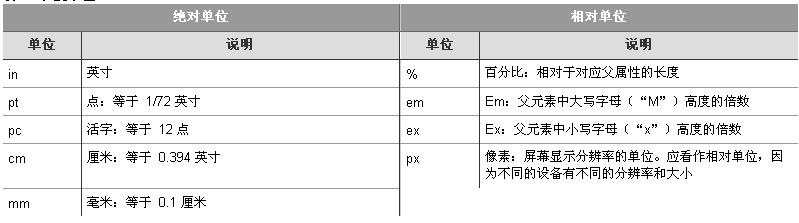
href ЪєадЕФ URI жЕжИЯђАќКЌЫљвЊЬэМгЕФзЊЛЛЕФЮФМўЕФТЗОЖКЭУћГЦЁЃURI жЕПЩвдЪЧЯрЖдТЗОЖвВПЩвдЪЧОјЖдТЗОЖЁЃетСНИідЊЫиЕФЧјБ№ЪЧЃЌЭЈЙ§ xsl:import в§ШыЕФФЃАцдЪаэГіЯжУћГЦГхЭЛЃЌШчЙћЗЂЩњетжжЧщПідђКіТдЕМШыЕФФЃАхЁЃЖјЪєгкгЩ xsl:include в§ШыЕФзЊЛЛЕФУќУћФЃАхЃЌВЛФмгыЕМШыЫќЕФзЊЛЛжаЕФШЮКЮУќУћФЃАхГхЭЛЁЃетаЉЮФМўдк xsl:include ГіЯжЕФЮЛжУжБНгИДжЦЕНЕБЧАзЊЛЛжаЁЃЮоТлФФИідЊЫиЃЌБЛЕМШыКЭЕМШыЮФМўжЎМфЖМВЛдЪаэДцдкбЛЗв§гУЁЃКЭ XML жаЕФЖрЪ§ЪТЮявЛбљЃЌдЪаэЭЈЙ§ xsl:import КЭ xsl:include ЧЖЬзЮФМўЁЃ XSLT аЁНс XSLT ЪЧвЛжжЙІФмШЋУцЕФБрГЬгябдЃЌЖјЧвЦцУюЕФЪЧЫќЧЁЧЁвВЪЧНсЙЙСМКУЕФЁЃдкЯТвЛНкжаНЋПДЕНЃЌXSLT гы XPath НсКЯЦ№РДПЩвдНтОіЖрЪ§МЦЫуКЭИёЪНЛЏЮЪЬтЁЃеЦЮе XSLT ЕФЧЯУХЪЧбЇЛсЪЙгУЧЖЬзЕФУќУћФЃАхЕїгУКЭЪьЯЄЕнЙщЕФЫМЯыЁЃ XPath ВидкЦЛЙћаФжаЕФвЛСЃжжзгЪЧвЛЦЌПДВЛМћЕФЙћдАЁЃ -- Welsh proverb ЩЯвЛНкжаЃЌФњвбОПДЕНСЫШчКЮЪЙгУ XPath в§гУ XML ЪОР§ЮФЕЕжаЕФдЊЫиЁЃБШЗНЫЕЃЌЮЊСЫЗУЮЪЪїжаЕФдЊЫиЃЌЮвУЧЪЙгУСЫ XPath БэДяЪНШч /ЃЈЮФЕЕИљЃЉЁЂpageЃЈашвЊЕФзгдЊЫиРраЭЃЉвдМА ..ЃЈЩЯЯТЮФНкЕуЕФИИдЊЫиЃЉЁЃКѓУцЮвУЧНЋПДЕНЃЌЪЙгУЪЪЕБЕФ XPath БэДяЪНзщКЯФмЙЛЗУЮЪ XML ЮФЕЕжаЕФШЮКЮВПЗжЁЃ XPath ЛЙЬсЙЉСЫМЏКЯЁЂзжЗћДЎКЭЪ§бЇКЏЪ§ЁЃЫфШЛДгМђНрадКЭЙІФмЩЯРДЫЕВЛвЛЖЈБШЕУЩЯЦфЫћЖрЪ§НХБОгябдЃЌШч Perl Лђ JavaScriptЃЌЕЋЖрЪ§ЧщПіЯТЃЌЭЈЙ§ЙЙдьЪЪЕБЕФ XSLT ФЃАхЃЌетаЉКЏЪ§дйМгЩЯКЯЪЪЕФТпМФмЙЛЭъГЩгУЦфЫћгябдЫљФмЭъГЩЕФШЮКЮЙЄзїЁЃетвЛНкжївЊЪЧНтЪЭ XSLT вЛНкжаЫљПДЕНЕФ XPath БэДяЪНЃЌШЛКѓВћЪіМИИіИХФюЁЃ жс XPath жаЕФвЛИіЙиМќИХФюЪЧжсЁЃXPath жаЕФжс ЪЧЮЛгкЩЯЯТЮФНкЕуЩЯЗНЃЈШч parent КЭ ancestor дЊЫиЃЉЁЂЯТЗНЃЈchild КЭ descendant дЊЫиЃЉЁЂзѓВрЃЈpreceding КЭ preceding-sibling дЊЫиЃЉЛђгвВрЃЈfollowing КЭ following-sibling дЊЫиЃЉЕФвЛзщНкЕуЁЃpreceding КЭ following жсЗжБ№жИЯђФЧаЉАДееЮФЕЕЫГађГіЯждкЩЯЯТЮФНкЕужЎЧАКЭжЎКѓЕФдЊЫиЃЌЖј preceding-sibling КЭ following-sibling жИЯђКЭЩЯЯТЮФНкЕуОпгаЯрЭЌИИдЊЫиЕФдЊЫиЁЃself жсБэЪОЩЯЯТЮФНкЕуздЩэЃЌПЩгыСэЭтСНИіжсНсКЯЦ№РДзщГЩ ancestor-or-self КЭ descendant-or-selfЁЃГ§ДЫвдЭтЃЌдйМгЩЯ attribute КЭ namespace жсОЭПЩвдБЃжЄФмЙЛЗУЮЪЕН XML ЮФЕЕЕФШЮКЮВПЗжСЫЁЃ МђаДКЭЗЧМђаДгяЗЈ вЛаЉ XPath жсПЩвдЕЋВЛвЛЖЈБэЪОГЩМђаДаЮЪНЃЌгаЕуРрЫЦгк UNIX? ЮФМўЯЕЭГЕФ shell гяЗЈЁЃЦфжаАќРЈКЂзгЃЈгУаЧКХЃЈ*ЃЉЛђИќОпЬхЕФзгдЊЫиРраЭБэЪОЃЉЁЂЫЋЧзЃЈ..