|
关键点
1.在分布式的、可扩展的系统(通常包含不稳定的基础设施)中排除故障的效率通常取决于是否有充分的日志记录和搜索设备。
2.唯一事件ID、事务追踪技术和结构化的日志输出等技术,让我们得以透彻地了解应用程序的行为,以及应用程序是否在正常运作。
3.日志记录不再会“拖慢”系统性能,相反地,它在系统故障恢复中有重要的速度增益,尤其是在使用了日志聚合的情况下。
4.我们需要测试核心操作需求,如日志记录。
5.我们可以采用类似功能性需求的方式来测试日志,比如用户故事和BDD场景等。
现代日志聚合和搜索工具为团队的建立、测试和运行软件系统提供了重要的新功能。通过把日志作为一个核心系统组件,并使用如唯一事件ID、事务追踪技术和结构化的日志输出等技术,我们可以获得对应用程序的行为和正常运作的丰富的见解,尤其是跨组件的视图。这篇文章解释了为什么测试日志是有价值的和如何用现代日志聚合工具做日志测试。这种方法使日志成为了一种渠道,使分布式系统更具可测试性。
日志在整体上会为各方面提速
按一直以来的观点,许多人认为,日志会“拖慢”软件。如果使用的是同步文件I
/ O、慢速磁盘存储、甚至更慢的网络速度,从这些方面来看这种观点有一定的道理。因此,我们往往对在现场环境中运行的软件中记录下来的日志,抱着审慎的态度。然而,异步文件I/O和SSD存储正在成为常态,1GB、10GB,甚至100Gb以太网也越来越普遍,日志的性能特性现在已经变得不同。
现在,除了时间关键型的应用程序,如金融交易和其他复杂算法的情况下,在软件系统中我们已经很少单纯地优化软件的运行速度了。特别是在分布式系统、云和物联网(IoT)的背景下,我们需要考虑的是在发生错误后,恢复服务的时间(通常被称为“平均恢复时间”,Mean
Time to Recovery,MTTR)。同时,我们也要考虑在上游(测试)环境里,确定问题原因所需要的时间。
现代日志聚合和搜索工具――比如ElasticSearch、Logstash、Kibana、LogEntries、Loggly、Sematext等等――给我们提供了丰富的方法与我们的软件的进行交互,它提供了丰富的用户接口去判断应用程序的行为,也提供了可编程的REST
API来在多台服务器之间搜索和关联事件。
虽然额外的日志记录可能会导致软件程序的执行速度下降5%-10%。但如果在要搜索的位置具有详细的可用信息就可以帮助我们更迅速地诊断问题,加快我们对故障的响应,并且往往可以显著地减少发现一些隐藏得非常深的错误的时间!
快速的I / O和存储以及现代日志工具的组合――特别是当有工具提供给所有测试人员和开发人员时,就使我们能够把日志作为我们的软件系统的一个重要组成部分;这会让我们产生疑问:如果日志是我们的软件系统的一个重要组成部分,我们该如何测试它呢?
