|
行为驱动开发(BDD Behavior Driven Development)指开发者站在客户的角度来观察系统,思考系统应该具有什么样的行为才能满足客户需求的这样一种开发过程。BDD
基于一种“通用语言”定义了同时能被客户和开发者理解的系统行为,在最大程度上避免表达不一致带来的问题。基于这一思想,本文以
Linux 平台为基础,图文并茂的解析了其应用于 Python 的开发测试过程,并给出了 Python
语言 Lettuce 测试框架搭建的详细步骤。既有助于用户形象理解 BDD 理论,又对 Python 学习者有很好的借鉴意义。
行为驱动开发 (BDD) 简介
行为驱动开发是什么?
说到行为驱动开发(BDD),无可避免的要提到敏捷里面的测试驱动开发(TDD),TDD 的主要思想是“代码即文档”,其倡导的流程是根据设计编写测试->
实现设计的功能 -> 用测试代码验证 -> 重构实现代码 -> 改善设计 ->
再次回到根据改善的设计编写测试。
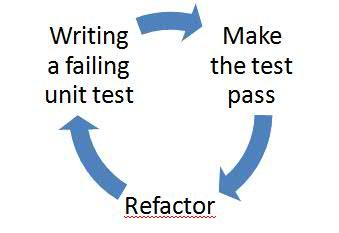
图 1 基于 TDD 的项目开发流程
BDD,即行为驱动编程,是 TDD 的一个改进版本,BDD 本质上也是 TDD,但是比 TDD 要更加自然一些,更
DSL 化。系统业务专家以及测试开发人员一起合作,分析出软件的需求,然后像故事一样描述出一个个具体可执行的
Behavior;之后开发者负责填充这些故事的内容,测试人员负责检验故事结果的正确性。一个比较简单的案例即用户登录场景测试:

图 2 用户登录场景测试
作为普通用户,我在登录网站时,就牵扯到用户名和密码的校验。同样的故事就因此会有不同的场景发生:
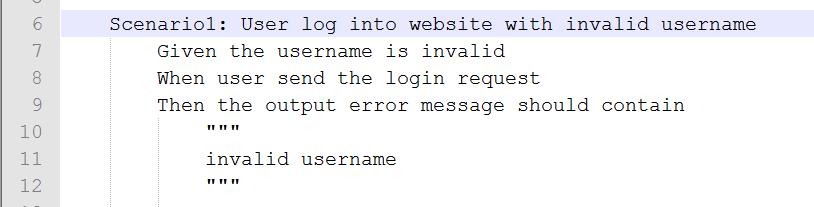
图 3 非法用户登录场景
如果是一个合法用户来发出请求,那么又将是另外一个场景:

图 4 合法用户登录场景
有了这些场景描述,测试人员可以通过一些 BDD 测试框架将上面的故事转成测试代码, 开发者实现产品功能,保证所有的测试案例成功通过。
为什么要进行行为驱动开发?
如上可以看出,行为驱动开发的根基是一种“通用语言”,类似于用一个最小化的词汇表来定义,其中这些词汇具有准确无误的表达能力和一致的含义。
as 指明系统行为是为什么角色而定义的。
In order to 和 I want 定义了行为的范围,表明了想达到的目的,想做的事情。
Given 给出了准备要测试的对象和测试环境。
When 调用要测试的业务方法。
Then 对测试结果进行验证
这种通用语言同时被需求,开发,测试和客户等项目相关人员用来定义系统的行为。这样子大家看到的描述一致,内容一致,最大程度的交付出符合用户期望的产品,避免表达不一致带来的问题。
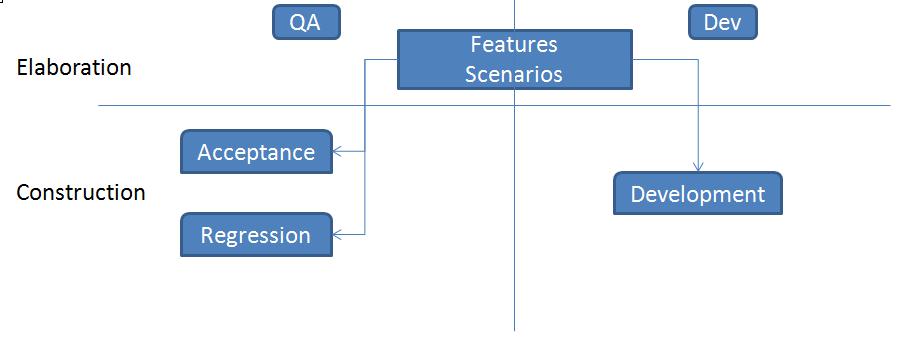
图 5 使用行为驱动开发的开发状态图
古人云“工欲善其事,必先利其器”,因此在详细介绍基于 BDD 思想的 Python 开发测试过程之前,我们先来看一下如何搭建一个有效易用且稳定的测试框架。
Python BDD 测试框架的搭建
Lettuce 简介
为什么在这里要提到 Lettuce 呢?看它的官网介绍,这个框架在 Python 语言的测试应用堪比 Ruby
语言领域的 Cucumber,它可以对 Python 项目进行自动化测试,值得注意的是这里的测试用例是纯文本的,具有很好的可读性。这样的话,即使是不懂编程的人也可以站在系统或用户的角度来写测试用例,并且在项目开发过程中,这个自动化测试用例可以很容易的修改、扩充,开发人员也能很快的调整,从而保证测试用例顺利通过。
搭建 Lettuce 测试框架
前面已经说了很多 Lettuce 的作用和好处,那么下面我们来看下如何在自己的环境上搭建这样一个测试框架。接下来笔者将给出
Redhat Linux + Python2.6 这样的环境下的搭建步骤。
首先,Python 上安装 package 的时候,一般都会建立一个 Virtualenv。
如何来理解 Virtualenv 呢?Virtualenv是一个 Python 环境管理工具,它可以创建独立的
Python 环境,多个 Python 相互独立,互不影响。简单的来说,你可以将它看做是一个个隔离的沙盒,每一个沙盒之间相对独立,保持着一个相对独立干净的环境。可能这样说,你还没有理解到它的实际好处,试想一下,你之前有一个项目
A 需要依赖 Django1.2.5, 而现在又有一个新的项目 B,它需要依赖 Django1.3,这时除了把它们放到不同的沙盒里面,你还可以重新搭一套
Python 环境,甚至于需要换台机器,这样沙盒的好处就显而易见的了,应该没有人会不喜欢这么简单的方法。好的,既然喜欢,那么如何来安装并激活呢?
1.install virtualenv
easy_install virtualenv-1.6.4.tar.gz
2.create virtual environment (vevn)
virtualev [vevn_folder] --no-site-packages
3.enter into [venv_folder]
source bin/active
仅需要以上 3 个命令就可以安装并激活 Virtualenv 了,值得注意的是,这个 Virtualenv
看上去就是个文件夹 [vevn_folder],可以很容易地删除、重建等等,但在每次使用前都需要将它激活。
另外我们这里使用了 easy_install 命令,这是 setuptools 带的一个命令,其中 setuptools
是一个非常好的应用于 Python 的安装工具,使用它,可以使用如上很简单的命令来安装所需要的 package。如下就是安装
setuptools 和 Virtualenv 的步骤图:
图 6 安装 setuptools
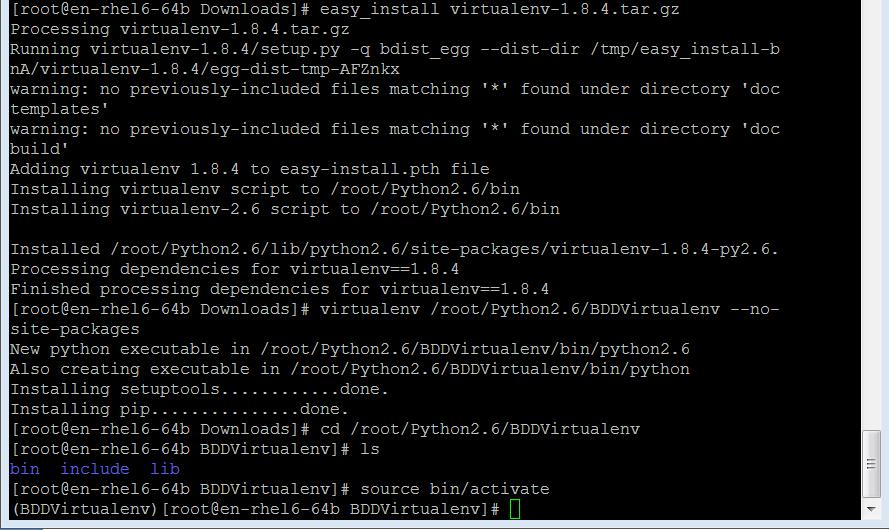
图 7 安装并激活 Virtualenv
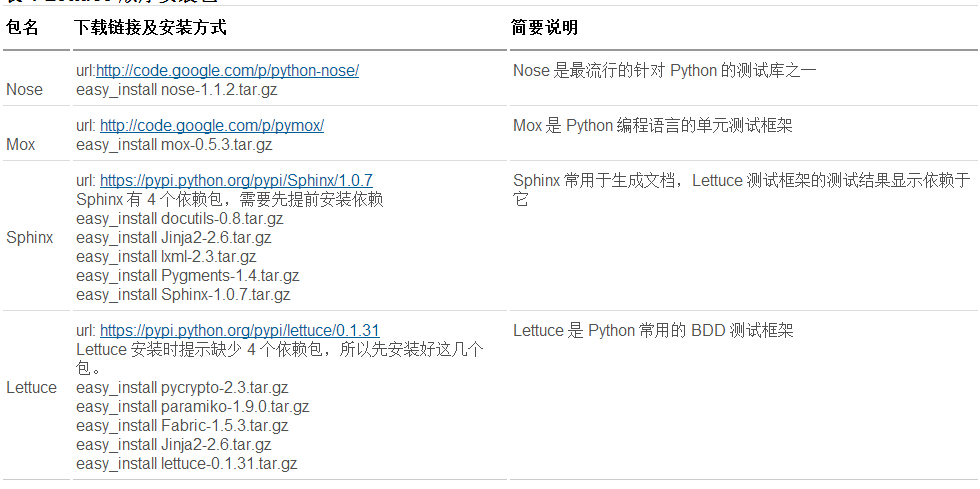
其次,我们需要清楚的是,Lettuce 安装包有很多依赖,因此在安装之前我们得将所有的依赖包装好。
我们可以从网站上下载这些需要的包到本地,当然也可以直接用 setuptools 来安装,如果本地没有安装包,它会自动下载
package 的最新版本来安装。不管怎么样,需要注意的是,由于这些包之间存在依赖关系,因此需要按照特定顺序来进行安装。以下就是所有依赖包的顺序安装:
表 1 Lettuce 顺序安装包
安装完之后可以做如下的简单测试来确定是否安装成功。
在命令行里直接输入 Lettuce, 如图所示,如果显示类似找不到 features 的提示信息,那么恭喜你已经成功安装上了
Lettuce 测试框架。