ЃЉЁЂздЩэЃЈ.ЃЉЁЂЪєадЃЈ@"ЃЉКЭ descendant-or-self жсЃЈ//ЃЉЁЃЦфЫћжсжЛФмЪЙгУЗЧМђаД аЮЪНЕФгяЗЈЁЃдкКѓУцЕФвЛаЉР§згжаПЩвдПДЕНетжжгяЗЈЁЃ ЮЛжУВНКЭЮЛжУТЗОЖ ЮЛжУВН ЪЧЮЛжУТЗОЖ ЕФЛљДЁЁЃЮЛжУВНЕФЗжИєЗћЪЧаБИмЃЈ/ЃЉЁЃЮЛжУТЗОЖгЩвЛЯЕСаЩЯЪіжсЕФЪЕР§ДЎдквЛЦ№зщГЩЁЃБШЗНЫЕЃЌДгЩЯЯТЮФНкЕуПЊЪМЃЌЮЛжУТЗОЖПЩвдЯђЩЯСНВуЃЌЗЂЯжгЩЮНДЪжИЖЈЕФФГИідЊЫиЃЌШЛКѓбизгЪїЯђЯТбАевФГИідЊЫиВЂЗЕЛиЦфЪєадЃК
XPath КЏЪ§ ПЩвдЪЙгУ XPath ЬсЙЉЕФКЏЪ§ЭъГЩзжЗћДЎКЭЪ§бЇдЫЫуЁЃБШЗНЫЕЃЌШчЙћвЊНЋСНИі xsl:variable дЊЫи x КЭ y ЕФжЕЯрМгЃЌПЩвдЪЙгУЃК
ЗЕЛивЛИіЪ§зжЃЌетбљЕФ XPath КЏЪ§ЛЙгаКмЖрЁЃXPath ЬсЙЉСЫЯТСаЪ§бЇдЫЫуЕФКЏЪ§ЃКМгЃЈ+ЃЉЁЂМѕЃЈ-ЃЉЁЂГЫЃЈ*ЃЉЁЂГ§ЃЈdivЃЉвдМАФЃЛђепЧѓгрЃЈmodЃЉЁЃ XPath КЏЪ§вВПЩвдЗЕЛи Boolean жЕЃЈtrue Лђ falseЃЉЁЃетЪЧЬѕМўТпМЫљБиашЕФЃК
XPath КЏЪ§ЛЙПЩвдЗЕЛизжЗћДЎЃК
етРяЃЌconcat() КЏЪ§ПЩвдНгЪмДѓгк 1 ЕФШЮвтЖрИіВЮЪ§ЁЃСэвЛИіГЃгУЕФзжЗћДЎКЏЪ§ЪЧ normalize-space(string)ЃЌЫќШЅЕєЧАЕМПеИёКЭЮВВППеИёЃЌВЂАбжаМфЕФПеАззжЗћађСабЙЫѕЮЊвЛИіЁЃЯТБэСаГіСЫЦфЫћгызжЗћДЎгаЙиЕФ XPath КЏЪ§ЃК
XPath КЏЪ§ЛЙПЩвдЗЕЛиНкЕуМЏЁЃБШШчдк sitemap.xml етИіР§згжаЃЌПЩвдетбљЕУЕНДјгазгвГУцЕФвГУцИіЪ§ЃК
етРяЭтВуЕФКЏЪ§ЗЕЛивЛИіЪ§зжЃЌЖјЦфФкВПЗЕЛиЕФЪЧвЛИіНкЕуМЏЁЃXPath count() КЏЪ§ЗЕЛиЕФЪ§зжЪЧ 3ЃЛАќРЈ lable жЕЮЊ AЁЂAA КЭ AAA ЕФШ§Иі page дЊЫиЃЌЫќУЧЖМгазг page дЊЫиЁЃЧызЂвтЃЌЩЯУцЕФДњТыЪЙгУСЫ descendant жсЕФМђаДгяЗЈЃЈ//ЃЉЁЃШчЙћЪЙгУ // ЕФЪБКђЧАУцУЛгаШЮКЮФкШндђДгИљдЊЫиПЊЪМНјааЕнЙщЫбЫїЃЛдкДѓаЭЮФЕЕжаетжжЫбЫїПЩФмКмЗбЪБЃЌвђДЫгУЕФЪБКђвЊаЁаФЁЃдкЗНРЈКХЃЈ[ КЭ ]ЃЉжаЪЧзїгУгкетаЉ page дЊЫиЕФЮНДЪЃЌвЊЧѓЫќУЧБиаыгазг page дЊЫиЁЃетИіЮНДЪБОЩэЕФФкШнЪЧвЛИі XPath БэДяЪНЃЌМДзгжсЩЯЕФЁАpageЁБЁЃДЫЭтЃЌЛЙПЩвдАбетжжТпМРЉеЙГЩЯТУцЕФБэДяЪНЃЌМДзгвГУцЛЙгазгвГУцЕФвГУцИіЪ§ЃЌЦфжаЧЖЬзСЫСэвЛИіЮНДЪЃК
