| 编辑推荐: |
重点分享了基于
AI 的自动化测试框架。以及在实践过程中领悟到的深度学习的优势与挑战。
本文来自于微信公众号前端之巅,由火龙果软件Anna编辑、推荐。 |
|
理想中的 UI 测试框架
从测试框架的角度来讲,肯定会有一些自己想要的功能或需求,对这个测试框架的期望也会很高。

首先,在衡量一个测试框架的过程中,会找一些指标来衡量这个测试框架的好坏,比如说我们会要求这个测试框架易于维护和开发,修改后的代码稳定性变得更好,会要求它的执行效率能够满足需求。在这些基础要求之上,可能还会要求它能够有些跨平台的能力,跨应用的能力,或者支持
Hybrid 的能力。
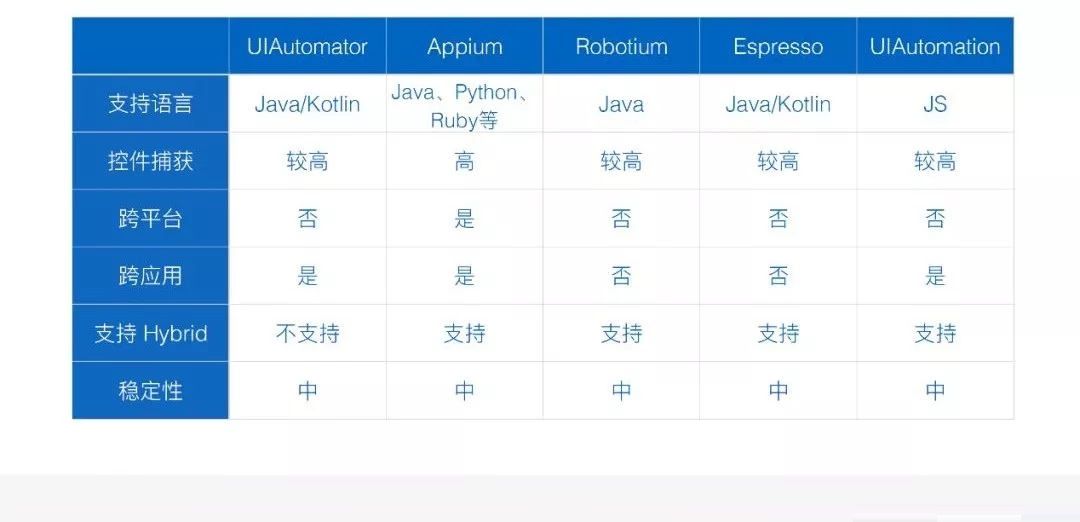
现在主流的测试框架在这些指标上的表现其实不太一致,因为有不同的侧重点。举个简单的例子,像 UIAutomator,它其实本身侧重于和系统的交互能力,所以它在跨应用的能力上会表现的更强一点,但是相对来说它对
Hybrid 这种场景的支持会相对来说弱一点。像 Espresso 这种框架,它的能力很强,可以做很多事情,比如可以拿到当前应用的运行状态,拿到当前代码里面内存的数据,这些功能其他测试框架都是不能做到的,但是这个测试框架,其弊端就是可能对你代码的要求比较高,要求你理解一些代码的运行逻辑,它本身更倾向于面向开发者的测试框架。
整体来说,每个平台它自己提供的测试框架,其实都不具有跨平台的能力,现在比较主流的具备跨平台能力是第三方的
Appium 这样一个框架,这个框架它本身是把各个平台的测试框架进行了整合,然后再进行封装,所以这种跨平台能力并没有实现技术上真正的跨平台。而且由于它做这些封装,支持很多语言,支持各种平台,它是一种基于协议的框架,这个框架就会导致代码的可维护性,相对来说比其他框架都要低。

总结一下传统框架都会存在的一些缺点。第一个就是跨平台能力比较差;第二个是跨应用能力也满足不了我们的需求。此外现在所有的测试框架都会有一个问题,就是系统对于
ID 的依赖性比较强,这个在之前问题不大,但是随着近期移动端技术的发展,移动端应用在发布的时候,会做一些资源
ID 混淆的事情,所以在每个版本里面 Android 的资源 ID 都会发生变化,这个时候你会发现你的测试的
ID 不断地变更,每个版本的测试代码都要进行维护。第四个是,由于要去捕捉控件,我们需要拿到控件对应的属性,这些属性很难直观去拿到,需要先
Dump 系统视图树出来,找到它的对应关系,才能够找到这些属性。相对来说,控件的捕获能力在我看来,是一个相对比较高的成本。还有一个问题就是,目前在所有的框架里面,在
Dump 系统树的过程中,都会存在一定级别的失败。
基于这些缺点,我们想要一个什么样的框架,才是理想的框架?我想象这种框架是一个支持所见即所得的自动化框架,什么是所见即所得?因为我们平时很多做
UI 测试的过程中,其实就是在模拟用户的操作。而用户在进行使用的时候,是不需要这些控件 ID 信息的,它是一种所见即所得的操作,所以如果我们的自动化测试框架里也能够做到这点,对测试代码的可维护性就会有个显著的提升,包括它的理解上也会变得轻松愉快。
