|
��Ҫ����
1.�����Զ�����һ�����Ƽ�¼���߱���������ķ�������˿��Է�������ͬһ�ײ��Խű���Ȼ�����ͬʱ�����ֲ����Զ����ű����ɽ�һ��ʵ���������д����Ӧ�á�
2.��Ȼ�Զ����ķ���˼ά����ʵ�֣������ǵĽű������ɿ��Ծ߱�һ��������ԡ�
3.�����С�����ԡ��ľ���̶ȸ��죺���������Ͳ������ٵ�ȫ���������������������һ���㡣
4.���ѽ������������Ӧ����֤��ʩƥ�������������ǿ���ʹ�ò�ͬ����֤����ȷ��Ӧ�ó����ܹ�����Ԥ�ڹ�����
5.���������ȡ�����ۻ�ͳ���Լ����������ڻع���Թ����������Ƕ�Ӧ�ó���������Ϊ���š�
����Cem Kaner������һƬ�̳�����˵��̽��ʽ������һ��ǿ���������ɶȺ��������Ա���ε��������Է�ʽ����ͨ����������йص�ѧϰ��������ơ�����ִ�У��Լ����Խ������������һϵ�б˴���Я������Ŀ���������в���ִ�еĻ����˶Բ��Թ����ijɹ����г������ϵ��Ż���
�����֮���������Ķ��壬������֪�ġ����������������ߣ�Software
Quality and Consumer��������Ϊ������Ա�ṩ������Ŀ�а����Լ���Ϊ���ʵķ�ʽ���в��Ե����ɺ����Ρ�ѭ���ؼ�¼���й淶�����������Ѿ������DZ��룬ԭ��Ҳ�ܼ�������̻���ʽ����¼�ģ��ɣ�������TestBash
3������йز����о��߹������ݽ��У�Mark Tomlinson��ϵͳ������������һ�뷨��ʾ֧�֡����������Ϊ̽��ʽ�ģ����ڷ��պͻ��ڻỰ�IJ��Լ������ɽ����֮Ϊ���ۼ������ĺ��ģ������߽������۵�ȷ��Ӧ�ó����п��ܵ���ʧ�ܵ���Ҫ���ڡ�
���Բο�������ת���ߵĶ���ѧ����ʾ��ͼ����ͬʱ���ڣ����ǵĴ��Ի��ж�������һ���ض���˳����ת����������ҡ����Թ���Ҳ������������������ǿ��ܿ���ʹ�ò�ͬ����ʵ����ͬ���������ͬ���̵����䲻ͬ������Ԥ�ڵĽ�������ߣ��š����κ����������
��������ִ�й������õ����ۼ�������ͨ�����ֳ���ķ���˼ά�͡�����ԡ������Ƽ������������к�����һ������Ҫ��Ҫ�أ�����,����¶�Զ��������С����������������ɴ��
��ȷ����������Զ���������һ�ִ����������һ�����Ƽ�¼����������ķ�������˿�����ͬһ�ײ��Խű���������ʹ�á��������ڣ����Ǹ����ʹ����Щ�����Զ����ű���ͬʱ�����ߴ��⣿
��Ʒ������ʱ�����
��Ʒ����ģ�ͺ�����¼�IJ��Գ�����ͨ���ض���״̬���Լ��ⲿ���Լ��Ը�������һ�����Dz����Զ������Ȱ��ġ������Զ�������ע�����Ǹ���һЩ�dz�����IJ�������д���Խű���
�����������ʺϹ����Իع���ԣ���������ĥ��ȫ�·���������ɿ�����ʦ���������ҽ����֮ΪShiny�ɡ�
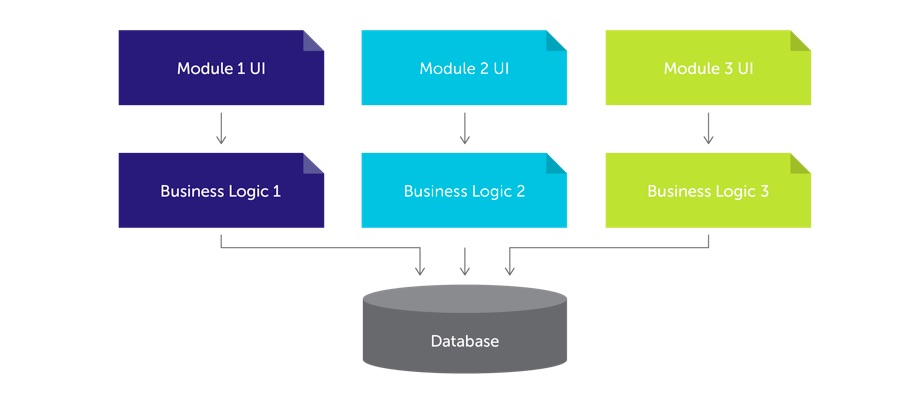
������һ���߳�����ƣ���ߵĿ���ʱ���ߺ����Ŷ�η��������������֧�֣����ٸ�Bug������������ȣ���ϵͳ����ʲô����
ȷʵ�����û��ӿڵĽǶ����������ܷdz�������������Ȼ�Ͼɵ���Ȼ�������õ�ϵͳ��������֮�£��������ͨ������֮Ϊ��������
����������ϵͳ������ʹ���Զ����ű������幦�ܵ���Щ������Ȼ�ܻ�ú������������ʱͬ�ȳ̶ȵIJ��ԣ�Ҳ��ֻ��30%-80%�IJ��ֿ��ɡ���ô���������أ���֪����
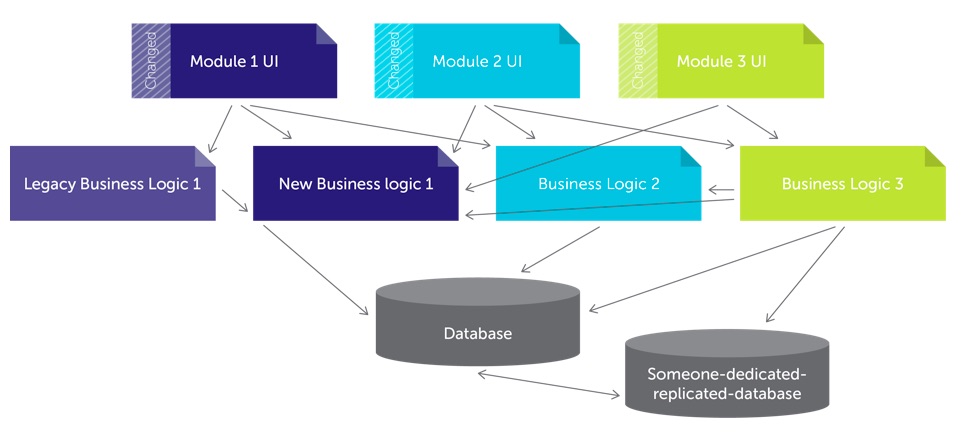
��Ȼ����ʱ��İ취����������������е������ĵ�������ԭ�еij���������ʱ�������µij����ȡ������ǵ�ҵ�ڵľ��飬��������ϵͳ�Ĺ�������ĵ���ʱ����Ȼ���¹�����Ȼ��Ҫ�������������������ǿ��С�
Ϊ�����Զ�����������������ƶ���ļܹ�
��ͼ��һ������IJ����Զ�����������ķ���ͼ�����а������㣨�����ڻ���UI��ҵ���������ݿ�ʵ��ҵ��Ӧ�ó���ķ�������UI/APIӳ�䡢ҵ��������Լ����Խű���
1.UI/APIӳ������ý�������ļ����ˣ�UI�Զ������̶߳����Զ���ϵͳ��UI�߶Ȱ���һ�����õķ�������������focus()��type_text()��click_button()��
2.ҵ������һ��������ҵ������Ĺؼ�����ɵĿ⡣ҵ�������ָ������Ӧ�ó�����ִ�е�ij�����裨��login()��create_user()��validate_user_created()����
3.���Խű�����ִ��һϵ������һ���ҵ���衣
�����˽�������ԣ�Separate Test��
��������һ�ּļ�¼����������ִ����� �C ��֤�����ִ���Ǹ� �C ��֤�Ǹ���ִ��ijij �C ��֤ijij���ϸ���Զ��������ᴴ��һϵ���������������ķ�����
do_that(), verify_that(), do_this(), verify_this(), do_bla(). |
���Խű��ᰴ��ij���ض���˳����������ķ�����
mySpecifiedCase_1(){
do_that();
verify_that();
do_this();
verify_this();
do_bla();
verify_that();
verify_this();
} |
���ڽű�û�ҵ��κ�Bug��������ijЩ�ض��ε�����ͱ����������DZ�ڵ�ϵͳ���⡣
���������1 �C �����
��ҵ��Ƕ���˵���Զ�������������κβ��趼����Ч�ġ����̽��ʽ����ʹ�����ǿ������ɵ����κ�ʱ���ִ���κβ��衣��Щ����Ļ��Ҳ�ܼ�������Ҫ��ִ�й��������β��Ժ���ѭ��ʵ�ֲ�����조���������������
���룺�������������ҵ����������Ҫ���ɵIJ��Խű�����������ÿ�����Խű����貽��������
��������������нű���
myRandomCase_1(){
do_that();
do_bla();
verify_this();
} |
�����ԣ�����ijЩ�����������ܣ������Ѿ����ɹ����У�����Ȼ��ʧ�ܣ���Ϊ��������ʵ����������ͼ�����Ч�����������ûִ�й�do_this()����ôverify_this()���ɻ�ʧ�ܡ�
���������2 �C ���Ⱦ��������������
���ַ�ʽ���뷨����ֻ���ڹ��������Ѱ����Ⱦ�������������м���������裬������Ҫ�Դ������б�Ҫ�����䣬ȷ���������������������Ⲣ��֤ȷ�����С�Ϊ�˿��ڷ���֮���������Ի�ע�⣺
@Reguires(do_this)
verify_this()
{��} |
�������Ǿ͵õ��ˣ�
myRandomCase_2(){
do_bla();
do_this();
verify_this(); //can be added, because prerequisite step is already in test
