| 编辑推荐: |
本文主要介绍了AI
基于Agent Skill驱动的测试用例生成方案相关内容。希望对您的学习有所帮助。
本文来自于微信公众号懒虫不会爬,由火龙果软件Alice编辑、推荐。 |
|
一、项目背景与愿景
1.1 痛点分析
在传统 QA 工作流中,从需求文档到测试用例的转化存在多个瓶颈:
| 痛点 |
表现 |
影响 |
| 需求理解偏差 |
不同人对 PRD 理解不一致 |
用例覆盖盲区 |
| 粒度跳跃 |
PRD → 用例中间无中间层 |
AI 自行拆分导致遗漏 |
| 覆盖不全 |
缺乏系统化信号扫描 |
边界/异常/跨模块场景遗漏 |
| 追溯断裂 |
用例无法回溯到原始需求 |
变更影响难评估 |
| 重复劳动 |
每次手工编写格式化文档 |
效率低下 |
1.2 设计愿景
构建 "需求 → 功能点 → 测试用例" 的全链路 AI 辅助生成管线,通过 Cursor
Agent Skill 机制实现:
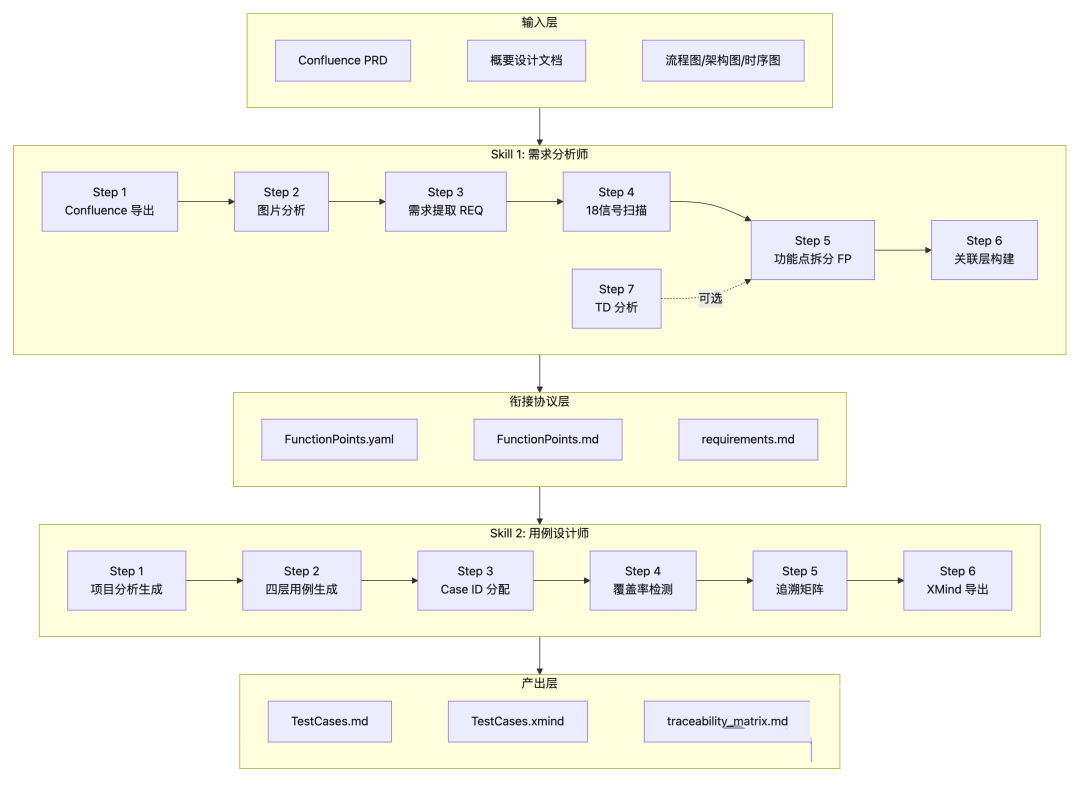
二、整体架构
2.1 双 Skill 协作架构
系统采用 职责分离 的双 Skill 设计,形成上下游管线:
step6 关联层构建:核心思想是把拆分出的需求点,建立关联关系,比如节点1和节点3的内容是有关联的,在验证时需要结合起来,这个如果单独分析,会存在遗漏。
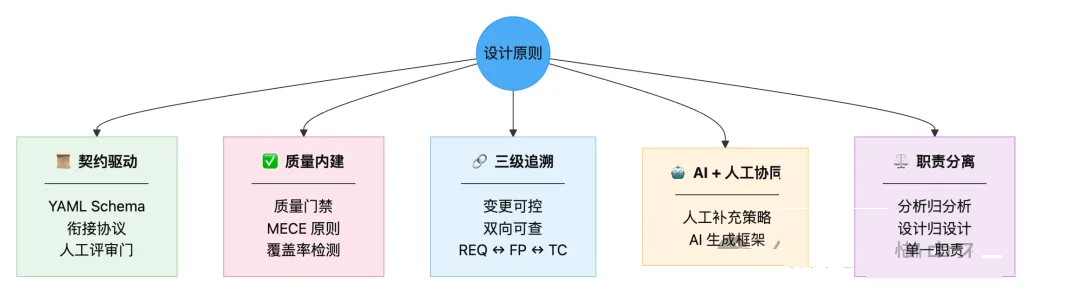
2.2 核心设计原则
三、Skill 1:需求分析师 — 设计详解
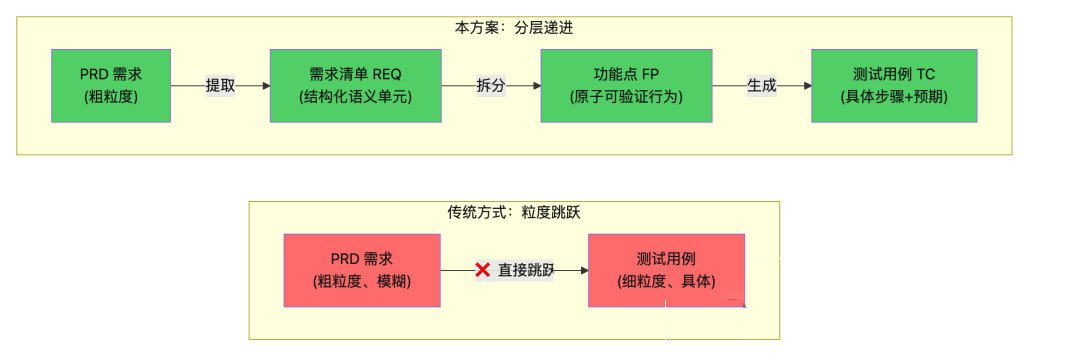
3.1 核心思想:消除粒度跳跃
传统方式中,从 PRD 到测试用例存在巨大的 粒度跳跃,AI 在这个跳跃中容易遗漏或歧义理解需求。