图 8 Lettuce 安装验证
到这里,算是打好了基础,回头再看看,安装时需要注意的有以下 2 个方面:
1. 如果建立的有 Virtualenv,那么在做任何操作之前必须要先激活它;
2. 对于 Python 来说,特别是要注意包之间的依赖,如果不清楚,可以先查查,实在不行,用 easy_install
这个工具来安装,它会自动检查依赖关系,如果缺失则会自动从网上下载最新的匹配版本并进行安装,但遇到依赖关系复杂而网络状况又不好的时候,最好手动下载放到本地目录,就像本文中用到的包一样。
基于 BDD 思想的 Python 开发测试过程
接下来这一章,我们希望通过生动详细的案例来讲述测试用例及测试脚本的编写和运行过程。比如说我们想自己实现一个计算整数
n 次方的计算器,当然这个程序可能比较简单,但这里为了更好的理解 BDD 的思想,我们假设它很复杂,刚开始不知道怎么实现,我们就只好先写测试用例,然后一步步的修改代码让所有可能的用例通过。接下来本文将以
4 个迭代详细描述该过程。
测试用例及测试脚本的编写
在写测试用例时,就参照前面章节所介绍的,用一些简单无异议的最小词汇组来描述可能的用户场景。
迭代 1
先给出一个 n 次方计算器程序的接口 computePow.py,如下所示,我们不知道如何实现它,所以让计算结果都为-1。