ФњПЩФмвбОВТЕНЃЌНсЙћЪЧ 2ЃЌМД page дЊЫи A КЭ AAЁЃ МйЩшашвЊжЊЕРИјЖЈЕФЩЯЯТЮФНкЕудкЦф XML ЪїжаЧЖЬзЕФЩюЖШЃЈгУеОЕуЕиЭМФЧИіР§згЕФЛАРДЫЕОЭЪЧЕМКНЕФВуДЮЃЉЁЃШдШЛПЩвдЪЙгУ count() КЏЪ§ЃЌЕЋЪЧетвЛДЮвЊбиВЛЭЌЕФжсЃК
ЪЙгУ ancestor жсШЗЖЈЩЯЯТЮФНкЕуЕФЩюЖШЁЃЯТУцЕФФЃАхЫЕУїСЫЦфгУЗЈЃК
зЂвтЃЌxsl:for-each ЪЧгЩЦф select ЪєадЕУЕНЕФНкЕуМЏЧ§ЖЏЕФЁЃЪфГіНсЙћШчЯТЃК
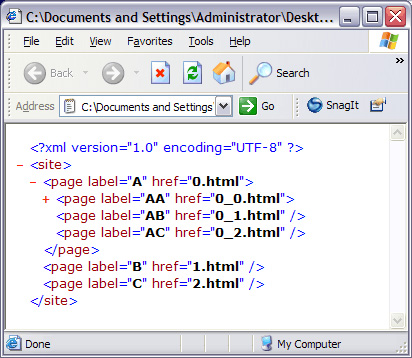
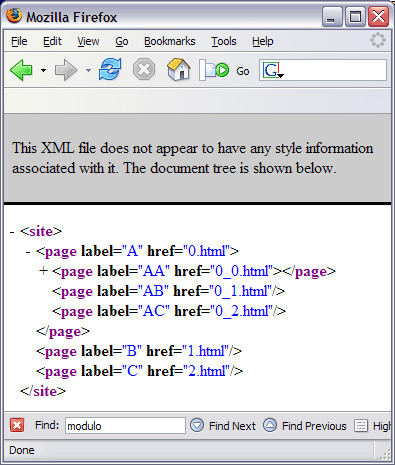
select="//page" ЪєадЗЕЛиЕФНкЕуМЏАќРЈДгИљдЊЫиПЊЪМЕФЫљга page дЊЫиЃЌАДееЮФЕЕЫГађХХСаЁЃxsl:for-each вРДЮНЋУПИі page дЊЫиЩшжУЮЊЩЯЯТЮФНкЕуЁЃШчЙћ xsl:for-each ВЛФмЩшжУЩЯЯТЮФНкЕуЃЌxsl:value-of дЊЫижаЕФБэДяЪНОЭВЛФмЦ№зїгУЁЃ XPath аЁНс XPath Ждгк XSLT жСЙиживЊЁЃЫќЬсЙЉСЫНјааЪ§бЇКЭзжЗћДЎдЫЫувдМАЫбЫїКЭБщРњ XML ЪфШыЕФЪжЖЮЁЃУЛга XPathЃЌXSLT ОЭГЩСЫУЛгабРЕФРЯЛЂЁЃ CSS ШЪепМћШЪЃЌжЧепМћжЧЁЃ -- William Blake ЙцдђЁЂЙцдђЃЌЛЙЪЧЙцдђ XML БОжЪЩЯЪЧЩЯЯТЮФЯрЙиЕФЁЃОЭЪЧЫЕЃЌБъЧЉЁЂБъЧЉЕФЫГађМАЦфЧЖЬзЕФЗНЪНдкКмДѓГЬЖШЩЯЫЕУїСЫЮФЕЕЕФКЌвхЁЃЕЋГ§СЫХХСавдЭтЃЌУЛгаШЮКЮаХЯЂЫЕУї XML ФкШнгІИУШчКЮИёЪНЛЏЮЊПЩЪгЕФаЮЪНЃЈЛђепЦфЫћУНЬхаЮЪНЃЉЁЃXML ЮФЕЕдкЮФБОБрМЦїЛђфЏРРЦїжаЕФФЌШЯЪгЭМЪЧЯдЪОЫљгаЕФБъЧЉЃЌШЮКЮдЊЫиЖМУЛгаЬиЪтЕФПЩЪгЛЏДІРэЃЌАќРЈИљдЊЫиЁЃЕЋЪЧШчЙћЯЃЭћФГаЉдЊЫигУДѓЕФДжЬхзжЯдЪОЃЌСэвЛаЉдЊЫигУЗћКХСаБэЛђепгаађСаБэЯдЪОИУдѕУДАьЃПЛђепашвЊАбвЛзщаХЯЂЗХдквГУцЕФЯрЭЌЮЛжУЩЯЃЌВЂЧвЪЙетзщаХЯЂЕФБГОАбеЩЋВЛЭЌгкжмЮЇЛЗОГИУдѕУДАьЃПЮЊДЫашвЊАбБэЪОЙцдђЭЈЙ§ CSS гГЩфЕНдЊЫиЁЃ CSS БэЪОЙцдђдЪаэАбаХЯЂЃЈXML дЊЫиЃЉКЭБэЪОЗжРыПЊРДЃЌОЭЪЧЫЕЃЌШчЙћашвЊПЩвддкВЛЭЌЧщПіЯТЖдвЛзщЪ§ОнЪЙгУВЛЭЌЕФЭтЙлЁЃЧызЂвтЃЌCSS ЮоЗЈгы XSLT зЊЛЛ XML ЕФФмСІЯрБШЃЌдкВЛЭЌЕФЦНЬЈКЭ Web фЏРРЦїЩЯЕФНтЪЭвВВЛОЁЯрЭЌЁЊЁЊгШЦфЪЧЩшжУ XML ЕФбљЪНЃЌКѓУцФњНЋПДЕНЁЃжЎЫљвддкетРяЬжТл CSSЃЌЪЧвђЮЊетЪЧвЛжжЧсаЭЕФЗНЗЈЃЌгаЪБКђгУЫќОЭзуЙЛСЫЁЃCSS ВЩгУвЛжжЗЧГЃМђЕЅЕФЗЧ XML гяЗЈЃЌвВКмШнвзЪЙгУЁЃБОНЬГЬжа CSS ЮФЕЕБЛМђГЦЮЊЁАбљЪНБэЁБЁЃ фЏРРЦїжаЕФ XML гУ Internet Explore ДђПЊвЛИі XML ЮФЕЕПЩвдПДЕНРрЫЦЭМ 2 ЕФНсЙћЁЃ ЭМ 2. Internet Explorer 6.0 