本方案引入 功能点 (Function Point) 作为中间层,消除跳跃:
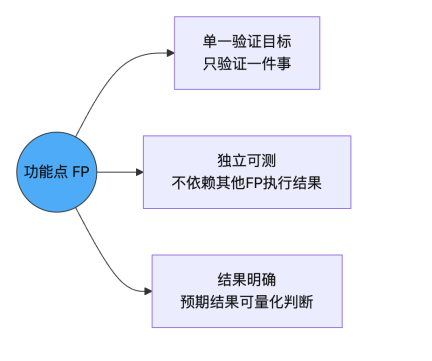
3.2 功能点原子性标准
每个 FP 必须满足三个原子性条件:
粒度控制示例:
| 粒度 |
示例 |
判定 |
| 太粗 |
"Checkout 时处理 Overpayment" |
包含冻结、更新、记录多件事 |
| 合适 |
"Checkout 冻结 Earmarked Limit = min(交易金额,
AL)" |
单一公式、可独立验证 |
| 太细 |
"EAL 在 Overpayment=$1 时等于 $1" |
是同一规则的测试数据,属于 test_hints |
3.3 18 类信号扫描体系
这是本方案最核心的方法论创新。从 PRD 中系统化地提取信息,避免遗漏:
3.4 6 Phase 分析流程
信号扫描按严格的 6 个阶段执行,确保不遗漏:
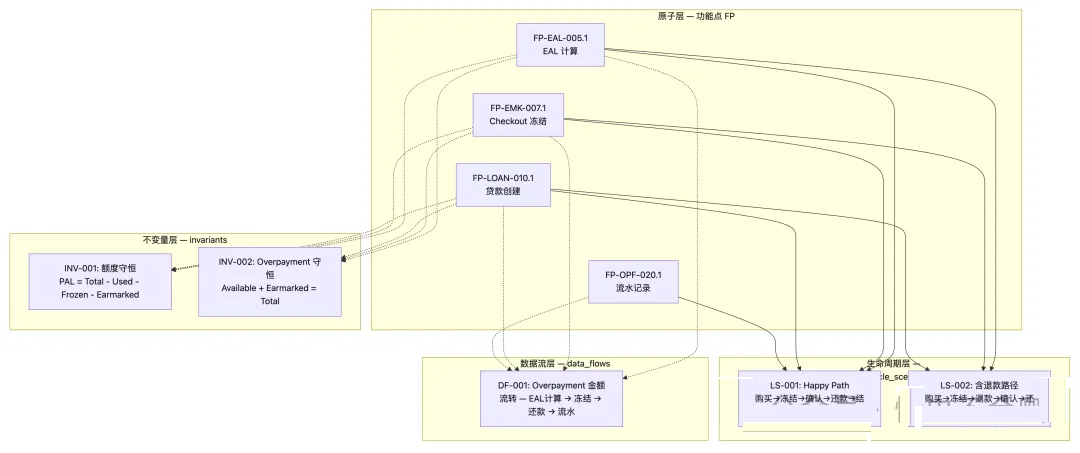
3.5 三层关联结构
功能点是"点",关联层描述"线"和"面",三者协同确保完整覆盖:
三层的用例生成对应关系:
| 关联层 |
生成用例类型 |
验证目标 |
| FP (原子层) |
原子用例 (正向/异常/边界) |
单个功能点的正确性 |
| data_flows |
集成用例 |
数据在 FP 之间流转的一致性 |
| invariants |
不变量校验用例 |
跨 FP 全局约束始终成立 |
| lifecycle_scenarios |
E2E 端到端用例 |
完整业务路径的正确性 |
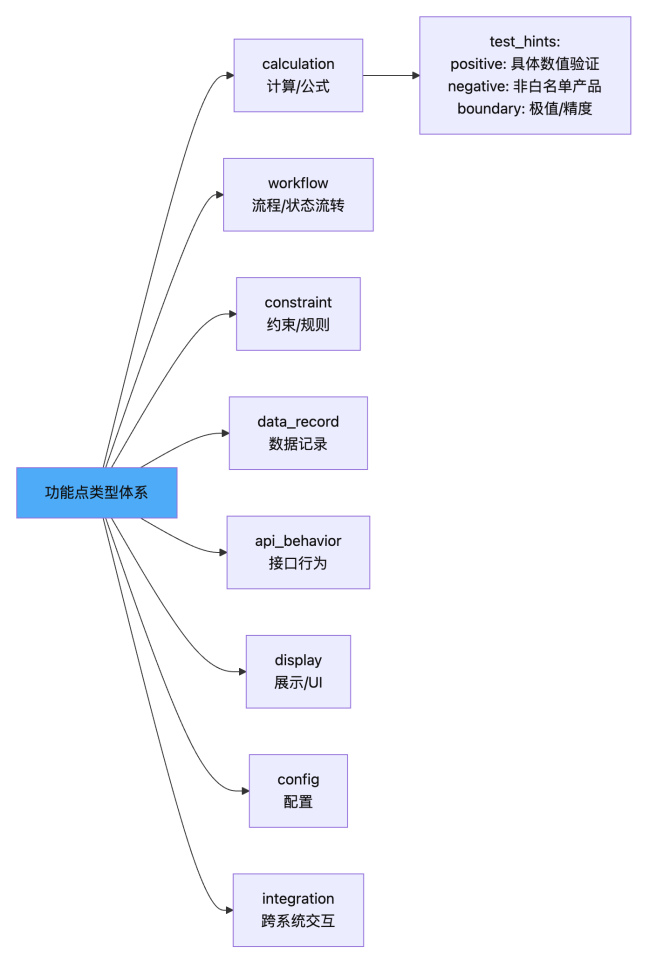
3.6 FP 类型体系与 test_hints