图 9 计算程序接口定义
接下来先来一条最简单的测试用例 computePow.feature,如下图所示,这个测试用例在上面首先说明了这是一个计算
n 次方的 feature,另外还简单说明了作者,目的等,最重要的是用 3 个步骤很清楚的描述了一个用户场景,即
1 的 0 次方为 1

图 10 测试用例描述
不用再多说,想必大家已经感受到这样的测试用例的好处,简单明了,易读性高,信息量大,便于维护。当然到此为止,这个看上去很清晰明了的测试用例只是对用户来说是这样的,计算机是如何理解的呢?这就需要我们对这些
step 做转换,从而使程序正确理解用户行为。如下所示我们定义了一个解释脚本 step.py:
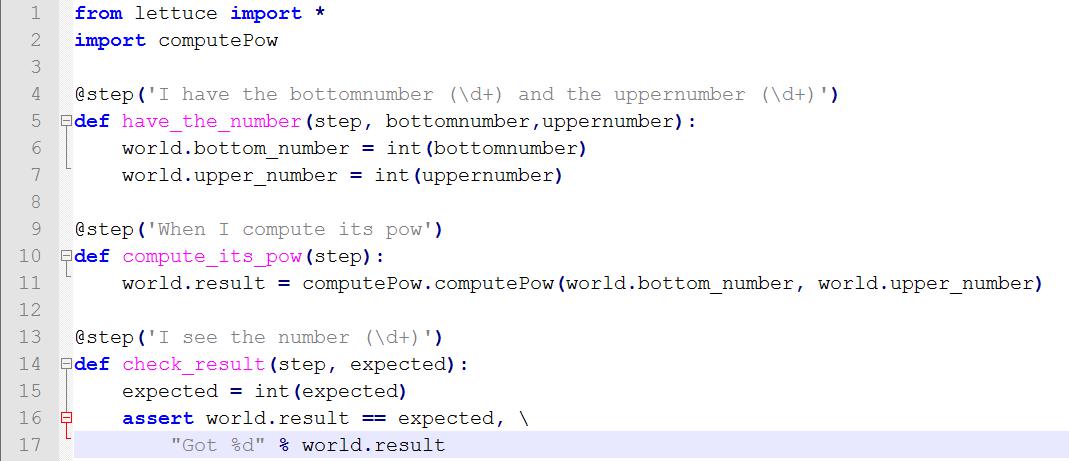
图 11 解释脚本
这个 step.py 需要和前面的测试用例 computePow.feature 结合来看,首先 step.py
里面定义了 3 个方法,每个方法是和 factorial.feature 文件里面的用户场景的每一个步骤对应,而这个对应规则就是靠方法上面的
@step(...) 所标识的正则表达式来匹配的,其中有正则表达式的地方,如 (\d+),表示是参数带入,比如在方法
have_the_number 中,上面的匹配规则有两个 (\d+),表示这里有两个数字参数,因此该方法也带了两个形式参数
bottomnumber 和 uppernumber。运行时,这两个参数值将从测试用例对应的 step
中获取,即 Given I have the bottomnumber 1 and the uppernumber
0,也就是说实际参数将是 1 和 0。另外需要注意的是我们强烈支持代码的可读性,因此这里 step.py
中的方法名都很容易理解。
好了,至此一条简单的测试用例已经完成,我们来让它运行一下,进入到文件所在目录,使用命令:lettuce
computePow.feature,运行结果如下图所示。