} |
����һ�ָ���Ԥ��ķ����������do_this()��verify_that()��Ҫ��ͬһ��Page1��ִ�У���do_bla()�Ѿ�����Page2�ָ�������
��ʱ��������һ�������⣺verify_that()���Ի�ʧ�ܣ���Ϊ���ҵ�ִ������Ŀ���/�����ġ�
�˹����������3 �C �����ĸ�֪
���������������˽�ִ��λ�������ģ�����Web�����еġ�ҳ�桱������Ȼ����ʱҲ����ͨ������/ע��Ϊ�������ṩ��Ծ�����ġ�
@ReguiresContext(pageThis)
verify_this()
{��}
@ReguiresContext(pageThis)
do_this()
{��}
@ReguiresContext(pageThis)
@MovesContextTo(pageThat)
do_bla()
{��} |
������do_this()��verify_this()������ڽ������ĸ�ΪpageThat�ķ�������������ΪpageThat�ķ���֮��
������ǿ��Եõ�һ���������������IJ��Խű���
myRandomCase_3(){
do_this();
do_bla();
do_that();
} |
����Ҳ����ͨ��������ʵ�֡�����ҵ�����صĶ���Ϊҳ�棬�������������������ִ�С����衱ǰ�����������ʾ��ҳ�棬��˿���ȷ����Ҫ������֤���衱��������ȷҳ�档���ַ�����Ҫ����������֤�����Ƿ���ȷ�������������������ע��ʵ�֡�
ɸѡǡ��������
���˽��ܵķ����Ѿ����������൱�����IJ���������
��Ҫ�������ڣ���֤���̱������Լ���֤ʧ�ܵIJ��Գ����Ƿ���Ӧ�ó����ڵ�Bug�������Զ������Խű������µģ���Щ����Ҳ��Ҫ�ķѴ���ʱ�䡣
��˿���ʵ��һ�֡�Ԥ�ԡ��࣬���Ԥ������õĽ���Ƿ����⣬���Ƿ�����κδ�����Ϣ�����ұ�Ҫʱ�ɽ��к���������Ȼ����������ѡ����һ������ͬ�ķ�����
����ͨ��������һ�������Ӧ�ó����ʧ����Bug����ģ�
1.500���������ҳ��
2.JavaScript����
3.��δ֪������Ϊ������ɵ����ƵĴ�����Ϣ
4.Ӧ�ó�����־���й��쳣��/������������Ϣ
5.�������κ�������Ʒ�йصĴ���
�����У�����ÿ������ִ����Ϻ���֤Ӧ�ó���״̬������Զ����ɵĽű��������������ģ�
myRandomCase_3(){
do_this();
validate_standard_rules();
do_bla();
validate_standard_rules();
do_that();
validate_standard_rules();
} |
����validate_standard_rules()�����������������ᵽ�ĸ������⡣
ע�⣺ͨ����OOP��ϣ����ַ������Եø�Ϊǿ���Լ���ʵ�ʵ�Bug����Page Object����ʵ�ֳ�������Ҫ���ҡ��������⡱������JavaScript������־�е�Ӧ�ó������ȡ��������ض�ҳ���йصĺ�����飬�����ƹ����ַ�������������Ծ���ҳ��ļ�顣
ʵ��
Ϊ�˽���ʵ�飬���Ǿ���ʹ�ù������ʼ�ϵͳ�����ǵ�Gmail��Yahoo�����жȣ���Щϵͳ�����д��ڵ�Bug���ѱ����ֵĿ������൱�ߡ��������ѡ����ProtonMail��
Taking Over Random
�����Զ�����������Ѿ���λ�����ǡ����á���Shinyϵͳ���Զ������Ի��ƣ����Ƚ���һ��ͨ�õ�Java/Selenium������Ŀ�����а�������ʹ��Page