жаЯдЪОЕФ XML ЮФЕЕ ЕЅЛїМгКХКЭМѕКХЭМБъПЩвделЕўЛђеЙПЊФЧаЉгазгдЊЫиЕФдЊЫиЃЌЙІФмЭъећЃЌЕЋЪЧжЛгаФЧаЉжїаоМЦЫуЛњПЦбЇЕФбЇЩњвВаэЛсЯВЛЖетжжЭтЙлЁЃFirefox вВКУВЛСЫЖрЩйЃЌЕЋжСЩйЬсЙЉСЫвЛИіРэгЩЃЌШчЭМ 3 ЫљЪОЁЃ ЭМ 3. Firefox жаЯдЪОЕФ XML ЮФЕЕ Firefox ЯдЪОЕФЮФЕЕЪїЩЯУцЕФЯћЯЂАЕЪОШчЙћга гыИУ XML ЮФЕЕЙиСЊЕФбљЪНаХЯЂЕФЛАЃЌПЩФмИќКУПДвЛЕуЁЃКУЁЃдѕУДзіФиЃП дк HTML ЮФЕЕжаПЩЭЈЙ§ЯТСааЮЪНАќКЌбљЪНаХЯЂЃК
етаЉЗНЗЈвВПЩгУгкБраД XSL зЊЛЛДг XML ЩњГЩ HTMLЁЃВЛЙ§етРяЙиаФЕФНіНіЪЧЮЊ XML діМгвЛаЉПЩЪгЛЏИёЪНЁЃЮЪЬтЪЧШчЙћЫцвтЮЊдЊЫидіМгааФк бљЪНЪєадПЩФмдьГЩ XML ЮФЕЕЪЧЮоаЇЕФЁЃДЫЭтЃЌXML ЮФЕЕЕФ DTD Лђеп XML ФЃЪНПЩФмУЛга script дЊЫиЃЌвђДЫвВВЛФмгУФкВП ЗНЗЈЁЃДЫЭтЃЌетСНжжЗНЗЈЖМвЊаоИФ XMLЃЌетЪЧЮвУЧВЛЯЃЭћЕФЁЃЮЉвЛПЩааЕФЗНЗЈОЭЪЧЪЙгУЭтВП бљЪНЁЊЁЊЭЈЙ§вЛИіЛђЖрИіКѓзКЮЊ .css ЕФЮФМўНЋПЩЪгЛЏДІРэгІгУгк XML ЮФЕЕЁЃЕЋЪЧгжВЛФмЪЙгУ HTML <link/> БъЧЉЃЈГ§ЗЧФЃЪНЛђеп DTD дЪаэЃЉЁЃвђДЫЃЌПЩЪЙгУЯТУцетжжфЏРРЦїжИСюАбвЛИіЛђЖрИі CSS ЮФМўКЭ XML ЮФЕЕЙиСЊЦ№РДЃК
АбетаажИСюЗХдк XML ЮФЕЕЕФПЊЪМЮЛжУЃЈађбдВПЗжЃЉЃЌНєИњдк <?xml version="1.0"?> жИСюжЎКѓЁЃИУбљЪНБэжИСюв§гУЕФ CSS ЮФМў catalog.css КЭ XML ЮФМўдкЭЌвЛИіФПТМжаЁЃhref ЪєадЕФжЕвВПЩвдЪЧОјЖдЕФЁЃЩЯУцЕФжИСюжаЛЙПЩЪЙгУЦфЫћЪєадЃЌЦфжажЎвЛЪЧ mediaЁЃИУЪєадЕФжЕПЩвдЪЧ allЁЂbrailleЁЂembossedЁЂhandheldЁЂprintЁЂprojectionЁЂscreenЁЂspeechЁЂtty КЭ tvЁЃ вђДЫЃЌПЩвддкЭЌвЛИі XML ЮФЕЕжав§гУВЛЭЌЕФМЖСЊбљЪНБэЙцдђЁЃИУЬиаддЪаэАб XML ИёЪНЛЏГЩвЊВщПДЃЈЛђепЁАЬ§ЁБЃЉЕФУНЬхРраЭЁЃПЩвдЭЈЙ§ @media ЙцдђВтЪдЕБЧАЪЙгУЕФУНЬхЃЈДгЖјгУЭЌвЛИібљЪНБэЮЊЦфЗўЮёЃЉЁЃЯТУцЕФДњТыИјГіСЫвЛИіР§згЃК
гяЗЈ МЖСЊбљЪНБэжаЖЈвхбљЪНЕФЛљБОгяЗЈЮЊЃКselector {property: value;}ЁЃбЁдёЦїЃЈselectorЃЉМДашвЊИљОнвЛИіЛђЖрИіЪєадЃЈproperty) ЕФжЕЃЈvalueЃЉЖЈвхЦфЭтЙлЕФ XML дЊЫиЁЃПЩвдНЋЖрИібЁдёЦїзщжЏдквЛЦ№ЃЌжаМфгУЖККХЗжПЊЁЃ вВПЩЪЙгУЭЈгУбЁдёЦїЃЌгУаЧКХЃЈ*ЃЉБэЪОЃЛЯргІЕФЙцдђгІгУгк XML ЮФЕЕжаЮДУїШЗЖЈвхЙцдђЕФЫљгаФкШнЁЃЪєаджЕгУдЪаэЕФЖШСПЕЅЮЛБэЪОЁЃетаЉЕЅЮЛБэЪОбеЩЋЁЂГЄЖШЕШЁЃвЛАуЖјбдЃЌCSS жаЕФПеАзЮоЙиНєвЊЃЌвђДЫПЩвдАДееЯВЛЖЕФЗНЪНЕїећЮФМўЕФИёЪНЁЃЕЋЪЧЪєадЕФжЕ КЭЯоЖЈЕФЕЅЮЛ жаМфВЛФмгаПеАзЁЃ дк CSS жаПЩвдСщЛюЕиЖЈвхбЁдёЦїЁЃБШЗНЫЕЃЌШчЙћвЊЩшжУ dvd ЕФзгдЊЫи title ЕФбљЪНЙцдђЃЌПЩвдЪЙгУЃК
