| 编辑推荐: |
本文主要分为3个部分,逐一讲解向量化回测的设计原则、架构与实现,希望对您的学习有所帮助。
本文来自于知乎,由Alice编辑、推荐。 |
|
基于Scikit-learn的向量化回测框架
回测是个老掉牙的问题了,开源社区也有不少优秀的回测框架,如zipline、backtrader等,那我们为什么要放弃他们而选择造轮子再设计一套呢?
其实我们并非放弃这些框架,只是在某些场合下,我们需要回测速度更快、数据处理能力更强的一个框架。我们将用后者快速验证因子或策略逻辑的有效性,然后再用前者进行精细化的回测。简而言之,前者“快”而后者“细”,优势互补,提高研究的效率。
那么为了实现“快”,我们需要做些什么呢?
很简单,感谢Python强大的生态圈,你需要做的最主要的事,是读文档、调包和组合。

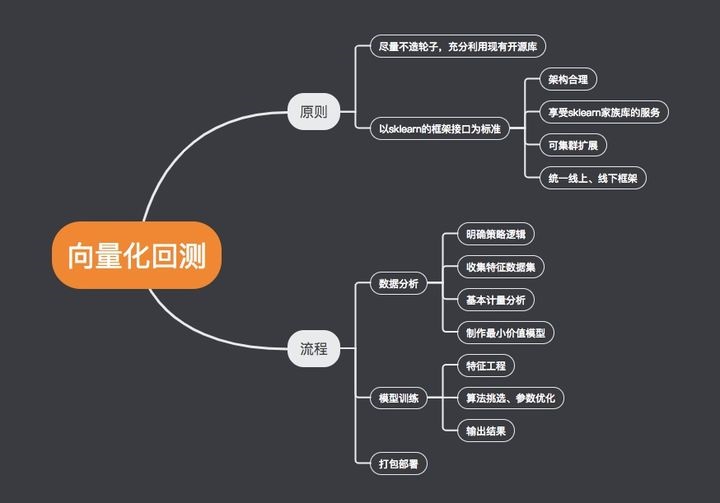
文章将分为3个部分,逐一讲解向量化回测的设计原则、架构与实现
设计原则
架构设计方面,有两个原则。
充分利用现有开源库,不造轮子
1.业务优先,不过度设计
2.主流库历经验证,坑少、也有社区的支持
以sklearn的接口为标准,可将策略视为算法对象
1.强大的社区支持,Google资助
2.合理的接口设计,丰富的家族库成员,紧贴Python生态,从sklearn-contrib中就可见一斑
3.可并行与集群训练,尤其适合数据量要求高的策略
4.便于部署,统一线上、线下程序框架
对了,打个预防针先吧:其实你可以认为,我在鼓励你成为一个调包侠,因为这篇文章的后半部分,基本都是在调用各类主流库的接口。但引用前人的话来说:
从人的客观认识规律来讲,你应该先成为一名调包侠。它有助于你抛开细节的枷锁,清晰地为一个现实目标搭建框架。你可以腾出更多的精力集中于解决方案的设计,而不是在基建设施上停滞不前。这些现成的程序包,能够为你快速地搭建起可以提供反馈的实验模型,让你通过实践来启发更多的思路。
“顺风而呼,声非加疾也,而闻者彰”,人的强大所在,就是在于善于利用工具、组合工具。
架构
流程方面,我们遵循机器学习监督式算法的开发流程,将策略视为自变量X和因变量Y之间函数映射关系,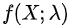 。
。
这里f代表映射函数,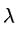 代表映射函数中的参数,而监督式学习的任务就是找到恰当的函数和参数
,使得该映射尽量符合以下要求 代表映射函数中的参数,而监督式学习的任务就是找到恰当的函数和参数
,使得该映射尽量符合以下要求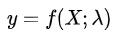
在实践中,为了实现这一目标,基本流程包括以下几个步骤
明确业务问题: 定下策略的核心逻辑
明确特征集: 搜集特征集、目标集数据,即X,Y
基本计量分析: 对于每个特征标签,均进行统计分析,确认数据质量、了解其数据分布及特点
制作最小价值模型: 做一个简易的可行模型,例如建立线性回归模型,作为对复杂模型的效果对比
以上步骤一般是非自动化的,需要借助分析员的经验,所谓garbage in garbage out,要从源头就保证好数据与特征的质量。
而以下步骤,则是我们框架中要实现自动化的部分
1.特征工程
预处理:必要的数据清洗