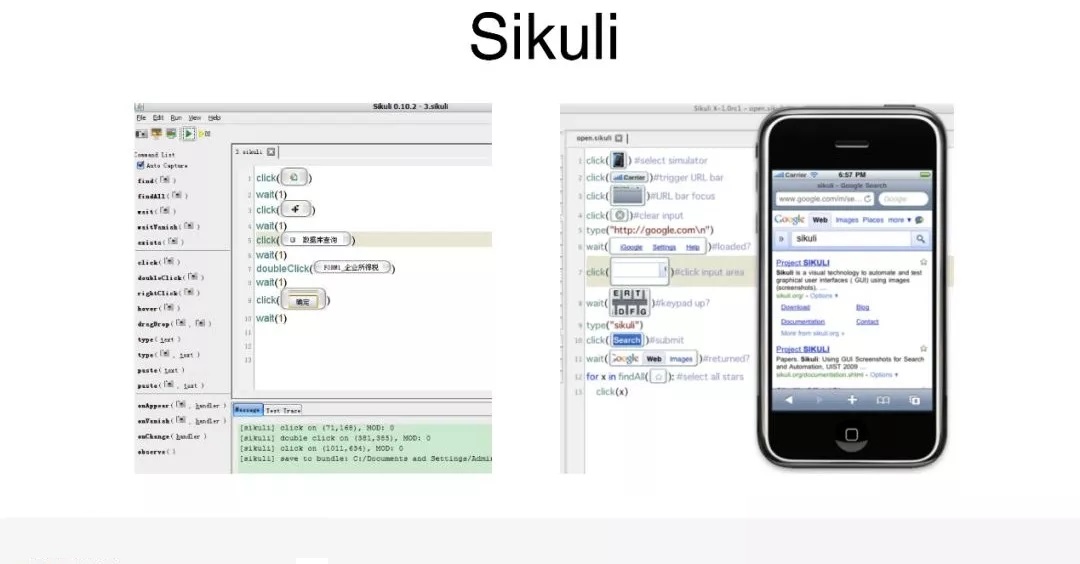
其实行业里有一些人,之前也不断地做过一些这样的尝试,这个是早期的,在 PC 端的测试框架,叫 Sikuli。可能测试做得比较久的人会有一些涉猎,现在这个框架已经不维护了,它的特点,是把对应的界面进行截图,如果想要匹配某个元素的话,把某个部分进行截取,匹配对应的模块,完全通过图片匹配的方式,做对应区域的选取和验证。这个框架是
PC 时代的,现在已经不怎么维护了。
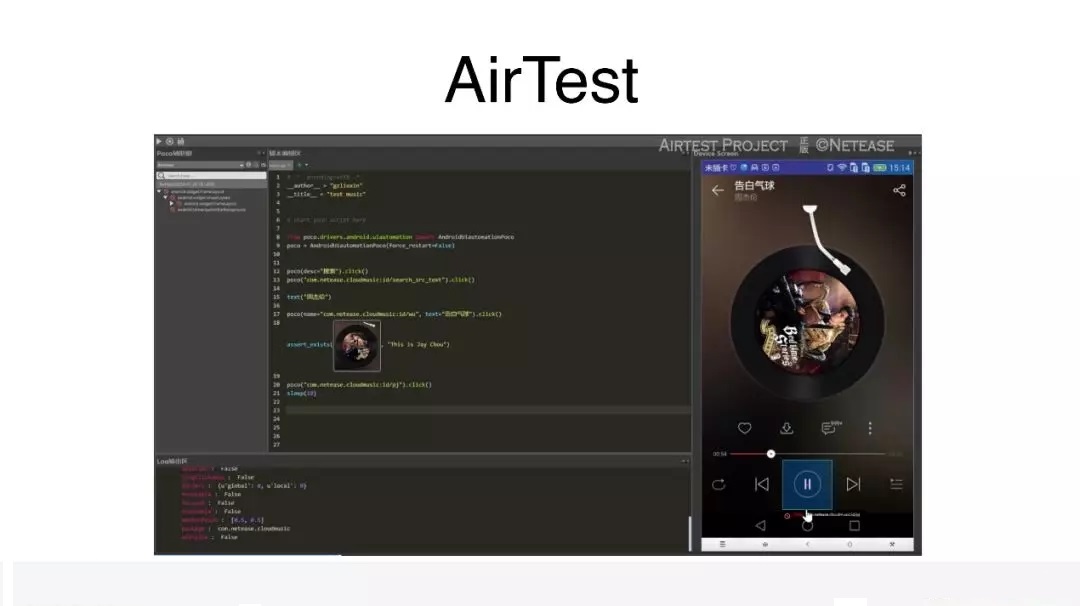
其实近期也有一些公司做过这样的尝试,例如,网易推出了一个比较火的框架 AirTest,这个框架本身能力比较强,一个很突出的特点也是基于图片截图匹配的方式。

这种完全基于图片匹配的方式存在很多不足。第一是准确率不足,不同手机分辨率情况下,或者手机存在一些色差的情况下,你会发现,你尝试截的那张图用来做测试用例,再去匹配新手机上的截图,经常匹配不上,就是准确率的问题。第二,截图的操作方式,肯定是构建不出层次结构的,它所有写的代码都是一层平级的概念。还有就是,由于我们是完全基于一张截图的方式,比如图片应用稍微发生一些界面上的变化,背景稍微发生一点变化,你会发现你都要重新截图,这个时候稳定性会变得很差。可以想象,这样的代码维护成本会变得比较高。
.jpg)
可以看一下平时交流过程中,你会是一个什么样的状况。我们在描述一个场景的时候,比如说点一下 tap
下面 VIP 按纽,或者点一下会员按纽,相对来说,在沟通过程中是一个比较直白的操作。当我们想要把这样的描述翻译成代码的时候,希望它是变成什么样的代码。我们进行一个简单的翻译,比如说前面点击会员按纽,就变成
find('tab').find('会员'),如果你要是写这样的代码,会发现代码维护性就会变得非常好。

要做这样的事情,需要具备什么样的能力。第一个就是我们要具备图像切割的能力,能切割对应的块出来。第二就是需要图像分类的能力,能够知道这块是什么东西。第三个需要
OCR 的文字识别能力,这个是由于我们没有去 Dump 一个系统树,所以不知道对应的视图里面有什么东西,要完全依赖图像
OCR 的识别能力,知道对应的视图里面有哪些文字。还有就是传统的图像相似度匹配能力。最后一个是像素点的操作,可以依赖传统的框架,比如给一个位置去做一些操作,也可以依赖一些机械臂来帮我们来完成像素点的操作。
深度学习带来的机会
在传统的技术框架里面,有一些能力得到满足,还有一些能力无法得到满足。这个时候,我们发现其实在深度学习技术发展过程中,它刚好能够帮完成一些之前的技术不能完成的任务。
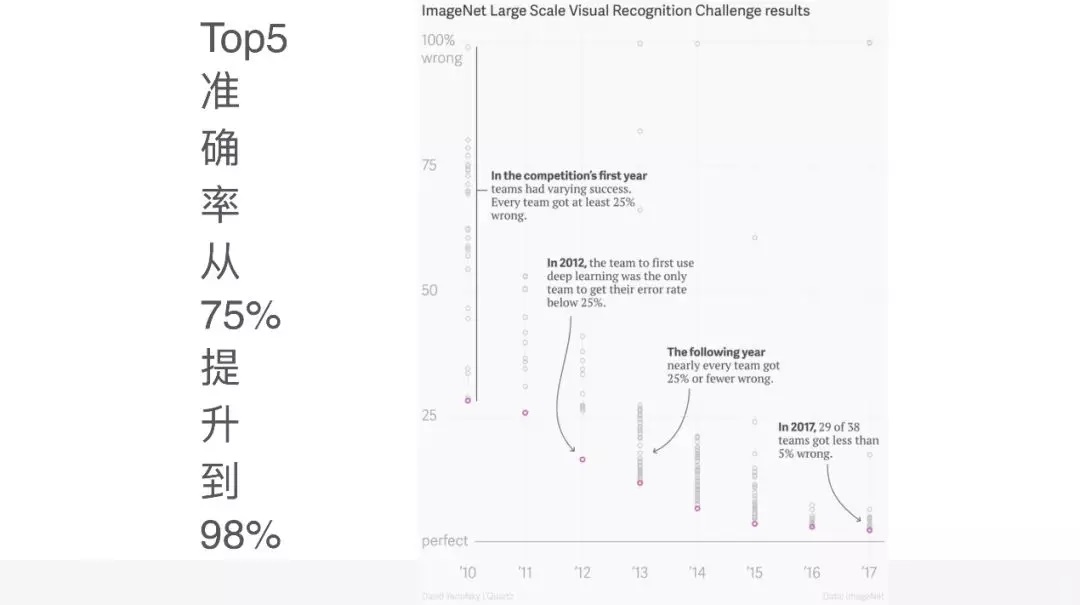
这会给我们带来什么样的机会呢?第一个就是它的图像分类能力,可以看到这是李飞飞发起的 ImageNet