图 12 运行测试用例
运行结果显示,总共运行了一个 feature 和一个 scenario,都运行失败,scenario 中共有
3 个 step, 其中 2 个成功运行,还有一个失败,从图中可以看到失败的地方以及具体堆栈信息。
从这里就可以体会 BDD 的好处,对于测试人员来说能很清楚的明白问题出在哪一步,可以找谁去沟通;而这些错误信息也能很好的帮助开发人员解决问题;另外下面的统计数字也能很清楚地看到测试通过百分比。
既然测试用例跑失败了,接下来我们就修改代码让用例成功跑通。通过数学计算,我们知道
1 的 0 次方是 1,因此我们修改计算程序 computePow.py,让它返回 1,修改完之后运行一下,发现这时测试用例已经完全跑过。如下所示:

图 13 修改后计算程序接口
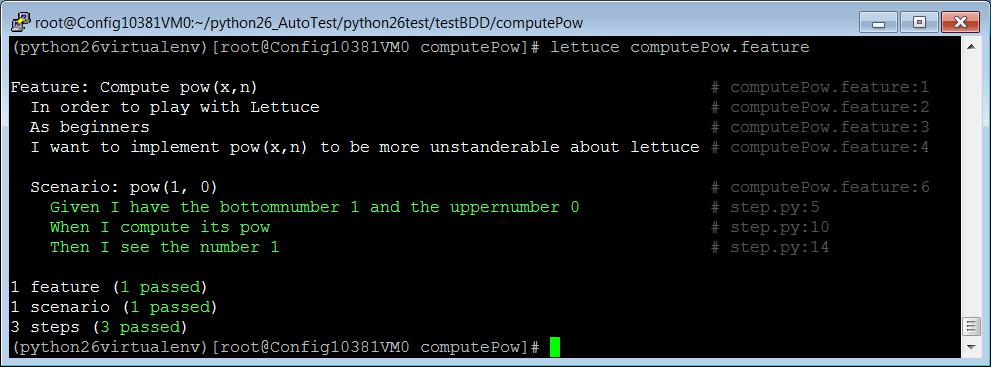
图 14 再次运行测试用例
迭代 2
接下来,我们就可以考虑扩展测试用例,为让测试更完备,在这里我们增加了 3 个计算,分别是 3 的 0 次方为
1,2 的 1 次方为 2 和 5 的 0 次方为 5,新增用例如下所示:

图 15 测试用例功能扩展
运行该用例之后,发现在 Scenario: pow(2, 1) 和 Scenario: pow(5, 1)
出错,如下所示,该次运行有 2 个 scenario 成功运行,2 个失败,从运行结果可以很容易地知道是哪一个步骤出错。
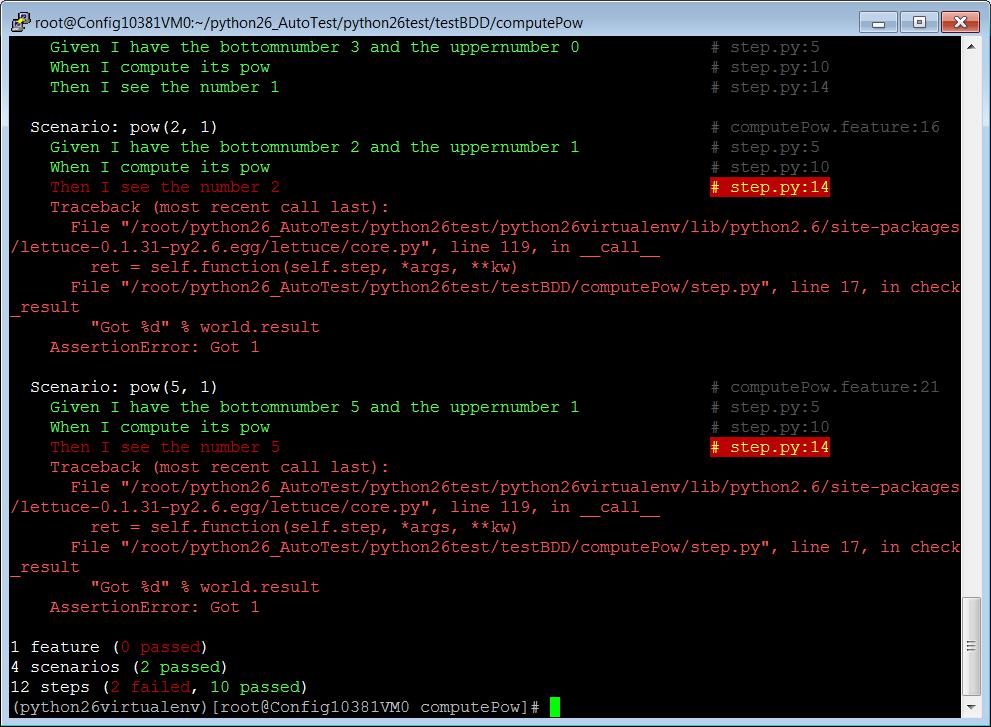
图 16 测试用例功能扩展后运行结果
因此我们修改计算程序 step.py,如下所示:

图 17 第 3 次修改计算程序接口
再次运行命令 lettuce computePow.feature, 发现我们的这 4 个 Scenario
和 12 个 step 都能成功跑过。
迭代 3
到这里我们才测试了 4 个简单用例,接下来我们再增加 2 个稍微复杂些的用例,计算 2 的 3 次方为
8,3 的 2 次方为 9,新增用例如下所示:

图 18 测试用例第 2 次功能扩展
运行该用例之后,发现在新增的 2 个用例处 Scenario: pow(2, 3),Scenario:
pow(3, 2) 出错,因此我们修改计算程序 computePow.py 以让用例通过,如下所示:

图 19 第 4 次修改计算程序接口
再次运行命令 lettuce computePow.feature, 发现我们的这 6 个 Scenario
和 18 个 step 都能顺利跑过。
迭代 4
至此我们的计算器小程序已经顺利跑过 6 个用户场景,如果再新增用例的话,就可仿照上述 3 个迭代过程来添加,但是这有一个问题,随着用户场景增多,我们发现
computePow.feature 变的越来越长,难以管理,仔细观察一下,发现每个场景的 step 很相似,也就说我们写了很多重复的描述信息,针对这一问题,Lettuce
测试框架可以用 scenarios outlines 来解决,如下图所示:

图 20 使用 scenarios outlines
描述测试用例
这样的写法可以使测试用例在依然能表达丰富的信息的情况下变的很精简,且更容易管理和扩展。
测试脚本运行及自动化
测试脚本如何运行在前一章的实例中已经提到,只需要简单命令 lettuce computePow.feature
就可以。这样它就会在当前路径下搜寻与每一个 step 匹配的脚本来解释执行。注意的是,这里的测试用例和测试脚本的名字没有关联性。如果当前路径下有多个测试用例文件,也就是说有很多*.feature
文件,就可以用 lettuce ./ 或者 lettuce *.feature 来批量执行。
到此想必大家已经对 BDD 在 Python 领域的开发测试过程以及测试框架搭建已经有一个形象的理解,在前面的实例中也体会到了这种方法的好处。最后要提到的自动化实质上是这种方法的另外一个好处,假设我们的计算器程序将分布于不同的
OS 上,需要对这些环境都进行测试,又或者说我们的计算器程序需要升级用 Python 的更高版本等等,这样我们就要将测试环境和开发环境分离,在我们的案例中,可以看到测试用例和计算器程序是彼此独立的,这样我们只用做很少的工作,譬如写一些简单的脚本,然后在测试环境上通过
set 或 export 设置远程开发环境的运行变量就能很轻易的让它自动化运行。
总结
本文首先对行为驱动开发做了一个简介,接下来通过实例图文并茂地讲述了如何将这一思想灵活运用到 Python
领域,同时中间还穿插了测试框架 Lettuce 的安装及运行。在此,希望本文能起到一个抛砖引玉的作用,增进读者对
Python 和 BDD 的了解,有兴趣的读者可以进行深入研究,将其灵活应用到项目实践中。
| 