Objectģʽʵ�ֵ�ð�̲��ԡ���������ʵ��������ҵ�����Է���һ���µ�Page Object�����ҵ������ʱ��Ȼ��ʾ��������е�ҳ�棩��ǰPage
Object������ҳ�汻���ġ�
Ϊ�����Զ���̽��ʽ���ԣ����������˰�����explr.core���е��࣬���������Ȥ�ĵ���TestCaseGenerator��TesCaseExecutor��
TestCaseGenerator
Ϊ�������µġ��������������������ͨ��TestCaseGenerator���������generateTestCase����֮һ�����������������Բ����ķ�ʽ���ܴ��������ɲ��������С�������֤�ԡ��������������ڶ����������ɶ������һ������Ҫʹ�õġ���֤���ԡ������IJ�������һ������ʹ��Ĭ�ϲ��ԣ�����ΪUSE_PAGE_SANITY_VERIFICATIONS����
��֤���Դ�����������������ӡ���顱����ʱ���õķ�����Ŀǰ����������ѡ�
1.USE_RANDOM_VERIFICATIONS����һ����ͬʱҲ�������ԵIJ��ԡ��ò��Ե��뷨���ڣ�ʹ������ҳ����ĵ�ǰ��֤������������֮�������������������ġ����磺�������ѡ����һ����������֤�ض��������Ϣ�Ƿ���ڡ����ȣ����DZ���֪��Ҫ�����ĸ����⡣Ϊ������������@Defaultע���DefaultTestData�ࡣDefaultTestData�����ij���������ݿ�����������ԡ�@Defaultע������ڽ������ݰ��ض��ķ������������������Ҫȷ���������������Ϣ������֤�������Ѵ��ڣ�����ִ�иù淶�Ĺ����У���֮ǰ���κβ��Թ����д�������Ϊ�˿�ͨ��@Dependsע�����TestCaseGenerator����ض������ĵ��ã������ǰ����֮ǰû�ҵ���ֱ�����ӡ��������ǻ���Ҫȷ����Ϣû������֤֮ǰɾ�������Ƿ��ֶ������ɵIJ���������������������������������̶ȣ��������ַ������ȶ���Ҳ������Ҫ��
2.USE_PAGE_SANITY_VERIFICATIONS���ò��Կɼ���Զ�����Ӧ�ó���ʧ�ܣ�����ʾ�˴����ҳ��������Ϣ��JavaScript����Ӧ�ó�����־�еĴ���ȡ��������Է���������Ը���������Ҫʱʵ����Ծ���ҳ�ļ�飬�����Ѿ��㹻�������ҳ�ʵ�ʵ�Bug��Ŀǰ���ǽ�������Ĭ�ϵ���֤���ԡ�
TestCaseGenerator��ɰ�����������Page����ÿ�������а�����Page���ַ�������ᱻ������ҳ����ҳ��������й��������ᱻ����ҵ�������ư�����Verify���ַ�����ҵ���ᱻ������֤���������������ᱻ�������Բ��衣@IgnoreInRandomTestingע������ڴ��б����ų�ijЩ���߷���������ҳ����
���ɴ������б������ѡ�����ɲ���������һ���б��������Բ��裬һ���б�������֤���裨�����ѡ��֤������Ҫ��֤����Ļ�����ѡ���һ������������䷵��ֵ�Ƿ�Ϊ��һ��ҳ�����������ֵ����һ��ҳ������ô�����䷽����ѡ����һ�����裨�μ����ı�ע����Ϊ����������ҳ֮��ѭ����������һ�ɵĸ��ʻ���ת��һ����ȫ�����ҳ�档�������ʹ��@Dependsע���ע���κ��������ᰴ������Щ���Ⲣ���ӡ�
Ϊ������ִӵ�ǰ����ʾҳ֮������������ò��Է�������������ɵIJ��������ᴫ��һ���������֤���������ȱ�ٵĵ������á�
TesCaseExecutor
����֮�������������Ͼ���һ�֡���-�����ԡ��б�����ͨ���ض���ʽִ�л档���ܿ�������ʱִ�У����ӵ��Ժͺ��������ĽǶ�����������Ϊ�ļ���һ�ָ��õ�������
���ɵIJ���������ͨ�����ַ�ʽִ�У�����TesCaseExecutor��Ϊ��ӿڣ���SaveToFileExecutor��ΪΨһ��ʵ�֣���˿ɼش���һ�����������ɲ���������.java�ļ������˾�����ǣ������൱�Ľ��������ȫ���������ǵ�����ʵ���ٶȿ죬�ɶԲ��Խ��������������������˽��������ɷ�ʽ��Ψһ�IJ������ڣ������ֹ����벢�������ɵIJ�����������������ʵ����˵����Ҳ�㲻��ʲô�����⡣
SaveToFileExecutor���ɵIJ������������ͨ��ģ��ת��Ϊ�ɱ�����ļ����������ɵIJ��Է������£�
@Test(dataProvider = "WebDriverProvider")
public void test(WebDriver driver){
login(driver);
//****<Generated>****
ContactsPage contactspage = new ContactsPage(driver, true);
InboxMailPage inboxmailpage = contactspage.inbox();
inboxmailpage.sanityCheck();
ComposeMailPage composemailpage = inboxmailpage.compose();
composemailpage.sanityCheck();
composemailpage.setTo("me@myself.com");
composemailpage.send();
inboxmailpage.sanityCheck();
List list = inboxmailpage.findBySubject("Seen that?");
inboxmailpage.sanityCheck();
inboxmailpage.inbox();
inboxmailpage.sanityCheck();
DraftsMailPage draftsmailpage = inboxmailpage.drafts();
draftsmailpage.sanityCheck();
inboxmailpage.inbox();
inboxmailpage.sanityCheck();
inboxmailpage.sendNewMessageToMe();
inboxmailpage.setMessagesStarred(true, "autotest", "Seen that?");
inboxmailpage.sanityCheck();
TrashMailPage trashmailpage = inboxmailpage.trash();
trashmailpage.sanityCheck();
//****</Generated>****
} |
SaveToFileExecutor���ɵĴ���λ��<Generated>��ע֮�䣬���������ģ�����ӡ�
����ִ�еIJ��������������������ɵ������������̶�һ�㣬��ֻҪ���Ӱ���������Բ���ĸ���ҳ�������ɽ����
�ڽ��й���ǧ������������Ժ����Ƿ���Protonmailûʲô�����⣨�������ҳ������������㱨��һЩJavaScript����������JavaScript�����ʼ�����빤����ϵͳ����Щ����dz���Ҫ�������ԣ�����ʵ�������Dz����ܷ��ʷ�������־������ʵ��ĽǶ���˵���Ѿ��㹻չʾ�������ķ����Ա�����ϵͳ�����Ĵٽ����������á�
��Ȼ�����������ȡ�����ۻ�ͳ���Լ����������ڻع���Թ����������Ƕ�Ӧ�ó���������Ϊ���š� | 