每个 FP 按类型分类,并自带测试提示(test_hints),作为 AI 生成用例的"种子":
test_hints 的核心价值:不再依赖 AI 自行判断"该测什么",而是在功能点层面就给出明确的测试方向引导。
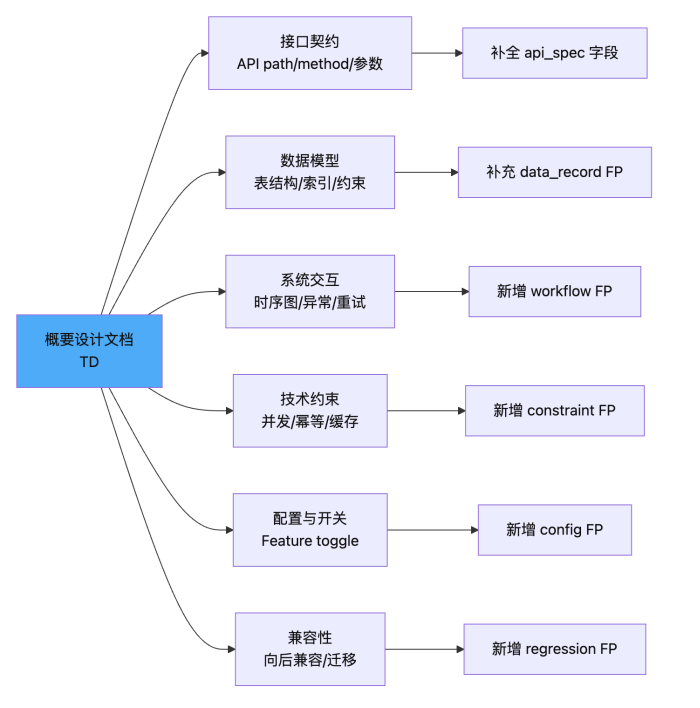
3.7 TD 分析增强(六维度)
当有概要设计文档时,通过六维度分析补全 FP 的技术细节:
四、Skill 2:用例设计师 — 设计详解
4.1 核心思想:智能覆盖而非机械覆盖
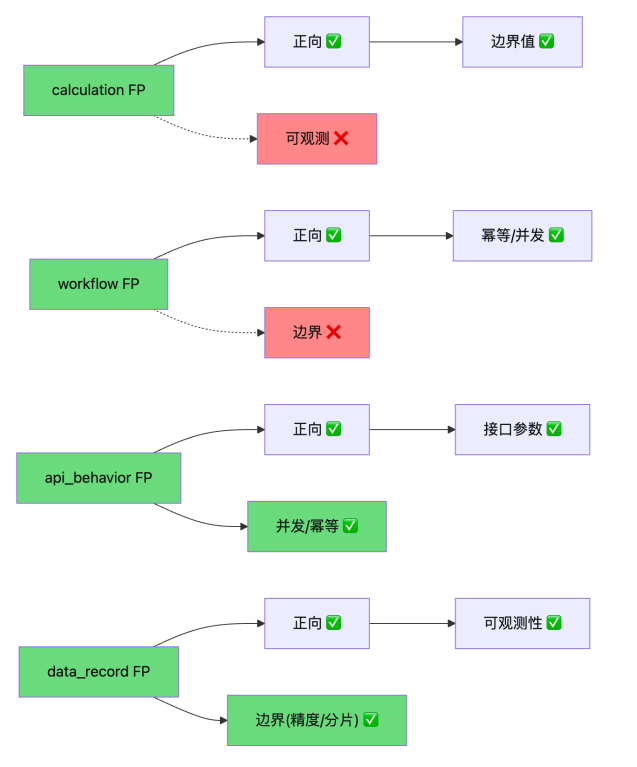
传统做法为每个功能点统一生成"正向/异常/边界"三板斧,本方案根据 FP 类型智能选择覆盖策略:
传统方式(三板斧):
本方案(按 FP 类型智能选择):
覆盖类型选择矩阵:
设计优点:
1.按需维护:可以按照需要,逐渐完善和丰富策略,又不至于过渡膨胀
2.差异化管理:针对不同的验证类型,采取不同策略,实现差异化管理
| FP
type |
必选 |
推荐 |
不推荐 |
| calculation |
正向 |
边界值、等价类 |
可观测性 |
| constraint |
正向 |
异常(违反约束) |
边界 |
| workflow |
正向 |
场景分支、幂等/并发 |
边界 |
| api_behavior |
正向 |
接口参数/响应/状态码、并发/幂等 |
可观测性 |
| data_record |
正向 |
可观测性(字段完整性)、边界(精度/长度/分片)、并发(乐观锁) |
- |
| config |
正向 |
兼容性(配置变更) |
并发 |
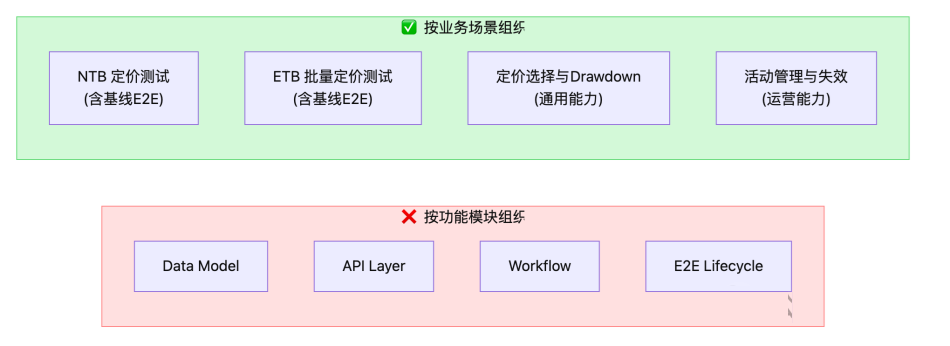
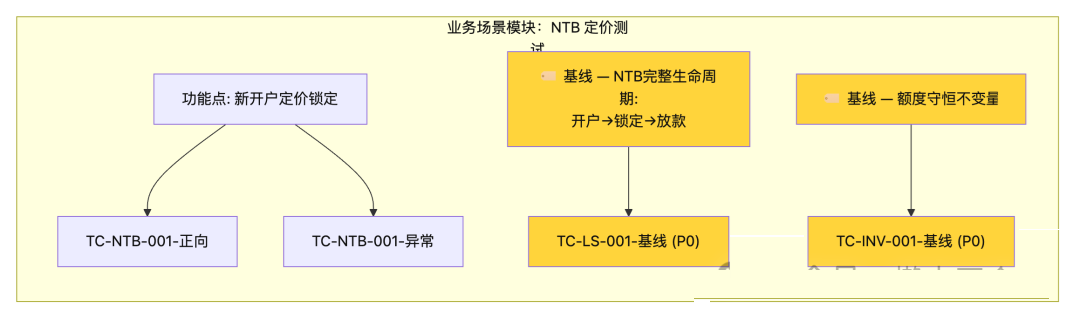
