|
一、性能测试支付宝场景介绍
2013年双11过程当中,促销开启的第一分钟内支付宝的交易总额就突破了一亿元,短时间内大量用户涌入的情况下,如何保证用户的支付顺畅,是对支付宝应用系统的一个极大的挑战。
支付宝的性能测试场景分为性能基线测试,项目性能测试。
任意一笔交易过来,我们都需要对交易进行风险扫描,对于有可能是账户盗用的交易,我们会把这笔支付直接拒绝掉,或者通过手机校验码等方式进行风险释放。
我们有一个老的扫描平台A,现在需要构建一个新的扫描平台B,对A中关键技术进行升级,并增加额外的功能。扫描的策略是存储在DB中的,需要通过发布来更新到应用服务器的内存中。
二、性能测试需求分析和方案制定
a. 需求挖掘
1),查看业务方的显性需求。业务方给到的需求为平台B的分析性能要优于平台A的性能。除此之外无其它的需求。
2),挖掘隐性需求.了解业务架构,了解业务流程。为了保证扫描的性能,大量的存储类的需求被设计为异步处理,但是结果类的扫描需要使用到前面落地的数据,那么在系统正常运行时是否会存在落地数据读取不到的问题,在存储抖动时是否会导致后续的分析扫描全部失效?
首先我们通过运维监控平台拿到平台A的分析性能,RT<130ms, TPS>35.
基于以上的需求挖掘,我们确认的性能测试场景为
扫描性能场景。(单场景)
发布性能场景。(单场景)
扫描过程中发布性能场景。(混合场景)
b. 技术方案
1).评估我们的系统架构,系统调到链路,定位可能存在问题的瓶颈点。
2).掌握详细技术实现方案,了解具体技术方案可能存在的性能问题。
比如我们是否使用到了脚本动态编译,是Java脚本还是groovy脚本。是否使用到了线程池等异步处理,系统幂等性是如何控制的,数据结构是如何存储与读取的,是决策树还是图型结构。
3).了解系统环境的差异,比如服务器位数、CPU、内存的差异,JDK版本及位数的差异。
基于以上的技术方案,我们确认了上述3个性能测试场景可能存在的性能问题
1. 扫描性能场景
技术方案为扫描引擎drools2升级到了drools5.
性能关注点为请求扫描RT,TPS是否满足我们的需求;JVM Old区内存溢出,Old区内存泄露;GC
频率过高。CPU使用率,load.
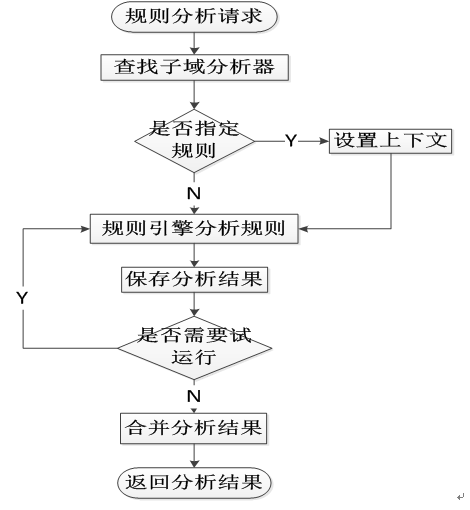
2. 发布性能场景
技术方案为规则DB捞取->规则加载->规则引擎切换->规则脚本编译。
性能关注点为CPU使用率,load。JVM Perm区内存溢出,Perm区内存泄露,GC 频率过高。GC
暂停应用时间。
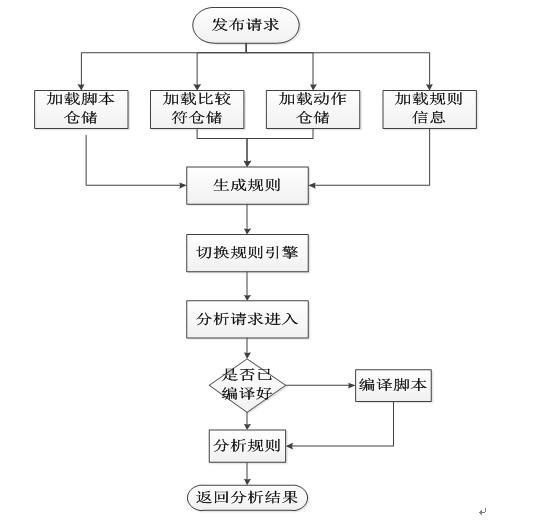
3. 扫描过程中发布性能场景。
性能关注点为请求扫描RT,TPS。规则发布耗时,CPU使用率,load, JVM GC频率。
c. 性能测试方案制订
分布式压测,参数自动化,使用单元测试脚本,接口测试脚本,jmeter脚本等进行压测。
性能结果收集及统计。
性能测试通过标准。
基于以上的分析
1. 扫描性能场景
性能测试方案:
使用jmeter 脚本进行分布式压测,一台master, 三台slaver. 参数自动构建,使用高斯定时器模拟真实场景。
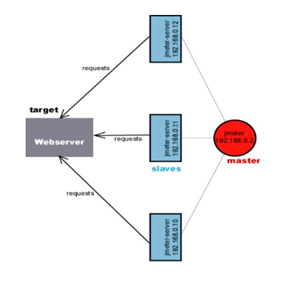
使用jmeter 收集分析性能数据,使用nmon收集服务器性能数据,使用jconsole收集JVM数据。
通过标准:
RT<130ms, TPS>35.