大型视觉分类挑战赛的结果。你会发现在 2012 年以前,也就是说在深度学习被引入到图像分类比赛之前,它的准确率一直在
75% 以下没有突破,但是在 2012 年,深度学习被引入到图像分类领域以后,它的准确率每一年都在提升,而且到最近一年,已经达到
98%、99% 的准确率,这个准确率意味着什么?因为之前看到过一些文章说,如果它的准确率提高到 95%
以上,就已经超过人类分辨图像的水平了,这是一个相当高的水平。
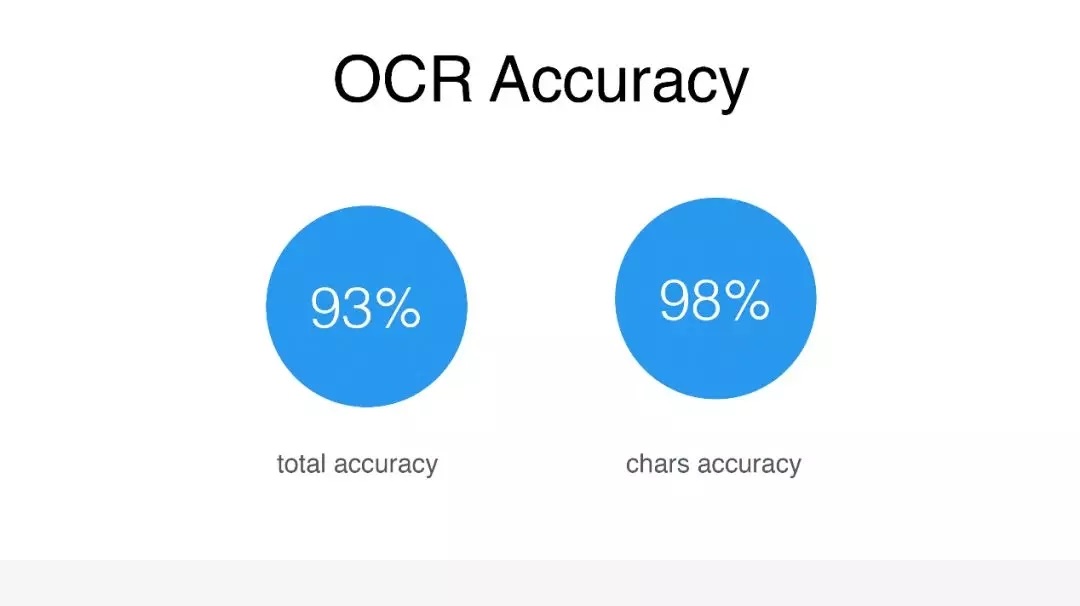
第二个是 OCR 的能力,我没有用一些行业的数据,而是和我们 OCR 团队做了一些尝试,他们给到一些数据。这里有两个指标,一个是它的完整准确率,一个是文字的准确率。完整的准确率是指,在一个截图里面,会有一些
title,会有一些词组,在一个 title 里面有一个字出现了错误,就认为这个 title 的识别是错误的,这就作为一条错误,这样的准确率能够达到
93%。文本的准确率,能够达到 98%。OCR 里面有一个比较重要的是召回率,整体的召回率在测试过程中是不太理想的,只有
70%-80% 这样的状态,但是在我们的应用场景里面,由于会做提前的预切割操作,给 OCR 的内容相当小的一个模块,整体来说对于它的召回率要求会更低一点。最后测试下来,它的确能够满足需求。
AIon 的诞生
有了这些技术基础以后,我们就去尝试 AIon 的框架。
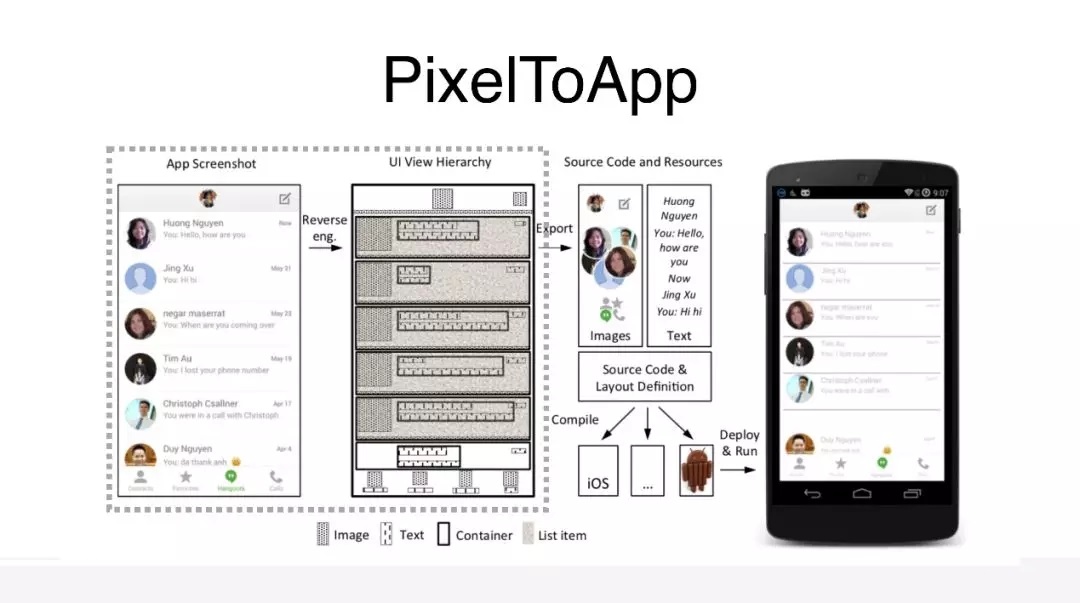
做这个框架之前,肯定会去对比一下,行业有没有人做过类似这样的事情,有没有可参考的地方。其实发现,在做
UI 自动化测试框架的时候,它和我们现有的一个领域比较像,UI2Code 这样一个应用场景,把一个应用截图,或者把一个
UI 的设计图,通过图像识别的方式生成出对应的代码,这样的应用场景和通过图像识别,找到它的输入元素进行点击是很像的。在这个方面的尝试,就有很多的例子,比如说像
PixelToApp,是国外的一个大学,他们在 2012 年到 2014 年的时候发布了这样一个项目,这是一个用传统的图像处理技术完成的项目。它的主要流程是,先把图片逆向生成视图树,然后提取出对应的资源,根据前面的视图树和资源就能生成核心的应用代码。
这里最核心的部分,就是通过一个截图,逆向生成出来我们想要的视图树,因为这个视图树生成出来以后用来生成布局图,还是用来生成
APP,或者用来做测试点击,其实是一样的。
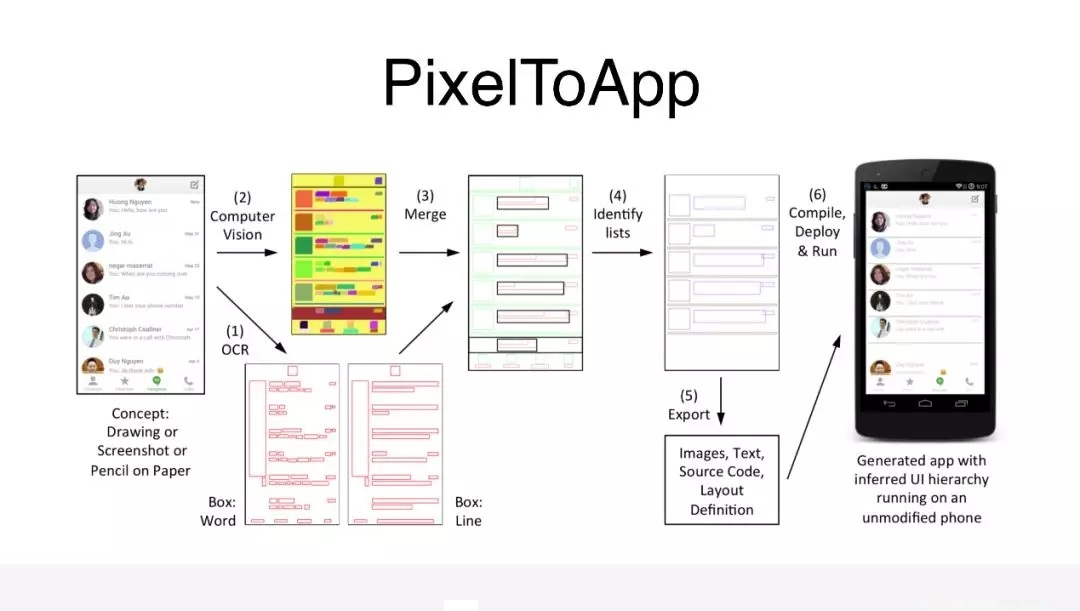
看下这里它是怎么做的,OCR 去识别出文本区域的位置,进行一个标记,再用图像识别技术,识别出对应元素的位置,同样也会生成布局图,再把这两个布局图进行融合,主要目的是提升最后布局的准确率,再对新的布局进行分析,比如说我们可以分析出它有没有列表,最后就会生成最终的布局文件,然后生成对应的
APP。
存在较多的问题:
第一个是它在复杂界面上的处理会比较难,文章里面用的图片相对来说会比较简单一点,但是实际应用中很多复杂场景,它根本处理不了。