以包裹追踪做类比
我们大多数人都非常熟悉在线包裹追踪工具。这些工具使我们只要有一个追踪ID就能够看到我们的包裹在哪里。这些工具有两个有趣的功能:通过派送网络能够跟踪一个特定的包裹,并且也可以显示出涉及到的这个包裹在不同的时间的各种不同的状态(或事件)。
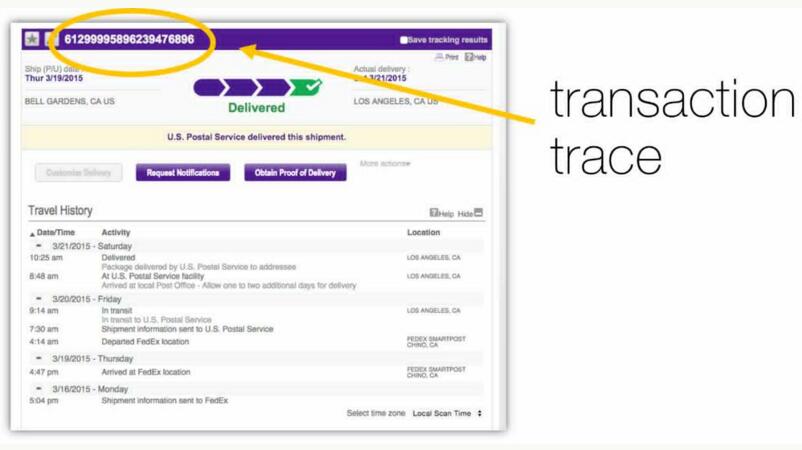
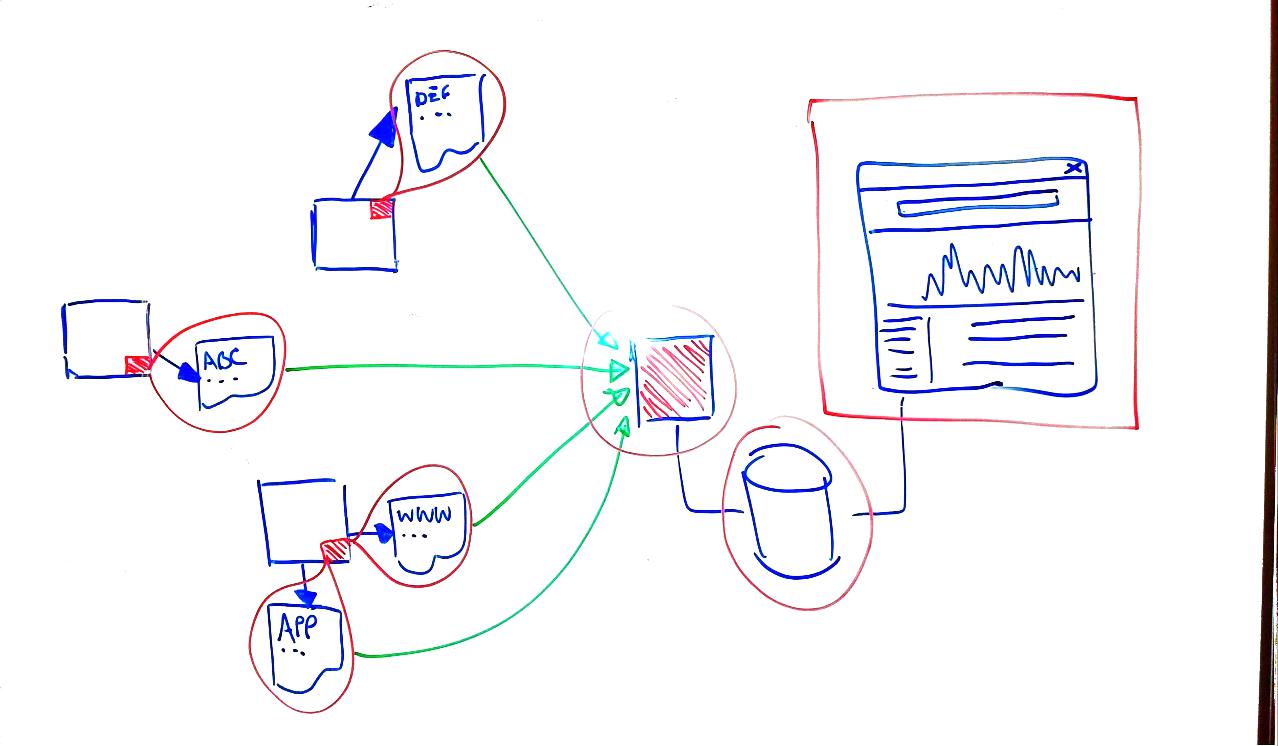
在跟踪一个包裹时,我们可以看到这些状态,比如“到达仓库”、“运输中”和“已送达”等等;这些都代表了特定的状态或事件,并且每一个都有一个系统内的内部标识符(ID)――事件ID。
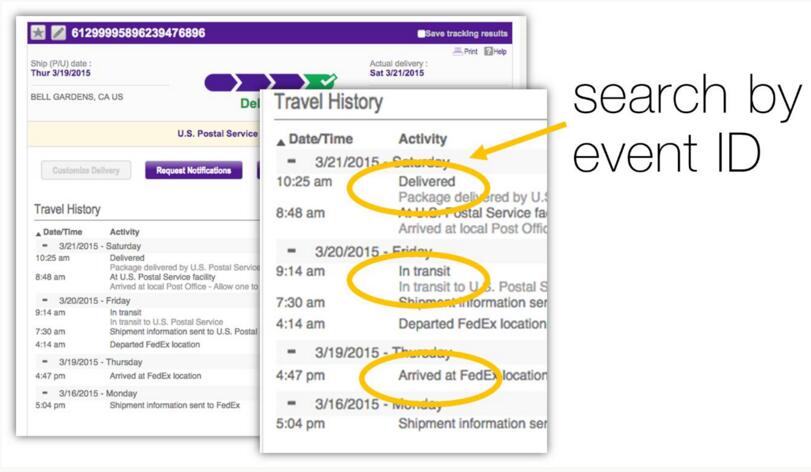
在现代的异步分布式软件系统中,我们可以使用一种类似的技术来跟踪跨不同模块的运作执行情况。为了帮助我们做到这一点,我们定义了一些我们自己的事件ID,并把这些事件ID与我们正在使用的系统相关联起来。
预期事件和相关性ID的测试
我们不应该把时间花在测试日志子系统本身之上,比如log4net、log4j,等等;我们应该假设日志的功能(写入磁盘、切转日志文件、刷新缓冲,等等)都已经就绪了。相反,我们应该集中精力确保三个独立但相关的东西:
1.我们希望发生的事件要在日志流中正确地出现
2.事务标识符(也就是关联ID)如预期一样通过日志流
3.事件按适当的级别被记录(Info、Error、Debug等)――如果我们正在使用可配置的日志级别
当然,通过检查这些东西,我们已经试用了日志子系统和并且隐含地对它也进行了测试。通过把日志作为一个可测试的系统组件,我们也往往会减少问题的“检测时间”,增加团队参与,加强合作,提高软件可操作性。
我们需要定义一组事件类型ID,这些事件类型ID对应于我们的软件中有用的和关键的操作或执行点。到底要定义多少这样的ID取决于你的软件,但至少我们有ApplicationStarted和DatabaseConnectionFailed或DocumentStoreUnavailable类似的东西(当要用到这些东西时再去定义相应的额外的ID,不要试图事先定义所有可能的事件)。
例如,如果我们正在用C#构建电子商务应用程序,我们可能会:
public enum EventID
{
// Badly-initialised logging data
NotSet = 0,
// An unrecognised event has occurred
UnexpectedError = 10000,
ApplicationStarted = 20000,
ApplicationShutdownNoticeReceived = 20001,
PageGenerationStarted = 30000,
PageGenerationCompleted = 30001,
MessageQueued = 40000,
MessagePeeked = 40001,
BasketItemAdded = 60001,
BasketItemRemoved = 60002,
CreditCardDetailsSubmitted = 70001,
// ...