JVM old 区内无内存泄露,无内存溢出。GC时间间隔>30min,暂停应用时间<150ms.
CPU<70%, load < core*1.5。
2. 发布性能场景
性能测试方案:
发布时间间隔时间限制从1min调整为3s, 更快的暴露问题。
使用单元测试类推送发布消息。
服务器shell 脚本收集发布模块性能数据。
使用nmon收集服务器性能数据。
使用jconsole收集JVM数据。
通过标准:
JVM Perm 区内无内存泄露,无内存溢出。GC时间间隔>10min,暂停应用时间<200ms.
发布时间<30S
CPU<70%, load < core*1.5。
3.扫描过程中发布性能场景
性能测试方案:
使用jmeter脚本进行分布式压测,同时提交发布请求进行发布。
同时使用扫描性能场景和发布性能场景收集数据功能。
通过标准:
RT < 扫描性能场景结果RT * 110%.
TPS > 扫描性能场景结果TPS * 90%.
发布时间 < 40s。
d. 发现的问题
1. 扫描性能场景
AVG RT = 473ms, CMS GC = 90ms, 应用暂停时间 = 1s, 因此测试未通过。
问题定位:
dump内存,使用ibm memory analyzer 分析。
确认cms gc的原因为drools引擎的finalize方法。Finzlize方法不能正确的释放对象的引用关系,导致引用关系一直存在,无法释放。
调优方案:
根据drools的升级文档,升级drools引擎后解决此问题
2. 发布性能场景
CMS GC 回收失败,内存无法被释放,应用宕机。
问题定位:
GC回收比例为默认值68%,OLD区内存1024M,那么回收的临界值为1024*0.68=696.32M。系统的JVM内存占用为500M,扫描策略相关的内存为120M,在切换的过程中,依赖额外的120M,因此只有在可用内存大于740M时才能正常回收。
解决方案:
调整JVM参数,扩大GC回收比例。
后续技术方案改造,使用增量发布解决此问题。
3. 扫描过程中发布性能场景
问题定位:
扫描平台发布流程,当首次请求进来时执行脚本动态编译过程,由于脚本较多,因此所有脚本的动态编译时间较长,在此过程中,进来的所有请求都会被hand住,造成大量超时
解决方案:
把脚本的动态编译提前到首次请求调用进来之前,编译通过后再切换扫描引擎,保证首次请求进来前一切准备就绪。
三:性能测试的执行和结果收集
3.1性能测试的执行
性能测试的执行需要具备以下几个条件:施压工具,测试环境以及对测试结果的收集工具。
3.1.1 施压工具
我们先来说说施压工具,支付宝使用的主流施压工具是开源工具Apache JMeter,支持很多类型的性能测试:
Web - HTTP, HTTPS
SOAP
Database via JDBC
LDAP
JMS
任何用java语言编写的接口,都可二次开发并调用。
支付宝大部分接口是webservice接口,基于soap协议,且都是java开发,所以使用jmeter非常方便,即使jemter工具本身没有自带支持的协议,也可以通过开发插件的方式支持。
3.1.2测试环境
测试环境包括被压机和施压机环境,需要进行硬件配置和软件版本确认,保证系统干净,无其他进程干扰,最好能提前监控半小时到1小时,确认系统各项指标都无异常。