4.2 业务场景维度组织
用例按 业务场景 而非技术功能模块组织,更贴合业务视角:
E2E/不变量用例融入场景:
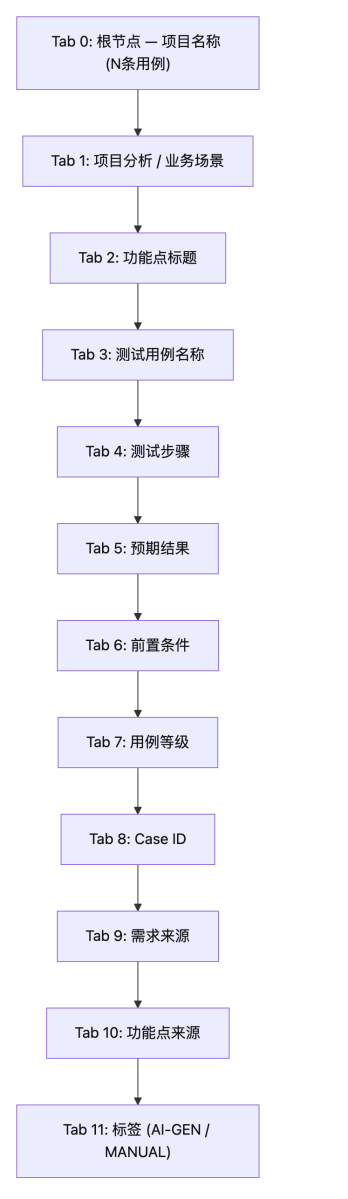
4.3 12 层 Tab 缩进结构
用例采用严格的 12 层 Tab 缩进格式,可直接转换为 XMind 思维导图:
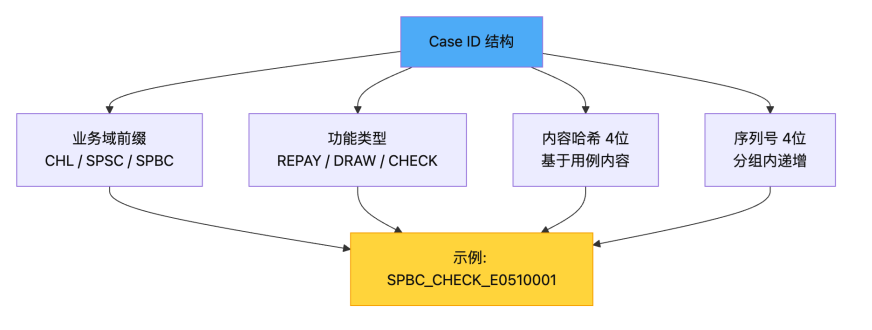
4.4 Case ID 管理体系
Case ID 采用结构化编码,支持跨项目复用和相似度去重:
相似度复用机制:新用例与已有用例相似度 >= 90% 时自动复用 Case ID,避免重复。
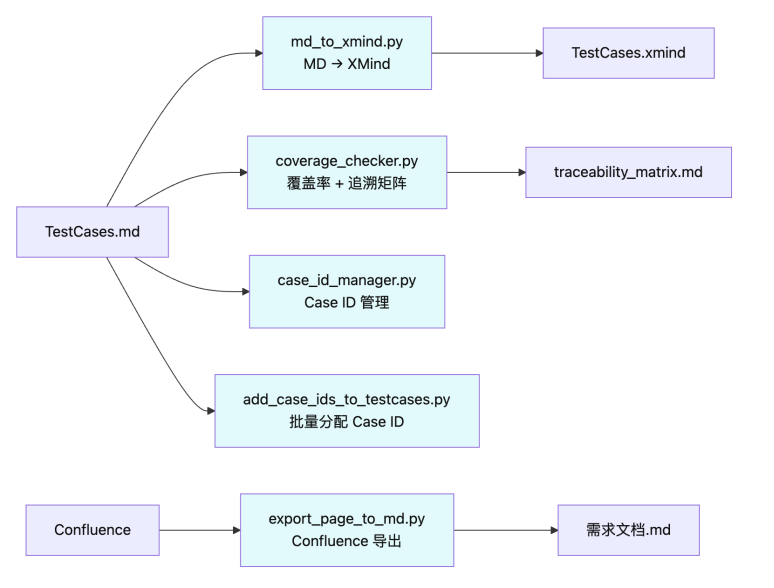
4.5 自动化工具链
五、数据流与衔接协议
5.1 端到端数据流
5.2 衔接协议
两个 Skill 之间通过 YAML Schema 契约 连接,协议包含 5 个约束:
5.3 文件组织结构
.cursor/skills/custom/
├── dbp-loan-requirement-analyzer/ # Skill 1: 需求分析师
│ ├── SKILL.md # 技能入口文档
│ ├── scripts/ # 工具脚本
│ │ ├── export_page_to_md.py # Confluence → MD
│ │ ├── confluence_client.py # Confluence API 客户端
│ │ └── html_to_markdown.py # HTML → Markdown
│ ├── templates/ # 模板与规范
│ │ ├── function_point_spec.md # FP 拆分规范 (18信号方法论)