第二是它应用传统的图像处理算法,一个比较大的问题是,它的阈值在不同的场景下需要不断调整,很难做到自动化。
第三是,很多算法在碰到一些问题的时候,它的瓶颈是很难突破的,跟我们前面图像分类的瓶颈是一样的,比较难突破。
第四是,由于它单个算法的瓶颈很难突破,可能会用很多算法,通过一种 filter 流的方式,让组合的方式达到更好的效果,这个时候会发现,你会叠加很多算法,最后整个代码的维护性会变得更差。
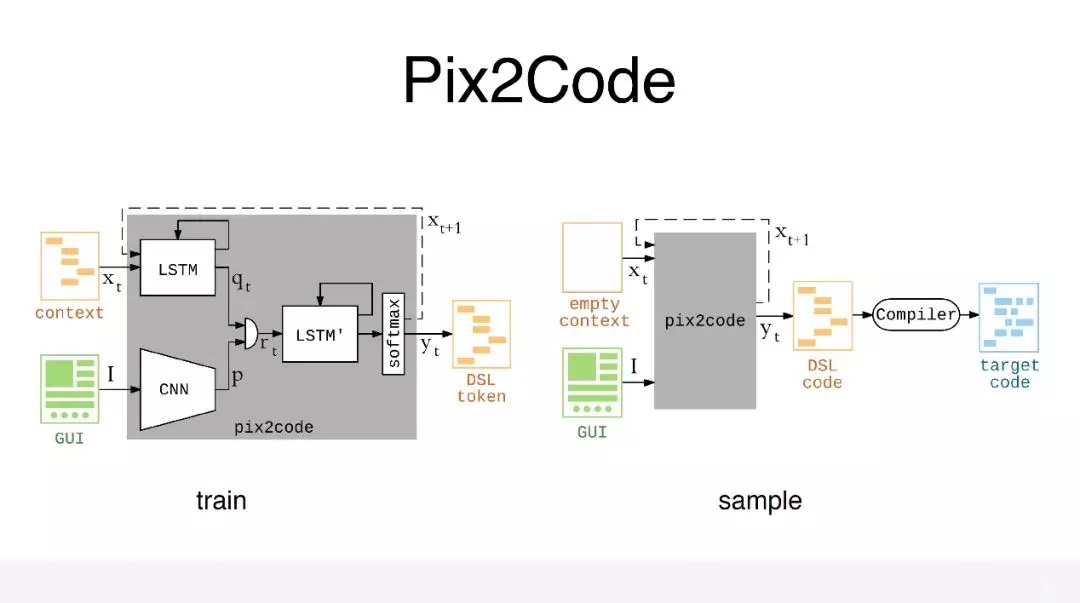
除了这种基于传统的图像处理技术之外,在深度学习以后,也有人做过这样的尝试,叫 Pix2Code,是一个比较知名的开源项目,跟我们现在图像识别里面图像理解的应用场景很像。给你一张图片,你告诉我,这个人是在打电话,还是在骑自行车。我们可以看见它构建了深度学习端对端的模型,这个模型相对来说会比较简单,它有两个输入,一个输入是图片的截图,另外一个输入是图片截图对应的布局描述文件,这个布局描述文件只是描述了布局里面的关键的视图节点,比我们真正的布局要简单很多。
第一步是先把对应的截图通过 CNN 网络生成特征向量,然后会把对应的布局描述文件切割成一个序列,序列的每一项先通过
LSTM 模块,也会同样生成特征向量,这个特征向量和之前的 CNN 的特征向量会进行级联,级联完成以后,再通过
LSTM 模块,再通过 softmax 进行一个分类,对当前的项进行预测。预测完了以后,它同时会把这个输出作为下一项的输入,这个模型相对来说会比较简单。且不说这个模型的好坏,但至少从准确率上来讲,它肯定是满足不了需求的,因为它的准确率只有
70% 左右。其实现在也有一些人在这个基础上,做过一些优化,比如西安交通大学之前就发过一篇论文,也是类似的这样,在它上面做了一些优化,这里就不做展开。

这样一个端对端的模型,它其实存在一些问题。第一个是从这个模型上来讲,它的准确度是不够的。第二如果这个模型的准确率达不到要求,就必须要重新构建一个模型,会发现它的成本相对比较高。第三,现在所有的深度学习里面都会碰到一个问题,就是它的训练素材标注成本高。另外,基于深度学习图像处理的技术,它在图像切割的准确度上是很难达到像素级的精确度,它的精确度也不能满足我们的需求。所以纯传统算法处理的和纯端对端深度学习的技术,都会存在一些问题。
AIon 是怎么做的?很简单,就是做了一个融合。

接下来看一下 AIon 是怎么做的。AIon 会把这样一个截图分切,切成几块以后会发现,TAB、导航、状态栏都会被切割出来,我们会用深度学习图像分类,对每一块进行分类识别,识别完了以后,就会把对应块里的子元素提取出来,再用一些
AI 的技术,提取里面的内容,把它填充到子元素的属性里面去,最后就会得到二级视图树的结构,然后就可以去做对应的点击操作。

这是一个简单的示例代码,可以从一个 TAB 里面找到一个叫热点的东西,它就可以实现我们前面说的操作。
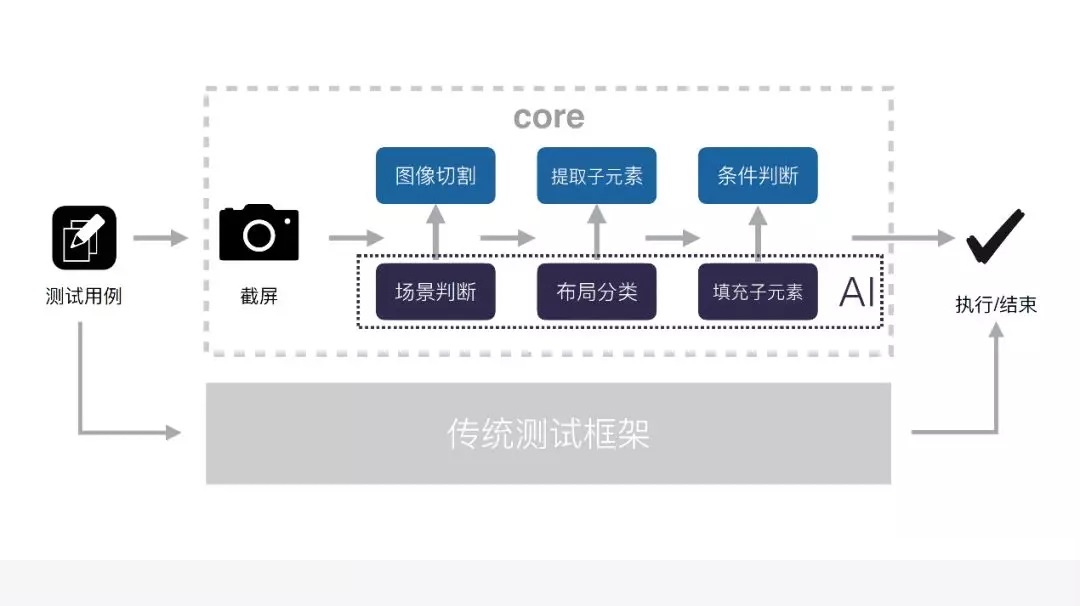
整个测试框架它的核心流程是什么样的呢?