另外除了被压机和施压机,有可能应用系统还依赖其他的系统,所以我们需要明确服务器的数量和架构,1是方便我们分析压力的流程,帮助后面定位和分析瓶颈,2是由于我们线下搭建的环境越接近线上,测试结果越准确。但是通常由于测试资源紧张或者需要依赖外围,例如银行的环境,就会比较麻烦,通常我们会选择适当的进行环境mock。当然,Mock的时候尽量和真实环境保持一致,举个简单的例子,如果支付宝端系统和银行进行通信,线上银行的平均处理时间为100ms,那么如果我们在线下性能测试时需要mock银行的返回,需要加入100ms延迟,这样才能比较接近真实的环境。
另外除了测试环境,还有依赖的测试数据也需要重点关注,数据需要关注总量和类型,例如支付宝做交易时,db中流水万级和亿级的性能肯定是不一样的;还有db是否分库分表,需要保证数据分布的均衡性。一般考虑到线下准备数据的时长,一般性能测试要求和线上的数据保持一个数量级。
3.1.3 测试结果收集工具
测试结果收集主要包括以下几个指标:
响应时间、tps、错误率、cpu、load、IO、系统内存、jvm(java虚拟内存)。
其中响应时间、tps和业务错误率通过jemter可以收集。
Cpu、load、io和系统内存可以通过nmon或linux自带命令的方式来监控。
Jvm可以通过jdk自带的jconsole或者jvisualvm来监控。
总体来说,监控了这些指标,对系统的性能就有了掌握,同样这样指标也可以反馈系统的瓶颈所在。
四.性能测试瓶颈挖掘与分析
我们在上面一章中拿到性能测试结果,这么多数据,怎么去分析系统的瓶颈在哪里呢,一般是按照这样的思路,先看业务指标:响应时间、业务错误率、和tps是否满足目标。
如果其中有一个有异常,可以先排除施压机和外围依赖系统是否有瓶颈,如果没有,关注网络、db的性能和连接数,最后关注系统本身的指标:
硬件:磁盘是否写满、内存是否够用、cpu的利用率、平均load值
软件:操作系统版本、jdk版本、jboss容器以及应用依赖的其他软件版本
Jvm内存管理和回收是否合理
应用程序本身代码
先看下图:是一般性能测试环境部署图
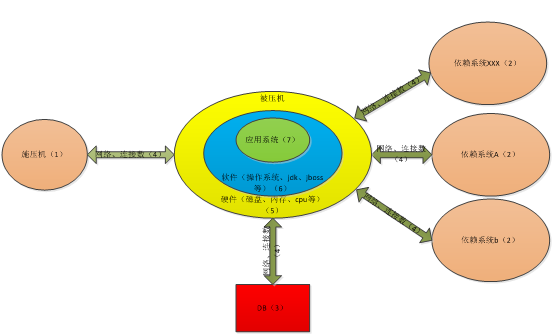
我们在定位的时候,可按照标注中的1、2、3数字依次进行排查,先排查施压机是否有瓶颈、接着看后端依赖系统、db、网络等,最后看被压机本身,例如响应时间逐渐变慢,一般来说是外围依赖的系统出现的瓶颈导致整体响应变慢。下面针对应用系统本身做下详细的分析,针对常见问题举1~2个例子:
4.1 应用系统本身的瓶颈
1. 应用系统负载分析:
服务器负载瓶颈经常表现为,服务器受到的并发压力比较低的情况下,服务器的资源使用率比预期要高,甚至高很多。导致服务器处理能力严重下降,最终有可能导致服务器宕机。实际性能测试工作中,经常会用以下三类资源指标判定是否存在服务器负载瓶颈:
1.CPU使用率
2,内存使用率
3.Load
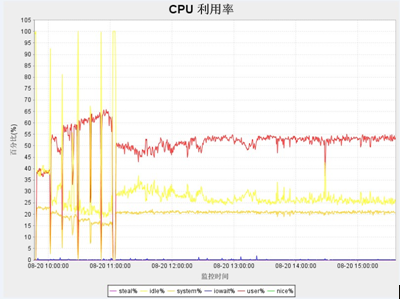
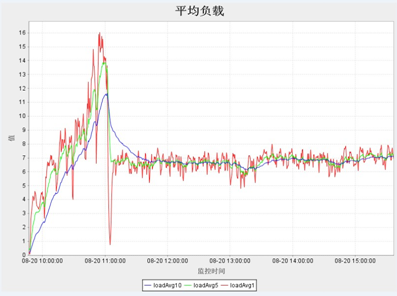