│ │ ├── function_point_template.yaml # FP YAML Schema
│ │ └── require_model_rules.md # 需求提取规则
│ └── resource/{版本号}/{JIRA-项目名}/ # 项目数据
│ ├── *.md (需求文档)
│ ├── *_requirements.md
│ ├── *_FunctionPoints.yaml
│ └── images/
│
├── dbp-loan-testcase-designer/ # Skill 2: 用例设计师
│ ├── SKILL.md # 技能入口文档
│ ├── scripts/ # 工具脚本
│ │ ├── md_to_xmind.py # MD → XMind
│ │ ├── coverage_checker.py # 覆盖率检测
│ │ ├── case_id_manager.py # Case ID 管理
│ │ └── add_case_ids_to_testcases.py # 批量 Case ID
│ ├── templates/
│ │ └── case_model.md # 用例格式模板
│ ├── resource/{版本号}/{JIRA-项目名}/ # 项目数据
│ │ ├── *_TestCases.md
│ │ ├── *_TestCases.xmind
│ │ └── *_traceability_matrix.md
│ └── .history/ # 版本归档
|
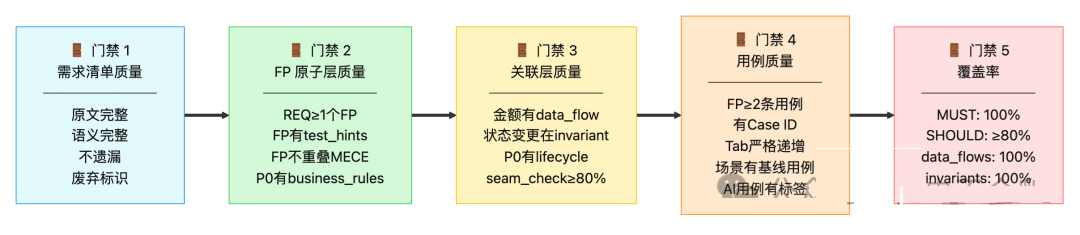
六、质量保障体系
6.1 多层门禁
6.2 三级追溯矩阵
追溯矩阵输出内容:
- 正向: REQ → FP → TC/Case ID
