| LoadRunner的强大也许不用我在此处多费唇舌,用过的同学自是可以深切体会一翻,没用过的同学用用就晓得啦~本文旨在针对一些想对loadrunner
有个初步了解并可以简单上手操作的同学做一个介绍,起到一个抛砖引玉的作用,更深入的使用以后会不定期的整理分享出来。主要介绍脚本及场景两部分内容。
1关于脚本
我们可以使用LoadRunner的Virtual user generator创建虚拟用户,以虚拟用户的方式模拟真实用户的业务操作行为,它会先记录业务流程,然后把它转化为脚本。利用虚拟用户,我们可以在业务主机上同时产生成千上万的用户访问。
1.1协议的选择
在录制脚本时选择那种方式呢:
如果应用是WEB应用,首选是HTML-based方式
如果应用是使用HTTP协议的非WEB应用,首选是URL-based方式
如果WEB应用中使用了java applet程序,且applet程序与服务器之间存在通讯,选用URL-based方式
如果WEB应用中使用的javascript、vbscript脚本与服务器之间存在通讯(调用了服务端组件),选用URL-based方式
基于以上分析,针对我们应用的特点,我们一般选择web(http/html)协议的html-based方式。采用这种方式录制的脚本,方便我们在后期增强脚本时做关联/参数化
1.2测试脚本规范
脚本越小越好。就像写code一样,不要太长,这样易于维护也易懂。尽量做到一个功能写一个脚本。如果那些功能是连续有序的,必须先做上一个,下一个动作才能进行,就只能放在一起了
插入事务。有时我们为了衡量某个action的性能,需要在action的开始和结束位置插入这样一个范围,这就定义了一个transaction,LoadRunner
运行到该事务的开始点时,LoadRunner 就会开始计时,直到运行到该事务的结束点,计时结束。这个事务的运行时间在结果中会有反映。插入事务操作可以在录制过程中进行,也可以在录制结束后进行。LoadRunner
可以在脚本中插入不限数量的事务。举个例子:比如购买书籍,把从登录到购买成功整个作为一个脚本,对于需要关注的输入资料到提交保存,定义为单独的事务,以取得响应时间,事务脚本函数如下:

只保留核心内容。录制后的脚本可能包含很多内容,而这些内容又不是我们本身应用所需要关注的,此时就需要对脚本进行修改,去除多余脚本,主要包括:删除cookies、删除关键字EXTRARS后面的url、删除不必要的url、删除一切带有敏感标记的内容(比如:不想压测到实际生产线上时,则需要删除www.*.com的所有相关内容)
脚本名称,事务名称、参数名称要做到见名知义。
1.3脚本增强
其实上面提到的去除多余脚本也可以放在这里来介绍,作为脚本增强的一个方面,外关于脚本增强的几个方面,就要涉及到以下内容:参数化,关联
1.3.1参数化
首先选择待参数化的内容,点击右键,选择”Replace with parameter”。在弹出的对话框中,填写参数名称、选择Parameter
Type,再点击Propeties,进行参数属性设置。
现选择最常用的一种参数类型,举例如下:假如我们要对登录进行性能测试,hello01是我们录制脚本时初始生成的用户名,当我们需要测试多个不同用户(eg:hello02\hello03……)时,就需要对用户名(密码同样操作)进行参数化操作,选中脚本中的“hello01”,点击右键后选择”Replace
with parameter”,设置“username”为其参数名称,类型选择file,再点击properties,对其进行具体内容设置,依次输入hello02\hello03……,并保存。如下图所示:
点击properties后,可对该参数进行个性化设置
“Select next row ”有以下几种选择:多个VU如何取值
- Sequential:按照顺序一行行的读取。每一个虚拟用户都会按照相同的顺序读取
- Random:在每次循环里随机的读取一个,但是在循环中一直保持不变
- Unique :每个VU取唯一的值。注意:使用该类型必须注意数据表有足够多的数。比如Controller
中设定20 个虚拟用户进行5 次循环,那么编号为1 的虚拟用户取前5个数,编号为2 的虚拟用户取6-10
的数,依次类推,这样数据表中至少要有100个数据,否则Controller 运行过程中会返回一个错误。
Same Line As 某个参数(比如username):
和前面定义的参数username 取同行的记录。通常用在有关联性的数据上面。这个也是很有用的,比如有时候我们要求指定VU取读取指定数据,就可以这样定义:创建参数文件,共两列,假设username、passwd,username设定取数方式是unique,passwd则设成
same line as icpcode,如果参数文件第一行数据为992201,200001,则当icpcode=992201时,icpservid会取200001。
“Update value on”有如下几种选择:多次迭代如何取值
- once在所有的反复中都使用同一个值,
- each iteration则每次反复都要取新值,
- each occurrence则只要发现该参数就要重新取值,即如果一个action中有多个该参数,每遇到一个就要重新取一个值。
1.3.2关联
关联是用来解决脚本中存在的动态数据问题的.当你回放一次后,LR会自动查找你录制的时候和回放时候的差别,找出动态数据,并作成参数。
如果用户想使用loadrunner自带的关联规则创建关联,那么需要在录制脚本时依次选择【Recording
Options】>【Internet Protocol】>【Correlation】中启用关联规则,选中“Enable
correlation during recording”,当录制这些应用系统的脚本时,VuGen会在脚本中自动建立关联。