因子生成:基于原始数据X生成新的因子特征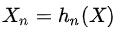 ,其中 ,其中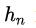 为因子n的生成函数
为因子n的生成函数
因子筛选:在全部因子中筛选出m个首选因子并进行特征融合
2. 策略训练
针对一组特征因子集,提供N1个备选策略,每个策略都有自己的信号生成方式
针对一个备选策略,提供N2个超参组合
针对一个超参组合,提供N3个交叉验证【可选】
每个交叉验证,对应的是一个带有具体超参组合的策略实例,实例在训练集上进行训练,在验证集上测试
3. 结果输出
生成最优策略实例模型
将测试集导入,生成样本外预测结果
根据效果决定是否上线或者重新调整、训练
流程看起来好像很复杂的样子,但是实现起来,却并非如此。

实现
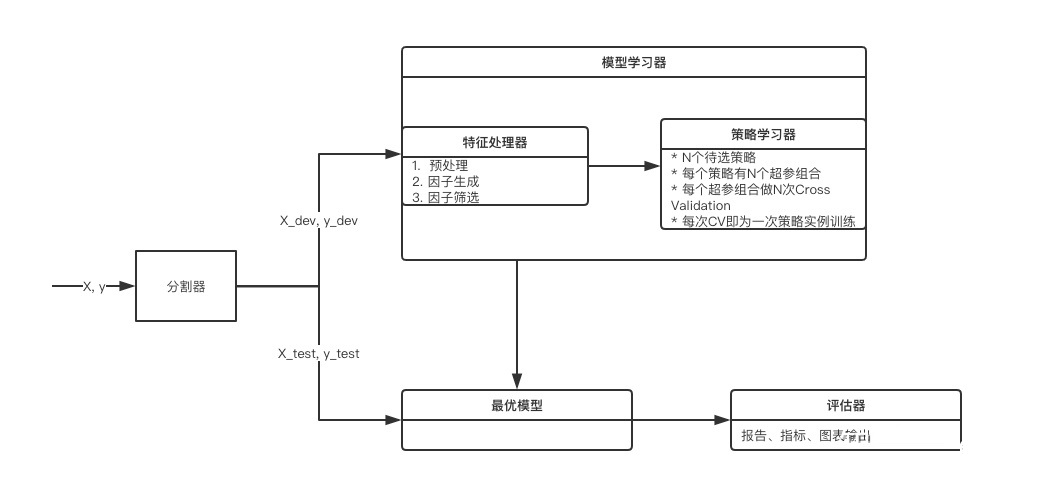
明确了功能需求之后,我们便可以着手设计框架的架构与实现。
分割器
首先,实现一个数据分割器。功能很简单,能将数据分割成开发集和测试集即可。其中,开发集用于模型的交叉验证使用,而测试集用于后期最优模型的效果测试。
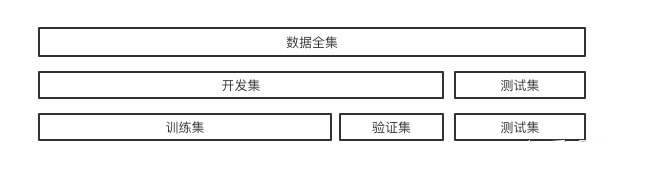
实现起来也很简单,设计一个类调用sklearn.model_selection.train_test_split函数即可。留心是否要设置shuffle=False,毕竟针对于策略而言大部分数据都是时序数据。
特别要注意的是,测试集数据在最后的模型测试阶段前,无论如何,都不应该被触碰。
因子处理器
因子预处理器以管道Pipeline形式串联或者并联多个Transformer,包括:
1.预处理方面,主要采用sklearn.preprocesser中的组件,如MaxAbsScaler,
Imputer, StandardScaler
2.因子生成方面,则定制化因子转换器,形如MATransformer这种形式,须实现接口fit,
transform以便接入到Pipeline中
3.因子筛选方面,可直接采用sklearn.feature_selection.SelectKBest,或者根据业务设计定制化筛选器
from sklearn.base
import TransformerMixin, BaseEstimator
import pandas as pd
class MATransformer(TransformerMixin, BaseEstimator):
def __init__(self, n_sma):
super(MATransformer, self).__init__()
self.n_sma = n_sma
def fit(self, X, y):
return self
def transform(self, X):
return pd.DataFrame(X).rolling(self.n_sma).mean().values |
以Transformer的形式来设计因子是颇有裨益的。一来可以将数据处理流程模块化,方便代码管理及复用。二来可使用管道的方式轻松地将不同的数据处理流程连接起来,方便多种因子的组合拼接。