- 反向: Case ID → FP → REQ
- 关联层覆盖统计: data_flows / invariants / lifecycle_scenarios
覆盖率
七、创新亮点
7.1 方法论创新
| 创新点 |
说明 |
价值 |
| 18 类信号扫描 |
系统化的需求分析 checklist,覆盖文本(10)+图表(5)+结构(3)三类信号 |
消除人工分析遗漏,AI 可按清单逐项扫描 |
| 功能点中间层 |
REQ → FP → TC 三级分层,FP 作为原子可验证行为 |
消除粒度跳跃,AI 生成用例时有精确输入 |
| 三层关联结构 |
data_flows + invariants + lifecycle_scenarios |
解决原子 FP 丢失全局关联的问题 |
| seam_check 接缝检查 |
生命周期场景中相邻步骤的接口验证 |
确保上游输出 = 下游输入,不断链 |
| FP type 智能覆盖策略 |
按功能点类型差异化选择覆盖类型 |
避免机械三板斧,生成高价值用例 |
7.2 工程实践创新
| 创新点 |
说明 |
价值 |
| Cursor Skill 机制 |
将 QA 方法论编码为 AI Agent Skill |
方法论可复用、可迭代、可分享 |
| YAML Schema 契约 |
上下游 Skill 通过结构化协议衔接 |
松耦合、可独立演进 |
| AI + 人工协同 |
AI 生成框架 + 人工评审确认 + 人工补充策略 |
兼顾效率和质量 |
| 影子目录版本管理 |
每次生成自动归档到 .history/ |
可回溯、可对比 |
| Case ID 相似度复用 |
90% 相似度自动复用 Case ID |
避免用例重复,支持跨版本追踪 |