ЫќЩљУїСЫ DVD title дЊЫиЕФЮФБОжЕгУДжЬхЯдЪОЁЃВЛвЛЖЈвЊЪЙгУетжжгяЗЈЃЈПЩвдИќМђЕЅЕиЩљУї title зїЮЊбЁдёЦїЃЉЃЌЕЋЪЧвЊМЧзЁПЩФмашвЊдкВЛЭЌЕФЩЯЯТЮФжажиаТЩшжУдЊЫиЕФбљЪНЃЈетРяЪЧзїЮЊвЛИідЊЫиЕФКЂзгГіЯжЕФЃЌЕЋвВПЩФмзїЮЊЦфЫћдЊЫиЕФКЂзгГіЯжЃЉЁЃЭМ 4 ЯдЪОСЫдк Internet Explore 6.0 жаЕФЪфГіНсЙћЁЃ ЭМ 4. CSS гУгк XMLЃЌЕквЛДЮ ЮЊСЫдіЧППЩЖСадЃЌЯждкЮвУЧАбУПИі dvd дЊЫизїЮЊвЛЖЮРДЯдЪОЃЌжмЮЇМгЩЯвЛЕуПеАзЃК
КѓУцНЋЬжТлетаЉЪєадКЭЫќУЧЕФжЕЁЃШчЙћашвЊЭЛГіЯдЪОФЧаЉАќКЌ genre ЪєадЕФ dvd дЊЫиЃЌПЩЪЙгУЯТУцЕФЙцдђЃК
ЯИаФЕФЖСепЛсЗЂЯжетжжгяЗЈКЭ XPath ЮНДЪгаЯрЫЦжЎДІЁЃЫфШЛ Internet Explore 6.0 ВЛФмЪЖБ№етжжгяЗЈЃЌЕЋЪЧ Firefox 1.0.7 ИјГіСЫЭМ 5 ЫљЪОЕФГЪЯжНсЙћЁЃ ЭМ 5. Firefox жаЕФЪєадЮНДЪ ЯждкЃЌвЛЮЛЬжШЫЯВЛЖЕФЕчгАЪеМЏепЯЃЭћгУЫ§ЯВАЎЕФбеЩЋРДЭЛГіЯдЪОЯЗОчЕчгАЃК
етЬѕЙцдђЃЌвдМАФЧЬѕЯдЪОДј genre ЪєадЕФ dvd дЊЫиЕФИќвЛАуЕФЙцдђЖМзёбСЫЃЌШчЭМ 6 ЫљЪОЁЃЭЌбљжЛдк Firefox жагааЇЖјВЛФмгУгк Internet Explore 6.0ЁЃ ЭМ 6. Firefox жаЕФЪєадЮНДЪ ЯждкПДЦ№РДКУЖрСЫЃЌЕЋЪЧ DVD ЕФЕЅМлгаЕуФбПДЃЌЪЧВЛЪЧЃПЮвУЧдкУПИі price дЊЫиЕФжЕЧАМгЩЯУРдЊЗћКХЃК
дйАбЕчгАжЦзїЕФФъЗнЗХдкРЈКХжаЁЃетРяПЩвдЪЙгУгы price дЊЫиЫљЪЙгУЕФЯрЭЌЕФЮБдЊЫи ММЪѕЃК
ЭМ 7 ЯдЪОСЫЩЯЪіЙцдђдк Firefox жаЕФГЪЯжНсЙћЁЃ ЭМ 7. ЮБдЊЫиЕФГЪЯж Internet Explore 6.0 ВЛФмЪЖБ№ selector:before КЭ selector:after ЮБдЊЫиЃЌвђДЫетРяУЛгаЬсЙЉЫќЕФГЪЯжНсЙћЁЃ дкЧАУцЕФЛљДЁЩЯЮвУЧдйдіМгвЛаЉИёЪНЃК ЧхЕЅ 3. ИёЪНЛЏ DVD ФПТМ XML ЮФЕЕЕФбљЪНБэ
етРяЮЊ catalogЃЈИљдЊЫиЃЉдіМгСЫМИИіЪєадРДЖЈвхећИіЮФЕЕЁЃЦфжаАќРЈБГОАбеЩЋЁЂБпПђЁЂfont-family КЭ font-size ЕФзмЬхЩшжУЁЃдкГЪЯжНсЙћжаПЩвдЗЂЯжЃЌетаЉзжЬхЪєадБЛ catalog ЕФЫљгазгдЊЫиМЬГа СЫЁЃвђЮЊ catalog ЪЧИљдЊЫиЃЌетаЉЙцдђгІгУгкећИіЮФЕЕЁЃЧЖЬздЊЫивВПЩгаздМКЕФзжЬхЪєадЙцдђЃЌетаЉЙцдђНЋИВИЧЮЊЦфИИдЊЫиЩшжУЕФЙцдђЁЃ ШЛКѓЮЊ dvd дЊЫидіМгСЫвЛаЉЙцдђЃЌЪЙЦфгыБГОАЃЈcatalog дЊЫиЃЉЧјЗжПЊЁЃетРяЪЙгУСЫСНжжВЛЭЌЕФЗНЪНУшЪібеЩЋЃКУћГЦКЭЪЎСљНјжЦДЎЃЌCSS