比如写了一个这样的测试用例,第一件事情是截屏,我们会对它进行场景判断,场景判断会应用到一些 AI
分类识别,就是会识别出当前界面有没有弹出对话,或者它是否是登陆页的场景识别。场景识别完了以后,就会进行传统的图像切割,图像切割完了以后,进行布局分类,布局分类也会应用到一些
AI 的技术,分类完了以后,进行子元素的提取,对这个子元素进行填充,填充会应用到一些 AI 的技术。
最后就是当视图树构建完了之后,我们就会匹配之前写的测试用例里面的条件,进行一些条件匹配,匹配完了以后,这个测试用例就可以去执行了,这就是我们整个
AIon 的核心流程。由于考虑到之前的一些测试用例,还有一些传统的测试框架写的测试用例,我们本身还做了对传统测试框架的融合。
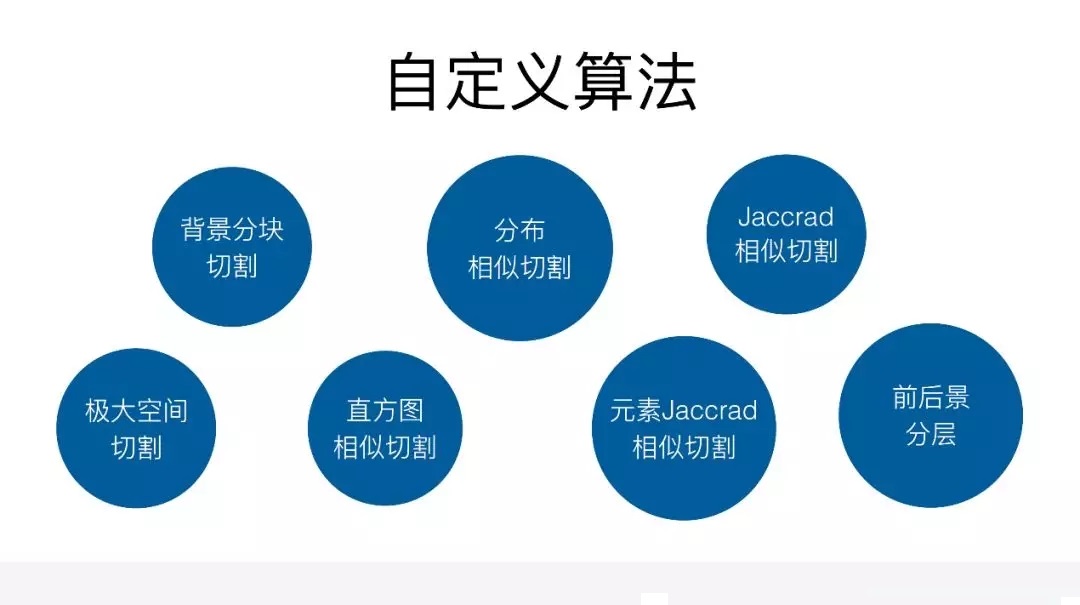
整个流程以后,接下来介绍一下涉及到的一些技术性的问题。第一个就是在图像切割里面用到的一些算法,因为有一些传统的图像处理可能会应用到很多算法,不可能把所有的算法都给大家逐一介绍,这里给大家简单介绍其中一个算法。就是利用子元素布局的相似度来切割界面。
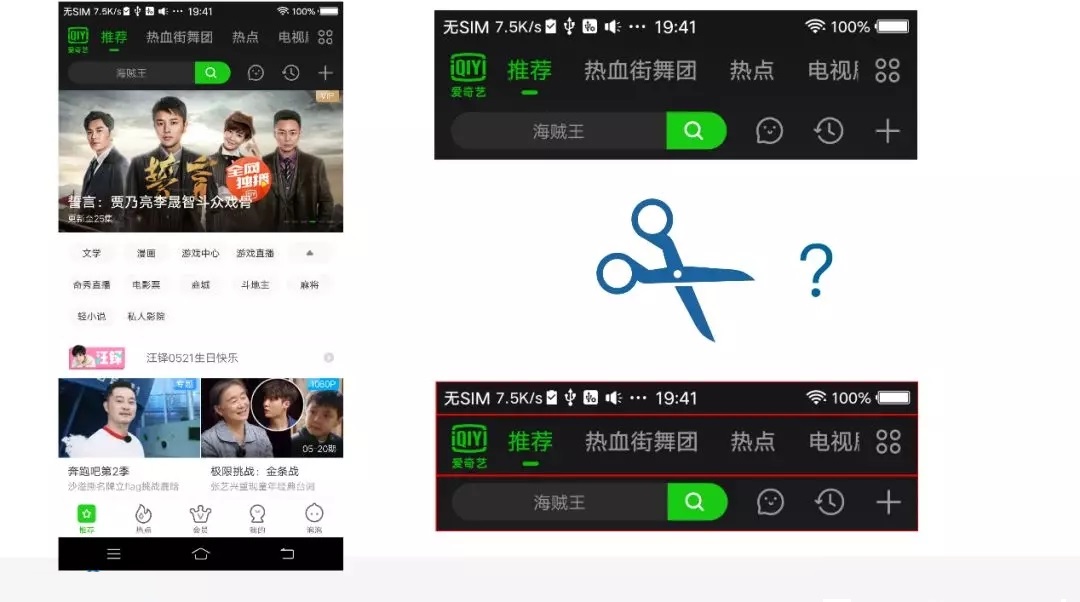
可以看到在这张图里面,要提取前面的头是比较简单的,但是如果我们要把这个头再进一步切割成下面三块,是有一定的难度的,这个时候应该怎么做?