| 基线场景 [基线] 标记 |
E2E/不变量用例融入业务场景并标记 |
P0 回归套件自动识别 |
| AI-GEN 标签体系 |
AI 生成用例统一标记 标签:AI-GEN,人工用例标记 MANUAL |
区分用例来源,便于质量追踪和人机协作度量 |
| XMind 自动生成 + 标签 |
MD → XMind 转换,支持基线标签 |
一键导出可视化思维导图 |
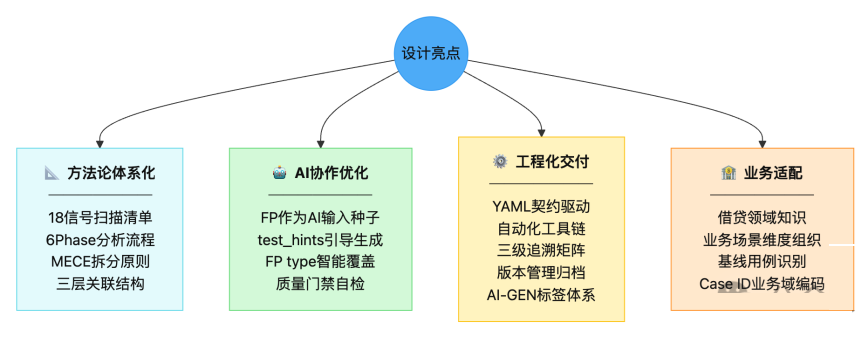
7.3 设计亮点总结
八、未来提升方向
8.1 短期优化 (1-2 个月)
| 方向 |
当前状态 |
提升目标 |
| FP 自动验证 |
质量门禁依赖 AI 自检 |
编写 Python 脚本自动校验 YAML schema、编号连续性、test_hints
完整性 |
| 增量更新 |
每次全量重新生成 |
支持需求变更时仅更新受影响的 FP 和 TC,保留未变更部分 |
| 覆盖率可视化 |
文本报告 |
生成覆盖率热力图,直观展示薄弱区域 |
| 用例去重优化 |
90% 阈值硬编码 |
引入可配置的去重策略,支持语义级去重 |
8.2 中期演进 (3-6 个月)
| 方向 |
说明 |
| 测试数据生成 |
基于 FP 的 inputs/outputs/boundary 自动生成测试数据集,支持参数化用例 |
| API 自动化用例 |
基于 api_spec 字段自动生成可执行的 API 测试脚本 (Python/Java) |
| 多项目知识库 |
跨项目复用 FP 和用例模板,建立借贷领域知识图谱 |
| 概要设计联动 |
自动从 TD 补全所有 api_spec,实现 PRD+TD 双源驱动 |
| 回归套件生成 |
基于 [基线] 标记自动抽取 P0 回归套件,支持按版本差异裁剪 |