如果需要在回放脚本时进行关联,loadrunner自动检测需要关联的部分,那么需要在【Tools】>【general
options】>【Correlation】中选中“save correlation information
during replay”和“show scan for correlations popup after
replay of vuser”,当回放玩脚本后,会弹出Scan action for correlation窗口,进行关联点的搜索。
如果没有进行上述设置,那么可以执行ctrl + F8此命令可启动自动关联。
1.4脚本验证
脚本修改完,一定要回放脚本来验证脚本的正确性。尤其是当功能环境与性能环境环境分开时,要确保脚本的运行只对性能环境产生压力而不能影响到功能环境。这就需要我们除了要观察回放后页面展示的正确性之外,还要注意数据流流向,如果涉及到写数据库的操作时,就需要去性能环境的数据库check一下,数据是否有写入进去;如果是涉及到读库操作的,最好在准备性能测试数据时就构造与功能数据库不同的数据以方便直接从页面显示上判断,如果没有的话,就用netstat命令来判断。
调试修改脚本时,可以在【Tools】>【general options】>【Display】中,选中所有项。这样做的好处在于,通过浏览器快照和report,查看脚本运行情况,方便查错。
注意:场景运行时,切记将所有项的勾去掉,否则会将loadrunner测试机的硬盘撑爆!而且也会影响到测试结果,产生TPS波动现象。
2创建运行场景(Controller)
当脚本创建好后,需要创建测试场景Scenario,一个运行场景包括一个运行虚拟用户的机器列表,一个测试脚本的列表,及大量的虚拟用户,然后利用LoadRunner的Controller来组织测试方案。
2.1虚拟用户数
虚拟用户数目会直接影响到压力的大小。在一般情况下,采用递增虚拟用户的方式来寻找系统能够承受的合理压力。比如,预估总虚拟用户数为20个,可以设置初始为2个,每5分钟增加1或2个用户。
2.2 场景选择
Loadrunner提供给我们两种方式的场景:Manual Scenario和Goal-Oriented
Scenario,根据实际情况具体选择哪种进行测试
Manual Scenario:该项要完全手动的设置场景,这项下面还可以设置为每一个脚本分配要运行的虚拟用户的百分比,可在Controller的Scenario菜单下设置。
Goal-Oriented Scenario:如果目标测试是要达到某个性能指标,比如:每秒多少点击,每秒多少transactions,能到达多少VU,某个Transaction在某个范围VU(50-100)内的反应时间等等,那么就可以使用面向目标的场景。
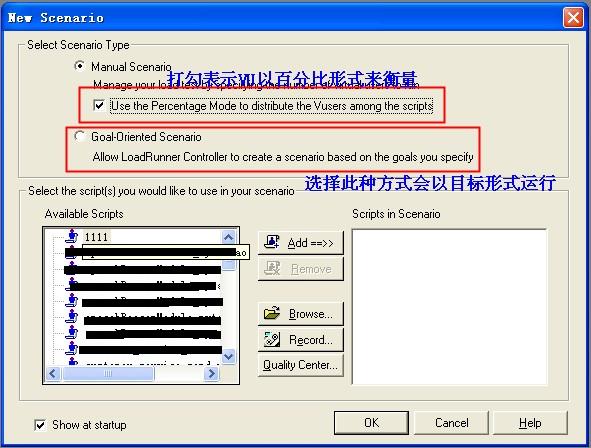
选择待运行的脚本后,点击add -> OK,进入到下图所示页面,点击Edit
Schedule按钮,可以对VU在整个场景中的加载、卸载及持续时间进行设置,同时还可以通过页面右边的Load
Preview 预览用户加载情况。
设置好后,接下来就要对Run-Time Setting进行设置了。
2.3 Run-Time Setting
VU中也有一个run-time setting,但作用有所不同,此处的设置主要用来对整个场景运行时进行约束,此时脚本的运行时设置就会失效;若在此没有对运行时设置,则按照脚本的设置来运行。一般情况下,会按照以下方式进行设置
Run Logic:设置成1;--比如设置这里为3,有2个并发用户,相当于执行了6次脚本
Log: 将Enable logging前面勾去掉;--即不打印输出日志,避免造成loadrunner压测机器磁盘撑爆
Think Time:一般情况,为了增大对服务器的压力而选择Ignore
think time;
Browser Emulation:一般情况下,不选择Smulate
brower cache和 Down non-HTML resousces;--不选择Smulate brower
cache 是为了最大程度模拟一个新用户打开链接时请求的都是服务器的资源而不是本地的一些浏览器中缓存的内容;不选择Down
non-HTML resousces是因为在压测时,更关注后端应用本身的性能,而不去下载存放在其他机器上的静态资源
Preferences:可以将Advanced下的File and line
in automatic transaction name取消掉;--目的也是为减少压测机本身资源的消耗。
其它设置项:使用默认设置即可。
2.4Result设置
场景设置好后,即将要开始运行。此时一定要记得的一件事情就是在【Result】>【Result
Settings】下将 directory指定到硬盘空间大一点的目录下。因为我们在压测过程中会产生大量的临时文件,如果放在默认目录C:\Documents
and Settings\hanshan\Local Settings\Temp下的话,一般C盘空间都不会太大,会导致压测机器本身磁盘爆掉,进而影响压测结果。
2.5应用服务器监控
按照前面的步骤一步步走下来后,就可以运行设定的好性能场景了。在运行时,一般需要关注应用的Running
Vusers,Trans Response Time,Trans/Sec(Passed), unix resources等。监控应用环境的系统资源(cpu\load等)使用情况,需要事先安装rstate守护程序。
关于测试结果
利用loadrunner的Analysis组件可以实现对整个测试场景的结果分析,场景结束后,在controller中可以点击【Resuluts】>【Analyze
Results】,即可实现。关于对测试结果的分析内容由于篇幅有限故不在本文中作详细介绍,有兴趣的同学可私下交流。 |