жаЕФбеЩЋвЛНкНЋЖдДЫМђвЊЕиЬжТлЁЃЖд catalog КЭ dvd дЊЫиЕФ display ЪєадЪЙгУжЕ "block"ЃЌШУЫќУЧЕЅЖРеМвЛааВЂЪЕЯжСЫ
paddingЁЃДЫЭтЃЌЛЙЪЙгУ first-child КЭ last-child ЮБРр бЁдёЦїЖдЕквЛИіКЭзюКѓвЛИі dvd дЊЫиЪЙгУМгДжЕФ
borderЁЃЃЈЮБРрбЁдёЦїгыдЊЫиЕФЬѕМўЖјВЛЪЧдЊЫиУћЦЅХфЁЃЃЉзюКѓЃЌФЧЮЛЬжШЫЯВЛЖЕФЕчгАЪеМЏепвЊЧѓвўВиЖЏзїРрЕФЕчгАЃЌетЪЧЭЈЙ§ display:
hidden ЪєаджЕЪЕЯжЕФЁЃЭМ 8 КЭЭМ 9 ЗжБ№ЫЕУїСЫ Firefox КЭ Internet Explore 6.0 ШчКЮДІРэетИібљЪНБэЁЃ
ЭМ 9. Internet Explorer 6.0 ГЪЯжЕФбљЪНБэ ЧызЂвтЃЌFirefox жаЭЈЙ§НЋЦф display ЪєадЩшжУЮЊ "none"ЃЌГЩЙІвўВиСЫ genre ЪєаджЕЮЊ ActionЃЈRaiders of the Lost ArkЃЉЕФ DVDЁЃЪТЪЕЩЯЃЌFirefox ЭъУРЕижДааСЫбљЪНБэжаЕФЫљгаЙцдђЁЃЕЋЪЧдк Internet Explore 6.0 жаЪЇАмСЫЁЃНЋ background-color ЪєадгІгУгк catalog дЊЫижЎКѓгШЦфУїЯдЃЌМДИВИЧСЫЭМ 9 жаДѓВПЗжФкШнЕФЛвЩЋЭХЁЃДгДЫПЩМћЃЌВЛдѕУДМсГжБъзМЕФ Internet Explore 6.0 дк CSS Жд XML ЕФжЇГжЗНУцИЯВЛЩЯ FirefoxЁЃ зюКѓЃЌДгЩЯвЛИібљЪНБэЃЈЧхЕЅ 3ЃЉЕФПЊЪМПЩвдПДГіЃЌCSS ЮФМўжадЪаэЪЙгУзЂЪЭЁЃзЂЪЭБиаывд /* ПЊЪМЃЌвд */ НсЪјЃЌгы C МА Java БрГЬжавЛбљЁЃ беЩЋ CSS жаЕФбеЩЋЭЈГЃгУКьТЬРЖШ§дЩЋАДееЫГађБэЪОЃЌгаЯТСаШ§жжВЛЭЌЕФЗНЗЈЃК
ЯдЪО ШчЧхЕЅ 3 ЫљЪОЃЌdisplay ЪєаддЪаэвдВЛЭЌЕФЗНЪНЯдЪОвЛИідЊЫиЃЌПЩвдШЁЯТСажЕЃК
Table дЊЫиЮЊ CSS ЬцДњ HTML БэИёЬсЙЉСЫФГаЉжЇГжЃЌШчЙће§ШЗЧЖЬзЕФЛАПЩвдЪЙдЊЫиПДЦ№РДЯё HTML tableЁЂtr КЭ td дЊЫиЁЃЕЋЪЧЯШЭќЕєЫќАЩЃЌШчЙћашвЊгы HTML БэИё rowspan Лђ colspan ЕШМлЕФЙІФмЃЌЗЧБэИёбљЪНЕФдЊЫиБиаыТњзуетжжЧщПіЁЃ ГЄЖШ КмЖр CSS ЪєаджагУЕНСЫГЄЖШЁЃПэЁЂИпЁЂзжЬхДѓаЁЁЂБпПђЁЂЬюАзЁЂвГБпОрКЭЖЈЮЛЖМЪЙгУФГжжГЄЖШЕЅЮЛРДУшЪіЫќУЧЕФжЕЁЃГЄЖШПЩвдЪЧОјЖдСПвВПЩвдЪЧЯрЖдСПЁЃОјЖдЕЅЮЛЪЪКЯгкДђгЁУННщЃЈЕЋГ§ДЫвдЭтКмЩйЃЉЃЌАќРЈЕуЁЂЛюзжЁЂКСУзЁЂРхУзКЭгЂДчЁЃЯрЖдЕЅЮЛИќГЃгУгкЦСФЛУННщЃЌАќРЈЯёЫиЁЂАйЗжБШЁЂems КЭ exesЁЃ ГѕПДЦ№РДПЩФмвдЮЊЯёЫиЪЧОјЖдЕЅЮЛЃЌЕЋЯёЫиЪЧЯрЖдгкЯдЪОЩшБИЕФЗжБцТЪЖјбдЕФЁЃЯёЫиЭЈГЃгУгкЖШСПгыЮЛЭМЭМЯёгаЙиЕФПщРраЭдЊЫиЃЌЕЋЪЧгІБмУтгУгкзжЬхДѓаЁЁЃШчЙћЪЙгУЯёЫиЕЅЮЛУшЪізжЬхДѓаЁЃЌдђНЋЦфЪгзїОјЖдЕЅЮЛЃЌЮЊСЫИФЩЦПЩЖСадЃЌЖрЪ§фЏРРЦїВЛдЪаэгУЛЇгУЫќУшЪізжЬхДѓаЁЁЃ АйЗжБШЯрЖдгкЦфЫћФГИіЖдЯѓУшЪіЪТЮяЕФГЄЖШЁЃетИіЖдЯѓЭЈГЃЪЧзюДѓПЩгУПеМфЁЃжЕЮЊ 60% ЕФПэЖШЪєадОЭБэУїзюЖрПЩеМгУПЩгУЧјгђЕФ 60%ЁЃБШШчЃЌПЩвдНЋЩЯЪі catalog дЊЫиЕФЙцдђИФЮЊЃК