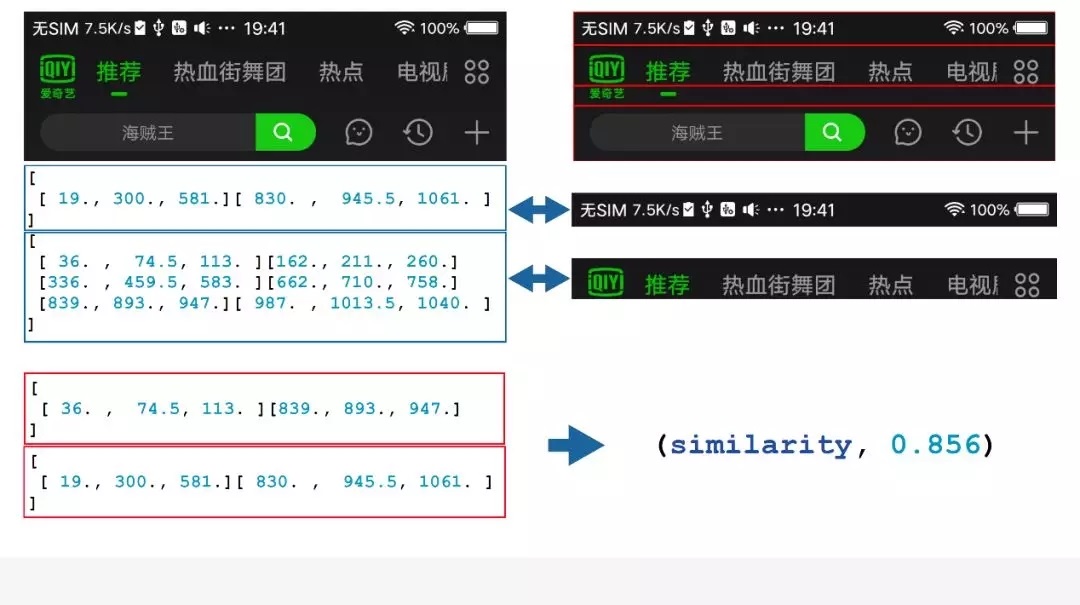
首先把它切成四块,每一块之间都会有个比较清晰的分割,然后把对每一块子元素的分布进行元素提取,提取完了以后,再对提取完的特征进行一个处理,处理完了以后,用这个处理完的特征,计算它当前的上面两个块和下面两个块的相似度,计算相似度的过程中,会应用到一些子元素的数量、分布,还有一些当前界面的宽度信息,综合起来就有这样一个相似度。可以看到,这里它得出来的相似度是
85.6%,乍看起来,它的相似度还是很高的。
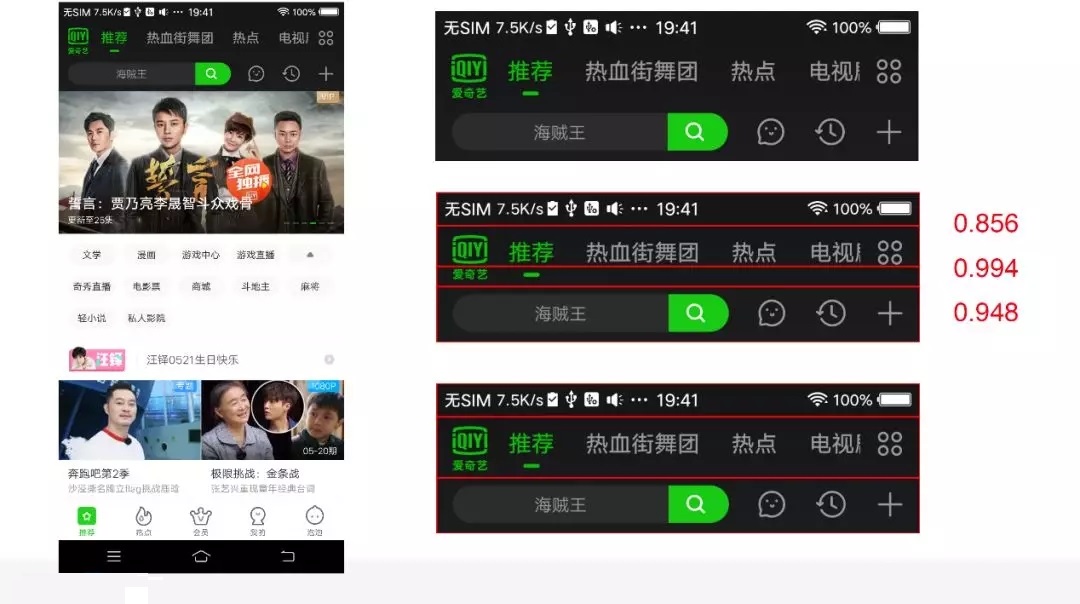
再看一下整体的三个相似度分别是多少,这张图切割出来会得到三个相似度,85.6%、99.4% 和 94.8%,在我们的定义里面,低于
99% 的都会不满足需求,所以会直接把中间这个满足需求的给去掉,其他不满足需求的就直接切割开来,这样就完成了这一块的切割。这是我们在传统算法里面的一些尝试。
我们在 AI 上也会有一些 AI 技术上的应用。
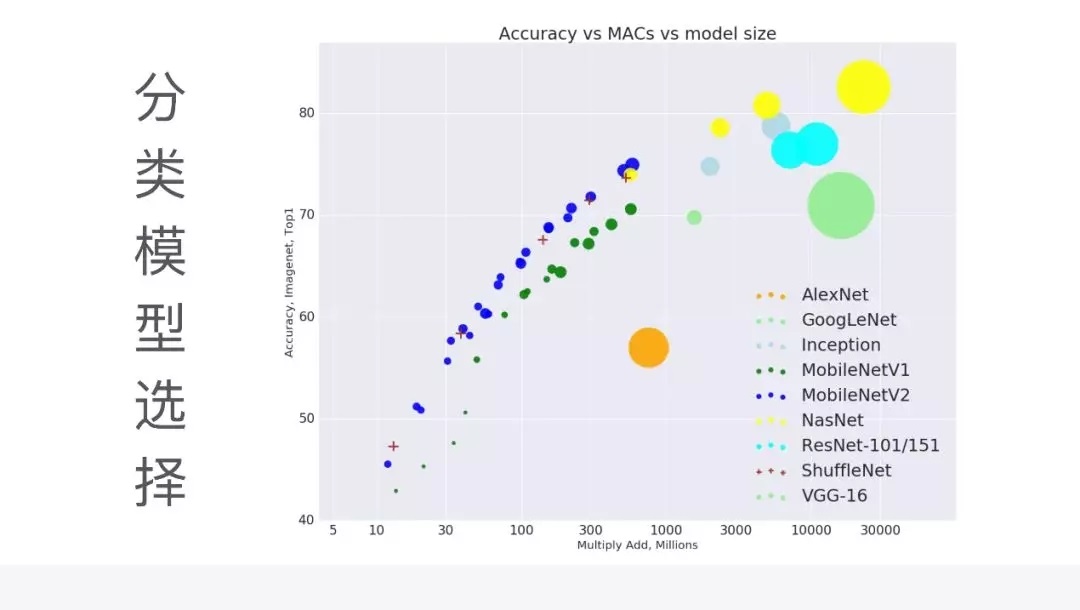
第一个就是在 AI 模型的选择,有一个最大的问题是模型的执行效率,和执行的性能上面会做均衡。早期一开始是选择
Google 的 Inception V3 这样一个网络,它的网络准确率相对来说还是比较高的,但是它现在有个问题,它的执行效率会比较慢,因为模型比较大也比较深。后面我们经过衡量,采用了
MobileNetV2 这样一个模型,相对来说它的执行效率会更高,但是它的准确率会稍微偏一点点,也是满足需求的。
除了分类模型的选择,我们在其他 AI 应用中也会碰到一些问题,也做过一些优化。
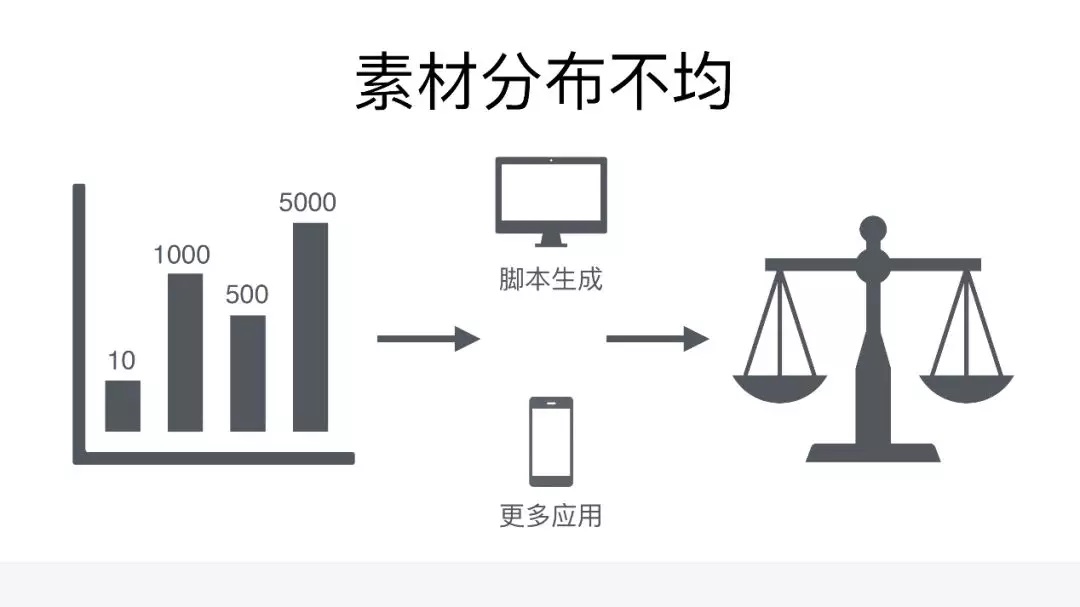
第一个就是这个素材分布不均的问题,因为有些元素相对来说是比较好截取,但有些素材因为它的场景比较少,这样的素材可能跑完了整个应用只有一两个,跑完四五个应用,发现只有十个,这样的场景对我们来说比较尴尬,这样的素材拿来训练肯定是有问题的。而我们就会通过一些方法去解决,第一个是通过脚本生成的方式,帮我们扩充很多素材。
第二个,我们会找更多的应用去截取图片,以扩充素材库。为什么用了脚本生成后,还会再去找更多应用呢?因为脚本生成是基于一些假设,而我们的假设是有一些局限性的,所以其实还是要基于更多的场景去截取更多的图片,所以会找更多的应用。通过这两种方式就能够找到比较均衡的训练素材的状态,然后就可以进行分类训练。
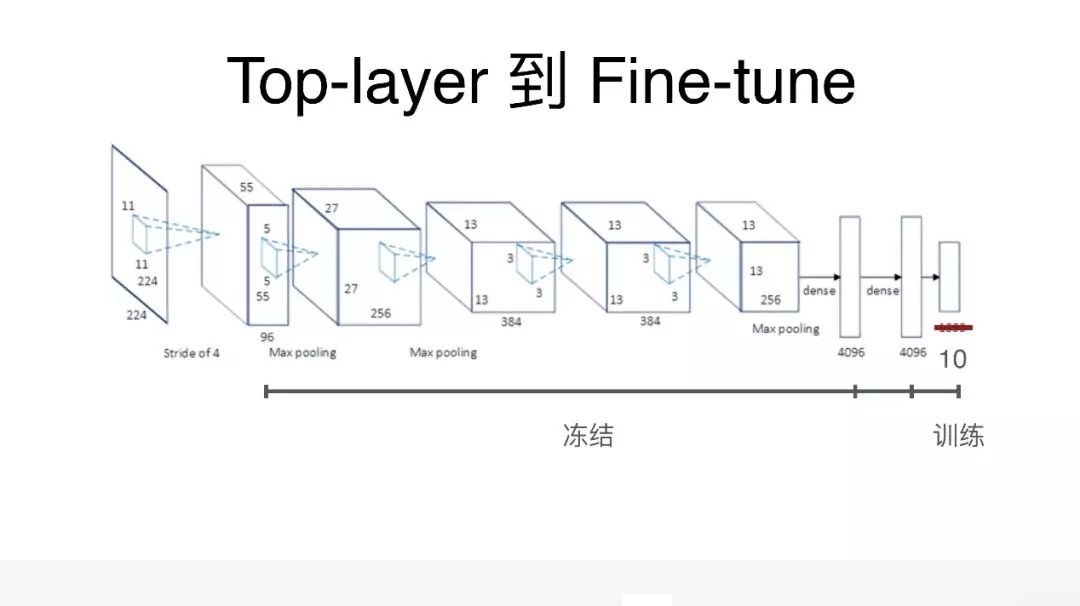
由于用的是迁移学习的方式,在迁移学习里面比较快速上手的方式就是 Top-layer 的方式,在 Top-layer