通常而言,为了找到一个好策略,你还需要定义其他因子,形容均线类因子,突破类因子、形态类因子等等,寻找有效因子一直都是研究员最重要的任务之一。抽象来说,因子本质上是从原始数据中抽取出来的特征,隶属于特征工程,是一个很大的话题,所以这期不会深入探讨,这块内容计划在未来的【Analyst-特征工程】一期中做探讨与分享,希望不跳票
:)

策略学习器
这块是对策略实例进行训练和优化,是整个框架的核心部分
流程方面,主要是如下4步:
1.针对一组特征因子集,提供N1个备选策略,每个策略都有自己的信号生成方式
遍历N1个备选策略的优化过程,选取最优策略
2. 针对每个备选策略,提供N2个超参组合
对于每个备选策略都使用sklearn.model_selection.GridSearchCV来做暴力网格优化
根据需求,也可以选择随机优化算法,形如模拟退火、粒子群等
3. 针对一个超参组合,提供N3个交叉验证【可选】
如果实现这一步,建议采用在GridSearchCV的参数中设定cv=TimeSeriesSplit()以指定训练集和验证集的切分
4. 每个交叉验证,对应的是一个带有具体超参组合的策略实例,实例在训练集上进行训练,在验证集上测试
策略是如何训练的:fit()函数
策略如何进行信号生成:predict()函数
如何判断策略是优是劣质:score()函数
可以看到,由于每次完整的流程,都至少要经过N1*N2*N3次策略实例训练,因此对单次训练的速度就有很高要求。显然逐bar进行回测并不是一个好的选择,此时我们应该选择一个更好的数据结构和算法完成策略的训练,作为python准一等公民的numpy和pandas立刻映入眼帘,特别是pandas.DataFrame,拥有着强大的数据向量化处理能力,接口友好,十分适合作为我们的基础数据单元X进行传递。
因而到此,我们确定下了3个策略基类的重要接口,并以DataFrame形式传递数据
from sklearn.base
import BaseEstimator
class Strategy(BaseEstimator):
def fit(self, X, y):
pass
def predict(self, X):
pass
def score(self, X, y):
pass |
数据结构方面,对于传统的机器学习数据集,其维度一般是2维的,每列1个标签,每行1个个体数据。然而对于股票这样的时间序列数据而言,情况就稍有一点不同了。
以择股策略为例,数据通常都是三维的,包括【股票,时间,特征】。股票数据序列一般都有自相关性,展开成二维矩阵时,若处理不当,则很容易丢失时间维度上的信息。因此,可以考虑采用三维结构来存储数据信息。一来保留数据的维度信息,二来这样的结构也符合研究员的直觉。
庆幸的是,python包xarray中的类DataArray提供了这方面的功能支持,高效支持向量化运算的同时,也保留了轴和维度元信息,操作同样简单便利,相当于是一个高维度的pandas.DataFrame。所以在fit()接口收到X这样的二维矩阵数据时,不妨先转换成3维数据以便于后期模型逻辑的处理。
而整个策略训练的过程,实际上可以看做我们从3维矩阵中提取标量指标的过程。其过程如下:
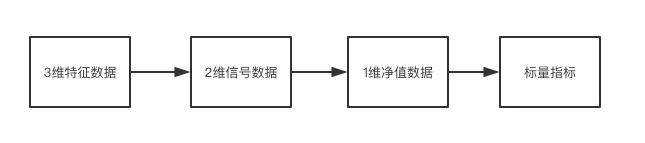
1.通过对3维矩阵的处理,我们能得到2维的信号矩阵数据,横轴为时间,纵轴为标的名称,值为对应时间下、给定标的的信号值(权重值)