}
|
我们使用人类可读的名称再加上一个唯一整数值一起作为事件ID,这样就可以将相关或相类似事件组合在一起:在这里,所有有关“篮子”的事件类型会使用60000到69999之间的整数ID。当我们的软件在代码中处理到相应的状态时,它会将相关的事件类型的ID与其他日志数据一起写入日志文件中。这反过来又被日志聚合系统收集起来,可以提供给搜索(通过浏览器和一个API)使用。
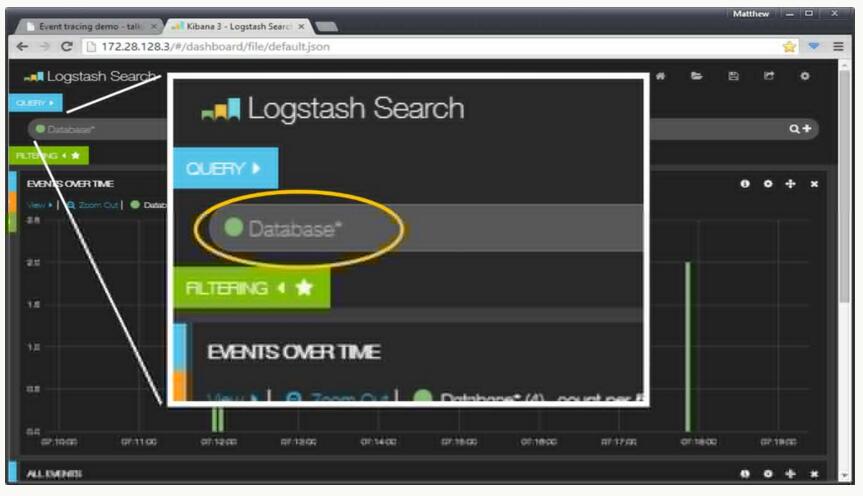
如果我们想把一个关于发生在日志流中预期或意外事件的测试用例自动化,我们可以通过curl做一个简单的API调用来进行查询。
例如,我们可能想检查发生了一次数据库查询(预期发生事件DatabasePreQuery
和DatabasePostQuery)并且没有出现连接问题(突发事件DatabaseConnectionFailed)。
这里是为DatabasePreQuery事件(你也可以在GitHub找到它)查询Elasticsearch
API (在本地运行)的curl命令:
$ curl -XGET 'http://localhost:9200/_search?q=message:DatabasePreQuery&pretty'
|
这个查询的结果可能是,例如(为了清晰度重新格式化过,并添加了行数以供参考):
{
2 "took" : 19,
3 "timed_out" : false,
4 "_shards" : {
5 "total" : 20,
6 "successful" : 20,
7 "failed" : 0
8 },
9 "hits" : {
10 "total" : 1,
11 "max_score" : 11.516103,