етИібљЪНБэР§згжаЕФЦфЫћЙцдђОЁСПБЃГжМђЕЅЃЌдк Firefox жаЕУЕНЕФЯдЪОНсЙћШчЭМ 10 ЫљЪОЁЃ ЭМ 10. ЯрЖдИИдЊЫиЕФАйЗжБШПэЖШ ДгжаПЩвдПДЕН catalog дЊЫиШЗЪЕеМОнСЫПЩгУПеМфЃЈМДфЏРРЦїДАПкЃЉЕФ 60%ЃЌгыаТдіМгЕФ width ЪєадЫљЙцЖЈЕФвЛбљЁЃ Ems КЭ exes ЗЧГЃЪЪКЯЯрЖдгкИИзжЬхДѓаЁжИЖЈЕБЧАзжЬхЕФДѓаЁЁЃЪЙгУетСНжжЕЅЮЛЕФЙиМќдкгкБиаыжЊЕРИИдЊЫиПЩБШЪєадЕФДѓаЁЁЃ Бэ 1 ИХРЈСЫОјЖдКЭЯрЖдГЄЖШЕЅЮЛЁЃ зжЬх зжЬхЪєадПижЦзХЯдЪОЕФзжаЮЁЃПЩгУЕФзжЬхЪєадАќРЈЃК
ЮФБО ЮЊСЫПижЦзжЬхЪєадВЛФмДІРэЕФЦфЫћЪєадЃЌПЩЪЙгУЮФБОЪєадЁЃЦфжаАќРЈЃК
БГОА ПЩвдЭЈЙ§ background-color ЪєадЛђЪЙгУБГОАЭМЯёЮЊИїжжааФкЁЂПщЛђБэИёдЊЫидіМгБГОАДІРэЁЃbackground-color ЪєадЕФШЁжЕзёбЧАУцЙигкбеЩЋЕФЫЕУїЁЃВЛЙ§ЭМЯёЕФЪЙгУПЩФмгаЕуИДдгЁЃгУгкУшЪіБГОАЭМЯёЕФЪєадАќРЈЃК
БШШчЯТУцЕФР§згЃК
ЬюАз ЬюАзЪєадгУгкааФкКЭПщдЊЫиЁЃПЩвдЪЙгУЕЅИі padding: ЪєадЃЌвВПЩвдЗжБ№жИЖЈЫФИіЗНЯђжаЕФвЛИіЛђЖрИіЃКpadding-top:ЁЂpadding-left:ЁЂpadding-right: КЭ padding-bottom:ЁЃЪЙгУЕФЕЅЮЛВЮМћГЄЖШвЛНкЁЃЪЙгУЕЅИі padding: ЪєадЃЌШдШЛвЊАДеевЛЖЈЕФЫГађжИЖЈЫФИіЗНЯђЩЯСєАзЕФЪ§жЕЁЃБШШчЃК
ГЄЖШЕЅЮЛПЩвдШЮвтзщКЯЃЌЕЋЪЧВЛФмЪЙгУИКЪ§ЁЃИУЪєадВЛФмДгИИдЊЫиМЬГаЁЃ БпПђ гы padding: ЪєадРрЫЦЃЌПЩвдЭЌЪБУшЪідЊЫиЕФЫФУц border: ЛђепЗжБ№УшЪіЫФИіЗНЯђЩЯЕФБпПђЃКborder-top:ЁЂborder-left:ЁЂborder-right: КЭ border-bottom:ЁЃжЕЕФгяЗЈИёЪНЮЊЃКlength border-style colorЁЃГЄЖШЕЅЮЛВЮМћЧАУцЕФГЄЖШвЛНкЁЃБпПђРраЭПЩвдЪЧЃКdashedЁЂdoubleЁЂdottedЁЂgrooveЁЂinsetЁЂoutset Лђ solidЁЃБШШчЯТУцЕФР§згЃК
ЖЈЮЛ ЪЙгУ CSS ЕФ position ЪєадЃЌПЩвдЫЕУїдЊЫидкЮФЕЕжаЯдЪОЕФОпЬхЮЛжУЁЃБШЗНЫЕЃЌШчЙћашвЊЙцЖЈФПТМжаЕФЕквЛИі dvd дЊЫиГіЯждкЯрЖдгкЫљгаЦфЫћдЊЫиФГИіЙЬЖЈЕФЮЛжУЃЌПЩЪЙгУЯТУцЕФДњТыЃК