利用xarray.DataArray.sel().to_pandas()的操作,我们能便捷的抽取出某个特征标签的矩阵信息,以策略逻辑叠加处理多个特征信息,获得最终的信号矩阵信息
2. 得到信号矩阵后,我们确认了各个时间点的标的持仓情况,以此,可以计算下个时间阶段的收益情况,进而得到整个资产组合的收益曲线
一般情况下,我们会对信号矩阵采用shift(1)的操作,然后和收益矩阵close_df.pct_change()进行点乘,并按标的轴方向加总,得到净值曲线
3. 对于收益曲线,一般以年化收益、夏普比率、或者最大回撤幅度作为策略拟合优度的度量
最简单的例子只需要四行代码即可。
signal_df = (ma_12
> ma_26).astype(float)
pnl_ratio = (signal_df.shift(1) * close_df.pct_change()).sum(axis=1)
nav = (1 + pnl_ratio).cumprod()
total_return = nav.iloc[-1] - 1 |
可以注意到,整个过程中的,我们刻意的不使用任何for循环,而是把所有的数据处理任务交由xarray,pandas,
numpy,它们是高效的数据处理包,能帮助我们实现充分向量化的目标,到达快速训练和回测的效果。对于单机可处理的数据量而言,数据越大,加速效果越好。
训练完毕后,score(X, y)会以同样的流程处理测试数据,输出模型的样本外训练效果。
到此,我们便完成了一个带有具体超参组合的策略实例的训练,剩下的工作,交给GridSearchCV即可,你可以去冲杯咖啡,回来就该有一个最优策略模型出来了。
评估器
通过策略学习器,我们得到开发集上的最优策略模型,现在需要我们进行最后的收官测试阶段
先以整个开发集X_dev, y_dev重新训练 带有最优超参的策略模型
然后以测试数据X_test, y_test(again,测试集数据在此阶段之前,无论如何,都不应该被触碰)输入评估策略效果,如果效果优良,那么恭喜你,你得到了一个统计学上验证有效的策略!
小结
到此为止,“调包侠”的任务全部完成,你会发现回测框架的代码量并不多,大部分代码逻辑都在讲如何把现有库的接口以合理的形式聚集起来。对于研究员而言这已然足够,自动化且高效率的训练验证流程已经可以让他们潜心研究,将精力放在因子和策略的设计上。
当然,这个框架也还有两方面的不足:
一者,框架目前还是单机运行的,对于简单策略而言是足够的,但是如果策略涉及了复杂的处理逻辑,或者数据量庞大,单机显然是无法处理过来的。土豪的方案一般是扩内存、提性能,而更一般的方案则是集群运行。庆幸的是我们采取了sklearn的设计方案,你不需要重头进行集群设计,你已经拥有了不少现成的且经历验证的集群库,动手尝试一下dask和spark-sklearn,集群化也触手可及。
二者,是策略模型还不能实盘。当然,如果不是中高频策略,对延迟要求不高,我们训练出来的结果,还是有上实盘的能力的。我们需要额外做的是:
定义一个数据抓取器:能按时将特征数据抓全,并整理成DataFrame形式送到我们的策略实例,由策略实例生成信号矩阵
定义一个简单的发单器:能将信号矩阵处理成对应的订单发送给交易所。
但是,此时我们还是不建议直接上实盘的,因为这个系统还太脆弱了,没有风控,也没有仓位管理,这好比是一辆车,装了引擎能跑,却没装刹车停不下来。这样的系统是相当危险,一不小心,就容易翻车。 |