这样迁移学习的定义里面,我们会把网络模型中间的所有层都冻结,就是在训练的时候,这一段是不参与训练的,然后会把最后的分类层,替换成我们自己的分类层,只对最后分类层进行训练。这样的话,这种基于
Top-layer 的训练,已经能够达到比较好的效果。但是当我们想要把卷积率进一步提升的时候,就需要把训练的层次变得更多。比如我们之前全部冻结了,现在我们再放出两三层出来也参与训练,而这个时候训练层就会更多,这样准确率就会有一个更大的提升,这个相当于
Fine-tune 的训练模式。这样一个模式它碰到的问题是你需要更多的素材,这个在当前的过程中,也是需要均衡的问题,在素材有限的情况下,你会发现要做这个尝试,也是不太能满足需求,我们现在也还在扩充素材的过程中。
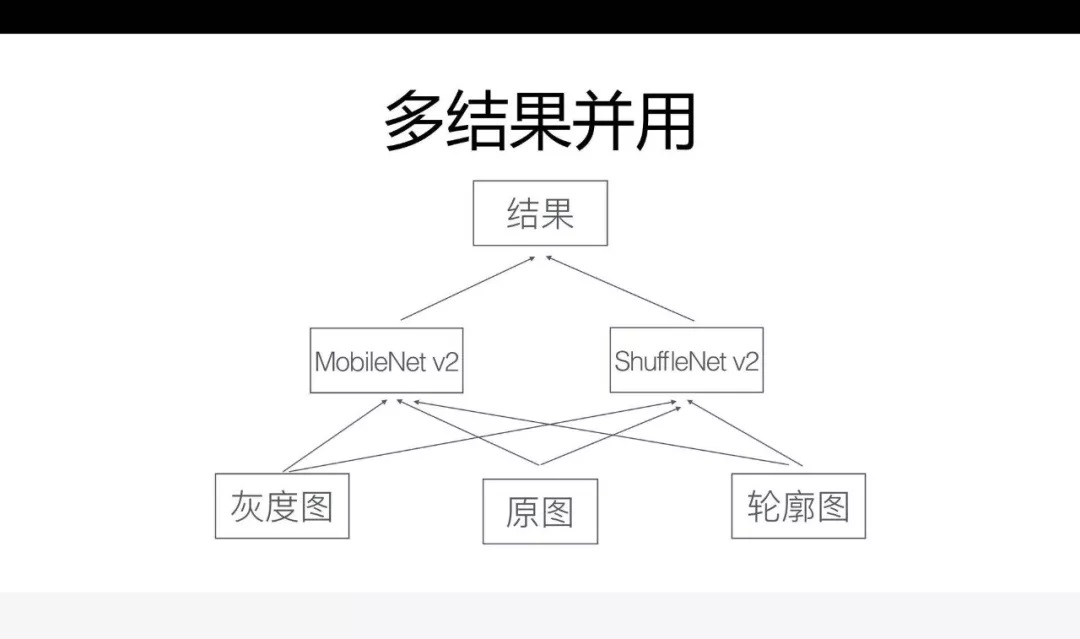
第三个是多结果并用,也是现在常用的一种方式,给一个原图,通过一个模型,就会得出想要的结果。还有没有其他的方式提升卷积率?还有一些比较好的方法,比如说可以把这张图,生成一张灰度图,再生成一张轮廓图,用灰度图、原图、轮廓图分别训练这个模型,模型在不同的图作为输入的时候,由于它的特征提取不太一致,有些图它的分类在灰度图的表现会变得更好,有些图在轮廓图里面的表现会更好,而这个情况下它会形成一个互补的关系,准确率也会得到一个比较好的提升。
其实除了在原图的输入素材上进行一些处理,还可以用更多的网络模型,我们选取了 ShuffleNet
轻量级的这样一个模型,这个时候就会产生大概六种输出结果,对结果进行最大概率的提取。最后的结果就会有一个比较显著的提升。
AIon 的优势与挑战
可以看一下整个测试框架,它本身存在哪些优势以及它会面临到哪些挑战。
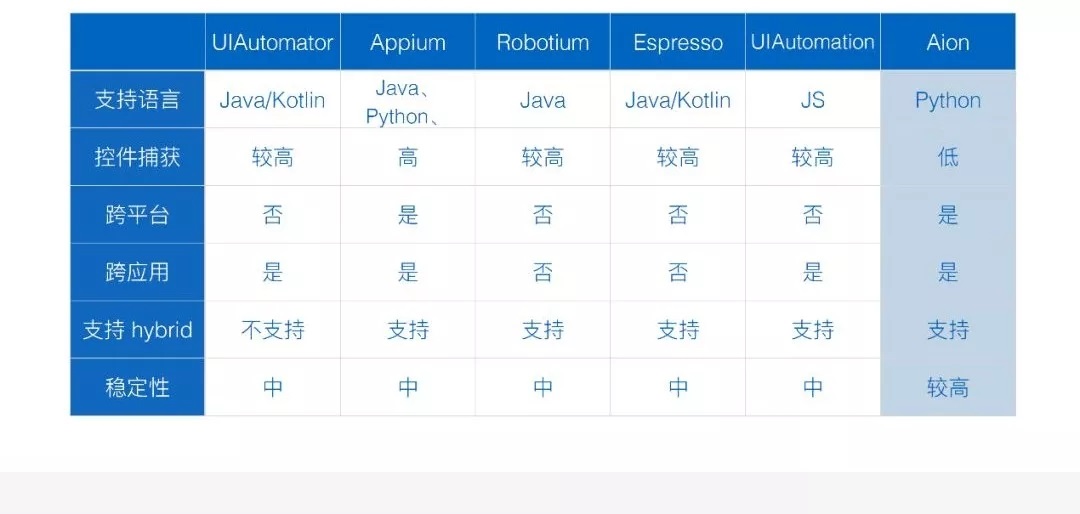
第一个,我们再看一下第一张图,这就是刚开始看的这张图,AIon 这个框架在各个指标上的表现,都会比其他框架要好,比如说它的控件捕获肯定是低的,因为它完全是基于图像识别,它的跨平台能力是支持的,由于它不依赖
ID,它的稳定性也是比较高的。

总结一下,可以看到,它是一个可见且可得的模型,比较易于理解和开发。由于它对系统框架依赖会比较弱,到现在来说,它只依赖于我们对像素点的操作,跨平台能力就会比较强。由于它不依赖于
ID,所以不用担心由于 ID 混淆的问题,导致代码要不断更新。
第四个,由于只有两层视图树,而且比较直观,相对来说,它的空间捕获会比较简单。还有个好处是,它也可以做到无缝支持传统框架,这是它相对于现在框架存在的优势。