8.3 长期愿景 (6-12 个月)
| 方向 |
说明 |
| 需求变更影响分析 |
当 PRD 更新时,自动识别受影响的 FP 和 TC,生成变更影响报告 |
| 测试平台集成 |
与 Jira、TestRail、Confluence 双向同步,用例直接推送到测试平台 |
| 可执行测试生成 |
从用例 → 可执行脚本的完整链路,支持 API 和 UI 自动化 |
| 跨团队泛化 |
从借贷业务扩展到支付、风控等其他业务线,沉淀为通用 QA Skill 框架 |
| 质量度量闭环 |
从需求覆盖 → 用例执行 → 缺陷关联 → 质量报告的全闭环 |
九、总结
核心价值一句话
通过 "18信号扫描 → 功能点中间层 → 智能覆盖策略" 的三级方法论,将 AI
从"辅助写用例"升级为"辅助做测试设计",实现需求到用例的结构化、可追溯、高覆盖的全链路生成。
关键数字
| 指标 |
数值 |
| 信号扫描维度 |
18 类 (文本 10 + 图表 5 + 结构 3) |
| FP 类型体系 |
8 种 (calculation / workflow / constraint /
...) |
| 用例覆盖类型 |
11 种 (功能/异常/边界/幂等/并发/...) + AI-GEN 标签体系 |
| 追溯层级 |
3 级 (REQ ↔ FP ↔ TC) |
| 关联结构 |
3 层 (data_flows / invariants / lifecycle) |
| 用例格式层级 |
12 层 Tab 缩进 (含标签层) |
| 质量门禁 |
5 层 (需求 / FP / 关联 / 用例 / 覆盖率) |
| 自动化脚本 |
5 个 (XMind/覆盖率/CaseID/批量分配/导出) |
| 






 订阅
订阅