12 "hits" : [ {
13 "_index" : "logstash-2016.05.06",
14 "_type" : "logs",
15 "_id" : "gHEKyHasRb6GaUhM1gywpg",
16 "_score" : 11.516103,
17 "_source":{"message":
18 "[2016-05-06 17:07:42] slim-skeleton.INFO: DatabasePreQuery [] []",
19 "@version":"1",
20 "@timestamp":"2016-05-06T16:07:42.749Z",
21 "host":"vagrant-ubuntu-trusty-64",
22 "path":"/var/www/wibble/logs/app.log"}
23 } ]
24 }
24
25 }
|
以上的第10行表明,查询精确地匹配上了一条日志(总命中量为1),并在第13行开始是查询响应,实际的日志消息在第18行开始的。
那么,我们可以使用我们的选择工具,将这些搜索结果输入到我们的数据库中查询测试,以解析JSON的响应并且确定事件是否发生了。
例如,测试用例的基本Ruby实现(你也可以在GitHub上找到它):
require 'json'
2
3 file = open("Database_prequery_search.json")
4 prequery = JSON.parse(file.read)
5
6 file = open("Database_postquery_search.json")
7 postquery = JSON.parse(file.read)
8
9 file = open("Database_connectionfailed_search.json")
10 connectionfailed = JSON.parse(file.read)
11
12 expected_prequery_event = (prequery["hits"]["total"] == 1)
13 expected_postquery_event = (postquery["hits"]["total"] == 1)
14 unexpected_connectionfailed_event = (connectionfailed["hits"]["total"] == 0)
15
16 expected_prequery_event && expected_postquery_event && unexpected_connectionfailed_event
|
我们使用'json' Ruby gem包去解析查询前后的curl搜索结果,这些结果是我们先前保存在重命名后的文件中的(前10行)。第12行到第14行说明了我们对测试结果的预期(即日志流中应该包含一个单一的DatabasePreQuery事件,一个单一的DatabasePostQuery事件,并且没有DatabaseConnectionFailed或其他事件)。最后一行是实际的测试(如果我们的期望都是正确的Ruby将返回“ture”,否则就会返回false)。
更复杂的测试(或对事件的分析)可能,比如说,需要在给定时间内搜索所有数据库事件、计算查询次数、故障等。然而,使用的方法和上面描述的是一样的,只是在一个较大的JSON响应包中要执行稍微复杂的迭代代码。
这是一个对这类测试进行curl查询的例子(你也可以在GitHub找到它):