当然它也会有些不足的地方,也就是我们所要面临的挑战。第一个,由于技术选型的问题,它一定会面临准确率的问题,迁移出来的问题是样本数量不够的问题,而且这两个问题是比较有挑战的。除此之外,还有就是执行效率的问题,因为会跑很多模型,做图像切割,做图像分类,还有
OCR 这样的事情,你会发现它涉及的步骤很多,因为我们执行一个测试用例,时间肯定在一两秒,最多两三秒。要在一两秒之内,完成这么多操作,在执行效率上也是有一些挑战的。由于是元素提取的方式,当碰到和背景的融合度比较高的场景,你会发现它的前景的提取相对来说比较困难。
还有就是像特征值非常少的元素,最典型的就是文本输入框,很多文本输入框设计只有下面一条线,再好的情况,在聚焦的情况下会有光标,要基于这样的特征值,把它识别出来是输入框,难度相对来说比较大。还有一些悬浮元素的提取,悬浮元素和第四个碰到的问题是一样的,它在一些和背景元素融合度不是很高的情况下,也没有太大的问题,但是如果碰到一些场景和背景的元素融合非常深,这个时候它也会有一些问题。
AI 未来
今天主要讲了一下可以用 AI 帮我们解决之前一些传统框架可能会碰到的问题,即使传统的算法也会碰到一些算法,用了
AI 技术也会发现,这些问题都会得到比较好的解决。除此之外,我们在 AI,还有更多的畅想,除了这个事情以外,还能用
AI 做更多的事情。

第一,错误界面的识别,在所有的自动化测试过程中,都会碰到一个问题,比如某一个界面,某一个文字被遮盖住了,或者说这两个文本出现了重叠,或者出现一个大的空白,而这样的场景如果用传统的测试框架,去做验证相对来说是比较困难的,但是如果用我们的测试框架,就会发现你要做这个事情非常简单。可以很方便地帮你检测出一大段空白,文本重叠,文字覆盖这样的场景,甚至有些背景色不满足需求也可以帮你检测出来。
第二,子元素的 AI 识别,这是对我们框架的一个优化,对传统图像匹配技术的依赖性会更弱,我们要找搜索按纽的时候,就不用搜索按纽去匹配,只要给它一个搜索文字,这件事
APM 框架公司也在做。
第三,在应用的性能优化场景上也能做了一些事情,如果在客户端能够预测出用户下一个会进入某个页面,这个是通过用户行为分析,或者基于学习的话,是可以预测有多大概率会进入到那个界面的。如果你能预测出,它下面会进入哪一个界面,你会发现,对它进行预加载的话,整个应用的体验就会变得更好。
第四个,现在也是非常火的应用场景了,那就是 UI2Code,包括微软、阿里,还有多公司都在做这样的尝试,包括我们也在做这样的尝试,就是它可以把一张图片,逆向生成布局图出来。我们在自动化测试过程中还会录取一些视频信息,录取完视频信息以后,我们会在后面对视频信息进行分帧识别或者一些分析,而这个时候如果再引入
AI 技术,你会发现它能大大提升分析时候的准确率和人工参与度。
|