ЧызЂвт position ЪєадКЭЫќЕФжЕ absoluteЁЃетбљжИЖЈжЎКѓЃЌОЭПЩвдУшЪіЯЃЭћИУдЊЫиЯрЖдгквГУцзѓЩЯНЧЕФОјЖдЮЛжУСЫЁЃЩЯР§жаЩљУїЕФЮЛжУЪЧОрРызѓВрБпНч 80 ЯёЫиЃЌОрРыЩЯБпНч 150 ЯёЫиЁЃЭМ 11 ЯдЪОСЫдк Firefox жаЕФГЪЯжНсЙћЁЃ ЭМ 11. Firefox жаЕФОјЖдЖЈЮЛ дк ЭМ 11 жаЃЌTerminator 2 АДееЮФЕЕЫГађЪЧЕквЛИі dvd дЊЫиЃЌвђДЫЪеЕНСЫЮЊЕквЛИі dvd дЊЫиЩљУїЕФОјЖдЖЈЮЛЙцдђЁЃГ§СЫ left КЭ top ЪєадЭтЃЌЛЙПЩвдЩљУї right КЭ bottomЃЌЗжБ№гУгкЯрЖдгкВМОжЕФгвБпНчКЭЯТБпНчЖЈЮЛдЊЫиЁЃетаЉЪєадПЩвдШЮвтзщКЯЪЙгУЃЌжЛвЊКЯРэОЭааЁЃЖЈЮЛЪєадЕФСэвЛИіжЕЪЧ relativeЃЌЫќвРОнЭЈГЃЕФдЊЫиГЪЯжЮЛжУАД topЁЂleftЁЂright КЭ bottom ЪєадЖЈЮЛЁЃБШЗНЫЕЃЌПЩЪЙгУЯТСаДњТыНЋЕквЛИі dvd дЊЫиЗХдкЭЈГЃЮЛжУЦЋзѓ 10 ИіЯёЫиЃЌЦЋЩЯ 10 ИіЯёЫиЃК
ЭМ 12 ЯдЪОСЫдк Firefox жаЕФГЪЯжНсЙћЁЃ ЭМ 12. Firefox жаЕФЯрЖдЖЈЮЛ ШУвЛИідЊЫижиЕўдкЦфЫћдЊЫиЩЯУцЯдЪОЪЧПЩФмЕФЁЃПЩвдЭЈЙ§ z-index: ЪєадПижЦФФИідЊЫидкЩЯУцЁЃетРяЪЙгУећЪ§жЕЃЌжЕдНДѓдНдкЩЯУцЁЃ СэвЛжжЖЈЮЛдЊЫиЕФОјЖдЗНЪНЪЧЭЈЙ§ЙЬЖЈЖЈЮЛЁЃposition: absolute ЯрЖдгквГУцжаЦфЫћдЊЫиЕФВМОжЖЈЮЛдЊЫиЃЌЖј position: fixed ИљОнфЏРРЦїДАПкШЗЖЈдЊЫиЕФЮЛжУЁЃВЛЪЙгУПЩЙіЖЏЕФР§згКмФбЫЕУїЦфгУЗЈЃЌВЛЙ§ФњПЩвдздМКГЂЪдЃЌгяЗЈОЭЪЧ position: fixedЁЃtopЁЂleftЁЂright КЭ bottom ЪєадПЩгУгкЩшжУдЊЫизЄСєЃЈМДБувГУцЙіЖЏСЫЃЉЕФЮЛжУЁЃ CSS аЁНс ЫфШЛЭЈГЃВЛзїЮЊЩшжУ XML ЮФЕЕбљЪНЕФЪзбЁЗНЪНЃЌвВУЛга XSLT ФЧбљНјааМЦЫуКЭзЊЛЛЕФФмСІЃЌЕЋ CSS жСЩйЮЊПЩЪгЕФИёЪНЛЏ XML дЊЫиЬсЙЉСЫвЛжжЧсаЭЕФЗНЗЈЁЃгЩгкИїжжфЏРРЦїЖд CSS ЕФжЇГжВЛвЛжТЃЈЖд XML гШЦфШчДЫЃЉЃЌжСЩйНЋ CSS гУгкЦСФЛУНЬхЪБвЊЗЧГЃаЁаФЁЃВЛЙ§ШчЩЯЫљЪіЃЌMozilla Firefox Жд CSS дк XML жаЕФгІгУЬсЙЉСЫЧПДѓЕФжЇГжЁЃЙигкНЋ CSS гУгкДђгЁУНЬхЕФЮФеТБэУїЗЧГЃГЩЙІЃЌШчЙћЯыБмУт XSLT ЕФИДдгадЃЌCSS ЪЧвЛжжВЛДэЕФбЁдёЁЃ НсЪјгя змНс ЯждкЮвУЧНсЪјСЫ XML зЊЛЛетИіжїЬтЙигк XSLTЁЂXPath КЭ CSS ЕФЬжТлЁЃЯЃЭћФмЙЛЮЊФЧаЉИеНгДЅетИіжїЬтЕФЖСепЬсЙЉСЫзуЙЛЕФаХЯЂЁЃжЛвЊШЯецеЦЮеБОЮФжаЬсЙЉЕФВФСЯМАЫљИНЕФВЮПМзЪСЯЃЌЖдгкзМБИПМЪд 142 ЁАXML МАЯрЙиММЪѕЁБжа XML зЊЛЛВПЗжЕФФкШнРДЫЕДТДТгагрСЫЁЃ |
зщжЏМђНщ | СЊЯЕЮвУЧ | Copyright 2002 ® UMLШэМўЙЄГЬзщжЏ ОЉICPБИ10020922КХ ОЉЙЋКЃЭјАВБИ110108001071КХ |