$ curl -XGET 'http://localhost:9200/_search?q=message:Database*&pretty' -d '
{
"query" : {
"range" : {
"@timestamp" : {
"gte" : "now-10m/m"
}
}
}
}'
|
我们也可以在系统中跟踪一条单一的执行路径,使用当活动最初被启动时我们注入系统的相关的ID:比如,用户点击一个按钮或一个批量作业开始。只要关联ID对于我们在日志聚合工具中的搜索是能够保证唯一的,我们将看到只与该查询有关的结果。
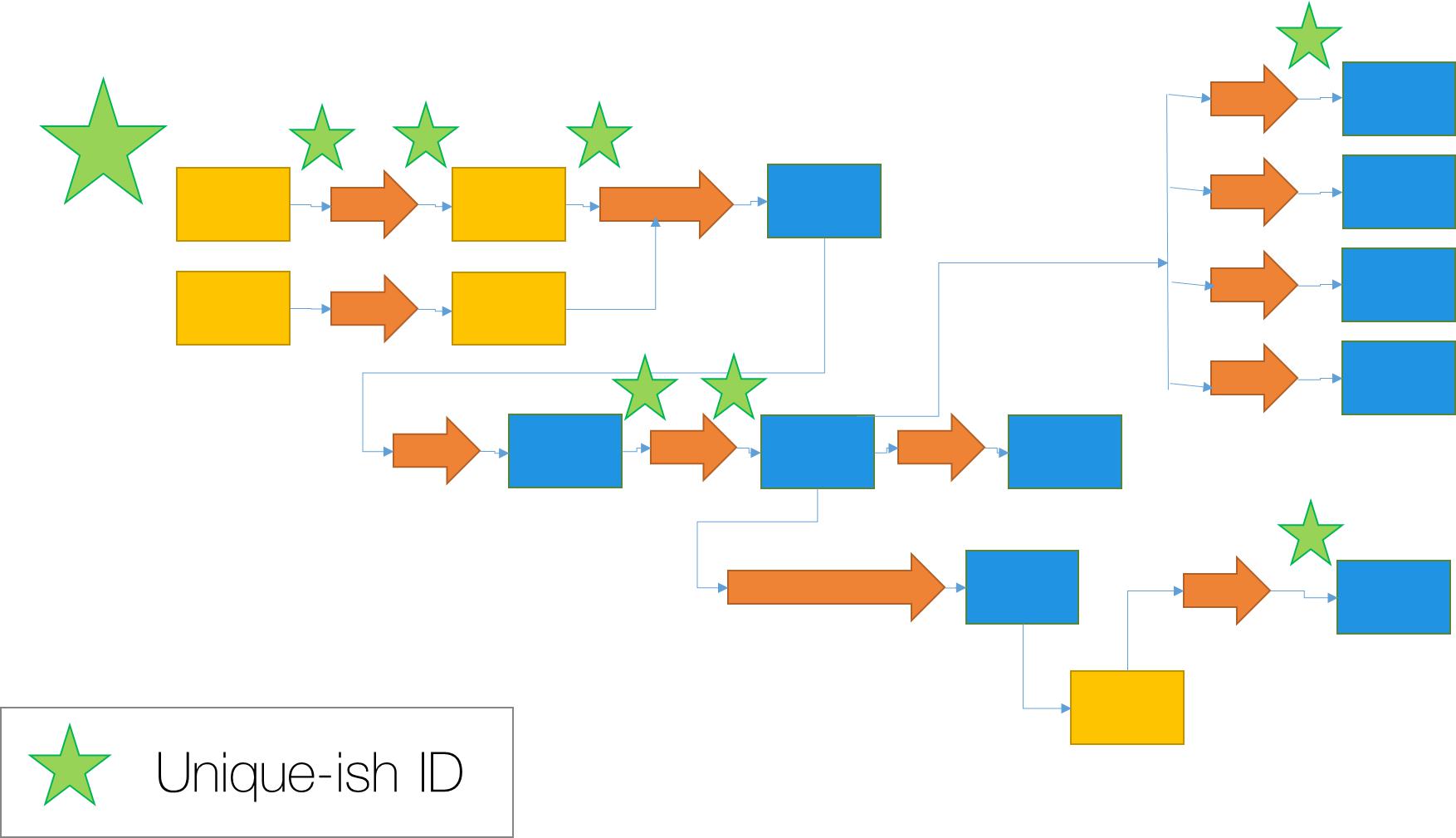
通过搜索关联ID,我们就可以精确地确定到底是哪些服务器或容器参与了请求的处理和重建请求的过程。有一些商业工具能提供这样的功能,但通过我们自己建立这些功能中的一部分功能,我们也可以获得对系统运行情况的有益见解。
测试日志的用户故事
比如说,我们有一个关于法律市场的基于浏览器的系统,这个系统允许专业的法律从业者来编辑和保存文档。将文档数据保存到文档存储数据库,并将消息放在消息队列上。然而,作为一个国家的监管制度的一部分,我们需要确保该文件符合一定的要求,所以需要提供“审计”服务监听消息队列上的消息,然后检查最近更新过的文档:
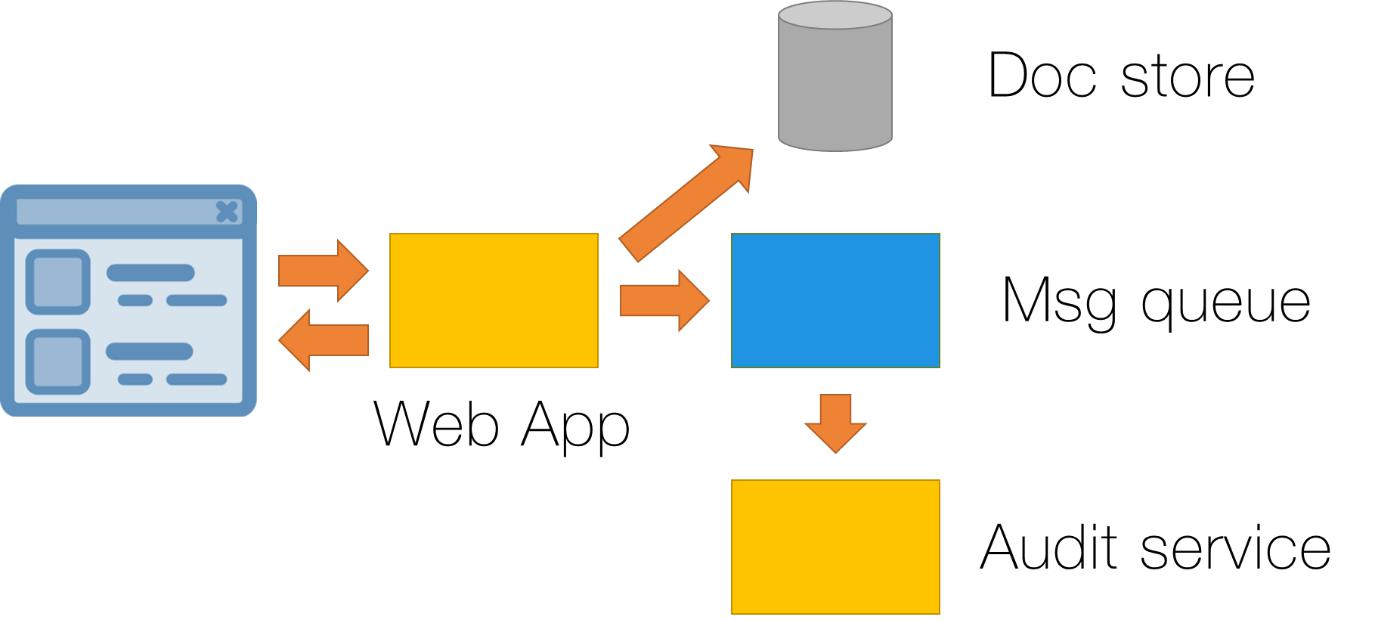
在这里,我们已经有了一个异步的、分布式的系统。当在浏览器中应用程序明确地显示了成功――该文档已经成功更新时,可能实际上还需要启动进一步的工作流程(例如,如果文档审计发现了文件的问题)。
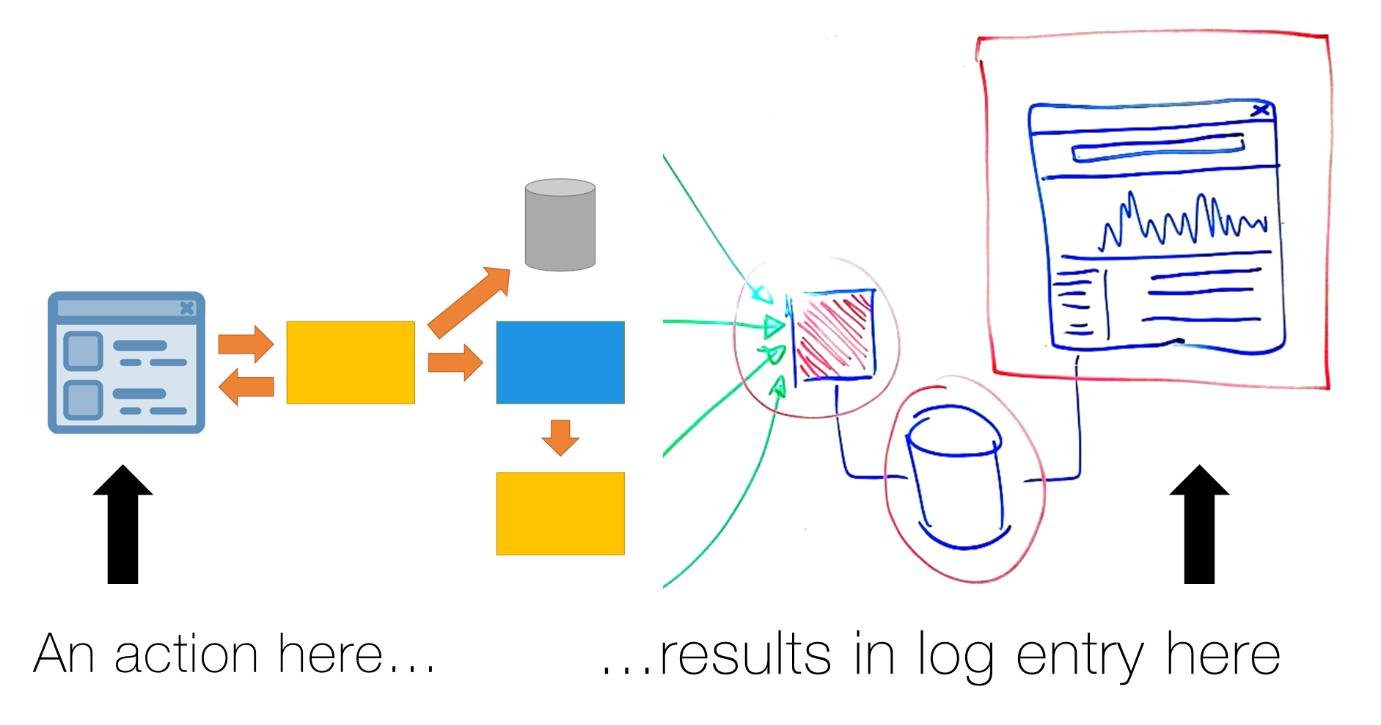