一般cup的使用率应低于50%,如果过高有可能程序的算法耗费太多cpu,或者某些代码块进行不合理的占用。Load值尽量保持在cpuS+2
或者cpuS*2,其中cpu和load一般与并发数成正比(如下图)
内存可以通过2种方式来查看:
1) 当vmstat命令输出的si和so值显示为非0值,则表示剩余可支配的物理内存已经严重不足,需要通过与磁盘交换内容来保持系统的稳定;由于磁盘处理的速度远远小于内存,此时就会出现严重的性能下降;si和so的值越大,表示性能瓶颈越严重。
2) 用工具监控内存的使用情况,如果出现下图的增长趋势(used曲线呈线性增长),有可能系统内存占满的情况:
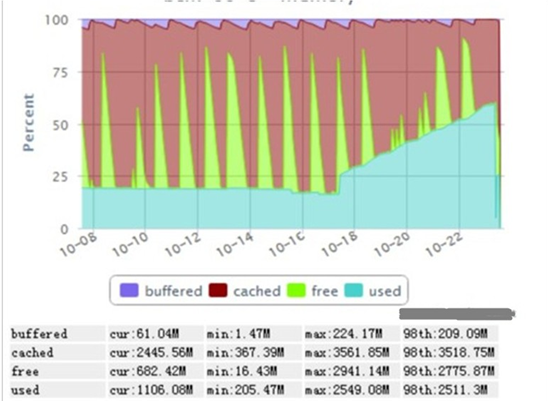
如果出现内存占用一直上升的趋势,有可能系统一直在创建新的线程,旧的线程没有销毁;或者应用申请了堆外内存,一直没有回收导致内存一直增长。
4.2 Jvm瓶颈分析
4.2.1Gc频率分析
对于java应用来说,过高的GC频率也会在很大程度上降低应用的性能。即使采用了并发收集的策略,GC产生的停顿时间积累起来也是不可忽略的,特别是出现cmsgc失败,导致fullgc时的场景。下面举几个例子进行说明:
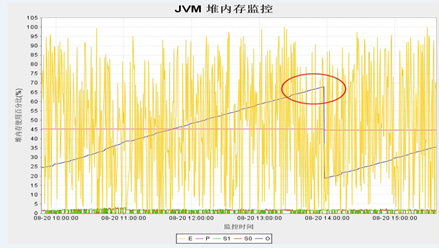
1. Cmsgc频率过高,当在一段较短的时间区间内,cmsGC值超出预料的大,那么说明该JAVA应用在处理对象的策略上存在着一些问题,即过多过快地创建了长寿命周期的对象,是需要改进的。或者old区大小分配或者回收比例设置得不合理,导致cms频繁触发,下面看一张gc监控图(蓝色线代表cmsgc)
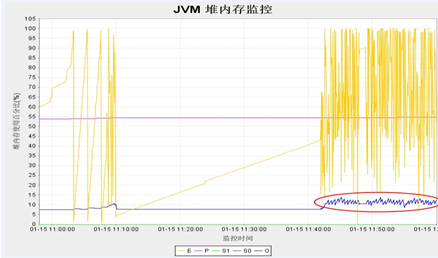
由图看出:cmsGC非常频繁,后经分析是因为jvm参数-XX:CMSInitiatingOccupancyFraction设置为15,比例太小导致cms比较频繁,这样可以扩大cmsgc占old区的比例,降低cms频率注。
调优后的图如下:
2. fullgc频繁触发
当采用cms并发回收算法,当cmsgc回收失败时会导致fullgc:

由上图可以看出fullgc的耗时非常长,在6~7s左右,这样会严重影响应用的响应时间。经分析是因为cms比例过大,回收频率较慢导致,调优方式:调小cms的回比例,尽早触发cmsgc,避免触发fullgc。调优后回收情况如下

可以看出cmsgc时间缩短了很多,优化后可以大大提高。从上面2个例子看出cms比例不是绝对的,需要根据应用的具体情况来看,比如应用创建的对象存活周期长,且对象较大,可以适当提高cms的回收比例。
3. 疑似内存泄露,先看下图
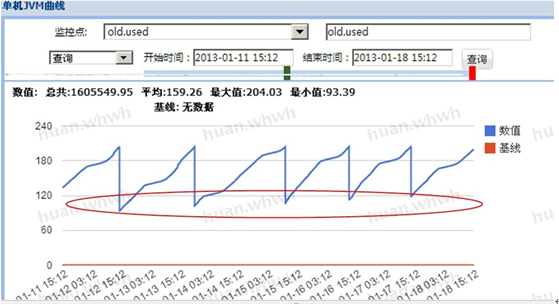
分析:每次cmsgc没有回收干净,old区呈上升趋势,疑似内存泄露
最终有可能导致OOM,这种情况就需要dump内存进行分析:
找到oom内存dump文件,具体的文件配置在jvm参数里:
-XX:HeapDumpPath=/home/admin/logs
-XX:ErrorFile=/home/admin/logs/hs_err_pid%p.log
借助工具:MAT,分析内存最大的对象。具体工具的使用这里就不再介绍。 | 