通过使用事件ID和事务跟踪的日志聚合功能,我们就有能力断言,基于在主要事务系统中的某些操作,某些特定的日志消息应该出现在日志聚合系统之中:
具体来说,如果我们知道,审计服务应以事件ID“AuditRecordCreated”写一条日志信息,我们在Web应用程序的用户搜索完成后,就可以运行一个测试来寻找那个ID:
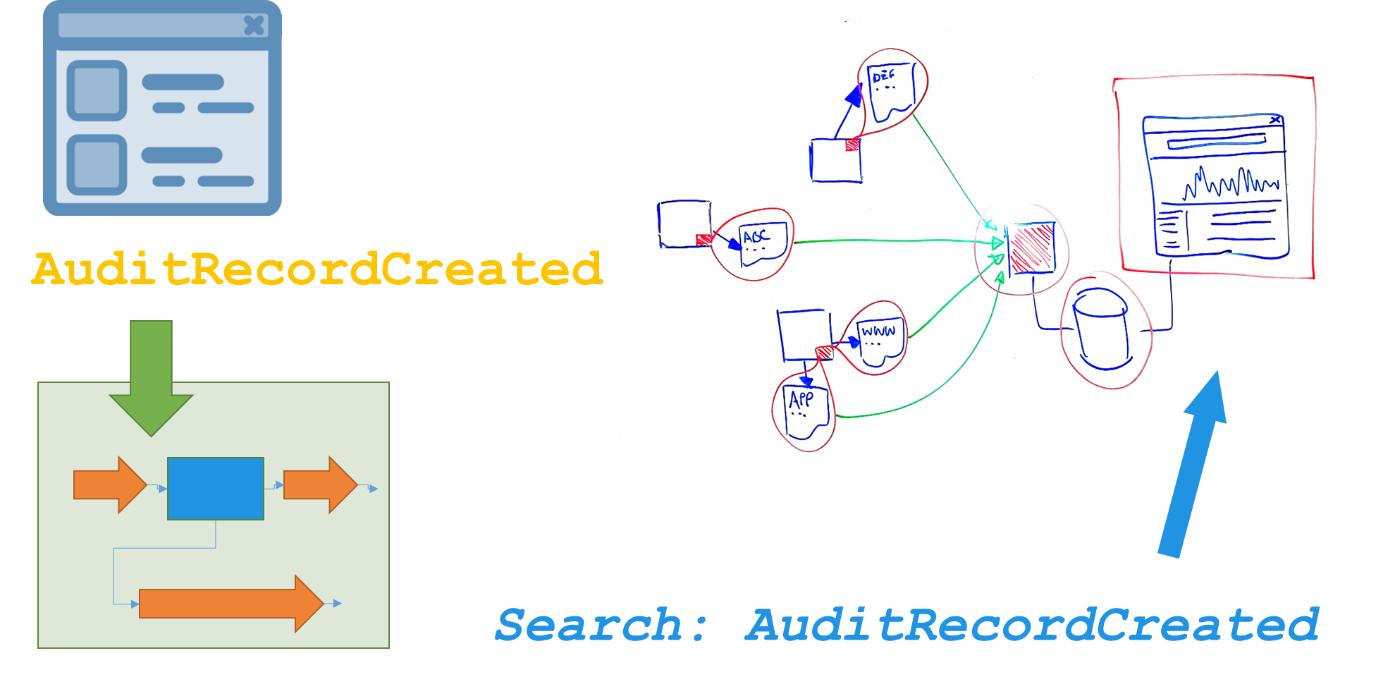
有了这个能力去断言我们对系统的行为的期望之后,我们可以写出类似这样的行为水平测试:
Given I run a scenario as a Lawyer
And I create a document
[And I wait 5 seconds]
When I search the logs API
Then I should find a recent entry for “AuditRecordCreated” |
这意味着,日志记录已经成为了一种可以扩展我们对分布式系统的测试的方式,只要能够明确在某些具体时刻我们期望哪些行为或事件会被记录下来,然后再去搜索就好了。
结论
对分布式的、可扩展的系统(通常包含不稳定的基础设施)进行故障排除,取决于是否有足够的日志记录和搜索设备。我们需要记录发生在我们的系统中的重要的事件,并通过一个唯一的关联ID将它们关联到一个特定的业务交易(如包裹快递)上。日志聚合和搜索工具使我们能够用一个简单的ID查询来跟踪终端到终端的业务交易。我们也可以查询一个类别的事件以调查组件或系统故障(例如,为了找到导致某次故障的所有的数据库事件)。最后,我们看到,我们可以而且我们也应该以与功能需求类似的方式来测试这些操作需求,即通过用户故事和BDD的场景。
| 





